深度学习基础1
目录
1. 深度学习的定义
2.神经网络
2.1. 感知神经网络
2.2 人工神经元
2.2.1 构建人工神经元
2.2.2 组成部分
2.2.3 数学表示
2.2.4 对比生物神经元
2.3 深入神经网络
2.3.1 基本结构
2.3.2 网络构建
2.3.3 全连接神经网络
3.神经网络的参数初始化
3.1 固定值初始化
3.1.1 全零初始化
3.1.2 全1初始化
3.1.3 任意常数初始化
3.2 随机初始化
3.2.1 均匀初始化
3.2.2 正态分布初始化
3.3 Xavier 初始化 / Glorot 初始化
3.4 He初始化 / kaiming 初始化
4.激活函数
4.1 非线性
4.2 非线性可视化
4.3 常见激活函数
4.3.1 Sigmoid
4.2.2 Tanh
4.2.3 ReLU
2.2.4 LeakyReLU
4.2.5 Softmax
4.4 选择激活函数
4.4.1 隐藏层
4.4.2 输出层
1. 深度学习的定义
传统机器学习算法依赖人工设计特征、提取特征,而深度学习依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从大量数据中学习特征,这也是深度学习被看做黑盒子、可解释性差的原因。
人工智能、机器学习和深度学习之间的关系:

2.神经网络
深度学习(Deep Learning)是神经网络的一个子领域,主要关注更深层次的神经网络结构,也就是深层神经网络(Deep Neural Networks,DNNs)。
2.1. 感知神经网络
神经网络(Neural Networks)是一种模拟人脑神经元网络结构的计算模型,用于处理复杂的模式识别、分类和预测等任务。生物神经元如下图:

生物学:
人脑可以看做是一个生物神经网络,由众多的神经元连接而成
-
树突:从其他神经元接收信息的分支
-
细胞核:处理从树突接收到的信息
-
轴突:被神经元用来传递信息的生物电缆
-
突触:轴突和其他神经元树突之间的连接
人脑神经元处理信息的过程:
-
多个信号到达树突,然后整合到细胞体的细胞核中
-
当积累的信号超过某个阈值,细胞被激活
-
产生一个输出信号,由轴突传递。
神经网络由多个互相连接的节点(即人工神经元)组成。
2.2 人工神经元
人工神经元(Artificial Neuron)是神经网络的基本构建单元,模仿了生物神经元的工作原理。其核心功能是接收输入信号,经过加权求和和非线性激活函数处理后,输出结果。
2.2.1 构建人工神经元
人工神经元接受多个输入信息,对它们进行加权求和,再经过激活函数处理,最后将这个结果输出。

2.2.2 组成部分
-
输入(Inputs): 代表输入数据,通常用向量表示,每个输入值对应一个权重。
-
权重(Weights): 每个输入数据都有一个权重,表示该输入对最终结果的重要性。
-
偏置(Bias): 一个额外的可调参数,作用类似于线性方程中的截距,帮助调整模型的输出。
-
加权求和: 神经元将输入乘以对应的权重后求和,再加上偏置。
-
激活函数(Activation Function): 用于将加权求和后的结果转换为输出结果,引入非线性特性,使神经网络能够处理复杂的任务。常见的激活函数有Sigmoid、ReLU(Rectified Linear Unit)、Tanh等。
2.2.3 数学表示

2.2.4 对比生物神经元
人工神经元和生物神经元对比如下表:
| 生物神经元 | 人工神经元 |
|---|---|
| 细胞核 | 节点 (加权求和 + 激活函数) |
| 树突 | 输入 |
| 轴突 | 带权重的连接 |
| 突触 | 输出 |
2.3 深入神经网络
神经网络是由大量人工神经元按层次结构连接而成的计算模型。每一层神经元的输出作为下一层的输入,最终得到网络的输出。
2.3.1 基本结构
神经网络有下面三个基础层(Layer)构建而成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结果
2.3.2 网络构建
我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个权重,经典如下:

注意:同一层的各个神经元之间是没有连接的。
2.3.3 全连接神经网络
全连接(Fully Connected,FC)神经网络是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接,常用于图像分类、文本分类等任务。
特点:
-
全连接层: 层与层之间的每个神经元都与前一层的所有神经元相连。
-
权重数量: 由于全连接的特点,权重数量较大,容易导致计算量大、模型复杂度高。
-
学习能力: 能够学习输入数据的全局特征,但对于高维数据却不擅长捕捉局部特征。
计算步骤:
(1)数据传递: 输入数据经过每一层的计算,逐层传递到输出层。
(2)激活函数: 每一层的输出通过激活函数处理。
(3)损失计算: 在输出层计算预测值与真实值之间的差距,即损失函数值。
(4)反向传播(Back Propagation): 通过反向传播算法计算损失函数对每个权重的梯度,并更新权重以最小化损失。
3.神经网络的参数初始化
神经网络的参数初始化是训练深度学习模型的关键步骤之一。初始化参数(通常是权重和偏置)会对模型的训练速度、收敛性以及最终的性能产生重要影响。
官方文档参考:torch.nn.init — PyTorch 2.5 documentation
3.1 固定值初始化
固定值初始化是指在神经网络训练开始时,将所有权重或偏置初始化为一个特定的常数值。
3.1.1 全零初始化
将神经网络中的所有权重参数初始化为0。
方法:将所有权重初始化为零。
缺点:导致对称性破坏,每个神经元在每一层中都会执行相同的计算,模型无法学习。
应用场景:通常不用来初始化权重,但可以用来初始化偏置。
import torch
import torch.nn as nnlinear =nn.Linear(in_features=6,out_features=4)
nn.init.zeros_(linear.weight)print(linear.weight)3.1.2 全1初始化
全1初始化会导致网络中每个神经元接收到相同的输入信号,进而输出相同的值,这就无法进行学习和收敛。所以全1初始化只是一个理论上的初始化方法,但在实际神经网络的训练中并不适用。
linear =nn.Linear(in_features=6,out_features=4)
nn.init.ones_(linear.weight)print(linear.weight)3.1.3 任意常数初始化
将所有参数初始化为某个非零的常数。虽然不同于全0和全1,但这种方法依然不能避免对称性破坏的问题。
linear =nn.Linear(in_features=6,out_features=4)
nn.init.constant_(linear.weight,0.54)print(linear.weight)3.2 随机初始化
方法:将权重初始化为随机的小值,通常从正态分布或均匀分布中采样。
应用场景:这是最基本的初始化方法,通过随机初始化避免对称性破坏。
3.2.1 均匀初始化
linear =nn.Linear(in_features=6,out_features=4)
nn.init.uniform_(linear.weight)print(linear.weight)3.2.2 正态分布初始化
linear =nn.Linear(in_features=6,out_features=4)
nn.init.normal_(linear.weight,mean=4,std=2)print(linear.weight)3.3 Xavier 初始化 / Glorot 初始化
方法:根据输入和输出神经元的数量来选择权重的初始值。权重从以下分布中采样:

优点:平衡了输入和输出的方差,适合Sigmoid 和 Tanh 激活函数。
应用场景:常用于浅层网络或使用Sigmoid 、Tanh 激活函数的网络。
linear = nn.Linear(in_features=6,out_features=4)
nn.init.xavier_normal_(linear.weight)print(linear.weight)linear = nn.Linear(in_features=6,out_features=4)
nn.init.xavier_uniform_(linear.weight)print(linear.weight)3.4 He初始化 / kaiming 初始化
方法:专门为 ReLU 激活函数设计。权重从以下分布中采样:

优点:适用于ReLU 和 Leaky ReLU 激活函数。
应用场景:深度网络,尤其是使用 ReLU 激活函数时。
linear = nn.Linear(in_features=6,out_features=4)
nn.init.kaiming_normal_(linear.weight)print(linear.weight)linear = nn.Linear(in_features=6,out_features=4)
nn.init.kaiming_uniform_(linear.weight)print(linear.weight)4.激活函数
激活函数的作用是在隐藏层引入非线性,使得神经网络能够学习和表示复杂的函数关系,使网络具备非线性能力,增强其表达能力。
4.1 非线性
如果在隐藏层不使用激活函数,那么整个神经网络会表现为一个线性模型。
线性模型中无论网络多少层:
- 无法捕捉数据中的非线性关系。
- 激活函数是引入非线性特性、使神经网络能够处理复杂问题的关键。
4.2 非线性可视化
可以通过可视化的方式去理解非线性的拟合能力
A Neural Network Playground

4.3 常见激活函数
激活函数通过引入非线性来增强神经网络的表达能力,对于解决线性模型的局限性至关重要。由于反向传播算法(BP)用于更新网络参数,因此激活函数必须是可微的,也就是说能够求导的。
4.3.1 Sigmoid
Sigmoid激活函数是一种常见的非线性激活函数。它将输入映射到0到1之间的值,因此非常适合处理概率问题,比如二分类问题。
公式:

其中,e 是自然常数(约等于2.718),x 是输入。
特征:
- 将任意实数输入映射到 (0, 1)之间。
- sigmoid函数一般只用于二分类的输出层。
- 微分性质: 导数计算比较方便,可以用自身表达式来表示:
![]()
缺点:
-
梯度消失: 在输入非常大或非常小时,Sigmoid函数的梯度会变得非常小,接近于0。这导致在反向传播过程中,梯度逐渐衰减。最终使得早期层的权重更新非常缓慢,进而导致训练速度变慢甚至停滞。
-
信息丢失:输入的数据相差巨大,但输出结果变化小。
-
计算成本高: 由于涉及指数运算。
函数绘制:
import torch
import matplotlib.pyplot as plt# 中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False_,ax = plt.subplots(1,2)# 1.绘制sigmoid函数
x = torch.linspace(-10,10,100)
y = torch.sigmoid(x)ax[0].grid(True)
ax[0].set_title('sigmoid函数曲线图')
ax[0].set_xlabel('x')
ax[0].set_ylabel('y')
ax[0].plot(x,y)# 2.绘制sigmoid导函数
x1 = torch.linspace(-10,10,100)y1 =torch.sigmoid(x1)*(1-torch.sigmoid(x1))ax[1].grid(True)
ax[1].set_title('sigmoid函数曲线图')
ax[1].set_xlabel('x1')
ax[1].set_ylabel('y1')
ax[1].plot(x1,y1)
ax[1].lines[0].set_color('red')plt.show()
4.2.2 Tanh
tanh(双曲正切)是一种常见的非线性激活函数,常用于神经网络的隐藏层。tanh 函数也是一种S形曲线,输出范围为(−1,1)。
公式:

特征:
-
输出范围: 将输入映射到(-1, 1)之间。相比于Sigmoid函数,这种零中心化的输出有助于加速收敛。
-
对称性: Tanh函数关于原点对称,因此在输入为0时,输出也为0。这种对称性有助于在训练神经网络时使数据更平衡。
-
平滑性: Tanh函数在整个输入范围内都是连续且可微的,这使其非常适合于使用梯度下降法进行优化。
缺点:
-
梯度消失: 虽然一定程度上改善了梯度消失问题,但在输入值非常大或非常小时导数还是非常小,这在深层网络中仍然是个问题。
-
计算成本: 由于涉及指数运算。
函数绘制:

4.2.3 ReLU
ReLU(Rectified Linear Unit)全称是修正线性单元。
公式:
ReLU 函数定义如下:
![]()
即ReLU对输入x进行非线性变换:

特征:
-
计算简单:ReLU 的计算非常简单,只需要对输入进行一次比较运算,这在实际应用中大大加速了神经网络的训练。
-
ReLU 函数的导数是分段函数:

-
缓解梯度消失问题:相比于 Sigmoid 和 Tanh 激活函数,ReLU 在正半区的导数恒为 1,这使得深度神经网络在训练过程中可以更好地传播梯度,不存在饱和问题。
-
稀疏激活:ReLU在输入小于等于 0 时输出为 0,这使得 ReLU 可以在神经网络中引入稀疏性(即一些神经元不被激活),这种稀疏性可以提升网络的泛化能力。
缺点:
神经元死亡:由于ReLU在x≤0时输出为0,如果某个神经元输入值是负,那么该神经元将永远不再激活,成为“死亡”神经元。随着训练的进行,网络中可能会出现大量死亡神经元,会降低模型的表达能力。
函数绘图:
# 创建子图
fig, ax = plt.subplots(1, 2)# 1. 绘制 relu 函数
x = torch.linspace(-10, 10, 100)
y = torch.relu(x)ax[0].grid(True)
ax[0].set_title('relu函数曲线图')
ax[0].set_xlabel('x')
ax[0].set_ylabel('y')
ax[0].plot(x, y, label='relu函数')# 2. 绘制 relu 导函数
x1 = torch.linspace(-10, 10, 100, requires_grad=True)
torch.relu(x1).sum().backward()ax[1].grid(True)
ax[1].set_title('relu导函数曲线图')
ax[1].set_xlabel('x1')
ax[1].set_ylabel('y1')
ax[1].plot(x1.detach().numpy(), x1.grad.detach().numpy(), color='red', label='relu导函数')# 添加图例
ax[0].legend()
ax[1].legend()plt.tight_layout()
plt.show()
2.2.4 LeakyReLU
Leaky ReLU是一种对 ReLU 函数的改进,旨在解决 ReLU 的一些缺点,特别是Dying ReLU 问题。Leaky ReLU 通过在输入为负时引入一个小的负斜率来改善这一问题。
公式:
Leaky ReLU 函数的定义如下:

其中,\alpha 是一个非常小的常数(如 0.01),它控制负半轴的斜率。这个常数 \alpha是一个超参数,可以在训练过程中可自行进行调整。
特征:
-
避免神经元死亡:通过在负半区域引入一个小的负斜率,这样即使输入值小于等于零,Leaky ReLU仍然会有梯度,允许神经元继续更新权重,避免神经元在训练过程中完全“死亡”的问题。
-
计算简单:Leaky ReLU 的计算与 ReLU 相似,只需简单的比较和线性运算,计算开销低。
缺点:
-
参数选择:\alpha 是一个需要调整的超参数,选择合适的\alpha 值可能需要实验和调优。
-
出现负激活:如果\alpha 设定得不当,仍然可能导致激活值过低。
函数绘制:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 创建子图
fig, ax = plt.subplots(1, 2)# 1. 绘制 leaky_relu 函数
x = torch.linspace(-5, 5, 200, requires_grad=True)
slope = 0.03
y = F.leaky_relu(x, slope)ax[0].grid(True)
ax[0].set_title('leaky_relu函数曲线图')
ax[0].set_xlabel('x')
ax[0].set_ylabel('y')
ax[0].plot(x.detach().numpy(), y.detach().numpy(), label='leaky_relu函数')# 2. 绘制 leaky_relu 导函数
y.sum().backward() # 计算梯度ax[1].grid(True)
ax[1].set_title('leaky_relu导函数曲线图')
ax[1].set_xlabel('x')
ax[1].set_ylabel('y')
ax[1].plot(x.detach().numpy(), x.grad.detach().numpy(), color='red', label='leaky_relu导函数')# 添加图例
ax[0].legend()
ax[1].legend()plt.tight_layout()
plt.show()
4.2.5 Softmax
Softmax激活函数通常用于分类问题的输出层,它能够将网络的输出转换为概率分布,使得输出的各个类别的概率之和为 1。Softmax 特别适合用于多分类问题。
公式:

特征:
-
将输出转化为概率:通过Softmax,可以将网络的原始输出转化为各个类别的概率,从而可以根据这些概率进行分类决策。
-
概率分布:Softmax的输出是一个概率分布,即每个输出值\text{Softmax}(z_i)都是一个介于0和1之间的数,并且所有输出值的和为 1

-
突出差异:Softmax会放大差异,使得概率最大的类别的输出值更接近1,而其他类别更接近0。
-
在实际应用中,Softmax常与交叉熵损失函数Cross-Entropy Loss结合使用,用于多分类问题。在反向传播中,Softmax的导数计算是必需的。

缺点:
(1)数值不稳定性:在计算过程中,如果z_i的数值过大,e^{z_i}可能会导致数值溢出。因此在实际应用中,经常会对z_i进行调整,如减去最大值以确保数值稳定。

解释:
- z_i-\max(z)是一个非正数,那么e^{z_i - \max(z)}的值就位于0到1之间,有效避免了数值溢出。
- 这中调整不会改变Softmax的概率分布结果,因为从数学的角度讲相当于分子、分母都除以了e^{\max(z)}。
(2)难以处理大量类别:Softmax在处理类别数非常多的情况下(如大模型中的词汇表)计算开销会较大。
代码示例:
x = torch.Tensor([[0.8,10,2,4.5],[1.32,6.0,7.71,11]])
y = nn.Softmax(x)
print(y)x = torch.Tensor([[0.8,10,2,4.5],[1.32,6.0,7.71,11]])
y = F.softmax(x)
print(y)4.4 选择激活函数
更多激活函数可以查看官方文档:
torch.nn — PyTorch 2.5 documentation

4.4.1 隐藏层
-
优先选ReLU;
-
如果ReLU效果较差,那么尝试其他激活函数,如Leaky ReLU等;
-
使用ReLU时注意神经元死亡问题, 避免出现过多神经元死亡;
-
不使用sigmoid,尝试使用tanh;
4.4.2 输出层
-
二分类问题选择sigmoid激活函数;
-
多分类问题选择softmax激活函数;
-
回归问题选择identity激活函数;
相关文章:
深度学习基础1
目录 1. 深度学习的定义 2.神经网络 2.1. 感知神经网络 2.2 人工神经元 2.2.1 构建人工神经元 2.2.2 组成部分 2.2.3 数学表示 2.2.4 对比生物神经元 2.3 深入神经网络 2.3.1 基本结构 2.3.2 网络构建 2.3.3 全连接神经网络 3.神经网络的参数初始化 3.1 固定值初…...

《FPGA开发工具》专栏目录
《FPGA开发工具》专栏目录 1.Vivado开发 1.1使用相关 Vivado工程创建、仿真、下载与固化全流程 Vivado工程快速查看软件版本与器件型号 Vivado IP核的快速入门 官方手册和例程 Vivado中对已调用IP核的重命名 Vivado中增加源文件界面中各选项的解释 Vivado IP中Generate…...

李春葆《数据结构》-查找-课后习题代码题
一:设计一个折半查找算法,求查找到关键字为 k 的记录所需关键字的比较次数。假设 k 与 R[i].key 的比较得到 3 种情况,即 kR[i].key,k<R[i].key 或者 k>R[i].key,计为 1 次比较(在教材中讨论关键字比…...

【Git】:分支管理
目录 理解分支 创建分支 切换分支 合并分支 删除分支 合并冲突 分支管理策略 快进合并 正常合并 bug 分支 总结 理解分支 在版本控制系统中,分支是一条独立的开发线路。它允许开发者从一个主要的代码基线(例如master分支)分离出来…...

C、C++ 和 Java的区别
C、C 和 Java 是三种广泛使用的编程语言,它们各有特点,适合不同的应用场景。以下从多个角度对它们的区别进行分析: 基础特性 特性CCJava语言类型过程式编程语言过程式 面向对象编程语言纯面向对象编程语言(也支持过程式&#x…...

【Python-Open3D学习笔记】005Mesh相关方法
TriangleMesh相关方法 文章目录 TriangleMesh相关方法1. 查看mesh三角形面信息2. 可视化三角形3. 上采样4. 计算mesh形成的面积和体积 1. 查看mesh三角形面信息 def view_hull_triangles(hull: o3d.geometry.TriangleMesh):"""查看mesh三角形面信息(…...

js原型、原型链和继承
文章目录 一、原型1、prototype2、constructor 二、原型链1、字面量原型链2、字面量继承3、构造函数的原型链4、Object.create5、Object.setPrototypeOf 三、继承1、构造函数继承2、原型链继承3、组合继承 四、常见链条1、Function2、Object.prototype 继承是指将特性从父代传递…...

团队自创【国王的魔镜-2】
国王的魔镜-2 题目描述 国王有一个魔镜,可以把任何接触镜面的东西变成原来的两倍——只是,因为是镜子嘛,增加的那部分是反的。比如一条项链,我们用AB来表示,不同的字母表示不同颜色的珍珠。如果把B端接触镜面的话&am…...

c++编程玩转物联网:使用芯片控制8个LED实现流水灯技术分享
在嵌入式系统中,有限的GPIO引脚往往限制了硬件扩展能力。74HC595N芯片是一种常用的移位寄存器,通过串行输入和并行输出扩展GPIO数量。本项目利用树莓派Pico开发板与74HC595N芯片,驱动8个LED实现流水灯效果。本文详细解析项目硬件连接、代码实…...

【Jenkins】docker 部署 Jenkins 踩坑笔记
文章目录 1. docker pull 超时2. 初始化找不到 initialAdminPassword 1. docker pull 超时 docker pull 命令拉不下来 docker pull jenkins/jenkins:lts-jdk17 Error response from daemon: Get "https://registry-1.docker.io/v2/": 编辑docker配置 sudo mkdir -…...

Unreal Engine使用Groom 打包后报错
Unreal Engine使用Groom打包后报错 版本5.4.4 blender 4.2.1 项目头发用了groom,运行后报错 错误: Assertion failed: Offset BytesToRead < UncompressedFileSize && Offset > 0 [File:E:\UnrealEngine-5.4.4-release\Engine\Source\R…...

嵌入式QT学习第3天:UI设计器的简单使用
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 Qt Creator 里自带的 Qt Designer,使用 Qt Designer 比较方便的构造 UI 界 面。 在 UI 文件添加一个按钮 左边找到 Push Button,然后拖拽到中…...

【连接池】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

图论入门编程
卡码网刷题链接:98. 所有可达路径 一、题目简述 二、编程demo 方法①邻接矩阵 from collections import defaultdict #简历邻接矩阵 def build_graph(): n, m map(int,input().split()) graph [[0 for _ in range(n1)] for _ in range(n1)]for _ in range(m): …...
)
在Java中使用Apache POI导入导出Excel(三)
本文将继续介绍POI的使用,上接在Java中使用Apache POI导入导出Excel(二) 使用Apache POI组件操作Excel(三) 24、拆分和冻结窗格 您可以创建两种类型的窗格;冻结窗格和拆分窗格。 冻结窗格按列和行进行拆分。您创建…...

UR开始打中国牌,重磅发布国产化协作机器人UR7e 和 UR12e
近日,优傲(UR)机器人公司立足中国市场需求,重磅推出UR7e和UR12e 两款本地化协作机器人。它们延续优傲(UR)一以贯之的高品质与性能特质,着重优化负载自重比,且在价格层面具竞争力&…...

FRU文件
FRU(Field Replaceable Unit)源文件的格式通常遵循IPMI FRU Information Storage Definition标准。在实际应用中,FRU源文件可以是JSON格式的,这种格式允许用户指定所有的FRU信息字段。以下是FRU源文件的JSON格式的一些关键点&…...

AI需求条目化全面升级!支持多格式需求,打破模板限制!
AI需求条目化全面升级!支持多格式需求,打破模板限制! 一、多格兼济 标准立成 1、功能揭秘 预览未来 平台需求板块的AI需求条目化功能迎来全面升级。它支持多种需求格式,不再受限于模板文件,能够一键自动快速且灵活地生…...

Java—I/O流
Java的I/O流(输入/输出流)是用于在程序和外部资源(如文件、网络连接等)之间进行数据交换的机制。通过I/O流,可以实现从外部资源读取数据(输入流)或将数据写入外部资源(输出流&#x…...

Huginn服务部署
工作中需要使用爬虫系统,做为技术选型需要对Huginn系统进行部署并进行功能验证。下面的文章会记录了Huginn的部署过程,本次部署采用的Ubuntu-23.0.4系统,使用Docker部署。部署过程需要翻墙。 一、安装Docker 删除旧版本 sudo apt-get remo…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...
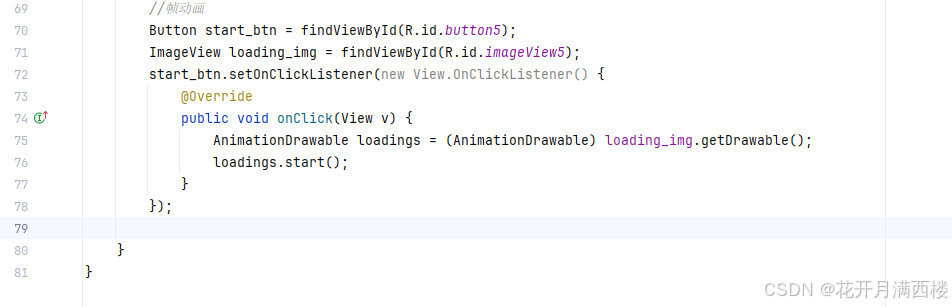
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...

CppCon 2015 学习:Reactive Stream Processing in Industrial IoT using DDS and Rx
“Reactive Stream Processing in Industrial IoT using DDS and Rx” 是指在工业物联网(IIoT)场景中,结合 DDS(Data Distribution Service) 和 Rx(Reactive Extensions) 技术,实现 …...

基于Uniapp的HarmonyOS 5.0体育应用开发攻略
一、技术架构设计 1.混合开发框架选型 (1)使用Uniapp 3.8版本支持ArkTS编译 (2)通过uni-harmony插件调用原生能力 (3)分层架构设计: graph TDA[UI层] -->|Vue语法| B(Uniapp框架)B --&g…...

RKNN开发环境搭建2-RKNN Model Zoo 环境搭建
目录 1.简介2.环境搭建2.1 启动 docker 环境2.2 安装依赖工具2.3 下载 RKNN Model Zoo2.4 RKNN模型转化2.5编译C++1.简介 RKNN Model Zoo基于 RKNPU SDK 工具链开发, 提供了目前主流算法的部署例程. 例程包含导出RKNN模型, 使用 Python API, CAPI 推理 RKNN 模型的流程. 本…...