Flink四大基石之State(状态) 的使用详解
目录
一、有状态计算与无状态计算
(一)概念差异
(二)应用场景
二、有状态计算中的状态分类
(一)托管状态(Managed State)与原生状态(Raw State)
两者的区别
具体区别
管理方式
数据结构支持
使用场景
(二)托管状态细分 Keyed State 和 Operator State
Keyed State(键控状态)
按键分区状态(Keyed State)分类
Operator State(算子状态)
列表状态(ListState)
联合列表状态(UnionListState)
广播状态(BroadcastState)
三、Keyed State 详解与代码实战
(一)数据格式
(二)代码示例:模拟 maxBy 求每个 key 的最大值
(三)代码示例 :体温异常监测统计输出
四、总结
在大数据流处理领域,Apache Flink 凭借其卓越的性能和丰富的功能备受青睐。而 Flink 中的状态(State)管理机制,更是支撑复杂流处理任务的关键支柱。无论是数据去重、模式匹配还是窗口聚合分析,状态管理都发挥着不可或缺的作用。本文将深入浅出地剖析 Flink 状态相关知识,结合实际代码案例助你理解这一重要概念。

一、有状态计算与无状态计算
(一)概念差异
无状态计算
无需考虑历史数据,具有幂等性,相同输入必然得到相同输出。例如 map 操作,输入单词 “hello” 就记为 (hello, 1),每次输入 “hello” 输出结果恒定。
有状态计算
要依据历史数据,相同输入可能因状态变化产生不同输出。像 sum、reduce、maxBy 等聚合操作,首次输入 (hello, 1) 得 (hello, 1),再输入 (hello, 1) 会更新状态输出 (hello, 2)。
(二)应用场景
无状态计算场景
适用于数据转换、过滤等基础操作,直接采用 map、filter 算子便捷高效。比如只想筛选出日志数据中特定级别的信息进行输出,用 filter 按日志级别规则过滤即可。
有状态计算场景
涉及聚合(求和、求最值等)、比较操作时,就得倚仗有状态算子。像统计电商平台各品类商品销售额,借助 sum 基于商品品类 key 聚合金额数据。
二、有状态计算中的状态分类
Flink状态
- 托管状态
- KeyedState ( 在keyBy之后可以使用状态 )
- ValueState (存储一个值)
- ListState (存储多个值)
- MapState (存储key-value)
- OperatorState ( 没有keyBy的情况下也可以使用 ) [不用]
- 原生状态 (不用)
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态(State),然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
- 数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
- 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
其实窗口本身就是状态,他不是立即出结果,而是将数据都保存起来,达到触发条件才计算。
一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。

以wordcout为例,说明上图的流程

(一)托管状态(Managed State)与原生状态(Raw State)
两者的区别
Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
具体区别
管理方式
- 托管状态:由 Flink Runtime 托管,自动存储、恢复,并行度调整时能自动重新分布状态,开发者无需操心底层存储细节,Flink 已做优化处理。
- 原生状态:开发者全程自主把控,要手动序列化,以字节数组存储,Flink 不了解存储的数据结构,管理成本高。
数据结构支持
- 托管状态:支持
ValueState(存单值)、ListState(存列表值)、MapState(存键值对)等多样结构,方便依业务逻辑选择适配。 - 原生状态:仅支持字节,上层复杂数据结构得自行序列化为字节数组再操作。
使用场景
- 托管状态:多数算子继承
Rich函数类等接口即可轻松使用,涵盖日常众多流处理任务。 - 原生状态:在现有算子与托管状态无法满足特殊、复杂自定义需求,比如自研特殊聚合逻辑算子时才会启用。
(二)托管状态细分 Keyed State 和 Operator State
Keyed State(键控状态)
Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
需要注意的是键控状态只能在 KeyedStream 上进行使用,可以通过 stream.keyBy(...) 来得到 KeyedStream 。

按键分区状态(Keyed State)分类
Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State)
- ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
- ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
- ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
- AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
- FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使用 AggregatingState 代替。
- MapState:维护 Map 类型的状态。
Operator State(算子状态)
引用:Flink中的状态管理_flink有状态和无状态-CSDN博客 三.算子状态(Operator State)
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。(每个算子子任务共享一个算子状态,子任务间不共享)
算子状态的实际应用场景不如Keyed State多,一般用在Source或Sink等与外部系统连接的算子上,一般使用不多。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间进行重组分配。根据状态类型的不同,重组分配的方案也会有所差异。
综上所述,算子状态是一种在特定算子上定义的状态,其作用范围仅限于该算子任务,且与数据的键值无关。相比之下,按键分区状态提供了更丰富的功能和操作,适用于处理与特定键值相关联的数据。在实际应用中,需要根据具体需求和场景选择合适的状态类型来管理数据和共享状态。
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState和BroadcastState。
列表状态(ListState)
与Keyed State中的ListState一样,将状态表示为一组数据的列表。
与Keyed State中的列表状态的区别是,在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的状态列表将会被全部收集收集起来,再通过轮询的方式重新依次分配给新的所有并行任务。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
联合列表状态(UnionListState)
与ListState类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
在并行度进行缩放调整时,联合列表与普通列表不同,联合列表会将所有并行子任务的列表状态收集起来,并直接向所有并行子任务广播完整的列表。如果列表中状态项太多则不推荐使用联合里欸包状态。
使用上也与ListState类似,只需要在实现CheckpointedFunction类的initializeState方法时,通过上下文获取算子状态使用 .getUnionListState() 即可,其他与ListState无异。
广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
在并行度进行缩放操作时,由于是全局状态,也不会造成影响。
简单来说,就是一条流广播后专门读取配置,与普通的数据流进行连结,然后广播流将配置加载到广播状态中,这样普通的数据流就能够在不重启程序的情况下通过上下文动态读取配置。
三、Keyed State 详解与代码实战
(一)数据格式
Flink 为 Keyed State 提供多种实用数据格式:
- ValueState:存储单个值,用
update(T)更新,T value()检索取值,常用于保存当前最值、计数等单一数据指标。 - ListState:能存多个值,通过
add(T)、addAll(List)添加元素,get()获取完整列表,适合缓存历史数据序列,如记录用户近期操作记录列表。 - ReducingState:基于
ReduceFunction计算结果存储,add(T)增添元素,持续归约数据。 - AggregatingState:存放
AggregatingState计算结果,按自定义聚合逻辑add(IN)处理输入更新状态,满足复杂聚合求值。 - MapState:维护
Map类型状态,灵活处理键值对形式数据存储与操作。
(二)代码示例:模拟 maxBy 求每个 key 的最大值
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class _01_KeyedStateDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<Tuple2<String, Long>> tupleDS = env.fromElements(Tuple2.of("北京", 1L),Tuple2.of("上海", 2L),Tuple2.of("北京", 6L),Tuple2.of("上海", 8L),Tuple2.of("北京", 3L),Tuple2.of("上海", 4L),Tuple2.of("北京", 7L));//2. source-加载数据tupleDS.keyBy(new KeySelector<Tuple2<String, Long>, String>() {@Overridepublic String getKey(Tuple2<String, Long> value) throws Exception {return value.f0;}}).map(new RichMapFunction<Tuple2<String, Long>, Tuple2<String,Long>>() {// 借助状态这个API实现ValueState<Long> maxValueState= null;@Overridepublic void open(Configuration parameters) throws Exception {// 就是对ValueState初始化ValueStateDescriptor<Long> stateDescriptor = new ValueStateDescriptor<Long>("valueState",Long.class);maxValueState = getRuntimeContext().getState(stateDescriptor);}@Overridepublic Tuple2<String, Long> map(Tuple2<String, Long> value) throws Exception {Long val = value.f1;if(maxValueState.value() == null){maxValueState.update(val);}else{if(maxValueState.value() < val){maxValueState.update(val);}}return Tuple2.of(value.f0,maxValueState.value());}}).print();//.maxBy(1).print();//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
} 在此代码中,先构建 Flink 执行环境、加载数据,按城市 keyBy 后,在 map 里利用 ValueState。open 方法初始化状态,map 里对比输入值与状态存储的最大值,按需更新并输出对应城市及最大值,清晰展示 Keyed State 求最值用法。
通过Map计算最大值的案例

完整代码
package com.bigdata.state;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.HashMap;
import java.util.Map;public class _01_KeyedStateDemo_MapTest {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<Tuple2<String, Long>> tupleDS = env.fromElements(Tuple2.of("北京", 1L),Tuple2.of("上海", 2L),Tuple2.of("北京", 6L),Tuple2.of("上海", 8L),Tuple2.of("北京", 3L),Tuple2.of("上海", 4L),Tuple2.of("北京", 7L));//2. source-加载数据tupleDS.keyBy(new KeySelector<Tuple2<String, Long>, String>() {@Overridepublic String getKey(Tuple2<String, Long> value) throws Exception {return value.f0;}}).map(new RichMapFunction<Tuple2<String, Long>, Tuple2<String,Long>>() {// 借助状态这个API实现Map<String,Long> map = new HashMap<String,Long>();@Overridepublic Tuple2<String, Long> map(Tuple2<String, Long> value) throws Exception {Long val = value.f1;if(!map.containsKey(value.f0)){map.put(value.f0,value.f1);}else{Long mapValue = map.get(value.f0);if(mapValue < val){map.put(value.f0,value.f1);}}return Tuple2.of(value.f0,map.get(value.f0));}}).print();//.maxBy(1).print();//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}(三)代码示例 :体温异常监测统计输出
package com.bigdata.state;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.planner.expressions.In;
import org.apache.flink.util.Collector;import java.util.ArrayList;public class _02_KeyedStateDemo2 {// 如果一个人的体温超过阈值38度,超过3次及以上,则输出: 姓名 [温度1,温度2,温度3]public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8889);//3. transformation-数据处理转换 zs,37dataStreamSource.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String[] arr = value.split(",");return Tuple2.of(arr[0],Integer.valueOf(arr[1]));}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}}).flatMap(new RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, ArrayList<Integer>>>() {ValueState<Integer> valueState = null;ListState<Integer> listState = null;@Overridepublic void open(Configuration parameters) throws Exception {ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<Integer>("numState",Integer.class);valueState = getRuntimeContext().getState(stateDescriptor);ListStateDescriptor<Integer> listStateDescriptor = new ListStateDescriptor<>("listState", Integer.class);listState = getRuntimeContext().getListState(listStateDescriptor);}@Overridepublic void flatMap(Tuple2<String, Integer> value, Collector<Tuple2<String, ArrayList<Integer>>> out) throws Exception {Integer tiwen = value.f1;if(tiwen >= 38){valueState.update(valueState.value()==null?1:(valueState.value()+1));listState.add(tiwen);}if(valueState.value()!=null && valueState.value() >= 3){ArrayList<Integer> list = new ArrayList<>();Iterable<Integer> iterable = listState.get();for (Integer tiwenwen : iterable) {list.add(tiwenwen);}out.collect(Tuple2.of(value.f0,list));}}}).print();//4. sink-数据输出//5. execute-执行env.execute();}
} 这段代码从本地 socket 读取姓名与体温数据,转换格式后按姓名 keyBy。在 flatMap 里,用 ValueState 统计体温超 38 度次数,ListState 缓存超温数据,次数达标则输出对应姓名及体温列表,巧妙实现复杂业务规则监测。
四、总结
Flink 状态管理是构建强大流处理应用的基石,合理运用有状态、无状态计算,精准抉择托管状态类型及对应数据格式,结合实战代码灵活处理业务逻辑,能解锁 Flink 在大数据场景无限潜能,高效应对各类数据处理挑战,助你在大数据开发之路上稳步前行。后续可深入探索状态持久化、故障恢复等进阶特性,深挖 Flink 流处理精髓。
相关文章:
Flink四大基石之State(状态) 的使用详解
目录 一、有状态计算与无状态计算 (一)概念差异 (二)应用场景 二、有状态计算中的状态分类 (一)托管状态(Managed State)与原生状态(Raw State) 两者的…...

Linux中dos2unix详解
dos2unix 是一个用于将文本文件从DOS/Windows格式转换为Unix/Linux格式的工具。在不同的操作系统中,文本文件中的换行符表示方式是不一样的。具体来说: 在DOS和Windows系统中,换行由两个字符组成:回车(Carriage Retur…...

MySQL MVCC 介绍
MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。MVCC通过在每个数据行上维护多个版本的数据来实现。当一个事务要对数据库中的数据进行修改时,MVCC不会…...

Linux篇之日志管理工具Logrotate介绍并结合crontab使用
1. Logrotate介绍 logrotate 是一个用于管理和轮换日志文件的工具,通常用于 Unix 和 Linux 系统。它可以自动化日志文件的轮换、压缩、删除和邮寄等操作,确保日志文件不会无限制地增长,占用过多的磁盘空间。 2. 主要功能 轮换:定期将日志文件移动到备份目录,并生成新的…...

Vulnhub靶场 Matrix-Breakout: 2 Morpheus 练习
目录 0x00 准备0x01 主机信息收集0x02 站点信息收集0x03 漏洞查找与利用1. 文件上传2. 提权 0x04 总结 0x00 准备 下载连接:https://download.vulnhub.com/matrix-breakout/matrix-breakout-2-morpheus.ova 介绍: This is the second in the Matrix-Br…...

秒杀项目 超卖问题 详解
秒杀项目中的超卖问题详解 秒杀场景是一种高并发场景,用户在短时间内大量涌入抢购有限的商品。超卖问题指的是由于系统设计不合理,导致实际售出的商品数量超过库存数量。 1. 为什么会出现超卖问题? 超卖问题通常由以下原因引发:…...

Linux系统编程之进程控制
概述 在Linux系统中,创建一个新的进程后,如何对该进程进行有效的控制,是一项非常重要的操作。控制进程状态的操作主要包括:进程的执行、进程的等待、进程的终止等。下面,我们将逐个进行介绍。 进程的执行 创建进程后&a…...

集合的相关性质与定义
集合 集合 集合描述了一组对象的集合,而映射描述了集合之间的对应关系。 集合 集合是由一组无序的,互不相同的对象组成的整体,集合中的对象称为元素或成员。集合可以用大括号{}表示,元素之间用逗号进行分隔。 定义: 集合 A …...

pytest自定义命令行参数
实际使用场景:pytest运行用例的时候,启动mitmdump进程试试抓包,pytest命令行启动的时候,传入mitmdump需要的参数(1)抓包生成的文件地址 (2)mitm的proxy设置 # 在pytest的固定文件中…...

c++预编译头文件
文章目录 c预编译头文件1.使用g编译预编译头文件2.使用visual studio进行预编译头文件2.1visual studio如何设置输出预处理文件(.i文件)2.2visual studio 如何设置预编译(初始创建空项目的情况下)2.3 visual studio打开输出编译时…...

YOLOv8模型pytorch格式转为onnx格式
一、YOLOv8的Pytorch网络结构 model DetectionModel((model): Sequential((0): Conv((conv): Conv2d(3, 64, kernel_size(3, 3), stride(2, 2), padding(1, 1))(act): SiLU(inplaceTrue))(1): Conv((conv): Conv2d(64, 128, kernel_size(3, 3), stride(2, 2), padding(1, 1))(a…...

电子课程开发中的典型误区
创建一个有效的电子课程需要仔细的规划和执行,但常见的错误可能会破坏其成功。以下是开发人员应该避免的一些典型陷阱: 1.缺乏明确的目标 如果没有明确的学习目标,课程可能会缺乏重点,让学习者不确定自己应该实现什么。明确、可衡…...

Docker 逃逸突破边界
免责声明 本博客文章仅供教育和研究目的使用。本文中提到的所有信息和技术均基于公开来源和合法获取的知识。本文不鼓励或支持任何非法活动,包括但不限于未经授权访问计算机系统、网络或数据。 作者对于读者使用本文中的信息所导致的任何直接或间接后果不承担任何…...

残差连接,就是当某一偏导等于0时,加上x偏导就是1,这样乘以1保证不失效
目录 残差连接,就是当某一偏导等于0时,加上x偏导就是1,这样乘以1保证不失效 残差连接中F(x)一般代表什么,将F(x)变为F(x) +x,这样不是改变了函数 本身的性质 F(x)=F(x) +x F(x)偏导若==0;偏导连乘就是0,这样就梯度消失了 F(x) +x;求偏导时x导数是1,保证不丢失F(x)…...

博泽Brose EDI项目案例
Brose 是一家德国的全球性汽车零部件供应商,主要为全球汽车制造商提供机电一体化系统和组件,涵盖车门、座椅调节系统、空调系统以及电动驱动装置等。Brose 以其高质量的创新产品闻名,在全球拥有多个研发和生产基地,是全球第五大家…...

从科举到高考,人才选拔制度的变革与发展
一、引言 在人类历史的长河中,人才选拔机制始终是推动社会进步与文明传承的关键环节。古代科举制度与现代高考制度,分别在各自的时代背景下承担着筛选人才的重任,二者虽皆关乎教育与人才进阶之路,却有着诸多本质性的区别与独特的…...

利用Docker一键发布Nginx-Tomcat-MySQL应用集群
Docker简介,可以看上一篇文章: 为什么互联网公司离不开Docker容器化,它到底解决了什么问题?-CSDN博客 Docker体系结构 docker核心就是镜像和容器: 镜像就是应用程序的安装文件,包含了所有需要的资源&…...
关于数据库数据国际化方案
方案一:每个表设计一个翻译表 数据库国际化的应用场景用到的比较少,主要用于对数据库的具体数据进行翻译,在需要有大量数据翻译的场景下使用,举个例子来说,力扣题目的中英文切换。参考方案可见: https://b…...

【系统架构设计师】高分论文:论信息系统的安全与保密设计
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 摘要正文摘要 本人所在工作单位承担了我市城乡智慧建设工程综合管理平台项目的开发工作。我有幸参与了本项目,并担任架构师一职,全面负责项目的需求分析和系统设计等工作。城乡智慧建设工程综合管理平台项目包括…...

使用Tauri创建桌面应用
当前是在 Windows 环境下 1.准备 系统依赖项 Microsoft C 构建工具WebView2 (Windows10 v1803 以上版本不用下载,已经默认安装了) 下载安装 Rust下载安装 Rust 需要重启终端或者系统 重新打开cmd,键入rustc --version,出现 rust 版本号&…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...
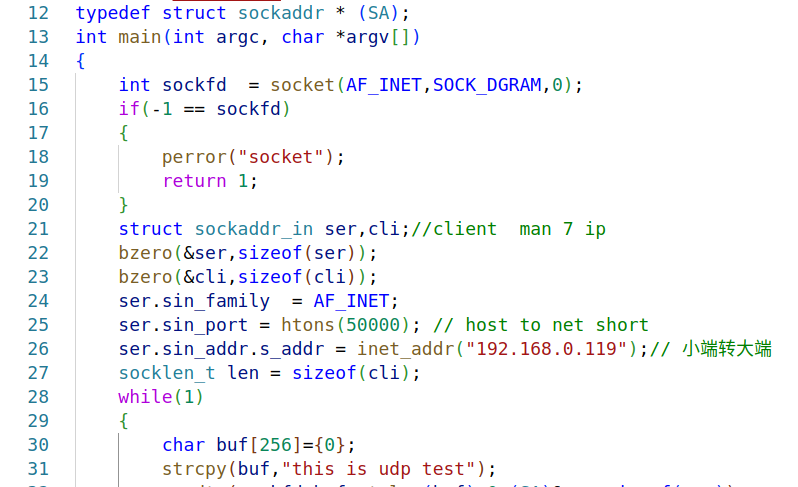
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...