flink学习(13)—— 重试机制和维表join
重试机制
当任务出现异常的时候,会直接停止任务——解决方式,重试机制
1、设置checkpoint后,会给任务一个重启策略——无限重启
2、可以手动设置任务的重启策略
代码设置
//开启checkpoint后,默认是无限重启,可以设置该值 表示不重启
env.setRestartStrategy(RestartStrategies.noRestart());//作业失败flink中最多重启3次,每次重启的最小间隔是10s
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));//2分钟内最多重启3次,每次重启的最小间隔是5秒
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(2,TimeUnit.MINUTES),Time.of(5,TimeUnit.SECONDS))
);//无限重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(Integer.MAX_VALUE, // 无限重启次数Time.of(10, TimeUnit.SECONDS) // 每次重启的延迟时间
));维表join
所谓的维表Join: 进入Flink的数据,需要关联另外一些存储设备的数据,才能计算出来结果
那么存储在外部设备上的表称之为维表,可能存储在mysql也可能存储在hbase 等。
维表一般的特点是变化比较慢。——名词表,维度表。
解决方式
解决维表join的方式方式一:可以用一个静态代码块,或者在open方法中对一个集合初始化,用于存放想要相关联的数据。缺点:数据不能动态改变了方式二:在open中初始化连接,在map中每拿到流中的一条数据,就去mysql中查找一次缺点:数据可以动态改变,但是去mysql查找的次数太多了方式三:创建一个缓存区,用于存放数据,若过期则再去mysql中查询数据。没有缺点,可以动态获取数据了,也减少了mysql的查询次数(缓冲)唯一的是,若是多线程,可能会去mysql查询多次方式一
package com.bigdata.day06;import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapHandler;
import org.apache.commons.dbutils.handlers.MapListHandler;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.List;
import java.util.Map;
import java.util.Properties;/*** 直接从mysql中拿出* 弊端 只能拿到一次 不能实现动态*/
public class _03_维表join_01 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("edu",new SimpleStringSchema(),properties);DataStreamSource<String> source = env.addSource(consumer);source.map(new RichMapFunction<String, String>() {ComboPooledDataSource pool = null;QueryRunner queryRunner = null;List<Map<String, Object>> list = null;@Overridepublic void open(Configuration parameters) throws Exception {// 在open中执行sqlpool = new ComboPooledDataSource();queryRunner = new QueryRunner(pool);String sql = "select * from city ";list = queryRunner.query(sql, new MapListHandler());}@Overridepublic void close() throws Exception {pool.close();}@Overridepublic String map(String line) throws Exception {String[] split = line.split(",");Object cityName = "未知";for (Map<String, Object> map : list) {String cityId = (String)map.get("city_id");if (cityId.equals(split[1])){cityName = map.get("city_name");}}return line+","+cityName;}}).print();env.execute();}
}方式二
package com.bigdata.day06;import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapHandler;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Map;
import java.util.Properties;/*** 每次从kafka中拿到一条数据就从mysql中查一遍* 弊端 对mysql的压力加大*/
public class _03_维表join_02 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("edu",new SimpleStringSchema(),properties);DataStreamSource<String> source = env.addSource(consumer);source.map(new RichMapFunction<String, String>() {ComboPooledDataSource pool = null;QueryRunner queryRunner = null;@Overridepublic void open(Configuration parameters) throws Exception {pool = new ComboPooledDataSource();queryRunner = new QueryRunner(pool);}@Overridepublic void close() throws Exception {pool.close();}@Overridepublic String map(String line) throws Exception {// 在处理逻辑中执行sqlString[] split = line.split(",");String sql = "select city_name from city where city_id = ?";Map<String, Object> rs = queryRunner.query(sql, new MapHandler(), split[1]);String cityName="未知";if (rs !=null){cityName = (String) rs.get("city_name");}return line+","+cityName;}}).print();env.execute();}
}方式三
package com.bigdata.day06;import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapHandler;
import org.apache.commons.dbutils.handlers.MapListHandler;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava18.com.google.common.cache.*;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.TimeUnit;/*** 最终 非常好的方式* 现在内存中查 查不到在去mysql中找* 唯一的问题是,假如是多线程情况下,可能会触发多次去mysql中查找的方法*/
public class _03_维表join_03_cache {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("edu",new SimpleStringSchema(),properties);DataStreamSource<String> source = env.addSource(consumer);// 记得设置并行度env.setParallelism(1);source.map(new RichMapFunction<String, String>() {ComboPooledDataSource pool = null;QueryRunner queryRunner = null;// 定义一个Cache// 第一个是传入的参数类型 第二个是存放的值的类型// 也就是,传入一个参数,根据这个值获取结果,拿的时候通过传入的值 拿存放的值LoadingCache<String, String> cache;@Overridepublic void open(Configuration parameters) throws Exception {pool = new ComboPooledDataSource();queryRunner = new QueryRunner(pool);cache = CacheBuilder.newBuilder()//最多缓存个数,超过了就根据最近最少使用算法来移除缓存 LRU.maximumSize(1000)//在更新后的指定时间后就回收// 不会自动调用,而是当过期后,又用到了过期的key值数据才会触发的。.expireAfterWrite(50, TimeUnit.SECONDS)//指定移除通知.removalListener(new RemovalListener<String, String>() {@Overridepublic void onRemoval(RemovalNotification<String, String> removalNotification) {System.out.println(removalNotification.getKey() + "被移除了,值为:" + removalNotification.getValue());}}).build(//指定加载缓存的逻辑new CacheLoader<String, String>() {// 假如缓存中没有数据,会触发该方法的执行,并将结果自动保存到缓存中@Overridepublic String load(String cityId) throws Exception {String sql = "select city_name from city where city_id = ? ";Map<String, Object> rs = queryRunner.query(sql, new MapHandler(), cityId);String cityName = null;if (rs!=null){cityName = (String) rs.get("city_name");}System.out.println("进入数据库查询成功,查询的值为"+cityId+"--"+cityName);return cityName;}});}@Overridepublic void close() throws Exception {pool.close();}@Overridepublic String map(String line) throws Exception {String[] arr = line.split(",");// 使用这种方式取值String cityName = cache.get(arr[1]);return line+","+cityName;}}).print();env.execute();}
}相关文章:
—— 重试机制和维表join)
flink学习(13)—— 重试机制和维表join
重试机制 当任务出现异常的时候,会直接停止任务——解决方式,重试机制 1、设置checkpoint后,会给任务一个重启策略——无限重启 2、可以手动设置任务的重启策略 代码设置 //开启checkpoint后,默认是无限重启,可以…...

第三方Cookie的消亡与Google服务器端标记的崛起
随着互联网用户对隐私保护的关注日益增强,各大浏览器正在逐步淘汰第三方Cookie。这一变革深刻影响了广告商和数字营销人员的用户跟踪和数据分析方式。然而,Google推出的服务器端标记技术为这一挑战提供了新的解决方案。 什么是第三方Cookie? …...

微信小程序——文档下载功能分享(含代码)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

Burp Suite 全面解析:开启你的 Web 安全测试之旅
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...
)
Oracle DataGuard 主备正常切换 (Switchover)
前言 众所周知,DataGuard 的切换分为两种情况: 系统正常情况下的切换:这种方式称为 switchover,是无损切换,不会丢失数据。灾难情况下的切换:这种情况下一般主库已经启动不起来了,称为 failov…...

为什么编程语言会设计不可变的对象?字符串不可变?NSString *s = @“hello“变量s是不可变的吗?Rust内部可变性的意义?
为什么编程语言会设计不可变的对象? Java和C#中String是不可变的,StringBuilder是可变的。Obj-C中NSArray是不可变数组,NSMutableArray是可变数组。编程语言设计不可变的对象其实是为了优化(更高性能和节省存储空间)、安全(包括线程安全)。 字符串不可变…...

安装 RabbitMQ 服务
安装 RabbitMQ 服务 一. RabbitMQ 需要依赖 Erlang/OTP 环境 (1) 先去 RabbitMQ 官网,查看 RabbitMQ 需要的 Erlang 支持:https://www.rabbitmq.com/ 进入官网,在 Docs -> Install and Upgrade -> Erlang Version Requirements (2) …...

爬虫—Scrapy 整合 ChromeDriver 实现动态网页拉取
在进行爬虫开发时,使用 Scrapy 配合 ChromeDriver 来模拟真实浏览器加载 JavaScript 渲染内容是一种常见且高效的方法。Scrapy 本身是一个非常强大的爬虫框架,然而它默认使用的是 requests 库来抓取静态网页内容。对于需要通过 JavaScript 渲染的动态网页…...

Linux 进程管理详解
Linux 进程管理详解 引言 在现代操作系统中,进程是执行程序的基本单位。Linux作为一个强大的多任务操作系统,提供了丰富且灵活的机制来管理和控制进程。本文将详细介绍Linux进程管理的基本概念、核心机制以及常用的管理工具,帮助读者深入了…...

MySQL更新JSON字段key:value形式
MySQL更新JSON字段key:value形式 1. 介绍 MySQL的JSON数据类型是MySQL 5.7及以上版本中引入的一种数据类型,用于存储JSON格式的数据。使用JSON数据类型可以自动校验文档是否满足JSON格式的要求,优化存储格式,并允许快速访问文档中的特定…...

vue.js学习(day 18)
实例:面经基础版...

WINDOWS 单链表SLIST_ENTRY使用
1.初始化链表头 //初始化链表头qq1490900437 void InitialGloubleVar() {while (1){G_Handle.SaveProcessThreadHandle (PSLIST_HEADER)_aligned_malloc(sizeof(SLIST_HEADER), MEMORY_ALLOCATION_ALIGNMENT);if (G_Handle.SaveProcessThreadHandle ! NULL){break;}}Initiali…...

【Linux 篇】Docker 容器星河与镜像灯塔:Linux 系统下解锁应用部署奇幻征程
文章目录 【Linux 篇】Docker 容器星河与镜像灯塔:Linux 系统下解锁应用部署奇幻征程前言一 、docker上部署mysql1. 拉取mysql镜像2. 创建容器3. 远程登录mysql 二 、docker上部署nginx1. 拉取nginx镜像2. 在dockerTar目录下 上传nginx.tar rz命令3. 创建nginx容器4…...

不同云计算网络安全等级
导读云计算的本质是服务,如果不能将计算资源规模化/大范围的进行共享,如果不能真正以服务的形式提供,就根本算不上云计算。 等级保护定级流程 定级是开展网络安全等级保护工作的 “基本出发点”,虚拟化技术使得传统的网络边界变…...

手机实时提取SIM卡打电话的信令声音-蓝牙电话如何适配eSIM卡的手机
手机实时提取SIM卡打电话的信令声音 --蓝牙电话如何适配eSIM卡的手机 一、前言 蓝牙电话的海外战略中,由于海外智能手机市场中政策的差异性,对内置eSIM卡的手机进行支持是非常合理的需求。Android系列手机中,无论是更换通信运营商…...

视频流媒体服务解决方案之Liveweb视频汇聚平台
一,Liveweb视频汇聚平台简介: LiveWeb是深圳市好游科技有限公司开发的一套综合视频汇聚管理平台,可提供多协议(RTSP/RTMP/GB28181/海康Ehome/大华,海康SDK等)的视频设备接入,支持GB/T28181上下级联…...

【在Linux世界中追寻伟大的One Piece】多线程(三)
目录 1 -> Linux线程同步 1.1 -> 条件变量 1.2 -> 同步概念与竞态条件 1.3 -> 条件变量函数 1.4 -> 为什么pthread_cond_wait需要互斥量 1.5 -> 条件变量使用规范 2 -> 生产者消费者模型 2.1 -> 为什么要使用生产者消费者模型 2.2 -> 生产…...

mvc命令
命令 mvc MVC(Model-View-Controller)是一种软件架构模式,用于组织和管理应用程序的代码mvc重要的三部分 (1)模型(Model):负责存储系统的中心数据,提供访问数据的函数,封装了应用程序的功能内核。 (2)视图&…...
 - 错误处理)
17 go语言(golang) - 错误处理
错误处理 错误处理是编程中用于识别、响应和恢复程序运行时出现的错误和异常情况的过程。其目的是确保程序的鲁棒性(一个系统、模型或函数在面对错误输入、工作压力、意外情况或故意攻击时仍能保持稳定性和可靠性的能力),即使在出现错误的情…...

PG 库停库超时异常案例
文章目录 现象官方文档停库底层流程:恢复脚本优化思路总结 现象 停库超时 <2024-11-29 12:50:43.022 UTC 87472 192.167.60.1(54862) PostgreSQL JDBC Driver postgres stk>FATAL: terminating connection due to administrator command <2024-11-29 12:50:43.022 …...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
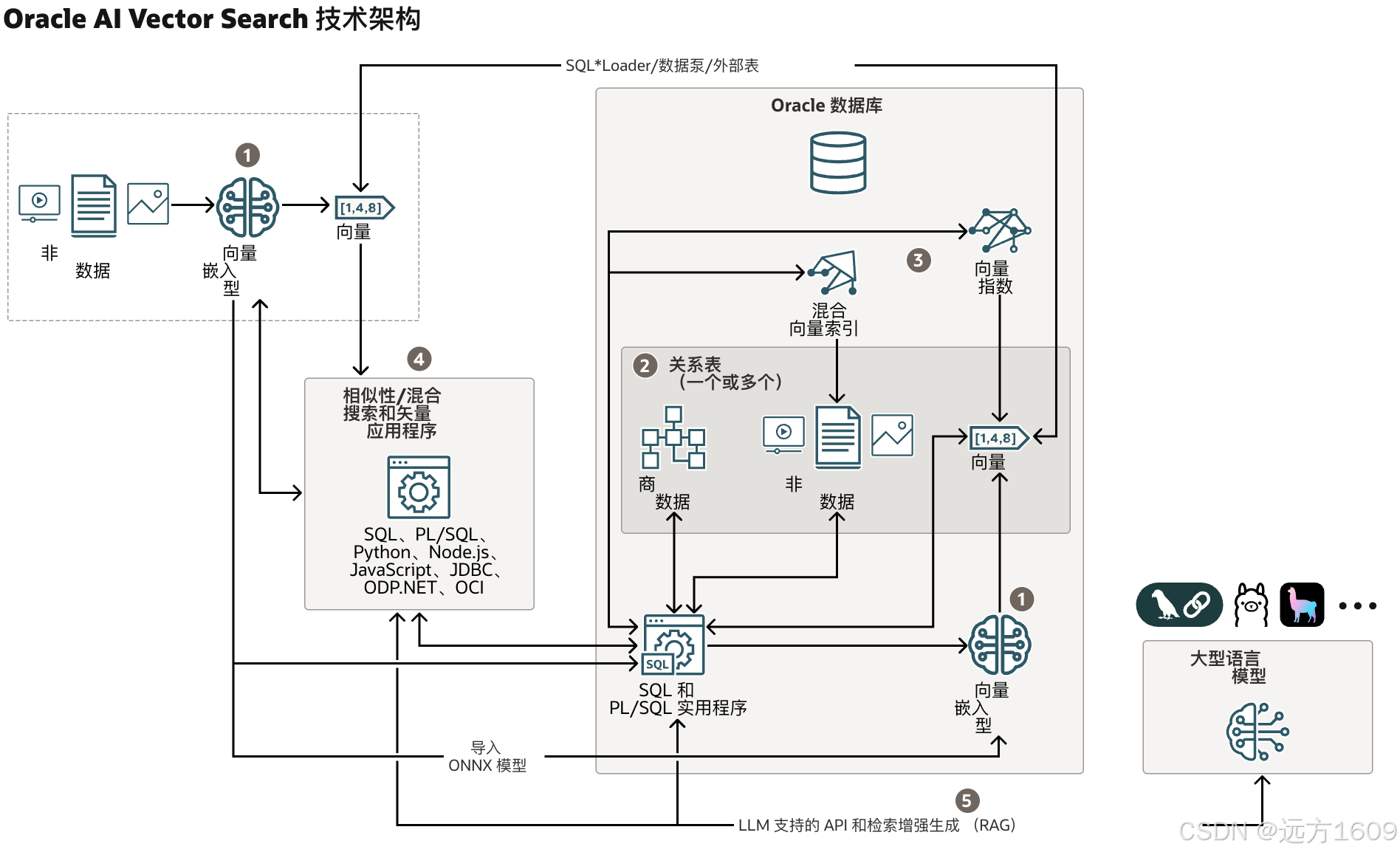
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...