spark3 sql优化:同一个表关联多次,优化方案
目录
- 1.合并查询
- 2.使用 JOIN 条件的过滤优化
- 3.使用 Map-side Join 或 Broadcast Join
- 4.使用 Partitioning 和 Bucketing
- 5.利用 DataFrame API 进行优化
- 假设 A 和 B 已经加载为 DataFrame
- Perform left joins with specific conditions
- 6.使用缓存或持久化
- 7.避免笛卡尔积
- 总结
1.合并查询
如果在 SQL 中的多个 JOIN 操作是针对同一个表,只是条件不同,可以考虑将条件合并成一个查询,从而减少对同一表的多次扫描。例如,将多个 LEFT JOIN 转换成一个 JOIN,使用 CASE 或 FILTER 直接处理不同的关联条件。
优化前:
SELECT A.id, A.col1, A.col2, B1.col3 AS B1_col3, B2.col3 AS B2_col3
FROM A
LEFT JOIN B AS B1 ON A.id = B1.id AND A.col1 = B1.col4
LEFT JOIN B AS B2 ON A.id = B2.id AND A.col2 = B2.col4
优化后:
SELECT A.id, A.col1, A.col2, MAX(CASE WHEN A.col1 = B.col4 THEN B.col3 END) AS B1_col3,MAX(CASE WHEN A.col2 = B.col4 THEN B.col3 END) AS B2_col3
FROM A
LEFT JOIN B ON A.id = B.id
GROUP BY A.id, A.col1, A.col2
2.使用 JOIN 条件的过滤优化
通过精简 JOIN 条件,尽量减少连接的行数。例如,如果 B 表中有索引列,可以直接根据索引列做筛选,而不依赖复杂的条件。
假设对 B 表进行的连接条件中,有部分条件可以通过过滤的方式提前应用,比如通过 WHERE 子句或者 JOIN 之前的 FILTER。
SELECT A.id, A.col1, A.col2, B1.col3 AS B1_col3, B2.col3 AS B2_col3
FROM A
LEFT JOIN B AS B1 ON A.id = B1.id AND A.col1 = B1.col4
LEFT JOIN B AS B2 ON A.id = B2.id AND A.col2 = B2.col4
WHERE B1.col3 IS NOT NULL OR B2.col3 IS NOT NULL
3.使用 Map-side Join 或 Broadcast Join
在 Spark SQL 中,当其中一个表(比如 A)较小且能完全加载到内存时,Spark 会自动选择广播连接,即将小表广播到所有工作节点进行连接计算,而不是进行全表扫描。
如果你知道某个表的规模较小(例如 A),可以手动启用广播连接,减少 shuffle 的开销。
SELECT /*+ BROADCAST(A) */A.id, A.col1, A.col2, B1.col3 AS B1_col3, B2.col3 AS B2_col3
FROM A
LEFT JOIN B AS B1 ON A.id = B1.id AND A.col1 = B1.col4
LEFT JOIN B AS B2 ON A.id = B2.id AND A.col2 = B2.col4
在这里,通过 /*+ BROADCAST(A) */ 强制 Spark 将 A 表广播到各个执行节点,从而避免了对大表 B 进行多次 shuffle。
广播条件:
A 表要相对较小,可以完全加载到内存中。
B 表较大,且 A 表的行数远小于 B。
4.使用 Partitioning 和 Bucketing
在分布式环境下,通过合理的分区和分桶设计,可以减少 JOIN 时的 shuffle 开销。尤其是对于大表,可以考虑对 A 或 B 表做分区(PARTITION BY)或分桶(BUCKET BY)。
– 对 B 表进行分桶(根据 id 或其他相关字段)
CREATE TABLE B (id INT,col3 STRING,col4 STRING
)
USING parquet
CLUSTERED BY (id) INTO 10 BUCKETS;
通过将表按某个字段进行分桶,Spark 在进行连接时能够减少数据的移动和重新分配。
5.利用 DataFrame API 进行优化
如果 SQL 性能不够高,可以尝试将查询转为 DataFrame API 编写,Spark DataFrame API 可能在某些复杂的连接和查询场景下更加高效。
假设 A 和 B 已经加载为 DataFrame
from pyspark.sql import functions as F
Perform left joins with specific conditions
df_A = spark.table("A")
df_B = spark.table("B")df_B1 = df_B.filter(df_B.col4.isNotNull()).select("id", "col3")
df_B2 = df_B.filter(df_B.col4.isNotNull()).select("id", "col3")df_result = df_A.join(df_B1, (df_A.id == df_B1.id) & (df_A.col1 == df_B1.col4), "left") \.join(df_B2, (df_A.id == df_B2.id) & (df_A.col2 == df_B2.col4), "left") \.select(df_A.id, df_A.col1, df_A.col2, df_B1.col3.alias("B1_col3"), df_B2.col3.alias("B2_col3"))df_result.show()
DataFrame API 可以对复杂的 JOIN 和条件执行更多优化,比如延迟执行和缓存策略。
6.使用缓存或持久化
如果你在多次查询中重复使用某些中间结果(例如对 B 表的过滤结果或计算结果),可以选择缓存或持久化某些 DataFrame。
df_B1_cached = df_B1.cache()
df_B2_cached = df_B2.cache()df_result = df_A.join(df_B1_cached, (df_A.id == df_B1_cached.id) & (df_A.col1 == df_B1_cached.col4), "left") \.join(df_B2_cached, (df_A.id == df_B2_cached.id) & (df_A.col2 == df_B2_cached.col4), "left")
缓存对于反复使用的子查询可以减少重新计算的开销。
7.避免笛卡尔积
笛卡尔积会导致非常高的计算开销和内存占用,因此在 JOIN 时需要确保条件足够明确,避免无条件的多表连接。你可以使用 EXPLAIN 来分析查询计划,检查是否出现了笛卡尔积。
查询计划中的 CartesianProduct 或 CROSS JOIN
EXPLAIN SELECT A.id, A.col1, A.col2, B.col3 FROM A JOIN B ON A.id = B.id
Spark SQL / Hive 中,查询计划可能会显示 CartesianProduct 或类似的描述,指明两张表间进行了笛卡尔积连接。
== Physical Plan ==
CartesianProduct(0)
PostgreSQL、MySQL 等关系型数据库,通常会标明连接类型。如果执行计划中显示了 CROSS JOIN,则明确表示笛卡尔积。
-> Seq Scan on table_a (cost=0.00..10.00 rows=100 width=20)
-> Seq Scan on table_b (cost=0.00..10.00 rows=100 width=20)
-> Hash Join (cost=200.00..220.00 rows=1000 width=100)
如果这里显示了 CROSS JOIN,就意味着没有任何连接条件,导致笛卡尔积的生成。
通过查看执行计划(EXPLAIN)了解是否存在不必要的全表扫描。
总结
合并查询: 用 CASE WHEN 合并多个 JOIN。
简化 JOIN 条件: 提前通过 WHERE 子句过滤无效数据。
广播连接: 对小表使用 BROADCAST,减少 shuffle 开销。
分区和分桶: 对大表进行分区或分桶优化 JOIN 性能。
使用 DataFrame API: 在某些复杂查询中,DataFrame API 性能更优。
缓存数据: 重复使用的数据可以进行缓存或持久化。
避免笛卡尔积: 确保 JOIN 有明确的条件,避免全表扫描。
相关文章:

spark3 sql优化:同一个表关联多次,优化方案
目录 1.合并查询2.使用 JOIN 条件的过滤优化3.使用 Map-side Join 或 Broadcast Join4.使用 Partitioning 和 Bucketing5.利用 DataFrame API 进行优化假设 A 和 B 已经加载为 DataFramePerform left joins with specific conditions6.使用缓存或持久化7.避免笛卡尔积总结 1.合…...

JavaWeb学习(4)(四大域、HttpSession原理(面试)、SessionAPI、Session实现验证码功能)
目录 一、web四大域。 (1)基本介绍。 (2)RequestScope。(请求域) (3)SessionScope。(会话域) (4)ApplicationScope。(应用域) (5)PageScope。(页面域) 二、Ht…...

Ubuntu22.04系统源码编译OpenCV 4.10.0(包含opencv_contrib)
因项目需要使用不同版本的OpenCV,而本地的Ubuntu22.04系统装了ROS2自带OpenCV 4.5.4的版本,于是编译一个OpenCV 4.10.0(带opencv_contrib)版本,给特定的项目使用,这就不用换个设备后重新安装OpenCV 了&…...

【Unity高级】在编辑器中如何让物体围绕一个点旋转固定角度
本文介绍如何在编辑器里让物体围绕一个点旋转固定角度,比如上图里的Cube是围绕白色圆盘的中心旋转45度的。 目标: 创建一个在 Unity 编辑器中使用的旋转工具,使开发者能够在编辑模式下快速旋转一个物体。 实现思路: 编辑模式下…...

2024.11.29——[HCTF 2018]WarmUp 1
拿到题,发现是一张图,查看源代码发现了被注释掉的提示 <!-- source.php--> step 1 在url传参看看这个文件,发现了这道题的源码 step 2 开始审计代码,分析关键函数 //mb_strpos($haystack,$needle,$offset,$encoding):int|…...

AGameModeBase和游戏模式方法
AGameModeBase和游戏模式方法有着密切的关系: AGameModeBase是游戏模式的基础类: 它提供了控制游戏规则的基本框架包含了一系列管理游戏流程的核心方法是所有自定义游戏模式类的父类 主要的游戏模式方法包括: // 游戏初始化时调用 virtua…...

Swift 扩展
Swift 扩展 Swift 是一种强大的编程语言,由苹果公司开发,用于iOS、macOS、watchOS和tvOS应用程序的开发。自2014年发布以来,Swift因其易于阅读和编写的语法、现代化的设计以及出色的性能而广受欢迎。本文将探讨Swift的一些关键特性ÿ…...

【NebulaGraph】官方查询语言nGQL教程1 (四)
【NebulaGraph】官方查询语言nGQL教程1 1. 课程信息2. 查找路径FIND PATH2.1 补充说明FIND PATH2.2 例子 1. 课程信息 课程地址: https://www.bilibili.com/video/BV1PT411P7w8/?spm_id_from333.337.search-card.all.click&vd_source240d9002f7c7e3da63cd9a975639409a …...

阿里云负载均衡SLB实践
基于上篇文章继续,如果你使用的是阿里云等云平台,通过配置nginxkeepAlived行不通,因为阿里云服务器不支持你虚拟出ip提供给外部访问,需要使用阿里云的负载均衡产品 对应的产品有三个系列 1、应用场景 ALB: 主要是对应应用层的7层…...

鸿蒙技术分享:❓❓[鸿蒙应用开发]怎么更好的管理模块生命周期?
鸿蒙HarmonyOS NEXT应用开发架构设计-模块生命周期管理 模块化开发 模块化开发已经是应用开发中的一个共识,一般对于公司级的应用开发,都会考虑是否可以进行模块化开发。 HarmonyOS NEXT系统应用开发目前使用的Stage模型其实就有涉及模块化开发的部分…...

深度解析 Ansible:核心组件、配置、Playbook 全流程与 YAML 奥秘(上)
文章目录 一、ansible的主要组成部分二、安装三、相关文件四、ansible配置文件五、ansible 系列 一、ansible的主要组成部分 ansible playbook:任务剧本(任务集),编排定义ansible任务集的配置文件,由ansible顺序依次执…...

LabVIEW气缸摩擦力测试系统
基于LabVIEW的气缸摩擦力测试系统实现了气缸在不同工作状态下摩擦力的快速、准确测试。系统由硬件平台和软件两大部分组成,具有高自动化、精确测量和用户友好等特点,可广泛应用于精密机械和自动化领域。 项目背景: 气缸作为舵机关键部件…...

Leetcode. 688骑士在棋盘上的概率
题目描述 原题链接:Leetcode. 688骑士在棋盘上的概率 解题思路 多元dp 将dp[step][i][j])定义为从(i, j)出发,走step步之后骑士还在棋盘上的概率。 如果 ( i , j ) (i,j) (i,j)不在棋盘上,即非 0 < i < n 0<i<n 0<i<…...

TCP/IP 协议栈高效可靠的数据传输机制——以 Linux 4.19 内核为例
TCP/IP 协议栈是一种非常成熟且广泛使用的网络通信框架,它将复杂的网络通信任务分成多个层次,从而简化设计,使每一层的功能更加清晰和独立。在经典的 TCP/IP 协议栈中,常见的分层为链路层、网络层、传输层和应用层。本文将对每一层的基本功能进行描述,并列出对应于 Linux …...

Ubuntu22.04搭建LAMP环境(linux服务器学习笔记)
目录 引言: 一、系统更新 二、安装搭建Apache2 1.你可以通过以下命令安装它: 2.查看Apache2版本 3.查看Apache2运行状态 4.浏览器访问 三、安装搭建MySQL 1.安装MySQL 2.查看MySQL 版本 3.安全配置MySQL 3.1是否设置密码?(按y|Y表…...

鸿蒙面试---1208
HarmonyOS 三大技术理念 分布式架构:HarmonyOS 的分布式架构使得设备之间能够无缝协同工作。例如,它允许用户在不同的智能设备(如手机、平板、智能手表等)之间共享数据和功能。比如,用户可以在手机上开始编辑文档&…...
)
java基础教程第16篇( 正则表达式)
Java 正则表达式 正则表达式定义了字符串的模式。 正则表达式可以用来搜索、编辑或处理文本。 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。 Java 提供了 java.util.regex 包,它包含了 Pattern 和 Matcher 类,用于处理正…...

Docker部署的gitlab升级的详细步骤(升级到17.6.1版本)
文章目录 一、Gitlab提示升级信息二、老版本的docker运行gitlab命令三、备份老版本Gitlab数据四、确定升级路线五、升级(共分3个版本升级)5.1 升级第一步(17.1.2 > 17.3.7)5.2 升级第二步(17.3.7 > 17.5.3)5.3 升级第三步(17.5.3 > 17.6.1) 六、web端访问gitlab服务 一…...

【如何制定虚拟货币的补仓策略并计算回本和盈利】
在虚拟货币市场中,价格波动性极大,如何在波动中生存并获得盈利是每个投资者都在思考的问题。作为一种投资策略,补仓(又称“摊低成本”)常常被用来降低持仓成本,并在市场回升时获得更大的盈利。但如何科学地设定补仓计划,确定回本点和盈利目标呢? 本文将以 Dogecoin 为…...

给图像去除水印攻
去除水印的过程与添加水印相反,它涉及到图像修复、颜色匹配和区域填充等技术。OpenCV-Python 提供了多种方法来处理不同类型的水印,包括但不限于纯色水印、半透明水印以及复杂背景上的水印。下面将详细介绍几种常见的去水印策略,并给出具体的…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...
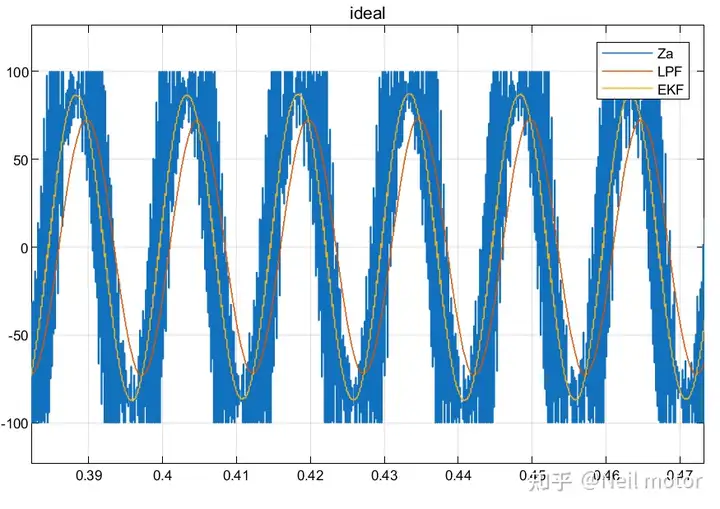
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...