Elasticsearch 的存储与查询
Elasticsearch 的存储与查询
在搜索系统领域,数据的存储与查询是两个最基础且至关重要的环节。Elasticsearch(ES) 在这两方面进行了深度优化,使其在关系型数据库或非关系型数据库中脱颖而出,成为搜索系统的首选。
映射 (Mapping)
- 映射 (Mapping)
- 映射是 ES 中的一种元数据,用于描述文档中的数据结构和类型。映射可以在创建索引时自动推断,也可以手动定义。映射包括字段名、字段类型、是否可搜索、是否可分析等属性。映射可以在文档级别和索引级别定义。
- ES 中是实现了动态映射的,在索引中写入下面的一个文档。
{"name":"jack","age":18,"birthDate": "1991-10-05"
}
-
在动态映射的作用下,name 会映射成 text 类型,age 会映射成 long 类型,birthDate 会被映射为 date 类型,自动判断的规则如下
-
JSON Type Field Type true, false boolean 123, 456, 876 long 123.43, 234.534 double String, “2022-05-15” date String: “Hello Elasticsearch” string 符合 IPv4 或 IPv6 地址格式 ip 字段的内容是 base64 编码的字符串 binary 字段的内容是一个数组,数组中的每个元素都将根据其内容被映射为相应的类型 array 字段的内容是一个 JSON 对象,那么它将被映射为 object 类型。对象中的每个属性都将根据其内容被映射为相应的类型 object 字段的内容是一个数组,且数组中的元素是对象,并且可以对内部对象进行精确查询 nested 字段的内容是经纬度对 geo_point 字段的内容是除点外的任意几何形状坐标 geo_shape
-
-
Mapping 的字段类型
- 字段类型是映射中的一种属性,用于描述文档中的字段数据类型。ES 支持多种字段类型,如文本、数值、日期、布尔值等。每种字段类型有其特点和限制,因此选择合适的字段类型对于优化查询性能和存储空间至关重要。
-
一级分类 二级分类 具体类型 核心类型 字符串类型 string,text,keyword整数类型 integer,long,short,byte 浮点类型 double,float,half_float,scaled_float 逻辑类型 boolean 日期类型 date 范围类型 range(Integer_range,long_range,date_range…) 二进制类型 binary (BASE64 的二进制) 复合类型 数组类型 array 对象类型 object 嵌套类型 nested 地理类型 地理坐标类型 geo_point 地理地图 geo_shape 特殊类型 IP 类型 ip … … …
-
字符串类型
text: ES 5x 后不再支持string, 由text和keyword类型替代- 子类型
text: 类型适用于需要被全文检索的字段match_only_text: 是text的空间优化变体,它禁用评分,它适合为日志消息建立索引
text类型的 常用参数analyzer: 指明该字段用于索引时和搜索时的分析字符串的分词器 (使用 search_analyzer 可覆盖它)。 默认为索引分析器或标准分词器search_analyzer: 在搜索时,用于分析该字段的分析器,默认是analyzer参数的值boost: 查询时字段匹配上时的权重级别,接受浮点数,默认为 1.0fields: 它允许同一个字符串值以多种方式进行索引以满足不同的目的index: 设置该字段是否可以用于搜索,默认为 trueeager_global_ordinals: 在刷新时急切地加载全局序数,对于经常用于term聚合的字段,启用此功能是个好主意 (但会影响写入速度)fielddata: 指明该字段是否可以使用内存中的fielddata进行排序,聚合或脚本编写?该字段可能会消耗大量的内存,如果要用的话建议keyword类型的字段使用similarity: 设置相关性排序公式,默认为 BM25
- 子类型
keyword- 子类型
keyword: 用于结构化过的内容,只能用于精准搜索,不会进行分词处理,常用户 ID、Email 等constant_keyword: 某个字段为 constant_keyword 类型,则该索引中,所有文档的该字段的值必须一致,常用于版本号wildcard: 这种类型主要用于非结构化的机器生成内容,对大数据量的字段做了优化,支持模糊匹配,常用于日志服务
keyword类型的 常用参数ignore_above: 当字段文本的长度大于指定值时,不会被索引,但是会存储其它参数: 同text
- 子类型
## fields 字段示例
{"properties": {"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart","similarity": "custom_similarity","doc_values": false,"fields": {"title_smart": {"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart","similarity": "custom_similarity","doc_values": false}}}}
}# 自定义排序算法
"similarity": {"custom_similarity": {"type": "BM25","b": 0.9,"k1": 1.2}
}
-
数字类型
-
Type Description long A signed 64-bit integer with a minimum value of -263 and a maximum value of 263-1. integer A signed 32-bit integer with a minimum value of -231 and a maximum value of 231-1. short A signed 16-bit integer with a minimum value of -32,768 and a maximum value of 32,767. byte A signed 8-bit integer with a minimum value of -128 and a maximum value of 127. double A double-precision 64-bit IEEE 754 floating point number, restricted to finite values. float A single-precision 32-bit IEEE 754 floating point number, restricted to finite values. half_float A half-precision 16-bit IEEE 754 floating point number, restricted to finite values. scaled_float A floating point number that is backed by a long, scaled by a fixed double scaling factor. unsigned_long An unsigned 64-bit integer with a minimum value of 0 and a maximum value of 264-1.
-
-
范围类型
integer_range和integer类型的区别在于,如果你的字段只包含一个整数值,你可以使用integer类型。如果你的字段包含一个整数范围,你可以使用integer_range类型-
Range Type Description integer_range A range of signed 32-bit integers with a minimum value of -231 and maximum of 231-1. float_range A range of single-precision 32-bit IEEE 754 floating point values. long_range A range of signed 64-bit integers with a minimum value of -263 and maximum of 263-1. double_range A range of double-precision 64-bit IEEE 754 floating point values. date_range A range of date values. Date ranges support various date formats through the format mapping parameter. Regardless of the format used, date values are parsed into an unsigned 64-bit integer representing milliseconds since the Unix epoch in UTC. Values containing the now date math expression are not supported. ip_range A range of ip values supporting either IPv4 or IPv6 (or mixed) addresses.
# integer 存储例子
{"name": "John","age": 25
}# integer_range 存储例子
{"name": "John","age": {"gte": 20,"lte": 30}
}# 若用 keyword 类型定义 my_field, 则范围查询会变成"字符串比较"而非"数值比较"
GET /keyword_test/_search
{"query": {"range": {"my_field": {"gte": 21,"lt": 32}}}
}"hits" : [{"_index" : "keyword_test","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"my_field" : "3"}}
]
- 对象类型
- 对象类型即一个 JSON 对象,JSON 字符串允许嵌套对象,所以一个文档可以嵌套多个多层对象。但 Lucene 没有内部对象的概念,会将 JSON 文档扁平化
# 插入这个的一个文档
PUT my-index-000001/_doc/1
{"region": "US","manager": {"age": 30,"name": {"first": "John","last": "Smith"}}
}# 实际上该文档会被存储成 key-value 对的形式
{"region": "US","manager.age": 30,"manager.name.first": "John","manager.name.last": "Smith"
}# 该文档会被动态的 mapping
{"mappings": {"properties": {"region": {"type": "keyword"},"manager": {"properties": {"age": { "type": "integer" },"name": {"properties": {"first": { "type": "text" },"last": { "type": "text" }}}}}}}
}# 在搜索时
{"query": {"bool": {"must": [{"match": {"manager.name.first": "John"}}]}}
}
- 嵌套类型
nested是一种特殊类型的object类型,它可以以数组对象的形式来进行索引,并且可以独立的查询其中的每一个对象
# ES 是没有内部对象的概念的,下述例子会动态的转化成一个"扁平化"的对象
{"group" : "fans","user" : [{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]
}# 类似下述的方式存储
{"group" : "fans","user.first" : [ "alice", "john" ],"user.last" : [ "smith", "white" ]
}# 执行下述 query 会得到不正确的结果,因为对象失去了层级结构
{"query": {"bool": {"must": [{ "match": { "user.first": "Alice" }},{ "match": { "user.last": "Smith" }}]}}
}# 以嵌套类型来定义字段
{"mappings": {"properties": {"user": {"type": "nested"}}}
}# 插入相同的 doc
{"group" : "fans","user" : [{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]
}# 以 nested 的方式进行检索,无结果返回
{"query": {"nested": {"path": "user","query": {"bool": {"must": [{ "match": { "user.first": "Alice" }},{ "match": { "user.last": "Smith" }}]}}}}
}# 在 ES 中,嵌套类型的字段会被转化成独立的文档,这些文档和主文档有相同的 id
- 向量类型
- 支持最大不超过 2048 维的向量,
dense_vector字段不支持查询、排序和聚合,只能接受 scripts 定义的函数
- 支持最大不超过 2048 维的向量,
# 定义向量类型和维度
{"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 768}}}
}# 定义相似度函数
{
"query": {"bool": {"must": {"function_score": {"functions": [{"script_score": {"script": {"source": "cosineSimilarity(params.queryVector, 'TitleVector') + 2.0","params": {"queryVector": query_embedding}}}}]}}}},
}
查询
- 分析器
- 被分析的字符串片段通过
analyzer来传递,将字符串转换为一串 terms(词条) 用于索引及检索 - 分析器
analyzer和分词器tokenizer并不相同,分析器不等于分词器,分词器只是分析器的一部分 - analyzer = [char_filter] + tokenizer + [token filter]
- char filter: 对输入字符进行预处理,如去除 HTML 标签,ES 内置字符处理器
- tokenizer: 对文本进行分词操作,如按照空格分词 (whitespace),标注分词器 (standard) 等,ES 内置分词器
- standard: Elasticsearch 默认的分词器,它会根据空格和标点符号将文本拆分为 term, 会过滤掉标点符号,大写转小写
- simple: 会根据非字母字符将文本拆分为 term, 过滤数字和标点符号,大写转小写
- whitespace: 根据空格字符将文本拆分为 term, 不会进行过滤和大小写转换
- keyword: 不会对文本进行拆分,常用于关键字字段或精确匹配字段
- filter (token filter): 对 token 集合的元素做过滤和转换,如统一转小写、过滤停用词等,token 经过 filter 处理之后的结果被定义为:term, ES 内置 token filter
- 被分析的字符串片段通过
POST _analyze
{"analyzer": "simple","text": ["HI 111 , 哈哈"]
}# 分词结果
{"tokens" : [{"token" : "hi","start_offset" : 0,"end_offset" : 2,"type" : "word","position" : 0},{"token" : "哈哈","start_offset" : 9,"end_offset" : 11,"type" : "word","position" : 1}]
}
- match 查询
- 支持全文搜索和精确查询,取决于字段是否支持全文检索
operator默认情况下该操作符是 or, 我们可以将它修改成 and 让所有指定词项都必须匹配minimum_should_match最小匹配参数,可以指定必须匹配的词项数 (或者百分数) 来表示一个文档是否相关
# 全文搜索
GET job_item_profile/_search
{"query": {"match": {"job_name": "java 工程师"}}
}# 精确查询
# 对于精确值的查询,可以使用 filter 语句来取代 query,因为 filter 将会被缓存
GET job_item_profile/_search
{"query": {"match": {"edu_level": "5000"}}
}# operator
GET job_item_profile/_search
{"query": {"match": {"job_name": {"query": "java 工程师","operator": "and"}}}
}# minimum_should_match
GET job_item_profile/_search
{"query": {"match": {"job_name": {"query": "java 工程师","minimum_should_match": "2"}}}
}
- multi_match 查询
- 多字段查询,可以给不同的字段指定不同的权重,返回匹配更高的结果
GET job_item_profile/_search
{"query": {"multi_match": {"query": "red","fields": ["job_name^2.0", "company_name^1.0"]}}
}
- range 查询
- 范围查询操作符:gt (大于), gte(大于等于), lt(小于), lte(小于等于)
GET job_item_profile/_search
{"query": {"range": {"salary_max": {"gt": 4,"lt": 8}}}
}
-
term 查询
- term 查询会去倒排索引中寻找确切的 term, 它并不会走分词器,只会去配倒排索引,若某个字段的
type是text, 若用 term 去查询有可能出现查询不到的情况 - term 查询也不会处理大小写,
type是text的字段会调用分词器进行大小写转换
- term 查询会去倒排索引中寻找确切的 term, 它并不会走分词器,只会去配倒排索引,若某个字段的
-
terms 查询
- terms 查询与 term 查询一样,但它允许你指定多值进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档就满足条件
GET job_item_profile/_search
{"query": {"terms": {"edu_level": [5000, 6000]}}
}
- match_phrase
- 短语查询/精确匹配,查询"java 专家"会匹配 job_name 字段包含"java 专家"短语的,而不会进行分词查询,也不会查询出"java 技术专家"这种词汇
GET job_item_profile/_search
{"query": {"match_phrase": {"job_name": "java 专家"}}
}
- 复合查询
- 使用 bool 语句实现复合查询,包括 must, must_not, should 和 filter
- must: 表示文档一定要包含查询的内容
- must_not: 表示文档一定不要包含查询的内容
- should: 表示如果文档匹配上可以增加文档相关性得分
- query DSL: 结构化查询,用于检查内容与条件是否匹配,内容查询中使用的 bool 和 match 语句,用于计算每个文档的匹配得分
- filter DSL: 结构化过滤,只是简单的决定文档是否匹配,内容过滤中使用的 term 和 range 语句,会过滤掉不匹配的文档,并且不影响计算文档匹配得分,使用过滤查询会被 ES 自动缓存用来提高效率
- 原则上来说,使用结构化查询语句做全文本搜索或其他需要进行相关性评分的情况,剩下的全部用过滤语句
实践
- 列表字段如何处理
- text
- 纯中文 逗号分隔,simple
- 纯英文,可能包含下划线,空格分隔,standard
- 纯数字,空格分隔,standard
- array, 通用方案,type=keyword, double. 注意,手动转小写。
- text
- IK 分析器的使用方式
- 网上很多文章会建议,建立索引的时候使用 ik_max_word 模式;搜索的时候使用 ik_smart 模式。但在实际应用中,我们会发现 ik_smart 的结果并不完全是 ik_max_word 结果的子集,这样会出现搜不出的情况 参考: IK分词器实现原理剖析 —— 一个小问题引发的思考
- 一种解决方法如下所示,对 title 字段分别以 ik_max_word 方式建立
title字段,再以 ik_smart 方式建立title_smart子字段;在用户搜索时统一使用 ik_smart 方式进行搜索,这样能保证相关的 query 一定能命中索引
{"properties": {"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart","similarity": "custom_similarity","doc_values": false,"fields": {"title_smart": {"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart","similarity": "custom_similarity","doc_values": false}}}}
}
相关文章:

Elasticsearch 的存储与查询
Elasticsearch 的存储与查询 在搜索系统领域,数据的存储与查询是两个最基础且至关重要的环节。Elasticsearch(ES) 在这两方面进行了深度优化,使其在关系型数据库或非关系型数据库中脱颖而出,成为搜索系统的首选。 映射 (Mapping) 映射 (Ma…...

008静态路由-特定主机路由
按照如上配置,用192.168.0.1 电脑ping 192.168.1.1 发现能够ping通 用192.168.0.1 电脑ping 192.168.2.1 发现不能ping通 这是因为192.168.0.1 和 192.168.1.1 使用的是同一个路由器R1。 192.168.0.1 和 192.168.2.1 通信需要先经过R1,再经过R2 …...

SystemUI 下拉框 Build 版本信息去掉
需求及场景 去掉SystemUI 下拉框 Build 版本信息 如下图所示:去掉 12 (SP1A.201812.016) 了解 去掉之前我们先了解它是个什么东西:其实就是一个Build RTM 信息显示 Android_12_build_SP1A.210812.016 修改文件 /frameworks/base/packages/Syste…...

【JS】栈内存、堆内存、事件机制区别、深拷贝、浅拷贝
js中,内存主要分为两种类型:栈内存(stack)、堆内存(heap),两种内存区域在存储和管理数据时有各自的特点和用途。 栈内存 访问顺序 栈是先进后出、后进先出的数据结构,栈内存是内存用…...

如何确保Java爬虫获得1688商品详情数据的准确性
在数字化商业时代,数据的价值日益凸显,尤其是对于电商平台而言。1688作为中国领先的B2B电子商务平台,提供了海量的商品数据接口,这些数据对于市场分析、库存管理、价格策略制定等商业活动至关重要。本文将详细介绍如何使用Java编写…...

【蓝牙通讯】iOS蓝牙开发基础介绍
1. iOS 蓝牙开发基础 在 iOS 中,蓝牙的操作主要是通过 Core Bluetooth 框架来实现。理解 Core Bluetooth 的基本组件和工作原理是学习 iOS 蓝牙开发的第一步。 核心知识点: Core Bluetooth 框架:这是 iOS 系统提供的专门用于蓝牙低功耗&am…...

Vue 90 ,Element 13 ,Vue + Element UI 中 el-switch 使用小细节解析,避免入坑(获取后端的数据类型自动转变)
目录 前言 在开发过程中,我们经常遇到一些看似简单的问题,但有时正是这些细节问题让我们头疼不已。今天,我就来和大家分享一个我在开发过程中遇到的 el-switch 使用的小坑,希望大家在使用时能够避免。 一. 问题背景 二. 问题分…...

echarts的双X轴,父级居中的相关配置
前言:折腾了一个星期,在最后一天中午,都快要放弃了,后来坚持下来,才有下面结果。 这个效果就相当是复合表头,第一行是子级,第二行是父级。 子级是奇数个时,父级label居中很简单&…...
)
RuoYi-Vue部署到Linux服务器(Jar+Nginx)
一、本地环境准备 源码下载、本地Jdk及Node.js环境安装,参考以下文章。 附:RuoYi-Vue下载与运行 二、服务器环境准备 1.安装Jdk 附:JDK8下载安装与配置环境变量(linux) 2.安装MySQL 附:MySQL8免安装版下载安装与配置(linux) 3.安装Redis 附:Redis下载安装与配置(…...

Linux firewalld常用命令
启动防火墙 systemctl start firewalld 停止防火墙 systemctl stop firewalld 防火墙开机自启动 systemctl enable firewalld 禁止防火墙开机自启动 systemctl disable firewalld 检查防火墙的状态 systemctl status firewalld 重新加载防火墙的配置 firewall-cmd -…...

Vue 组件之间的通信方式
Vue.js 中组件之间的通信是构建复杂应用的关键部分。以下是一些常见的Vue组件通信方式: 1. Props 和 Emit(父子组件通信) Props:父组件通过props向子组件传递数据。Emit:子组件通过emit触发事件,向父组件…...

el-select 修改样式
这样漂亮的页面,搭配的却是一个白色风格的下拉框 ,这也过于刺眼。。。 调整后样式为: 灯红酒绿总有人看着眼杂,但将风格统一终究是上上选择。下面来处理这个问题。 分为两部分。 第一部分:是修改触发框的样式 第二部…...

Java项目实战II基于微信小程序的亿家旺生鲜云订单零售系统的设计与实现(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、核心代码 五、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着移动互联网技术的不断…...
)
算法训练营day27(回溯算法03:组合总和,组合总和2,分割回文串)
第七章 回溯算法part03● 39. 组合总和 ● 40.组合总和II ● 131.分割回文串详细布置 39. 组合总和 本题是 集合里元素可以用无数次,那么和组合问题的差别 其实仅在于 startIndex上的控制题目链接/文章讲解:https://programmercarl.com/0039.%E7%BB%84%E…...

【青牛科技】D8331 流量计电路芯片,兼容 CTs,电阻分流器和罗氏线圈传感器
概述: D8331 系列超低功耗混合信号处理器由多种设备组成,具有针对电能表应用的不 同外围设备。它们集成了模拟前端和固定功能 DSP 解决方案与一个增强型 8052 单片 机核心,RTC 和 LCD 驱动程序集成在一个单一部件中。测量内核包括有功、无功…...

R语言森林生态系统结构、功能与稳定性分析与可视化实践高级应用
在生态学研究中,森林生态系统的结构、功能与稳定性是核心研究内容之一。这些方面不仅关系到森林动态变化和物种多样性,还直接影响森林提供的生态服务功能及其应对环境变化的能力。森林生态系统的结构主要包括物种组成、树种多样性、树木的空间分布与密度…...

【IntelliJ IDEA 中 Run Dashboard 不显示端口号问题解决办法】
IntelliJ IDEA 中 Run Dashboard 不显示端口号问题解决办法 解决 IntelliJ IDEA Run Dashboard 不显示端口号问题方法一:删除临时文件方法二:设置启动参数方法三:编辑 Run/Debug Configurations方法四:检查端口占用情况方法五&…...

idea中git的将A分支某次提交记录合并到B分支
一 实操案例 1.1 背景描述 在开发过程中,有时候需要将A分支某次提交记录功能合并到B分支上。主要原理用到git的cherry pick功能。 1.2 案例 实现的功能: master分支的11.24提交记录合并到feature_A分支; 1.master分支提交的记录 2.fea…...

华为关键词覆盖应用市场ASO优化覆盖技巧
在我国的消费者群体当中,华为的品牌形象较高,且产品质量过硬,因此用户基数也大。与此同时,随着影响力的增大,华为不断向外扩张,也逐渐成为了海外市场的香饽饽。作为开发者和运营者,我们要认识到…...

蓝桥杯第 23 场 小白入门赛
一、前言 好久没打蓝桥杯官网上的比赛了,回来感受一下,这难度区分度还是挺大的 二、题目总览 三、具体题目 3.1 1. 三体时间【算法赛】 思路 额...签到题 我的代码 // Problem: 1. 三体时间【算法赛】 // Contest: Lanqiao - 第 23 场 小白入门赛 …...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

0x-3-Oracle 23 ai-sqlcl 25.1 集成安装-配置和优化
是不是受够了安装了oracle database之后sqlplus的简陋,无法删除无法上下翻页的苦恼。 可以安装readline和rlwrap插件的话,配置.bahs_profile后也能解决上下翻页这些,但是很多生产环境无法安装rpm包。 oracle提供了sqlcl免费许可,…...
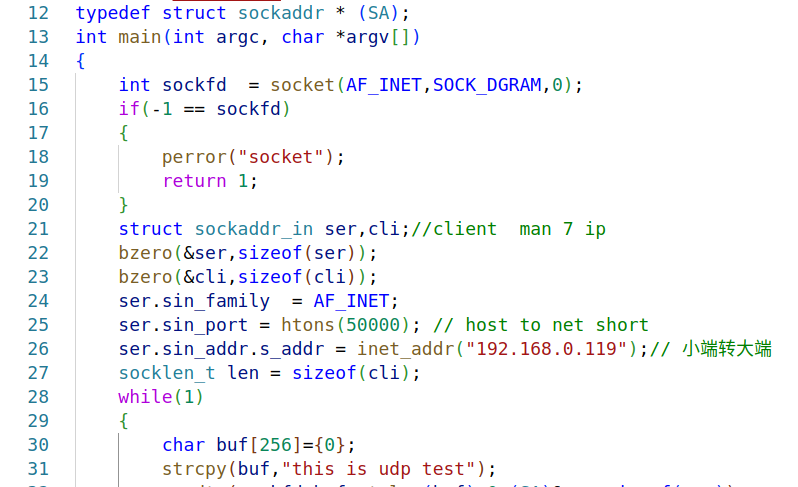
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...
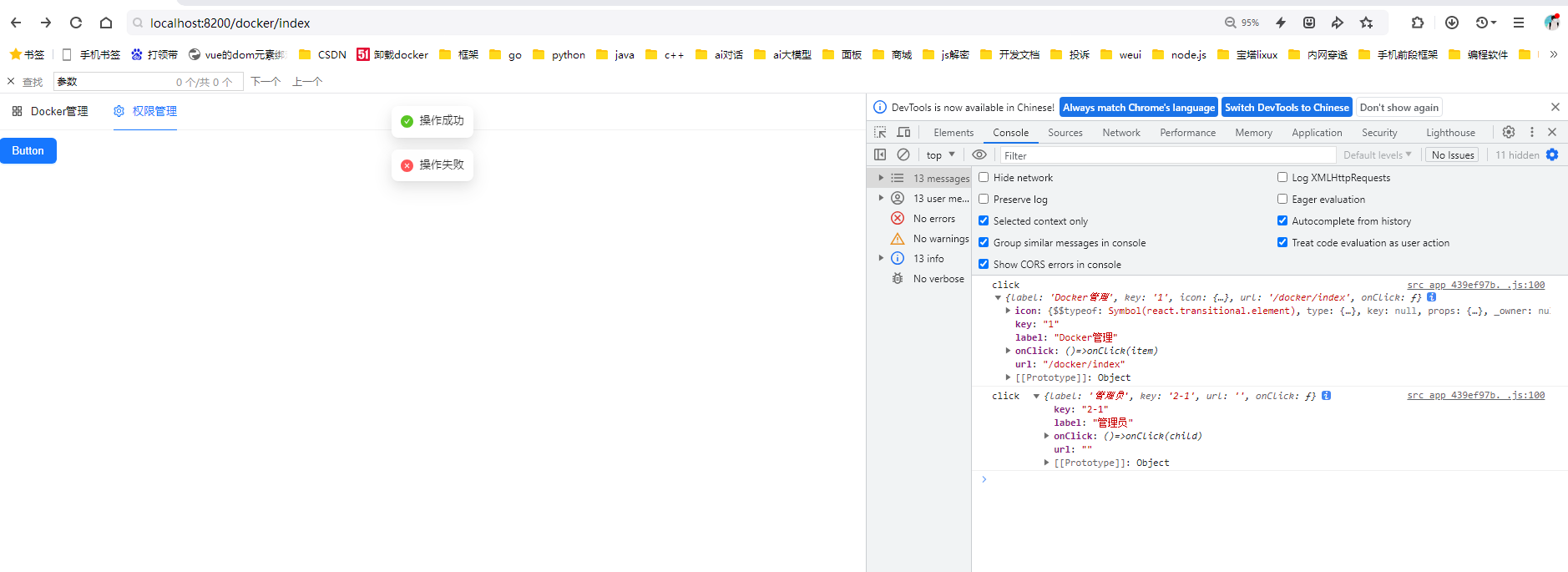
react菜单,动态绑定点击事件,菜单分离出去单独的js文件,Ant框架
1、菜单文件treeTop.js // 顶部菜单 import { AppstoreOutlined, SettingOutlined } from ant-design/icons; // 定义菜单项数据 const treeTop [{label: Docker管理,key: 1,icon: <AppstoreOutlined />,url:"/docker/index"},{label: 权限管理,key: 2,icon:…...

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...