docker安装hadoop环境
一、使用docker搭建基础镜像
1、拉取centos系统镜像
# 我这里使用centos7为例子
docker pull centos:7
2、创建一个dockerfiler文件,用来构建自定义一个有ssh功能的centos镜像
# 基础镜像
FROM centos:7
# 作者
#MAINTAINER hadoop
ADD Centos-7.repo /etc/yum.repos.d/CentOS-Base.repo
# 将工作目录切换到`/etc/yum.repos.d/`
RUN cd /etc/yum.repos.d/
# 使用sed命令注释掉mirrorlist行。
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
# 使用sed命令将baseurl修改为`http://vault.centos.org`。
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
# 更新yum缓存。
RUN yum makecache
# 使用yum更新系统软件。
RUN yum update -y
# 使用yum安装openssh-server和sudo。
RUN yum install -y openssh-server sudo
# 使用sed命令将UsePAM设置为no,禁用PAM认证。
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
# 使用yum安装openssh-clients。
RUN yum install -y openssh-clients
# 使用echo和chpasswd命令将root用户的密码设置为123456。
RUN echo "root:123456" | chpasswd
# 将root用户添加到sudoers文件中,允许其执行任何命令。
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
# 生成DSA类型的SSH密钥。
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
# 生成RSA类型的SSH密钥。
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 创建`/var/run/sshd`目录。
RUN mkdir /var/run/sshd
# 暴露容器的22端口,用于SSH连接。
EXPOSE 22
# 设置容器启动时默认运行的命令为`/usr/sbin/sshd -D`,即启动SSH服务。
CMD ["/usr/sbin/sshd", "-D"]
3、因为默认的centos镜像是没有任何功能的,根据上面的dockerfile文件,生成我们的centos-ssh镜像
# 生成centos7-ssh镜像
docker build -t="centos7-ssh" .# 生成之后,我们的docker中就有了这个镜像
docker images
4、将jdk、hadoop安装包和Dockerfile目录平级,我是windows系统

5、之前的Dockerfile备份为dockerfile_centos7-ssh,我们重新再创建一个Dockerfile文件,用来构建hadoop镜像
# 基础镜像为centos7-ssh
FROM centos7-ssh# 将当前目录下的jdk复制到镜像中
ADD jdk-8u11-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_11 /usr/local/jdk
# 设置java环境变量
ENV JAVA_HOME /usr/local/jdk
ENV JRE_HOME=${JAVA_HOME}/jre
ENV CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
ENV PATH=${JAVA_HOME}/bin:$PATH# 将hadoop目录复制到镜像中
ADD hadoop-3.2.2.tar.gz /usr/local/
RUN mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
# 设置hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH6、根据这个Dockerfile生成centos-hadoop镜像
docker build -t="centos7-hadoop" .
7、由于hadoop集群的机器需要网络通讯,我们单独给这些服务创建一个网桥
docker network create hadoop
8、启动容器并连接到刚刚创建的网桥
docker run -itd --network hadoop --name hadoop1 -p 50070:50070 -p 8088:8088 -p 9870:9870 centos7-hadoopdocker run -itd --network hadoop --name hadoop2 centos7-hadoopdocker run -itd --network hadoop --name hadoop3 centos7-hadoop# 查看网桥使用情况
docker network inspect hadoop# 记录每台服务器ip,后面可能会用
172.18.0.2 hadoop1
172.18.0.3 hadoop2
172.18.0.4 hadoop3
二、进入每台容器,配置ip地址映射和ssh免密登录
1、配置ip地址,配置完成后,容器之间互相ping一下,看看是否可以ping通
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash# 在每台hadoop服务器的终端输入:
vi /etc/hosts
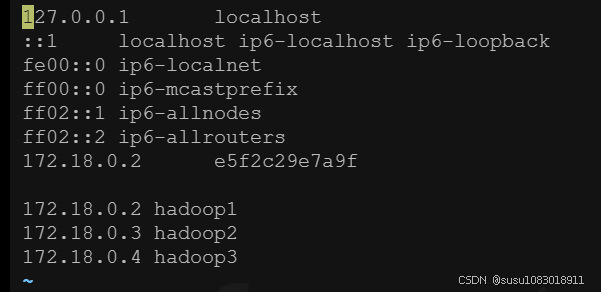
我本地发现,我修改完hosts文件后,我的环境变量配置失效了,重新又配置了一下
echo $PATHvi /etc/profileexport JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native# 保存文件并退出编辑器# 重新加载环境变量配置
source /etc/profile记得配置hadoop2和hadoop3,可以scp拷贝过去
2、配置免密登录
# 在每台hadoop服务器终端输入:
# 谁要去免密登录,谁就生成密钥对,使用ssh-keygen生成密钥对,密钥对包含id_rsa和id_rsa.pub,pub就是公钥,id_rsa是私钥,我们要把id_rsa发送到要免密登录的服务器上去
ssh-keygen# 然后一直回车即可,再在每台hadoop服务器终端中输入:
# 将公钥发送到需要免密登录的服务器上
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop1
# 填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop2
# 填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 root@hadoop3
# 填yes后,输入第二(3)步时设置的密码,123456# 测试是否成功配置ssh免密登录,ssh + hadoop服务器名:
ssh hadoop1
三、进入hadoop1中测试hadoop本地模式
1、修改配置文件
# 进入下面的目录
cd /usr/local/hadoop/etc/hadoop
# 修改hadoop-env.sh
vi ./hadoop-env.sh
# 显示行号
:set number
# 修改java目录为/usr/local/jdk
export JAVA_HOME=/usr/local/jdk
# 注意看下hadoop_home的路径是否正确2、新建一个测试数据集
# 在root目录下创建一个temp目录
mkdir /temp
# 创建测试数据集
vi /temp/data.txt
# 测试数据集内容
I Love Bejing
I Love LiuChang
I Love My Home
I Love you
I Love China
Do you miss me?
where are you doing?
this is hadoop hello world!# 进入share下面有一个测试的jar
cd /usr/local/hadoop/share/hadoop/mapreduce
# 这里面有很多mapreduce的测试jar包,这里我们测试一下wordcount,/root/temp表示测试数据集的目录,会读取下面所有的文件,/root/output/wc是输出目录
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /temp /output/wc# 执行之后,在/root/output/wc下就有生成的结果
more /output/wc/part-r-00000

四、hadoop全分布模式
以下配置在hadoop1上进行配置,配置完成后,直接把整个目录拷贝到hadoop2和hadoop3从节点
1、修改hadoop-env.sh
# 进入下面的目录
cd /usr/local/hadoop/etc/hadoop
# 修改hadoop-env.sh
vi ./hadoop-env.sh
# 显示行号
:set number
# 修改25行的java目录为/usr/local/jdk
export JAVA_HOME=/usr/local/jdk
2、修改hdfs-site.xml文件
<configuration>
<!-- 数据块的冗余度,默认是3 -->
<!-- 一般来说,数据块冗余度跟数据节点的个数一致,最大不超过3 -->
<property><name>dfs.replication</name><value>2</value>
</property><!-- 禁用了HDFS的权限检查 -->
<property><name>dfs.permissions</name><value>false</value>
</property>
</configuration>
3、配置core-site.xml文件
<configuration><!-- 配置NameNode地址 --><!-- 9000是RPC通信的端口 --><property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value></property><!-- HDFS对应的操作系统目录 --><!--默认是linux的/tmp,一定要进行修改,并且要创建该目录 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property></configuration>
4、配置mapred-site.xml文件
<configuration><!-- 配置MapReduce运行的框架是Yarn --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
5、配置yarn-site.xml文件
<configuration><!-- 配置ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value></property><!-- MapReduce运行的方式是:洗牌 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
注意如果是hadoop2.x版本配置slaves,Hadoop3.x版本中,集群配置的设置文件是workers
6、配置slaves文件
# 编辑从节点信息
vi ./etc/hadoop/slaves
# slaves内容
hadoop2
hadoop3
cd /usr/local/hadoop/etc/hadoop
即默认的情况下,Hadoop在本机启动,不加入分布式集群,因此无法随着集群的启动而启动。所以我们要把机器加入到集群环境中,在workers文件中,将hadoop1、hadoop2、hadoop3追加进去。
7、对NameNode进行格式化
hdfs namenode -format
8、hadoop1配置完成之后,把整个目录拷贝到hadoop2和hadoop3中
# 将hadoop1中的文件夹复制到hadoop2中
scp -r /usr/local/hadoop/ root@hadoop2:/usr/local# hadoop1中复制到hadoop3中
scp -r /usr/local/hadoop/ root@hadoop3:/usr/local
9、启动hadoop
## 启动hadoop
start-all.sh## 判断启动是否成功
# 在hadoop1上执行jps如果执行start-all.sh报错:
ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.

- 进入sbin目录,需要修改start-dfs.sh,stop-dfs.sh,start-yarn.sh,stop-yarn.sh四个文件
- 在start-dfs.sh,stop-dfs.sh两个文件顶部添加如下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 在start-yarn.sh,stop-yarn.sh顶部添加如下参数
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
在master节点上运行start-all.sh后,分别在hadoop2、hadoop3两台机器上进行进程检测。执行命令 jps

查看 Hadoop 的日志文件
cd $HADOOP_HOME/logsls -lt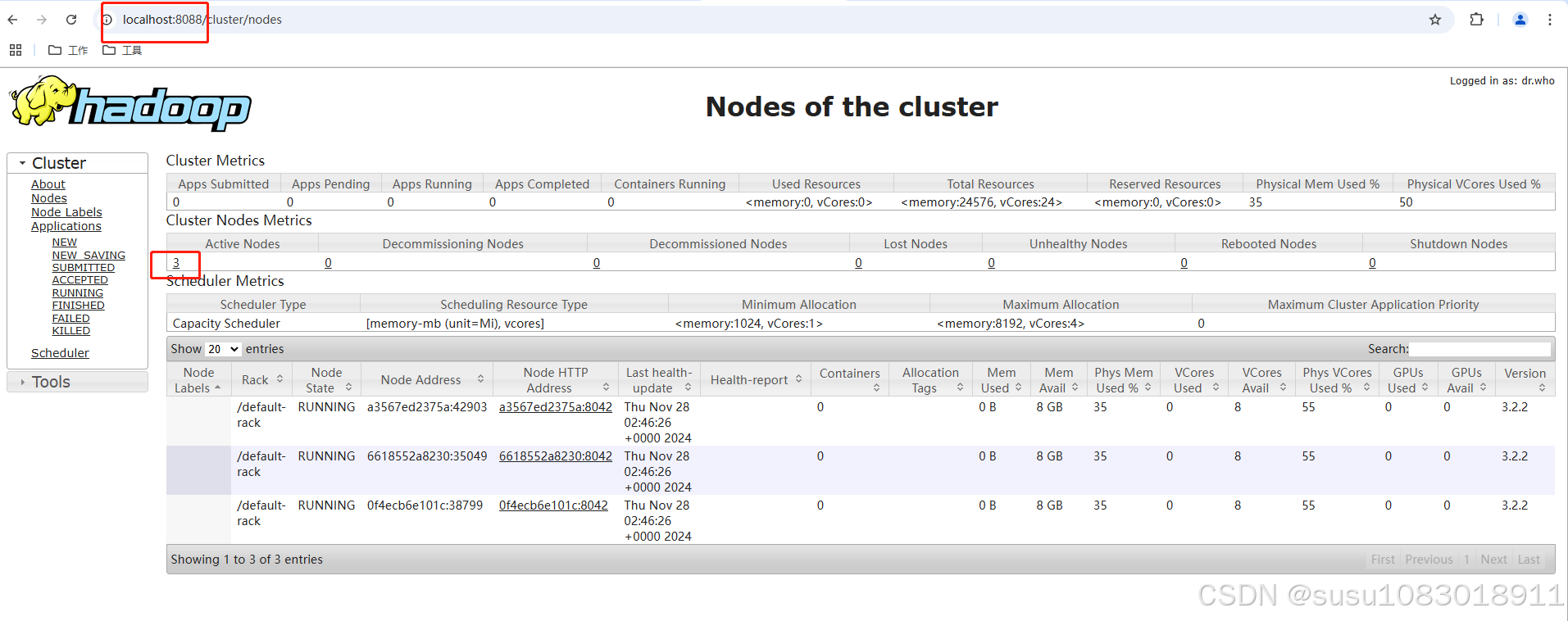
相关文章:
docker安装hadoop环境
一、使用docker搭建基础镜像 1、拉取centos系统镜像 # 我这里使用centos7为例子 docker pull centos:7 2、创建一个dockerfiler文件,用来构建自定义一个有ssh功能的centos镜像 # 基础镜像 FROM centos:7 # 作者 #MAINTAINER hadoop ADD Centos-7.repo /etc/yum.re…...

开源多媒体处理工具ffmpeg是什么?如何安装?使用ffmpeg将M3U8格式转换为MP4
目录 一、FFmpeg是什么二、安装FFmpeg(windows)三、将M3U8格式转换为MP4格式 一、FFmpeg是什么 FFmpeg是一款非常强大的开源多媒体处理工具,它几乎可以处理所有类型的视频、音频、字幕以及相关的元数据。 FFmpeg的主要用途包括但不限于&…...

算法刷题Day5: BM52 数组中只出现一次的两个数字
描述: 一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。 要求:空间复杂度 O(1),时间复杂度O(n)。 题目传送门 is here 思路: 方法一:最简单的思路就…...

55 基于单片机的方波频率可调
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 采用STC89C52单片机最小系统,设计DAC0832、放大器、与示波器显示方波,四位数码管显示频率,两个按键可调。 二、硬件资源 基于KEIL5编写C代码,PROT…...

23.useUnload
在 Web 应用开发中,处理页面卸载(unload)事件是一个重要但常常被忽视的方面。无论是提醒用户保存未保存的更改,还是执行一些清理操作,都需要在用户即将离开页面时进行处理。useUnload 钩子提供了一种简洁的方式来在 React 组件中处理 beforeunload 事件,使得在用户试图关…...

linux环境搭建
1、**连接外网** ssh在192.168.4.x上运行sudo ip link set ens160 down ssh切换到192.168.3.x(外网ip),运行sudo ip route add default via 192.168.2.1 dev ens192 onlink //连接外网 使用完外网后 ssh在192.168.3.x上运行sudo ip link set ens160 up ssh在1…...

《C++与生物医学的智能融合:医疗变革新引擎》
在当今科技飞速发展的时代,人工智能正以前所未有的深度和广度渗透到各个领域,为传统行业带来革新与突破。其中,将 C与生物学、医学等领域知识相结合,开发用于处理生物医学数据、辅助疾病诊断和治疗的人工智能应用,成为…...

Matlab 绘制雷达图像完全案例和官方教程(亲测)
首先上官方教程链接 polarplothttps://ww2.mathworks.cn/help/matlab/ref/polarplot.html 上实例 % 定义角度向量和径向向量 theta linspace(0, 2*pi, 5); r1 [1, 2, 1.5, 2.5, 1]; r2 [2, 1, 2.5, 1.5, 2];% 绘制两个雷达图 polarplot(theta, r1, r-, LineWidth, 2); hold …...

Lua的环境与热更
一、global_State,lua_State与G表 Lua支持多线程环境,使用 lua_State 结构来表示一个独立的 Lua 线程(或协程)。每个线程都需要一个独立的全局环境。而lua_State 中的l_G指针,指向一个global_State结构,这个就是我们常…...

HTML CSS JS基础考试题与答案
一、选择题(2分/题) 1.下面标签中,用来显示段落的标签是( d )。 A、<h1> B、<br /> C、<img /> D、<p> 2. 网页中的图片文件位于html文件的下一级文件夹img中,…...

若依解析(一)登录认证流程
JWTSpringSecurity 6.X 实现登录 JWT token只包含uuid ,token 解析uuid,然后某个常量加UUID 从Redis缓存查询用户信息 流程图如下 感谢若依,感谢开源,能有这么好系统供我学习。 设计数据库,部门表,用户表,…...
)
Redis设计与实现第17章 -- 集群 总结1(节点 槽指派)
集群通过分片sharding来进行数据共享,并提供复制和故障转移功能。 17.1 节点 一个Redis集群通常由多个节点node组成,刚开始每个节点都是相互独立的,必须将各个独立的节点连接起来,才能构成一个包含多个节点的集群。通过CLUSTER …...

汽车控制软件下载移动管家手机控车一键启动app
移动管家手机控制汽车系统是一款实现车辆远程智能控制的应用程序。通过下载并安装特定的APP,用户可以轻松实现以下功能:远程启动与熄火:无论身处何地,只要有网络,即可远程启动或熄火车辆,提前预冷或预…...

推荐几个可以免费下载网站模板的资源站
推荐几个可以免费下载网站模板的资源站,上面有免费的wordpress模板和帝国CMS模板可以下载。 模板帝 Mobandi.com 模板帝是一个提供丰富网站模板资源的平台,旨在帮助用户快速构建和美化自己的网站。无论是个人博客、企业官网还是电子商务平台ÿ…...

H3C OSPF实验
实验拓扑 实验需求 按照图示配置 IP 地址按照图示分区域配置 OSPF ,实现全网互通为了路由结构稳定,要求路由器使用环回口作为 Router-id,ABR 的环回口宣告进骨干区域 实验解法 一、配置IP地址 [R1]int l0 [R1-LoopBack0]ip add 1.1.1.1 32 […...

Vue框架开发一个简单的购物车(Vue.js)
让我们利用所学知识来开发一个简单的购物车 (记得暴露属性和方法!!!) 首先来看一下最基本的一个html框架 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"&…...

Windows Terminal Solarized Dark 配色方案调整
起因 Widnows 10/11 下面自带的 Terminal 还是比较方便的,因为不需要安装额外的 Terminal 软件。 我喜欢 Solarized Dark 配色方案,虽然有人批评这个配色方案比较老,但我觉得它比较优雅,尤其对外这种眼神比较差的人,比…...

PyTorch张量运算与自动微分
PyTorch张量运算与自动微分 PyTorch由Facebook人工智能研究院于2017年推出,具有强大的GPU加速张量计算功能,并且能够自动进行微分计算,从而可以使用基于梯度的方法对模型参数进行优化,大部分研究人员、公司机构、数据比赛都使用P…...

【从零开始的LeetCode-算法】3264. K 次乘运算后的最终数组 I
给你一个整数数组 nums ,一个整数 k 和一个整数 multiplier 。 你需要对 nums 执行 k 次操作,每次操作中: 找到 nums 中的 最小 值 x ,如果存在多个最小值,选择最 前面 的一个。将 x 替换为 x * multiplier 。 请你…...

【Linux】gdb / cgdb 调试 + 进度条
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、Linux调试器-gdb 🌟开始使用 🌠小贴士: 🌟gdb指令 🌠小贴士: ✨watch 监视 ✨打条件断点 二、小程序----进…...
和JLink的配合使用)
国产小华芯片(HC32L196)和JLink的配合使用
一、硬件的连接 主控芯片:HC32L196PCTA 小华,国产芯片 有SWD和JTAG模式,我用的是SWD模式 日常开发用SWD模式就够了,接线少不容易接错 有电源供电,只需要接SWDIO,SWCLK和GND即可 我这个是有独立电源供电…...

GCC -flto究竟多危险?——某车规MCU因启用全局链接时优化引发CAN总线丢帧的全链路复现与6步规避法
第一章:GCC -flto的本质与车规MCU的编译语义鸿沟 GCC 的 -flto(Link-Time Optimization)并非简单地延迟优化时机,而是将中间表示(GIMPLE)嵌入目标文件,使链接器(如 GNU ld 配合 plu…...

20 Python 关联分析:数据量大了,Apriori 太慢怎么办?一文入门 FP-Growth 算法
Python 数据分析入门:数据量大了,Apriori 太慢怎么办?一文入门 FP-Growth 算法适合人群:Python 初学者 / 数据分析入门 / 数据挖掘入门 / 教学案例分享在前面的学习里,我们已经知道: 可以通过关联分析找出商…...

如何为Fiber框架搭建WireMock接口Mock服务:完整测试环境配置指南
如何为Fiber框架搭建WireMock接口Mock服务:完整测试环境配置指南 【免费下载链接】fiber ⚡️ Express inspired web framework written in Go 项目地址: https://gitcode.com/GitHub_Trending/fi/fiber Fiber接口mock服务是现代Web开发中确保API可靠性的关键…...

MTools实战指南:从安装到使用,全面掌握图片视频AI处理工具
MTools实战指南:从安装到使用,全面掌握图片视频AI处理工具 还在为处理图片、剪辑视频、或者想用AI做点创意工作而发愁吗?是不是觉得Photoshop太复杂,Premiere太专业,而各种在线工具又功能分散、效果有限?如…...

Genshin FPS Unlock终极指南:突破帧率限制的完整技术方案
Genshin FPS Unlock终极指南:突破帧率限制的完整技术方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock Genshin FPS Unlock是一款针对原神游戏的帧率解锁工具,核…...

C#类型转换避坑指南:为什么你的Cast方法总抛InvalidCastException?
C#类型转换避坑指南:为什么你的Cast方法总抛InvalidCastException? 在C#开发中,类型转换是每个开发者都会遇到的常见操作。特别是使用LINQ的Cast<T>方法时,稍不注意就会遇到令人头疼的InvalidCastException异常。本文将深入…...

TMC4671开环控制实战:从参数配置到电机运转
1. TMC4671开环控制基础入门 第一次接触TMC4671这款伺服控制器时,我被它强大的集成度震惊了。这款芯片把BLDC/PMSM电机控制需要的所有功能都打包进了硬件,连ADC和位置传感器接口都内置了。对于刚入门的开发者来说,开环控制是最友好的起点&…...

ollama部署Phi-4-mini-reasoning实操手册:支持中文的高密度推理模型
ollama部署Phi-4-mini-reasoning实操手册:支持中文的高密度推理模型 想找一个推理能力强、支持中文、还特别轻量好部署的模型?最近上手的Phi-4-mini-reasoning让我眼前一亮。它虽然名字里有“mini”,但在逻辑推理和数学解题上的表现…...
)
KLayout新手必看:5分钟搞定圆形、文字和复杂图案绘制(附实例截图)
KLayout新手必看:5分钟搞定圆形、文字和复杂图案绘制(附实例截图) 作为一名芯片设计工程师,我深知KLayout在版图设计中的重要性。这款开源工具虽然功能强大,但对新手来说却有些门槛。记得我第一次使用时,光…...