2020年国赛高教杯数学建模E题校园供水系统智能管理解题全过程文档及程序
2020年国赛高教杯数学建模
E题 校园供水系统智能管理
原题再现
校园供水系统是校园公用设施的重要组成部分,学校为了保障校园供水系统的正常运行需要投入大量的人力、物力和财力。随着科学技术的发展,校园内已经普遍使用了智能水表,从而可以获得大量的实时供水系统运行数据。后勤部门希望基于这些数据,通过数学建模和数据挖掘及时发现和解决供水系统中存在的问题,提高校园服务和管理水平。
附件是某校区水表层级关系以及所有水表四个季度的读数(以一定时间为间隔,如15分钟)与相应的用水数据。请利用这些信息和数据,建立数学模型,讨论以下问题:
1. 统计、分析各个水表数据的变化规律,并给出校园内不同功能区(宿舍、教学楼、办公楼、食堂等)的用水特征。
2. 结合校区水表层级关系,建立水表数据之间的关系模型,并利用已有数据分析模型误差。
3. 输水管网的漏损是一个严重问题。资料显示,在维护良好的公共供水网络中,平均失水在5%左右;而在比较老旧的管网中,失水则会更多。请利用附件提供的数据,建立数学模型,分析该校园供水管网的漏损情况。
4. 地下水管暗漏不容易被发现,需要花费大量人力对供水管道的漏损进行检测及定位,如果能够从水表的实时数据及时发现并确定发生漏损的位置,将极为有益。请帮助学校解决这个问题。
5. 管网维修需要一定的人工费和材料费,但同时可以降低管网漏损程度。请根据以上结果和你了解的水价及维修成本确定管网漏损的最优维修决策方案。
整体求解过程概述(摘要)
智能水表的使用伴随着人工智能与科技的发展,变得越来越广泛,它的使用极大的方便了管理人员对用水情况的管理,它产生的数据也可以帮助其进行合理的数据估计,从而合理规划维修,本文基于某校园智能水表产生的数据,进行了挖掘和分析,具体如下:
对问题一,首先借助Python中的pandas库对大规模、多种数据类型共存数据处理的优势进行数据的操作和处理,描述分析了宿舍、教学楼、办公楼、食堂的用水特征:
对问题二,在问题一的基础上,首先利用水表层级关系附件,建立各级表的数据关系拓扑图,结合实际情况分析得出,一级水表中 401X、403X、405X 处的数据与二级水表相比误差率分别为 11%、11%、4%: 其他一级水表按照优质水表+0.5%-+3%:二级以上水表按照普通水表-5%-3%来标记误差;
对于问题三,首先利用时间点左右各5个点对其本身进行样条插值平滑预测,利用预测值与原始值的差值估计漏损量,总漏损量为 32215,总漏损率为9.8%,该校园漏损率低于全国的平均漏损率,此外还分析评估了各水表漏损情况;
对于问题四,根据上一问的估计结果,以 9.8%为闽值,漏损率超出闽值则标记一次漏损事故,结合各水表处的漏水量情况,按照漏损次数对水表进行漏损等级评定,得到40118T/40121T/40331T 等水表点的漏水可能性较高:
对于问题五,通过查看相关文献资料,获得平均水价范围5.5元/吨-6.5元/吨,单次维修费用500元/次-1500元/次,建立了每天是否维修的0-1规划模型,并取平均水价6元/吨以及单次维修成本均价1000元/次分析维修次数、损失金额与水价和维修成本的关系,最终的漏水维修33 次,总损失金额为 174630 元。
本文由数据驱动,建立模型挖掘校园用水的特性,对于供热网、高速路网等问题都具有良好的推广应用价值。
模型假设:
1.假设一级水表采用测量精度较高的电磁水表:
2.假设二级至四级采用均已广泛使用机械速度式水表,并有 2%-5%的相对误差
3.无人蓄意破坏供水管道:
4.各水表工作在理想状态下,不受强磁等外界因素干扰;
5.水质良好,无明显杂质,不对机械速度式水表产生过大影响:
问题分析:
问题一分析
问题需要根据已有季度用水表(附件)、水表层次(附件)的数据分析宿舍、教学楼、办公楼、食堂的用水情况特性。为此需要有以下几个分析步骤。
1. 对数据进行描述性统计,获得缺失值、异常值,以及校园用水的总体特征。
2. 需要对数据进行缺失值、异常值的处理,并对水表进行功能区划分,建立用水情况的水表层级关系表。
3. 对宿舍功能区、教学楼功能区、办公楼功能区、食堂功能区进行用水分析。
问题二分析
问题需要根据附件中提供的水表层级关系,建立不同层级间水表的关系模型,利用已知数据分析模型误差。
水表的合理使用:
由资料可知电磁水表的误差率较小,而机械速度式水表可检测的最小水流量与管道直径成正比,在直径较大的骨干管道中,采用机械速度式水表难以检测弱水流,误差较大,因此:
1一级水表采用精度更高的电磁水表;
2二级至四级均采用已广泛使用的机械速度式水表,
我们采用拓扑图将水表间的层级关系可视化;
计算上级水表表显读数和下属水表表显读数之和的差值,将误差分为三类;一级水表误差按电磁水表统计, 二级至四级水表按照机械速度式水表统计,二级水表按照实际误差来计算,利用其表显数据与一级表数据做差得出误差;
问题三分析
问题需要根据各级水表的显示数据分析出校园水网的具体漏损情况,文献2采用时间序列神经网络 (NAR神经网络) 的预测方法,基于当前各水表读数时间序列,对每个读数进行预测,表显读数与预测值波动超过一定闯值的则视为该时刻发生漏水,为解决本问题提供了思路,但是根据附件的数据,各水表的年用水情况各不相同,如若进行时间序列分析,需分水表、分时间段进行稳定性、白噪声以及参数预置的讨论,所有情况过于繁琐复杂,本问题并不合适。
有鉴于此,我们参考其预测方法,对时间序列 t 时刻的值进行样条插值平滑预测,从而进行漏损估计,具体的步骤如下:
1.首先对数据进行预处理工作。对一级水表按照超过一定误差的阙值的异常数据进行置均值的平滑处理:
2.其次对一级水表的时间序列数据进行样条插值平滑预测:
3.利用表显数据与预测值之差进行漏损量的估计.
问题四分析
问题需要从水表的实时数据中发现供水管网的漏损位置:
我们基于问题三的样条插值平滑预测模型:
1.对二级水表及下属水表进行漏损偏差统计:
2.计算漏损率
漏损率=(原始值-预测值)/预测值
3.对漏损率超过总体漏损率的时间点和地点判定其发生漏损现象,根据偏差统计划分风险等级,给出供水管网中,可能出现漏损的位置及概率。
问题五分析
问题五需要根据查询资料,结合前面所得到的漏水数据,做出最佳维修策略,为此应首先查阅国家相关水务数据 3,劳务数据以及材料费用数据 4,从而确定水价范围和单次维修价格的范围。以总损失金额最小作为规则目标函数,以每天是否维修作为决策变量,建立 0-1 规划模型,从而得到维修决策。
模型的建立与求解整体论文缩略图

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
import pandas as pd
shuju1=pd.read_excel('一季度.xlsx')
shuju2=pd.read_excel('二季度.xlsx')
shuju3=pd.read_excel('三季度.xlsx')
shuju4=pd.read_excel('四季度.xlsx')
print(shuju1)#==查看一季度的统计描述:====
#可以得到一季度的最大值、最小值、平均值等信息
print(shuju1.describe())#==为了快速浏览数据集,我们使用dataframe.info()功能===
print(shuju1.info())#===查看缺失值======
print(shuju1.isnull().sum())'''2 读取水表层:'''
shui_biao = pd.read_excel("水表层级.xlsx")
print(shui_biao)#查看水表有哪些不同类型:
print(shui_biao['水表名'].unique())#查看四个季度水表名数量:
print(len(shuju1['水表名'].unique()))
print(len(shuju2['水表名'].unique()))
print(len(shuju3['水表名'].unique()))
print(len(shuju4['水表名'].unique()))#给数据表添加上具体季度更方便观察:
import numpy as np
# 合并数据
shuju1['季度'] = pd.Series(["一季度" for i in range(len(shuju1.index))])
shuju2['季度'] = pd.Series(["二季度" for i in range(len(shuju2.index))])
shuju3['季度'] = pd.Series(["三季度" for i in range(len(shuju3.index))])
shuju4['季度'] = pd.Series(["四季度" for i in range(len(shuju4.index))])
print(shuju1)#添加合并:
shuju = shuju1.append([shuju2,shuju3,shuju4],ignore_index=True) # 添加合并
print(shuju)#再查看表数量:
print(len(shuju['水表名'].unique()))
print(len(shui_biao['水表名'].unique()))'''3 按照水表名分类,统计总用量'''
use_water = shuju.groupby(by='水表名')['用量'].sum() # 按照水表名分类,统计总用量
print(use_water)#从高到低排序下:
use_water.sort_values(ascending=False)import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
#mpl.rcParams['font.sans-serif'] = ['Times New Roman'] #Times New Roman字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
import matplotlib; matplotlib.use('TkAgg')
#====根据使用绘制直方图:=====
use_water.plot.hist(histtype='bar', rwidth=0.5)
plt.savefig('可视化/0.1.png', dpi=300, bbox_inches="tight")
plt.show()'''4 对这些功能区的类型进行分析:'''# 全部水表list_table_name = list(shuju['水表名'].unique()) #合并后的数据'''4.1 功能区分类'''#======4.1.1 找到所有宿舍的水表==========
list_home = [] #宿舍
list_teaching_build = [] #教学楼
list_teacher_build = [] #活动地方
for name in list_table_name.copy():if name.find("学生宿舍") != -1 or name.find("留学生楼") != -1:list_home.append(name)list_table_name.remove(name)
print(list_home)#=======4.1.2 同理,找到教学楼=========
for name in list_table_name.copy():if name.find("XX") != -1 and name.find("楼") != -1:print(name)list_teaching_build.append(name)list_table_name.remove(name)
print(list_teaching_build)#======4.1.3 农业区=================
list_agritural = []
for name in list_table_name.copy():if name.find("养殖") != -1 or name.find("养鱼") != -1 or name.find("大棚")!=-1 or name.find("花")!=-1:list_agritural.append(name)list_table_name.remove(name)
print(list_agritural)#=======4.1.4 后勤===============
for name in list_table_name.copy():if name.find("楼")!= -1:list_teaching_build.append(name)list_table_name.remove(name)
print(list_table_name)#========类型添加上去·:================list_backup = list_table_name
name_list = shuju['水表名'].tolist() #.tolist:将数组转化为列表
type_list = []
for name in name_list:if name in list_backup:type_list.append("后勤")elif name in list_agritural:type_list.append("农业")elif name in list_home:type_list.append('宿舍')elif name in list_teaching_build:type_list.append("活动地方")else:type_list.append('教学楼')shuju['类型'] = pd.Series(type_list)
print(shuju)'''4.2 不同类型的用量:'''
type_sum = shuju.groupby(by='类型')['用量'].sum()
print(type_sum)#===对不同类型可视化:=====type_sum.plot.barh(alpha=0.7)
df_group_two = shuju.groupby(by=['类型'])
i = 0
colors=['r','g','b','m','c']
plt.figure(figsize=(35, 35), dpi=100)
for types ,group in df_group_two:i += 1plt.subplot(3,2,i)group.groupby(by='水表名').sum()["用量"].plot.barh(title=types,color=colors[i-1],alpha=.5)
plt.savefig('可视化/1不同类型可视化.png', dpi=300, bbox_inches="tight")
plt.show()#分析完把合并后的数据保存起来:
shuju.to_csv('data1.txt',index=False) #data1.csv容易数据缺失,所以考虑txt
#shuju.to_xlsx('total.xlsx',index=False)#按照时间聚合:
shuju['timeStamp'] = pd.to_datetime(shuju['采集时间'])
shuju.set_index("timeStamp", inplace=True)
data_quarter = shuju.resample("Q") # 时间聚合采样。.resample:重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。'''4.3 接下来分析每个季度、月份、天数、24小时变化:'''#===4.3.1 季度变化规律:===================
data_quarter.sum()["用量"].plot.line(style="m>-.",alpha=0.5,title="用水量随着季度变化趋势") #Q:季度
plt.savefig('可视化/0.2用水量随着季度变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()#===4.3.2 月份变化规律:===================
data_month = shuju.resample('M').sum()["用量"].plot.line(style="c*-.",alpha=0.5,title="用水量随着月份变化趋势") #M:月份
plt.savefig('可视化/0.3用水量随着月份变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()'''添加具体时间:'''
shuju['hour'] = pd.to_datetime(shuju['采集时间']).dt.hour
shuju['day'] = pd.to_datetime(shuju['采集时间']).dt.day
print(shuju)#====4.3.3 用水量一天随着小时变化规律:=============
shuju.groupby(by='hour').sum()['用量'].plot.line(style="gh-.",alpha=0.5,title="用水量随着时间变化趋势")
plt.grid()
plt.savefig('可视化/0.4用水量一天随着小时变化规律.png', dpi=300, bbox_inches="tight")
plt.show()#=====4.3.4 一个月内用水量随着天数变化:=======
shuju.groupby(by='day').sum()['用量'].plot.line(style="rd-.",alpha=0.5,title="用水量随着天变化趋势")
plt.grid()
plt.savefig('可视化/0.5一个月内用水量随着天数变化.png', dpi=300, bbox_inches="tight")
plt.show()'''4.4 不同区域的特征:'''
# 不同区域用水特征#=======4.4.1 不同区域随着季度用水变化=======================
i = 0
styles=['*-.','-.','1-.','2-.','3-.']
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):i += 1plt.subplot(3,2,i)group.resample("Q").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着季度变化趋势".format(index)) #四个季度
plt.savefig('可视化/2 不同区域随着季度用水变化.png', dpi=300, bbox_inches="tight")
plt.show()#======4.4.2 不同区域随着月份用水变化===============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):i += 1plt.subplot(3,2,i)group.resample("M").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着月份变化趋势".format(index))
plt.savefig('可视化/3不同区域随月份变化.png', dpi=300, bbox_inches="tight")
plt.show()#=====4.4.3 不同区域随着每月的天数用水变化==============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):i += 1plt.subplot(3,2,i)group.groupby(by='day').sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着天数变化趋势".format(index))plt.grid()
plt.savefig('可视化/4不同区域随着每月的天数用水变化.png', dpi=300, bbox_inches="tight")
plt.show()#=====4.4.4 不同区域随着每天的时辰用水变化==============
i = 0plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):i += 1plt.subplot(3,2,i)group.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着时辰变化趋势".format(index))plt.grid()
plt.savefig('5.png', dpi=300, bbox_inches="tight")
plt.show()
#分析完毕~把数据保存起来:
shuju.to_csv('data2.txt',index=False) #data2.csv容易装不下数据,照成数据缺失
#shuju.to_xlsx('all.xlsx',index=False)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2020年国赛高教杯数学建模E题校园供水系统智能管理解题全过程文档及程序
2020年国赛高教杯数学建模 E题 校园供水系统智能管理 原题再现 校园供水系统是校园公用设施的重要组成部分,学校为了保障校园供水系统的正常运行需要投入大量的人力、物力和财力。随着科学技术的发展,校园内已经普遍使用了智能水表,从而可以…...

ip地址显示本地局域网什么意思?ip地址冲突怎么解决
在日常使用网络的过程中,我们可能会遇到IP地址显示“本地局域网”的情况,同时,局域网内IP地址冲突也是一个常见且令人头疼的问题。本文将首先解释IP地址显示本地局域网的含义,随后详细探讨局域网IP地址冲突的解决方法,…...

[软件工程]八.软件演化
8.1什么是软件演化 由于种种不可避免的原因,系统开发完成后的软件需要进行修改来适应变更的需求,我们对软件的修改就叫软件演化。 8.2为什么软件会演化 由于业务的变更或者为了满足用户期待的改变,使得对已有的系统的新需求浮现出来。由于…...

【大数据学习 | 面经】yarn的资源申请和分配的单位-Container
在yarn中,资源的申请和分配是以container为单位进行的,而不是直接以application和task为单位。 每个提交到yarn上的应用程序(application)都有一个对应的ApplicationMaster(AM)。这个AM负责与ResourceMana…...

WiFi受限不再愁,电脑无网络快速修复指南
有时在试图连接WiFi时,会发现网络连接受限,或无法正常访问互联网。这种情况不仅影响了工作效率,还可能错过重要的信息。那么,究竟是什么原因导致了电脑WiFi连接受限呢?又该如何解决这一问题呢?小A今天就来教…...
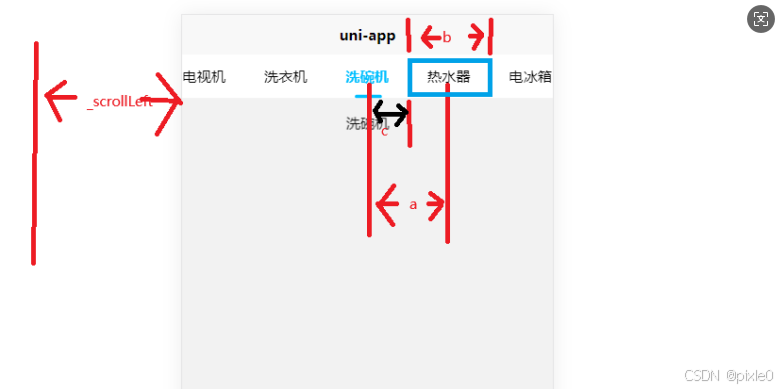
【组件封装】uniapp vue3 封装一个完整的Tabs(标签页)组件教程,功能由简到杂实现讲解。
文章目录 前言一、简单版Tabs代码实现: 二、下划线带动画的TabsAPI回顾:代码实现: 三、内容区域滑动切换切换动画代码实现:(2)禁用手势滑动切换(3)内容区域换为插槽 四、标签栏可滚动…...

TDesign:Picker 选择器
Picker 选择器 API文档地址 单列选择器用法 /// view onTap:(){TDPicker.showMultiPicker(context,data: [controller.coinList],title: ,rightTextStyle: TextStyle(color: AppColors.ColorMain),onConfirm: (selected) {controller.onTapCoin(selected);Navigator.of(contex…...

【AI赋能心理学论文创作策略】第十二章 AI辅助临床启示撰写指南
AI赋能心理学论文创作策略-系列文章目录 第十二章 AI辅助临床启示撰写指南 文章目录 AI赋能心理学论文创作策略-系列文章目录第十二章 AI辅助临床启示撰写指南 前言基础分析框架第一阶段:核心要素分析第二阶段:应用场景展开 关键环节提示第三阶段&#x…...

Pynsist 打包应用 和 PyWebIO 构建Web 应用
Pynsist:一键打包Python 应用代码为Windows 安装程序。 项目地址: https://github.com/takluyver/pynsist PyWebIO:为Python 开发者提供了一种快速、简洁的方式来创建Web 应用,无需学习前端技术 项目地址:https://g…...
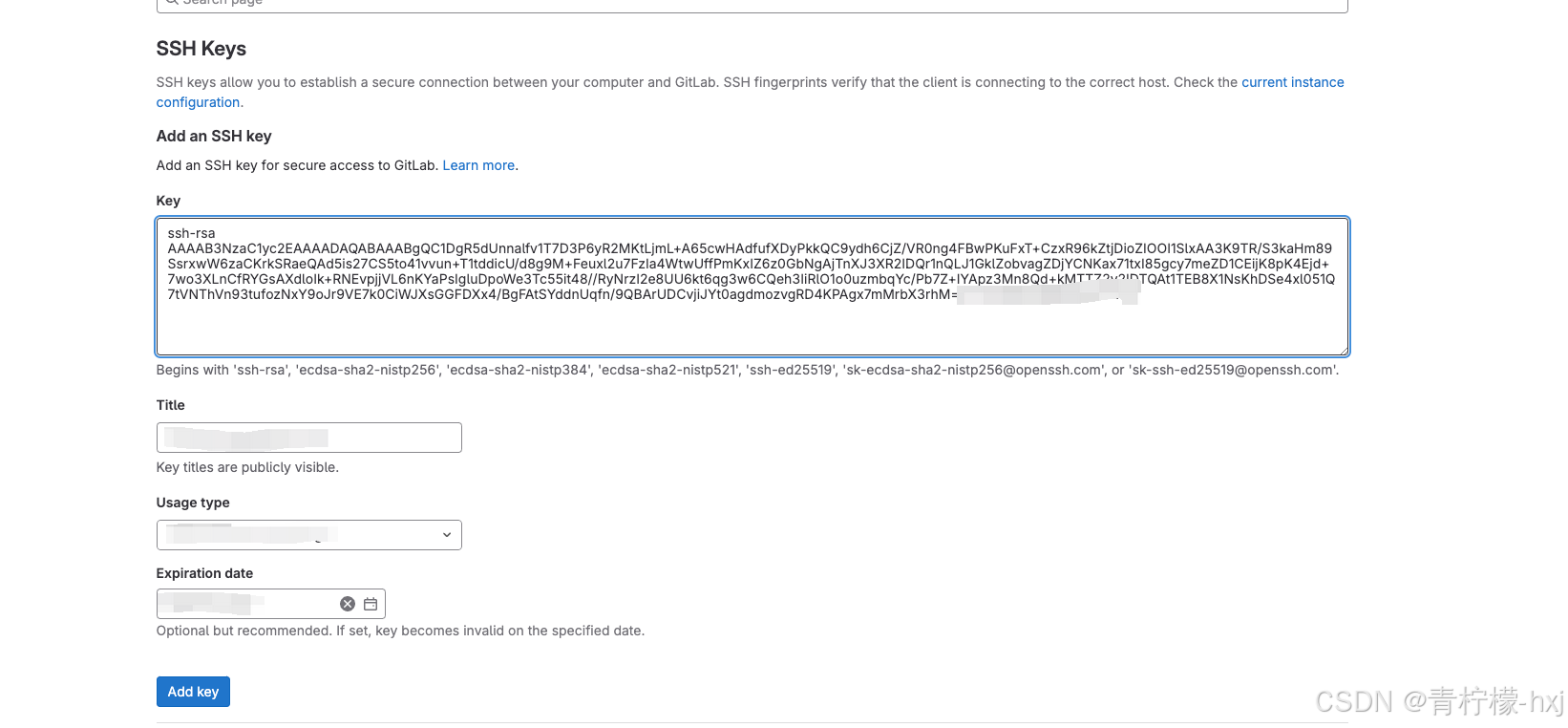
git 使用配置
新拿到机器想配置git 获取代码权限,需要的配置方法 1. git 配置用户名和邮箱 git config --global user.name xxxgit config --global user.email xxemail.com 2. 生成ssh key ssh-keygen -t rsa -C "xxemail.com" 3. 获取ssh key cat ~/.ssh/id_rsa.…...
)
记一次Mysql的SELECT command denied to user...报错(非权限问题)
java.sql.SQLSyntaxErrorException: SELECT command denied to user ‘user_name’‘1.1.1.1’ for table ‘table_name’。错误信息的字面意思是:表“table_name”拒绝用户“user_name”“1.1.1.1”的SELECT命令 。 比较多的情况是:用户没有查看user表…...

element-plus的el-tree的双向绑定
el-tree改造了下 可选可取消 有默认值 不包含父级id 默认展开 点击节点也可触发选择 节点内容自定义 <template>{{ childKeys }}<!--default-checked-keys:默认展开值(正常来说需要包含父级id的 但是我们后端不要后端id )show-checkbox&#x…...
)
代码随想录-算法训练营day41(动态规划04:01背包,01背包滚动数组,分割等和子集)
第九章 动态规划part04● 01背包问题,你该了解这些! ● 01背包问题,你该了解这些! 滚动数组 ● 416. 分割等和子集 正式开始背包问题,背包问题还是挺难的,虽然大家可能看了很多背包问题模板代码…...
方法)
c#中context.SaveChanges()方法
跟踪实体的状态: Entity Framework 使用 Change Tracker 来跟踪上下文中所有实体的状态。实体的状态可以是: Added:新添加的实体(即将插入到数据库中)。Modified:已修改的实体(即将更新数据库中…...

李飞飞首个“空间智能”模型发布:一张图,生成一个3D世界 | LeetTalk Daily
“LeetTalk Daily”,每日科技前沿,由LeetTools AI精心筛选,为您带来最新鲜、最具洞察力的科技新闻。 在人工智能技术迅速发展的背景下,李飞飞创立的世界实验室于近期发布了首个“空间智能”模型,这一创新成果引发了3D生…...

Node.js简单接口实现教程
Node.js简单接口实现教程 1. 准备工作 确保您的计算机已安装: Node.js (建议版本16.x以上)npm (Node包管理器) 2. 项目初始化 # 创建项目目录 mkdir nodejs-api-tutorial cd nodejs-api-tutorial# 初始化npm项目 npm init -y# 安装必要依赖 npm install expres…...

AIGC 012-Video LDM-更进一步,SD作者将LDM扩展到视频生成任务!
AIGC 012-Video LDM-Stable Video diffusion前身,将LDM扩展到视频生成任务! 文章目录 0 论文工作1论文方法实验结果 0 论文工作 Video LDM作者也是Stable diffusion的作者,作者在SD的架构上进行扩展,实现了视频的生成。后续在Vid…...

windows文件下换行, linux上不换行 解决CR换行符替换为LF notepad++
html文件是用回车换行的,在windows电脑上,显示正常。 文件上传到linux服务器后,文件不换行了。只有一行。而且相关js插件也没法正常运行。 用notepad查看,显示尾部换行符,是CR,这就是原因。CR是不被识别的。…...
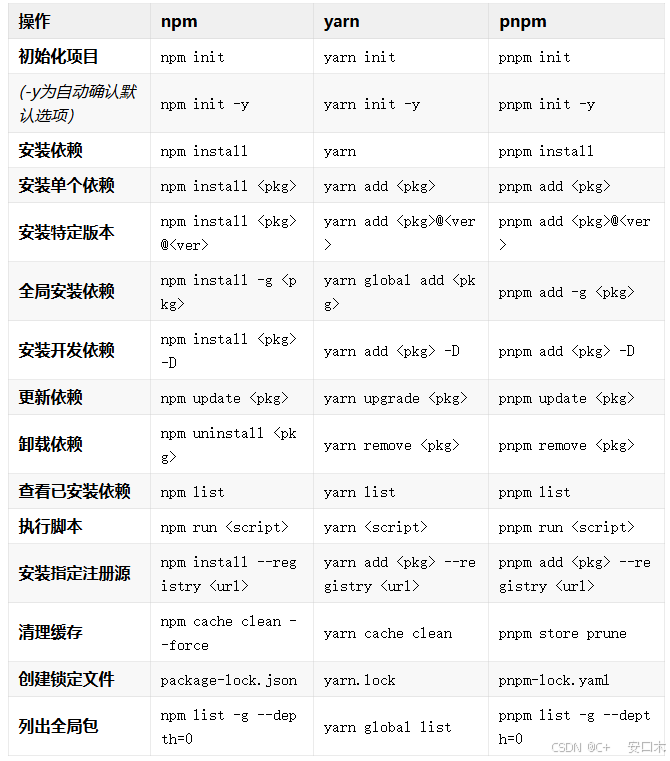
npm, yarn, pnpm之间的区别
前言 在现代化的开发中,一个人可能同时开发多个项目,安装的项目越来越多,所随之安装的依赖包也越来越臃肿,而且有时候所安装的速度也很慢,甚至会安装失败。 因此我们就需要去了解一下,我们的包管理器&#…...

静态链接和动态链接的特点
静态链接 链接方式:在编译时,所有依赖的库代码被直接打包到生成的可执行文件中。这意味着在程序运行时,不需要再加载任何外部库文件。 优点: 独立性强:生成的可执行文件可以在没有依赖库的系统上直接运行&am…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...