MySQL底层概述—7.优化原则及慢查询
大纲
1.Explain概述
2.Explain详解
3.索引优化数据准备
4.索引优化原则详解
5.慢查询设置与测试
6.慢查询SQL优化思路
1.Explain概述
使用Explain关键字可以模拟查询优化器来执行SQL查询语句,从而知道MySQL是如何处理SQL语句的,从而分析出查询语句和表结构的性能瓶颈。
MySQL查询过程:


通过Explain可以获得以下信息:
一.表的读取顺序
二.数据读取操作的操作类型
三.哪些索引可以被使用
四.哪些索引真正被使用
五.表的直接引用
六.每张表的有多少行被优化器查询了
Explain使用方式:Explain + SQL语句,通过执行Explain可以获得SQL语句执行的相关信息。
EXPLAIN SELECT * FROM L1;
2.Explain详解
(1)数据准备
(2)ID字段说明
(3)select_type和table字段说明
(4)type字段说明
(5)possible_keys与key说明
(6)key_len字段说明
(7)ref字段说明
(8)rows字段说明
(9)filtered字段说明
(10)extra字段说明
(1)数据准备
-- 创建数据库CREATE DATABASE test CHARACTER SET 'utf8';-- 创建表CREATE TABLE L1(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );CREATE TABLE L2(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );CREATE TABLE L3(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );CREATE TABLE L4(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );-- 每张表插入3条数据INSERT INTO L1(title) VALUES('test001'),('test002'),('test003');INSERT INTO L2(title) VALUES('test004'),('test005'),('test006');INSERT INTO L3(title) VALUES('test007'),('test008'),('test009');INSERT INTO L4(title) VALUES('test010'),('test011'),('test012');
(2)ID字段说明
ID字段代表SELECT查询的序列号,它是一组数字,表示的是查询或操作表的顺序。
一.ID相同,执行顺序就是由上至下
EXPLAIN SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id;
二.ID不同,如果有子查询,ID号会递增
ID值越大优先级越高,越先被执行。
EXPLAIN SELECT * FROM L2 WHERE id = (SELECT id FROM L1 WHERE id = (SELECT L3.id FROM L3 WHERE L3.title = 'test007')
);
(3)select_type和table字段说明
select_type表示查询类型,主要用于区别普通查询还是子查询等,table表示被操作的表。
一.SIMPLE:简单的SELECT查询,查询中不包含子查询或者UNION
EXPLAIN SELECT * FROM L1 where id = 1;
二.PRIMARY:在有子查询的情况下,最外层被标记为PRIMARY
三.SUBQUERY:在SELECT或WHERE列表中包含了子查询
EXPLAIN SELECT * FROM L2 WHERE id = (SELECT id FROM L1 WHERE id = (SELECT L3.id FROM L3 WHERE L3.title = 'test08')
);
四.UNION:UNION连接的两个SELECT查询
在使用UNION时,左边的表的select_type是DERIVED,右边的表的select_type是UNION。
五.DERIVED:在FROM列表中包含的子查询被标记为DERIVED派生表
MySQL会递归执行这些被标记为DERIVED的子查询,然后把结果放到临时表中。
六.UNION RESULT:UNION的结果
EXPLAIN SELECT * FROM (SELECT * FROM L3 UNION SELECT * FROM L4) a;
(4)type字段说明
type字段表示的是连接类型,描述了找到所需数据而使用的扫描方式。
下面给出各种连接类型,按照从最好类型到最差类型进行排序:system -> const -> eq_ref -> ref -> fulltext -> ref_or_null -> index_merge -> unique_subquery -> index_subquery -> range -> index -> ALL
简化后,可以只关注以下几种 :system -> const -> eq_ref -> ref -> range -> index -> ALL
一般来说,需要保证查询至少达到range级别,最好能达到ref级别,否则就要就行SQL的优化调整。
下面介绍type字段不同值表示的含义:
一.system
表示表中仅有一行数据,这是const连接类型的一个特例,很少出现。
二.const
表示命中主键索引(primary key)或唯一索引(unique),通过主键索引或唯一索引一次就找到了数据。因为只匹配一条记录,所以被连接的部分是一个常量。如果将主键放在where条件中,MySQL就能将该查询转换为一个常量。这种类型非常快,例如以下查询:
EXPLAIN SELECT * FROM L1 WHERE id = 3;-- 为L1表的title字段添加唯一索引ALTER TABLE L1 ADD UNIQUE(title);EXPLAIN SELECT * FROM L1 WHERE title = 'test001';

三.eq_ref
表示的是使用了唯一索引。比如连表查询中,对于前一个表中的每一行,后表只有一行被扫描。除了system和const类型之外,这是最好的连接类型。只有在连表时使用的索引都是主键或唯一索引时,才会出现这种类型,例如以下查询:
EXPLAIN SELECT L1.id,L1.title FROM L1 LEFT JOIN L2 ON L1.id = L2.id;
四.ref
表示使用了普通索引,即非唯一性索引。比如连表时对于前表的每一行,后表可能有多于一行的数据被扫描,例如以下查询:
-- 为L1表的title字段添加普通索引ALTER TABLE L1 ADD INDEX idx_title (title);EXPLAIN SELECT * FROM L1 INNER JOIN L2 ON L1.title = L2.title;-- 如果L1表的title字段没有唯一索引,只有普通索引,如下查询也是refEXPLAIN SELECT * FROM L1 WHERE title = 'test001';

五.range
表示的是进行了索引上的范围查询,检索了给定范围的行,比如between、in函数、>都是典型的范围查询,例如以下查询:
EXPLAIN SELECT * FROM L1 WHERE L1.id BETWEEN 1 AND 10;
注意:当in函数中的数据很大时,可能会导致效率下降,最终不走索引。
六.index
当可以使用索引覆盖,但需要扫描全部索引记录时,则type为index。
当需要执行全表扫描,且需要对主键进行排序时,则type也为index。
所以如果type的值等于index,那么就需要进行优化了。因为出现index表示没有通过索引进行过滤,需要扫描索引的全部数据。index会遍历扫描索引树,比ALL快一些。如果索引文件过大,index的速度还是会很慢的。
总结:
当遍历二级索引不需要回表或者主键排序全表扫描时,type就为index。
注意:
使用索引进行排序分组时,可能会出现这种type值为index的情况。比如进行统计操作时,会出现type值为index的情况。
EXPLAIN SELECT * FROM L2 GROUP BY id ORDER BY id;-- 该count查询需要通过扫描索引上的全部数据来计数EXPLAIN SELECT count(*) FROM L2;

七.ALL
表示没有使用到任何索引,连表查询时对于前表的每一行,后表都要被全表扫描。
EXPLAIN SELECT * FROM L3 inner join L4 on L3.title = L4.title;
总结各类type类型的特点:
system:不进行磁盘IO,查询系统表,仅仅返回一条数据。
const:查找主键索引,最多返回1条或0条数据,属于精确查找。
eq_ref:查找唯一性索引,返回数据最多一条,属于精确查找。
ref:查找非唯一性索引,返回匹配的多条数据,属于精确查找。
range:查找索引中给定范围的行,属于范围查找(>、<、in、between)。
index:使用了索引但扫描全部了,比all快,因索引文件比数据文件小。
index:比如遍历二级索引不需要回表或者主键排序全表扫描。
all:不使用任何索引,直接进行全表扫描。
(5)possible_keys与key说明
一.possible_keys
表示可能用于查询的表上的索引。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
二.key
表示实际使用的索引。若为null,则表示没有使用到索引或索引失效。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
情形一:理论和实际都用到了索引
EXPLAIN SELECT * FROM L1 WHERE id = 1;
情形二:理论上没有使用索引,但实际上使用了
EXPLAIN SELECT L3.id FROM L3;
情形三:理论和实际上都没有使用索引
EXPLAIN SELECT * FROM L3 WHERE title = 'test007';
(6)key_len字段说明
表示索引中使用的字节数,通过该列可以计算查询中使用索引的长度。key_len字段能够帮我们检查是否充分利用了索引,ken_len越长越好,说明索引使用的越充分。
一.创建表
CREATE TABLE L5(a INT PRIMARY KEY,b INT NOT NULL,c INT DEFAULT NULL,d CHAR(10) NOT NULL);
二.使用EXPLAIN进行测试
-- 下面的查询只用到了主键a的索引EXPLAIN SELECT * FROM L5 WHERE a > 1 AND b = 1;
观察key_len的值,用到了主键索引,是int类型的,所以key_len是4字节。

三.为b字段添加索引,进行测试
ALTER TABLE L5 ADD INDEX idx_b(b);-- 执行SQL,这次将b字段也作为条件EXPLAIN SELECT * FROM L5 WHERE a > 1 AND b = 1;
ken_len还是4。

四.为c、d字段添加联合索引,然后进行测试
ALTER TABLE L5 ADD INDEX idx_c_b(c,d);EXPLAIN SELECT * FROM L5 WHERE c = 1 AND d = 'A';

c字段是int类型4个字节,d字段char(10)代表的是10个字符30个字节。因为数据库的字符集是utf8,一个字符3个字节。d字段是char(10)代表的是10个字符相当30个字节。多出的一个字节用来表示是联合索引。
下面这个例子虽然使用了联合索引,但没充分利用索引,还有优化空间。因为可以根据ken_len的长度推测出该联合索引只使用一部分。
EXPLAIN SELECT * FROM L5 WHERE c = 1;
(7)ref字段说明
表示的是显示索引的哪一列被使用了,如果可能的话,最好是一个常数。表示的是哪些列或常量被用于查找索引列上的值。
如下的"L1.id=1"中,由于1是常量,所以ref = const,此时的ref = const表示着查询过程中使用到了常量。
EXPLAIN SELECT * FROM L1 WHERE L1.id = 1;
(8)rows字段说明
表示MySQL为了找到所需的记录,一共访问了多少行(预估的)。L3中的title没有添加索引,所以L3中有3条记录,就需要访问3条记录。
EXPLAIN SELECT * FROM L3,L4 WHERE L3.id = L4.id AND L3.title LIKE 'test007';
需要注意的是rows只是一个估算值,并不准确。所以rows行数过大的问题并不值得过多考虑,主要分析的还是索引是否使用正确了。
(9)filtered字段说明
它指返回结果的行占需要读到的行(rows列的值)的百分比。
(10)extra字段说明
Extra是EXPLAIN输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息。
一.准备数据
CREATE TABLE users (uid INT PRIMARY KEY AUTO_INCREMENT,uname VARCHAR(20),age INT(11));INSERT INTO users VALUES(NULL, 'lisa', 10);INSERT INTO users VALUES(NULL, 'lisa', 10);INSERT INTO users VALUES(NULL, 'rose', 11);INSERT INTO users VALUES(NULL, 'jack', 12);INSERT INTO users VALUES(NULL, 'sam', 13);
二.Using filesort(需要进行文件排序)
执行结果Extra为Using filesort,说明得到所需结果集,需要对所有记录进行文件排序。表示执行的SQL语句性能极差,需要进行优化。
下面就是在一个没有建立索引的列上进行order by,此时会触发filesort。优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
EXPLAIN SELECT * FROM users ORDER BY age;
三.Using temporary
表示使用了临时表来存储结果集,常见于排序和分组查询。
EXPLAIN SELECT COUNT(*),uname FROM users GROUP BY uname;
四.Using where
表示使用了全表扫描或者在查找时使用索引的情况下,还有查询条件不在索引字段中需要回表。
注意一:返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,这类SQL往往需要进行优化。
注意二:使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断。例如下面查询的age未设置索引,所以返回的type为ALL,仍有优化空间,可建立索引优化查询。
EXPLAIN SELECT * FROM users WHERE age = 10;
五.Using index
表示直接访问索引就能获取所需数据(覆盖索引),不需要回表。
-- 为uname创建索引ALTER TABLE users ADD INDEX idx_uname(uname);EXPLAIN SELECT uid,uname FROM users WHERE uname='lisa';

六.Using join buffer
表示使用了连接缓存,还会显示join连接查询时使用的算法。
EXPLAIN SELECT * FROM users u1 LEFT JOIN(SELECT * FROM users WHERE age = 1) u2 ON u1.age = u2.age;

Using join buffer(Block Nested Loop)说明,需要进行嵌套循环计算。这里每个表都有五条记录,内外表查询的type都为ALL。两个表通过字段age进行关联,且age字段未建立索引。
七.Using index condition
表示的是使用了索引,但是只使用了索引的一部分。一般发生在使用联合索引时,需要回表查询。
EXPLAIN SELECT * FROM L5 WHERE c > 10 AND d = '';
八.Extra主要指标的含义总结
using index:查找时使用了覆盖索引的时候就会出现,不需要回表。
using where:查找时使用索引的情况下需要回表或全表扫描。
using index condition:查找时使用了索引但只用一部分索引需要回表。
Using filesort:在一个没有建立索引的列上order by,发生文件排序。
Using temporary:使用了临时表存储结果集,常见于排序和分组查询。
当遍历二级索引不需要回表或者主键排序全表扫描时,type就为index。
查找非唯一性索引,返回匹配的多条数据,type就为ref。
查找唯一性索引,返回匹配的数据最多一条,type就为eq_ref。
查找索引中给定范围的行,type就为range。
3.索引优化数据准备
(1)创建数据库、表,插入数据
create database idx_optimize character set 'utf8';CREATE TABLE users(id INT PRIMARY KEY AUTO_INCREMENT,user_name VARCHAR(20) NOT NULL COMMENT '姓名',user_age INT NOT NULL DEFAULT 0 COMMENT '年龄',user_level VARCHAR(20) NOT NULL COMMENT '用户等级',reg_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间');INSERT INTO users(user_name,user_age,user_level,reg_time)VALUES('tom',17,'A',NOW()),('jack',18,'B',NOW()),('lucy',18,'C',NOW());
(2)创建联合索引
ALTER TABLE users ADD INDEX idx_nal (user_name,user_age,user_level) USING BTREE;4.索引优化原则详解
(1)最左侧列匹配和最左前缀匹配法则
(2)不要在索引列上做任何计算
(3)范围之后全失效
(4)避免使用is null、is not null、!= 、or
(5)like以%开头会使索引失效
(6)索引优化原则总结
(1)最左侧列匹配和最左前缀匹配法则
如果创建的是联合索引,就要遵循该法则。where后面的条件需从索引的最左侧列开始,且不能跳过索引中的列。如果where只匹配一个列,那么该列在索引最左侧,且只匹配前缀字段。
一.最左侧列匹配和最左前缀匹配的场景
场景1:按照索引字段顺序使用,三个字段都使用了索引,没有问题。
EXPLAIN SELECT * FROM usersWHERE user_name = 'tom' AND user_age = 17 AND user_level = 'A';

场景2:直接跳过user_name使用索引字段,索引无效,未使用到索引。
EXPLAIN SELECT * FROM users WHERE user_age = 17 AND user_level = 'A';
场景3: 不按照创建联合索引的顺序,使用索引。
EXPLAIN SELECT * FROM users WHERE user_age = 17 AND user_name = 'tom' AND user_level = 'A';
where后面查询条件顺序是user_age、user_level、user_name,这与创建的索引顺序user_name、user_age、user_level不一致。为什么还是使用了索引,原因是MySQL底层优化器对其进行了优化。
场景4:只要包含最左侧字段,索引就可以生效
但从key_len可知只是用到索引的一部分。
EXPLAIN SELECT * FROM users WHERE user_name = 'tom';
二.最左侧列匹配和最左前缀匹配的原理
InnoDB创建联合索引的规则是:
首先会对联合索引最左边的字段进行排序,例子中是user_name。在第一个字段的基础之上再对第二个字段进行排序,例子中是user_age。所以最佳左前缀原则其实是和B+树的结构有关系,最左字段肯定是有序的,第二个字段则是无序的。
联合索引的排序方式是:
先按第一个字段进行排序,如果第一个字段相等再根据第二个字段排序。所以如果直接使用第二个字段user_age通常是使用不到索引的。
(2)不要在索引列上做任何计算
不要在索引列上做任何操作,否则会导致索引失效,从而转向全表扫描。比如计算、使用函数、自动或手动进行类型转换(字符串不加双引号)。
一.插入数据
INSERT INTO users(user_name,user_age,user_level,reg_time) VALUES('11223344',22,'D',NOW());场景1:使用系统函数left()函数,对user_name进行操作
EXPLAIN SELECT * FROM users WHERE LEFT(user_name, 6) = '112233';
场景2:字符串不加单引号(隐式类型转换)
对于varchar类型的字段,如果查询时不加单引号就会进行隐式转换,导致索引失效转向全表扫描。
EXPLAIN SELECT * FROM users WHERE user_name = 11223344;
(3)范围之后全失效
where条件中如果有范围条件,并且范围条件之后还有其他过滤条件,那么范围条件之后的列就都将会索引失效。
场景1:条件单独使用user_name时,type=ref、key_len=62。
-- 条件只有一个 user_nameEXPLAIN SELECT * FROM users WHERE user_name = 'tom';

场景2:条件增加一个user_age(使用常量等值),type= ref、key_len = 66。
EXPLAIN SELECT * FROM users WHERE user_name = 'tom' AND user_age = 17;
场景3:使用全值匹配,type = ref、key_len = 128,索引都利用上了。
EXPLAIN SELECT * FROM users WHERE user_name = 'tom' AND user_age = 17 AND user_level = 'A';
场景4:使用范围条件时,avg > 17、type = range、key_len = 66。与场景3比较,可发现user_level索引没用上。
EXPLAIN SELECT * FROM users WHERE user_name = 'tom' AND user_age > 17 AND user_level = 'A';
(4)避免使用is null、is not null、!= 、or
一.使用is null会使索引失效
EXPLAIN SELECT * FROM users WHERE user_name IS NULL;
Impossible Where:表示where条件不成立,不能返回任何行。
二.使用is not null会使索引失效
EXPLAIN SELECT * FROM users WHERE user_name IS NOT NULL;
三.使用!=和or会使索引失效
EXPLAIN SELECT * FROM users WHERE user_name != 'tom';EXPLAIN SELECT * FROM users WHERE user_name = 'tom' or user_name = 'jack';

(5)like以%开头会使索引失效
一.like查询中%出现在左边则索引失效,%出现在右边索引未失效
场景1:两边都有%或者%在左边,索引都会失效
EXPLAIN SELECT * FROM users WHERE user_name LIKE '%tom%';EXPLAIN SELECT * FROM users WHERE user_name LIKE '%tom';

场景2:%在右边,索引生效
EXPLAIN SELECT * FROM users WHERE user_name LIKE 'tom%';
二.解决%出现在左边索引失效的方法——使用覆盖索引
EXPLAIN SELECT user_name FROM users WHERE user_name LIKE '%jack%';EXPLAIN SELECT user_name,user_age,user_level FROM users WHERE user_name LIKE '%jack%';

对比场景1可以知道:通过使用覆盖索引type = index,并且extra = Using index,从原来的全表扫描变成了全索引扫描,也就是索引的全表扫描。
三.like失效的原理
原理一:%号在右
由于B+树的索引顺序,是按照首字母的大小进行排序,而%号在右时的匹配又会匹配首字母,所以能在B+树上进行有序的查找。也就是查找出首字母符合要求的数据,所以%号在右可以用到索引。
原理二:%号在左是匹配字符串尾部的数据
由于尾部的字母是没有顺序的,所以不能按索引顺序查询,用不到索引。
原理三:两个%%号
这个是查询任意位置的字母满足条件即可。只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的。
(6)索引优化原则总结
一.最左侧列匹配和最左前缀匹配
二.索引列上不计算不转换
三.范围之后全失效
四.最好使用覆盖索引
五.!=、is null、is not null、or会索引失效
六.like百分号加右边,加左边导致索引失效的解决方法是使用覆盖索引
5.慢查询设置与测试
(1)慢查询介绍
(2)慢查询参数
(3)慢查询配置方式
(4)慢查询测试
(5)慢日志内容
(1)慢查询介绍
MySQL的慢查询全名是慢查询日志,是MySQL提供的一种日志记录。慢查询日志会记录在MySQL中响应时间超过阈值的语句。MySQL数据库默认不启动慢查询日志,需要手动来设置这个参数。
如果不是调优需要的话,一般不建议启动该参数。因为开启慢查询日志会或多或少带来一定的性能影响,慢查询日志支持将日志记录写入文件和数据库表。
(2)慢查询参数
执行下面的语句
mysql> show variables like '%slow_query_log%';+---------------------+------------------------------+| Variable_name | Value |+---------------------+------------------------------+| slow_query_log | ON || slow_query_log_file | /var/lib/mysql/test-slow.log |+---------------------+------------------------------+mysql> show variables like '%long_query%';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+
MySQL慢查询的相关参数解释:
一.slow_query_log:是否开启慢查询日志。
二.slow-query-log-file:慢查询日志存储路径。
三.long_query_time:慢查询阈值,查询时间多于设定阈值则记录日志。
(3)慢查询配置方式
一.默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的
mysql> show variables like '%slow_query_log%';+---------------------+------------------------------+| Variable_name | Value |+---------------------+------------------------------+| slow_query_log | ON || slow_query_log_file | /var/lib/mysql/test-slow.log |+---------------------+------------------------------+
二.可以通过设置slow_query_log的值来开启
mysql> set global slow_query_log=1;三.set global slow_query_log=1开启慢查询日志当前生效重启失效
如果要永久生效,就必须修改配置文件my.cnf,其它系统变量也是如此。
-- 编辑配置vim /etc/my.cnf-- 添加如下内容slow_query_log =1slow_query_log_file=/var/lib/mysql/ruyuan-slow.log-- 重启MySQLservice mysqld restartmysql> show variables like '%slow_query%';+---------------------+--------------------------------+| Variable_name | Value |+---------------------+--------------------------------+| slow_query_log | ON || slow_query_log_file | /var/lib/mysql/ruyuan-slow.log |+---------------------+--------------------------------+
四. 开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里
这个由参数long_query_time控制,默认long_query_time的值为10秒。
mysql> show variables like 'long_query_time';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+mysql> set global long_query_time=1;Query OK, 0 rows affected (0.00 sec)mysql> show variables like 'long_query_time';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+
五.修改变量long_query_time,但查询值还是10
执行命令set global long_query_time=1后,需要重新连接或者打开新开会话才能看到修改值。
mysql> show variables like 'long_query_time';+-----------------+----------+| Variable_name | Value |+-----------------+----------+| long_query_time | 1.000000 |+-----------------+----------+
六.log_output参数是指定日志的存储方式
log_output=FILE表示将日志存入文件,默认值是FILE。log_output=TABLE表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。
MySQL数据库可以同时支持两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。
日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源。因此如果启用慢查询日志+获得更高系统性能,则建议优先记录到文件。
mysql> SHOW VARIABLES LIKE '%log_output%';+---------------+-------+| Variable_name | Value |+---------------+-------+| log_output | FILE |+---------------+-------+
七.开启系统变量让未使用索引的查询也被记录到慢查询日志中
这个系统变量就是log-queries-not-using-indexes,所以在进行调优时,可以开启这个选项。
mysql> show variables like 'log_queries_not_using_indexes';+-------------------------------+-------+| Variable_name | Value |+-------------------------------+-------+| log_queries_not_using_indexes | OFF |+-------------------------------+-------+mysql> set global log_queries_not_using_indexes=1;Query OK, 0 rows affected (0.00 sec)mysql> show variables like 'log_queries_not_using_indexes';+-------------------------------+-------+| Variable_name | Value |+-------------------------------+-------+| log_queries_not_using_indexes | ON |+-------------------------------+-------+
(4)慢查询测试
一.执行test_index.sql脚本,监控慢查询日志内容
[root@localhost mysql]# tail -f /var/lib/mysql/test-slow.log
/usr/sbin/mysqld, Version: 5.7.30-log (MySQL Community Server (GPL)). started with:
Tcp port: 0 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument二. 执行下面的SQL,执行超时(超过1秒)我们去查看慢查询日志
SELECT * FROM test_index WHEREhobby = '20009951' OR hobby = '10009931' OR hobby = '30009931'OR dname = 'name4000' OR dname = 'name6600' ;
(5)慢日志内容
我们得到慢查询日志后,最重要的一步就是去分析这个日志。先来看慢日志里到底记录了哪些内容,如下是慢日志里其中一条记录,可以看到有时间戳、用户、查询时长及具体的SQL等信息。
Time Id Command Argument
# Time: 2022-02-23 T03:55:15. 336037Z
# User@Host: root[root] @ localhost [] Id: 6
# Query_time: 2.375219 Lock_time: 0.000137 Rows_sent: 3 Rows_examined: 5000000
use db4;
SET timestamp=1645588515;
SELECT * FROM test_index WHERE hobby = '20009961' OR hobby = '10009941' OR hobby = '30009961' OR dname = 'name4001' OR dname = 'name6601';Time:执行时间;
Users:用户信息;
Query_time:查询时长;
Lock_time:等待锁时长;
Rows_sent:结果行统计数量;
Rows_examined:扫描的行数;
6.慢查询SQL优化思路
(1)SQL性能下降的原因
(2)慢查询优化思路
(1)SQL性能下降的原因
导致SQL执行性能下降的原因可体现在以下两方面:
一.等待时间长
锁表导致查询一直处于等待状态。
二.执行时间长
查询语句没优化、索引失效、关联查询太多join、机器及参数没调优。
(2)慢查询优化思路
一.优先选择优化高并发执行的SQL
因为高并发的SQL出现问题带来后果更严重,比如下面两种情况:SQL1每小时执行10000次,每次20个IO,优化后每次18个IO,每小时节省2万次IO;SQL2每小时10次,每次20000个IO,每次优化减少2000个IO,每小时节省2万次IO。此时SQL2更难优化,SQL1更好优化。但是第一种属于高并发SQL,更急需优化,因为成本更低。
二.定位优化对象的性能瓶颈
在去优化SQL时,选择优化分方向有三个:
方向1:IO,数据访问消耗了太多时间,查看是否正确使用索引。
方向2:CPU,数据运算花费了太多时间,数据的运算分组、排序是不是有问题。
方向3:网络带宽,加大网络带宽。
三.明确优化目标
根据数据库当前状态、当前SQL的具体功能,来确定最好情况下消耗的资源和最差情况下消耗的资源。因为优化的结果只有一个,即给用户一个好的体验。
四.从explain执行计划入手
只有explain能告诉我们当前SQL的执行状态。
五.永远用小的结果集驱动大的结果集
小的数据集驱动大的数据集,减少内层表读取次数。
//类似于嵌套循环
for (int i = 0; i < 5; i++) {for (int i = 0; i < 1000; i++) {}
}六.尽可能在索引中完成排序
排序操作用得比较多,所以order by后面的字段尽量使用上索引。因为索引本来就是排好序的,所以速度很快。没有索引的话,就需要从表中拿数据,在内存中进行排序。如果内存空间不够还会发生临时文件落盘操作。
七.只获取自己需要的列
不要使用select *,因为select * 很可能不使用索引,而且数据量过大。
八.只使用最有效的过滤条件
where后面的条件并非越多越好,应该用最短的路径访问到数据。
九.尽可能避免复杂的join和子查询
每条SQL的JOIN操作建议不要超过三张表。将复杂的SQL,拆分成多个小的SQL,单个表执行,然后对获取的结果在程序中进行封装。因为如果join占用的资源比较多,会导致其他进程等待时间变长。
十.合理设计并利用索引
也就是合理判断是否需要创建索引,以及合理选择合适索引。
(3)如何判定是否需要创建索引
一.频繁作为查询条件的字段应该创建索引
二.唯一性太差的字段不适合单独创建索引,即使它频繁作为查询条件
唯一性太差的字段主要是指哪些呢?如状态字段、类型字段等。这些字段中的数据可能总共就是那么几个几十个数值重复使用。当一条Query所返回的数据超过了全表的15%时,就不应该再使用索引扫描来完成这个Query了。
三.更新非常频繁的字段不适合创建索引
因为索引中的字段被更新时,不仅要更新表的数据,还要更新索引数据。
四.不会出现在WHERE子句中的字段不该创建索引
(4)如何选择合适索引
一.单键索引,尽量选择针对当前Query过滤性更好的索引。
二.联合索引,当前查询中过滤性最好的字段在索引字段顺序中排列靠前。
相关文章:
MySQL底层概述—7.优化原则及慢查询
大纲 1.Explain概述 2.Explain详解 3.索引优化数据准备 4.索引优化原则详解 5.慢查询设置与测试 6.慢查询SQL优化思路 1.Explain概述 使用Explain关键字可以模拟查询优化器来执行SQL查询语句,从而知道MySQL是如何处理SQL语句的,从而分析出查询语句…...

R““有什么作用在C++中,举例说明
在C中,R""(双引号前加R)表示一个原始字符串字面量(Raw String Literal),其主要作用是让字符串中的反斜杠\和其他特殊字符不被当作转义字符处理,而是保留其原始字面意义。这在处理包含…...

linux中top 命令返回数据解释
当您在 Linux 终端中运行 top 命令时,它会显示一个动态更新的系统状态视图,其中包括许多有关系统性能的数据。下面是对 top 命令返回数据的详细解释: 标题栏 top - 22:46:12 up 2 days, 3:14, 1 user, load average: 0.05, 0.07, 0.09 22:46:12:当前时间。up 2 days, 3:14…...

深入理解二叉树及其变体:平衡二叉树、红黑树、B-树和B+树
一、二叉树简介 二叉树是一种非常常见的数据结构,它具有以下特点: 每个节点最多有两个子节点,分别称为左子节点和右子节点。每个节点的左子树和右子树都是二叉树。 二叉树的常见操作包括:创建、插入、删除、查找、遍历等。下面…...
)
C++ 编程技巧之StrongType(1)
最近看到一个NamedType的开源库,被里面的Strong Type这个概念和里面的模版实现给秀了一脸,特此总结学习一下 GitHub - joboccara/NamedType: Implementation of strong types in C C本身是一种强类型语言,类型包括int、double等这些build i…...

芯片测试-smith圆图
smith圆图 💢smith圆图的故事💢💢smith圆图中的各部分来历💢💢公式推导💢💢等电阻圆特点💢💢等电抗圆💢💢等电抗圆特点💢 Ὂ…...

HTML技术深度解析:构建现代网页的基石
引言 HTML(HyperText Markup Language,超文本标记语言)是构建网页和网上应用的标准标记语言。随着互联网技术的飞速发展,HTML已经成为前端开发中不可或缺的核心技术之一。本文将深入探讨HTML的基本概念、核心元素、最新发展以及在…...

Leecode刷题C语言之判断是否可以赢得数字游戏
执行结果:通过 执行用时和内存消耗如下: bool canAliceWin(int* nums, int numsSize) {int single_digit_sum 0;int double_digit_sum 0;for (int i 0; i < numsSize; i) {if (nums[i] < 10) {single_digit_sum nums[i];} else {double_digit_sum nums[…...

Ubuntu 关机命令
在 Ubuntu 系统中,有几种方法可以关机。以下是常用的关机命令及其说明: 1. 使用 shutdown 命令 shutdown 命令是最常用和最灵活的关机方式。它可以设置定时关机,并且可以发送警告消息给所有登录用户。 立即关机 sudo shutdown now定时关机…...

数据采集中,除了IP池的IP被封,还有哪些常见问题?
在数据采集的过程中,代理IP池的使用无疑为我们打开了一扇通往信息宝库的大门。然而,除了IP被封禁这一常见问题外,还有许多其他问题可能影响数据采集的效果。本文将探讨在数据采集中,除了IP被封之外,还可能遇到的一些常…...

【Anaconda】 创建环境报错:CondaHTTPError: HTTP 000 CONNECTION FAILED for url
问题描述 使用 Anaconda 创建环境时报错: CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/free/noarch/repodata.json.bz2> Elapsed: -An HTTP error occurred when trying to retrieve this URL. HTTP errors are o…...

社交电商破局之“2+1 链动模式 O2O 商城小程序源码”赋能流量困境突围
摘要:本文聚焦于当下商家在流量困境中挣扎的现状,剖析传统电商高流量成本、平台流量获取难等痛点,阐述私域流量池兴起的缘由与价值。重点探究“21 链动模式 O2O 商城小程序源码”如何融入社交电商架构,通过创新机制与线上线下融合…...

【ArcGIS Pro微课1000例】0062:ArcGIS Pro3.3.1中文版安装教程(附安装包下载)
本文讲述ArcGIS Pro3.3.1中文版安装教程(附安装包下载)。 文章目录 一、ArcGIS Pro3.3.1中文版下载二、ArcGIS Pro3.3.1中文版安装一、ArcGIS Pro3.3.1中文版下载 【订阅专栏】,获取完整安装包及专栏配套实验数据。下载后解压,如下图所示: 二、ArcGIS Pro3.3.1中文版安装…...

Linux - web服务器
四、web服务器 1、基础知识 URL:Uniform Resource Locator,统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。 网址格式:<协议>://<主机或主机名&g…...

设计模式-适配器模式-注册器模式
设计模式-适配器模式-注册器模式 适配器模式 如果开发一个搜索中台,需要适配或接入不同的数据源,可能提供的方法参数和平台调用的方法参数不一致,可以使用适配器模式 适配器模式通过封装对象将复杂的转换过程隐藏于幕后。 被封装的对象甚至…...

减速机润滑油更换的最佳周期是多久?
减速机是工业设备中的重要组成部分,润滑油的使用对于其正常运转和寿命具有至关重要的作用。那么,减速机多久更换一次润滑油呢?实际上,减速机润滑油的更换周期受多种因素影响,以下是一些具体的更换周期建议:…...

程序执行堆栈执行模拟
所有的文件都是在硬盘(磁盘)上,调用时先调用javac指令的jdk编译成.class然后被java指令的jre送到内存中,java在内存中有自己的一片区域叫JVM,编译进来的文件首先进入方法区。 staitc的属性就是在进入内存的时候开辟了一…...

《Python基础》之数据加密模块hashlib的用法
目录 一、简介 二、用法 步骤一、导入hashlib库 步骤二、创建哈希对象 步骤三、往哈希对象中传值 1、可以在创建对象的时候传值 2、使用updata传值 步骤四、获取经过哈希对象加密后的值 三、注意事项 1、编码问题 2、安全性 3、多次传值 四、总结 一、简介 hashli…...
-Ubuntu通用)
安装Fcitx5输入框架和输入法自动部署脚本(来自Mark24)-Ubuntu通用
在Ubuntu22.04上安装rime中文输入法的基本教程 上述文章接近废弃。 使用新逻辑配置基本的Fcitx5的输入法。 安装 第一步,下载相关组件 sudo nala install vim sudo nala install ruby sudo nala install fcitx5-rime第二步,设置语言为Fcitx5 而非 默认…...

【IMF靶场渗透】
文章目录 一、基础信息 二、信息收集 三、flag1 四、flag2 五、flag3 六、flag4 七、flag5 八、flag6 一、基础信息 Kali IP:192.168.20.146 靶机IP:192.168.20.147 二、信息收集 Nmap -sP 192.168.20.0/24 Arp-scan -l nmap -sS -sV -p- -…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...
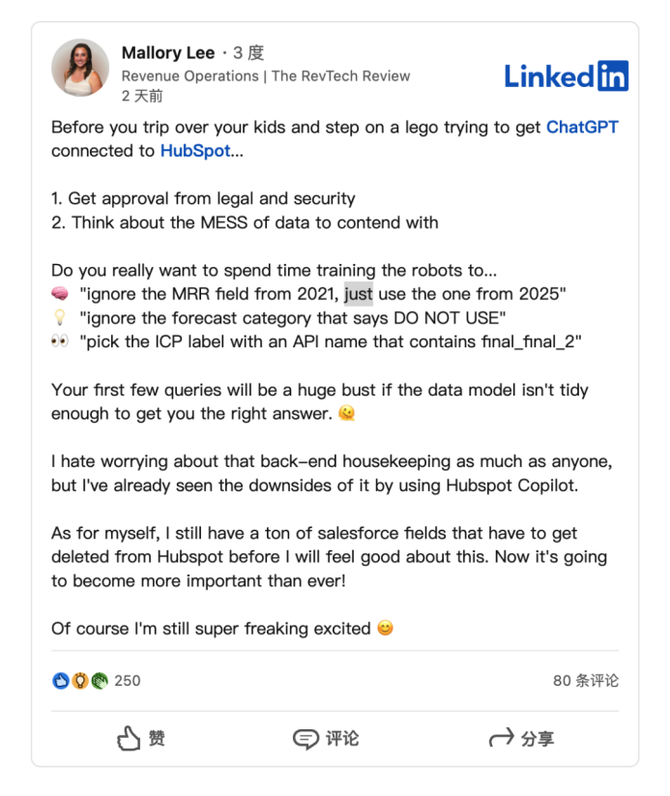
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...