【数据结构】文件和外部排序
外部排序
外存信息的存取
- 计算基本存储方式
- 内部存储(主存):断电后数据会丢失,访问速度快,成本高容量通常较小
- 外部存储(辅存):断电后数据不会丢失,访问速度较慢,成本低容量通常较大
- 常见外存
- 磁带:低成本存储,适合长期归档,低能耗,但访问速度慢。
- 磁盘(HDD):提供较高性价比,适合大量数据存储,随机读写较慢,耐用性较好。
- 固态硬盘(SSD):速度快,无机械部件,适合快速访问需求,价格相对高但持续下降,寿命受写入量限制。
- 磁带存储技术
- 磁带结构:磁带是一种涂有磁性材料的窄带
- 读写机制:磁带通过驱动器控制转动,以200英寸/秒的速度移动,并且是按需启停的
- 间隙(IRG):由于启停需要一段时间才能达到稳定状态,所以字符组间需留空白区(IRG),影响磁带利用率
- 成块技术:为提高磁带利用率,将多个字符组合并成块写入,减少IRG,增加数据紧凑性。物理块大小通常限制在1K字节到8K字节之间,以平衡效率和可靠性(太大会出错)
- I/O操作优化:通过成块,一次I/O可读取整个物理块到缓冲区,减少单个字符组的读写操作,提升效率。
外部排序指的是大文件的排序,即待排序的记录存储在外存储器上,在排序过程中需进行多次的内、外存之间的交换。 - 在磁带上读写一块信息所需的时间 T I / O = t a + n ∗ t w T_{I/O}=t_a+n*t_w TI/O=ta+n∗tw,其中 t a t_a ta为延迟时间(读/写头到达传输信息所在物理块起始位置所需时间), t w t_w tw为传输一个字符的时间

- 磁盘存储技术
- 直接存取:与顺序存取的磁带不同,磁盘允许直接存取任何字符组
- 容量与速度:磁盘容量大,存取速度快,远超磁带。
- 盘片组成:磁盘可以是单片或多片盘组,每片有两个面,但最顶和最底面不存信息。
- 驱动器功能:磁盘驱动器负责执行读/写操作,盘片绕主轴高速旋转。
- 磁头类型:固定头盘的每个磁道有独立磁头,而活动头盘磁头可移动
- 定位机制:磁盘上信息定位需用
柱面号、盘面号、块号的三维地址。 - 读写时间:磁盘读写时间包括寻查时间、等待时间和传输时间。
- 优化策略:相关数据应放在同一柱面或邻近柱面,以减少磁头移动次数,提高效率。
- 磁盘上读取一块信息所需的时间 T I / O = t f + t l + n ∗ t w T_{I/O}=t_{f}+t_{l}+n*t_w TI/O=tf+tl+n∗tw
- t f t_{f} tf寻道时间:将磁头移动到指定磁道所需要的时间
- t l t_{l} tl延迟时间:磁头定位到某一磁道的扇区所需要的时间
- t w t_w tw传输时间:从磁盘读出或向磁盘写入数据所经历的时间
- 启动时间:(一般忽略):控制器的启动时间。

外部排序的方法
- 外部排序的步骤
- 按可用内存大小,将外存上含n个记录的文件分成若干长度为l的子文件或端,这些子文件和段称为
归并段或顺串,将这些段一次读入内存,然后进行内部排序,将获得的有序的子文件重新写入外存。 - 对这些有序子文件进行逐趟归并,直至得到整个有序文件。
- 按可用内存大小,将外存上含n个记录的文件分成若干长度为l的子文件或端,这些子文件和段称为
- 二路归并算法步骤
- 每次将两个页块读取到磁盘中,进行内排序后写回到磁盘中
- 然后重复上述步骤,两两归并,直到形成一个有序文件

- 提高外存读写效率的主要方法
- 多路归并:通过多路归并可以减少文件归并的趟数,从而提高效率。
- 增加归并段长度:增加归并段的长度可以减少初始归并的数目,降低处理时间。
- 最佳归并方案:根据不同归并段的长度,采取最佳归并方案以优化性能。
- 外排序的总时间由三部分组成:
- 产生初始归并段的时间(内排序):
初始归并段数目 m × 得到一个归并段的内排序时间 t i s 初始归并段数目m \times 得到一个归并段的内排序时间t_{is} 初始归并段数目m×得到一个归并段的内排序时间tis - I/O操作的时间: 总的读写次数 d × 一次读写的时间 t i o 总的读写次数d \times 一次读写的时间t_{io} 总的读写次数d×一次读写的时间tio
- 内部归并的时间:
归并的趟数 s × 对 u 个记录进行一趟内部归并排序的时间 t m g 归并的趟数s \times 对u个记录进行一趟内部归并排序的时间t_{mg} 归并的趟数s×对u个记录进行一趟内部归并排序的时间tmg
- 产生初始归并段的时间(内排序):
- 影响外排序效率的主要原因:内、外存之间数据交换的速度。
多路平衡归并的实现
- 二路归并
- 令 u 个记录分布在两个归并段上,按 merge 过程进行归并。
- 每得到归并后的一个记录,仅需一次比较即可,得到含 u 个记录的归并段需进行 u - 1 次比较。
- k路归并
- 令 u 个记录分布在 k 个归并段上,归并后的第一个记录是 k 个归并段中关键字最小的记录,需从每个归并段的第一个记录的相互比较中选出最小者,进行 k - 1 次比较。
- 每得到归并后的有序段中的一个记录,都要进行
k - 1 次比较,得到含 u 个记录的归并段需进行(u - 1)(k - 1)次比较。

- 多路归并的优化
- 问题:k越大,内部归并的代价也会增大,当其大于从外存读取减少的代价,则内部归并就失去了其意义。
- 解决方法:使用败者树,在k-路归并时,用于快速选出关键字最小的记录,从而减少比较次数
- 对比:普通多路归并需要k-1次比较,而败者树只需要 O ( k l o g 2 k ) O(klog_2k) O(klog2k)的构建时间,但经过 O ( l o g 2 k ) O(log_2k) O(log2k)次比较即可。假设k=5,则普通多路需要4次,败者树只需要2.321928次
- 三种最值结构的不同
- 堆:每次调整需要父亲和左右孩子进行比较,比较两次
- 胜者树:每次调整需要和兄弟节点进行比较
- 败者树:每次调整著需要和父亲节点进行比较
- 败者树有几个特点
- 是一颗用于高效合并 k 个有序序列的完全二叉树
- 败者树的根结点记录的是胜者,需要加一个结点来记录整个比赛的最终败者
- 建立一棵败者树的时间代价为 O ( k l o g 2 k ) O(klog_2k) O(klog2k)
- 从建立好的败者树获取最值的时间代价为 O ( l o g 2 k ) O(log_2k) O(log2k)
- 败者树的建立和重构仅仅涉及到父子节点之间的比较
- 生成过程
- 所有数字进行标号作为叶子节点
- 每次比较将
剩余的数值大的叶子节点的标号写入 - 最后根节点存储

- 插入过程
- 再继续新插入的节点从叶子节点开始,每次与父亲节点进行比较,直到生成最终败者

- 再继续新插入的节点从叶子节点开始,每次与父亲节点进行比较,直到生成最终败者
- 败者树的优缺点
- 优点:败者树优化使得内部归并的比较次数与 k 无关,所以只要内存空间允许,增大归并路数 k 将有效地减少归并树的高度,从而减少 I/O 次数,提高外部排序的速度。
- 当归并路数 k 增大过大时,相应地会增加输入缓冲区的个数。所以会使得内外存交换数据的次数增大

置换-选择排序
- 概述
- 作用
- 在处理大规模数据时,由于内存容量有限,无法一次性将所有数据加载到内存中进行排序
- 置换 - 选择排序可以有效地在有限内存空间下,将大规模数据分批次处理,生成相对有序的归并段,以便后续进行归并操作,最终实现对大规模数据的排序。
- 作用
- 步骤
- 设初始待排文件为 FI,初始归并段输出文件为 FO,内存工作区为 WA,FO 和 WA 的初始状态为空, WA 可容纳 w 个记录。
- ① 从 FI 输入 w 个记录到工作区 WA 。
- ② 从 WA 中选出其中关键字取最小值的记录,记为 MINIMAX 记录。
- ③ 将 MINIMAX 记录输出到 FO 中去。
- ④ 若 FI 不空,则从 FI 输入下一个记录到 WA 中。
- ⑤ 从 WA 中所有关键字比 MINIMAX 记录的关键字大的记录中选出最小关键字记录,作为新的 MINIMAX 记录。
- ⑥ 重复 ③-⑤,直至在 WA 中选不出新的 MINIMAX 记录为止,由此得到一个初始归并段,输出一个归并段的结束标志到 FO 中去。
- ⑦ 重复 ②-⑥,直至 WA 为空。由此得到全部初始归并段。
- 【注:上述算法,在 WA 中选择 MINIMAX 记录的过程需利用败者树来实现。】

最佳归并树
- 作用:将长度不等的归并段进行多路平衡归并,通过构造最佳归并树进行优化
- 特点
- 带权路径长度最小:最佳归并树是一棵哈夫曼树,其带权路径长度最小,这意味着在进行归并操作时,总的读写次数最少,从而提高了外部排序的效率。
- 减少 I/O 操作:通过最小化带权路径长度,最佳归并树可以减少归并过程中的输入 / 输出(I/O)操作次数,这对于处理大规模数据非常重要,因为 I/O 操作通常是外部排序中最耗时的部分。
- 证明题

- 构建步骤
- 确定归并段数量和权值:首先确定初始归并段的数量,并为每个归并段赋予一个权值,通常权值可以是归并段的长度或记录数量。
- 构建哈夫曼树:将权值最小的两个归并段作为叶子节点,构建一棵二叉树,其根节点的权值为两个叶子节点权值之和。重复这个过程,每次选择权值最小的两个节点构建二叉树,直到所有的归并段都被包含在一棵树中。
- 确定归并顺序:根据构建好的哈夫曼树,从根节点开始,按照左子树优先的顺序进行遍历,确定归并的顺序。每次归并两个子树对应的归并段,直到所有的归并段都被归并为一个有序的文件。

文件
有关文件的基本概念
- 基本概念:
- 文件:性质相同的记录的集合。
- 记录:文件中存取的基本单位
- 数据项/字段:文件可使用的最小单位
- 文件的操作
- 检索:顺序、按关键字和随机存取
- 修改:插入、删除和更新
- 排序:可以实时处理或批量处理
- 文件的结构
- 逻辑结构:线性结构。
- 物理结构
- 顺序文件:按记录进入文件的先后顺序存放、其逻辑顺序和物理顺序一致的文件
- 索引文件:在文件本身外,建立一张指明逻辑记录和物理记录之间映射关系的表
- 索引顺序存取方法(ISAM)文件
- 虚拟存储存取方法(VSAM)文件
- 散列文件:利用散列存储方式组织的文件,亦称为直接存取文件。
- 多关键字文件:对被查询的次关键字也建立相应的索引,则这种包含有多个次关键字索引的文件
顺序文件
- 定义:文件物理结构中的记录顺序和文件逻辑结构中的记录顺序一致
- 组织形式:
- 连续文件(顺序):次序相继的记录其存储位置相邻;
- 串联文件(链式):物理记录之间的顺序由指针相链。
- 特点:
- 适合进行顺序存取,但不便于进行直接存取,直接访问某个特定记录变得低效,尤其是当文件很大时。
- 若记录是有序的,则可以进行折半查找
- 插入新的记录只能加在文件的末尾,因为文件中间的记录不能被移动。
- 删除记录时,只作逻辑标记,因为物理删除记录可能时间较长
- 更新副本:更新顺序文件中的记录通常需要创建一个新文件,将未更改的记录和更新后的记录写入新文件,然后替换旧文件。
- 顺序文件的批处理操作
- 定义:在顺序文件中,插入、删除和更新操作通常通过批处理方式进行,以提高效率
- 操作步骤:
- 创建主文件(本体记录):主文件是已经存在的有序文件,包含当前的所有记录。
- 创建事务文件(增量逻辑):事务文件包含所有需要插入和更新的记录。这些记录也需要被排序,以便于后续的合并操作。
- 合并:将主文件和事务文件合并为一个新的有序文件。这个过程类似于归并两个有序表。
- 删除操作:在合并过程中,可以同时执行删除操作。通常,删除操作是通过标记已删除的记录来实现的,然后在合并时忽略这些记录。
- 生成新的主文件:合并完成后,新的有序文件成为新的主文件,替换旧的主文件。
- 假设主文件中有 n n n 个记录,事务文件中有 m m m个记录:
- 对事务文件进行排序的时间复杂度为 O ( m l o g m ) O(m log m) O(mlogm)。
- 内部归并的时间复杂度为 O ( m + n ) O(m+n) O(m+n)。
- 因此,总的内部处理的时间复杂度为 O ( m log m + n ) O(m \log m + n) O(mlogm+n)
- 假设对外存进行一次读/写为 s s s个记录,则整个批处理过程中读/写外存的次数为:
- 读取主文件 n s \frac{n}{s} sn 次。
- 读取事务文件 m s \frac{m}{s} sm 次。
- 写入新主文件 m + n s \frac{m+n}{s} sm+n次。
- 整个批处理过程中读/写外存的总次数为 2 × ( m s + m + n s ) 2 \times \left( \frac{m}{s} + \frac{m+n}{s} \right) 2×(sm+sm+n),只需要对事务文件进行处理
- 文件的处理方式
- 实时处理:响应时间要求严格
- 批量处理:响应时间不是重要因素,提高整体效率是重要因素
索引文件
- 基本概念
- 组成:
- 主文件:文件本身,包含所有记录
- 索引表:在文件外建立的表,指明逻辑记录和物理记录之间的对应关系。
- 通常,索引文件中的主文件是无序文件,索引是(按关键字有序)的有序文件。
- 组成:
- 索引表组成:
- 索引表由多个索引项组成。
- 每个索引项包括主关键字和该关键字所在记录的物理地址。
- 索引表必须按主关键字有序,而主文件本身可以有序或无序。
- 索引顺序文件:
- 主文件按主关键字有序。
- 只对一个记录块(含多个有序记录)建立一个索引项,
- 索引顺序文件中的索引表为稀疏索引
- 索引非顺序文件/索引文件
- 主文件按主关键字无序。
- 为每个记录建立一个索引项,称为
稠密索引。 - 适合于随机存取,不适合顺序存取。
- 索引非顺序文件中的索引表为稠密索引
- 区别
- 索引顺序文件适合于随机存取和顺序存取。
- 索引顺序文件的索引是稀疏索引,占用空间较少,是最常用的文件组织方式。
- 最常用的索引顺序文件类型包括ISAM文件和VSAM文件。
- 若记录很大使得索引表也很大时,可对索引表再建立索引,称为查找表,通常可达四级索引。
- 索引文件的存储
- 索引区:存放索引表,占用空间较小
- 数据区:存放主文件。
- 存储过程:
- 文件建立时,开辟一个索引区,通常固定在磁盘的一个或多个磁道上。
- 写入记录时,在索引区相应登入一个索引项,记录关键字和存储地址。
- 文件建立后,将索引读入内存缓冲区,按关键字排序。
- 最终将排序好的索引项写回到磁盘上的索引区。
- 检索过程
- 预查找/读索引:将含有索引区的页块送入内存,查找所需记录的物理地址。
- 读取记录/读文件:根据已查到的地址,从外存读取所查的记录
- 注意事项:
- 索引表不大时:索引表可一次读入内存,检索只需两次访问外存。
- 查找方法:由于索引表有序,可用顺序查找或二分查找等方法。
ISAM文件
- 定义:
- ISAM(Indexed Sequential Access Method)是索引顺序存取方法的缩写。
- 专为磁盘存取文件设计,采用静态索引结构。
- 文件结构:
- 记录按关键字大小顺序存放在磁盘的连续或相邻的存储区中。
- 文件划分为若干个记录块,只为每块中关键字最大(或最小)的记录设置一个索引项。
- 索引结构:
- 磁盘上的数据文件可以建立盘组、柱面和磁道三级索引。
- 每个柱面建立一个磁道索引,索引项包括关键字和指针。
- 柱面索引的索引项包括关键字和指向磁道索引的位置。

- 检索操作:
- 从主索引出发找到相应的柱面索引。
- 从柱面索引找到记录所在柱面的磁道索引。
- 从磁道索引找到记录所在磁道的第一个记录的位置,然后顺序查找。
- 插入操作:
- 将插入记录置于数据区的末尾,并在索引表中插入索引项。
- 需要移动记录并将同一磁道上最后一个记录移至溢出区,同时修改磁道索引项。
- 删除操作:
- 找到待删除的记录,在其存储位置上作删除标记。
- 不需要移动记录或改变指针。
- 溢出区:
- 每个柱面上还开辟有一个溢出区。
- 磁道索引项中有溢出索引项,这是为插入记录所设置的。
- 文件整理:
- 经过多次的增删后,文件的结构可能变得很不合理。
- 需要周期地整理ISAM文件,把记录读入内存,重新排列,复制成一个新的ISAM文件,填满基本区而空出溢出区。
- 溢出区的设置方法:
- 集中存放:整个文件设一个大的单一的溢出区。
- 分散存放:每个柱面设一个溢出区。
- 集中与分散相结合:记录先移至每个柱面各自的溢出区,待满之后再使用公共溢出区。
- 基本区与溢出区的结构:
- 基本区是顺序存储结构。
- 溢出区是链表结构。
- 同一磁道溢出的记录由指针相链。
VSAM文件
- 定义:
- VSAM(Virtual Storage Access Method)是虚拟存储存取方法的缩写。
- 采用B+树作为动态索引结构的索引顺序文件组织方式。
- B+Tree 数据结构(MySQL InnoDB 的默认索引数据结构)
- 定义:B+树可以分两部分进行理解
由非叶子结点组成的多路平衡查找树用于快速的随机查找操作由叶子结点组成的按主键顺序的双链表用于高效的数据的增删操作和基于范围的顺序查找
- 多路平衡查找树
多路表示是一棵多叉树(m>2),每个非叶子结点由两部分组成按主键顺序的子节点索引链表:每个子节点索引指向一个子节点,且索引结点键值等于索引子节点的最小键值(类似目录查找)。最大和最小键值:主要用于快速定位和过滤查询请求的。
平衡表示B+树的每个子树的高度是相等的,尽可能“矮胖”查找表示B+树的快速查找能力较强。相比B树,非叶子结点不存放数据:可以存放更多的索引,使得树更加“矮胖”,极大减少比较耗时的I/O操作。搜索复杂度为O ( l o g d N ) O(log_dN) O(logdN):当最大分支数d大于100时,千万级数据量的查询操作也只需做3~4次的磁盘 I/O 操作,即树的高度只有3~4层。
- 双链表
- 叶子结点的组成:一个叶子结点通常存储多个数据记录的物理地址,
页目录由槽组成,索引数据记录分组。数据记录分组由数据记录组成,按主键顺序存储可由二分法进行查找。 - 提高磁盘IO效率:页是磁盘IO的基本单位(默认为16KB),通常与叶子结点一一对应,但可以根据业务场景进行调节
- 顺序查找和增删快:B+Tree 的层内结点均
按指定键顺序进行双链表链接。可以高效满足数据的增删操作和基于范围的顺序查找

- 叶子结点的组成:一个叶子结点通常存储多个数据记录的物理地址,
- 定义:B+树可以分两部分进行理解
- VSAM文件的逻辑存储单位:
- 控制区间:用户进行一次存取的逻辑单位,可看作逻辑磁道,大小与物理磁道无关。
- 控制区域:由若干控制区间和它们的索引项组成,可看作逻辑柱面。
- VSAM文件的记录分布:
- 文件初建时,控制区间内的记录数不足额定数,有的控制区间的记录数可能为零。
- 顺序集和索引集:
- 顺序集:本身是一个单链表,包含文件的全部索引项。
- 顺序集中的每个结点即为B+树的叶子结点。
- 索引集:结点即为B+树的非叶结点。
直接存取文件/散列文件
- 基本概念
- 定义:根据记录的关键字“直接”得到记录在外存上的映象地址。
- 哈希文件的结构:
- 允许多个记录映象到同一个地址上。
- 外存储器中存放多个记录的“数据块”称为“桶”。
- 由哈希函数得到的映象地址为“桶地址”。
- 哈希函数:根据文件中关键字的特点设计“哈希函数”。
- 处理冲突:当多个记录可能映象到同一个桶地址,需要有方法处理这种冲突。
- 检索
- 只能进行按关键字的查找,不能进行顺序查找
- 先在基桶内进行查找,若基桶内不存在,则再到溢出桶中进行查找
- 插入:当查找不成功时,将记录插入在相应的基桶或溢出桶内。
- 删除
- 定义:对被删记录作特殊标记,而不是真正从存储中删除。
- 操作: 标记记录为已删除。
- 直接存取文件的优缺点
- 优点
- 记录随机存放:不需要进行排序。
- 插入、删除方便:操作简单快捷。
- 存取速度快:直接通过哈希函数定位记录。
- 节省存储空间:不需要索引区。
- 缺点
- 不能进行顺序存取:只能按关键字查找。
- 重组文件:在经过多次插入和删除操作之后,可能需要进行“重组文件”的操作以优化文件结构。
- 优点
多关键字文件
- 主索引
- 按主关键字顺序构成的串联文件
- 次索引
- 对各个次关键字项建立的索引记录文件
- 次索引包含指向记录的指针
- 多关键字文件的组织形式
-
多重链表文件
- 记录按主关键字的顺序构成一个串联文件,并建立主关键字的索引(称为主索引);
- 对每一个次关键字项建立次关键字索引(称为次索引),所有具有同一关键字的记录构成一个链表。(次索引)
- 主索引为非稠密索引,次索引为稠密索引;
- 每个主索引项包括次关键字、头指针和链表长度。
- 容易插入,但是删除需要在每个次索引表中进行删除


-
倒排文件
- 将所有具有相同次关键字的记录构成一个次索引顺序表。
- 在次索引顺序表中仅存放记录的“主关键字”或记录的“物理记录号”。
- 次索引项中的“指针”指向相应的次索引顺序表。
- 插入和删除倒排表也要维护,处理困难

-
- 次关键字索引表的结构
- 次关键字索引表本身的结构可以是顺序表,也可以是树表或哈希表。
- 结构的选择视具体的次关键字的特性而定。
主要参考
- 数据结构ppt
相关文章:
【数据结构】文件和外部排序
外部排序 外存信息的存取 计算基本存储方式 内部存储(主存):断电后数据会丢失,访问速度快,成本高容量通常较小外部存储(辅存):断电后数据不会丢失,访问速度较慢&#x…...

新手学习:网页前端、后端、服务器Tomcat和数据库的基本介绍
首先一点,不管是那个框架开发的网页前端,最后都需要Build,构建完毕以后都是原始的HTML CSS JS 三样文件! 网页前端 目录结构 在开始开发网站之前,首先需要了解如何组织文件。一个简单的网页项目通常会有以下几个文件夹和文件&…...

机器学习贝叶斯模型原理
一、引言 在机器学习与数据分析的广袤天地中,贝叶斯模型犹如一颗璀璨的明星,闪耀着独特的光芒,为众多领域的分类、预测等任务提供了强大的理论支撑与实用解法。然而,对于许多初涉此领域的小伙伴而言,贝叶斯模型背后的…...

【C++】实现100以内素数的求解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯代码概览💯代码结构与逻辑分析1. 包含的头文件和命名空间2. 素数判断函数 isPrime功能输入与输出核心逻辑数学背景 3. 主函数 main功能核心逻辑输出示例 &#…...

Python 浏览器自动化新利器:DrissionPage,让网页操作更简单!
Python 浏览器自动化新利器:DrissionPage,让网页操作更简单! 文章目录 Python 浏览器自动化新利器:DrissionPage,让网页操作更简单!🚀 引言🌟 DrissionPage简介🛠️ 三大…...

Rust学习笔记_13——枚举
Rust学习笔记_10——守卫 Rust学习笔记_11——函数 Rust学习笔记_12——闭包 枚举 文章目录 枚举1. 定义1.1 无值变体1.2 有值变体1.3 枚举与泛型的结合 2. 使用2.1 和匹配模式一起使用2.2 枚举作为类型别名 3. 常用枚举类型 在Rust编程语言中,枚举(enum…...

Postgresql 格式转换笔记整理
1、数据类型有哪些 1.1 数值类型 DECIMAL/NUMERIC 使用方法 DECIMAL是PostgreSQL中的一种数值数据类型,用于存储固定精度和小数位数的数值。DECIMAL的精度是由用户指定的,可以存储任何位数的数值,而小数位数则由用户自行定义。DECIMAL类型的…...

AI开发:卷积神经网络CNN原理初识,简易例程 - 机器学习
一 、卷积神经网络是什么 (1)印象 今天说的CNN,并不是我们熟知的美国有线电视新闻网。 那什么是CNN呢? Convolutional Neural Networks, CNN)简单来说,就是用一个筛子来筛面粉的。 筛子就是卷积核&…...
)
详细介绍vue的递归组件(重要)
递归组件在 Vue 中是一个非常强大的概念,尤其在渲染层级结构(如树形结构、嵌套列表、评论系统等)时,能够极大地简化代码。 什么是递归组件? 递归组件就是一个组件在其模板中引用自身。这种做法通常用于渲染树形结构或…...

【单片机基础知识】基础知识(CortexM系列、STM32系统框架、存储器映射、寄存器映射)
1. CortexM系列介绍 ARM官方资料: 📎Arm Cortex-M4 Processor Datasheet.pdf📎Arm-Cortex-M7-Processor-Datasheet.pdf📎Arm Cortex-M Comparison Table_v3.pdf📎Arm Cortex-M3 Processor Datasheet.pdf 课程资料&a…...

yolov5导出命令
python export.py --weights yolov5s.pt --img-size 640 --batch-size 1 --device cpu --include onnx 关闭动态输入,cpu导出 检测onnx模型能否加载成功指令: python detect.py --weights yolov5s.onnx --dnn 终端调用detect.py检测图片命令&…...

RabbitMQ的常用术语介绍
出版商 “出版商”一词在不同的上下文中有不同的含义。一般来说,在消息传递中 发布者(也称为“生成者”)是应用程序(或应用程序实例) 发布 (生成) 消息。同一应用程序也可以使用消息 因此同时也…...

Docker魔法:用docker run -p轻松开通容器服务大门
前言 “容器”与“虚拟化”作为现代软件开发和运维中的关键概念,已经广泛应用于各个技术领域。然而,在使用 Docker 部署应用时,常常会遇到这样的问题:容器正常运行,却无法让外界访问其内部服务?即使容器内的应用顺利启动,外部无法通过浏览器或 API 进行连接。此时,doc…...

【后端面试总结】Redis过期删除策略
Redis会将每个设置了过期时间的key放入一个独立的字典中,以后会定时遍历这个字典来删除到期的key。除了定时遍历之外,它还会使用惰性策略来删除过期的key。所谓惰性策略就是在客户端访问这个key的时候,Redis对key的过期时间进行检查ÿ…...

数字图像处理(15):图像平移
(1)图像平移的基本原理:计算每个像素点的移动向量,并将这些像素按照指定的方向和距离进行移动。 (2)平移向量包括水平和垂直分量,可以表示为(dx,dy)ÿ…...

高级java每日一道面试题-2024年12月08日-JVM篇-什么是类加载器?
如果有遗漏,评论区告诉我进行补充 面试官: 什么是类加载器? 我回答: 在Java高级面试中,类加载器(ClassLoader)是一个重要的概念,它涉及到Java类的加载和初始化机制。以下是对类加载器的详细解释: 定义与作用 类加…...

JAVA子类的无参构造器中第一行的super
在 Java 中,子类的构造器是否需要显式调用 super 取决于父类(超类)的构造器。 如果父类有一个无参构造器: 如果父类有一个无参构造器,那么子类的构造器可以不显式调用 super。在这种情况下,如果子类构造器的…...

mysql程序介绍,选项介绍(常用选项,指定选项的方式,特性),命令介绍(查看,部分命令),从sql文件执行sql语句的两种方法
目录 mysql程序 介绍 选项 介绍 常用选项 指定选项的方式 编辑配置文件 环境变量 选项特性 指定选项 选项名 选项值 命令 介绍 查看客户端命令 tee/notee prompt source system help contents 从.sql文件执行sql语句 介绍 方式 source 从外部直接导入…...

Unity教程(十九)战斗系统 受击反馈
Unity开发2D类银河恶魔城游戏学习笔记 Unity教程(零)Unity和VS的使用相关内容 Unity教程(一)开始学习状态机 Unity教程(二)角色移动的实现 Unity教程(三)角色跳跃的实现 Unity教程&…...

lanqiaoOJ 3744:小蓝的智慧拼图购物 ← pair+优先队列
【题目来源】https://www.lanqiao.cn/problems/3744/learning/【题目描述】 在小蓝的生日那天,他得到了一个由神秘人赠送的拼图游戏,每个拼图都有其特定的价值和相应的优惠券。小蓝决定要买下所有的拼图,但他希望能尽可能地节省花费。小蓝手中…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...
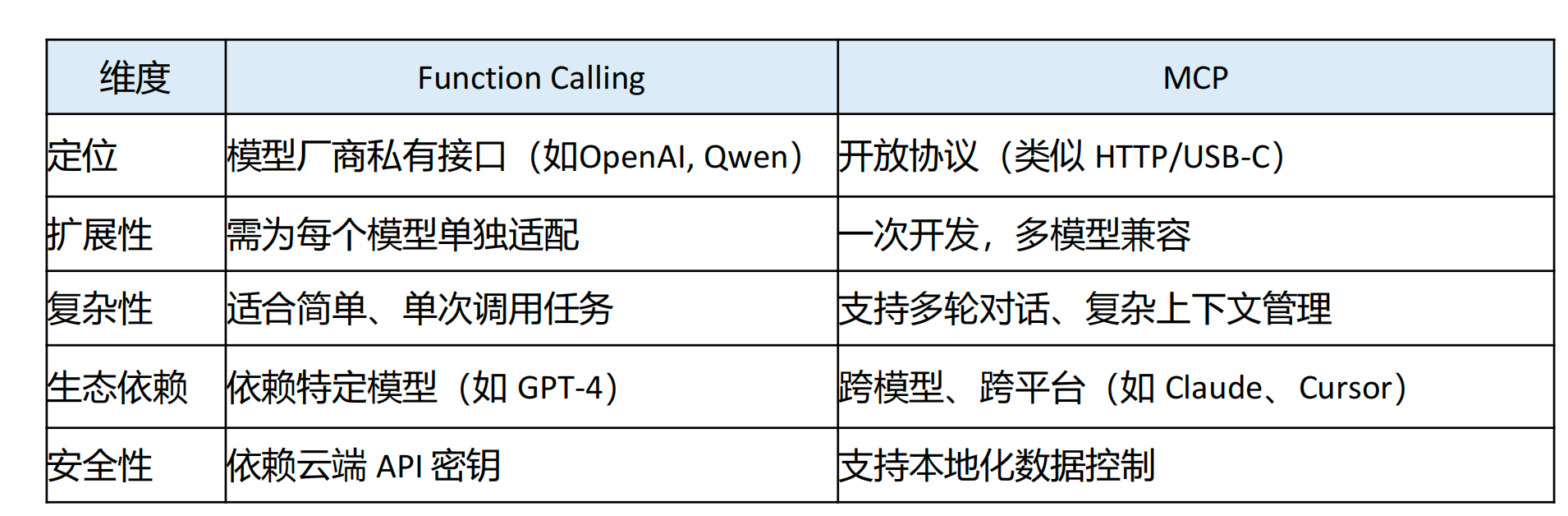
MCP和Function Calling
MCP MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而…...

RFID推动新能源汽车零部件生产系统管理应用案例
RFID推动新能源汽车零部件生产系统管理应用案例 一、项目背景 新能源汽车零部件场景 在新能源汽车零部件生产领域,电子冷却水泵等关键部件的装配溯源需求日益增长。传统 RFID 溯源方案采用 “网关 RFID 读写头” 模式,存在单点位单独头溯源、网关布线…...