AI - RAG中的状态化管理聊天记录
AI - RAG中的状态化管理聊天记录
大家好,今天我们来聊聊LangChain和LLM中一个重要的话题——状态化管理聊天记录。在使用大语言模型(LLM)的时候,聊天记录(History)和状态(State)管理是非常关键的。那我们先从为什么需要状态和历史记录讲起,然后再聊聊如何保留聊天记录。

为什么需要状态和历史记录
- 保持上下文:我们聊天时是有上下文的,比如你刚问我“什么是状态化管理”,下一个问题可能是“怎么实现”,这些问题之间是有联系的。如果没有上下文,LLM每次回答都会像是第一次见到你,回答可能就会前后不一致。
- 个性化体验:有了历史记录,我们可以根据用户之前的对话内容来做个性化的回复。这就像是我们和朋友之间的对话,大家了解彼此的喜好和习惯,交流起来更顺畅。
- 追踪用户意图:管理聊天状态可以帮助我们更好地理解用户当下的意图。例如,用户可能在连续的问题中逐渐明确他们的需求,通过记录这些对话历史,我们能够更准确地提供帮助。
怎么保留聊天记录呢
-
内存保存:最简单的方法就是将历史记录保存在内存中。这种方式适用于短时间的对话,因为内存是有限的,长时间或者大量用户会耗尽内存。实现方法很简单,我们可以用一个列表来存储历史记录。
chat_history = [] # 用列表来保存聊天记录def add_message_to_history(user_message, bot_response):chat_history.append({"user": user_message, "bot": bot_response}) -
文件或数据库保存:对于需要长时间保存或者需要跨会话保留历史记录的情况,我们可以选择将聊天记录保存到文件或者数据库中。文件保存可以用简单的JSON,数据库可以用SQLite或者更复杂的数据库系统。
import jsondef save_history_to_file(chat_history, filename="chat_history.json"):with open(filename, "w") as file:json.dump(chat_history, file)def load_history_from_file(filename="chat_history.json"):with open(filename, "r") as file:return json.load(file) -
状态图管理:在LangChain中,我们可以用状态图(StateGraph)来管理复杂的聊天状态。状态图允许我们定义不同的状态节点,如查询、检索、生成回复等,并设置它们之间的转换条件。这种方式灵活且强大,适用于复杂的对话场景管理。
from langgraph.graph import StateGraph, MessagesStatestate_graph = StateGraph(MessagesState) # 初始化状态图# 定义各个状态节点 state_graph.add_node(query_or_respond) state_graph.add_node(tools) state_graph.add_node(generate)# 设置节点之间的条件和转换 state_graph.set_entry_point("query_or_respond") state_graph.add_conditional_edges("query_or_respond",tools_condition,{END: END, "tools": "tools"}, ) state_graph.add_edge("tools", "generate") state_graph.add_edge("generate", END)
如何用代码来实现呢
接下来我们详细讲解如何一步步实现这样的功能。备注:对于本文中的代码片段,主体来源于LangChain官网,有兴趣的读者可以去官网查看。
首先导入了一些必要的库和模块:
import os # 导入操作系统模块,用来设置环境变量
from langchain_openai import ChatOpenAI # OpenAI 聊天模型类
from langchain_openai import OpenAIEmbeddings # OpenAI 嵌入向量类
from langchain_core.vectorstores import InMemoryVectorStore # 内存向量存储类
import bs4 # BeautifulSoup 库,用于网页解析
from langchain import hub # langchain 的 hub 模块
from langchain_community.document_loaders import WebBaseLoader # 加载网页内容的 class
from langchain_core.documents import Document # 文档类
from langchain_text_splitters import RecursiveCharacterTextSplitter # 文本切分工具
from langgraph.graph import START, StateGraph, MessagesState # 状态图相关模块
from typing_extensions import List, TypedDict # Python 类型扩展
from langchain_core.tools import tool # 工具装饰器
from langchain_core.messages import SystemMessage # 系统消息类
from langgraph.graph import END # 状态图中的结束节点
from langgraph.prebuilt import ToolNode, tools_condition # 预先构建的工具节点和工具条件
from langgraph.checkpoint.memory import MemorySaver # 内存保存器
然后,我们设置一个环境变量来存放 OpenAI 的 API Key:
os.environ["OPENAI_API_KEY"] = 'your-api-key' # 设置 OpenAI API Key
接下来,我们初始化一些主要组件,包括嵌入模型、内存向量存储和语言模型:
embeddings = OpenAIEmbeddings(model="text-embedding-3-large") # 初始化 OpenAI 嵌入模型
vector_store = InMemoryVectorStore(embeddings) # 创建一个内存向量存储llm = ChatOpenAI(model="gpt-4o-mini") # 初始化聊天模型
下一步是从一个指定的网址加载博客内容,并将其切分成小块:
# 加载并切分博客内容
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), # 指定要加载的博客的网址bs_kwargs=dict( # BeautifulSoup 的参数,仅解析指定的类parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load() # 加载文档内容# 设置文本切分器,指定每块大小为1000字符,重叠200字符
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs) # 切分文档
然后,我们将切分后的文档块添加到向量存储中进行索引:
# 索引这些文档块
_ = vector_store.add_documents(documents=all_splits) # 将文档块添加到向量存储中
接着,我们定义一个名为 retrieve 的工具函数,用于根据用户查询检索信息:
@tool(response_format="content_and_artifact")
def retrieve(query: str):"""Retrieve information related to a query."""retrieved_docs = vector_store.similarity_search(query, k=2) # 搜索与查询最相似的2个文档serialized = "\n\n".join((f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")for doc in retrieved_docs)return serialized, retrieved_docs # 返回序列化的内容和检索到的文档
然后我们定义三个步骤的函数来处理用户的查询和生成回答:
# 第一步:生成包含工具调用的 AI 消息并发送
def query_or_respond(state: MessagesState):"""生成检索的工具调用或响应。"""llm_with_tools = llm.bind_tools([retrieve]) # 绑定 retrieve 工具与聊天模型response = llm_with_tools.invoke(state["messages"]) # 生成响应# MessagesState 会附加消息到状态而不是覆盖return {"messages": [response]} # 返回消息状态# 第二步:执行检索
tools = ToolNode([retrieve]) # 创建工具节点# 第三步:使用检索内容生成响应
def generate(state: MessagesState):"""生成答案。"""# 获取生成的工具消息recent_tool_messages = []for message in reversed(state["messages"]):if message.type == "tool":recent_tool_messages.append(message)else:breaktool_messages = recent_tool_messages[::-1] # 反向排序# 格式化为提示docs_content = "\n\n".join(doc.content for doc in tool_messages)system_message_content = ("You are an assistant for question-answering tasks. ""Use the following pieces of retrieved context to answer ""the question. If you don't know the answer, say that you ""don't know. Use three sentences maximum and keep the ""answer concise.""\n\n"f"{docs_content}")conversation_messages = [messagefor message in state["messages"]if message.type in ("human", "system")or (message.type == "ai" and not message.tool_calls)]prompt = [SystemMessage(system_message_content)] + conversation_messages# 运行response = llm.invoke(prompt)return {"messages": [response]} # 返回消息状态
然后我们创建一个状态图并设置各个节点和连接:
graph_builder = StateGraph(MessagesState) # 创建状态图构建器
graph_builder.add_node(query_or_respond) # 添加 query_or_respond 节点
graph_builder.add_node(tools) # 添加 tools 节点
graph_builder.add_node(generate) # 添加 generate 节点graph_builder.set_entry_point("query_or_respond") # 设置入口点为 query_or_respond
graph_builder.add_conditional_edges("query_or_respond",tools_condition,{END: END, "tools": "tools"},
)
graph_builder.add_edge("tools", "generate") # 从 tools 到 generate 的连接
graph_builder.add_edge("generate", END) # 从 generate 到 END 的连接memory = MemorySaver() # 创建内存保存器
graph = graph_builder.compile(checkpointer=memory) # 编译状态图,使用内存保存器
最后,我们设置一个线程ID,并模拟两个问题的问答过程:
# 指定线程 ID
config = {"configurable": {"thread_id": "abc123"}}# 输入第一个问题
input_message = "What is Task Decomposition?"
for step in graph.stream({"messages": [{"role": "user", "content": input_message}]},stream_mode="values",config=config,
):step["messages"][-1].pretty_print() # 打印最后一条消息内容# 输入第二个问题
input_message = "Can you look up some common ways of doing it?"
for step in graph.stream({"messages": [{"role": "user", "content": input_message}]},stream_mode="values",config=config,
):step["messages"][-1].pretty_print() # 打印最后一条消息内容
总的来说,这段代码是一个完整的流程,用于从网页加载文档、切分文档、存储文档向量,然后使用这些数据来回应用户的查询。下面是代码输出:
================================ Human Message =================================What is Task Decomposition?
================================== Ai Message ==================================
Tool Calls:retrieve (call_pUlHd3ysUAh2666YBKXL75XX)Call ID: call_pUlHd3ysUAh2666YBKXL75XXArgs:query: Task Decomposition
================================= Tool Message =================================
Name: retrieveSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
Content: Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Source: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
Content: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
================================== Ai Message ==================================Task Decomposition is the process of breaking down a complicated task into smaller, more manageable steps. It utilizes techniques like Chain of Thought (CoT) prompting, which encourages models to think step by step, enhancing performance on complex tasks. This approach helps clarify the model's reasoning and makes it easier to tackle difficult problems.
================================ Human Message =================================Can you look up some common ways of doing it?
================================== Ai Message ==================================
Tool Calls:retrieve (call_U0A6DW6gKGchUp6Nkt2exHlL)Call ID: call_U0A6DW6gKGchUp6Nkt2exHlLArgs:query: common methods for task decomposition
================================= Tool Message =================================
Name: retrieveSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
Content: Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Source: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}
Content: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
================================== Ai Message ==================================Common ways of Task Decomposition include using simple prompts like "Steps for XYZ.\n1." or "What are the subgoals for achieving XYZ?" Additionally, task-specific instructions can be employed, such as asking for a story outline when writing a novel, or incorporating human inputs to guide the decomposition process.LLM调用分析
因为LLM调用次数是和账户扣费相关的,所以我们需要知道钱花在了什么地方,我们深入分析以下几个部分来确定有多少次 LLM 调用。
状态图构建和执行分析
在状态图 (StateGraph) 的构建和执行过程中,以下节点涉及调用 LLM:
query_or_respondgenerate
流程分析
Step 1: 消息生成/工具调用
- 在
query_or_respond中,通过llm_with_tools.invoke(state["messages"])调用一次 LLM。
Step 2: 工具执行
- 在
tools中,并不涉及 LLM 调用,这里是调用定义的retrieve工具函数。
Step 3: 生成最终答案
- 在
generate节点中,通过llm.invoke(prompt)调用一次 LLM。
具体流程跟踪
当我们运行两个输入消息 "What is Task Decomposition?" 和 "Can you look up some common ways of doing it?",每次输入都会依次经过这三个阶段:
query_or_respond调用 LLM 1 次。tools调用,并不涉及 LLM。generate调用 LLM 1 次。
所以,每次输入消息会触发 2 次 LLM 调用。现在两个输入消息分别通过这些步骤:
- 第一次输入
"What is Task Decomposition?",经过 2 次 LLM 调用。 - 第二次输入
"Can you look up some common ways of doing it?",经过 2 次 LLM 调用。
总计:2 次输入消息 * 每次 2 次 LLM 调用 = 4 次 LLM 调用
对话回合管理
在上面的代码中,checkpointer 的确是用来管理多个对话回合和线程的。具体来看,代码中的 checkpointer 实际上是 MemorySaver(),它被用来保存和恢复对话的状态。通过 MemorySaver 类,可以记录对话的历史状态,并在需要时检索和恢复这些状态,这对于管理复杂对话流程非常有用,尤其是跨多个对话回合或者不同的线程。
这里是设置和使用 checkpointer 的部分代码:
from langgraph.checkpoint.memory import MemorySaver# 初始化 MemorySaver 作为 checkpointer
memory = MemorySaver()# 将 MemorySaver 作为 checkpointer 编译状态图
graph = graph_builder.compile(checkpointer=memory)
MemorySaver 是一个用于保存状态的工具,它可以帮助你在管理多个对话回合和不同的对话线程时保存和恢复状态。这样做的好处是,你可以在用户和系统之间的多轮对话中保持上下文一致性,从而提供更连贯和一致的用户体验。
具体来说,MemorySaver 如何帮助管理多个会话回合和线程呢?
-
状态保存:每当对话状态发生变化时,
MemorySaver会保存当前的状态。这包括用户的输入、模型的响应以及使用的工具等信息。 -
状态恢复:在继续对话时,
MemorySaver可以从保存的状态中恢复对话的上下文。这意味着即使在对话中断后,也可以从上次停止的地方继续。 -
线程管理:对于每一个对话线程,可以使用唯一的线程ID。在代码中,
config中提供了一个示例:config = {"configurable": {"thread_id": "abc123"}}这样的配置可以让系统知道当前对话是属于哪个线程,
MemorySaver可以根据线程ID来保存和恢复相应的状态。

代码中涉及到一个多轮对话:
- 用户输入:“What is Task Decomposition?”
- 系统通过
query_or_respond生成工具调用,并可能使用retrieve工具来检索相关信息。 - 系统使用
generate生成最终答案。
在这个过程中,每一步的状态都会由 MemorySaver 保存。因此,当用户继续问下一个问题时,比如“Can you look up some common ways of doing it?”,系统可以利用 MemorySaver 恢复之前保存的状态,确保对话能够连贯的继续下去。
LLM消息抓取
交互1

Request
{"messages": [[{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "What is Task Decomposition?","type": "human","id": "794404f1-e906-4923-adee-3a8f60501ab1"}}]]
}
Response
{"generations": [[{"text": "","generation_info": {"finish_reason": "tool_calls","logprobs": null},"type": "ChatGeneration","message": {"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "","additional_kwargs": {"tool_calls": [{"id": "call_pUlHd3ysUAh2666YBKXL75XX","function": {"arguments": "{\"query\":\"Task Decomposition\"}","name": "retrieve"},"type": "function"}],"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 15,"prompt_tokens": 49,"total_tokens": 64,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "tool_calls","logprobs": null},"type": "ai","id": "run-d0d6303a-0af6-4a01-9be0-7691c7663429-0","tool_calls": [{"name": "retrieve","args": {"query": "Task Decomposition"},"id": "call_pUlHd3ysUAh2666YBKXL75XX","type": "tool_call"}],"usage_metadata": {"input_tokens": 49,"output_tokens": 15,"total_tokens": 64,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"invalid_tool_calls": []}}}]],"llm_output": {"token_usage": {"completion_tokens": 15,"prompt_tokens": 49,"total_tokens": 64,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b"},"run": null,"type": "LLMResult"
}
交互2

request
{"messages": [[{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","SystemMessage"],"kwargs": {"content": "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, say that you don't know. Use three sentences maximum and keep the answer concise.\n\nSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.","type": "system"}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "What is Task Decomposition?","type": "human","id": "794404f1-e906-4923-adee-3a8f60501ab1"}}]]
}
response
{"generations": [[{"text": "Task Decomposition is the process of breaking down a complicated task into smaller, more manageable steps. It utilizes techniques like Chain of Thought (CoT) prompting, which encourages models to think step by step, enhancing performance on complex tasks. This approach helps clarify the model's reasoning and makes it easier to tackle difficult problems.","generation_info": {"finish_reason": "stop","logprobs": null},"type": "ChatGeneration","message": {"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "Task Decomposition is the process of breaking down a complicated task into smaller, more manageable steps. It utilizes techniques like Chain of Thought (CoT) prompting, which encourages models to think step by step, enhancing performance on complex tasks. This approach helps clarify the model's reasoning and makes it easier to tackle difficult problems.","additional_kwargs": {"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 64,"prompt_tokens": 384,"total_tokens": 448,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "stop","logprobs": null},"type": "ai","id": "run-c4a6b376-0377-4ca0-a689-d490cf841ca5-0","usage_metadata": {"input_tokens": 384,"output_tokens": 64,"total_tokens": 448,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"tool_calls": [],"invalid_tool_calls": []}}}]],"llm_output": {"token_usage": {"completion_tokens": 64,"prompt_tokens": 384,"total_tokens": 448,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b"},"run": null,"type": "LLMResult"
}
交互3


request
{"messages": [[{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "What is Task Decomposition?","type": "human","id": "794404f1-e906-4923-adee-3a8f60501ab1"}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "","additional_kwargs": {"tool_calls": [{"id": "call_pUlHd3ysUAh2666YBKXL75XX","function": {"arguments": "{\"query\":\"Task Decomposition\"}","name": "retrieve"},"type": "function"}],"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 15,"prompt_tokens": 49,"total_tokens": 64,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "tool_calls","logprobs": null},"type": "ai","id": "run-d0d6303a-0af6-4a01-9be0-7691c7663429-0","tool_calls": [{"name": "retrieve","args": {"query": "Task Decomposition"},"id": "call_pUlHd3ysUAh2666YBKXL75XX","type": "tool_call"}],"usage_metadata": {"input_tokens": 49,"output_tokens": 15,"total_tokens": 64,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"invalid_tool_calls": []}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","ToolMessage"],"kwargs": {"content": "Source: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.","type": "tool","name": "retrieve","id": "3c8ef510-5057-46b5-a054-0f832ff1341d","tool_call_id": "call_pUlHd3ysUAh2666YBKXL75XX","artifact": [{"id": "5a79841e-af10-4176-a401-ed6a33df7434","metadata": {"source": "https://lilianweng.github.io/posts/2023-06-23-agent/"},"page_content": "Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.","type": "Document"},{"id": "29fb08c3-b292-4bdd-b82e-73c7d5c2eff0","metadata": {"source": "https://lilianweng.github.io/posts/2023-06-23-agent/"},"page_content": "Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.","type": "Document"}],"status": "success"}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "Task Decomposition is the process of breaking down a complicated task into smaller, more manageable steps. It utilizes techniques like Chain of Thought (CoT) prompting, which encourages models to think step by step, enhancing performance on complex tasks. This approach helps clarify the model's reasoning and makes it easier to tackle difficult problems.","additional_kwargs": {"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 64,"prompt_tokens": 384,"total_tokens": 448,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "stop","logprobs": null},"type": "ai","id": "run-c4a6b376-0377-4ca0-a689-d490cf841ca5-0","usage_metadata": {"input_tokens": 384,"output_tokens": 64,"total_tokens": 448,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"tool_calls": [],"invalid_tool_calls": []}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "Can you look up some common ways of doing it?","type": "human","id": "0a330541-f893-4c38-9fb4-563f713406f3"}}]]
}
response
{"generations": [[{"text": "","generation_info": {"finish_reason": "tool_calls","logprobs": null},"type": "ChatGeneration","message": {"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "","additional_kwargs": {"tool_calls": [{"id": "call_U0A6DW6gKGchUp6Nkt2exHlL","function": {"arguments": "{\"query\":\"common methods for task decomposition\"}","name": "retrieve"},"type": "function"}],"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 17,"prompt_tokens": 476,"total_tokens": 493,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "tool_calls","logprobs": null},"type": "ai","id": "run-02649b1b-a159-4036-bf41-af98442264fc-0","tool_calls": [{"name": "retrieve","args": {"query": "common methods for task decomposition"},"id": "call_U0A6DW6gKGchUp6Nkt2exHlL","type": "tool_call"}],"usage_metadata": {"input_tokens": 476,"output_tokens": 17,"total_tokens": 493,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"invalid_tool_calls": []}}}]],"llm_output": {"token_usage": {"completion_tokens": 17,"prompt_tokens": 476,"total_tokens": 493,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b"},"run": null,"type": "LLMResult"
}
交互4

request
{"messages": [[{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","SystemMessage"],"kwargs": {"content": "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, say that you don't know. Use three sentences maximum and keep the answer concise.\n\nSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nSource: {'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}\nContent: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.","type": "system"}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "What is Task Decomposition?","type": "human","id": "794404f1-e906-4923-adee-3a8f60501ab1"}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "Task Decomposition is the process of breaking down a complicated task into smaller, more manageable steps. It utilizes techniques like Chain of Thought (CoT) prompting, which encourages models to think step by step, enhancing performance on complex tasks. This approach helps clarify the model's reasoning and makes it easier to tackle difficult problems.","additional_kwargs": {"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 64,"prompt_tokens": 384,"total_tokens": 448,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "stop","logprobs": null},"type": "ai","id": "run-c4a6b376-0377-4ca0-a689-d490cf841ca5-0","usage_metadata": {"input_tokens": 384,"output_tokens": 64,"total_tokens": 448,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"tool_calls": [],"invalid_tool_calls": []}},{"lc": 1,"type": "constructor","id": ["langchain","schema","messages","HumanMessage"],"kwargs": {"content": "Can you look up some common ways of doing it?","type": "human","id": "0a330541-f893-4c38-9fb4-563f713406f3"}}]]
}
response
{"generations": [[{"text": "Common ways of Task Decomposition include using simple prompts like \"Steps for XYZ.\\n1.\" or \"What are the subgoals for achieving XYZ?\" Additionally, task-specific instructions can be employed, such as asking for a story outline when writing a novel, or incorporating human inputs to guide the decomposition process.","generation_info": {"finish_reason": "stop","logprobs": null},"type": "ChatGeneration","message": {"lc": 1,"type": "constructor","id": ["langchain","schema","messages","AIMessage"],"kwargs": {"content": "Common ways of Task Decomposition include using simple prompts like \"Steps for XYZ.\\n1.\" or \"What are the subgoals for achieving XYZ?\" Additionally, task-specific instructions can be employed, such as asking for a story outline when writing a novel, or incorporating human inputs to guide the decomposition process.","additional_kwargs": {"refusal": null},"response_metadata": {"token_usage": {"completion_tokens": 62,"prompt_tokens": 467,"total_tokens": 529,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b","finish_reason": "stop","logprobs": null},"type": "ai","id": "run-03b1c7c8-562a-4466-9f8c-1ce1c0afe00d-0","usage_metadata": {"input_tokens": 467,"output_tokens": 62,"total_tokens": 529,"input_token_details": {"audio": 0,"cache_read": 0},"output_token_details": {"audio": 0,"reasoning": 0}},"tool_calls": [],"invalid_tool_calls": []}}}]],"llm_output": {"token_usage": {"completion_tokens": 62,"prompt_tokens": 467,"total_tokens": 529,"completion_tokens_details": {"accepted_prediction_tokens": 0,"audio_tokens": 0,"reasoning_tokens": 0,"rejected_prediction_tokens": 0},"prompt_tokens_details": {"audio_tokens": 0,"cached_tokens": 0}},"model_name": "gpt-4o-mini-2024-07-18","system_fingerprint": "fp_bba3c8e70b"},"run": null,"type": "LLMResult"
}
总结

状态和聊天记录对于聊天机器人来说非常重要,它们不仅帮助我们保持对话的一致性和上下文,还能提供更个性化和准确的服务。在实现上,我们可以根据需求选择内存、文件、数据库或者状态图等不同的方式来管理和保留聊天记录。希望这些内容对大家有所帮助,感谢大家的阅读!如果有问题或者想要深入探讨,欢迎随时交流!
相关文章:
AI - RAG中的状态化管理聊天记录
AI - RAG中的状态化管理聊天记录 大家好,今天我们来聊聊LangChain和LLM中一个重要的话题——状态化管理聊天记录。在使用大语言模型(LLM)的时候,聊天记录(History)和状态(State)管理是非常关键的。那我们先…...
JAVA安全—SpringBoot框架MyBatis注入Thymeleaf模板注入
前言 之前我们讲了JAVA的一些组件安全,比如Log4j,fastjson。今天讲一下框架安全,就是这个也是比较常见的SpringBoot框架。 SpringBoot框架 Spring Boot是由Pivotal团队提供的一套开源框架,可以简化spring应用的创建及部署。它提…...

【STM32系列】提升ADC采样精度的方法
资料地址 兆易创新GigaDevice-资料下载兆易创新GD32 MCU ADC简介 ADC转换包括采样、保持、量化、编码四个步骤。的采样电容上,即在采样开关 SW 关闭的过程中,外部输入信号通过外部的输入电阻 RAIN 和以及 ADC 采样电阻 RADC 对采样电容 CADC 充电。采样…...

前端面试如何出彩
1、原型链和作用域链说不太清,主要表现在寄生组合继承和extends继承的区别和new做了什么。2、推荐我的两篇文章:若川:面试官问:能否模拟实现JS的new操作符、若川:面试官问:JS的继承 3、数组构造函数上有哪些…...

Linux 切换用户的两种方法
sudo -su user1 与 su - user1 都可以让当前用户切换到 user1 的身份执行命令或进入该用户的交互式 Shell。但它们在权限认证方式、环境变量继承和 Shell 初始化过程等方面存在一些差异。 权限认证方式 su - user1 su 是 “switch user” 的缩写,默认情况下需要你输…...
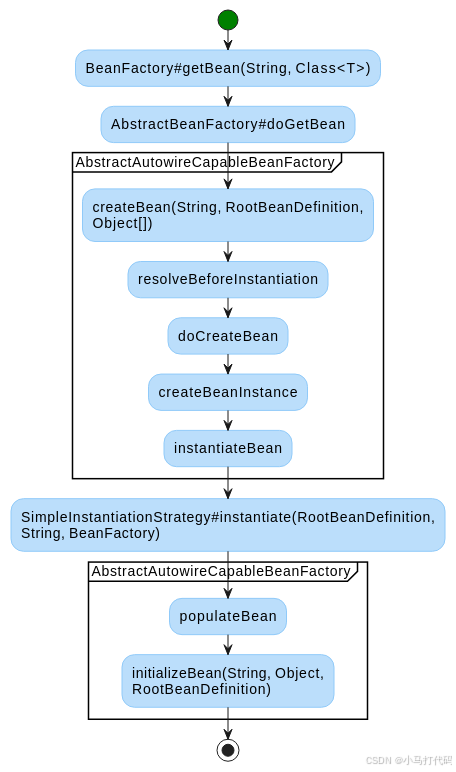
Spring Boot 3 中Bean的配置和实例化详解
一、引言 在Java企业级开发领域,Spring Boot凭借其简洁、快速、高效的特点,迅速成为了众多开发者的首选框架。Spring Boot通过自动配置、起步依赖等特性,极大地简化了Spring应用的搭建和开发过程。而在Spring Boot的众多核心特性中ÿ…...
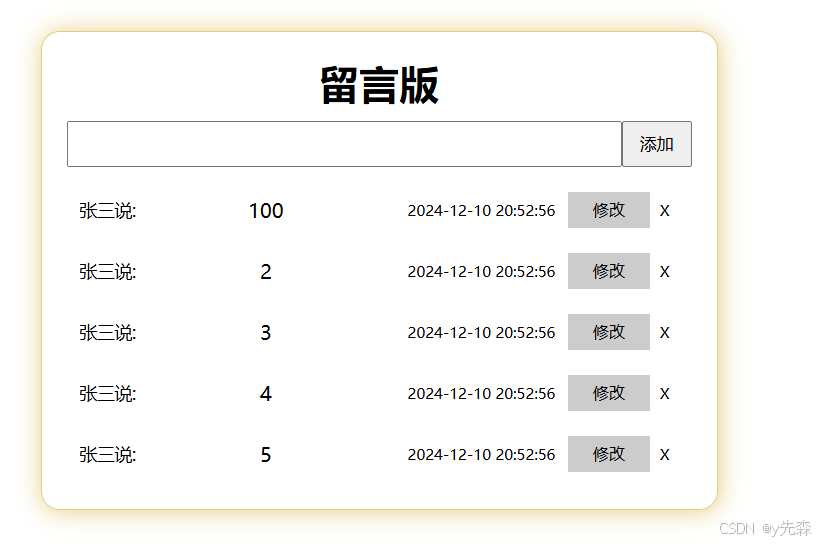
Vue实现留言板(实现增删改查)注意:自己引入Vue.js哦
代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><scri…...
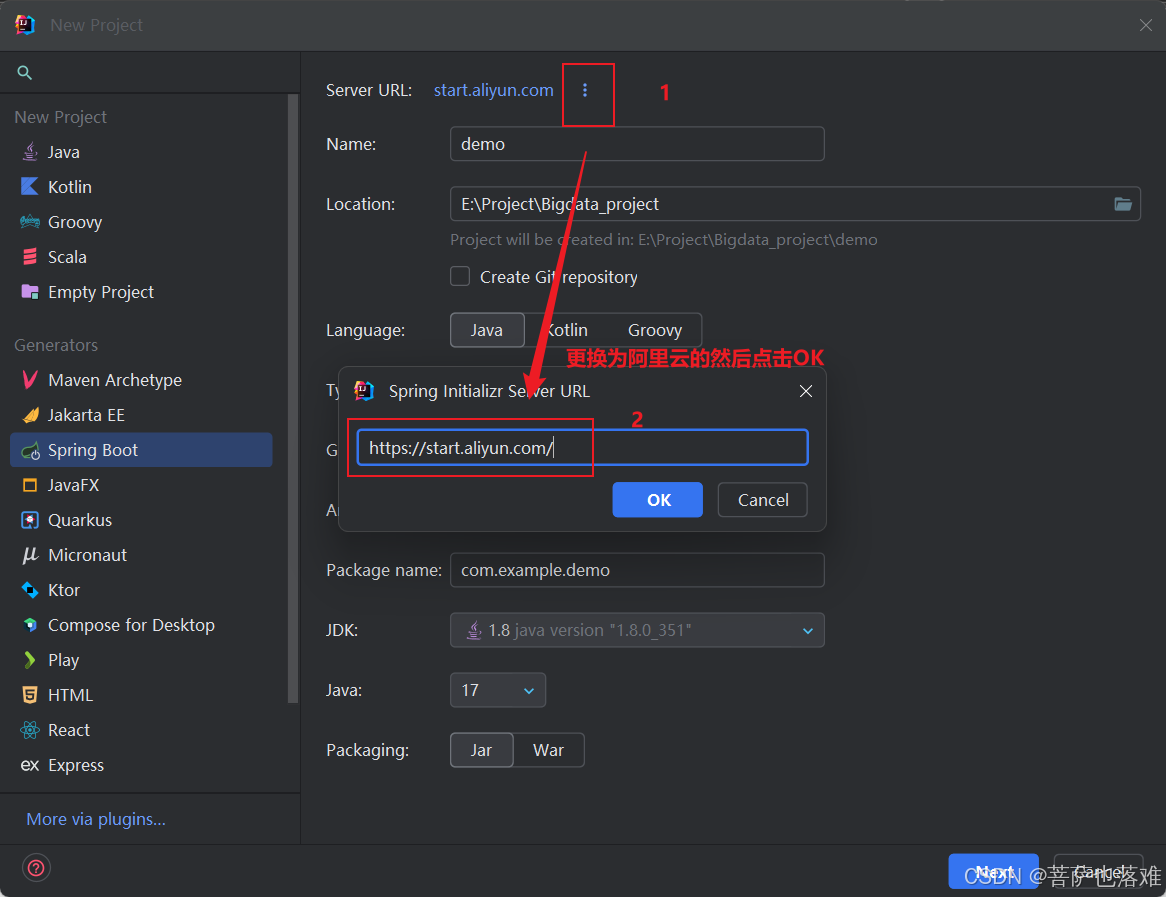
IDEA创建Spring Boot项目配置阿里云Spring Initializr Server URL【详细教程-轻松学会】
1.首先打开idea选择新建项目 2.选择Spring Boot框架(就是选择Spring Initializr这个) 3.点击中间界面Server URL后面的三个点更换为阿里云的Server URL Idea中默认的Server URL地址:https://start.spring.io/ 修改为阿里云Server URL地址:https://star…...
读取电视剧MP4视频的每一帧,检测出现的每一个人脸并保存
检测效果还不错,就是追踪有点难做 import cv2 import mediapipe as mp import os from collections import defaultdict# pip install msvc-runtime# 初始化OpenCV的MultiTracker # multi_tracker = cv2.MultiTracker_create() # multi_tracker = cv2.legacy.MultiTracker_cre…...

HTML前端开发-- Iconfont 矢量图库使用简介
一、SVG 简介及基础语法 1. SVG 简介 SVG(Scalable Vector Graphics)是一种基于 XML 的矢量图形格式,用于在网页上显示二维图形。SVG 图形可以无限缩放而不会失真,非常适合用于图标、图表和复杂图形。SVG 文件是文本文件&#x…...
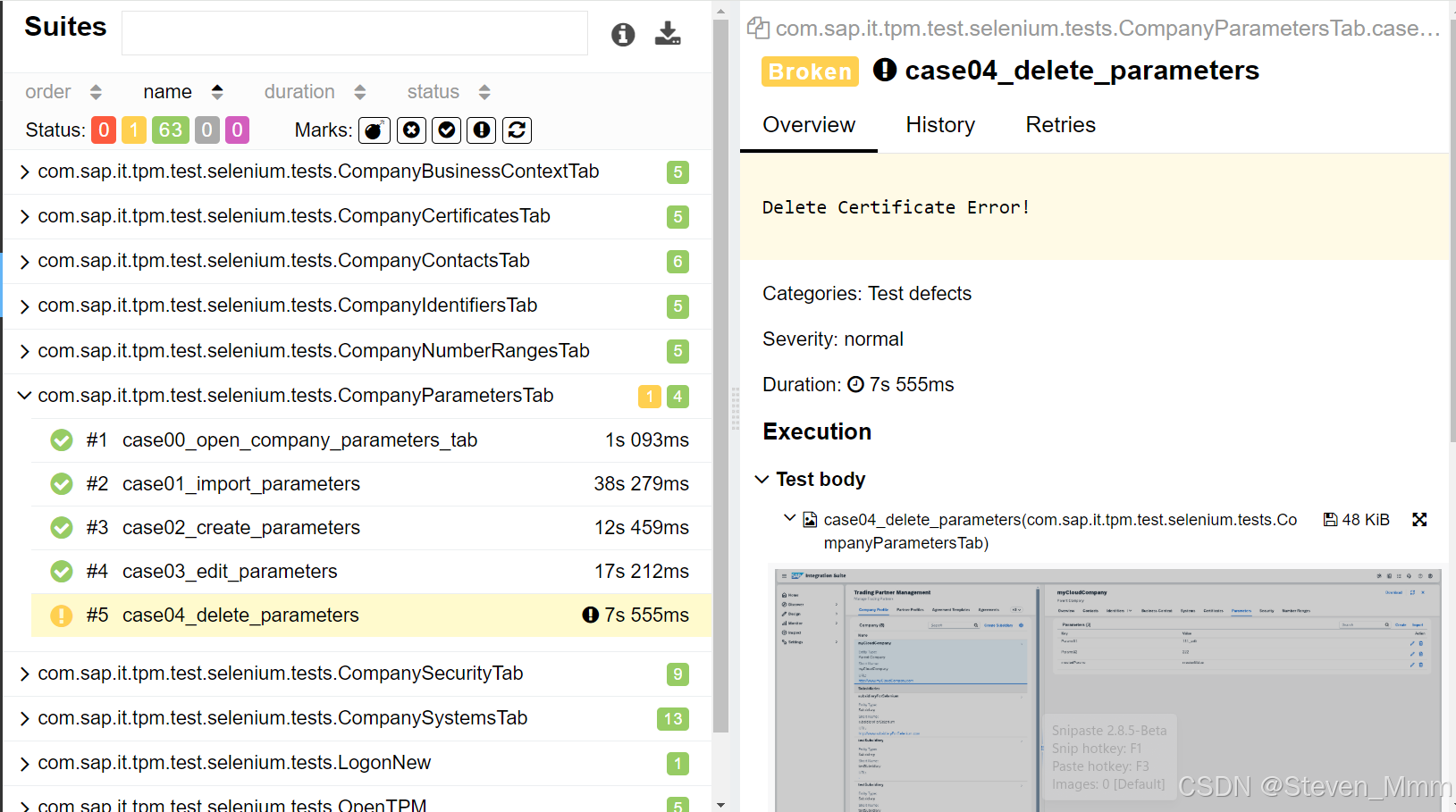
使用Allure作为测试报告生成器(Java+Selenium)
背景 JAVA项目中原先用Jenkinsseleniumselenium grid来日常测试UI并记录。 问题 当某一个testSuite失败时,当需要确认UI regression issue还是selenium test case自身的问题,需要去jenkins中查log,一般得到的是“Can not find element xxx…...

RocketMQ面试题合集
消费者获取消息是从Master Broker还是Slave Broker获取? Master Broker宕机,Slave Broker会自动切换为Master Broker吗? 这种Master-Slave模式不是彻底的高可用模式,他没法实现自动把Slave切换为Master。在RocketMQ 4.5之后&…...
Qt初识_对象树
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 Qt初识_对象树 收录于专栏【Qt开发】 本专栏旨在分享学习Qt的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 什么是对象树 为什么要引…...

axios的get和post请求,关于携带参数相关的讲解一下
在使用 Axios 发送 HTTP 请求时,GET 和 POST 请求携带参数的方式有所不同。以下是关于这两种请求方法携带参数的详细讲解: GET 请求携带参数 对于 GET 请求,参数通常附加在 URL 之后,以查询字符串的形式传递。 直接在 URL 中拼接…...

Vue前端开发-路由其他配置
在路由文件中,除了跳转配置外,还可以进行路径重定向配置,如果没有找到对应的地址,还可以实现404的配置,同时,如果某个页面需要权限登录,还可以进行路由守卫配置,接下来,分…...

框架建设实战7——定时任务组件
在金融系统中,或者其他对账系统里,往往离不开分布式定时任务。用来做查证或者重试处理。 分布式job目前一般有如下三种: 1.elastic job 当当出品,比较老牌。新公司用的应该不多了。 2.xxl-job 个人开源项目。便于二开;有简洁的后管配置界面,方便接入。 3.powerjob …...

mybatis 整合 ehcache
pom.xml <!-- ehcache依赖 --><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.1.0</version></dependency>ehcache.xml <?xml version"1.0" en…...
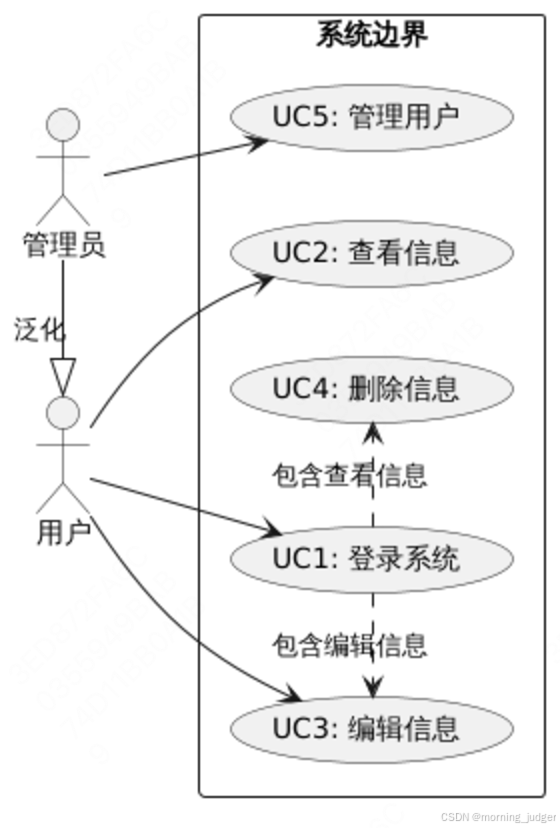
【PlantUML系列】用例图(三)
目录 一、组成部分 二、典型案例 一、组成部分 参与者(Actors):使用关键字 actor 后跟参与者的名称。用例(Use Cases):使用关键字 usecase 后跟用例的名称和编号(可选)。系统边界…...

发送请求时遇到了数据库完整性约束错误 1048 Column ‘platform‘ cannot be null
可以这样解决 在 Vue 2 中封装接口请求时,确保每次请求都包含 platform Header 参数的最佳实践是通过创建一个全局的 Axios 实例,并为这个实例设置默认的 Header。这样可以确保所有通过该实例发送的请求都会自动包含 platform 参数。此外,你…...
三菱FX3U模拟量产品的介绍
FX3u可编程控制器模拟量产品包括:特殊适配器、特殊功能模块的连接 1、连接在FX3U可编程控制器的左侧。 2、连接特殊适配器时,需要功能扩展板。 3、最多可以连接4台模拟量特殊适配器。 4、使用高速输入输出特殊适配器时,请将模拟量特殊适配器连…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...