Flume——进阶(agent特性+三种结构:串联,多路复用,聚合)
目录
- agent特性
- ChannelSelector
- 描述:
- SinkProcessor
- 描述:
- 串联架构
- 结构图解
- 定义与描述
- 配置示例
- Flume1(监测端node1)
- Flume3(接收端node3)
- 启动方式
- 复制和多路复用
- 结构图解
- 定义描述
- 配置示例
- node1
- node2
- node3
- 启动方式
- 聚合架构
- 结构图解
- 定义描述
- 示例
- node1
- node2
- node3
agent特性

ChannelSelector
ChannelSelector是Flume中的一个关键组件,负责根据特定逻辑决定Event的流向。
| 名称 | 类型 | 描述 |
|---|---|---|
| ReplicatingSelector | ChannelSelector类型 | 将同一个Event复制并发往所有配置的Channel |
| MultiplexingSelector | ChannelSelector类型 | 根据预设的规则或条件,将不同的Event分发至不同的Channel |
描述:
ReplicatingSelector会无条件地将每个Event发送到与其关联的所有Channel中,实现事件复制。MultiplexingSelector则基于某种规则(如Event中的特定字段、时间戳等)来将Event分发到不同的Channel,实现事件的多路复用。
SinkProcessor
SinkProcessor是Flume中负责处理Sink中Event的组件,它决定了Event如何被发送和处理。
| 名称 | 类型 | 描述 |
|---|---|---|
| DefaultSinkProcessor | SinkProcessor类型 | 对应于单个Sink,直接处理并发送Event至该Sink |
| LoadBalancingSinkProcessor | SinkProcessor类型 | 对应于Sink Group,实现负载均衡,将Event分发至多个Sink中处理 |
| FailoverSinkProcessor | SinkProcessor类型 | 对应于Sink Group,提供错误恢复功能,当主Sink失败时自动切换至备用Sink |
描述:
DefaultSinkProcessor是最基础的Sink处理器,直接与单个Sink关联,负责将Event发送至该Sink。LoadBalancingSinkProcessor用于处理Sink Group,能够智能地将Event分发至多个Sink中,以实现负载均衡,提高处理效率。FailoverSinkProcessor同样用于处理Sink Group,但它提供了错误恢复机制。当主Sink因故障无法工作时,它会自动将Event发送至备用Sink,以确保数据的连续性和可靠性。
串联架构
结构图解


Avro Sink作为Avro客户端,向Avro服务端发送Avro事件。它允许Flume Agent将数据以Avro格式序列化后,发送到指定的Avro Source或其他Avro客户端。
定义与描述
这种模式是将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
配置示例
Flume1(监测端node1)
Flume1(node1),监听node1上的44444端口(source),并输出到node3的10086端口上(sink)
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
# port,监听的端口
a1.sources.r1.port = 44444# Describe the sink
a1.sinks.k1.type = avro
# 指定 Avro Sink 发送数据的目标主机名和端口号
a1.sinks.k1.hostname = node3
a1.sinks.k1.port = 10086# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1Flume3(接收端node3)
Flume3(node3),监听node3上的10086端口(source)(当然source内容是来自node1的44444端口的变化情况),输出一般的控制台内容
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
# 监听的来自node3上的source,source类型为avro
a1.sources.r1.type = avro
a1.sources.r1.bind = node3
# port,监听的端口
a1.sources.r1.port = 10086# Describe the sink
a1.sinks.k1.type = logger# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动方式
先启动node3(flume3),node3的监听是串行的最后一环,从后向前依次启动
理由:
先启动node3的监听(此时node1还未启动),再启动node1,此时可以保证没有任何内容错过
复制和多路复用
结构图解


定义描述
Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。详细可以参考上面的Agent ChannelSelector和SinkProcessor
配置示例
此部分示例会按照如上的结构图进行配置
node1
replicating_channel.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 这个selector是复制类型的。
# 复制selector会将接收到的每个事件复制到所有配置的channel中。
a1.sources.r1.selector.type = replicating# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/nginx/logs/access.log
a1.sources.r1.shell = /bin/bash -c# Describe the sink
# avro类型的sink,发送给下一个agent
# sink k1的参数配置
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node2
a1.sinks.k1.port = 10010# sink k2的参数配置
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node3
a1.sinks.k2.port = 10010# channel c1的参数配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# channel c2的参数配置
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
node2
接收node1,并输出到hdfs中,hdfs的参数配置:flume——hdfs
a2.sources = r1
a2.sinks = k1
a2.channels = c1# Describe/configure the source
# avro类型的source,接收来自上一个agent的sink输出
a2.sources.r1.type = avro
# 这个source来自于node2节点的10010端口
a2.sources.r1.bind = node2
a2.sources.r1.port = 10010# 传输至hdfs中
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = /flume2/%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 2
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k1.hdfs.rollCount = 0# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
node3
接收node1,并输出到日志
a3.sources = r3
a3.sinks = k3
a3.channels = c3# Describe/configure the source
a3.sources.r3.type = avro
a3.sources.r3.bind = node3
a3.sources.r3.port = 10010# Describe the sink
a3.sinks.k3.type = logger# Describe the channel
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3启动方式
先启动node2(flume2)、node3(flume3),在启动node1(flume1)
理由:
同上,请注意,无论何种架构,都应到先启动最末端的接收,再启动发送
聚合架构
结构图解


定义描述
最常见实用的结构模式。
日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析。
示例
node1
发送端1,输出到node3的10000端口
没什么需要特别注明的地方,关键节点已经在前面描述了,建议直接复制代码,GPT检查
[root@node1 jobs]# vim agg1.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/nginx/logs/access.log
a1.sources.r1.shell = /bin/bash -c# Describe the sink
# sink端的avro是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node3
a1.sinks.k1.port = 10000# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1node2
发送端2,输出到node3的10000端口
a2.sources = r1
a2.sinks = k1
a2.channels = c1# Describe/configure the source
# source端的netcat是一个数据接收服务
a2.sources.r1.type = netcat
a2.sources.r1.bind = node2
a2.sources.r1.port = 10000# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = node3
a2.sinks.k1.port = 10000# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1node3
最末的接收端,监听10000端口即可,前面两个节点会发送内容到此端口
[root@node3 jobs]# vim agg3.conf
# Name the components on this agent
a3.sources = r3
a3.sinks = k3
a3.channels = c3# Describe/configure the source
a3.sources.r3.type = avro
a3.sources.r3.bind = node3
a3.sources.r3.port = 10000# Describe the sink
a3.sinks.k3.type = logger# Describe the channel
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3相关文章:
Flume——进阶(agent特性+三种结构:串联,多路复用,聚合)
目录 agent特性ChannelSelector描述: SinkProcessor描述: 串联架构结构图解定义与描述配置示例Flume1(监测端node1)Flume3(接收端node3)启动方式 复制和多路复用结构图解定义描述配置示例node1node2node3启…...

ragflow连ollama时出现的Bug
ragflow和ollama连接后,已经添加了两个模型但是ragflow仍然一直warn:Please add both embedding model and LLM in Settings > Model providers firstly.这里可能是我一开始拉取的镜像容器太小,容不下当前添加的模型,导…...

基于centos7.7编译Redis6.0
背景: OS:CentOs 7.7 Redis: 6.0.6 编译构建报错如下: In file included from server.c:30:0: server.h:1044:5: error: expected specifier-qualifier-list before ‘_Atomic’_Atomic unsigned int lruclock; /* Clock for LRU eviction …...

uni-app项目无法在Android Studio模拟器上运行
目录 1 问题描述2 尝试解决3 引发原因4 解决方法4.1 换用 MuMu 模拟器 5 结语 1 问题描述 在使用 uni-app 开发 Pad 端 App 时,初始化项目后打算先运行一下确保初始化正常。打开 Android Studio 模拟器后,然后在 HbuilderX 中选择使用 App 标准基座 运…...
)
第一部分:Linux系统(基础及命令)
Linux操作系统的实操性非常强,纯操作,不适用于日常的办公使用 1.初始Linux 1.1 操作系统概述 1.1.1 了解OS的作用 OS:是计算机软件的一种,主要负责:作为用户和计算机硬件之间的桥梁,调度和管理计算机硬…...

No module named ‘_ssl‘ No module named ‘_ctypes‘
如果你使用的是基于 yum 的 Linux 发行版(例如 CentOS、RHEL、Fedora),安装 libc6-dev 的方式稍有不同。在这些系统中,通常对应的包是 glibc-devel。 No module named ‘_ctypes’ 使用 yum 安装 glibc-devel 更新系统的软件包列…...

【QT】编写第一个 QT 程序 对象树 Qt 编程事项 内存泄露问题
目录 1. 编写第一个 QT 程序 1.1 使用 标签 实现 🐇 图形化界面实现 🐇 纯代码形式实现 1.2 使用 按钮 实现 🐋 图形化界面实现 🐋 纯代码形式实现 1.3 使用 编辑框 实现 🥝 图形化界面实现 ᾕ…...

VTK编程指南<六>:VTK可视化管线与渲染详解
1、VTK渲染引擎 回顾前几章节的RenderCylinder示例 可以找到以下的类: vtkProp; ytkAbstractMapper; vtkProperty; vtkCamera; vtkLight; vtkRenderer; vtkRenderWindow; vtkRenderWindowInteractor vtkTransform; vtkLookupTable;可以发现这些类都是与数据显示或渲染相关的。…...

基于STM32的智能计步器
引言 随着健康意识的提高,计步器逐渐成为人们日常生活中重要的健康管理工具。本文将指导你如何使用STM32微控制器制作一个智能计步器。该计步器通过加速度传感器检测步伐,并使用OLED显示屏显示步数。通过这个项目,你将学习到STM32开发的基本流…...

VB.NET 从入门到精通:开启编程进阶之路
摘要: 本文全面深入地阐述了 VB.NET 的学习路径,从基础的环境搭建与语法入门开始,逐步深入到面向对象编程、图形用户界面设计、数据访问、异常处理、多线程编程以及与其他技术的集成等核心领域,通过详细的代码示例与理论讲解&…...

射频电路屏蔽简略
电磁波的干扰是每个射频设备的自带属性,不管是内部还是外部,怎样去更好的抑制掉干扰,关系到射频设备的工作状态,而能够找到产生干扰的来源就是重中之重,电磁波的干扰与其产生的源密不可分,而源就离不开所需…...

基础算法——搜索与图论
搜索与图论 图的存储方式2、最短路问题2.1、Dijkstra算法(朴素版)2.2、Dijkstra算法(堆优化版)2.3、Bellman-Ford算法2.4、SPFA求最短路2.5、SPFA判负环2.6、Floyd算法 图的存储方式 2、最短路问题 最短路问题可以分为单源最短路…...
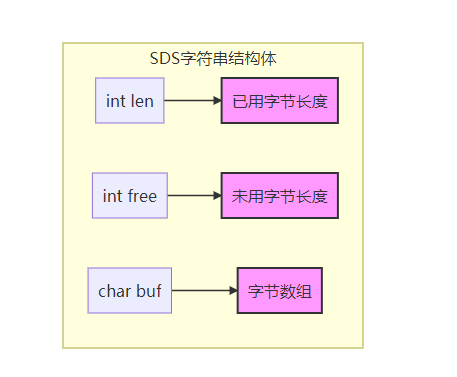
redis优化编码之字符串
redis 优化编码之字符串 ### 字符串优化 字符串对象是redis内部最常用的数据类型。 所有的键是字符串对象值对象除了整数之外都是使用字符串存储lpush cache:type "redis" "tair" "memcache" "leveldb"创建如上一个链表 需要创建一…...
Python特定版本的安装/卸载/环境配置,Spyder安装教程
目录 1.Python安装 1.1 Python下载 1.2 下载特定版本 1.3 安装Python 1.4 修改安装 1.5 环境配置 1.6 卸载Python 2.Spyder安装使用 2.1 Spyder下载 2.1.1 官网下载Spyder 2.2.2 Github下载Spyder 2.2 安装 参考资料:网盘 1.Python安装 1.1 Python下载…...
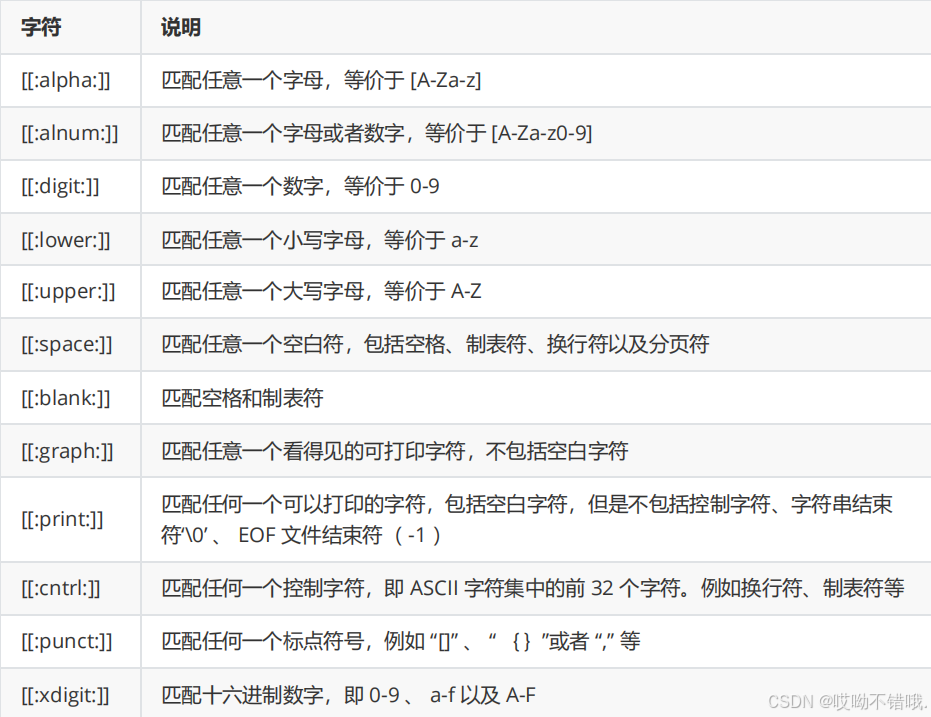
全局搜索正则表达式(grep)
一.grep简介 grep 全程Globally search a Regular Expression and Print,是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行。Unix的grep家族包括grep和egrep 二.grep的工作…...

linux-12 关于shell(十一)ls
登录系统输入用户名和密码以后,会显示给我们一个命令提示符,就意味着我们在这里就可以输入命令了,给一个命令,这个命令必须要可执行,那问题是我的命令怎么去使用,命令格式有印象吗?在命令提示符…...

编写指针函数使向右循环移动m个位置
题目描述:有n个整数,要求你编写一个函数使其向右循环移动m个位置 请仔细阅读右侧代码,结合相关知识,在Begin-End区域内进行代码补充。 输入 输入n m表示有n个整数,移动m位 输出 输出移动后的数组 样例输入: 10 5 1 2 3…...

xvisor调试记录
Xvisor是一种开源hypervisor,旨在提供完整、轻量、移植且灵活的虚拟化解决方案,属于type-1类型的虚拟机,可以直接在裸机上启动。 启动xvisor步骤: 1、搭建riscv编译环境 首先从github上下载riscv-gnu-toolchain很费劲,建议直接从国内的源下载 git clone https://gitee…...

MongoDB-ObjectID 生成器
前言 MongoDB中一个非常关键的概念就是 ObjectID,它是 MongoDB 中每个文档的默认唯一标识符。了解 ObjectID 的生成机制不仅有助于开发人员优化数据库性能,还能帮助更好地理解 MongoDB 的设计理念。 什么是 MongoDB ObjectID? 在 MongoDB …...
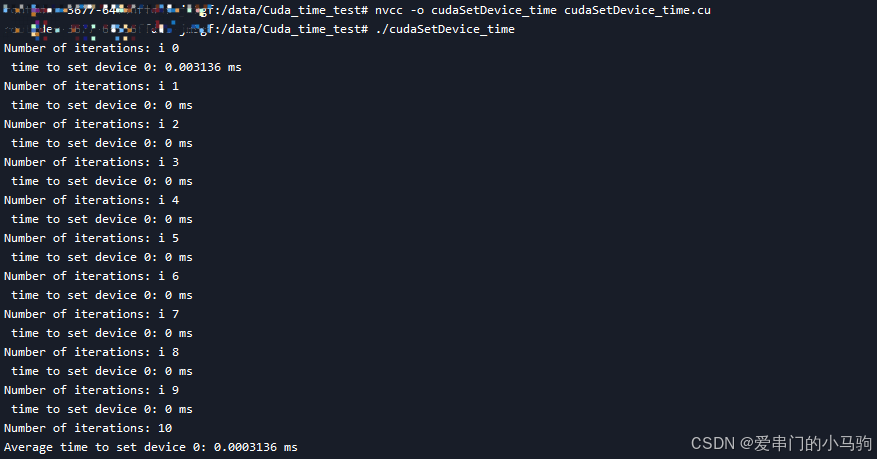
CUDA 计时功能,记录GPU程序/函数耗时,cudaEventCreate,cudaEventRecord,cudaEventElapsedTime
为了测试GPU函数的耗时,可以使用 CUDA 提供的计时功能:cudaEventCreate, cudaEventRecord, 和 cudaEventElapsedTime。这些函数可以帮助你测量某个 CUDA 操作(如设置设备)所花费的时间。 一、记录耗时案例 以下是一个示例程序&a…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...
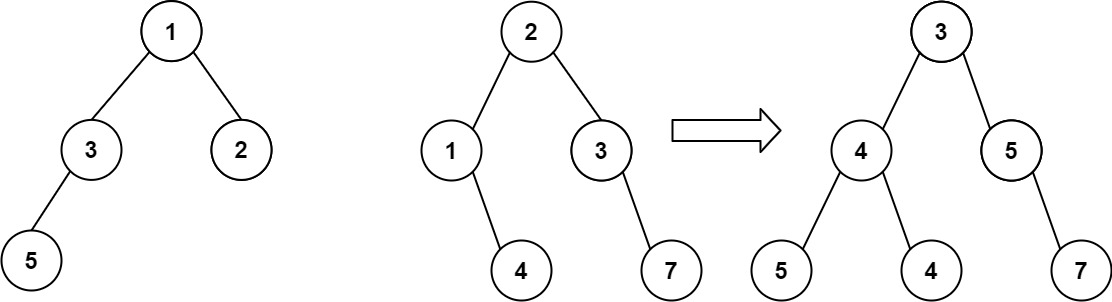
算法打卡第18天
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...