Fluss:面向实时分析设计的下一代流存储
摘要:本文整理自阿里云智能 Flink SQL 和数据通道负责人、Apache Flink PMC 伍翀(花名:云邪)老师,在 Flink Forward Asia 2024 主会场的分享。主要分享了一种专为流分析设计的新一代存储解决方案——Fluss,并由阿里巴巴开源委员会副主席王峰先生,在 FFA 2024 现场进行了 Fluss 项目的开源。内容分为以下五个部分:
-
Kafka 在实时分析场景遇到的问题
-
Fluss:Flink Unified Streaming Storage
-
Fluss 核心特性
-
Fluss 未来规划
-
Fluss 开源
当前业界呈现出一个显著的趋势,即大数据的处理正在从离线模式转向实时化。我们可以观察到,多个行业和应用场景都在进行实时化的演进。例如,互联网、车联网和金融等领域都正通过挖掘实时数据来提升业务价值。

在技术方面,大数据计算架构经历了显著的演变。从最初的 Hive 传统数据仓库,到引入 Lakehouse 湖仓架构,再到目前国内流行的 Paimon 流式湖仓架构,这些演进的核心驱动力在于提升业务的时效性。从传统的 T+1 天模式,逐步缩短到 T+1 小时,再到 T+1 分钟。然而,由于湖存储架构是基于文件系统的,其分钟级延迟几乎是极限。但是许多业务场景,如搜索推荐、广告归因和异常检测,都要求秒级的实时响应。因此,业界亟需能够支持秒级存储的解决方案。尽管大数据技术已经取得了长足的发展,但在大数据分析场景中,仍然缺乏一款能够有效支持秒级存储的解决方案。
那么在大数据里面最常用的秒级存储是什么呢?当然是 Apache Kafka。Flink 与 Kafka 的组合也已经成为业界构建实时数仓的典型架构。然而,这个组合在实际应用中并不总是那么理想,原因在于当我们将 Kafka 应用于大数据分析时,会遇到一系列挑战和问题。
Kafka 在实时分析场景遇到的问题

一个主要的问题是,Kafka 不支持数据更新功能。在数据仓库中,“更新”是一个非常重要的功能,对于一个数仓来说,经常需要“更新”的能力去修正一些数据。由于 Kafka 不支持更新,所以它只能将主键上重复的数据都存储下来。当计算引擎消费这些数据时,就会接收到重复的数据。
为了确保计算结果的准确性,计算引擎必须执行去重操作。然而,这个去重过程本身是非常耗费资源的。在 Flink 中,这需要使用 State 来物化上游的全部数据,并且每次消费 Kafka 数据时,都必须承担去重的成本,这个成本是相当高的。这种高成本的去重要求限制了 Kafka 数据的业务复用能力。例如,在淘天集团构建实时数据中间层的过程中,由于 Kafka 的这些限制,他们选择不构建 DWS 层。

第二个主要问题是,Kafka 不支持数据探查功能。在数据仓库建设中,数据探查是一个基本能力。无论是排查问题还是进行数据探索,都需要进行数据查询。然而,Kafka 本质上是一个黑盒,不支持直接查询。为了解决这个问题,业界通常采用两种方案:
-
同步到 OLAP 系统:将 Kafka 数据同步到 OLAP 系统中进行查询。不过,这种方法会引入额外的系统组件,增加复杂性和成本。此外,数据在不同系统间的同步也可能导致不一致性。
-
使用 Trino 等查询引擎直接查询 Kafka:这种方法避免了数据同步问题,但由于 Kafka 仅支持 Full Scan,无法实现 Data Skipping,因此在处理大规模数据时效率较低。例如,在 1GB 数据上进行简单查询都可能需要一分钟,这使得这种方法在大规模应用中基本上不可行。

第三个问题是数据回溯的困难。在数据仓库中,数据回溯是常见需求,例如在物流行业中,可能需要回溯几个月的数据进行分析。然而,在 Kafka 中,长时间存储大量数据会导致成本过高,因此通常只能存储几天的数据。此外,当进行大规模数据回溯时,所有数据流量都必须经过 Kafka Broker,这会导致回溯操作的性能非常慢。同时,这种操作还会消耗 Broker 的 CPU 资源,污染其页面缓存(page cache),从而对其他在线业务产生负面影响。

最后一个问题是网络成本。根据多项数据资料显示,网络成本占据了 Kafka 成本的 88%。在数据仓库中,一写多读是非常常见的操作模式,并且每个消费者通常只消费数据的一部分。例如,在阿里巴巴内部的数万条 Flink SQL 作业中,平均每个作业仅使用了上游数据的 49% 的列。然而,当用户需要消费这 49% 的列时,仍然需要读取所有列的数据,这意味着需要承担 100% 的网络带宽成本。这种情况导致了网络资源的极大浪费。
总结来说,将 Kafka 用于实时分析场景时,会面临以下核心问题:不支持更新、无法探查、数据回溯难、网络成本高。这些问题导致 Flink + Kafka 的组合在某些实时分析应用场景中并不是最理想的选择。
那么其本质的原因是什么?

这是因为Kafka 是为流消息设计的,并不是为流分析设计的。每个系统都有其特定的定位和优势,Kafka 在消息队列场景中非常高效,因为它通常以行存格式(如 CSV、JSON、AVRO)存储数据。然而,对于需要处理大规模数据和复杂查询的分析场景来说,行存格式的效率则显得不足。需要底层存储具备强大的Data Skipping 能力,以及支持列裁剪和条件下推等特性。在这种情况下,列存格式显然更为适合。
Fluss:Flink Unified Streaming Storage

在构建这样的四象限矩阵时,我们可以观察到一个有趣的现象:象限左边是业务型系统,右边是分析型系统,上面是流存储,下面是表存储。可以看到,业务型系统里面不管是数据库,还是流存储,都采用的是行存,因为行存在这个场景更为高效。相反,像 Iceberg, Snowflake 这些分析型系统都采用的列存,因为列存在分析场景更高效。在这个矩阵中,右上角是一个空白区域,代表这个市场里空缺了一个存储,即面向分析场景的流存储,不出意料的话,这个流存储采用的会是列存格式。
为了填补这一市场空白,并解决 Flink 在实时流分析场景中的痛点问题,我们在两年前发起了一个流存储项目,命名为 "FLink Unified Streaming Storage",取了项目名的首字母缩写,拼成了 Fluss 这个单词。值得一提的是,Flink 这个名字源自德语,意为“敏捷迅速”,而 Fluss 恰巧也是个德语单词,意为“河流”。这种命名不仅向 Flink 项目的起源致敬,也象征着流数据如同河流般源源不断地流动、分发,并最终汇聚到数据湖中。

Fluss 核心特性
接下来介绍一下 Fluss 的一些核心特性:

首先,不出所料,Fluss 采用列式的流存储。在底层文件存储中采用了 IPC Streaming Format 协议,而 Arrow 是一种非常优秀的流式列存储格式。基于 Arrow,我们实现了非常高效的列裁剪功能。右侧展示了对 Fluss 和 Kafka 的基准测试结果。横轴表示读取列的数量,纵轴表示读取吞吐量。可以看到,随着裁剪的列数增加,Fluss 的读取性能成比例上升。当裁剪到 90% 的列时,Fluss 的读取吞吐量已经提高了 10 倍。此外,Fluss 的列裁剪是在服务端进行的,这意味着发送给客户端的数据已经是裁剪过的,从而节省了大量的网络成本。

第二点,实时更新和CDC是流分析中非常依赖的存储能力,我们也对此进行了支持。可以理解为 Fluss 的流存储基础是一个日志表(Log Tablet),我们在日志之上构建了 KV 索引,从而支持高效的实时更新。Log 和 KV 之间的关系类似于流表的二象性,KV 的更新会生成变更日志(Changelog)写入 Log Tablet;在故障恢复时,Log Tablet 的数据又用于恢复键值表(KV Tablet)。KV Tablet 底层实际上是一个 RocksDB 的 LSM 树。因此,我们将流存储与 LSM 结构结合,支持大规模实时更新以及部分列的更新,从而实现高效的宽表拼接。
此外,KV 生成的 Changelog 可以直接被 Flink 流读取,无需额外的去重操作,节省了大量计算资源,实现了数据的业务复用。由于我们构建了 KV 索引,因此可以支持高性能的主键点查,并可作为实时处理链路中的维表关联。用户还可以通过点查的 query 语句直接探查 Fluss 数据,我们还支持 LIMIT、COUNT 等查询功能,以满足用户的数据探查需求。
Fluss 还有一个非常重要的特性是湖流一体。过去,用户为了搭建实时链路和离线链路,同样一份数据需要在流存储和湖存储冗余存储,造成成本浪费。湖流一体的概念是指“湖存储的数据”和“流存储的数据”能够作为一个整体进行管理和消费,从而避免数据的冗余存储,避免数据和元数据不一致的问题。

在底层,Fluss 维护了一个 Compaction Service,该服务会自动地将 Fluss 数据转换为湖存储的格式,并确保两边元数据的一致性。此外,它还保证两边的数据分布也是一致的,即分区和分区一一对齐,Bucket 和 Bucket 也一一对齐。这使得在流转湖的过程中,无需引入网络 Shuffle,只需将 Arrow 文件直接转换为 Parquet 文件即可。这种转换在业界已有非常成熟且高效的实现。
在拥有湖和流两层数据后,Fluss 的一个关键特性是共享数据。具体来说,湖存储作为流存储的历史数据层,负责存储长周期、分钟级延迟的数据;而流存储作为湖存储的实时数据层,负责存储短周期、毫秒级延迟的数据,这两者的数据可以互相共享。当进行流读取时,湖存储可以作为历史数据提供高效的回溯性能。在回溯到当前位点后,系统会自动切换到流存储继续读取,并确保不会读取重复数据。在批查询分析中,流存储可以为 Lakehouse 提供实时数据的补充,从而实现 Lakehouse 秒级新鲜度的分析。我们将这种功能称为 Union Read。
除此之外,我们同步到湖存储的格式完全遵循现有湖存储的开放协议,因此现有的一些查询引擎(如 Spark、StarRocks、Trino)可以直接查询湖存储中的数据,无缝融入用户已有的 Lakehouse 架构中。目前,Fluss 已经完成了对 Paimon 的完全集成,对 Iceberg 的集成也在计划中。

这就是我们Fluss整体的架构图,Fluss是一个面向实时分析的流存储。Fluss 需要维护一个 Server 集群,提供实时读写的能力,同时使用 Remote Storage 来做数据的分层,降低数据存储成本。并且跟Lakchouse 做了一个非常无缝的集成来支持丰富的查询能力。Fluss 的核心特性包括实时的流读流写、列式裁剪、流式的更新、CDC订阅、实时点查、还有湖流一体。

Fluss 的核心特性结合,实现了一个非常理想的应用场景 Delta Join。在 Flink 中,双流 Join 是一个非常基础的功能,常用于构建宽表。然而,这也是一个常常让开发人员感到头疼的功能。因为双流 Join 需要在 State 中维护上游全量的数据,这导致其状态通常非常庞大。例如,淘宝最大的 Flink 作业之一是成交引导的双流 Join(曝光关联订单),需要消耗 50TB 的状态。但这带来了很多问题,包括成本高、作业不稳定、Checkpoint超时、重启恢复慢等等。
因此我们充分利用 Fluss 的 CDC 流读+索引点查的能力研发了一套新的 Flink 的 Join 算子实现,叫 Delta Join。Delta Join 可以简单理解成“双边驱动的维表Join”,就是左边来了数据,就根据Join Key去点查右表;右边来了数据,就根据 Join Key 去点查左表。全程就像维表Join一样不需要state,但是实现了双流Join一样的语义,即任何一边有数据更新,都会触发对关联结果的更新。
在测试中,我们使用了淘宝最大的双流 Join 作业进行性能评估。在从双流 Join 迁移到 Delta Join 后,成功减免了 50TB 的大状态,使得作业运行更加稳定,Checkpoint 也不再超时。在双十一的数据压测回追中,我们发现,在保证相同吞吐量的情况下,Flink 的资源消耗能够降低10倍,从2300 CU 减少到200 CU。此外,在回追过程中,我们还可以利用湖流一体归档的 Paimon 表加上 Flink Batch Join 进行数据回追,将回追1天数据的时间从4小时缩短到0.5小时。使用批作业进行数据回追,展示了流批一体的一个非常有前景的应用场景。
除了资源的减少和性能的提升,对于用户最大的收益其实是灵活性的提升。以前的 State 是 Flink 内置的黑盒,用户看不见摸不着,一修改作业就要重跑 State,耗时耗力。在使用 Delta Join 后,相当于状态与作业进行了解耦,修改作业不需要重跑 State,所以回追很高效。并且数据都在 Fluss 里面,变得可查可分析,提升了业务灵活性和开发效率。目前,我们已经在 Flink 社区提交了 Delta Join 的 FLIP-486 提案,对于这个提案感兴趣的朋友可以关注一下。
Fluss 未来规划

关于 Fluss 的未来规划,最重要的有三件事,这三件事分别对应了 Fluss 与三个开源软件之间的关系:
-
Kafka 协议兼容:这是为了帮助已有的流数据更好地迁移到 Fluss 上。
-
与 Flink 的深度协同优化:这一规划包括通过存储+优化器+执行引擎的协同优化,以解决之前存在的一些难点和痛点。Delta Join 就是一个很好的例子,通过这种深度协同,Fluss 可以与 Flink 紧密结合,提升整体的流处理性能和稳定性。
-
为 Paimon 提供实时数据层:通过打造湖流一体架构,Fluss 希望与 Paimon 结合,提供一个实时与离线一体化的存储解决方案。
Fluss 开源
在11月29日举办的 Flink Forward Asia 2024 大会主题演讲上,阿里巴巴正式开源了 Fluss 项目(https://github.com/alibaba/fluss)。阿里巴巴开源委员会副主席王峰先生,在现场进行了 Fluss 项目的开源,赢得了现场观众的热烈反响。

Fluss 目前已经在 GitHub 上以 Apache 2.0 协议正式开源,项目地址为:https://github.com/alibaba/fluss,欢迎大家关注和 Star。并且我们计划于 2025 年将其捐赠到 Apache 软件基金会。
相关文章:
Fluss:面向实时分析设计的下一代流存储
摘要:本文整理自阿里云智能 Flink SQL 和数据通道负责人、Apache Flink PMC 伍翀(花名:云邪)老师,在 Flink Forward Asia 2024 主会场的分享。主要分享了一种专为流分析设计的新一代存储解决方案——Fluss,…...

【一本通】质因数分解
【一本通】质因数分解 C语言实现C 语言实现Java语言实现Python语言实现 💐The Begin💐点点关注,收藏不迷路💐 已知正整数n 是两个不同的质数的乘积,试求出较大的那个质数。 输入 输入只有一行,包含一个正…...

vue2+html2canvas+js PDF实现试卷导出和打印功能
1.首先安装 import html2canvas from html2canvas; import { jsPDF } from jspdf; 2.引入打印插件print.js import Print from "/assets/js/print"; Vue.use(Print) // 打印类属性、方法定义 /* eslint-disable */ const Print function (dom, options) {if (…...

【Python网络爬虫 常见问题汇总】
目录 1. 爬取图片出现403解决办法:设置请求头中的Referer字段 2.关于干坏事的问题后续不定期更新 欢迎共同探讨学习进步 1. 爬取图片出现403 问题出自案例9,已解决。 【Python网络爬虫笔记】9- 抓取优美图库高清壁纸 当在爬取图库图片时遇到 403 错误…...

Java SpringBoot 项目怎样在 IDEA 中运行、部署
大家好,我是程序员徐师兄,今天为大家带来的是Java SpringBoot 项目怎样在 IDEA 中运行、部署。Java 项目的安装部署教程,包括软件的下载,软件的安装。该系统采用 Java 语言开发,SpringBoot 框架,MySql 作为…...

GAMES101:现代计算机图形学-笔记-10
今天来聊一些基本的概念:相机,棱镜与光场。 众所周知,成像的方法有两种:合成与捕获。 像我们之前所学的内容如光栅化,如光线追踪,本质上都是合成图像的方法,他们只是在计算机中模拟来成像。 那…...

【前端面试】Http篇
1. HTTPS 概念 加密(Encryption) 防止数据被截获 数据完整性(Data Integrity) 防止数据篡改 身份验证(Authentication) 验证网站的真实性 2. HTTPS 与 HTTP 的区别 HTTP 是明文传输,HTTPS 是…...

ZZCMS2023存在跨站脚本漏洞(CNVD-2024-44822、CVE-2024-44818)
ZZCMS是一款用于搭建招商网站的CMS系统,由PHP语言开发,可快速搭建:医药招商、保健品招商、化妆品招商、农资招商、孕婴童招商、酒类副食类等招商网站。 国家信息安全漏洞共享平台于2024-11-14公布其存在跨站脚本漏洞。 漏洞编号:…...

Android 15 前台服务类型的变更
在 Android 15 中对前台服务类型做出以下更改。 仍在处理中的媒体内容 要在其清单中声明的前台服务类型 android:foregroundServiceType mediaProcessing在清单中声明的权限 FOREGROUND_SERVICE_MEDIA_PROCESSING要传递给 startForeground() 的常量 FOREGROUND_SERVICE_TYPE_ME…...

微信小程序开发简易教程
微信小程序文件结构详解 1. 项目配置文件 project.config.json 项目的配置文件包含项目名称、appid、编译选项等配置示例: {"description": "项目配置文件","packOptions": {"ignore": []},"setting": {&quo…...

树莓派 发那科 Fanuc Linux跨平台CNC数控数据采集协议,TCP协议包
市面上的数控基本都支持了跨平台通讯,下面以发那科为列讲解跨平台协议如何通讯,无需任何DLL,适配任何开发语言,纯Socket通讯 先上采集图 握手包:a0 a0 a0 a0 00 01 01 01 00 02 00 02 释放包:a0 a0 a0 a…...

Ubuntu中安装配置交叉编译工具并进行测试
01-下载获取交叉编译工具的源码 按照博文 https://blog.csdn.net/wenhao_ir/article/details/144325141的方法,把imx6ull的BSP下载好后,其中就有交叉编译工具。 当然,为了将来使用方便,我已经把它压缩并传到了百度网盘ÿ…...

C++核心day3作业
作业: 1.整理思维导图 2.整理课上代码 3.把课上类的三个练习题的构造函数写出来 函数全部类内声明,类外定义 定义一个矩形类Rec,包含私有属性length、width,包含公有成员方法: void set_length(int l); //设置长度v…...

socket UDP 环路回显的服务端
基于socket通讯的方式,无论用http或者udp或者自定义的协议,程序结构都是类似的。这个以UDP协议为例简要说明。 #include <stdio.h> // 标准输入输出库 #include <sys/types.h> // 提供了一些数据类型,如ssize_t #include <sy…...

springboot/ssm车辆违章信息管理系统Java代码web项目汽车违章处罚源码
基于springboot(可改ssm)htmlvue项目 springboot/ssm车辆违章信息管理系统Java代码web项目汽车违章处罚源码 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库&…...

5G模组AT命令脚本-关闭模组的IP过滤功能
关闭模组的IP过滤功能 关闭模组的IP过滤功能 5G 模组通常使用nat方式为 下挂设备或上位机提供上网服务,默认情况,不做NAt的包无法经由 模组转发,如果禁掉这个限制 ,可使用本文中的配置命令本脚本用于关闭模组的IP过滤功能…...
)
STM32:实现ping命令(lwip)
目录 0.协议介绍ICMP数据包格式ping指令发送的ICMP回声请求消息ping指令接收的ICMP回声应答消息1.实现步骤2.源码分析2.1 初始化函数2.2 发送函数2.3 回调函数2.3.1 函数定义:2.3.2 解析数据包:2.3.3.处理ICMP数据包:2.3.4 资源释放:2.3.5 返回值:3.源码展示4.源码链接5.问…...

nvm安装指定版本显示不存在及nvm ls-remote 列表只出现 iojs 而没有 node.js 解决办法
在使用 nvm install 18.20.3 安装 node 时会发现一直显示不存在此版本 Version 18.20.3 not found - try nvm ls-remote to browse available versions.使用 nvm ls-remote 查看可安装列表时发现,列表中只有 iojs 解决方法: 可以使用以下命令查看可安装…...

Spring Boot 中 WebClient 的实践详解
在现代微服务架构中,服务之间的通信至关重要。Spring Boot 提供了 WebClient,作为 RestTemplate 的替代方案,用于执行非阻塞式的 HTTP 请求。本文将详细讲解 WebClient 的实践,包括配置、使用场景以及常见的优化策略,帮…...

在GITHUB上传本地文件指南(详细图文版)
这份笔记简述了如何在GITHUB上上传文件夹的详细策略。 既是对自己未来的一个参考,又希望能给各位读者带来帮助。 详细步骤 打开目标文件夹(想要上传的文件夹) 右击点击git bash打开 GitHub创立新的仓库后,点击右上方CODE绿色按…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...
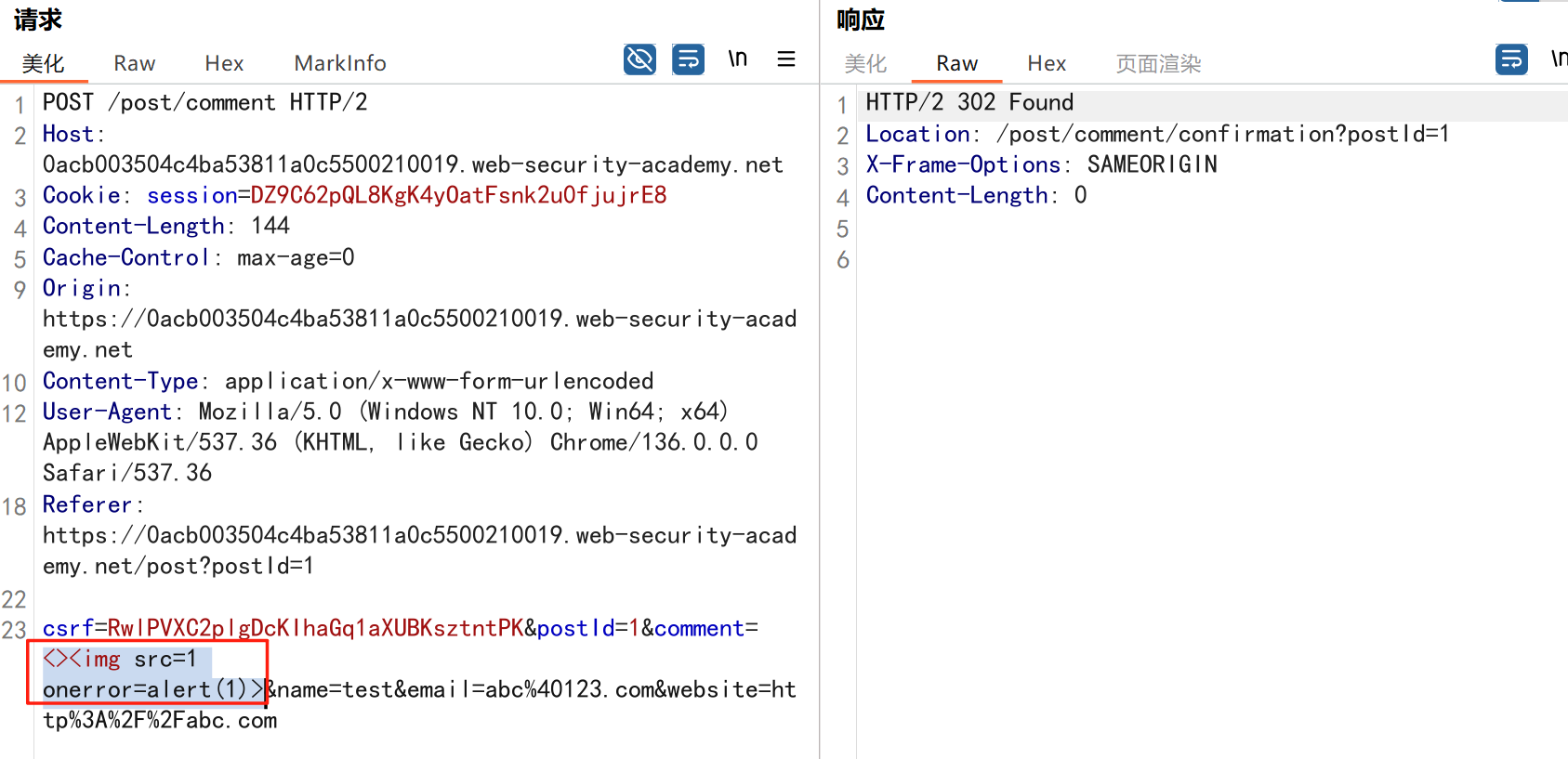
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...

文件上传漏洞防御全攻略
要全面防范文件上传漏洞,需构建多层防御体系,结合技术验证、存储隔离与权限控制: 🔒 一、基础防护层 前端校验(仅辅助) 通过JavaScript限制文件后缀名(白名单)和大小,提…...