C++《set与map》
在之前我们已经学习了解了C++STL当中的string和vector等容器,现在我们已经懂得了这些容器提供的接口该如何使用,并且了解了这些容器的底层结构。接下来我们在本篇当中将继续学习STL内的容器set与map,在此这两个容器与我们之前学习的容器提供的成员函数以及底层结构有细微的差异。接下来就开始本篇的学习吧!!!

1.顺序式容器与关联式容器
在了解set与map之前我们要先来了解什么是顺序式容器、什么是关联式容器。
前面我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,比如交换⼀下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
关联式容器也是用来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是非线性结构,两个位置有紧密的关联关系,交换⼀下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
注:本篇讲解的map和set底层是红⿊树,红黑树是⼀颗平衡⼆叉搜索树。set是key搜索场景的结构,map是key/value搜索场景的结构。红黑树的结构我们将在红黑树实现篇章详细的讲解
2.set
2.1 set使用介绍
set - C++ Reference

通过文档就可以看出set的底层其实就是Key搜索场景的结构,在此set的声明中还可以看出T就是set底层关键字的类型,并且set默认执行小于比较,如果不支持或者想按自行的需求走可以自行实现仿函数传给第⼆个模版参数 ;set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第三个参数。但⼀般情况下,我们都不需要传后两个模版参数。
• set底层是用红黑树实现,增删查效率是 O(logN) ,迭代器遍历是走的搜索树的中序,所以是有序的。
注:在此在之前我们已经学习了vector和list等的容器,由于因此在set的学习中我们就不再将接口一一的详细学习,而是选择重点的和之前学习的容器不同的部分进行学习
2.1.1 构造和迭代器
在set当中由于支持正向和反向的遍历,这是由于set的迭代器是双向迭代器;这也就使得set支持范围for。遍历时默认的是升序,因为底层是⼆叉搜索树,迭代器遍历走的是中序。由于set的底层是二叉搜索树这就使得set的迭代器iterator和reserve_iterator等都不支持使用迭代器修改元素内的数据,这是由于在二叉搜索树当中随意的修改数据就会破坏二叉搜索树的底层结构,因此在set内的迭代器只有读的权限没有写的权限。
并且在没有显示的传comp对应的参数时默认的是key_compare,在此你可能会疑惑key_compare是什么,在此其实就是仿函数less,只不过在set内被重命名了

注:在set当中key_type和value_type都是模板类参数T被重命名之后得到的
以上文档中各个构造函数的作用如下所示
set::set - C++ Reference
// empty (1) ⽆参默认构造
explicit set (const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());// range (2) 迭代器区间构造
template <class InputIterator>
set (InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type& = allocator_type());// copy (3) 拷⻉构造
set (const set& x);// initializer list (5) initializer 列表构造
set (initializer_list<value_type> il,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());以上文档中常用的迭代器如下所示
set - C++ Reference

// 正向迭代器
iterator begin();
iterator end();// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();2.1.2 增删查
set - C++ Reference

 在set当中提供了以上的成员函数来实现增删查,接下来我们就来学习这些成员函数的使用
在set当中提供了以上的成员函数来实现增删查,接下来我们就来学习这些成员函数的使用
首先来看在set内提供的插入数据的相关的成员函数只有insert,这是由于set底层是二叉搜索树,在插入时也要维护住搜索二叉树的结构,所以在set当中就没有提供push系列的相关插入函数,这就和之前我们学习的序列式容器vector和list等不同。

以上文档中insert各接口的作用如下所示
// 单个数据插⼊,如果已经存在则插⼊失败
pair<iterator,bool> insert (const value_type& val);// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);//插入一组值也就是一个initializer_list对象
void insert (initializer_list<value_type> il);
使用例如以下示例:
#include<iostream>
#include<set>
using namespace std;
int main()
{// 去重+升序排序set<int> s;// 去重+降序排序(给⼀个⼤于的仿函数)//set<int, greater<int>> s;s.insert(5);s.insert(2);s.insert(7);s.insert(5);//set<int>::iterator it = s.begin();auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;// 插⼊⼀段initializer_list列表值,已经存在的值插⼊失败s.insert({ 2,8,3,9 });for (auto e : s){cout << e << " ";}cout << endl;set<string> strset = { "sort", "insert", "add" };// 遍历string⽐较ascll码⼤⼩顺序遍历的for (auto& e : strset){cout << e << " ";}cout << endl;
}接下来来了解set内删除和查找相关函数的使用
set::erase - C++ Reference

set::find - C++ Reference

set::count - C++ Reference

以上文档中函数各接口的作用如下所示
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);// 删除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find (const value_type& val);// 查找val,返回Val的个数
size_type count (const value_type& val) const;
以上函数使用如下示例所示:
#include<iostream>
#include<set>
using namespace std;
int main()
{set<int> s = { 4,2,7,2,8,5,9 };for (auto e : s){cout << e << " ";}cout << endl;// 删除最⼩值s.erase(s.begin());for (auto e : s){cout << e << " ";}cout << endl;// 直接删除xint x;cin >> x;int num = s.erase(x);if (num == 0){cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;// 直接查找在利⽤迭代器删除xcin >> x;auto pos = s.find(x);if (pos != s.end()){s.erase(pos);}else{cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;cin >> x;if (s.count(x)){cout << x << "在!" << endl;}else{cout << x << "不存在!" << endl;}return 0;
}在此你可能会疑惑为什么在set内要提供find来实现元素的查找,不是直接调用算法库内的find就可以实现要求了吗?
在想到这种问题时就先要思考直接调用算法库内的函数有什么缺点还是算法库内的函数是否无法满足要求。就比如之前string内实现自己find就是由于在string当中有的场景下要在string对象内查找字符串,算法库内的find就无法实现该功能;再比如list内自己实现sort而不去调用算法库内的sort是由于算法库内的sort要求容器对应的迭代器是随机迭代器,而由于list的迭代器是双向迭代器就无法满足要求。
在此要解答以上的问题就首先要了解到算法库内的find查找的时间复杂度是O(N),当数据很多时这种查找效率就很低下了,因此set内就自己实现了find,在此该函数底层根据set底层是二叉搜索树的性质来实现查找,使用的查找方式就类似于之前我们实现的二叉搜索树的查找, 时间复杂度就为O(logN)
在此在set内删除除了使用以上的方式来删除以外还可以使用以下的两个函数配合来实现指定大小的区间值全部删除
使用到的就是lower_bound和upper_bound


在此itlow_bound返回的是要查找的指定值的迭代器,如果对应的set对象内没有指定的值就返回最接近指定值且大于指定值的迭代器, upper_bound返回的是大于要查找的指定值的迭代器,如果对应的set对象内没有指定的值就返回最接近指定值且大于指定值的迭代器。
这两个函数这样实现就是为了配合erase在使用迭代器区间删除时,迭代器区间是左闭右开的。
例如以下示例:
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> myset;for (int i = 1; i < 10; i++)myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90for (auto e : myset){cout << e << " ";}cout << endl;// 实现查找到的[itlow,itup)包含[30, 60]区间// 返回 >= 30auto itlow = myset.lower_bound(30);// 返回 > 60auto itup = myset.upper_bound(60);// 删除这段区间的值myset.erase(itlow, itup);for (auto e : myset){cout << e << " ";}cout << endl;return 0;
}以上代码输出结果:
再例如以下示例:
#include<iostream>
#include<set>
using namespace std;int main()
{set<int> myset({ 10 ,20, 35, 40, 50, 65, 70, 80, 90 });for (auto e : myset){cout << e << " ";}cout << endl;// 实现查找到的[itlow,itup)包含[30, 60]区间// 返回 >= 30auto itlow = myset.lower_bound(30);// 返回 > 60auto itup = myset.upper_bound(60);// 删除这段区间的值myset.erase(itlow, itup);for (auto e : myset){cout << e << " ";}cout << endl;return 0;
}以上代码输出结果:

其实在算法库当中也提供了itlow_bound和upper_bound
在此算法库内的函数就可以在vector和list等容器也可以使用,不过在使用这两个函数之前要求对象内的元素是有序的,这就使得在调用这两个函数之前如果对象内的元素不是有序的就需要先使用sort排序

2.2 multiset和set的差异
multiset - C++ Reference
set - C++ Reference
在set当中还提供了multiset,其实在此multiset就类似于我们之前二叉搜索树的key搜索场景支持冗余的情况。所以multiset和set的使⽤基本完全类似,主要区别点在于multiset支持值冗余,那么
insert/find/count/erase都围绕着支持值冗余有所差异,具体参看下面的样例代码理解。
#include<iostream>
#include<set>
using namespace std;
int main()
{// 相⽐set不同的是,multiset是排序,但是不去重multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;// 相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个int x;cin >> x;auto pos = s.find(x);while (pos != s.end() && *pos == x){cout << *pos << " ";++pos;}cout << endl;// 相⽐set不同的是,count会返回x的实际个数cout << s.count(x) << endl;// 相⽐set不同的是,erase给值时会删除所有的xs.erase(x);for (auto e : s){cout << e << " ";}cout << endl;return 0;
}
2.3 set使用练习
在了解了set的使用之后接下来我们就来试着通过两道算法题来巩固以上了解的set使用
349. 两个数组的交集 - 力扣(LeetCode)

通过以上的题目描述就可以看出该算法题要我们实现的是将两个数组的交集返回,那么要使用什么样的算法才能实现呢?
在此先要将两个数组都排序为升序并且去重,之后创建两个下标一开始分别指向两个数组的首元素,之后比较两个下标的元素;将元素值小的那个数组下标++;当两个数组下标指向的元素值相同时就将两个下标都++并且将值存储到新的数组当中,之后一直重复以上的操作直到两个下标中有一个到数组的末尾。
例如以下示例:

在以上示例的两个数组排序为升序并且去重之后就变为以下的形式
这时cur1和cur2指向的元素值相同就将对应的元素值存储到新的数组当中,接下来继续进行操作
最终就可以得到新数组内的元素为4和9,因此原来两个数组的交集为4和9




那么接下来就来实现该算法题的代码
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//要将数组nums1和nums2调整为升序而且还要去重就很适合使用setset<int> s1={nums1.begin(),nums1.end()};set<int> s2={nums2.begin(),nums2.end()};//vt内存储s1和s2的交集vector<int> vt;auto it1=s1.begin();auto it2=s2.begin();//遍历s1和s2while(it1!=s1.end() && it2!=s2.end()){if(*it1<*it2){it1++;}else if(*it1>*it2){it2++;}else{vt.push_back(*it1);it1++;it2++;}}return vt;}};
142. 环形链表 II - 力扣(LeetCode)

以上的算法题在数据结构当中的链表专题就已经解决过,不过之前我们解决该算法题的步骤较为繁琐,首先要快慢指针得到快慢指针相交的节点下标之后再定义一个新的指针指向链表的第一个节点,之后让新的节点和相交节点同时遍历,最终两个指针指向的同一个节点就是入环的第一个节点
那么有什么更加简洁的算法呢?
其实在此解决该算法题就可以使用到set,首先通过遍历将链表内的节点指针不断地插入到set对象内,并且在插入之前通过调用find来查找set对象内是否含有要插入的指针,当不存在时才执行插入,最终当find的返回值不为迭代器end()时,此时的指针就是链表入环的第一个节点指针
以下算法实现代码如下所示:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;ListNode* cur=head;while(cur){auto found=s.find(cur);if(found!=s.end()){return cur;}else{s.insert(cur);}cur=cur->next;}return nullptr;}
};
3. map
3.1 map类介绍
map - C++ Reference

通过文档就可以看出map的底层其实就是key/val搜索场景的结构,在此map的声明中还可以看出Key就是map底层关键字的类型,T是map底层value的类型,并且map默认执行小于比较,如果不支持或者想按自行的需求走可以自行实现仿函数传给第三个模版参数 ;set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第三个参数。⼀般情况下,我们都不需要传后两个模版参数。map底层是用红黑树实现,增删查改效率是 O(logN) ,迭代器遍历是走的中序,所以是按key有序顺序遍历的。
3.2 pair类型介绍
pair - C++ Reference
由于map是key/val搜索场景的结构,在map中为了实现key/val就其内部的成员变量就使用到了存储键值对的变量pair,在此pair也是一种模板类;pair内的成员变量有两个分别是first和second,这两个变量的类型是根类模板参数T1和T2确定的
具体的结构如下所示:

pair::pair - C++ Reference
在pair中也提供了以下的构造函数
3.3 map使用介绍
在了解了map的结构我们知道了map适用于key/val的搜索场景,那接下来就来了解map中的成员函数
3.3.1 构造函数和迭代器
map::map - C++ Reference


以上文档中各个构造函数的作用如下所示:
// empty (1) ⽆参默认构造
explicit map (const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());// range (2) 迭代器区间构造
template <class InputIterator>map (InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type& = allocator_type());// copy (3) 拷⻉构造
map (const map& x);// initializer list (5) initializer 列表构造map (initializer_list<value_type> il,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());在map当中支持正向和反向迭代遍历,这是由于map的迭代器是双向迭代器。遍历默认按key的升序顺序,因为底层是⼆叉搜索树,迭代器遍历走的中序;支持迭代器就意味着支持范围for,map⽀持修改value数据,不⽀持修改key数据,这和之前我们学习二叉搜索树key/val场景时一样如果修改关键字数据,就会破坏了底层搜索树的结构。
3.3.2 增删查
在map当中和set类似也提供了以下的成员函数来实现对map对象内元素的增、删、查


接下来先来看map内的提供的插入函数insert

![]()
注:以上的value_type实际上表示的是pair<const key_type,mapped_type>,在此value_type是被重命名之后得到的。而pair内的模板参数也是被重命名之后的,在此key_type实际上表示的是Key,mapped_type表示的是T。
以上文档中insert各接口的作用如下所示
//单个数据插入,当该数据原来就存在会插入失败,当Key相同value不同时也会插入失败
pair<iterator,bool> insert (const value_type& val);//单个数据在指定的迭代器位置插入,当当该数据原来就存在会插入失败
iterator insert (iterator position, const value_type& val);//迭代器区间插入,插入的值原来就存在不会插入
template <class InputIterator>
void insert (InputIterator first, InputIterator last);//列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);接下来来了解map内删除和查找相关函数的使用
map::erase - C++ Reference

map::find - C++ Reference

map::count - C++ Reference

以上文档中函数各接口的作用如下所示
// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find(const key_type& k);// 查找k,返回k的个数
size_type count(const key_type& k) const;// 删除⼀个迭代器位置的值
iterator erase(const_iterator position);// 删除k,k存在返回0,存在返回1
size_type erase(const key_type& k);// 删除⼀段迭代器区间的值
iterator erase(const_iterator first, const_iterator last);在此在map中和set一样也提供了lower_bound和upper_bound
// 返回⼤于等k位置的迭代器
iterator lower_bound (const key_type& k);
// 返回⼤于k位置的迭代器
const_iterator lower_bound (const key_type& k) const;// 返回小于等k位置的迭代器
iterator upper_bound (const key_type& k);
// 返回小于等k位置的迭代器
const_iterator upper_bound (const key_type& k) const;
使用例如以下示例:
#include<iostream>
#include<map>
using namespace std;
int main()
{// initializer_list构造及迭代遍历map<string, string> dict = { {"left", "左边"}, {"right", "右边"},{"insert", "插入"},{ "string", "字符串" } };//map<string, string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){//cout << (*it).first <<":"<<(*it).second << endl;// map的迭代基本都使⽤operator->,这⾥省略了⼀个->// 第⼀个->是迭代器运算符重载,返回pair*,第⼆个箭头是结构指针解引⽤取pair数据//cout << it.operator->()->first << ":" << it.operator->()-> second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;// insert插⼊pair对象的4种⽅式,对⽐之下,最后⼀种最⽅便pair<string, string> kv1("first", "第一个");dict.insert(kv1);dict.insert(pair<string, string>("second", "第二个"));dict.insert(make_pair("sort", "排序"));dict.insert({ "auto", "自动的" });// "left"已经存在,插⼊失败dict.insert({ "left", "左边,剩余" });// 范围for遍历for (const auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;string str;while (cin >> str){auto ret = dict.find(str);if (ret != dict.end()){cout << "->" << ret->second << endl;}else{cout << "⽆此单词,请重新输⼊" << endl;}}// erase等接⼝跟set完全类似,这⾥就不演⽰讲解了return 0;
}3.3.3 map的数据修改
前⾯提到map支持修改mapped_type 数据,不⽀持修改key数据,修改关键字数据,破坏了底层搜索树的结构。
map除了支持修改的⽅式时通过迭代器,迭代器遍历时或者find返回key所在的iterator修改,map
还有⼀个非常重要的修改接口operator[ ],但是operator[ ]不仅仅⽀持修改,还⽀持插⼊数据和查数
据,所以他是⼀个多功能复合接口
注:注意从内部实现⻆度,map这⾥把我们传统说的value值,给的是T类型,typedef为mapped_type。⽽value_type是红⿊树结点中存储的pair键值对值。日常使用我们还是习惯将这里的T映射值叫做value。
Member types
key_type -> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type -> pair<const key_type,mapped_type>在此我们先通过文档中insert函数返回值的描述就可以总结出以下的结论

1、如果key已经在map中,插⼊失败,则返回⼀个pair<iterator,bool>对象,返回pair对象
first是key所在结点的迭代器,second是false
2、如果key不在在map中,插⼊成功,则返回⼀个pair<iterator,bool>对象,返回pair对象
first是新插⼊key所在结点的迭代器,second是true
在此也就是说⽆论插⼊成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭
代器,那么也就意味着insert插⼊失败时充当了查找的功能,正是因为这⼀点,insert可以用来实现operator[]
接下来我们就来看看operator[ ]运算符重载函数内的实现
// operator的内部实现
mapped_type& operator[] (const key_type& k)
{// 1、如果k不在map中,insert会插⼊k和mapped_type默认值,同时[]返回结点中存储//mapped_type值的引⽤,那么我们可以通过引⽤修改返映射值。所以[]具备了插⼊ + 修改功能// 2、如果k在map中,insert会插⼊失败,但是insert返回pair对象的first是指向key结点的迭代器//返回值同时[]返回结点中存储mapped_type值的引⽤,所以[]具备了查找 + 修改的功能pair<iterator, bool> ret = insert({ k, mapped_type() });iterator it = ret.first;return it->second;
}使用例如以下示例:
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{// 利⽤[]插⼊+修改功能,巧妙实现统计⽔果出现的次数string arr[] = { "苹果", "西⽠", "苹果", "西⽠", "苹果", "苹果", "西⽠","苹果", "⾹蕉", "苹果", "⾹蕉" };map<string, int> countMap;for (const auto& str : arr){// []先查找⽔果在不在map中// 1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 0},同时返回次数的引⽤,++⼀下就变成1次了// 2、在,则返回⽔果对应的次数++countMap[str]++;}for (const auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{map<string, string> dict;dict.insert(make_pair("sort", "排序"));// key不存在->插⼊ {"insert", string()}dict["insert"];// 插⼊+修改dict["left"] = "左边";// 修改dict["left"] = "左边、剩余";// key存在->查找cout << dict["left"] << endl;return 0;
}
通过以上示例就可以看出相比find与insert,在一些场景下直接适用operator就简介许多
3.4 multimap和map的差异
multimap和map的使用基本完全类似,主要区别点在于multimap⽀持关键值key冗余,那么
insert/find/count/erase都围绕着⽀持关键值key冗余有所差异,这⾥跟set和multiset完全⼀样,⽐如find时,有多个key,返回中序第⼀个。其次就是multimap不⽀持[],因为支持key冗余,[]就只能⽀持插⼊了,不能⽀持修改。
3.5 map使用练习
在了解了map的使用之后接下来我们就来试着通过两道算法题来巩固以上了解的map使用
138. 随机链表的复制 - 力扣(LeetCode)

数据结构初阶阶段,为了控制随机指针,我们将拷贝结点链接在原节点的后⾯解决,后⾯拷⻉节点还得解下来链接,非常⿇烦。这⾥我们直接让{原结点,拷贝结点}建⽴映射关系放到map中,控制随机指针会非常简单⽅便,这⾥体现了map在解决⼀些问题时的价值,完全是降维打击。
实现代码如下所示:
/*
// Definition for a Node.
class Node {
public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};
*/class Solution {
public:Node* copyRandomList(Node* head) {Node* cur=head;Node* newhead,*newtail;newhead=newtail=nullptr;map<Node*,Node*> m;while(cur){if(newhead==nullptr){newhead=newtail=new Node(cur->val);}else{newtail->next=new Node(cur->val);newtail=newtail->next;}m[cur]=newtail;cur=cur->next;} //拷贝节点内randomcur=head;Node* newcur=newhead;while(cur){if(cur->random==nullptr){newcur->random=nullptr;}else{newcur->random=m[cur->random];}cur=cur->next;newcur=newcur->next;}return newhead;}
};
692. 前K个高频单词 - 力扣(LeetCode)

通过以上的题目描述就可以看出本题目我们利⽤map统计出次数以后,返回的答案应该按单词出现频率由⾼到低排序,有⼀个特殊要求,如果不同的单词有相同出现频率,按字典顺序排序。
在此有两种方法可以解决该算法题:
解决思路1:
⽤排序找前k个单词,因为map中已经对key单词排序过,也就意味着遍历map时,次数相同的单词,字典序⼩的在前面,字典序⼤的在后面。那么我们将数据放到vector中用⼀个稳定的排序就可以实现上面特殊要求,但是sort底层是快排通过之前数据结构——排序的学习我们知道快排是不稳定的,所以我们要⽤stable_sort,他是稳定的,其底层排序是归并排序。
实现代码如下所示:
class Solution {
public:class compare{public:bool operator()(const pair<string,int> x1,const pair<string,int> x2){return x1.second>x2.second ;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> m;for(auto& x:words){m[x]++;}vector<pair<string,int>> vt(m.begin(),m.end());stable_sort(vt.begin(),vt.end(),compare());vector<string> VT;for(int i=0;i<k;i++){VT.push_back(vt[i].first);}return VT;}
};解决思路2:
将map统计出的次数的数据放到vector中排序,或者放到priority_queue中来选出前k个。利⽤仿函数强行控制次数相等的,字典序⼩的在前面。
实现代码如下所示:
class Solution {
public:class compare{public:bool operator()(const pair<string,int> x1,const pair<string,int> x2){return x1.second>x2.second || (x1.second==x2.second && x1.first<x2.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> m;for(auto& x:words){m[x]++;}vector<pair<string,int>> vt(m.begin(),m.end());sort(vt.begin(),vt.end(),compare());vector<string> VT;for(int i=0;i<k;i++){VT.push_back(vt[i].first);}return VT;}
};class Solution {
public:struct Compare {bool operator()(const pair<string, int>& x,const pair<string, int>& y) const {// 要注意优先级队列底层是反的,⼤堆要实现⼩于⽐较,所以这⾥次数相等,想要字典序⼩的在前⾯要⽐较字典序⼤的为真return x.second < y.second ||(x.second == y.second && x.first > y.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string, int> countMap;for (auto& e : words) {countMap[e]++;}// 将map中的<单词,次数>放到priority_queue中,仿函数控制⼤堆,次数相同按照字典序规则排序priority_queue<pair<string, int>, vector<pair<string, int>>, Compare> p(countMap.begin(), countMap.end());vector<string> strV;for (int i = 0; i < k; ++i){strV.push_back(p.top().first);p.pop();}return strV;}
};以上就是本篇的全部内容了,希望能得到你的点赞和收藏 ❤️
相关文章:
C++《set与map》
在之前我们已经学习了解了CSTL当中的string和vector等容器,现在我们已经懂得了这些容器提供的接口该如何使用,并且了解了这些容器的底层结构。接下来我们在本篇当中将继续学习STL内的容器set与map,在此这两个容器与我们之前学习的容器提供的成…...

深度学习-52-AI应用实战之基于Yolo8的目标检测自动标注
文章目录 1 YOLOv81.1 YOLOV8的不同版本1.2 可检测类别1.3 数据说明1.4 网络结构1.5 算法核心步骤2 目标检测的基本原理2.1 安装yolov8(cpu版本)2.2 图片检测2.3 视频检测2.4 自动标注2.5 保存标注结果3 参考附录1 YOLOv8 YOLOv8是一种前沿的计算机视觉技术,它基于先前YOLO版…...

【Elasticsearch】05-DSL查询
1. 查询所有 es最多只支持查询1万条数据。 # 查询所有 GET /items/_search {"query": {"match_all": {}} }2. 叶子查询 全文检索 会对结果进行相关度打分。 # 检索单个字段 GET /items/_search {"query": {"match": {"name&…...

qml项目创建的区别
在Qt框架中,你可以使用不同的模板来创建应用程序。你提到的这几个项目类型主要针对的是Qt的不同模块和用户界面技术。下面我将分别解释这些项目类型的区别: 根据你提供的信息,以下是每个项目模板的详细描述和适用场景: Qt Widgets…...
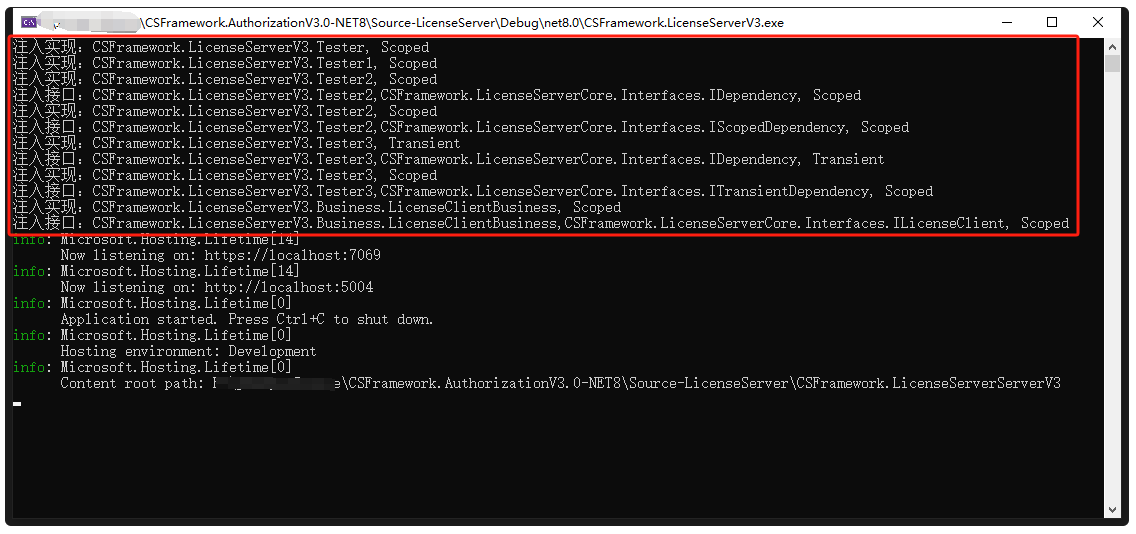
.NET8/.NETCore 依赖注入:自动注入项目中所有接口和自定义类
.NET8/.NETCore 依赖接口注入:自动注入项目中所有接口和自定义类 目录 自定义依赖接口扩展类:HostExtensions AddInjectionServices方法GlobalAssemblies 全局静态类测试 自定义依赖接口 需要依赖注入的类必须实现以下接口。 C# /// <summary>…...

Flutter:city_pickers省市区三级联动
pubspec.yaml city_pickers插件地址 自己用的GetBuilder页面模板 cupertino_icons: ^1.0.8 # 省市区城市选择 city_pickers: ^1.3.0编辑地址页面:controller class AddressEditController extends GetxController {AddressEditController();Future<Result?>…...

Kafka-Connect自带示例
一、上下文 《Kafka-Connect》中已经阐述了Kafka-Connect的理论知识,为了更生动的理解它,我们今天通过官方的一个小例子来感受下它的妙用。 二、创建topic kafka-topics --create --topic connect-test --bootstrap-server cdh1:9092 --partitions 2 -…...

Hbase应用案例 随机号码生成
Hbase应用案例1 随机号码生成 在Hbase中插入如下格式的数据,数据内容随机生成 名称示例说明phonenumber158randomrowkey,号码dnum199randomcolumn,另一位通话者lengthrandomcolumn,时长valuerandomcolumn,接收或拨打…...

论文阅读——量子退火Experimental signature of programmable quantum annealing
摘要:量子退火是一种借助量子绝热演化解决复杂优化问题的通用策略。分析和数值证据均表明,在理想化的封闭系统条件下,量子退火可以胜过基于经典热化的算法(例如模拟退火)。当前设计的量子退火装置的退相干时间比绝热演…...
(长期更新)《零基础入门 ArcGIS(ArcMap) 》实验二----网络分析(超超超详细!!!)
相信实验一大家已经完成了,对Arcgis已进一步熟悉了,现在开启第二个实验 ArcMap实验--网络分析 目录 ArcMap实验--网络分析 1.1 网络分析介绍 1.2 实验内容及目的 1.2.1 实验内容 1.2.2 实验目的 2.2 实验方案 2.3 实验流程 2.3.1 实验准备 2.3.2 空间校正…...

go语言 Pool实现资源池管理数据库连接资源或其他常用需要共享的资源
go Pool Pool用于展示如何使用有缓冲的通道实现资源池,来管理可以在任意数量的goroutine之间共享及独立使用的资源。这种模式在需要共享一组静态资源的情况(如共享数据库连接或者内存缓冲区)下非 常有用。如果goroutine需要从池里得到这些资…...

mysql一个事务最少几次IO操作
事务的IO操作过程 开始事务:用户发起一个事务,例如执行START TRANSACTION;,此时事务开始。读取和修改数据:用户读取和修改数据时,InnoDB首先从Buffer Pool查找所需的数据页。如果数据页不在Buffer Pool中,…...

运输层总结
运输层协议:端到端协议 面向连接的传输控制协议 TCP无连接的用户数据报协议 UDP - 主要任务:为相 互通信的应用进程 提供 逻辑通信服务 - 屏蔽:运输层向高层用户 屏蔽 了下面网络核心的细节(如网络拓扑、所采用 的路由选择协议等…...

【嵌套查询】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

React 前端框架1
一、React 简介 (一)什么是 React React 是一个用于构建用户界面的 JavaScript 库,由 Facebook 开源并维护。它采用了组件化的开发思想,允许开发者将复杂的 UI 拆分成一个个独立、可复用的小组件,就如同搭积木一般&am…...
)
【真正离线安装】Adobe Flash Player 32.0.0.156 插件离线安装包下载(无需联网安装)
网上很多人声称并提供的flash离线安装包是需要联网才能安装成功的,其实就是在线安装包,而这里提供的是真正的离线安装包,无需联网即可安装成功。 点击下面地址下载离线安装包: Adobe Flash Player 32.0.0.156 for IE Adobe Fla…...

数据采集时,不同地区的动态IP数据质量有什么差异?
在数据采集的广阔世界中,动态IP扮演着至关重要的角色。它们不仅帮助我们突破地域限制,还能够提供多样化的数据来源。但是,不同地区的动态IP在数据质量上是否存在差异呢?本文将探讨这一问题,并为您提供实用的见解。 动…...

【Python爬虫五十个小案例】爬取猫眼电影Top100
博客主页:小馒头学python 本文专栏: Python爬虫五十个小案例 专栏简介:分享五十个Python爬虫小案例 🐍引言 猫眼电影是国内知名的电影票务与资讯平台,其中Top100榜单是影迷和电影产业观察者关注的重点。通过爬取猫眼电影Top10…...

等保测评和 ISO27001 都是信息保护,区别是什么?
ISO27001 和等级保护(等保)都是信息安全领域重要的标准和制度,但它们在多个方面存在区别: 定义和性质 ISO27001 它是国际标准化组织(ISO)发布的信息安全管理体系标准,其目的是帮助组织建立、实…...

Linux系统编程之进程创建
概述 在Linux系统中,通过创建新的进程,我们可以实现多任务处理、并发执行和资源隔离等功能。创建进程的主要方法为:fork、vfork、clone。下面,我们将分别进行介绍。 fork fork是最常用的创建新进程的方法。当一个进程调用fork时&a…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...
针对药品仓库的效期管理问题,如何利用WMS系统“破局”
案例: 某医药分销企业,主要经营各类药品的批发与零售。由于药品的特殊性,效期管理至关重要,但该企业一直面临效期问题的困扰。在未使用WMS系统之前,其药品入库、存储、出库等环节的效期管理主要依赖人工记录与检查。库…...
docker容器互联
1.docker可以通过网路访问 2.docker允许映射容器内应用的服务端口到本地宿主主机 3.互联机制实现多个容器间通过容器名来快速访问 一 、端口映射实现容器访问 1.从外部访问容器应用 我们先把之前的删掉吧(如果不删的话,容器就提不起来,因…...