Kylin Server V10 下基于Kraft模式搭建Kafka集群
一、Kraft 模式与 ZooKeeper 模式简介
在Kafka 2.8 之前,Kafka 重度依赖 ZooKeeper 集群做元数据管理、Controller 的选举等(统称为共识服务);当ZooKeeper 集群性能发生抖动时,Kafka 的性能也会受到很大的影响。如下图所示:

在 Kafka 2.8 之后,引入了基于 Raft 协议的 Kraft 模式,支持取消对 ZooKeeper 的依赖。在2022 年 10月 3日发布 Kafka 3.3.1 版本之后,将名为 KRaft 的新元数据管理方案标记为生产环境可用。
在此模式下,一部分 Kafka Broker 被指定为 Controller, 另一部分则为 Broker。这些 Controller 的作用就是以前由 ZooKeeper 提供的共识服务,并且所有的元数据都将存储在 Kafka 主题中并在内部进行管理。

Kraft 模式相比 ZooKeeper 模式的主要优势如下:
- 运维简化:只需要部署 Kafka, 不再依赖 ZooKeeper。
- 横向扩展能力提升:Kafka 集群能支持的 Partition 数量是衡量其横向扩展能力的重要指标。此前这个值受 ZooKeeper 与 Controller 之间传递元数据的限制,只能到十万量级,而 Kraft 模式不需要这种传递,因此可以提升到百万量级。
- 元数据传播提效:元数据通过 Kafka 的 Topic 管理,并利用 Topic 的生产消费传播,集成性更好的同时也提升了一些底层实现的性能。
二、基于 Kraft 模式的 Kafka 集群部署
1.主机规划
| 主机名 | IP 地址 | 角色 | node id |
| 10.8.3.35 | Broker,Controller | 0 | |
| 10.8.3.36 | Broker,Controller | 1 | |
| 10.8.3.37 | Broker,Controller | 2 |
2.部署
(1)编辑 10.8.3.35 上的server.properties 配置文件
[root@localhost kraft]# vi server.properties
| # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # This configuration file is intended for use in KRaft mode, where # Apache ZooKeeper is not present. # ########################### Server Basics ########################### # The role of this server. Setting this puts us in KRaft mode process.roles=broker,controller # The node id associated with this instance's roles node.id=1 # The connect string for the controller quorum controller.quorum.voters=1@10.8.3.35:9093,2@10.8.3.36:9093,3@10.8.3.37:9093 ########################Socket Server Settings ######################## # The address the socket server listens on. # Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum. # If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(), # with PLAINTEXT listener name, and port 9092. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://10.8.3.35:9092,CONTROLLER://10.8.3.35:9093 # Name of listener used for communication between brokers. inter.broker.listener.name=PLAINTEXT # Listener name, hostname and port the broker will advertise to clients. # If not set, it uses the value for "listeners". advertised.listeners=PLAINTEXT://10.8.3.35:9092 # A comma-separated list of the names of the listeners used by the controller. # If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol # This is required if running in KRaft mode. controller.listener.names=CONTROLLER # Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # The number of threads that the server uses for receiving requests from the network and sending responses to the network num.network.threads=3 # The number of threads that the server uses for processing requests, which may include disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics ########################### # A comma separated list of directories under which to store log files log.dirs=/usr/local/kafka/logs/kraft-combined-logs # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=1 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1 ######################## Internal Topic Settings ###################### # The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state" # For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3. offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 ########################### Log Flush Policy ######################### # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk #log.flush.interval |
相关文章:
Kylin Server V10 下基于Kraft模式搭建Kafka集群
一、Kraft 模式与 ZooKeeper 模式简介 在Kafka 2.8 之前,Kafka 重度依赖 ZooKeeper 集群做元数据管理、Controller 的选举等(统称为共识服务);当ZooKeeper 集群性能发生抖动时,Kafka 的性能也会受到很大的影响。如下图所示: 在 Kafka 2.8 之后,引入了基于 Raft …...

tauri使用github action打包编译多个平台arm架构和inter架构包踩坑记录
这些error的坑,肯定是很多人不想看到的,我的开源软件PakePlus是使用tauri开发的,PakePlus是一个界面化将任何网站打包为轻量级跨平台软件的程序,利用Tauri轻松构建轻量级多端桌面应用和多端手机应用,为了实现发布的时候…...
)
Python爬虫与窗口实现翻译小工具(仅限学习交流)
Python爬虫与窗口实现翻译小工具(仅限学习交流) 在工作中,遇到一个不懂的单词时,就会去网页找对应的翻译,我们可以用Python爬虫与窗口配合,制作一个简易的翻译小工具,不需要打开网页,自动把翻译结果显示出来。 整个过程比较简单。 # This is a sample Python script. …...

紫光展锐联合上汽海外发布量产车型,赋能汽车智能化
当前,智能汽车产业迎来重大变局,随着人工智能、5G、大数据等新一代信息技术的迅猛发展,智能网联汽车正呈现强劲发展势头。 11月26日,在2024紫光展锐全球合作伙伴大会汽车电子生态论坛上,紫光展锐与上汽海外出行联合发…...

Maven 打包出现问题解决方案
我执行 mvn install 报如下错误 可是我在 web 模块中能正确引用到 common 的类,于是我把 web 引用到的 common 中的类先移动到 web 模块中,然后把 common 模块的类都删掉,然后再次执行 mvn install,结果报错如下: [ERROR] Faile…...

第四话:JS中的eval函数
theme: channing-cyan 1.不要使用eval! 如果你从来都没有用到过eval这个函数,甚至你都不知道这个函数的作用。那么我只能说:你做了一件正确的事情 o.O 虽然我这篇文章要说一下eval函数的一些能力和注意点,但是我希望࿰…...

歇一歇,写写段子
无聊的日子都在写段子1.0 中学的时候喜欢看意林之类的杂志, 里面的作者用乱七八糟的理由跑去旅游,然后说“阻碍你脚步的永远只有逃离的勇气和对生活的热爱”, 我觉得太对了,可惜 12306 付款方式里没有勇气和热爱,不…...

TypeScript (一)运行环境配置,数据类型,可选类型,联合类型,type与interface,交叉类型,断言as,字面量类型,类型缩小
文章目录 一、认识TS1.1 JS 存在的问题1.2 TS的出现1.3 TS运行环境运行ts的三种方式 1.4 变量声明1.5 类型推断 二、数据类型2.1 JS数据类型(1) 数组Array(2) 对象Object(3) 其他类型 2.2 TS特有数据类型(1) any类型(2) unknown类型(3) void类型(4) never (了解)(5) tuple类型 …...

Linux Find 命令详情解释
文件查找 普通查询find /etc -maxdepth 1 -type f -name "pa*"命令 目录... 查找深度 类型 文件名称包含 # -type文件类型:f表示文件,不指定类型的话,文件和目录都会查找# -maxdepth查找深度:目录层级的意思࿰…...

2024年认证杯SPSSPRO杯数学建模A题(第一阶段)保暖纤维的保暖能力全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 A题 保暖纤维的保暖能力 原题再现: 冬装最重要的作用是保暖,也就是阻挡温暖的人体与寒冷环境之间的热量传递。人们在不同款式的棉衣中会填充保暖材料,从古已有之的棉花、羽绒到近年来各种各样的人造纤维。不…...
)
Milvus python库 pymilvus 常用操作详解之Collection(下)
上篇博客 Milvus python库 pymilvus 常用操作详解之Collection(上) 主要介绍了 pymilvus 库中Collection集合的相关概念以及创建过程的代码实现,现在我们要在该基础上实现对于collection中插入数据的混合检索(基于dense vector 和…...

李飞飞:Agent AI 多模态交互的前沿探索
发布于:2024 年 11 月 27 日 星期三 北京 #RAG #李飞飞 #Agent #多模态 #大模型 Agent AI在多模态交互方面展现出巨大潜力,通过整合各类技术,在游戏、机器人、医疗等领域广泛应用。如游戏中优化NPC行为,机器人领域实现多模态操作等。然而,其面临数据隐私、偏见、可解释性…...

[October 2019]Twice SQL Injection
有一个登录框和一个注册页面,题目也说这个是二次注入,那么就用二次注入的payload就行 1 union select database()# //爆库 1 union select group_concat(table_name) from information_schema.tables where table_schemactftraining# //爆表 1 union …...

Python爬虫——城市数据分析与市场潜能计算(Pandas库)
使用Python进行城市市场潜能分析 简介 本教程将指导您如何使用Python和Pandas库来处理城市数据,包括GDP、面积和城市间距离。我们将计算每个城市的市场潜能,这有助于了解各城市的经济影响力。 步骤 1: 准备环境 确保您的环境中安装了Python和以下库&…...

如何搭建JMeter分布式集群环境来进行性能测试
在性能测试中,当面对海量用户请求的压力测试时,单机模式的JMeter往往力不从心。如何通过分布式集群环境,充分发挥JMeter的性能测试能力?这正是许多测试工程师在面临高并发、海量数据时最关注的问题。那么,如何轻松搭建…...

【Halcon】 derivate_gauss
1、derivate_gauss Halcon中的derivate_gauss算子是一个功能强大的图像处理工具,它通过将图像与高斯函数的导数进行卷积,来计算各种图像特征。这些特征在图像分析、物体识别、图像增强等领域具有广泛的应用。 参数解释 Sigma:高斯函数的标准差,用于控制平滑的程度。Sigma…...

stm32中systick时钟pinlv和系统节拍频率有什么区别,二者有无影响?
在STM32中,SysTick时钟频率和系统节拍频率是两个不同的概念,它们之间存在区别,并且这种区别会对系统的运行产生一定的影响。以下是对这两个概念的详细解释以及它们之间关系的探讨: 一、SysTick时钟频率 定义:SysTick…...

柔性数组详解+代码展示
系列文章目录 🎈 🎈 我的CSDN主页:OTWOL的主页,欢迎!!!👋🏼👋🏼 🎉🎉我的C语言初阶合集:C语言初阶合集,希望能…...

前端入门指南:Webpack插件机制详解及应用实例
前言 在现代前端开发中,模块化和构建工具的使用变得越来越重要,而Webpack作为一款功能强大的模块打包工具,几乎成为了开发者的默认选择。Webpack不仅可以将各种资源(如JavaScript文件、CSS文件、图片等)打包成优化后的…...

C++备忘录模式
在读《大话设计模式》,在此记录有关C实现备忘录模式。 场景引入:游戏中的存档,比如打boss之前记录人物的血量等状态。 下面代码是自己根据理解实现的存档人物血量功能。 #include <iostream>using namespace std;//声明玩家类 class …...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...
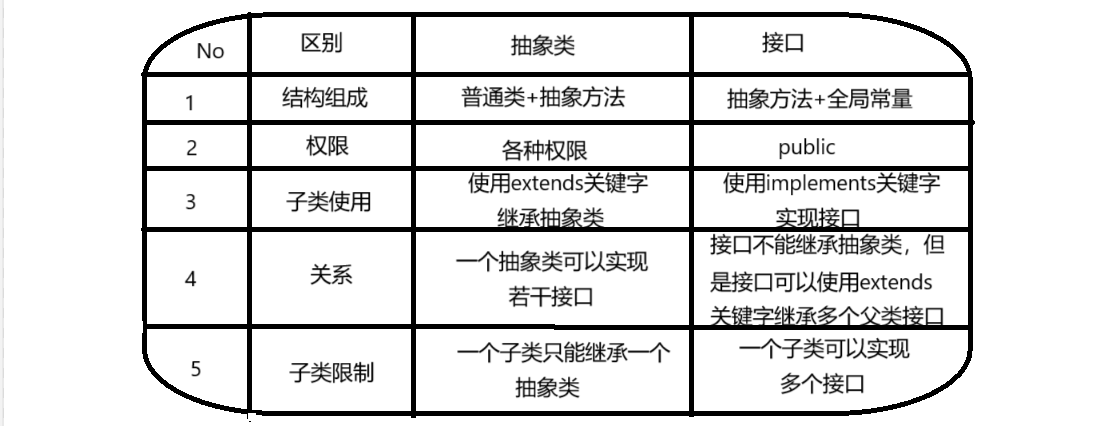
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...
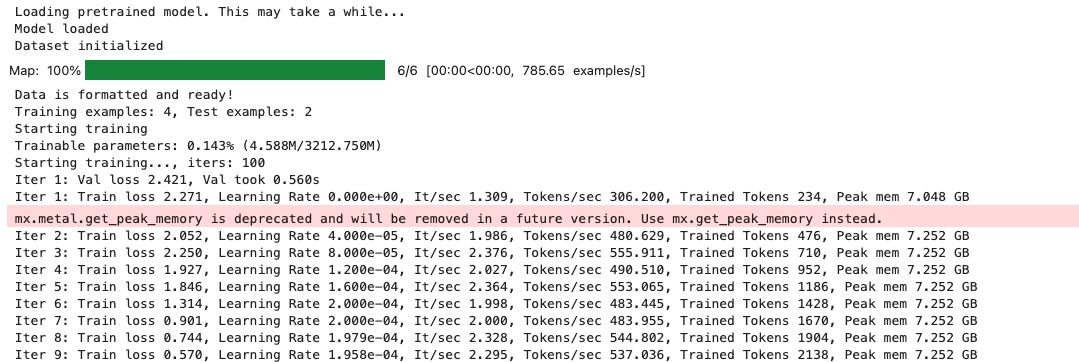
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...