python网络爬虫基础:html基础概念与遍历文档树
开始之前导入html段落,同时下载好本节将用到的库。下载方式为:pip install beautifulsoup4
一点碎碎念:为什么install后面的不是bs4也不是BeautifulSoup?
html_doc = """
<html><head><title>The Dormouse's story</title></head><body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""一、html基础与BeautifulSoup解析过程
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')首先导入BeautifulSoup库并对html文档对象进行解析。
HTML解析器把这段字符串转换成一连串的事件:打开<html>标签,打开<head>标签,打开<title>标签,添加一段字符串,关闭<title>标签等等。
解析后的html文档大体上可分为四类对象:Tag(标签)即 <html> <title> 等,一个Tag可能包含多个字符串或其它的Tag,称为子节点,字符串节点没有子节点。还有NavigableString(标签内文字)、Comment(注释)以及BeautifulSoup(文档整体)。
BeautifulSoup对象本身也是一个特殊的Tag,可视为html标签,只有一个。可以非严格认为soup.html==soup。
二、BeautifulSoup对象方法
前情提要:没有索引到实际段落会返回None,前提是上个节点有索引,因为对None继续索引会报错。此处要结合后续代码理解。
1.子孙节点
print(soup.head)
# <head><title>The Dormouse's story</title></head>
print(soup.head.title)
# <title>The Dormouse's story</title>首先是通过点取属性的方式获取相应的文档标签,此方式只能获取到匹配到的第一个tag,同时支持链式操作,在输出结果中会保留匹配到的tag(这里与以下contents等方法区分)。
print(soup.head.contents)
# [<title>The Dormouse's story</title>]
print(soup.head.contents[0].contents)
# ["The Dormouse's story"]contents方法用于获取某个tag内的所有(直接)子节点,返回列表,在输出结果中不会保留匹配到的tag。
for child in soup.children:print(child)
for child in soup.descendants:print(child)children方法的作用与结果类似于contents,只不过返回的是生成器对象。descendants 方法用于获取某个tag内的所有子孙节点,同样返回生成器对象。children方法与descendants 方法均不会在输出结果中保留匹配到的tag。
到底什么叫“在输出结果中不保留匹配到的tag”呢?以下例子帮助理解。
for child in soup.head.descendants:print(child)print(child.name)
# <title>The Dormouse's story</title>
# title
# The Dormouse's story
# None2.字符串节点
print(soup.head.string)
# The Dormouse's story如果tag有一个NavigableString类型子节点(重点是只有一个),那么这个tag可以使用string方法得到该子节点(即字符串)。
如果一个tag仅有一个子节点,该子节点只有一个NavigableString 类型子节点,那么这个tag也可以使用string方法直接获取到内部字符串,同理,文档树深度可无限大,但是直到NavigableString子节点结束时只有一条枝干(即宽度始终为1)才能调用。
for string in soup.strings:print(repr(string))
for string in soup.stripped_strings:print(repr(string))如果tag内包含多个字符串可以使用strings或者stripped_strings方法获取,同样为生成器对象。其中stripped_strings方法会过滤掉字符串中的空白内容:全部是空格的行会被忽略掉,段首和段末的空白会被删除。
3.父节点
大部分tag或字符串都有父节点:被包含在某个tag中,此tag即为其父节点。
title_tag = soup.title
print(title_tag.parent)
# <head><title>The Dormouse's story</title></head>
print(title_tag.string.parent)
# <title>The Dormouse's story</title>通过parent方法可获取到某个元素的父节点。
<html>的父节点是 BeautifulSoup 对象。以下为树结构辨析,帮助理解:
print(type(soup.html.parent.parent))
# <class 'NoneType'>
print(type(soup.html.parent))
# <class 'bs4.BeautifulSoup'>
print(type(soup.html))
# <class 'bs4.element.Tag'>
print(type(soup))
# <class 'bs4.BeautifulSoup'>通过parents方法可以递归得到元素的所有父辈节点,同样是生成器对象。
link = soup.a
for parent in link.parents:print(parent.name)
# p
# body
# html
# [document]
# 其中soup.name结果即为[document]4.兄弟节点
ibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></a>", 'html.parser')
print(sibling_soup.b.next_sibling)
# <c>text2</c>
print(sibling_soup.c.previous_sibling)
# <b>text1</b>
print(sibling_soup.b.previous_sibling)
# None
print(sibling_soup.c.next_sibling)
# None兄弟节点定义:父节点相同的节点。next_sibling与previous_sibling分别表示“下一个兄弟节点”与“上一个兄弟节点”。从实际情况来说文档中tag的兄弟节点往往会出现字符串或者空白,这是由于解析html时标签之间的空白和换行也会被解析为字符串节点,其父节点与同级标签相同,符合兄弟节点定义。一般来说调用多次后总会得到想要的值,支持链式调用。
for sibling in soup.a.next_siblings:print(repr(sibling))
for sibling in soup.find(id="link3").previous_siblings:print(repr(sibling))通过next_siblings和previous_siblings属性可以对当前节点的兄弟节点迭代输出,且同样是生成器对象。
last_a_tag = soup.find("a", id="link3")
'''
last_a_tag周围内容如下
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
'''
print(last_a_tag.next_sibling)
# ;
# and they lived at the bottom of a well.
print(last_a_tag.next_element)
# Tillie
# 解释 :解析器先进入<a>标签,然后是字符串“Tillie”,然后关闭</a>标签,然后是分号和剩余部分.所以next_element输出Tillienext_element与previous_element类似于next_sibling与previous_sibling,不同的是前者是指向解析过程中下一个或上一个被解析的对象,这里需要了解BeautifulSoup的解析过程,前文已有提过不在赘述。
last_a_tag = soup.find("a", id="link3")
for element in last_a_tag.next_elements:print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p class="story">...</p>
# '...'
# '\n'next_elements和previous_elements为逐步解析,依旧是生成器对象。
相关文章:

python网络爬虫基础:html基础概念与遍历文档树
开始之前导入html段落,同时下载好本节将用到的库。下载方式为:pip install beautifulsoup4 一点碎碎念:为什么install后面的不是bs4也不是BeautifulSoup? html_doc """ <html><head><title>The…...

【已解决】MacOS上VMware Fusion虚拟机打不开的解决方法
在使用VMware Fusion时,不少用户可能会遇到虚拟机无法打开的问题。本文将为大家提供一个简单有效的解决方法,只需删除一个文件,即可轻松解决这一问题。 一、问题现象 在MacOS系统上,使用VMware Fusion运行虚拟机时,有…...

经典视觉神经网络1 CNN
一、概述 输入的图像都很大,使用全连接网络的话,计算的代价较高,图像也很难保留原本特征。 卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格状结构数据的深度学习模型。主要应用…...

一些硬件知识【2024/12/6】
MP6924A: 正点原子加热台拆解: PMOS 相比 NMOS 的缺点: 缺点描述迁移率低PMOS 中的空穴迁移率约为电子迁移率的 1/3 到 1/2,导致导通电流较低。开关速度慢由于迁移率较低,PMOS 的开关速度比 NMOS 慢,不适合高速数字电…...

网络安全法-网络安全支持与促进
第二章 网络安全支持与促进 第十五条 国家建立和完善网络安全标准体系。国务院标准化行政主管部门和国务院其他有关部门根据各自的职责,组织制定并适时修订有关网络安全管理以及网络产品、服务和运行安全的国家标准、行业标准。 国家支持企业、研究机构、高等学…...

【Docker】如何在Docker中配置防火墙规则?
Docker本身并不直接管理防火墙规则;它依赖于主机系统的防火墙设置。不过,Docker在启动容器时会自动配置一些iptables规则来管理容器网络流量。如果你需要更细粒度地控制进出容器的流量,你需要在主机系统上配置防火墙规则。以下是如何在Linux主…...

Cesium 问题: 添加billboard后移动或缩放地球,标记点位置会左右偏移
文章目录 问题分析原先的:添加属性——解决漂移移动问题产生新的问题:所选的经纬度坐标和应放置的位置有偏差解决坐标位置偏差的问题完整代码问题 添加 billboard 后, 分析 原先的: // 图标加载 function addStation ({lon, lat, el, testName...

使用Python3 连接操作 OceanBase数据库
注:使用Python3 连接 OceanBase数据库,可通过安装 PyMySQL驱动包来实现。 本次测试是在一台安装部署OBD的OceanBase 测试linux服务器上,通过python来远程操作OceanBase数据库。 一、Linux服务器通过Python3连接OceanBase数据库 1.1 安装pyth…...

SpringBoot该怎么使用Neo4j - 优化篇
文章目录 前言实体工具使用 前言 上一篇中,我们的Cypher都用的是字符串,字符串拼接简单,但存在写错的风险,对于一些比较懒的开发者,甚至觉得之间写字符串还更自在快速,也确实,但如果在后期需要…...

Flutter如何调用java接口如何导入java包
文章目录 1. Flutter 能直接调用 Java 的接口吗?如何调用 Java 接口? 2. Flutter 能导入 Java 的包吗?步骤: 总结 在 Flutter 中,虽然 Dart 是主要的开发语言,但你可以通过**平台通道(Platform …...

Redis 数据结构(一)—字符串、哈希表、列表
Redis(版本7.0)的数据结构主要包括字符串(String)、哈希表(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)、超日志(…...

day1:ansible
ansible-doc <module_name>(如果没有网,那这个超级有用) 这个很有用,用来查单个模块的文档。 ansible-doc -l 列出所有模块 ansible-doc -s <module_name> 查看更详细的模块文档。 ansible-doc --help 使用 --help …...

如何设置Java爬虫的异常处理?
在Java爬虫中设置异常处理是非常重要的,因为网络请求可能会遇到各种问题,如连接超时、服务器错误、网络中断等。通过合理的异常处理,可以确保爬虫的稳定性和健壮性。以下是如何在Java爬虫中设置异常处理的步骤和最佳实践: 1. 使用…...

阿里云盘permission denied
问题是执行 ./aliyunpan 时遇到了 Permission denied 的错误。这通常是因为文件没有执行权限。以下是解决问题的步骤: 检查文件权限 运行以下命令检查文件的权限: ls -l aliyunpan输出中会看到类似以下内容: -rw-r--r-- 1 user group 123…...

在 Ubuntu 24 上安装 Redis 7.0.15 并配置允许所有 IP 访问
前提条件 一台运行 Ubuntu 24 的服务器拥有 sudo 权限的用户 步骤一:更新系统包 首先,确保系统包是最新的,以避免潜在的依赖问题。 sudo apt update sudo apt upgrade -y步骤二:安装编译 Redis 所需的依赖 Redis 需要一些编译…...

构建高效可靠的分布式推理系统:深入解析控制器与模型服务的协同工作
在现代互联网应用中,随着用户需求的增长和技术的进步,单一服务器已经难以满足大规模并发请求的需求。为了提升系统的性能和可靠性,开发者们越来越多地采用分布式架构。本文将结合具体的代码示例,深入浅出地探讨如何构建一个高效的分布式推理系统,并详细解析其中的关键组件…...

springboot394疫情居家办公系统(论文+源码)_kaic
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统疫情居家办公系统信息管理难度大,容错率低&a…...

共筑数字安全防线,2024开源和软件安全沙龙即将启幕
随着数字化转型进程的加快以及开源代码的广泛应用,开源凭借平等、开放、协作、共享的优秀创作模式,逐渐成为推动数字技术创新、加速传统行业转型升级的重要模式。但随着软件供应链日趋复杂多元,使得其安全风险不断加剧,针对软件供…...

后端报错: message: “For input string: \“\““
这个错误信息表明后端尝试将一个空字符串 "" 转换为某种数值类型(如整数、长整型等),但转换失败了。在许多编程语言中,如果你试图解析一个非数字的字符串(在这个情况下是一个空字符串)为数值类型…...

39 矩阵置零
39 矩阵置零 39.1 矩阵置零解决方案 解题思路: 利用第一行和第一列标记: 使用两个标记变量,rowZero和colZero,来判断第一行和第一列是否需要置零。遍历矩阵从(1,1)开始,如果某个元素是0,则标记该行和该列…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...
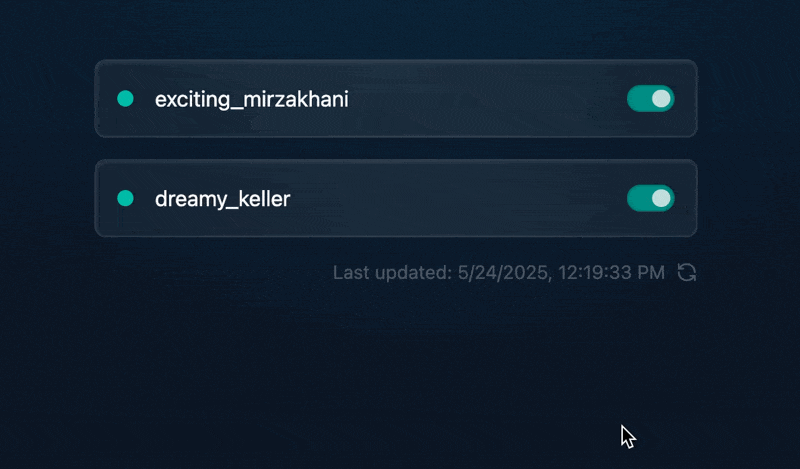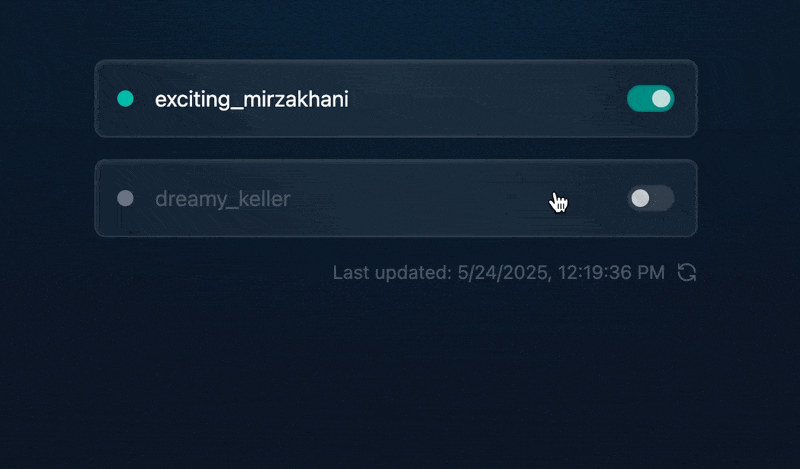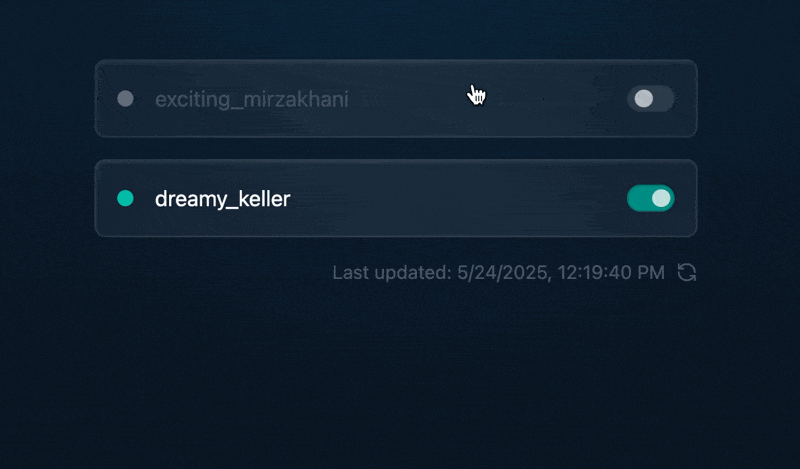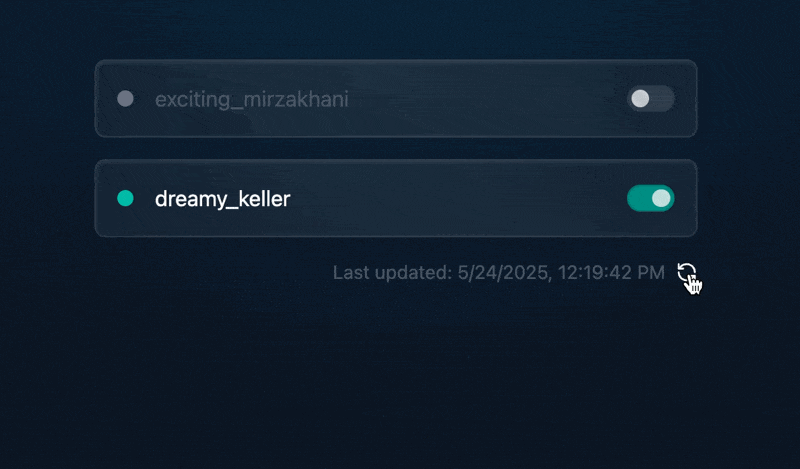
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...
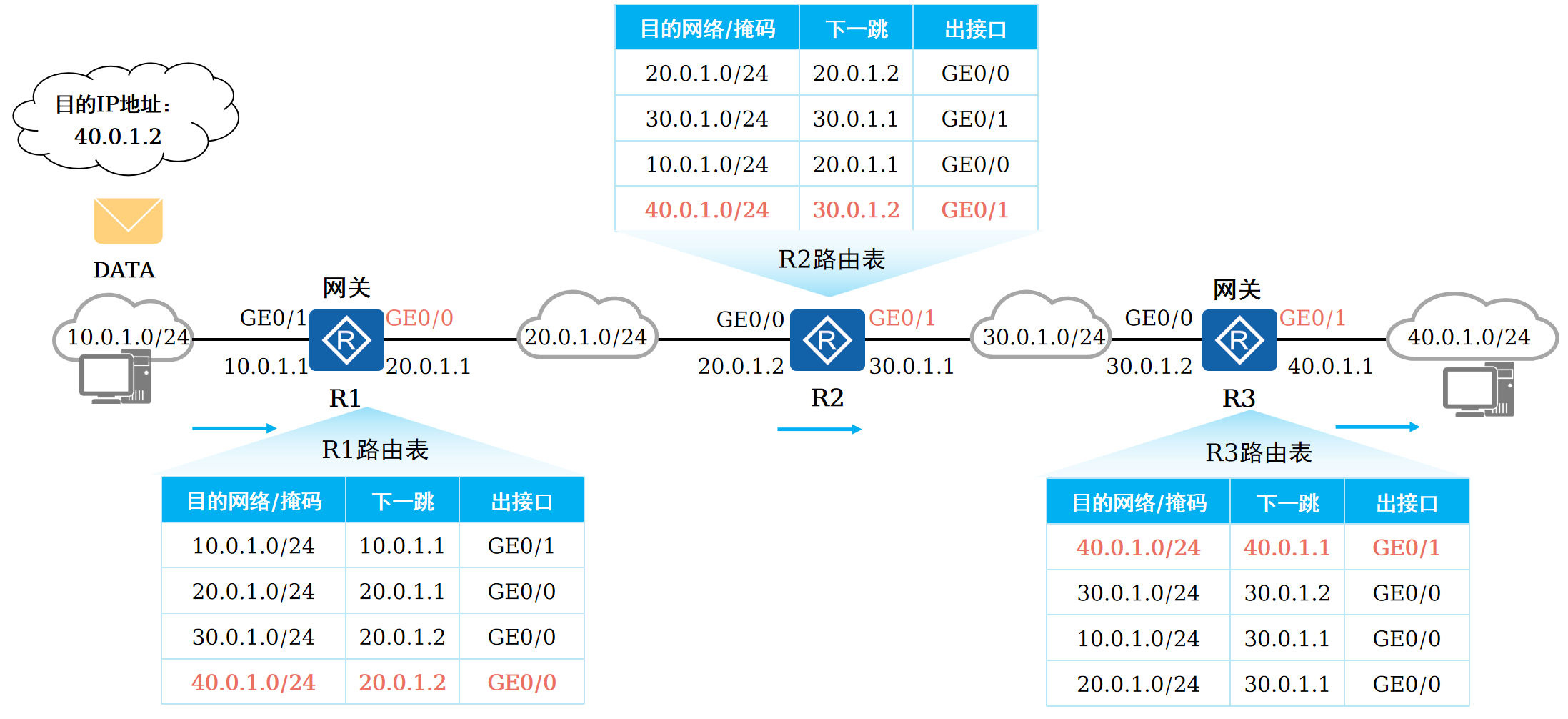
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...

32位寻址与64位寻址
32位寻址与64位寻址 32位寻址是什么? 32位寻址是指计算机的CPU、内存或总线系统使用32位二进制数来标识和访问内存中的存储单元(地址),其核心含义与能力如下: 1. 核心定义 地址位宽:CPU或内存控制器用32位…...