简单好用的折线图绘制!
折线图的概念及作用:
折线图(Line Chart)是一种常见的图表类型,用于展示数据的变化趋势或时间序列数据。它通过一系列的数据点(通常表示为坐标系中的点)与这些点之间的线段相连,直观地展示变量随着时间或其他因素变化的情况。折线图适用于比较多个数据集的变化趋势,尤其是在时间序列数据分析中,常用于反映数据的连续性和波动。

1. 折线图的基本概念
折线图是由坐标系中的一系列数据点和这些点之间的直线段组成。每个数据点的横坐标通常代表某一时间点或顺序,而纵坐标则表示对应的数值(如销量、温度、股票价格等)。通过连接这些点,形成折线图,可以清晰地看到数据的波动趋势和变化规律。
- 横坐标(X轴):通常表示自变量,例如时间、日期、阶段等。它是连续的或离散的。
- 纵坐标(Y轴):表示因变量,即需要观察的数据值。
- 数据点:每一个数据点对应一个横坐标和纵坐标的组合,表示某个时刻或某个条件下的观测值。
- 折线:通过连接数据点,形成的线条展示了数据的变化趋势。
2. 折线图的作用
折线图的作用主要体现在以下几个方面:
a. 展示数据变化的趋势
折线图最常见的用途是展示数据随时间或其他因素变化的趋势。通过观察折线的走势,可以直观地了解数据随时间的波动和变化模式。
- 例如,绘制一年中每个月的气温变化折线图,可以清晰地看出气温的升降趋势,揭示季节性变化。
b. 比较多个数据系列
折线图还可以用来比较多个数据系列的变化趋势。当有多个变量或不同类别的时间序列数据时,可以将它们绘制在同一张图表上,通过不同的颜色、线型或符号区分不同的数据系列。
- 例如,比较不同公司在同一时间段内的股票价格变化,或不同地区的气温变化。
c. 揭示数据的波动性和周期性
折线图不仅能展示数据的趋势,还能揭示数据中的周期性波动(如季节变化)、突发性变化、趋势反转等重要特征。
- 例如,通过绘制股票市场的折线图,可以看到市场的波动性,识别牛市和熊市的周期性变化。
d. 识别异常值或趋势变化点
折线图能够帮助观察数据中的异常值或突变点。例如,突如其来的数据激增或暴跌在折线图中会形成尖锐的波动,容易被观察者识别出来。
- 例如,销售额的急剧下降可能是某个重要事件导致的,需要进一步分析。
3. 折线图的类型
根据数据的特点和需求,折线图可以有不同的变种,常见的有:
a. 基本折线图(Simple Line Chart)
最基本的折线图,展示一个数据系列随时间的变化趋势。
b. 多重折线图(Multiple Line Chart)
适用于比较多个数据系列。每个系列通过不同的颜色或线型区分,以便在同一图表中显示多个变量的变化趋势。
c. 堆叠折线图(Stacked Line Chart)
在多重折线图的基础上,堆叠折线图显示了不同数据系列之间的叠加关系。每个数据系列的值在前一系列之上堆叠起来,适用于表示部分与整体的关系。
- 例如,展示各个产品在某个月的销售额时,可以通过堆叠折线图看到不同产品的销售额与总销售额之间的关系。
d. 平滑折线图(Smooth Line Chart)
在基本折线图的基础上,通过平滑算法(如样条插值等)使得折线不那么尖锐,适用于数据变化较为平稳、且不要求每个数据点之间的波动都十分显著的情况。
代码:
第一部分:加载所需包
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)
ggplot2:用于数据可视化。dplyr:用于数据操作。tidyr:用于数据整理(例如宽表和长表的转换)。gridExtra:用于排版多个图表。openxlsx:用于读取和写入 Excel 文件。
第二部分:数据加载与清理
mydata <- read.xlsx("gpt.xlsx")
mydata <- subset(mydata, mydata$final != 3)
mydata <- mydata %>%mutate(gpt = factor(gpt, levels = c("gpt3.5", "gpt4")),system = factor(system, levels = c("system2", "system1")),query = factor(query, levels = c("query1", "query2")),final_new = factor(final, labels = c("不参加", "参加")),sort_new = factor(sort, labels = paste0(seq(10, 90, by = 10), "%")))
-
数据加载:
read.xlsx("gpt.xlsx"):读取 Excel 文件gpt.xlsx。
-
数据过滤:
subset(mydata, mydata$final != 3):去除final列中值为 3 的数据。
-
数据清理:
- 使用
mutate对数据进行格式化处理:- 将
gpt、system和query列转为因子变量,设定排序规则。 - 对
final和sort列创建新的因子变量,并赋予更易读的标签。
- 将
- 使用
第三部分:分组并汇总数据
result_wide <- mydata %>%group_by(gpt, system, query, final_new) %>%summarise(Frequency = n(), .groups = 'drop') %>%pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)) %>%mutate(Proportion = 参加 / (不参加 + 参加))
-
分组与汇总:
group_by(gpt, system, query, final_new):按gpt、system、query和final_new进行分组。summarise(Frequency = n(), .groups = 'drop'):计算每组的频数,生成Frequency列。
-
宽表转换:
pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)):- 将
final_new的值("不参加" 和 "参加")作为新列,值来源于Frequency。 - 未匹配的单元格填充为
0。
- 将
-
计算比例:
mutate(Proportion = 参加 / (不参加 + 参加)):计算 "参加" 在总频数中的比例,结果存储在Proportion列中。
第四部分:绘制折线图
plota <- ggplot(result_wide, aes(x = system, y = Proportion, color = gpt, linetype = query, group = interaction(gpt, query))) +geom_line(linewidth = 1.1) +geom_point(size = 2) +labs(title = "比对折线图", x = "system", y = "参加比例") +theme_minimal() +theme(plot.title = element_text(hjust = 0.5),legend.title = element_blank(),legend.position = "bottom") +scale_color_manual(values = c("gpt3.5" = "red", "gpt4" = "green")) +scale_linetype_manual(values = c("query1" = "solid", "query2" = "dashed", "query4" = "dotted"),labels = c("query1" = "query1-单次博弈", "query2" = "query2-多次博弈", "query4" = "query4-聚合结果的多次博弈")) +scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】"))
核心部分解释:
-
ggplot初始化:aes(x = system, y = Proportion, color = gpt, linetype = query, group = interaction(gpt, query)):- x:
system作为 x 轴变量。 - y:
Proportion作为 y 轴变量(参加比例)。 - color:
gpt区分颜色。 - linetype:
query区分线型(例如虚线、实线等)。 - group:按照
gpt和query的组合分组,确保线条连续。
- x:
-
绘制折线和点:
geom_line(linewidth = 1.1):绘制折线,设置线宽为 1.1。geom_point(size = 2):在线上叠加点,设置点大小为 2。
-
添加标题和标签:
labs(title = "比对折线图", x = "system", y = "参加比例"):设置图表标题和轴标签。
-
主题样式:
theme_minimal():应用简约主题。theme(...):plot.title = element_text(hjust = 0.5):标题居中。legend.title = element_blank():去除图例标题。legend.position = "bottom":将图例放在底部。
-
自定义颜色和线型:
scale_color_manual(...):指定颜色:"gpt3.5"为红色,"gpt4"为绿色。
scale_linetype_manual(...):values:指定线型(实线、虚线、点线)。labels:为每种query提供易读的标签描述。
-
自定义 x 轴标签:
scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】")):- 将
system1和system2的标签分别替换为system1【AI】和system2【Human】。
- 将
第五部分:保存图表
ggsave("plota.png", plota, width = 8, height = 6, bg = "white")
- 将绘制的图形
plota保存为 PNG 文件:- 文件名为
plota.png。 - 宽度和高度分别为 8 英寸和 6 英寸。
- 背景色为白色。
- 文件名为
总结:
# ------- 加载所需包 -------
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)# ------- 加载并清理数据 -------
mydata <- read.xlsx("gpt.xlsx")
mydata <- subset(mydata, mydata$final != 3)
mydata <- mydata %>%mutate(gpt = factor(gpt, levels = c("gpt3.5", "gpt4")),system = factor(system, levels = c("system2", "system1")),query = factor(query, levels = c("query1", "query2")),final_new = factor(final, labels = c("不参加", "参加")),sort_new = factor(sort, labels = paste0(seq(10, 90, by = 10), "%")))# ------- 分组并汇总数据 -------
result_wide <- mydata %>%group_by(gpt, system, query, final_new) %>%summarise(Frequency = n(), .groups = 'drop') %>%pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)) %>%mutate(Proportion = 参加 / (不参加 + 参加))# 打印汇总数据
print(result_wide)# ------- 绘制折线图 -------
plota <- ggplot(result_wide, aes(x = system, y = Proportion, color = gpt, linetype = query, group = interaction(gpt, query))) +geom_line(linewidth = 1.1) +geom_point(size = 2) +labs(title = "比对折线图", x = "system", y = "参加比例") +theme_minimal() +theme(plot.title = element_text(hjust = 0.5),legend.title = element_blank(),legend.position = "bottom") +scale_color_manual(values = c("gpt3.5" = "red", "gpt4" = "green")) +scale_linetype_manual(values = c("query1" = "solid", "query2" = "dashed", "query4" = "dotted"),labels = c("query1" = "query1-单次博弈", "query2" = "query2-多次博弈", "query4" = "query4-聚合结果的多次博弈")) +scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】"))# 显示图表
print(plota)# ------- 保存图表 -------
ggsave("plota.png", plota, width = 8, height = 6, bg = "white")
相关文章:
简单好用的折线图绘制!
折线图的概念及作用: 折线图(Line Chart)是一种常见的图表类型,用于展示数据的变化趋势或时间序列数据。它通过一系列的数据点(通常表示为坐标系中的点)与这些点之间的线段相连,直观地展示变量…...

Hadoop批量计算实验
参考: Hadoop(一)之实验一CentOS7配置Hadoop系统:配置CentOS和下载安装包_基于虚拟机cents7搭建hadoop实验目的-CSDN博客 --------------------------------------------------------- 一、安装Vmware 二、创建虚拟机 1.安装centos7 ①打开VMware,点击新建虚拟机。 …...

基于rpcapd与wireshark的远程实时抓包的方法
基于rpcapd与wireshark的远程实时抓包的方法 服务端安装wireshark侧设置 嵌入式设备或服务器上没有图形界面,通常使用tcpdump抓包保存为pcap文件后,导出到本地使用wireshark打开分析,rpcapd可与wireshark配合提供一种远程实时抓包的方案&…...

ubuntu多版本安装gcc
1.ubuntu安装gcc 9.3.1 $ sudo apt update $ sudo apt install gcc-9 g-9 二、配置GCC版本 安装完成后,需要使用update-alternatives命令来配置GCC版本。这个命令允许系统在多个安装的版本之间进行选择 1.添加GCC 9.3.1到update-alternatives管理 $ sudo update-a…...

算法刷题Day1
BM47 寻找第k大 第一天就随便记录吧,万事开头难,我好不容易开的头,就别难为自己,去追求高质量了。嘿嘿嘿 题目 传送门 解题思路一:维护一个大小为k的最小堆。最后返回堆顶元素。 代码: # # 代码中的类名…...

泛化调用 :在没有接口的情况下进行RPC调用
什么是泛化调用? 在RPC调用的过程中,调用端向服务端发起请求,首先要通过动态代理,动态代理可以屏蔽RPC处理流程,使得发起远程调用就像调用本地一样。 RPC调用本质:调用端向服务端发送一条请求消息&#x…...

Java 泛型详细解析
泛型的定义 泛型类的定义 下面定义了一个泛型类 Pair,它有一个泛型参数 T。 public class Pair<T> {private T start;private T end; }实际使用的时候就可以给这个 T 指定任何实际的类型,比如下面所示,就指定了实际类型为 LocalDate…...

题解:CF332B Maximum Absurdity
CF332B CF332B 暴力思路 题目要我们找两个不重叠的区间,并使区间的值最大。那我们可以考虑使用双重循环搭配前缀和暴力求最大值。代码如下。 for(int i1;i<n;i) {ll lsum[ik-1]-sum[i-1],maxx;for(int jik;j<n;j){maxxlsum[jk-1]-sum[j-1];if(maxx>ans.…...

Vue 集成和使用 SQLite 的完整指东
1. 引言 SQLite 是一种轻量级的关系型数据库管理系统,以其简单易用、无需服务器等特点广泛应用于嵌入式系统、移动应用和小型应用程序中。在 Web 开发中,尤其是前端应用开发中,SQLite 可以作为客户端本地存储的一种选择,为用户提…...

【JVM什么时候触发YoungGC和FullGC】
YoungGC 年轻代Eden区满,就会触发YoungGC FullGC 老年代空间不足 经过多次GC后的大年龄对象会被放进老年代,或创建的大对象会直接在老年代分配,此时若老年代空间不足,就会触发FullGC。空间分配担保失败 触发YoungGC的时候会进行…...

ubuntu配置网络
1,设置桥接模式 1-1: 确定。 1-2: 编辑--->虚拟网络编辑器 刚安装ubuntu的时候,可能没有任何VMnet. 更改设置的目的: 添加VMnet0,并且设置VMnet为桥接模式--自动桥接。 如果没有VMnet0,选择添加网络…...

第十一课 Unity编辑器创建的资源优化_预制体和材质篇(Prefabs和Materials)详解
预制体(Prefabs) Unity中的预制体是用来存储游戏对象、子对象及其所需组件的可重用资源,一般来说预制体资源可充当资源模版,在此模版基础上可以在场景中创建新的预制体实例。 使用预制体的好处 由于预制体系统可以自动保持所有实例副本同步,…...
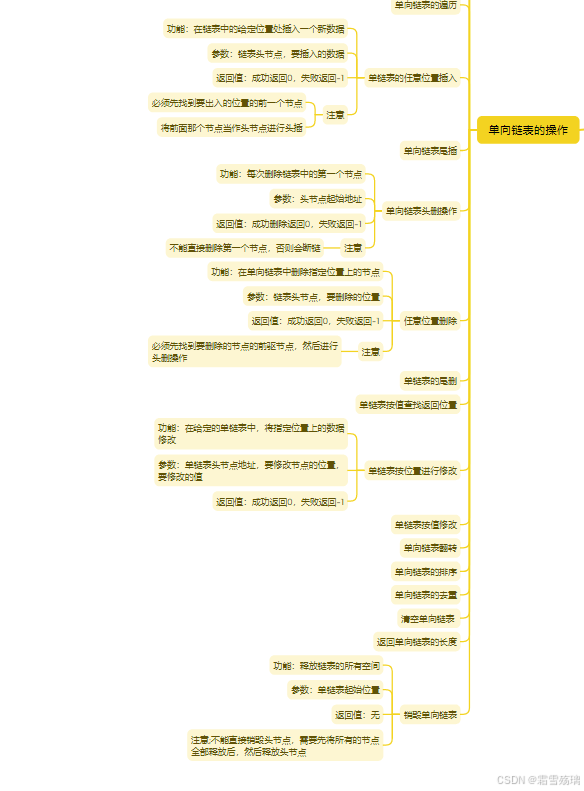
2024.11.29(单链表)
思维导图 声明文件 #ifndef __LINKLIST_H__ #define __LINKLIST_H__#include <myhead.h>typedef char datatype; //数据元素类型 //定义节点类型 typedef struct Node {union{int len; //头节点数据域datatype data; //普通节点数据域};struct Node *next; //指针域…...

基于深度学习和卷积神经网络的乳腺癌影像自动化诊断系统(PyQt5界面+数据集+训练代码)
乳腺癌是全球女性中最常见的恶性肿瘤之一,早期准确诊断对于提高生存率具有至关重要的意义。传统的乳腺癌诊断方法依赖于放射科医生的经验,然而,由于影像分析的复杂性和人类判断的局限性,准确率和一致性仍存在挑战。近年来…...

opengl 三角形
最后效果: OpenGL version: 4.1 Metal 不知道为啥必须使用VAO 才行。 #include <glad/glad.h> #include <GLFW/glfw3.h>#include <iostream> #include <vector>void framebuffer_size_callback(GLFWwindow *window, int width, int heigh…...

23种设计模式-抽象工厂(Abstract Factory)设计模式
文章目录 一.什么是抽象工厂设计模式?二.抽象工厂模式的特点三.抽象工厂模式的结构四.抽象工厂模式的优缺点五.抽象工厂模式的 C 实现六.抽象工厂模式的 Java 实现七.代码解析八.总结 类图: 抽象工厂设计模式类图 一.什么是抽象工厂设计模式?…...

手机上怎么拍证件照,操作简单且尺寸颜色标准的方法
在数字化时代,手机已成为我们日常生活中不可或缺的一部分。它不仅是通讯工具,更是我们拍摄证件照的便捷利器。然而,目前证件照制作工具鱼龙混杂,很多打着免费名号的拍照软件背后却存在着泄漏用户信息、照片制作不规范导致无法使用…...

IDEA报错: java: JPS incremental annotation processing is disabled 解决
起因 换了个电脑打开了之前某个老项目IDEA启动springcloud其中某个服务直接报错,信息如下 java: JPS incremental annotation processing is disabled. Compilation results on partial recompilation may be inaccurate. Use build process “jps.track.ap.depen…...

OCR实现微信截图改名
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple/ ──(Sat,Nov30)─┘ pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install paddleo…...

第一届“吾杯”网络安全技能大赛 Writeup
战队信息 战队名称:在你眼中我是誰,你想我代替誰? 战队排名:13 Misc Sign Hex 转 Str,即可得到flag。 原神启动! 不好评价,stegsolve 秒了: WuCup{7c16e21c-31c2-439e-a814-b…...

PlantUML vs Visual Paradigm:哪个更适合你的UML绘图需求?
PlantUML与Visual Paradigm深度对比:如何选择最适合你的UML工具? 在软件开发、系统设计或业务流程建模中,UML(统一建模语言)是工程师们不可或缺的沟通工具。面对众多UML工具,开发者常陷入选择困境ÿ…...

拒绝从入门到放弃:自学C语言前的“必修课”——一些重要基础概念的解析
C语言基础教程:变量和数据类型 大家好!我本身作为C语言的初学者,深知学习过程中对一些问题和概念的理解只停留在知其然而不知其所以然的状态,因而在系统性的查找文献和询问业内从业者后写出了这篇推文。这是我将新学的知识内化的…...

[.NET 9] BlazorWebView 无法在较旧的 Android 设备上加载, 附临时解决方法
BlazorWebView 无法在较旧的 Android 设备上加载Uncaught SyntaxError: Unexpected token . .NET 9 低于 v17 的 iOS 版本,IOS 16(2022年9月)、安卓API 31(2021年10月)上的 blazor.webview.js 出现意外语法错误 参考链…...
免配置环境!用Ollama部署TranslateGemma,支持55种语言翻译
免配置环境!用Ollama部署TranslateGemma,支持55种语言翻译 1. 为什么选择TranslateGemma-4b-it? 1.1 轻量级多语言翻译专家 TranslateGemma是Google基于Gemma 3模型系列开发的专用翻译模型,专注于解决实际翻译场景中的痛点。这…...

基于Qwen3-ASR-0.6B的语音质检系统:客服场景落地
基于Qwen3-ASR-0.6B的语音质检系统:客服场景落地 客服中心每天产生海量通话录音,传统人工质检只能覆盖极小样本,大量问题被遗漏。现在,借助Qwen3-ASR-0.6B语音识别模型,我们可以构建高效的智能质检系统,实现…...

2025 高效整理雪球内容:自动化下载与多格式导出实战
1. 为什么需要自动化整理雪球内容? 作为一个在金融信息领域摸爬滚打多年的老手,我深知及时获取和整理投资信息的重要性。雪球作为国内领先的投资社区,每天产生大量优质内容,但手动保存和整理这些内容简直是一场噩梦。想象一下&…...

墨语灵犀GPU低功耗部署:Jetson Orin Nano边缘设备运行轻量版实测
墨语灵犀GPU低功耗部署:Jetson Orin Nano边缘设备运行轻量版实测 1. 项目背景与需求 在边缘计算场景中,如何将大型AI模型高效部署到资源受限的设备上,是一个极具挑战性的工程问题。墨语灵犀作为一款基于腾讯混元大模型的深度翻译工具&#…...

UE4导航网格实战:如何用NavMeshBoundsVolume和NavModifierVolume打造智能AI寻路系统
UE4导航网格实战:智能AI寻路系统深度优化指南 在虚幻引擎4的AI开发中,导航网格(NavMesh)是实现角色自主移动的核心技术。不同于简单的路径点移动,基于导航网格的寻路系统能够模拟真实环境中的空间认知与路径规划能力。…...

用Python从零实现占据栅格地图:逆传感器模型与对数概率的代码优化技巧
Python实战:从零构建高效占据栅格地图的五大核心技术 在机器人感知领域,占据栅格地图(Occupancy Grid Mapping)是实现环境建模的基础技术。本文将带您深入探索如何用Python实现一个工业级强度的占据栅格地图系统,重点解…...

GTE文本向量中文大模型保姆级教程:从部署到旅游评论分析全流程
GTE文本向量中文大模型保姆级教程:从部署到旅游评论分析全流程 1. 引言:为什么需要文本向量模型? 想象一下,你正在经营一家旅游平台,每天新增数万条用户评论。如何从这些海量文字中快速了解游客对景点的真实评价&…...