【C语言】二叉树(BinaryTree)的创建、3种递归遍历、3种非递归遍历、结点度的实现
代码主要实现了以下功能:
- 二叉树相关数据结构定义
定义了二叉树节点结构体 BiTNode,包含节点数据值(字符类型)以及指向左右子树的指针。
定义了顺序栈结构体 SqStack,用于存储二叉树节点指针,实现非递归遍历。
- 二叉树的创建与遍历
创建二叉树:通过 CreateBiTree 函数,根据输入的先序遍历字符序列(# 表示空节点),以递归方式创建二叉树。
递归遍历:实现了二叉树的递归先序、中序、后序遍历函数,分别按照根 - 左 - 右、左 - 根 - 右、左 - 右 - 根的顺序输出节点字符序列。
非递归遍历:借助栈实现了二叉树的非递归先序、中序、后序遍历函数,在遍历过程中除输出节点字符外,还输出节点进栈、出栈过程及栈顶节点字符。
- 二叉树相关应用实例
统计节点度数:通过 TNodes 函数统计二叉树中度为 0、1、2 的节点个数。
计算树的高度:利用 High 函数计算二叉树的高度。
创建二叉排序树:通过 CreateBST 函数根据给定字符序列生成二叉排序树,并对创建的二叉树进行中序遍历及高度计算。
- 主函数功能整合
在 main 函数中,依次调用上述函数完成以下操作:
创建一棵二叉树并输出其递归和非递归的三种遍历结果及栈变化情况。
统计该二叉树不同度数的节点个数。
创建两棵二叉排序树并输出它们的中序遍历结果及高度。
以
为例
实现效果


完整代码
如下,注释详细
//
// Created by 13561 on 2024/11/28.
//#include<stdio.h>
#include<stdlib.h>
#include<string.h>#define ERROR 0
#define TRUE 1
#define OK 1
#define MAXSIZE 100typedef int Status; //声明函数类型名
typedef char TElemType; //声明结点元素值的类型//定义二叉树结点类型
typedef struct BiTNode {TElemType data;struct BiTNode *lchild, *rchild; //指向左右孩子结点的指针} BiTNode, *BiTree;// 栈
typedef struct {BiTree data[MAXSIZE];int top;
}SqStack;// 根据先序遍历的字符序列,创建一棵按二叉链表结构存储的二叉树,指针变量T指向二叉树的根节点
void CreateBiTree(BiTree *T) {TElemType ch;scanf(" %c",&ch);printf("Read character: %c\n", ch);// # 代表空结点if(ch == '#') {printf("#设置为空结点\n");*T = NULL;} else {*T = (BiTree)malloc(sizeof(BiTNode));if(!*T) {exit(0);}(*T)->data = ch;// 创建左、右子树CreateBiTree(&(*T)->lchild);CreateBiTree(&(*T)->rchild);}}// 递归先序遍历二叉树 T ,输出访问的结点字符序列
Status PreOrderTraverse(BiTree T) {// 根 - 左 - 右if(T) {printf("%c ",T->data);PreOrderTraverse(T->lchild);PreOrderTraverse(T->rchild);}return OK;
}// 递归中序遍历二叉树 T ,输出访问的结点字符序列
Status InOrderTraverse(BiTree T) {// 左 - 根 - 右if(T) {InOrderTraverse(T->lchild);printf("%c ",T->data);InOrderTraverse(T->rchild);}return OK;
}// 递归后序遍历二叉树 T ,输出访问的结点字符序列
Status PostOrderTraverse(BiTree T) {// 左 - 右 - 根if(T) {PostOrderTraverse(T->lchild);PostOrderTraverse(T->rchild);printf("%c ",T->data);}return OK;
}// 栈基本操作
void InitStack(SqStack *S) {S->top = -1;
}// 判断是否空
int StackEmpty(SqStack S) {return S.top == -1;
}// 进栈
void Push(SqStack *S, BiTree e) {if (S->top == MAXSIZE - 1) {printf("栈满\n");return;}S->top++;S->data[S->top] = e;
}// 出栈
BiTree Pop(SqStack *S) {if (StackEmpty(*S)) {printf("栈空\n");return NULL;}BiTree e = S->data[S->top];S->top--;return e;
}BiTree GetTop(SqStack S) {if (StackEmpty(S)) {printf("栈空\n");return NULL;}return S.data[S.top];
}// 非递归先序遍历二叉树 T,依靠栈实现
// 要求在遍历过程中输出访问的结点字符的同时,输出结点进栈/出栈的过程 和 栈中指针所指的结点字符
Status NRPreOrderTraverse(BiTree T) {SqStack S;InitStack(&S);if(T!=NULL) {BiTree p ;S.data[++(S.top)] = T;while(S.top != -1) {// 根节点出栈再找它的子树p = S.data[(S.top)--];printf("出栈 %c \n",p->data);// 右子树压在最底下if(p->rchild != NULL) {S.data[++(S.top)] = p->rchild;}if(p->lchild != NULL) {S.data[++(S.top)] = p->lchild;}}}return OK;
}// 非递归中序遍历二叉树 T 左根右
Status NRInOrderTraverse(BiTree T) {SqStack S;InitStack(&S);BiTree p = T;while (p ||!StackEmpty(S)) {while (p) {//printf("结点 %c 准备进栈 \n", p->data);Push(&S, p);//printf("当前栈顶: %c \n", GetTop(S)->data);//printf("正在访问结点 %c \n", p->data);// 访问左边p = p->lchild;}// 栈不空就出栈if (!StackEmpty(S)) {p = Pop(&S);printf("结点 %c 出栈 \n", p->data);// 访问右边p = p->rchild;}}return OK;
}// 非递归后序遍历二叉树 T 左右根
Status NRPostOrderTraverse(BiTree T) {SqStack S;InitStack(&S);BiTree p = T;BiTree lastVisited = NULL;while (p ||!StackEmpty(S)) {if(p) {S.data[++(S.top)] = p;// 访问左结点p = p->lchild;}else {p = S.data[S.top];// 不急着出栈左结点 看看右节点是否存在以及是否被访问过 压入栈中if (p->rchild != NULL && p->rchild != lastVisited) {p = p->rchild;S.data[++(S.top)] = p;// 查看右结点的左结点p = p ->lchild;}else {p = S.data[(S.top)--];printf("出栈 %c \n",p->data);lastVisited = p;// 在一个结点出栈后,紧接着下一个结点出栈,所以p直接置空p = NULL;}}}return OK;
}// 应用实例1:返回二叉树T度分别为 0 , 1 , 2的结点数
void TNodes(BiTree T, int d, int *count) {if (T) {int degree = (T->lchild!= NULL) + (T->rchild!= NULL);if (degree == d) {(*count)++;}TNodes(T->lchild, d, count);TNodes(T->rchild, d, count);}
}// 应用实例2:求二叉树 T 的高度
int High(BiTree T) {if (T == NULL) return 0;else {int leftHeight = High(T->lchild);int rightHeight = High(T->rchild);return (leftHeight > rightHeight)? (leftHeight + 1) : (rightHeight + 1);}
}// 应用实例3:根据给定的字符序列生成二叉排序树
void CreateBST(BiTree *T, const char *chars) {*T = NULL;int len = strlen(chars);for (int i = 0; i < len; i++) {BiTree p = *T;BiTree q = NULL;while (p!= NULL) {q = p;if (chars[i] < p->data) {p = p->lchild;} else {p = p->rchild;}}BiTree newNode = (BiTree)malloc(sizeof(BiTNode));newNode->data = chars[i];newNode->lchild = newNode->rchild = NULL;if (q == NULL) {*T = newNode;} else if (chars[i] < q->data) {q->lchild = newNode;} else {q->rchild = newNode;}}
}int main() {// (1) 调用CreateBiTree(T)函数生成一棵二叉树TBiTree T;printf("请输入二叉树T的先序遍历序列(#表示空节点):\n");CreateBiTree(&T);printf("先序遍历成功!\n");printf("------------------------------\n");// (2) 分别调用先序遍历、中序遍历和后序遍历的递归函数输出相应的遍历结果printf("递归先序遍历结果:\n");PreOrderTraverse(T);printf("\n");printf("递归中序遍历结果:\n");InOrderTraverse(T);printf("\n");printf("递归后序遍历结果:\n");PostOrderTraverse(T);printf("\n");printf("------------------------------\n");// (3) 分别调用先序遍历、中序遍历和后序遍历的非递归函数输出相应的遍历结果和栈元素的变化过程printf("非递归先序遍历结果及栈变化:\n");NRPreOrderTraverse(T);printf("------------------------------\n");printf("非递归中序遍历结果及栈变化:\n");NRInOrderTraverse(T);printf("------------------------------\n");printf("非递归后序遍历结果及栈变化:\n");NRPostOrderTraverse(T);printf("------------------------------\n");// (4) 调用TNodes(T)函数,输出二叉树T度分别为0、1、2的结点数int count0 = 0, count1 = 0, count2 = 0;TNodes(T, 0, &count0);TNodes(T, 1, &count1);TNodes(T, 2, &count2);printf("度为0的节点个数:%d\n", count0);printf("度为1的节点个数:%d\n", count1);printf("度为2的节点个数:%d\n", count2);printf("------------------------------\n");// (5) 调用CreateBST(T1,"DBFCAEG"),CreateBST(T2,"ABCDEFG"),创建两棵二叉树,对它们进行中序遍历,并调用High()函数输出其高度BiTree T1, T2;CreateBST(&T1, "DBFCAEG");CreateBST(&T2, "ABCDEFG");printf("T1中序遍历结果:");InOrderTraverse(T1);printf("\nT1高度:%d\n", High(T1));printf("T2中序遍历结果:");InOrderTraverse(T2);printf("\nT2高度:%d\n", High(T2));return 0;
}
相关文章:
【C语言】二叉树(BinaryTree)的创建、3种递归遍历、3种非递归遍历、结点度的实现
代码主要实现了以下功能: 二叉树相关数据结构定义 定义了二叉树节点结构体 BiTNode,包含节点数据值(字符类型)以及指向左右子树的指针。 定义了顺序栈结构体 SqStack,用于存储二叉树节点指针,实现非递归遍历…...

2024年11月文章一览
2024年11月编程人总共更新了21篇文章: 1.2024年10月文章一览 2.《使用Gin框架构建分布式应用》阅读笔记:p307-p392 3.《使用Gin框架构建分布式应用》阅读笔记:p393-p437 4.《使用Gin框架构建分布式应用》读后感 5.《Django 5 By Example…...

重生之我在异世界学编程之C语言:二维数组篇
大家好,这里是小编的博客频道 小编的博客:就爱学编程 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!! 本文目录 引言正文一 二维数组的创建1. 二维数组的…...

和鲸科技创始人CEO范向伟出席首届工业智算产业发展研讨会,共话 AI 创新与产业化落地
11 月 22 日,首届工业智算产业发展研讨会在中国工业互联网研究院召开。工业和信息化部党组成员、副部长单忠德,国家信息中心大数据发展部副主任魏颖出席会议并致辞。中国工程院院士、北京化工大学教授高金吉,工业和信息化部信息通信发展司二级…...

postgres数据备份与主从配置
备份PostgreSQL数据库 备份格式有几种选择: bak:压缩二进制格式 sql:明文转储 tar: tarball mydb# \q -bash-4.2$ pg pgawk pg_dump pgrep pg_basebackup pg_dumpall pg_restore# 备份所有的 -bash-4.2$ pg_dumpall &…...

【二分查找】力扣 275. H 指数 II
一、题目 二、思路 h 指数是高引用引用次数,而 citations 数组中存储的就是不同论文被引用的次数,并且是按照升序排列的。也就是说 h 指数将整个 citations 数组分成了两部分,左半部分是不够引用 h 次 的论文,右半部分论文的引用…...

使用uni-app进行开发前准备
使用uni-app进行开发,需要遵循一定的步骤和流程。以下是一个详细的指南,帮助你开始使用uni-app进行开发: 一、开发环境搭建 安装Node.js: 首先,从Node.js的官方网站(https://nodejs.org/)下载并…...

AI开发-深度学习框架-PyTorch-torchnlp
1 需求 Welcome to Pytorch-NLP’s documentation! — PyTorch-NLP 0.5.0 documentation 2 接口 3 示例 4 参考资料...
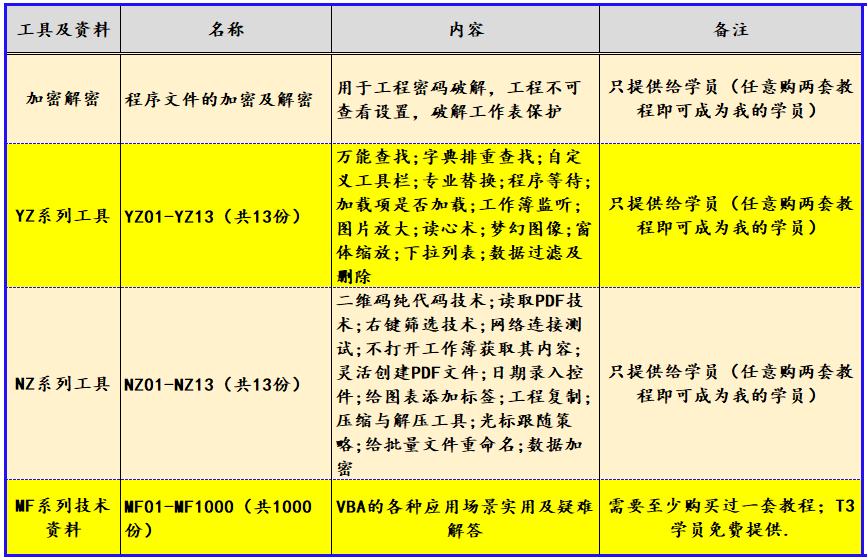
VBA数据库解决方案第十七讲:Recordset对象记录位置的定位方法
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

Ubuntu 操作系统
一、简介 Ubuntu 是一个基于 Linux 的开源操作系统,它由 Canonical Ltd. 公司维护和资助。Ubuntu 以其易用性、强大的社区支持和定期的安全更新而闻名,一个一桌面应用为主的操作系统。 二、用户使用 1、常规用户的登陆方式 在登录时一般使用普通用户&…...

Maven 内置绑定到底怎么回事?
Maven是一个很好的项目管理工具. 一方面有着众多脚手架,另一方面在依赖管理方面 帮助使用者做了很多准备工作. 随着Maven的使用和学习的深入,大家会不仅有一些问题。 比较浅显的一个就是, 日常我们的Maven 下载安装好以后,在IDE 里…...

如何把Qt exe文件发送给其他人使用
如何把Qt exe文件发送给其他人使用 1、先把 Debug改成Release2、重新构建项目3、运行项目4、找到release文件夹5、新建文件夹,存放exe文件6、打开qt控制台串口7、下载各种文件8、压缩,发送压缩包给别人 1、先把 Debug改成Release 2、重新构建项目 3、运行…...

【汇编语言】call 和 ret 指令(三) —— 深度解析汇编语言中的批量数据传递与寄存器冲突
文章目录 前言1. 批量数据的传递1.1 存在的问题1.2 如何解决这个问题1.3 示例演示1.3.1 问题说明1.3.2 程序实现 2. 寄存器冲突问题的引入2.1 问题引入2.2 分析与解决问题2.2.1 字符串定义方式2.2.2 分析子程序功能2.2.3 得到子程序代码 2.3 子程序的应用2.3.1 示例12.3.2 示例…...

定义函数合并字符串—超详细讲解
【问题描述】 编写一个函数void str_bin(char str1[ ], char str2[ ]), str1、str2是两个有序字符串(其中字符按ASCII码从小到大排序),将str2合并到字符串str1中,要求合并后的字符串仍是有序的,允许字符重…...

实现 vue3 正整数输入框组件
1.实现代码 components/InputInteger.vue <!-- 正整数输入框 --> <template><el-input v-model"_value" input"onInput" maxlength"9" clearable /> </template><script lang"ts" setup> import { ref …...

Leetcode - 周赛425
目录 一,3364. 最小正和子数组 二, 3365. 重排子字符串以形成目标字符串 三,3366. 最小数组和 四,3367. 移除边之后的权重最大和 一,3364. 最小正和子数组 本题可以直接暴力枚举,代码如下: …...
)
c++(斗罗大陆2)
我把魂力等级更新到了31级 #include<iostream> #include<conio.h> #include<windows.h> #include<stdlib.h> #include<stdio.h> #include<time.h> #include<string.h> using namespace std; int qs10; int xthl0;//先…...

redis常见数据类型
Redis是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息代理,支持多种数据类型。 一、数据类型介绍 String(字符串) Redis中最基本的数据类型。可以存储任何类型的数据,包括字符串、数字和二进制…...

MySQL - 性能优化
使用 Explain 进行分析 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。 比较重要的字段有: select_type : 查询类型,有简单查询、联合查询、子查询等 key : 使用的索引 rows : 扫描的行数 type :…...

Linux进程概念-详细版(一)
目录 进程概念 描述进程-PCB task_struct-PCB的一种 task_struct内容分类 查看进程 通过系统目录查看 通过ps命令查看 通过系统调用获取进程的PID和PPID 通过系统调用创建进程 fork的认识 使用if进行分流 最后的总结 Linux进程状态 运行状态-R 浅度睡眠状态-S 深度睡…...

RV1108图像处理单元选型指南:什么情况下该用CIF?什么情况必须选ISP?
RV1108图像处理单元选型指南:CIF与ISP的核心差异与实战选型策略 在嵌入式视觉系统设计中,RV1108作为一款集成了丰富图像处理资源的芯片,其CIF(Camera Interface)和ISP(Image Signal Processing)…...

Ostrakon-VL-8B智能零售案例:上传货架图,自动生成缺货报告和补货建议
Ostrakon-VL-8B智能零售案例:上传货架图,自动生成缺货报告和补货建议 1. 零售行业的痛点:人工盘点效率低下 走进任何一家便利店或超市,你都会看到店员拿着纸笔或平板电脑,在货架前逐一核对商品库存。这个过程不仅耗时…...

ESP32-C3-Super-Mini开发板外部供电方案解析:从3.3V到6V的灵活适配
1. ESP32-C3-Super-Mini开发板供电特性全解析 第一次拿到ESP32-C3-Super-Mini开发板时,最让我惊喜的就是它灵活的供电设计。这块小板子虽然体积迷你,但电源系统却相当"聪明"——既支持USB供电,又能接受3.3V到6V的宽电压范围外部供电…...

AI产品体验优化:可用性评估中的用户画像应用
AI产品体验优化:可用性评估中的用户画像应用 关键词:AI产品、体验优化、可用性评估、用户画像、应用 摘要:本文聚焦于AI产品体验优化,深入探讨了在可用性评估中用户画像的应用。通过了解相关背景知识,解释核心概念及它们之间的关系,阐述核心算法原理和操作步骤,结合数学…...

nlp_structbert_sentence-similarity_chinese-large 一键部署实战:从GitHub下载到CSDN星图平台运行
nlp_structbert_sentence-similarity_chinese-large 一键部署实战:从GitHub下载到CSDN星图平台运行 你是不是也遇到过这种情况?手头有个中文文本相似度计算的需求,比如判断两段用户评论是不是在说同一件事,或者给一堆问答对做智能…...

wan2.1-vae企业级审计:生成日志留存+用户行为追踪+内容合规性审查
wan2.1-vae企业级审计:生成日志留存用户行为追踪内容合规性审查 1. 平台概述 wan2.1-vae是基于Qwen-Image-2512模型的AI图像生成平台,专为企业级应用设计。它不仅支持高质量图像生成,还内置了完善的审计功能,满足企业在内容生成…...

Phi-3-vision-128k-instruct入门必看:128K上下文多模态模型快速上手教程
Phi-3-vision-128k-instruct入门必看:128K上下文多模态模型快速上手教程 1. 认识Phi-3-vision-128k-instruct模型 Phi-3-Vision-128K-Instruct是微软推出的轻量级多模态模型,属于Phi-3系列的最新成员。这个模型最大的特点是支持128K的超长上下文窗口&a…...

图神经网络三剑客:GAT、GraphSAGE与GCN的核心差异与实战场景解析
1. 图神经网络三剑客:从入门到实战 第一次接触图神经网络时,我被GCN、GAT和GraphSAGE这三个缩写搞晕了——它们看起来都像在图上做卷积,但实际差异大到能影响整个项目的成败。记得去年做社交网络用户分类时,用错模型导致预测准确率…...

Windows下Vivim环境搭建实战:causal_conv1d与mamba_ssm的避坑指南
1. Windows下Vivim环境搭建全攻略 最近在复现Vivim这个基于Mamba的医疗视频分割模型时,发现很多小伙伴在Windows环境下配置causal_conv1d和mamba_ssm这两个核心库时频频踩坑。作为一个在Windows平台折腾过无数次环境搭建的老司机,今天我就把实战中积累的…...

Lychee-Rerank参数调优实战:针对特定领域数据的微调策略
Lychee-Rerank参数调优实战:针对特定领域数据的微调策略 你是不是也遇到过这种情况?用一个通用的文本排序模型来处理自己行业的数据,比如医疗报告、金融合同或者法律条文,总觉得效果差那么点意思。模型好像能理解,但又…...