Python微博动态爬虫
本文是刘金路的《语言数据获取与分析基础》第十章的扩展,详细解释了如何利用Python进行微博爬虫,爬虫内容包括微博指定帖子的一级评论、评论时间、用户名、id、地区、点赞数。
整个过程十分明了,就是用户利用代码模拟Ajax请求,发送给服务器,服务器再处理该请求,返回相应的数据,最后在页面进行渲染。
本文所使用的第三方库有requests、openpyxl,请先自行安装。
偷懒的读者可以直接跳到第七章,直接复制代码运行。
效果图

文章目录
???一、基本流程
???二、查看全部评论
???三、找到评论的数据接口
???四、分析数据接口内容
???五、获取内容
???六、批量获取内容
???七、完整代码
???八、微博的限制
8.1 评论数量的限制
8.2 访问的限制
一、基本流程
我们正常使用浏览器上网,通过前端浏览器这一用户界面方便地输入网址、点击链接等,相当于发送了HTTP请求,后端再进行数据返回。
而爬虫是通过代码模拟浏览器发送请求,请求的内容包含headers、cookies等自定义信息,而这些信息浏览器本身就自带的,所以我们正常上网就没必要考虑这么多。在发送请求后,如果服务器能正常响应,就会返回海量看似杂乱的数据。最后,我们需要解析这些数据,得到我们想要的。
模拟浏览器发送请求,我们使用Python的第三方库,requests库。下面我们对百度(https://www.baidu.com)进行访问。
import requestsurl = 'https://www.baidu.com' response = requests.get(url=url) #发送请求print(response.status_code) #若结果返回200则表示正常
print(response.text) #请求获得源代码
仔细观察返回内容可以发现内容不仅少,而且出现了乱码“
o| °±¥é ”,这是因为我们没有对请求进行伪装,被响应端发现了。因此我们需要再加上一些额外的自定义信息。
import requestsurl = 'https://www.baidu.com'headers={
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.5.11051 SLBChan/10 SLBVPV/64-bit',
}response = requests.get(url=url,headers=headers) #发送请求print(response.status_code) #若结果返回200则表示正常
print(response.text)
其中的’User-agent’即用户代理,包含了用户所使用的操作系统版本、浏览器版本等信息。通过增加了headers(头部信息),瞒过了响应端,因此能正常返回源代码。
————————————————————————————————————————
上述情景只适用于静态网页,即所需要的信息在源代码里。
然而在我们进行微博评论爬虫的时候,我们所需要的数据并不在源代码内,而是动态加载的。
二、查看全部评论
以易烊千玺微博的最新帖子为例,我们需要点击查看全部评论,就会跳转到一个新的页面。

鼠标右键<检查>或按F12打开浏览器的开发者模式,并勾选Disable cache(禁用缓存)。
刷新页面,如图,Name栏下有各种各样的数据接口,储存着不同的数据,我们的目的就是找到我们需要的数据接口,并拿到接口下的数据。

三、找到评论的数据接口
既然有这么多数据接口,那怎么找到我们需要的呢?最简单的方法就是复制评论一部分内容。复制了“祝全世界最帅的千千宝贝生日快乐”后,点击放大镜图标,再在左侧一列粘贴该内容,点击刷新图标。之后,双击接口,再点击Preview。
Preview内的数据是以json格式化展示,简明易读。黑色小三角形功能类似目录,可以进行展开、折叠。

四、分析数据接口内容
点开’data’后,可以发现有0-19条数据,里面的格式高度地统一,依次点开几个可以发现,我们需要的id、评论等数据都存储在一种类似Python字典格式的键值对里。

五、获取内容
首先进行伪装,即自定义请求信息,其中重要的包括’User-agent’、‘referer’(防盗链)、‘cookie’,不同网站有不同的限定。需要登陆的网站一般都要用到cookie,网站通过它识别用户登录身份。现在我们来找到自己的这些数据。
在上一步的浏览器开发者工具中,如图,我们复制这些数据。代码中的params与帖子有关,在开发者工具的Payload内,全部复制粘贴即可。

import requests
headers={
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.5.11051 SLBChan/10 SLBVPV/64-bit',
#自行更改
'referer':'https://weibo.com/2653906910/P2d23mO3l',
#自行更改
'cookie':'SINAGLOBAL=2437751658391.7534.1732613052480; XSRF-TOKEN=S9eYHPNYBb4EA4CdIq_CsaWG; SCF=AnvWdOkk8nI9JwyZmH86cW9gt7wNLX4DFiQqFt3_n9fGf4sNBNG7XKR5z9qPUIumCMmBA3d_mSh_9zSSYO2KkA8.; SUB=_2A25KQtf1DeRhGeFJ7VoX8ifNzj2IHXVpPlU9rDV8PUNbmtAbLRj1kW9Nf1irkxLTL3bKCn4suSuV-7E8sDlud4Jz; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5vESPCc8VG.fle.Bw7Y00g5JpX5KzhUgL.FoMNSonceo.pSK22dJLoIEqLxKqL1KzL1K-LxKnLBKeL1hzLxK-LBKBLBKMLxK-L1-eLBoWjd5tt; ALF=02_1735275685; _s_tentry=weibo.com; Apache=9101971672823.17.1732683724233; ULV=1732683724323:2:2:2:9101971672823.17.1732683724233:1732613052488; WBPSESS=KeGgzHFKbGYlLSsXAQi6w6yIVnFklCB92g9IEwKcT6IFw9t3w4GlWYLNWnobudclqNZRGUlNn00rwRSM5bdBO4FLz3Qf7TPT6G0fBQoHQ4hZcFJP5XODD1aum01okGffqFku3aTug5eregoCSIz73Q=='}
params ={'is_reload':'1','id': '5105261544737539','is_show_bulletin': '2','is_mix':'0','count':'10','uid': '3623353053','fetch_level': '0','locale': 'zh-CN',
}
response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params,headers=headers)for i in range(len(response.json()['data'])-1):time = response.json()['data'][i]['created_at']id = response.json()['data'][i]['id']comment = response.json()['data'][i]['text_raw']area = response.json()['data'][i]['source']like_counts = response.json()['data'][i]['like_counts']print(time)print(id)print(comment)print(area)print(like_counts)
偷懒点,读者只需要将cookie、referer更换为自己的就可以了。
六、批量获取内容
但是这些数量很少,于是我们就可以猜想,会不会其他的数据在类似名称的数据接口里?为了试验是否该帖子下的评论数据全部存储在以buildComments…为名的数据接口下,我们可以下拉评论区以便产生更多数据接口。在右侧的Filter输入框内输入buildComments,就能从海量数据接口中过滤出名称为buildComments的数据接口,如图。

我们可以在Headers(HTTP请求头)内找到Request URL(请求网址),打开该网址,我们可以看到密密麻麻的海量数据,这些数据便是Preview内展开后的数据。

依次复制前几个URL,如下:
https://weibo.com/ajax/statuses/buildCommentsis_reload=1&id=5105473521456009&is_show_bulletin=2&is_mix=0&count=10&uid=3623353053&fetch_level=0&locale=zh-CN
https://weibo.com/ajax/statuses/buildCommentsis_reload=1&id=5105473521456009&is_show_bulletin=2&is_mix=0&max_id=4998721601702697&count=20&uid=3623353053&fetch_level=0&locale=zh-CN
https://weibo.com/ajax/statuses/buildCommentsis_reload=1&id=5105473521456009&is_show_bulletin=2&is_mix=0&max_id=1218463186455944&count=20&uid=3623353053&fetch_level=0&locale=zh-CN
通过比对,我们可以发现以下规律:
https://weibo.com/ajax/statuses/buildComments这一部分均一致,之后的参数以’&’进行分隔;第一个数据接口的URL并不包含’max_id’这一参数,且该参数在不断变化;第一个数据接口的count=10,其余都为count=20。
那么max_id到底是什么呢?又如何找到max_id变化的规律呢?
返回开发者工具,点击第一个数据接口的Preview界面,我们可以发现它数据内存储着max_id,而且该值与第二个数据接口的URL的max_id一致。多验证几次,我们就能合理猜测前一个数据接口的max_id就是第二个数据接口URL的参数max_id的值。

所以,我们还需要获取数据接口的max_id。
max_id = response.json()['max_id']
至此,整个逻辑已经非常清楚了。第一个数据接口的url不包含max_id;从第二个数据接口开始,url的max_id参数在前一个数据接口内。所以,我们在获取评论等数据的时候,还需要获取这一数据接口的max_id,从而在之后访问url之前,把max_id参数加进去。
七、完整代码
import time
import requests
import os
from openpyxl import Workbookheaders = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/105','referer': 'https://weibo.com/2951605050/ODUbvvNAy','cookie':input('请输入你的cookies:')
}def fetch_weibo_comments(id, uid, max_id=None):params = {'id': id,'is_show_bulletin': '2','uid': uid,'fetch_level': '0','locale': 'zh-CN','max_id': max_id # 如果有max_id,则添加到参数中}response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params,headers=headers)data = response.json()return datadef write_to_excel(data, ws):titles = ["用户", "时间", "ID", "评论", "地区", "点赞数"]for col_num, title in enumerate(titles, start=1):ws.cell(row=1, column=col_num, value=title)for index, comment in enumerate(data, start=2):ws[f'A{index}'] = comment['user']['screen_name']ws[f'B{index}'] = comment['created_at']ws[f'C{index}'] = comment['id']ws[f'D{index}'] = comment['text_raw']ws[f'E{index}'] = comment['source']ws[f'F{index}'] = comment['like_counts']def main():id = input('请输入主页id:')uid = input('请输入主页uid:')max_id_list = []comment_data = []for i in range(15): #因为微博限制,只能爬取15页if i == 0:data = fetch_weibo_comments(id, uid)max_id_list.append(str(data['max_id']))comment_data.extend(data['data'])else:data = fetch_weibo_comments(id, uid, max_id_list[i - 1])max_id_list.append(str(data['max_id']))comment_data.extend(data['data'])print(f'成功自动爬取第{i + 1}页评论')time.sleep(1)# 写入Excelwb = Workbook()ws = wb.activewrite_to_excel(comment_data, ws)home_dir = os.path.expanduser("~")desktop_path = os.path.join(home_dir, 'Desktop')wb.save(desktop_path + './comment_list.xlsx')if __name__ == '__main__':main()
最后的结果会保存在桌面上,生成一个名为’comment_list’的excel文件。cookie、uid、id在下图位置找到。

八、微博的限制
8.1 评论数量的限制
在代码中,我们只爬取了前15页评论,这是因为微博设限,只能加载前300条评论。

8.2 访问的限制
在试验的时候,我们可以发现第一个数据接口可以短时间内无限次访问,但是其他的数据接口短时间内访问会出现如下图的结果。
因此在代码实践过程中,我们需要格外注意这个限制。

有问题的可以一起交流
相关文章:
Python微博动态爬虫
本文是刘金路的《语言数据获取与分析基础》第十章的扩展,详细解释了如何利用Python进行微博爬虫,爬虫内容包括微博指定帖子的一级评论、评论时间、用户名、id、地区、点赞数。 整个过程十分明了,就是用户利用代码模拟Ajax请求,发…...

【设计模式】单例模式 在java中的应用
文章目录 引言什么是单例模式单例模式的应用场景单例模式的优缺点优点缺点 单例模式的基本实现饿汉式单例模式懒汉式单例模式双重检查锁定静态内部类枚举单例 单例模式的线程安全问题多线程环境下的单例模式线程安全的实现方式1. **懒汉式单例模式(线程不安全&#…...

burp suite 8
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

为什么在Java中super与this不能共存于子类构造器中,其中this起什么作用
在 Java 中,super 和 this 是两个关键字,它们在子类的构造器中有特定的用途和限制。 super 关键字: super 用于从父类(超类)访问成员(属性和方法)或者调用父类的构造方法。 在子类的构造器中&…...

Hypothesis:高效的 Python 测试工具
简介:Hypothesis 是一个强大的 Python 测试库,旨在自动生成各种测试案例,以帮助开发者发现潜在的边界问题和隐藏的错误。通过对输入数据进行智能化的探索,Hypothesis 能够为测试提供更全面的覆盖,避免遗漏一些极端或不…...

Terminus Calculator 计算原理分享
在《使命召唤:黑色行动 6》僵尸模式中,Terminus 关卡的研究办公室里有一个复杂的数学谜题需要解决。为了获得多相共振器,玩家需要计算出三个数字并输入电脑。虽然可以花费 5000 精华来获得答案,但使用 Terminus Calculator 可以更…...

Wwise 使用MIDI文件、采样音频
第一种:当采样音频只有一个文件的时候 1.拖入MIDI文件到Interactive Music Hierarchy层级 2.拖入采样音频到Actor-Mixer Hierarchy层级 3.勾选MIDI显示出面板,设置Root Note与采样音频音高相同,这里是C#5 4.播放测试,成功&…...

在CentOS上无Parallel时并发上传.wav文件的Shell脚本解决方案
在CentOS上无Parallel时并发上传.wav文件的Shell脚本解决方案 背景概述解决方案脚本实现脚本说明使用指南注意事项在CentOS操作系统环境中,若需并发上传特定目录下的.wav文件至HTTP服务器,而系统未安装GNU parallel工具,我们可通过其他方法实现此需求。本文将介绍一种利用Sh…...

【RocketMQ 源码分析(一)】设计理念与源码阅读技巧
RocketMQ 的设计理念与源码阅读技巧 一、设计理念二、源码设计三、源码阅读技巧 一直想仔细仔细看看这个 RocketMQ 的源码,学学它的设计思想和编码风格,没准在以后自己在设计和编码的时候有思考的方向。这是专栏的第一篇 —— 介绍下 RocketMQ 的一些设计…...

独立ip服务器有什么优点?
网站的性能和安全性直接影响到用户体验和业务发,独立IP服务器作为一种主流的托管方式,因其独特的优势而受到许多企业和个人站长的青睐。与共享IP相比,独立IP服务器到底有哪些优点呢? 使用独立IP的用户不必担心与其他网站共享同一…...

如何使用Python库连接Redis
1、redis-py 库封装一个 Redis 工具类可以帮助我们简化 Redis 的操作并提高代码的复用性和可维护性。 安装redis pip install redisimport redis import logginglogging.basicConfig(levellogging.INFO) logger logging.getLogger(__name__)class RedisUtils:def __init__(s…...

Vant UI +Golang(gin) 上传文件
前端基本用法:点击查看 实现代码: const afterRead (file) > {console.log(file);//set content-type to multipart/form-dataconst formData new FormData();formData.append("file", file.file);request.POST("/api/v1/users/up…...

【Unity高级】如何实现粒子系统的间歇式喷射
先看下要最终实现的效果: 代码如下: using UnityEngine; using System.Collections;public class ParticleBurstController : MonoBehaviour {private ParticleSystem _particleSystem; // 获取粒子系统public float burstDuration 2f; // 每次…...

通过linux命令获取自选股票价格及大盘涨跌幅
技术发展与数据获取需求 互联网与金融数据融合:随着互联网的普及和金融市场的数字化发展,金融数据的获取和分析变得更加便捷和重要。投资者希望能够及时、准确地获取股票价格和市场指数等信息,以便做出合理的投资决策。Linux 作为一种强大的操作系统,为数据获取和处理提供…...

透彻理解并解决Mockito模拟框架的单元测试无法运行的问题
本篇的实例基于Maven IDE (VS Code) 运行 在VS Code 运行的时候, 不需要在pom.xml 中添加任何插件就可以在测试类中看到如下的绿色按钮,单击就可以运行使用Mockito 注解 ExtendWith(MockitoExtension.class) 或是 Mockito 代码方式的测试。 不使用注…...

vue3字典数据的显示问题(使用hooks解决)
我们在使用 element-plus的时候,经常会使用一些字典数据, 在搜索框的时候,字典数数要使用 el-select el-option 来显示,当在table表格的时候,我们通常记录的是 字典数据的id , 又要把它改变成 字典数据的 name 属性 因…...

Elasticsearch 单节点安全配置与用户认证
Elasticsearch 单节点安全配置与用户认证 安全扫描时发现了一个高危漏洞:Elasticsearch 未授权访问 。在使用 Elasticsearch 构建搜索引擎或处理大规模数据时,需要启用基本的安全功能来防止未经授权的访问。本文将通过简单的配置步骤,为单节…...

二分查找(带图详解)
优选算法系列 文章目录 优选算法系列前言一、二分查找的思想二、算法使用小总结 三、代码实现四、二分查找拓展4.1、查找第一次出现的target小总结 4.2、target最后出现的位置小总结 五、代码总结 前言 在这篇博客中,我会给大家分享二分查找及其扩展。 这是链接-&…...

【Git】:标签管理
目录 理解标签 创建标签 操作标签 理解标签 标签的作用 标记版本:标签 tag ,可以简单的理解为是对某次 commit 的⼀个标识,相当于起了⼀个别名。例如,在项目发布某个版本的时候,针对最后⼀次 commit 起⼀个 v1.0 这样…...
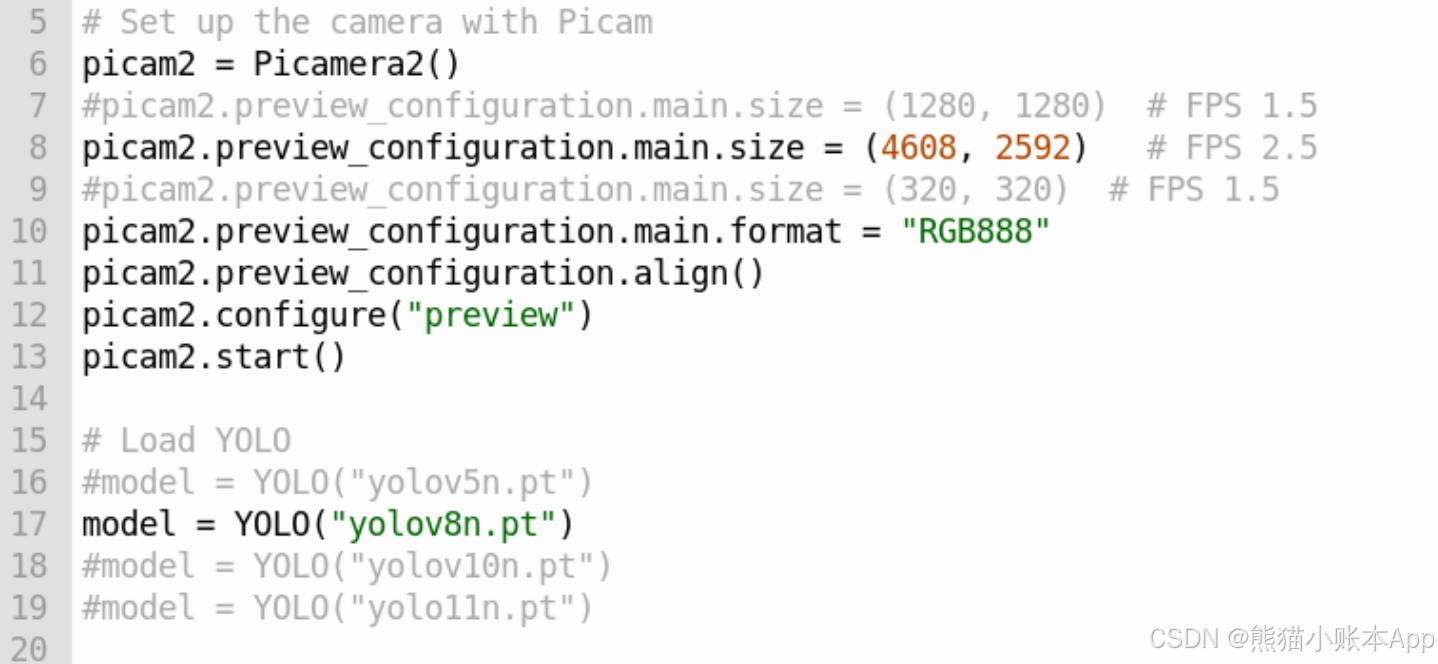
物品识别 树莓派 5 YOLO v5 v8 v10 11 计算机视觉
0. 要实现的效果 让树莓派可以识别身边的一些物品,比如电脑,鼠标,键盘,杯子,行李箱,双肩包,床,椅子等 1. 硬件设备 树莓派 5 raspberrypi.com/products/raspberry-pi-5/树莓派官方摄…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...