【pyspark学习从入门到精通24】机器学习库_7
目录
聚类
在出生数据集中寻找簇
主题挖掘
回归
聚类
聚类是机器学习中另一个重要的部分:在现实世界中,我们并不总是有目标特征的奢侈条件,因此我们需要回归到无监督学习的范式,在那里我们尝试在数据中发现模式。
在出生数据集中寻找簇
在这个例子中,我们将使用 k-means 模型在出生数据中寻找相似性:
import pyspark.ml.clustering as clus
kmeans = clus.KMeans(k = 5, featuresCol='features')
pipeline = Pipeline(stages=[assembler,featuresCreator, kmeans]
)
model = pipeline.fit(births_train)估计模型后,让我们看看我们是否能找到不同簇之间的一些差异:
test = model.transform(births_test)
test \.groupBy('prediction') \.agg({'*': 'count', 'MOTHER_HEIGHT_IN': 'avg'}).collect()前面的代码产生了以下输出:
嗯,MOTHER_HEIGHT_IN 在第 2 个簇中显著不同。仔细研究结果(这里我们显然不会这么做)可能会揭示更多的差异,并允许我们更好地理解数据。
主题挖掘
聚类模型不仅限于数值数据。在自然语言处理领域,像主题提取这样的问题依赖于聚类来检测具有相似主题的文档。我们将经历这样一个例子。
首先,让我们创建我们的数据集。数据由互联网上随机选择的段落组成:其中三个涉及自然和国家公园的主题,其余三个涵盖技术。
text_data = spark.createDataFrame([['''To make a computer do anything, you have to write a computer program. To write a computer program, you have to tell the computer, step by step, exactly what you want it to do. The computer then "executes" the program, following each step mechanically, to accomplish the end goal. When you are telling the computer what to do, you also get to choose how it's going to do it. That's where computer algorithms come in. The algorithm is the basic technique used to get the job done. Let's follow an example to help get an understanding of the algorithm concept.'''],(...),['''Australia has over 500 national parks. Over 28 million hectares of land is designated as national parkland, accounting for almost four per cent of Australia's land areas. In addition, a further six per cent of Australia is protected and includes state forests, nature parks and conservation reserves.National parks are usually large areas of land that are protected because they have unspoilt landscapes and a diverse number of native plants and animals. This means that commercial activities such as farming are prohibited and human activity is strictly monitored.''']
], ['documents'])首先,我们将再次使用 RegexTokenizer 和 StopWordsRemover 模型:
tokenizer = ft.RegexTokenizer(inputCol='documents', outputCol='input_arr', pattern='\s+|[,.\"]')
stopwords = ft.StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol='input_stop')接下来是我们管道中的 CountVectorizer:一个计算文档中单词数量并返回计数向量的模型。向量的长度等于所有文档中所有不同单词的总数,这可以在以下片段中看到:
stringIndexer = ft.CountVectorizer(inputCol=stopwords.getOutputCol(), outputCol="input_indexed")
tokenized = stopwords \.transform(tokenizer\.transform(text_data))stringIndexer \.fit(tokenized)\.transform(tokenized)\.select('input_indexed')\.take(2)前面的代码将产生以下输出:
如你所见,文本中有 262 个不同的单词,现在每个文档由每个单词出现次数的计数表示。
现在轮到开始预测主题了。为此,我们将使用 LDA 模型——潜在狄利克雷分配模型:
clustering = clus.LDA(k=2, optimizer='online', featuresCol=stringIndexer.getOutputCol())k 参数指定我们期望看到的主题数量,优化器参数可以是 'online' 或 'em'(后者代表期望最大化算法)。
将这些谜题拼凑在一起,到目前为止,这是我们最长的管道:
pipeline = ml.Pipeline(stages=[tokenizer, stopwords,stringIndexer, clustering]
)我们是否正确地发现了主题?嗯,让我们看看:
topics = pipeline \.fit(text_data) \.transform(text_data)
topics.select('topicDistribution').collect()这是我们得到的:

看起来我们的方法正确地发现了所有的主题!不过,不要习惯看到这么好的结果:遗憾的是,现实世界的数据很少是这样的。
回归
我们不能在没有构建回归模型的情况下结束机器学习库的一章。
在这一部分,我们将尝试预测 MOTHER_WEIGHT_GAIN,给定这里描述的一些特征;这些特征包含在这里列出的特征中:
features = ['MOTHER_AGE_YEARS','MOTHER_HEIGHT_IN','MOTHER_PRE_WEIGHT','DIABETES_PRE','DIABETES_GEST','HYP_TENS_PRE', 'HYP_TENS_GEST', 'PREV_BIRTH_PRETERM','CIG_BEFORE','CIG_1_TRI', 'CIG_2_TRI', 'CIG_3_TRI']首先,由于所有特征都是数值型的,我们将它们整合在一起,并使用 ChiSqSelector 仅选择最重要的六个特征:
featuresCreator = ft.VectorAssembler(inputCols=[col for col in features[1:]], outputCol='features'
)
selector = ft.ChiSqSelector(numTopFeatures=6, outputCol="selectedFeatures", labelCol='MOTHER_WEIGHT_GAIN'
)为了预测体重增加,我们将使用梯度提升树回归器:
import pyspark.ml.regression as reg
regressor = reg.GBTRegressor(maxIter=15, maxDepth=3,labelCol='MOTHER_WEIGHT_GAIN')最后,再次将所有内容整合到一个 Pipeline 中:
pipeline = Pipeline(stages=[featuresCreator, selector,regressor])
weightGain = pipeline.fit(births_train)创建了 weightGain 模型后,让我们看看它在我们测试数据上的表现如何:
evaluator = ev.RegressionEvaluator(predictionCol="prediction", labelCol='MOTHER_WEIGHT_GAIN')
print(evaluator.evaluate(weightGain.transform(births_test), {evaluator.metricName: 'r2'}))我们得到以下输出:
![]()
遗憾的是,这个模型不比抛硬币的结果好。看来,如果没有与 MOTHER_WEIGHT_GAIN 标签更相关的额外独立特征,我们将无法充分解释其方差。
相关文章:

【pyspark学习从入门到精通24】机器学习库_7
目录 聚类 在出生数据集中寻找簇 主题挖掘 回归 聚类 聚类是机器学习中另一个重要的部分:在现实世界中,我们并不总是有目标特征的奢侈条件,因此我们需要回归到无监督学习的范式,在那里我们尝试在数据中发现模式。 在出生数据…...

Echart折线图属性设置 vue2
Echart折线图 官方配置项手册 Documentation - Apache ECharts 下面代码包含:设置标题、线条样式、图例圆圈的样式、显示名称格式、图片保存、增加Y轴目标值 updateChart(data) {const sortedData data.slice().sort((a, b) > new Date(a.deviceTime) - ne…...

LabVIEW-简单串口助手
LabVIEW-简单串口助手 串口函数VISA配置串口VISA写入函数VISA读取函数VISA资源名称按名称解除捆绑 函数存放位置思维导图主体界面为以下 串口函数 VISA配置串口 VISA写入函数 VISA读取函数 VISA资源名称 按名称解除捆绑 函数存放位置 思维导图 主体界面为以下 从创建好的“枚举…...

Linux下,用ufw实现端口关闭、流量控制(二)
本文是 网安小白的端口关闭实践 的续篇。 海量报文,一手掌握,你值得拥有,让我们开始吧~ ufw 与 iptables的关系 理论介绍: ufw(Uncomplicated Firewall)是一个基于iptables的前端工具…...

C#开发-集合使用和技巧(九)Join的用法
在C#中,IEnumerable 的 Join 方法用于根据键将两个序列中的元素进行关联。Join 方法通常用于执行类似于 SQL 中的内连接操作。以下是 Join 方法的基本用法: 基本语法 public static IEnumerable<TResult> Join<TOuter, TInner, TKey, TResult…...

Dockerfile容器镜像构建技术
文章目录 1、容器回顾1_容器与容器镜像之间的关系2_容器镜像分类3_容器镜像获取的方法 2、其他容器镜像获取方法演示1_在DockerHub直接下载2_把操作系统的文件系统打包为容器镜像3_把正在运行的容器打包为容器镜像 3、Dockerfile介绍4、Dockerfile指令1_FROM2_RUN3_CMD4_EXPOSE…...

Github 2024-12-01 开源项目月报 Top20
根据Github Trendings的统计,本月(2024-12-01统计)共有20个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目10TypeScript项目9Go项目2HTML项目1Shell项目1Jupyter Notebook项目1屏幕截图转代码应用 创建周期:114 天开发语言:TypeScript, Py…...

Spring Boot 3项目集成Swagger3教程
Spring Boot 3项目集成Swagger3教程 ?? 前言 欢迎来到我的小天地,这里是我记录技术点滴、分享学习心得的地方。?? ?? 技能清单 编程语言:Java、C、C、Python、Go、前端技术:Jquery、Vue.js、React、uni-app、EchartsUI设计: Element-u…...

NISP信息安全一级考试200道;免费题库;大风车题库
下载链接:大风车题库-文件 大风车题库网站:大风车题库 大风车excel(试题转excel):大风车excel...

Android ConstraintLayout 约束布局的使用手册
目录 前言 一、ConstraintLayout基本介绍 二、ConstraintLayout使用步骤 1、引入库 2、基本使用,实现按钮居中。相对于父布局的约束。 3、A Button 居中展示,B Button展示在A Button正下方(距离A 46dp)。相对于兄弟控件的约束…...

在网安中什么是白帽子
在网络安全领域,白帽子是指那些专门从事网络安全研究,帮助企业或个人发现并修复安全漏洞的专家。以下是对白帽子的详细解释: 一、定义与角色 白帽子是网络安全领域的术语,通常指那些具备专业技能和知识的网络安全专家。他们的工作…...

软件专业科目难度分级 你输在了哪里?
感想: 我把我们现在软件专业学的东西分了个难度级别 级别描述视角服务对象例子0 基本软件的使用用户-Photoshop wps ssms等1 软件的原理开发者用户各种编程语言2软件的原理的原理开发者开发者各种函数的深层定义,数据结构等 0级就是咱们平时用的那些软…...

微信小程序实现图片拖拽调换位置效果 -- 开箱即用
在编写类似发布朋友圈功能的功能时,需要实现图片的拖拽排序,删除图片等功能。 博主的小程序首页也采用了该示例代码,可以在威信中搜索: 我的百宝工具箱 或者复制后面的🔗在手机打开: #小程序://百宝工具箱/…...

关于“浔川AI翻译”使用情况的调研报告
关于“浔川 AI 翻译”使用情况的调研报告 随着全球化进程加速及外语学习需求攀升,AI 翻译工具愈发普及。“浔川 AI 翻译”作为行业产品之一,为了解其市场表现与用户反馈,特开展本次问卷调查,现将关键结果汇报如下。 一、样本概…...

《芯片:科技之核,未来之路》
《芯片:科技之核,未来之路》 一、芯片的定义与重要性二、芯片的应用领域(一)新能源领域(二)信息通讯设备领域(三)4C 产业(四)智能电网领域(五&…...

️ 在 Windows WSL 上部署 Ollama 和大语言模型的完整指南20241206
🛠️ 在 Windows WSL 上部署 Ollama 和大语言模型的完整指南 📝 引言 随着大语言模型(LLM)和人工智能的飞速发展,越来越多的开发者尝试在本地环境中部署大模型进行实验。然而,由于资源需求高、网络限制多…...

使用Tomcat搭建简易文件服务器
创建服务器 1. 复制一个tomcat服务器,并命名为file-service(好区分即可) 2.在webapp里面新建一个文件夹 uploadfiles ,用于存储上传的文件 3. 修改conf/service.xml,配置文件服务器的端口与上传文件夹的访问 在Host标签之间加入一个Context标签 docBase"uploa…...

《C++赋能:构建智能工业控制系统优化算法新引擎》
在工业 4.0 的浪潮汹涌澎湃之际,传统工业控制系统正面临着前所未有的挑战与机遇。如何借助人工智能的强大力量,实现工业控制系统的深度优化,已成为工业领域乃至整个科技界关注的焦点。而 C语言,以其卓越的性能、高效的执行效率和对…...

node.js中跨域请求有几种实现方法
默认情况下,出于安全考虑,浏览器会实施同源策略,阻止网页向不同源的服务器发送请求或接收来自不同源的响应。 同源策略:协议、域名、端口三者必须保持一致 <!DOCTYPE html> <html lang"en"> <head>&l…...

Node.js新作《循序渐进Node.js企业级开发实践》简介
《循序渐进Node.js企业级开发实践》由清华大学出版社出版,已于近期上市。该书基于Node.js 22.3.0编写,提供26个实战案例43个上机练习,可谓是目前市面上最新的Node.js力作。 本文对《循序渐进Node.js企业级开发实践》一书做个大致的介绍。 封…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...
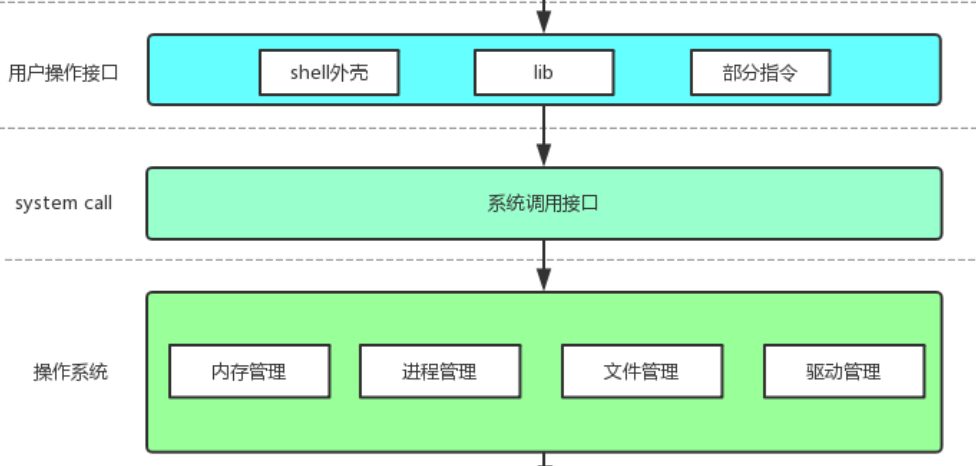
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...
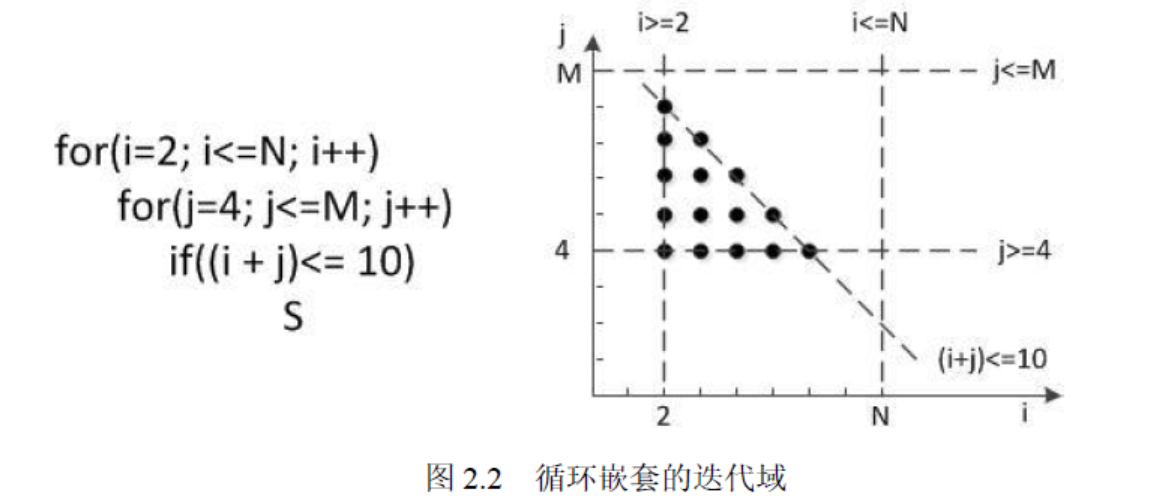
性能优化中,多面体模型基本原理
1)多面体编译技术是一种基于多面体模型的程序分析和优化技术,它将程序 中的语句实例、访问关系、依赖关系和调度等信息映射到多维空间中的几何对 象,通过对这些几何对象进行几何操作和线性代数计算来进行程序的分析和优 化。 其中࿰…...

【大厂机试题解法笔记】矩阵匹配
题目 从一个 N * M(N ≤ M)的矩阵中选出 N 个数,任意两个数字不能在同一行或同一列,求选出来的 N 个数中第 K 大的数字的最小值是多少。 输入描述 输入矩阵要求:1 ≤ K ≤ N ≤ M ≤ 150 输入格式 N M K N*M矩阵 输…...
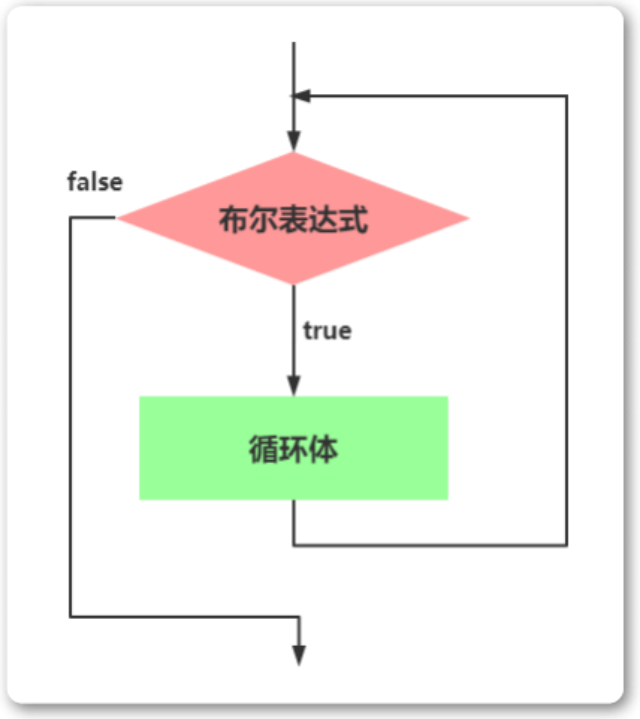
循环语句之while
While语句包括一个循环条件和一段代码块,只要条件为真,就不断 循环执行代码块。 1 2 3 while (条件) { 语句 ; } var i 0; while (i < 100) {console.log(i 当前为: i); i i 1; } 下面的例子是一个无限循环,因…...