深度学习笔记——生成对抗网络GAN
本文详细介绍早期生成式AI的代表性模型:生成对抗网络GAN。

文章目录
- 一、基本结构
- 生成器
- 判别器
- 二、损失函数
- 判别器
- 生成器
- 交替优化
- 目标函数
- 三、GAN 的训练过程
- 训练流程概述
- 训练流程步骤
- 1. 初始化参数和超参数
- 2. 定义损失函数
- 3. 训练过程的迭代
- 判别器训练步骤
- 生成器训练步骤
- 4. 交替优化
- 5. 收敛判别
- GAN 训练过程的挑战
- 四、GAN 的常见变体
- 1. DCGAN(Deep Convolutional GAN)
- 2. CycleGAN
- 3. BigGAN
- 4. StyleGAN
- 5. cGAN(Conditional GAN)
- 五、GAN 的应用场景
- 六、GAN 的优势与挑战
- 总结
- 历史文章
- 机器学习
- 深度学习
生成对抗网络(Generative Adversarial Network, GAN)是一种生成模型,由 Ian Goodfellow 等人于 2014 年提出。GAN 通过两个网络——生成器(Generator)和判别器(Discriminator)之间的对抗训练,使得生成器能够生成逼真的数据,从而被判别器难以区分。GAN 已广泛应用于图像生成、图像修复、风格迁移、文本生成等任务。
论文:Generative Adversarial Nets
一、基本结构
GAN 包含两个核心部分:生成器和判别器。
生成器
- 功能:生成器接收一个随机噪声向量(通常是高斯分布或均匀分布),并将其映射到数据空间,使生成的数据尽可能接近真实数据。
- 目标:生成器的目标是 “欺骗”判别器,使其无法区分生成数据和真实数据。
- 网络结构:生成器通常由一系列
反卷积(或上采样)层组成,以逐步生成更高分辨率的图像。
判别器
- 功能:判别器接收输入样本,并判断该样本真假。
- 目标:判别器的目标是尽可能准确地分辨出真假样本。
- 网络结构:判别器通常是一个
卷积神经网络(CNN),将输入数据压缩为一个概率值,表示该样本属于真实数据的概率。
二、损失函数
GAN 的训练是一个生成器和判别器相互博弈的过程,通过对抗训练逐步提高生成器的生成质量。训练过程主要包括以下步骤:
判别器
- 训练判别器时,其输入是真实数据和生成器的生成数据。
- 判别器的目标是区分真实数据和生成数据,即使得判别器输出接近 1 的概率表示真实数据,接近 0 的概率表示生成数据。
- 判别器的损失函数通常使用二元交叉熵(Binary Cross-Entropy):
L D = − E x ∼ p data [ log D ( x ) ] − E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] L_D = - \mathbb{E}_{x \sim p_{\text{data}}} [\log D(x)] - \mathbb{E}_{z \sim p_z} [\log(1 - D(G(z)))] LD=−Ex∼pdata[logD(x)]−Ez∼pz[log(1−D(G(z)))]
参数含义:
- x x x:真实数据样本,来自于真实数据分布 p data p_{\text{data}} pdata。
- z z z:生成器输入的噪声向量,通常从均匀分布或正态分布中采样。
- D ( x ) D(x) D(x):判别器对真实样本 x x x 的输出,表示判别器认为该样本是真实数据的概率。
- D ( G ( z ) ) D(G(z)) D(G(z)):判别器对生成数据 G ( z ) G(z) G(z) 的输出,表示判别器认为该样本为真实数据的概率。
判别器损失的计算过程:
-
第一部分:
− E x ∼ p data [ log D ( x ) ] - \mathbb{E}_{x \sim p_{\text{data}}} [\log D(x)] −Ex∼pdata[logD(x)]- 表示对真实样本的损失。
- 判别器希望尽量将真实数据的输出 D ( x ) D(x) D(x) 接近 1,因此这部分的目标是最小化 log D ( x ) \log D(x) logD(x)。
-
第二部分:
− E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] - \mathbb{E}_{z \sim p_z} [\log(1 - D(G(z)))] −Ez∼pz[log(1−D(G(z)))]- 表示对生成样本的损失。
- 判别器希望尽量将生成数据的输出 D ( G ( z ) ) D(G(z)) D(G(z)) 接近 0,因此这部分的目标是最小化 log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(z))) log(1−D(G(z)))。
生成器
- 训练生成器时,其输入是一个 随机噪声向量,通常记为 z。
- 生成器的目标是生成逼真的样本,“欺骗”判别器,使判别器无法分辨生成数据和真实数据,因此生成器希望判别器输出接近 1(让判别器以为生成的图像是真实的)。
- 生成器的损失函数与判别器的损失类似,但这里生成器希望最大化判别器对生成数据的输出,即让判别器认为生成数据为真实数据:
L G = − E z ∼ p z [ log D ( G ( z ) ) ] L_G = -\mathbb{E}_{z \sim p_z} [\log D(G(z))] LG=−Ez∼pz[logD(G(z))]
参数含义:
- z z z:生成器输入的噪声向量,通常从均匀分布或正态分布中采样。
- D ( G ( z ) ) D(G(z)) D(G(z)):判别器对生成数据 G ( z ) G(z) G(z) 的输出,表示判别器认为生成样本为真实数据的概率。
生成器损失的计算过程:
-
损失形式:
− E z ∼ p z [ log D ( G ( z ) ) ] -\mathbb{E}_{z \sim p_z} [\log D(G(z))] −Ez∼pz[logD(G(z))]
生成器的目标是使 D ( G ( z ) ) D(G(z)) D(G(z)) 接近 1,也就是希望判别器对生成的样本做出“真实”的判断。 -
目标:
生成器通过最大化判别器对生成样本的输出,使得判别器无法区分生成样本和真实样本。
生成器的目标是最小化该损失,即最大化判别器对生成样本的输出。
交替优化
在每轮训练中:
- 固定生成器,训练判别器。
- 固定判别器,训练生成器。
- 通过交替优化,两者不断改进,生成器的生成样本越来越逼真,而判别器的分辨能力也不断提高。
目标函数
GAN 的目标是找到一个平衡点,使生成器生成的样本和真实数据在分布上尽可能接近。它是一个极小极大(minimax)损失函数,表达了生成器和判别器的博弈:
min G max D V ( D , G ) = E x ∼ p data [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))]
参数含义:
- G G G:生成器的参数。
- D D D:判别器的参数。
- x x x:真实样本,来自真实数据分布 p data p_{\text{data}} pdata。
- z z z:噪声输入,通常从均匀分布或正态分布中采样。
- D ( x ) D(x) D(x):判别器对真实样本 x x x 的输出概率。
- D ( G ( z ) ) D(G(z)) D(G(z)):判别器对生成样本的输出概率。
这个目标函数包含两个部分:
- 最大化判别器的目标:判别器希望最大化 log D ( x ) \log D(x) logD(x) 和 log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(z))) log(1−D(G(z))),即尽可能将真实数据判断为真实样本、生成数据判断为生成样本。
- 最小化生成器的目标:生成器希望最小化 log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(z))) log(1−D(G(z))),即生成器希望生成的样本尽可能接近真实样本,以欺骗判别器。
实际的 GAN 训练过程中,不会直接出现极小极大损失函数,而是通过优化生成器和判别器的各自损失函数来间接实现这个目标。
极小极大损失函数的目标通过分解为判别器损失和生成器损失来实现,二者的对抗优化就是对极小极大目标函数的间接实现。通过交替优化生成器和判别器的损失。伪代码实现如下:
三、GAN 的训练过程
训练流程概述
GAN 的训练是一个极小极大(minimax)的博弈过程。
- 生成器的目标是生成逼真的样本来“欺骗”判别器,使得判别器无法分辨生成样本与真实样本;
- 判别器的目标是尽可能准确地区分真实样本和生成样本。
这种对抗关系通过两个网络的交替训练来实现。
GAN 的训练过程分为以下几个主要步骤。
训练流程步骤
1. 初始化参数和超参数
- 初始化生成器 G G G 和判别器 D D D 的网络参数。
- 设定超参数,如学习率、训练轮数、批量大小、优化器等。
- 通常选择的优化器为 Adam 优化器,初始学习率一般设为较小值,以确保训练过程稳定。
2. 定义损失函数
GAN 的损失函数由生成器和判别器的对抗损失组成。目标是找到一个平衡点,使生成器能够生成与真实样本分布相近的样本。
-
判别器损失:
(参考上节) -
生成器损失:
(参考上节)
3. 训练过程的迭代
训练过程的每一轮迭代中,生成器和判别器会交替优化。一般的训练过程如下:
判别器训练步骤
判别器的目标是区分真实样本和生成样本。每轮判别器训练分为以下步骤:
- 从真实数据分布中采样一批真实样本 x x x。
- 生成器从随机噪声分布 z z z(通常为正态分布或均匀分布)中采样一批噪声向量,并生成对应的样本 G ( z ) G(z) G(z)。
- 将真实样本 x x x 和生成样本 G ( z ) G(z) G(z) 分别输入判别器 D D D。判别器是一个二分类神经网络,通常由卷积层构成,以提取样本的特征。输出是一个概率值,表示输入样本为真实样本的概率。计算出对真实样本的输出 D ( x ) D(x) D(x) 和生成样本的输出 D ( G ( z ) ) D(G(z)) D(G(z))。
- 根据判别器损失函数 L D L_D LD计算判别器的损失,更新判别器的参数,使其能够更好地区分真实样本和生成样本。
判别器训练的目的是让它尽可能区分真实样本和生成样本,鼓励其将真实样本判断为 1,生成样本判断为 0。
生成器训练步骤
生成器的目标是生成能够“欺骗”判别器的样本。生成器的训练步骤如下:
- 从随机噪声分布 z z z 中采样一批噪声向量。
- 将噪声向量输入生成器 G G G,得到生成的样本 G ( z ) G(z) G(z)。生成器是一个神经网络,通常由多层神经网络构成。在图像生成任务中,生成器通常采用反卷积(转置卷积)或上采样层来逐步生成高分辨率图像。
- 将生成样本 G ( z ) G(z) G(z) 输入判别器 D D D,计算判别器对生成样本的输出 D ( G ( z ) ) D(G(z)) D(G(z))。
- 根据生成器损失函数 L G L_G LG计算生成器的损失,通过反向传播更新生成器的参数,使生成器生成的样本更加逼真,以“欺骗”判别器。
生成器的优化目标是使得判别器的输出 D ( G ( z ) ) D(G(z)) D(G(z)) 越接近 1 越好,即让判别器认为生成样本是真实样本。生成器训练时,这里的 D D D 的参数是不可训练的。
4. 交替优化
训练过程中,生成器和判别器会不断地交替优化。通常,每轮训练中会多次优化判别器(如更新判别器参数数次,再更新生成器参数一次),以确保判别器的分辨能力。这种交替优化的过程被称为 GAN 的“对抗训练”。
5. 收敛判别
GAN 的训练目标是找到生成器和判别器之间的平衡点,但收敛难以判断。通常可以通过以下方法判别 GAN 是否趋于收敛:
-
生成样本质量:
观察生成样本的视觉质量,当生成样本变得清晰且真实时,说明生成器已经学到了接近真实数据分布的特征。 -
判别器输出的均衡:
在理想的情况下,判别器对真实样本和生成样本的输出概率应接近 0.5,表示判别器很难区分真假样本。 -
损失变化:
监控生成器和判别器的损失,若损失趋于平稳,说明两者逐渐达到平衡状态。
GAN 训练过程的挑战
GAN 的训练通常存在一些挑战,需要在训练过程中进行调试和优化。
-
训练不稳定:
GAN 的训练过程可能会发生梯度消失或梯度爆炸,导致生成效果不佳。可以使用 WGAN、谱归一化等方法来提升稳定性。 -
模式崩溃(Mode Collapse):
生成器可能会陷入“模式崩溃”现象,即只生成相似的样本而缺乏多样性。可以通过多样性损失(如 Minibatch Discrimination)或训练策略(如添加噪声)来缓解模式崩溃。 -
对抗关系平衡:
判别器和生成器的能力需要平衡。若判别器太强,生成器难以改进;若生成器太强,判别器很快失去判断能力。可以适当调整判别器和生成器的训练频率,保持两者的平衡。
四、GAN 的常见变体
原始的 GAN 结构存在一些问题,例如训练不稳定、容易陷入模式崩溃(mode collapse)等。为了克服这些问题,出现了多种改进的 GAN 变体。
| 变体 | 主要改进 | 应用场景 | 优点 |
|---|---|---|---|
| DCGAN | 使用深度卷积结构生成图像,批量归一化等改进 | 高质量图像生成、人脸生成、艺术风格图像生成 | 生成质量高,结构简单 |
| CycleGAN | 无需配对数据,使用循环一致性损失和双生成器双判别器实现图像转换 | 图像风格迁移(照片转素描、白天转夜晚)等 | 无需配对数据,双向转换 |
| BigGAN | 标签嵌入、谱归一化、大型网络结构(更多层次的卷积) | 高清图像生成、超高分辨率生成 | 生成质量极高,适合大规模数据 |
| StyleGAN | 样式映射网络,自适应实例归一化(AdaIN),多尺度控制 | 高质量人脸生成、风格迁移 | 细节控制能力强,质量极高 |
| cGAN | 在生成器和判别器中加入条件输入,实现特定属性生成 | 根据类别标签生成图像(不同表情、年龄等) | 可控性高,适合特定属性生成 |
1. DCGAN(Deep Convolutional GAN)
DCGAN 是最早将卷积神经网络(CNN)应用于 GAN 的变体之一,被广泛应用于图像生成任务。DCGAN 的目标是提升图像生成质量,使生成器可以生成更高分辨率和更具细节的图像。
主要改进
- 使用卷积层替代 GAN 中传统的全连接层,生成器使用反卷积(或转置卷积)逐步生成图像,判别器使用标准的卷积层提取图像特征。
- 移除池化层,用步幅卷积(stride convolution)来减小分辨率,从而保留更多细节。
- 在生成器和判别器中使用批量归一化(Batch Normalization)来加速训练和提升稳定性。
- 生成器使用 ReLU 激活,判别器使用 Leaky ReLU 激活。
应用场景
- 高质量图像生成、人脸生成、艺术风格图像生成等。
优点
- 结构简单,训练稳定性较高,生成图像质量较好,是后续很多 GAN 变体的基础。
2. CycleGAN
CycleGAN 是一种专注于未配对数据集的图像到图像转换的 GAN 变体,用于解决当缺少成对样本时的风格迁移和图像转换任务。
主要改进
- 循环一致性损失(Cycle Consistency Loss):CycleGAN 在生成器中引入了循环一致性损失,使得图像从一种风格转换为另一种风格后,还可以还原回原始风格。这种双向映射的设计让 CycleGAN
能够在没有配对数据的情况下进行训练。- 双生成器双判别器:CycleGAN 使用两个生成器和两个判别器,分别负责从源域到目标域的转换,以及从目标域到源域的逆向转换。
应用场景
- 图像风格转换(如将马变为斑马、照片转为素描、白天转为夜晚)、图像修复和艺术创作等。
优点
- 无需配对训练数据,即可实现高质量的图像到图像转换,特别适合风格迁移任务。
3. BigGAN
BigGAN 是一种大规模、高分辨率的 GAN 变体,主要用于生成高质量、高分辨率的图像。BigGAN 在生成效果上达到了新的高度,但其训练难度和计算资源要求也较高。
主要改进
- 标签嵌入(Label Embedding):在生成器和判别器中加入标签嵌入,以便在条件 GAN 中生成具有特定类别的图像。
- 正则化和归一化技术:BigGAN 使用谱归一化(Spectral Normalization)来控制判别器的梯度,使得训练更稳定。此外,使用大批量训练、渐进式训练等手段来提高生成图像的分辨率和质量。
- 生成器架构调整:生成器中使用了更多层次的卷积,使得生成的图像更细腻,并利用大型网络结构提升生成质量。
应用场景
- 高清图像生成、图像生成研究等,适用于需要超高质量和分辨率的生成任务。
优点
- 生成质量出色,可以生成高分辨率的图像,但训练成本较高,适合有强大计算资源支持的场景。
4. StyleGAN
StyleGAN 是由 NVIDIA 提出的基于样式控制的 GAN 变体,提供了更高的图像生成质量和样式可控性。它被广泛用于高质量人脸生成和其他具有分层样式控制的生成任务中。
主要改进
- 样式映射网络(Style Mapping Network):StyleGAN 使用一个样式映射网络,将潜在空间中的输入向量映射到样式空间,然后将这些样式控制应用于生成器的不同层次。
- 自适应实例归一化(Adaptive Instance Normalization, AdaIN):生成器在每一层应用 AdaIN 操作,使样式向量可以控制每层的特征分布,实现不同分辨率下的细节和整体风格调整。
- 多尺度控制:通过在不同生成层次中应用样式向量,StyleGAN 可以在不同层次上控制图像的特征,从而生成更细腻、更有层次感的图像。
应用场景
- 高质量人脸生成、艺术风格迁移、细节编辑等。
优点
- 生成图像质量极高,具有强大的样式控制能力,能够在不同层次上调整生成样本的特征。
5. cGAN(Conditional GAN)
cGAN(条件 GAN) 是在生成器和判别器中引入条件信息(如类别标签、属性标签等)的 GAN 变体,使得 GAN 生成的图像可以带有特定的属性或类别。cGAN 的基本思想是在生成器和判别器的输入中加入条件变量。
主要改进
- 条件输入:在生成器的输入噪声向量上添加类别标签或其他条件变量,这使得生成器可以根据给定条件生成带有特定特征的图像。
- 判别器的条件输入:在判别器中引入相同的条件信息,使判别器能够更准确地判断生成样本是否符合给定条件。
应用场景
- 根据类别生成特定属性的图像,如不同表情、服装、场景、年龄等。适用于需要生成带有特定特征的图像任务。
优点
- 生成的图像具有更高的可控性,适合生成带有明确标签或特征的图像。
五、GAN 的应用场景
GAN 具有强大的生成能力,在多个领域中得到了广泛应用:
-
图像生成
- GAN 可用于生成高分辨率图像,应用于艺术创作、广告、电影制作等领域。
-
图像修复
- GAN 可用于修复有缺陷或损坏的图像,例如老照片修复、面部填补。
-
图像超分辨率
- GAN 可生成清晰的高分辨率图像,用于增强低分辨率图像的细节。
-
图像到图像的转换
- 例如将草图转为真实照片,黑白图像上色等。CycleGAN 在无监督图像转换任务上表现优异。
-
数据增强
- 在数据集有限的情况下,GAN 可以用于生成新样本,扩展训练数据,提升模型的泛化能力。
-
文本生成与文本到图像生成
- GAN 已应用于文本生成、文本到图像生成等任务,使 AI 能够根据描述生成符合语义的图像。
六、GAN 的优势与挑战
优势:
-
生成能力强
- GAN 的生成器可以生成逼真的样本,不仅限于简单的噪声分布。
-
无监督学习
- GAN 不需要带标签的样本,能够通过未标注数据进行无监督训练。
-
适用范围广
- GAN 的生成能力在图像、音频、文本等多种数据类型上都有广泛应用。
挑战:
-
训练不稳定
- GAN 的训练是生成器和判别器的对抗过程,容易陷入梯度消失或爆炸,训练过程不稳定。
-
模式崩溃
- GAN 可能生成重复样本而缺乏多样性(模式崩溃),即生成器只生成某些特定样本。
-
超参数敏感
- GAN 的训练对学习率、批量大小等超参数较为敏感,调优成本高。
-
难以衡量生成质量
- GAN 的生成样本质量较难定量评估,目前常用的 FID(Fréchet Inception Distance)等指标也无法完全反映样本质量。
总结
GAN 是一种强大的生成模型,通过生成器和判别器的对抗训练,使得生成器能够生成接近真实的数据。GAN 的多种变体和改进版本在图像生成、数据增强、风格转换等领域取得了显著成果。尽管 GAN 面临训练不稳定、模式崩溃等挑战,但它的生成能力为多个领域的研究和应用提供了新的可能性。未来的研究将继续优化 GAN 的稳定性和多样性,扩展其在不同场景的应用。
历史文章
机器学习
机器学习笔记——损失函数、代价函数和KL散度
机器学习笔记——特征工程、正则化、强化学习
机器学习笔记——30种常见机器学习算法简要汇总
机器学习笔记——感知机、多层感知机(MLP)、支持向量机(SVM)
机器学习笔记——KNN(K-Nearest Neighbors,K 近邻算法)
机器学习笔记——朴素贝叶斯算法
机器学习笔记——决策树
机器学习笔记——集成学习、Bagging(随机森林)、Boosting(AdaBoost、GBDT、XGBoost、LightGBM)、Stacking
机器学习笔记——Boosting中常用算法(GBDT、XGBoost、LightGBM)迭代路径
机器学习笔记——聚类算法(Kmeans、GMM-使用EM优化)
机器学习笔记——降维
深度学习
深度学习笔记——优化算法、激活函数
深度学习——归一化、正则化
深度学习——权重初始化、评估指标、梯度消失和梯度爆炸
深度学习笔记——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总
深度学习笔记——卷积神经网络CNN
深度学习笔记——循环神经网络RNN、LSTM、GRU、Bi-RNN
深度学习笔记——Transformer
深度学习笔记——3种常见的Transformer位置编码
深度学习笔记——GPT、BERT、T5
深度学习笔记——ViT、ViLT
深度学习笔记——DiT(Diffusion Transformer)
深度学习笔记——多模态模型CLIP、BLIP
深度学习笔记——AE、VAE
相关文章:

深度学习笔记——生成对抗网络GAN
本文详细介绍早期生成式AI的代表性模型:生成对抗网络GAN。 文章目录 一、基本结构生成器判别器 二、损失函数判别器生成器交替优化目标函数 三、GAN 的训练过程训练流程概述训练流程步骤1. 初始化参数和超参数2. 定义损失函数3. 训练过程的迭代判别器训练步骤生成器…...

网络安全开源组件
本文只是针对开源项目进行收集,如果后期在工作中碰到其他开源项目将进行更新。欢迎大家在评论区留言,您在工作碰到的开源项目。 祝您工作顺利,鹏程万里! 一、FW(防火墙) 1.1 pfSense pfSense项目是一个免费…...

Python毕业设计选题:基于django+vue的智慧社区可视化平台的设计与实现+spider
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 养老机构管理 业主管理 社区安防管理 社区设施管理 车位…...

Oracle LinuxR7安装Oracle 12.2 RAC集群实施(DNS解析)
oracleLinuxR7-U6系统Oracle 12.2 RAC集群实施(DNS服务器) 环境 RAC1RAC2DNS服务器操作系统Oracle LinuxR7Oracle LinuxR7windows server 2008R2IP地址172.30.21.101172.30.21.102172.30.21.112主机名称hefei1hefei2hefei数据库名hefeidbhefeidb实例名…...
M2芯片安装es的步骤
背景:因为最近经常用到es,但是测试环境没有es,自己本地也没安装,为了方便测试,然后安装一下,但是刚开始安装就报错,记录一下,安装的版本为8.16.1 第一步:去官网下载maco…...

macos下brew安装redis
首先确保已安装brew,接下来搜索资源,在终端输入如下命令: brew search redis 演示如下: 如上看到有redis资源,下面进行安装,执行下面的命令: brew install redis 演示效果如下: …...
第六届金盾信安杯-SSRF
操作内容: 进入环境 可以查询网站信息 查询环境url https://114.55.67.167:52263/flag.php 返回 flag 就在这 https://114.55.67.167:52263/flag.php 把这个转换成短连接,然后再提交 得出 flag...

【论文投稿】国产游戏技术:迈向全球引领者的征途
【IEEE出版南方科技大学】第十一届电气工程与自动化国际会议(IFEEA 2024)_艾思科蓝_学术一站式服务平台 更多学术会议论文投稿请看:https://ais.cn/u/nuyAF3 目录 国产游戏技术能否引领全球? 一、国产游戏技术的崛起之路 1.1 初期探索与积…...
面试题及参考答案)
腾讯微众银行大数据面试题(包含数据分析/挖掘方向)面试题及参考答案
为什么喜欢使用 XGBoost,XGBoost 的主要优势有哪些? XGBoost 是一个优化的分布式梯度增强库,在数据科学和机器学习领域应用广泛,深受喜爱,原因主要在于其众多突出优势。 首先,它的精度高,在许多机器学习竞赛和实际应用中,XGBoost 都展现出卓越的预测准确性。其基于决策…...

【Linux】死锁、读写锁、自旋锁
文章目录 1. 死锁1.1 概念1.2 死锁形成的四个必要条件1.3 避免死锁 2. 读者写者问题与读写锁2.1 读者写者问题2.2 读写锁的使用2.3 读写策略 3. 自旋锁3.1 概念3.2 原理3.3 自旋锁的使用3.4 优点与缺点 1. 死锁 1.1 概念 死锁是指在⼀组进程中的各个进程均占有不会释放的资源…...
Spring Web开发(请求)获取JOSN对象| 获取数据(Header)
大家好,我叫小帅今天我们来继续Spring Boot的内容。 文章目录 1. 获取JSON对象2. 获取URL中参数PathVariable3.上传⽂件RequestPart3. 获取Cookie/Session3.1 获取和设置Cookie3.1.1传统获取Cookie3.1.2简洁获取Cookie 3. 2 获取和存储Session3.2.1获取Session&…...

用c语言完成俄罗斯方块小游戏
用c语言完成俄罗斯方块小游戏 这估计是你在编程学习过程中的第一个小游戏开发,怎么说呢,在这里只针对刚学程序设计的学生,就是说刚接触C语言没多久,有一点功底的学生看看,简陋的代码,简陋的实现࿰…...
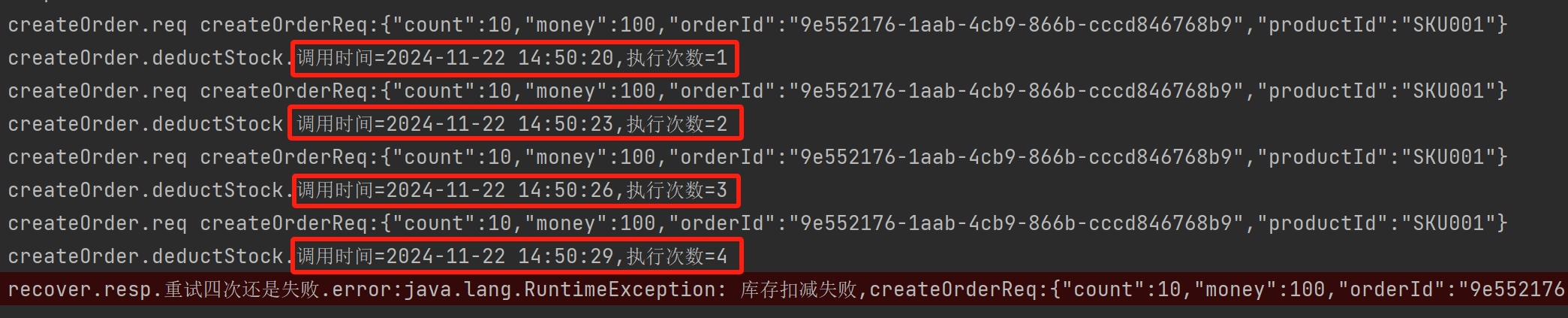
SpringBoot整合Retry详细教程
问题背景 在现代的分布式系统中,服务间的调用往往需要处理各种网络异常、超时等问题。重试机制是一种常见的解决策略,它允许应用程序在网络故障或临时性错误后自动重新尝试失败的操作。Spring Boot 提供了灵活的方式来集成重试机制,这可以通过…...
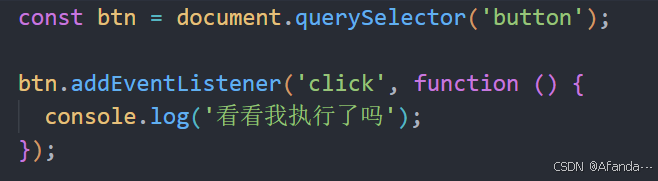
JS API事件监听(绑定)
事件监听 语法 元素对象.addEventListener(事件监听,要执行的函数) 事件监听三要素 事件源:那个dom元素被事件触发了,要获取dom元素 事件类型:用说明方式触发,比如鼠标单击click、鼠标经过mouseover等 事件调用的函数&#x…...

ceph手动部署
ceph手动部署 一、 节点规划 主机名IP地址角色ceph01.example.com172.18.0.10/24mon、mgr、osd、mds、rgwceph02.example.com172.18.0.20/24mon、mgr、osd、mds、rgwceph03.example.com172.18.0.30/24mon、mgr、osd、mds、rgw 操作系统版本: Rocky Linux release …...
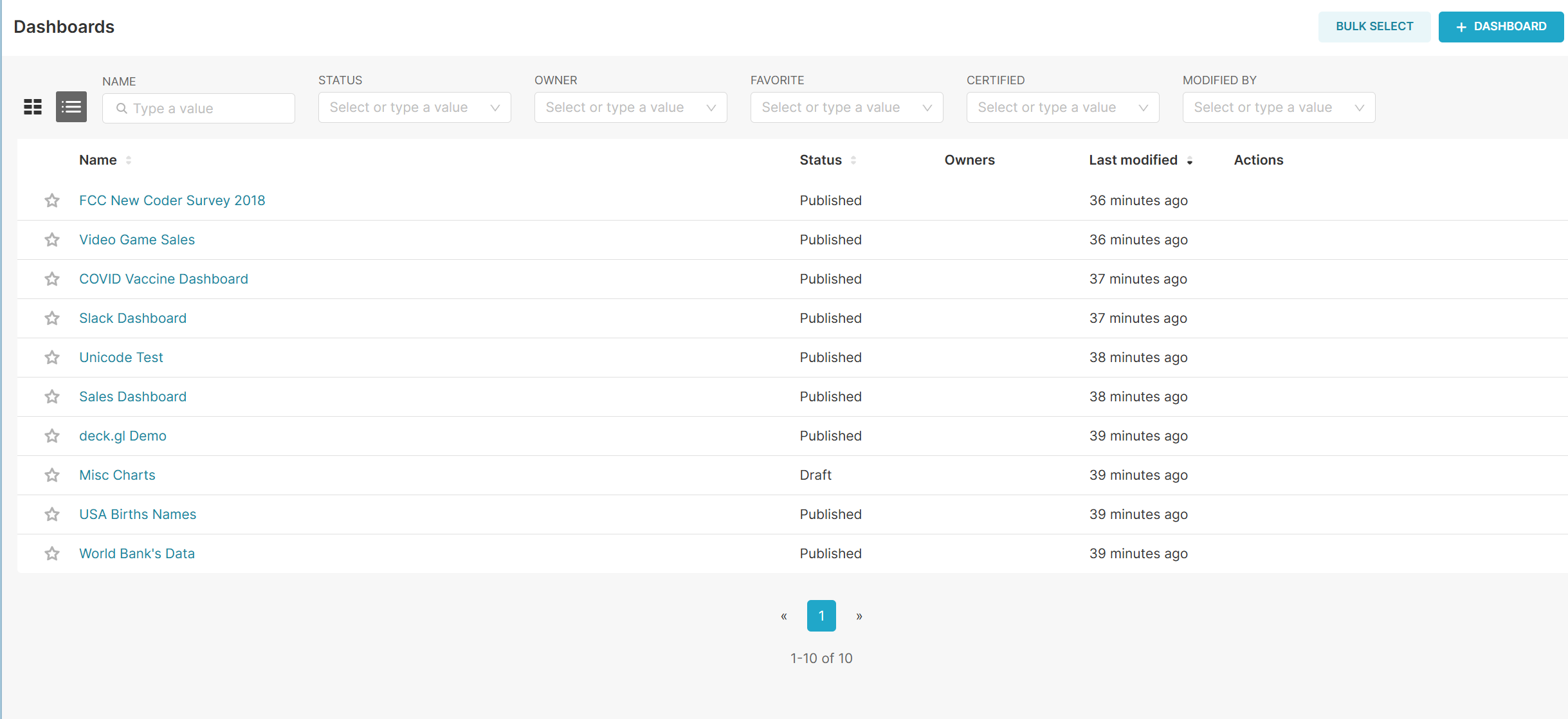
superset load_examples加载失败解决方法
如果在执行load_examples命令后,出现上方图片情况,或是相似报错(url error\connection error),大概率原因是python程序请求github数据,无法访问. 因此我们可以将数据下载在本地来解决. 1.下载zip压缩文件,存放到本地 官方示例地址:GitHub - apache-superset/examples-data …...

wareshark分析mysql协议的数据包
使用wareshark 分析mysql协议的数据包,是每个dba都应该掌握的技能,掌握以后,就可以通过tcpdump抓包分析,得到连接报错的信息了。 tcpdump抓包命令: tcpdump -nn -i bond0 dst 10.21.6.72 and port 4002 -w 1129_tcpdu…...
------UIAbility启动模式(文档编辑案例))
HarmonyOS4+NEXT星河版入门与项目实战(25)------UIAbility启动模式(文档编辑案例)
文章目录 1、启动模式2、Specified启动模式实现步骤3、文档编辑案例1、文件创建2代码实现3、Statge 创建4、添加配置1、启动模式 Singleton启动模式: 每个 UIAbility 只存在一个实例,是默认的启动模式,任务列表中只会存在一个相同的 UIAbilityStandard启动模式: 每次启动 U…...
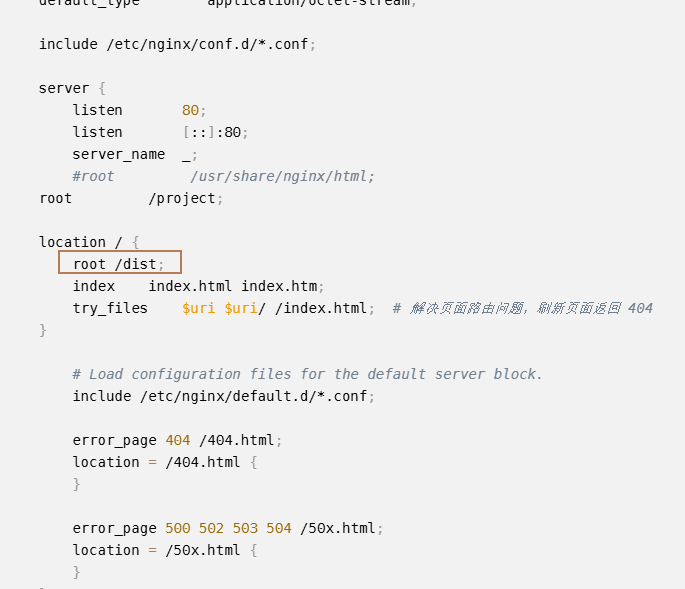
webpack 项目访问静态资源
使用 webpack dev serve 启动 react 项目后,发现无法使用 http://localhost:8080/1.png 访问到项目的 /static 目录下的 1.png 文件。我的 webpack-dev.js 配置如下: const webpack require(webpack) const webpackMerge require(webpack-merge) cons…...

UNION和UNION ALL区别
文章目录 结果集的处理方式:对重复记录的处理:排序处理:执行效率: UNION和UNION ALL的主要区别在于结果集的处理方式、对重复记录的处理、排序处理以及执行效率。 结果集的处理方式: UNION…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...