Kafka单机及集群部署及基础命令
目录
- 一、 Kafka介绍
- 1、kafka定义
- 2、传统消息队列应用场景
- 3、kafka特点和优势
- 4、kafka角色介绍
- 5、分区和副本的优势
- 6、kafka 写入消息的流程
- 二、Kafka单机部署
- 1、基础环境
- 2、iptables -L -n配置
- 3、下载并解压kafka部署包至/usr/local/目录
- 4、修改server.properties
- 5、修改/etc/profile
- 6、执行/etc/profile
- 7、启动kafka
- 三、Kafka集群部署
- 1、基础环境
- 2、集群
- 3、iptables -L -n配置
- 4、下载并解压kafka部署包至/usr/local/目录(cnode1执行)
- 5、修改/etc/profile(cnode1执行)
- 6、执行/etc/profile(cnode1执行)
- 7、创建存储目录(cnode1执行)
- 8、克隆出cnode2和cnode3
- 9、修改zookeeper配置文件(所有节点执行)
- 10、cnode1新增myid配置(cnode1执行)
- 11、cnode2新增myid配置(cnode2执行)
- 12、cnode2新增myid配置(cnode3执行)
- 13、修改cnode1节点kafka配置
- 14、修改cnode2节点kafka配置
- 15、修改cnode3节点kafka配置
- 16、启动zookeeper(所有节点执行)
- 17、启动kafka(所有节点执行)
- 18、也可以用脚本启动/停止(所有节点执行)
- 四、Kafka基础命令
- 一、KAFKA启停命令
- 二、Topic 相关命令
- 三、消息相关命令
- 四、消费者Group
- 五、其他
一、 Kafka介绍
1、kafka定义
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
2、传统消息队列应用场景
削峰填谷
诸如电商业务中的秒杀、抢红包、企业开门红等大型活动时皆会带来较高的流量脉冲,或因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验,消息队列可提供削峰填谷的服务来解决该问题。
异步解耦
交易系统作为淘宝等电商的最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等等,整体业务系统庞大而且复杂,消息队列可实现异步通信和应用解耦,确保主站业务的连续性。
顺序收发
细数日常中需要保证顺序的应用场景非常多,例如证券交易过程时间优先原则,交易系统中的订单创建、支付、退款等流程,航班中的旅客登机消息处理等等。与先进先出FIFO(First In First Out)原理类似,消息队列提供的顺序消息即保证消息FIFO。
分布式事务一致性
交易系统、支付红包等场景需要确保数据的最终一致性,大量引入消息队列的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
分布式缓存同步
电商的大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因带宽瓶颈,限制了商品变更的访问流量,通过消息队列构建分布式缓存,实时通知商品数据的变化。
3、kafka特点和优势
特点:
- 分布式: 多机实现,不允许单机
- 分区: 一个消息.可以拆分出多个,分别存储在多个位置
- 多副本: 防止信息丢失,可以多来几个备份
- 多订阅者: 可以有很多应用连接kafka
- Zookeeper: 早期版本的Kafka依赖于zookeeper, 2021年4月19日Kafka 2.8.0正式发布,此版本包括了很多重要改动,最主要的是kafka通过自我管理的仲裁来替代ZooKeeper,即Kafka将不再需要ZooKeeper!!!
优势:
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka 服务器分区消息。
- 分布式: Kafka 基于分布式集群实现高可用的容错机制,可以实现自动的故障转移。
- 顺序保证:在大多数使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。 Kafka保证一个Partiton内的消息的有序性(分区间数据是无序的,如果对数据的顺序有要求,应将在创建主题时将分区数partitions设置为1)。
- 支持 Hadoop 并行数据加载。
- 通常用于大数据场合,传递单条消息比较大,而Rabbitmq 消息主要是传输业务的指令数据,单条数据较小。
4、kafka角色介绍
(1)Producer: Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker
(2)Consumer: 消费者,用于消费消息,即处理消息
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如: broker-0、broker-1等……
(3)Topic : 消息的主题,可以理解为消息的分类,一个Topic相当于数据库中的一张表,一条消息相当于关系数据库的一条记录,一个Topic或者相当于Redis中列表类型的一个Key,一条消息即为列表中的一个元素。kafka的数据就保存在topic。在每个broker上都可以创建多个topic。物理上不同 topic 的消息分开存储在不同的文件夹,逻辑上一个 topic的消息虽然保存于一个或多个broker 上, 但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处,topic 在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应的topic 才能消费topic中的消息
(4)Consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group name,若不指定 group name 则属于默认的group),同一topic的一条消息只能被同一个consumer group 内的一个consumer 消费,类似于一对一的单播机制,但多个consumer group 可同时消费这一消息,类似于一对多的多播机制
(5)Partition : 是物理上的概念,每个topic 分割为一个或多个partition,即一个topic切分为多份.创建 topic时可指定 partition 数量,partition的表现形式就是一个一个的文件夹,该文件夹下存储该partition的数据和索引文件,分区的作用还可以实现负载均衡,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,一般Partition数不要超过节点数,注意同一个partition数据是有顺序的,但不同的partition则是无序的
(6)Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES的副本有所不同,Kafka中的副本数包括主分片数,而ES中的副本数不包括主分片数
为了实现数据的高可用,比如将分区 0 的数据分散到不同的kafka 节点,每一个分区都有一个 broker 作为 Leader 和一个 broker 作为Follower,类似于ES中的主分片和副本分片。
假设分区为 3, 即分三个分区0-2,副本为3,即每个分区都有一个 leader,再加两个follower,分区 0 的leader为服务器A,则服务器 B 和服务器 C 为 A 的follower,而分区 1 的leader为服务器B,则服务器 A 和C 为服务器B 的follower,而分区 2 的leader 为C,则服务器A 和 B 为C 的follower。
AR: Assigned Replicas,分区中的所有副本的统称,包括leader和 follower,AR= lSR+ OSR
lSR:ln Sync Replicas,所有与leader副本保持同步的副本 follower和leader本身组成的集合,包括leader和 follower,是AR的子集
OSR:out-of-Sync Replied,所有与leader副本同步不能同步的 follower的集合,是AR的子集
5、分区和副本的优势
- 实现存储空间的横向扩容,即将多个kafka服务器的空间组合利用
- 提升性能,多服务器并行读写
- 实现高可用,每个分区都有一个主分区即 leader 分布在不同的kafka 服务器,并且有对应follower 分布在和leader不同的服务器上
6、kafka 写入消息的流程
- 生产者(producter)先从kafka集群获取分区的leader
- 生产者(producter)将消息发送给leader
- leader将消息写入本地文件
- followers从leader pull消息
- followers将消息写入本地后向leader发送ACK
- leader收到所有副本的ACK后向producter发送ACK
二、Kafka单机部署
1、基础环境
查看centos版本
[root@localhost config]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
查看java版本
[root@localhost config]# java -version
openjdk version "1.8.0_412"
OpenJDK Runtime Environment (build 1.8.0_412-b08)
OpenJDK 64-Bit Server VM (build 25.412-b08, mixed mode)
2、iptables -L -n配置
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:443
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3306
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:21
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9090
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9104
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3000
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9092
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:2181
3、下载并解压kafka部署包至/usr/local/目录
tar -zxvf kafka_2.12-3.1.1.tgz -C /usr/local/
4、修改server.properties
vim /usr/local/kafka_2.12-3.1.1/config/server.properties修改以下内容
listeners=PLAINTEXT://192.168.15.128:9092
advertised.listeners=PLAINTEXT://192.168.15.128:9092
log.dirs=/data/kafka/logs
zookeeper.connect=localhost:2181(local改成192.168.15.128会报错[2024-12-03 11:17:06,427] INFO [ZooKeeperClient Kafka server] Closing. (kafka.zookeeper.ZooKeeperClient))
5、修改/etc/profile
vim /etc/profile新增:
export KAFKA_HOME=/usr/local/kafka_2.12-3.1.1
export PATH=$KAFKA_HOME/bin:$PATH
6、执行/etc/profile
source /etc/profile
7、启动kafka
先启动zookeeper
/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-start.sh /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties查看是否启动
netstat -tuln | grep 2181再启动kafka
/usr/local/kafka_2.12-3.1.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-3.1.1/config/server.properties查看是否启动
netstat -tuln | grep 9092
jps #有kafka则为启动后台启动
/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-start.sh -daemon /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-start.sh -daemon /usr/local/kafka_2.12-3.1.1/config/server.properties


三、Kafka集群部署
1、基础环境
查看centos版本
[root@localhost config]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
查看java版本
[root@localhost config]# java -version
openjdk version "1.8.0_412"
OpenJDK Runtime Environment (build 1.8.0_412-b08)
OpenJDK 64-Bit Server VM (build 25.412-b08, mixed mode)
2、集群
| IP | 主机名 |
|---|---|
| 192.168.15.130 | cnode1 |
| 192.168.15.131 | cnode2 |
| 192.168.15.132 | cnode3 |
3、iptables -L -n配置
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:443
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3306
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:21
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9090
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9104
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3000
ACCEPT icmp -- 0.0.0.0/0 0.0.0.0/0 icmptype 8
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9092
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:2181
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3888
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:2888
4、下载并解压kafka部署包至/usr/local/目录(cnode1执行)
tar -zxvf kafka_2.12-3.1.1.tgz -C /usr/local/
5、修改/etc/profile(cnode1执行)
vim /etc/profile新增:
export KAFKA_HOME=/usr/local/kafka_2.12-3.1.1
export PATH=$KAFKA_HOME/bin:$PATH
6、执行/etc/profile(cnode1执行)
source /etc/profile
7、创建存储目录(cnode1执行)
mkdir -p /opt/software/kafka/log
mkdir -p /opt/software/kafka/zookeeper
mkdir -p /opt/software/kafka/zookeeper/log
8、克隆出cnode2和cnode3
9、修改zookeeper配置文件(所有节点执行)
进入配置目录
cd /usr/local/kafka_2.12-3.1.1/config/
备份zookeeper配置文件
mv zookeeper.properties zookeeper.properties.bak
新建zookeeper配置文件
vi /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties
输入以下内容
dataDir=/opt/software/kafka/zookeeper
dataLogDir=/opt/software/kafka/zookeeper/log
clientPort=2181
maxClientCnxns=100
tickTimes=2000
initLimit=10
syncLimit=5
server.0=192.168.56.101:2888:3888
server.1=192.168.56.103:2888:3888
server.2=192.168.56.104:2888:3888
10、cnode1新增myid配置(cnode1执行)
vim/opt/software/kafka/zookeeper/myid
输入以下内容
0
11、cnode2新增myid配置(cnode2执行)
vim/opt/software/kafka/zookeeper/myid
输入以下内容
1
12、cnode2新增myid配置(cnode3执行)
vim/opt/software/kafka/zookeeper/myid
输入以下内容
2
13、修改cnode1节点kafka配置
进入配置目录
cd /usr/local/kafka_2.12-3.1.1/config/
备份kafka配置文件
mv server.properties server.properties.bak
新建server配置文件broker.id=0
listeners=PLAINTEXT://192.168.15.130:9092
advertised.listeners=PLAINTEXT://192.168.15.130:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.15.130:2181,192.168.15.131:2181,192.168.15.132:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
14、修改cnode2节点kafka配置
进入配置目录
cd /usr/local/kafka_2.12-3.1.1/config/
备份kafka配置文件
mv server.properties server.properties.bak
新建server配置文件broker.id=1
listeners=PLAINTEXT://192.168.15.131:9092
advertised.listeners=PLAINTEXT://192.168.15.131:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.15.130:2181,192.168.15.131:2181,192.168.15.132:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
15、修改cnode3节点kafka配置
进入配置目录
cd /usr/local/kafka_2.12-3.1.1/config/
备份kafka配置文件
mv server.properties server.properties.bak
新建server配置文件broker.id=2
listeners=PLAINTEXT://192.168.15.132:9092
advertised.listeners=PLAINTEXT://192.168.15.132:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.15.130:2181,192.168.15.131:2181,192.168.15.132:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
16、启动zookeeper(所有节点执行)
/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-start.sh /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties查看是否启动
netstat -tuln | grep 2181
17、启动kafka(所有节点执行)
/usr/local/kafka_2.12-3.1.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-3.1.1/config/server.properties查看是否启动
netstat -tuln | grep 9092
18、也可以用脚本启动/停止(所有节点执行)
启动脚本
[root@localhost config]# cat /usr/local/kafka_2.12-3.1.1/kafkaStart.sh
/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-start.sh /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties &
sleep 10
/usr/local/kafka_2.12-3.1.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-3.1.1/config/server.properties &
停止脚本
[root@localhost config]# cat /usr/local/kafka_2.12-3.1.1/kafkaStop.sh
/usr/local/kafka_2.12-3.1.1/bin/zookeeper-server-stop.sh /usr/local/kafka_2.12-3.1.1/config/zookeeper.properties &
sleep 10
/usr/local/kafka_2.12-3.1.1/bin/kafka-server-stop.sh /usr/local/kafka_2.12-3.1.1/config/server.properties &
将脚本复制到cnode2和cnode3节点
scp kafkaStart.sh kafkaStop.sh root@cnode2:$PWD
scp kafkaStart.sh kafkaStop.sh root@cnode3:$PWD
执行以下脚本启动
sh /usr/local/kafka_2.12-3.1.1/kafkaStart.sh
执行以下脚本停止
sh /usr/local/kafka_2.12-3.1.1/kafkaStop.sh
四、Kafka基础命令
一、KAFKA启停命令
1. 前台启动(先启动zookeeper)
bin/zookeeper-server-start.sh config/zookeeper.propertiesbin/kafka-server-start.sh config/server.properties
2. 后台启动
bin/zookeeper-server-start.sh -daemon config/zookeeper.propertiesbin/kafka-server-start.sh -daemon config/server.properties
或者
nohup bin/kafka-server-start.sh config/server.properties &
指定 JMX port 端口启动,指定 jmx,可以方便监控 Kafka 集群
JMX_PORT=9991 /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
3. 停止命令
bin/zookeeper-server-stop.shbin/kafka-server-stop.sh
二、Topic 相关命令
1.创建 Topic
--topic 指定 Topic 名
-–partitions 指定分区数
-–replication-factor 指定备份(副本)数,注意:指定副本因子的时候,不能大于broker实例个数,否则报错
bin/kafka-topics.sh --create --bootstrap-server 192.168.15.130:9092 --replication-factor 1 --partitions 1 --topic demo22.查询Topic列表
/usr/local/kafka_2.12-3.1.1/bin/kafka-topics.sh --bootstrap-server 192.168.15.130:9092 --list3.查询 Topic 详情
bin/kafka-topics.sh --describe --bootstrap-server 192.168.15.130:9092 --topic demo4. 增加 Topic 的 partition 数
bin/kafka-topics.sh --bootstrap-server 192.168.15.130:9092 --alter --topic demo --partitions 25. 查看 topic 指定分区 offset 的最大值或最小值
time 为 -1 时表示最大值,为 -2 时表示最小值:
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic test_kafka_topic --time -1 --broker-list 192.168.15.130:9092 --partitions 0 6.删除Topic
说明:在${KAFKA_HOME}/config/server.properties中配置 delete.topic.enable 为 true,这样才能生效,删除指定的 topic主题
bin/kafka-topics.sh --bootstrap-server 192.168.15.130:9092 --delete --topic demo2
三、消息相关命令
1.发送消息
bin/kafka-console-producer.sh --broker-list 192.168.15.130:9092 --topic demo
消费消息(从头开始)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --from-beginning --topic demo
2.消费消息(从尾开始)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --topic demo --offset latest
3.消费消息(从尾开始指定分区)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --topic demo --offset latest --partition 0
4.消费消息(指定分区指定偏移量)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --topic demo --partition 0 --offset 100
5.指定分组->消费消息
注意给客户端命名之后,如果之前有过消费,那么–from-beginning就不会再从头消费了
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --from-beginning --topic demo --group t1
6.取指定个数
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --topic demo --offset latest --partition 0 --max-messages 1
7.指定分组从头开始消费消息(应该会指定偏移量)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.15.130:9092 --topic demo -group t2 --from-beginning
四、消费者Group
1.消费者Group列表
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.15.130:9092 --list
2.查看Group详情
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.15.130:9092 --group test_group --describe
3.删除 Group中Topic
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.15.130:9092 --group test_group --topic demo --delete
4.删除Group
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.15.130:9092 --group test_group --delete
五、其他
1.平衡leader
bin/kafka-preferred-replica-election.sh --bootstrap-server 192.168.15.130:9092
2.自带压测工具
bin/kafka-producer-perf-test.sh --topic test --num-records 100 --record-size 1 --throughput 100 --producer-props bootstrap.servers=192.168.15.130:9092
相关文章:
Kafka单机及集群部署及基础命令
目录 一、 Kafka介绍1、kafka定义2、传统消息队列应用场景3、kafka特点和优势4、kafka角色介绍5、分区和副本的优势6、kafka 写入消息的流程 二、Kafka单机部署1、基础环境2、iptables -L -n配置3、下载并解压kafka部署包至/usr/local/目录4、修改server.properties5、修改/etc…...

如何使用 Python 实现链表的反转?
在Python中实现链表的反转可以通过几种不同的方法。这里,我将向你展示如何使用迭代和递归两种方式来反转链表。 1. 迭代方法 迭代方法是通过遍历链表,逐个节点地改变其指向来实现反转的。 class ListNode: def __init__(self, val0, nextNone): …...

react跳转传参的方法
传参 首先下载命令行 npm react-router-dom 然后引入此代码 前面跳转的是页面 后面传的是你需要传的参数接参 引入此方法 useLocation():这是 react-router-dom 提供的一个钩子,用于获取当前路由的位置对象location.state:这是从其他页面传…...

Scala:正则表达式
object test03 {//正则表达式def main(args: Array[String]): Unit {//定义一个正则表达式//1.[ab]:表示匹配一个字符,或者是a,或者是b//2.[a-z]:表示从a到z的26个字母中的任意一个//3.[A-Z]:表示从A到Z的26个字母中的任意一个//4.[0-9]:表示从0到9的10…...

【数电】常见时序逻辑电路设计和分析
本文目的:一是对真题常考题型总结,二是对常见时序电路设计方法进行归纳,给后面看这个文档的人留有一点有价值的东西。 1.不同模计数器设计 2.序列信号产生和检测电路 2.1序列信号产生电路 2.1.1设计思路 主要设计思路有三种 1)…...

Spring IOCAOP
Spring介绍 个人博客原地址 Spring是一个IOC(DI)和AOP框架 Sprng的优良特性 非侵入式:基于Spring开发的应用中的对象可以不依赖于Spring的API 依赖注入:DI是控制反转(IOC)最经典的实现 面向切面编程&am…...

Scala中的隐式转换
package qiqiobject qqqqq {//给参数设置一个默认值:如果用户不传入,就使用这个值def sayName(implicit name:String"小花"):Unit{println(s"我叫:$name")}//需求:能够自己设置函数的参数默认值,而不是在代码…...

GESP 2024年12月认证 真题 及答案
CCF GESP第八次认证将于2024年12月7日上午9:30正式开考,1-4级认证时间为上午9:30-11:30,5-8级认证时间为下午13:30-16:30。认证语言包括:C、 Python和图形化编程三种语言,其中C和Python编程为1-8级,图形化编程为1-4级。…...

C++多态性
概念 C中的多态性是面向对象编程的一个重要特征,它允许我们通过一个基类的指针或引用来操作不同派生类的对象。多态性增强了代码的灵活性和可扩展性。主要分为两种类型:编译时多态(静态多态)和运行时多态(动态多态&am…...

PyODBC: Python 与数据库连接的桥梁
PyODBC: Python 与数据库连接的桥梁 介绍 在现代的开发环境中,数据是核心要素之一。几乎所有的应用程序都需要与数据库进行交互。在 Python 中,pyodbc 是一个非常常用的库,它提供了一种简便的方法,通过 ODBC(开放数据…...

专题二十五_动态规划_两个数组的 dp (含字符串数组)_算法专题详细总结
目录 动态规划_两个数组的 dp (含字符串数组) 1. 最⻓公共⼦序列(medium) 解析: 1. 状态表⽰: 2. 状态转移⽅程: 3. 初始化:编辑 4. 填表顺序:编辑 5. 返回值…...

PHP语法学习(第七天)-循环语句,魔术常量
老套路了,朋友们,先回忆昨天讲的内容PHP语法学习(第六天)主要讲了PHP中的if…else语句、关联数组以及数组排序。 想要学习更多PHP语法相关内容点击“PHP专栏!” 下列代码都是在PHP在线测试运行环境中得到的!! 还记得电…...

数据库授权讲解一下
这条 SQL 命令是 MySQL 数据库中用于权限管理的 GRANT 语句。它用于授予用户特定的权限。下面是命令的详细解释: GRANT ALL PRIVILEGES ON *.* TO root% IDENTIFIED BY Zz!12345678 WITH GRANT OPTION;GRANT: 这是一个关键字,用于…...

组件开发的环境准备: nodejs安装,npm镜像源的修改,pnpm包管理器的安装(全局安装),基于pnpm创建脚手架项目
Node.js 是一个开源的、跨平台的 JavaScript 运行环境(本质是Chrome引擎的封装),允许开发者使用 JavaScript 来编写服务器端代码 npm(Node Package Manager)是 Node.js 包管理器, 用来安装各种库、框架和工具 【Node.js官网】 https://nodejs.org 【n…...

学生成绩统计系统
实验内容 问题描述: 输入n个学生的考试成绩,每个学生信息由姓名与分数组成;试设计一种算法: (1)按分数高低次序,打印出每个学生的名次,分数相同的为同一名次; (2)按名次输出每个学生的姓名与分数。 基本要求: (1)学生的考试成绩必须通过…...

【Spring项目】图书管理系统
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 一:项目实现准备 1:需求 (1)登录 2:准备…...

Vivado ILA数据导出MATLAB分析
目录 ILA数据导出 分析方式一 分析方式二 有时候在系统调试时,数据在VIVADO窗口获取的信息有限,可结合MATLAB对已捕获的数据进行分析处理 ILA数据导出 选择信号,单击右键后,会有export ILA DATA选项,将其保存成CS…...

【开源免费】基于SpringBoot+Vue.JS高校学科竞赛平台(JAVA毕业设计)
博主说明:本文项目编号 T 075 ,文末自助获取源码 \color{red}{T075,文末自助获取源码} T075,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析…...

【机器学习】——windows下安装anaconda并在vscode上进行配置
一、安装anaconda 1.进入清华的镜像网站,下载自己电脑对应的anaconda版本。网站:https://repo.anaconda.com/archive/ 这里我下载的版本是anaconda3-2024.10-1-Windows-x86-64 2.下载完毕后开始安装anaconda 3.配置anaconda环境变量 在设置中找到编…...

【H2O2|全栈】Node.js与MySQL连接
目录 前言 开篇语 准备工作 初始配置 创建连接池 操作数据库 封装方法 结束语 前言 开篇语 本节讲解如何使用Node.js实现与MySQL数据库的连接,并将该过程进行函数封装。 与基础部分的语法相比,ES6的语法进行了一些更加严谨的约束和优化&#…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...
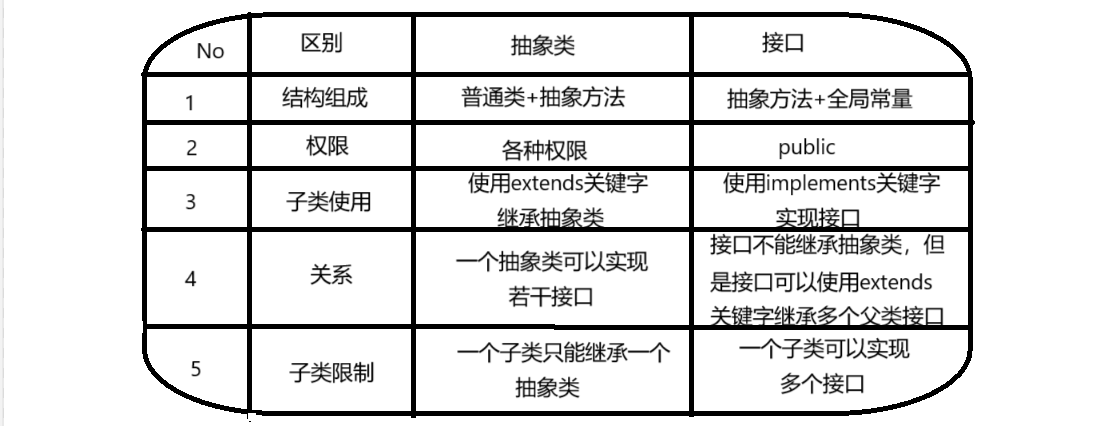
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...