Flink+Paimon实时数据湖仓实践分享

随着 Paimon 近两年的推广普及,使用 Flink+Paimon 构建数据湖仓的实践也越来越多。在 Flink 实时数据开发中,对于依赖大量状态 state 的场景,如长周期的累加指标计算、回撤长历史数据并更新等,使用实时数仓作为中间存储来代替 Flink 的内部状态 state 是非常有必要的。
本文主要分享了使用 Paimon 作为实时状态存储,并在 Flink 中通过 Lookup 维表 Join 的方式进行状态查询和更新的应用实践。

简介
▐ 是什么
Apache Paimon是一种流批统一的数据湖存储格式,结合 Flink 可以构建流批处理的实时湖仓一体架构。Paimon 具有实时更新的能力(可应用于对时效性要求不太高的场景,如 1-5 分钟),其主键表支持大规模更新写入,具有非常高的更新性能,同时也支持定义合并引擎,按照自定义的方式更新记录。
Paimon 底层使用 OSS/HDFS 等作为存储,同时数据文件以 LSMtree 的格式进行组织,具有更优的实时数据更新能力和完整的流处理能力。
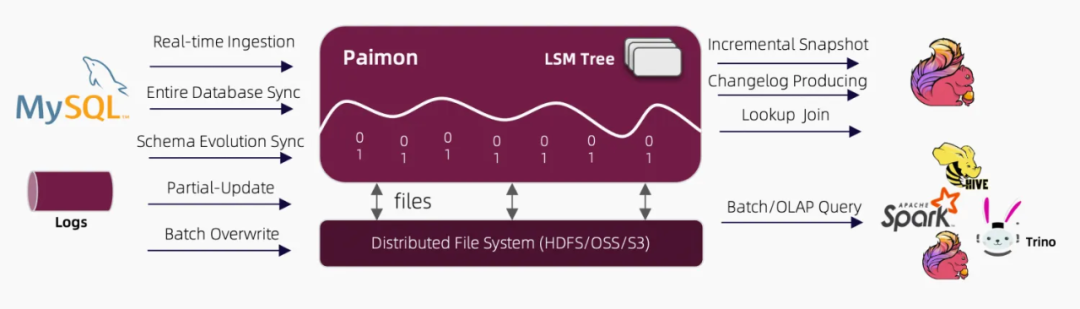
图片来源于 paimon 官网
▐ 为什么
1. 低成本、可扩展性:实时数仓产品也可以作为 flink 的中间存储,比如 hologres,但是 Paimon 的存储成本约为其的 1/9(通过查询官网,OSS 的存储为 0.12 元/GB/月,Hologres 为 1 元/GB/月)。同时数据湖相比于数据仓库可以与更多的大数据引擎(Hive/Spark/Trino 等等)兼容,解决数据孤岛和数据冗余存储的问题。
2. 实时性能:相比于其他的数据湖产品,Paimon 是天然面向 Flink 设计而诞生的,相比于 hudi(面向 Spark 批处理设计)、Iceberg 等,Paimon在与 Flink 结合具有更优的处理大批量数据的 upsert 能力,同时数据更新时效性最短可支持到 1 分钟,且性能稳定。
应用案例▐ 1. 排除逆向退款的用户下单标签
需求背景
目前奥格运营平台提供的下单相关的实时标签(如用户最近一次实物购买时间等),都是基于实时下单流来加工的,即不考虑用户后续的逆向退款情况。然而,运营同学需要实时圈选出近一段时间未成功购买(未下单或下单后退款)的人群,制定运营策略及发放权益,提高复购率。因此,该需求可以明确为:构建手淘用户排除逆向退款后的最近一次下单时间的实时标签。
问题分析
用户的下单行为和退款行为是有时序性的,因此当用户在下单后发生逆向退款行为时,需要回撤之前的订单结果,并回溯最近一次支付成功且未退款的订单信息。由于下单流和退款流是两条独立的流,因此我们首先考虑到使用双流 join 的方法将他们关联起来,但是会有如下两个限制:
1. 时效性限制:由于用户的两个行为发生的时间间隔是无法确定的(用户可能下单后立刻退款,也可能隔几个月后再申请退款),interval join 和 window join 对窗口的间隔长度有较大的限制,而 regular join 会受到状态存储大小的限制,无法将间隔时间很长的两条流关联在一起。
2. 状态依赖限制:这些方法都是完全依赖状态,任务一旦无状态重启,状态会丢失,导致数据不准确。
解决方法
为了突破上述限制,考虑采用 Paimon 表作为中间存储表,存储用户在某商家的历史订单的下单时间,当退款流来的时候,可以去进行 lookupjoin 维表关联,获取该用户在该商家的历史订单信息,并排除掉所有退款成功的订单后,输出最近一次未退款的订单时间。
整体方案设计
方案优势:
不依赖状态,可以节省大量内存,且任务可以随时无状态启动。
突破业务行为时间上的限制,即使用户在下单后 1 年退款成功,依然可以实现回撤。
方案不足:
Paimon 表固有的数据时效性限制。
存储在 Paimon 表中的历史订单数限制,不可能无限存储某用户 x 商家维度近一年的所有订单,通过和业务沟通,确定只需要存储近 10 单,即在极端情况下,如果用户近 10 单全部退款,则无法再回溯。
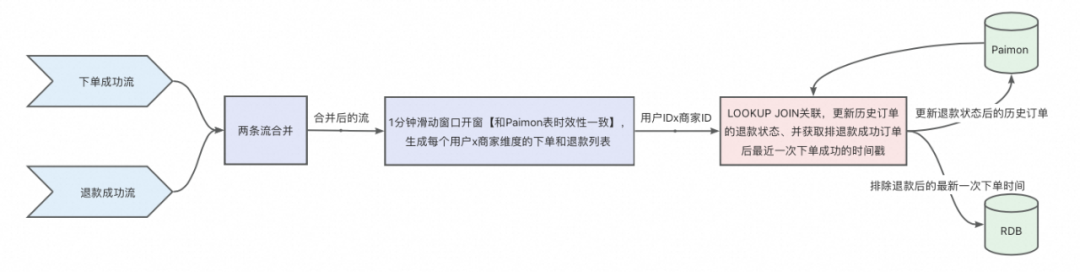
Paimon 维表设计
CREATE TABLE `paimon-catalog`.`paimon-db`.test_dws_pay_refund (test_buyer_id VARCHAR,test_seller_id VARCHAR,test_order_dict VARCHAR, -- 历史订单字典,格式见下文说明PRIMARY KEY (test_buyer_id, test_seller_id) NOT ENFORCED
) WITH ('merge-engine' = 'deduplicate', -- 使用预聚合数据合并机制产生聚合表'changelog-producer' = 'none','bucket' = '1000','bucket-key' = 'test_buyer_id,test_seller_id','delete-file.thread-num' = '32'
);说明:
1. 非分区表:该维表主要是用于存储用户的历史订单信息,与日期没有直接关系,因此直接设置为非分区表。
2. 主键表:主键设置为买家 ID+商家 ID,合并引擎采用 deduplicate,即保留同一主键下最新一条数据。
3. 分桶数量:因为要进行维表 join,为了能够采用 shuffle 策略,设置固定分桶,提前探查历史数据后,预估维表大小在 TB 级别,遵循每个桶的数据量大小在 2GB 左右的官方建议,设置分桶数量为 1000。
4. 不产生 changelog:由于该表只作为维表使用,为了节省资源,可以不产生 changelog。
5. 字段含义:对于非主键字段,test_order_dict 用于存储用的历史订单信息,格式为:${order_id}:${pay_timestamp}_${is_refund_flag},其中 order_id 表示订单号,pay_timestamp 表示下单时间,is_refund_flag 表示是否退款。
开发经验分享
1. 分桶数量设置不合理
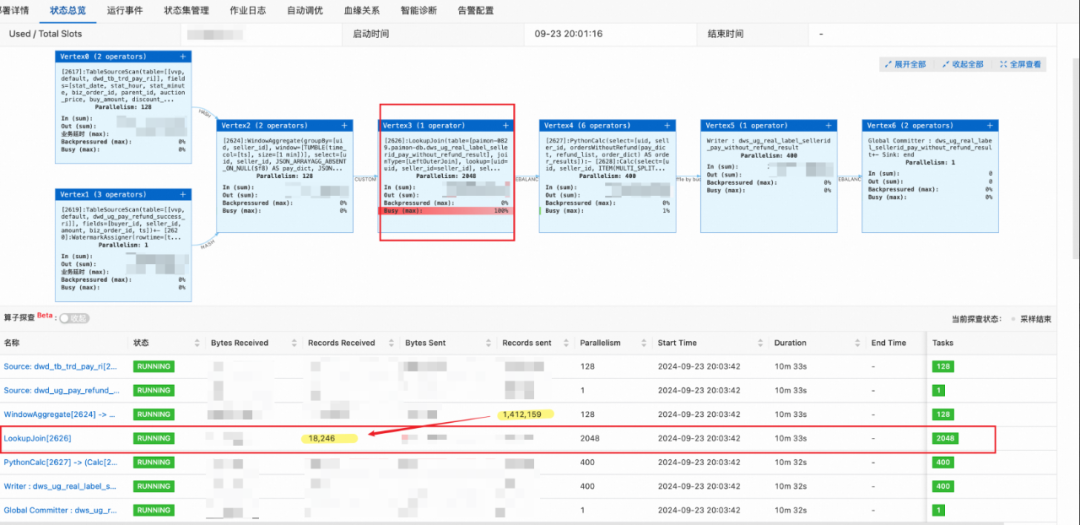
问题描述:初始化 Paimon 表后的大小为 TB 级别,一开始设置的分桶数为 400,即每个桶的数据量在 5-10GB 范围内,启动任务后,发现数据总是卡在 LookupJoin 这一节点,一直增大并发至 2048,也一直堵塞,如下图所示:
原因分析:
通过日志发现主要是在读取 Paimon 表的 OSS 存储时,出现了阻塞,原因是单个桶的文件量太大,且传输速率已达到带宽上线,因此依然需要长时间的同步。
对于 shuffle join,会对 join key(必须要包含所有的 bucket key)基于 bucket 的数量进行 shuffle,然后分配到各个并发上,当算子的并发=分桶数时,每个并发刚好只需要加载一个桶的文件到内存,如果并发数小于分桶数,则某些并发可能需要加载多个桶的文件数据,可能会出现倾斜的情况。
解决方法:按照官方文档的推荐,单个桶的数据量不要超过 5G,因此增大桶的数量到 1000,启动任务时,LookupJoin 算子各并发加载 Paimon 维表的时间明显缩短,3 分钟左右即可加载完成并正常处理数据。
2. 写 Paimon 表出现Heartbeat of TaskManager timed out
问题描述:初始化 Paimon 维表时,需要将 ODPS 计算好的历史数据批量写入到 Paimon 表中,在 vvp 中提交批任务,但是在 writer 算子阶段部分 TM 会出现Heartbeat of TaskManager timed out 大的报错导致频繁失败重启。
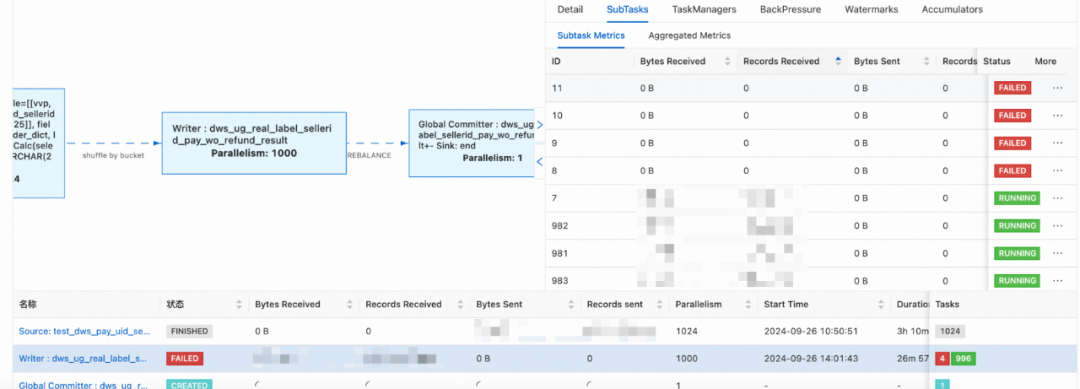
原因分析:通过查看官方文档,writer 算子出现此类情况通常是因为 TM 的堆内存不足导致的,paimon 表使用堆内存只要是以下 3 种方式:
Paimon 主键表 writer 算子的每个并发都有一个内存 buffer 用于排序。该 buffer 的大小受
write-buffer-size表参数控制,默认值为 256 mb。Paimon 默认使用 orc 文件格式,因此还需要一个内存 buffer 将内存里的数据分批转为列存格式。该 buffer 的大小受
orc.write.batch-size表参数控制,默认值为 1024,即默认保存 1024 行数据。每个被修改的分桶都有一个专用的 writer 对象处理该分桶的写入数据。
解决方法:
批任务配置时,增大 TM 的内存从 4GB 到 8GB
设置如下参数:如果 Flink 作业不依赖于状态,可以避免使用托管内存,从而增加对内存的使用。
taskmanager.memory.managed.size=1m3. 非分区表数据清除策略
问题描述:对于非分区主键表,无法向分区表一样设置分区定期清除策略,这样会导致表的数据量越来越大,影响后续该表的读写性能。
尝试方法:Paimon 官网中有对记录级别过期清除的参数,如下:
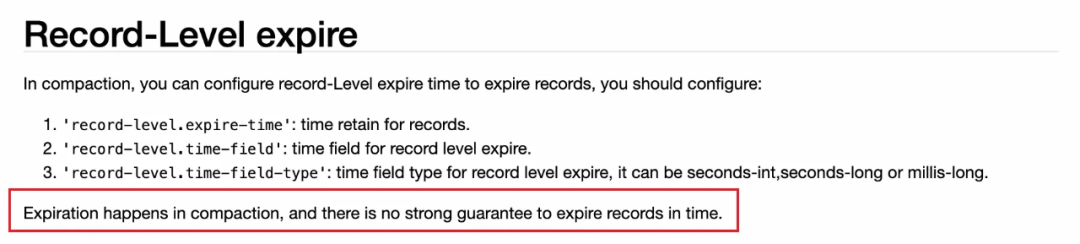
但在实际应用的过程中,发现这种方法只是在新记录写入时,会根据时间字段去判断该记录是否过期,若过期,则不会写入这条新记录,对于 Paimon 表中已有的历史记录,无法生效。
解决方法:
将 Paimon 表改为只写入不压缩模式

alter table `paimon-catalog`.`paimon-db`.test_dws_pay_refund set ('write-only' = 'true');通过 delete 语句清除过期数据【批处理】
待清除完成后,恢复压缩参数,设置为 write-only = 'false'
说明:如果直接启动批作业执行 delete 语句,在提交阶段任务会直接失败,因为当多个 writer 同时写入同一个分桶数据时,由于多个 writer 标记了同一条数据为‘deleted',,在压缩过程中会发生冲突,导致任务失败重启,但是批作业无法进行重启。
▐ 累加类实时标签开发
需求背景
目前平台提供的下单类实时标签大都为:某段时间是否下单的二元标签,为了丰富实时标签的多元性,考虑新增某段时间下单数量、下单金额等累计类的实时标签。
问题分析
对于长周期可累加型指标的问题,通常有以下几种思路:
1. 开窗聚合,这种方法的缺点是长时间的开窗会受到状态大小的限制,因此不适用于长周期指标的累加。
2. 离线 T-2 结果+实时结果关联汇总,这种方法需要:
离线任务必须在当天产出,在大促期间需要强保障;
实时任务依然需要进行长达 2 天的开窗,任务一旦无状态重启,就需要从 2 天前的点位重新计算。
解决方法
对于上述问题,中间存储是一定需要的,但是我们考虑使用 Paimon 表来代替方法 2 中的离线结果表,这样既可以摆脱对离线任务的强依赖,同时也可以随时进行无状态重启。
整体方案设计
1. 累计日期的选择:累计周期 N 的取值可以让用户自定义选择,这要求我们提前算好不同 N 天的结果并存储在数据库中, 因此 Paimon 维表必须存储天粒度的累加数据,方便不同时间段指标结果的累加。针对该方案,累加周期 N 的选择不建议太长,因为这样会增大 Paimon 表的存储成本和维表关联时的计算成本,因此我们这里选择 N 的最大取值为 7,也可以根据业务的需要,适当增加。
2. DAU 刷新数据:如果某个用户今日没有下单,那么存储在 Tair 中的近 N 天结果是不会被更新的,这就导致结果的不准确,因此需要使用 DAU 流驱动近 N 天累加结果的更新。
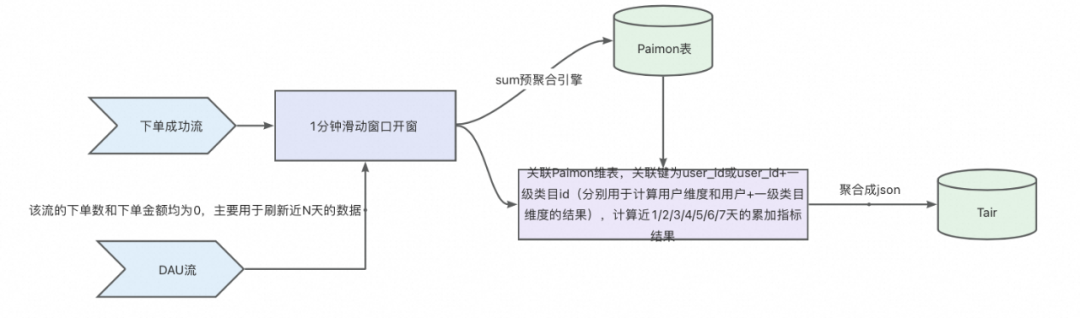
Paimon 维表设计
CREATE TABLE `paimon-catalog`.`paimon-db`.`test_dws_pay_cate1_result` (`test_buyer_id` BIGINT NOT NULL, `test_cate1_id` STRING NOT NULL, -- 一级类目ID`ds` STRING NOT NULL,`test_order_cnt` BIGINT, -- 下单数`test_gmv` DOUBLE, -- GMVPRIMARY KEY (test_buyer_id, test_cate1_id, ds) NOT ENFORCED
)
COMMENT ''
WITH ('bucket' = '40','bucket-key' = 'test_buyer_id','changelog-producer' = 'lookup','fields.test_order_cnt.aggregate-function' = 'sum','fields.test_gmv.aggregate-function' = 'sum','merge-engine' = 'aggregation','partition.expiration-time' = '7d','partition.timestamp-formatter' = 'yyyyMMdd','partition.timestamp-pattern' = '$ds'
)说明:
1. 分区表:分区粒度为天分区,存储每天每个用户 x 一级类目的成交单数和金额,设置分区过期日期为 7 天
2. 主键表:主键设置为用户 ID+一级类目 ID +分区字段
3. 分桶数量:分桶键设置为用户 ID(具体原因可在下文会详述),分桶数量根据维表大小(GB 级别)设置为 40
4. 聚合引擎:使用 Paimon 主键表的 aggregation 预聚合引擎,分别对字段 test_order_cnt(下单数)和 test_gmv(下单金额)采用 sum 累加的方式预聚合。
5. changelog 产生方式:设置为 lookup,其实我们下游并不需要实时消费 paimon 维表,但是对于使用 aggregation 引擎的表,必须设置该参数。
开发经验分享
由于分桶键设置不合理导致的 LookupJoin 算子报错
问题描述:在设计 Paimon 维表的时候,一开始会自然得把分桶键设置为主键,即 test_buyer_id 和test_cate1_id两个字段,但是在LookupJoin 的时候,发现如果 joinkey 只是 test_buyer_id,即 bucket key 的一部分,对应算子就会长时间处于初始化中,最后报错。
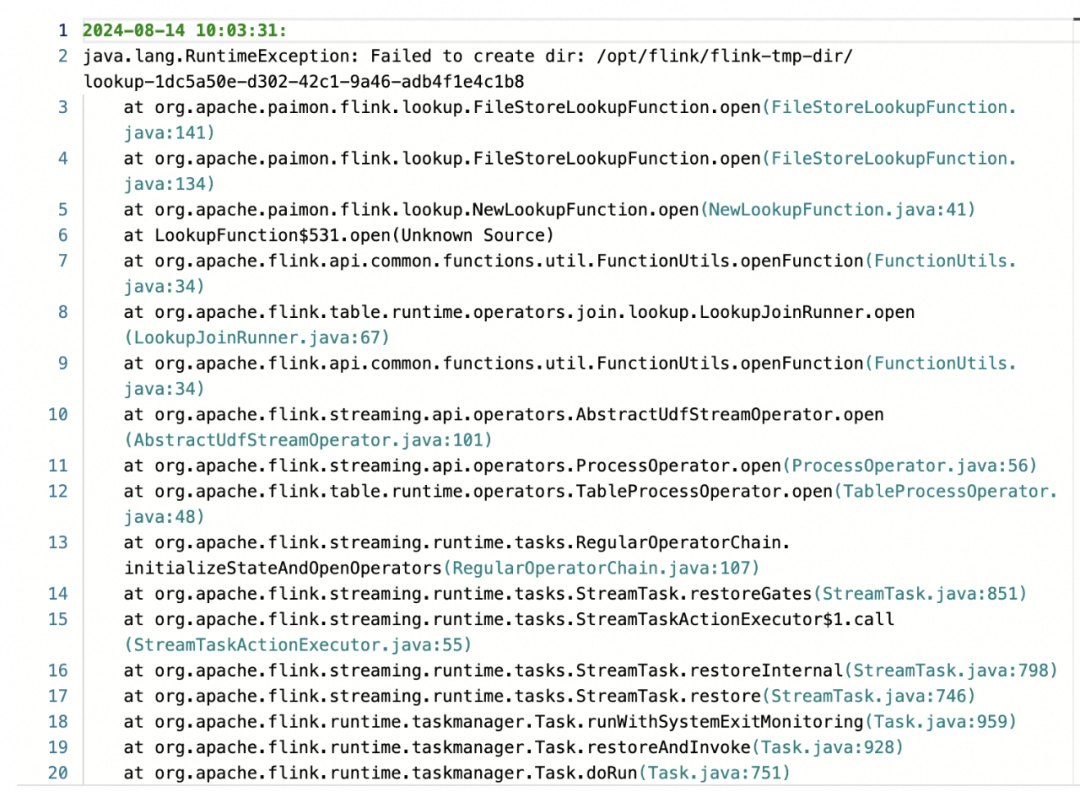
原因分析:如果 joinkey 只是 bucket key 的一部分,就会导致在 join 的时候,无法通过 joinkey 快速定位到目标维表数据所在分桶及目标数据的位置,导致查询效率低下。
解决方法:需要保证 joinkey 完全包括 bucket key,这样才可以通过 joinkey 快速定位到维表数据所在的分桶,从而定位快速读取维表数据。因此,将 bucket key 设置为 test_buyer_id。
衍生问题:采用上述解决方法后启动任务,会发现 LookupJoin 算子会有 5-10 分钟的初始化过程,这是因为我们在 join 的时候没有指定 ds 分区字段的值,导致 join 的时候会读取多个分区,而不同分区的数据是存在不同的分桶中的,因此 vvp 在加载维表数据的时候,不会通过 shuffle 策略将维表数据加载到对应内存中,而是将维表的全量数据加载到每个 TM 的 rocksdb 中,然后再去从 TM 本地根据 joinkey 查询数据,因此加载需要较长的时间。
经验总结通过上述两个案例,我们成功实践了 Paimon +Flink 的实时湖仓架构用于需要大量实时状态存储的场景。使用 Paimon 作为中间存储进行维表 JOIN,可以解决 Flink 内部状态 state 成本高、不可重启、存储周期短等限制,从而满足复杂实时场景的数据开发需求,同时这些中间存储结果也可以通过流/批的形式被 ODPS/Hologres 等大数据引擎消费,实现数据统一,这也是我们后续会进一步探索和应用的场景。

参考资料
Writer 算子堆内存的使用:
https://paimon.apache.org/docs/master/maintenance/write-performance/#write-memory
Flink 维表 Join:
https://help.aliyun.com/zh/flink/developer-reference/join-statements-for-dimension-tables#section-syw-j1p-cgb
Paimon dedicated compaction:
https://paimon.apache.org/docs/0.9/maintenance/dedicated-compaction/
记录级别过期策略:
https://paimon.apache.org/docs/0.9/primary-key-table/compaction/
数据湖产品对比:
https://www.cnblogs.com/johnnyzen/p/18189005

团队介绍
淘天业务技术用户运营平台技术团队是一支懂用户,技术驱动的年轻队伍,以用户为中心,通过技术创新提升用户全生命周期体验,持续为用户创造价值。团队立足体系化打造业界领先的用户增长基础设施,以媒体外投平台、ABTest平台、用户运营平台为代表的基础设施赋能阿里集团用户增长,日均处理数据量千亿规模、调用QPS千万级。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
相关文章:
Flink+Paimon实时数据湖仓实践分享
随着 Paimon 近两年的推广普及,使用 FlinkPaimon 构建数据湖仓的实践也越来越多。在 Flink 实时数据开发中,对于依赖大量状态 state 的场景,如长周期的累加指标计算、回撤长历史数据并更新等,使用实时数仓作为中间存储来代替 Flin…...

w~深度学习~合集1
我自己的原文哦~ https://blog.51cto.com/whaosoft/12663254 #Motion Plan 代码 github.com/liangwq/robot_motion_planing 轨迹约束中的软硬约束 前面的几篇文章已经介绍了,轨迹约束的本质就是在做带约束的轨迹拟合。输入就是waypoint点list,约束…...

KVM 虚拟化
KVM(Kernel-based Virtual Machine)是一种基于内核的虚拟机技术,具有以下优势: 开源性:KVM是完全开源的,这意味着它没有许可费用,适合预算有限的用户。性能:KVM利用Linux内…...

MONI后台管理系统-数据库设计
前言:该文档纯属个人总结设计,如果雷同,纯属巧合,其中还有很不合理之处,请大家批评指正。如有应用于项目,请慎重。 注意: 如有需要该文件的sql脚本,请移步:资源下载 1. 表清单 序号…...

Rigol DP711自动控制--SCPI命令
通过串口的SCPI命令来控制通道输入输出 也可以用UltraSigma UI来发送SCPI 物理连接: Pin2_2, Pin3_3, Pin5_5 串口命令控制: 命令:9600, 8bit, None SCPI CMD(Standard Commands for Programmable Instruments) OUTPut CH1, On…...

总结FastDFS的面试题
目录 一:FastDFS的基础知识 1:定义 2:FastDFS的优点 3:tracker server 4:storage server 二:FastDFS的存储原理 1:小文件存储的问题 2:小文件合并存储 3:文件上…...

Fiddler 5.21.0 使用指南:过滤浏览器HTTP(S)流量下(四)
概述 在上一篇文章中,我们介绍了一部分简单的过滤功能,已经可以帮助我们较为准确的定位到感兴趣的请求;提升我们的工作效率,我们可以通过设置更为复杂的过滤规则,精准到定位的我们想要的请求和响应信息。专注于分析对…...

【踩坑】pip安装依赖卡在Installing build dependencies ...
pip安装依赖卡在Installing build dependencies ... 如图,pip安装依赖一直卡着,最后不得不ctrlC强制终止 用–verbose显示详细安装信息,发现卡在安装numpy pip install -r requirements.txt --verbose大概率是网络问题,用镜像单…...
)
【WRF-Urban】SLUCM新增空间分布城市冠层参数及人为热排放AHF代码详解(下)
目录 详细解释更改文件内容4 运行模块(run):README.namelist5 输出模块(share):share/module_check_a_mundo.Fshare/output_wrf.F参考SLUCM新增空间分布城市冠层参数及人为热排放AHF代码详解的前两部分内容可参见-【WRF-Urban】SLUCM新增空间分布城市冠层参数及人为热排放A…...

云桌面:云计算桌面
目录 云桌面的定义和核心概念 技术架构详解 主流架构详解 管理成本分析 安全性措施 应用场景详解 云桌面的定义和核心概念 云桌面是一种通过云计算技术提供的虚拟桌面服务,它允许用户通过网络访问远程服务器上的虚拟机,这些虚拟机为用户提供了一个…...

WPF+LibVLC开发播放器-音量控制和倍速控制
界面 界面上增加音量的控件和倍速控制控件 音量控制 主要也是一个Slider进度条控件来实现音量调节 我们这里设置默认的最大值为100,默认Value值也为100,默认声音开到最大 这里目前完全由前端控制音量调节,可以直接使用ValueChanged事件实…...

数智运营一体化平台项目经营分享
分离前后台,增强产品管理灵活性 前端成熟的流程平台,支持低代码快速灵活配置流程表单,完美解决流程频繁变化与快速上线、费用控制的矛盾。使产品管理体系,摆脱了流程可移植性差和投入大量人力物力无止境修改流程的困境。同时&…...

记录blender学习过程中遇到的问题
物体发射的方向不对 被发射物体(例如一棵树)n键看旋转归0 切换正视图 将被发射物体的局部坐标的Z轴 指向 全局方向的X轴时 并且把粒子系统设置的物体旋转勾选上 方向就对了 做倒角发现有问题 检查缩放应用、面朝向、有没有重合点(融合点&am…...

(八)腾讯cloudstudio+Stable-Diffusion-webui AI绘画教程-安装插件
一、说明 本文安装8个插件,先安装,后面在慢慢学习,我也是第一次喔 二、中英文双语语言包 (二)Ubuntu22.04Stable-Diffusion-webui AI绘画 中英双语插件安装-CSDN博客https://blog.csdn.net/jiangkp/article/details…...

记一次跑前端老项目的问题
记一次跑前端老项目的问题 一、前言二、过程1、下载依赖2、启动项目3、打包 一、前言 在一次跑前端老项目的时候,遇到了一些坑,这里记录一下。 二、过程 1、下载依赖 使用 npm install下载很久,然后给我报了个错 core-js2.6.12: core-js…...

深度学习:MindSpore自动并行
随着模型规模的逐渐增大,需要的算力逐渐增强,但是算力需求增长速度远高于芯片算力增长速度。现在唯一的解决方案只有通过超大规模集群训练大模型。 大集群训练大模型的挑战 内存墙 200B参数量的模型,参数内存占用745GB内存,训练…...

python拆分Excel文件
按Sheet拆分Excel 或 按照某一列的不同值拆分Excel。文档样式如下: 结果:红色是按照Sheet名拆出的,蓝色和橙色是某个Sheet按照某列的不同值拆分的。 代码: # -*- coding: utf-8 -*- """ 拆分excel文件——按照…...

Python实现Excel中数据条显示
Python中要实现百分比数据条的显示,可以使用pandas库,pandas图表样式的设置与Excel中的条件格式设置比较类似,比如Excel里常用的数据条的用法,在pandas中使用代码进行高亮显示,用来突出重点数据,下面一起来…...

c#如何开发后端
1选择开发框架 在 C# 中,用于后端开发最常用的框架是ASP.NET。它提供了构建 Web 应用程序、Web API 和微服务等多种后端服务所需的功能。ASP.NET有不同的模式,如ASP.NET MVC(Model - View - Controller)和ASP.NET Web API。ASP.NE…...

6.Vue------async/await详细的讲解---知识积累
前提: 先说一下Promise解释 Promise是一种在JavaScript中处理异步操作的对象。它代表了一个尚未完成但承诺未来某个时间会完成的操作结果。Promise有三种状态:pending(等待中)、fulfilled(已成功)和reject…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...