使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
目标检测技术作为计算机视觉领域的核心组件,在自动驾驶系统、智能监控、零售分析以及增强现实等应用中发挥着关键作用。本文将详细介绍PaliGemma2模型的微调流程,该模型通过整合SigLIP-So400m视觉编码器与Gemma 2系列的高级语言模型,专门针对目标检测任务进行了优化设计。
本文适用于机器学习工程师和研究人员,旨在提供系统化的技术方案,帮助读者掌握PaliGemma2在目标检测项目中的实践应用。

PaliGemma2系统架构
PaliGemma2作为一个先进的多模态机器学习系统,实现了视觉和语言能力的深度集成。通过将SigLIP-So400m视觉编码器与Gemma 2系列语言模型相结合,该系统在目标检测任务中展现出优异的性能表现。
核心技术特性
多模态融合机制:实现视觉数据与语言描述的高效整合处理。
三阶段训练架构:
- 阶段一:在多样化多模态任务集上进行视觉和语言组件的联合训练
- 阶段二:通过更高分辨率(448px²和896px²)的图像训练增强细节捕获能力
- 阶段三:针对特定目标任务进行专项微调优化
系统性能优势:相较于原始PaliGemma模型,在各种分辨率和模型规模下均实现了性能提升,具有更高的准确率和计算效率。
可扩展性设计:支持模型规模和分辨率的灵活调整,可根据具体任务需求进行适配。
PaliGemma2不仅是对现有技术的改进,更代表了视觉-语言模型集成领域的重要技术突破,为复杂目标检测任务提供了强大的技术支持。
开发环境构建
在开始微调流程之前,我们先构建PaliGemma2的开发环境。这里使用免费的Google Colab。为确保模型训练的高效执行,需要进行以下运行时配置:
- 开启GPU支持:- 在顶部菜单中选择
Edit- 进入Notebook settings配置界面- 将Hardware accelerator设置为GPU- 优先选择A100 GPU配置,如不可用则使用T4 GPU作为替代方案- 确认配置并保存 - 验证GPU可用性:
!nvidia-smi
执行上述命令后,系统将返回GPU的详细信息,包括型号、显存容量及使用状态。如果配置正确,应该能看到完整的GPU信息输出。
API认证系统配置
为了安全地访问相关服务,需要正确配置API认证信息。本节详细说明HuggingFace和Roboflow的API配置流程。
HuggingFace认证配置
- 获取访问令牌:- 点击
New Token- 设置令牌名称(建议使用Colab-FineTuning-Token)- 根据开发需求设置适当的权限级别- 生成并安全保存令牌信息- 访问HuggingFace平台的设置页面- 导航至Access Tokens部分- 创建新令牌:
Roboflow认证配置
- 获取API密钥:- 登录Roboflow平台- 进入
Settings>API配置界面- 获取私有API密钥
安全凭证管理
在Colab环境中,使用内置的安全凭证管理系统存储API密钥:
- 访问凭证管理:- 点击Colab左侧面板的
Secrets(🔑)图标 - 配置HuggingFace令牌:- 选择
Add a new secret- 设置名称:HF_TOKEN- 输入HuggingFace访问令牌- 保存配置 - 配置Roboflow API密钥:- 添加新的安全凭证- 设置名称:
ROBOFLOW_API_KEY- 输入Roboflow API密钥- 保存配置
通过使用Colab的安全凭证管理系统,可以有效防止API密钥在开发过程中泄露,同时保证代码的可移植性。系统会自动加密存储这些敏感信息,并在运行时安全地注入到开发环境中。
安全性考虑
在配置过程中,需要注意以下安全事项:
- API密钥管理:- 避免在代码中硬编码API密钥- 使用环境变量或安全凭证系统管理敏感信息- 定期轮换API密钥以提高安全性
- 访问控制:- 为API密钥设置最小必要权限- 监控API的使用情况- 及时撤销不再使用的访问令牌
数据集预处理系统
数据集的质量和预处理直接影响模型的训练效果。本节详细阐述如何构建高质量的目标检测数据处理流程,重点说明使用Roboflow平台进行数据集管理和预处理的技术实现。
依赖库安装
首先需要安装必要的Python库,这些库提供了数据处理、模型微调和可视化等核心功能:
!pipinstall-qroboflowsupervisionpeftbitsandbytestransformers==4.47.0
各个库的具体功能说明:
roboflow: 提供数据集管理和API交互功能supervision: 实现目标检测任务的工具集,包括可视化和评估指标计算peft: 支持参数高效微调技术,如LoRA(低秩适应)bitsandbytes: 提供大型模型训练的优化支持transformers: HuggingFace的深度学习模型库,提供预训练模型访问
数据集获取与初始化
通过Roboflow API获取数据集,实现自动化的数据集下载和格式转换:
fromroboflowimportRoboflowfromgoogle.colabimportuserdata# 从环境变量获取API密钥ROBOFLOW_API_KEY=userdata.get('ROBOFLOW_API_KEY')rf=Roboflow(api_key=ROBOFLOW_API_KEY)# 初始化项目和版本project=rf.workspace("roboflow-jvuqo").project("poker-cards-fmjio")version=project.version(4)# 下载PaliGemma格式的数据集dataset=version.download("paligemma")
此代码段实现了以下功能:
- 建立与Roboflow平台的安全连接
- 访问特定的项目空间和数据集版本
- 将数据集转换为PaliGemma2兼容的格式并下载
数据集注释分析
检查数据集注释的结构和质量对于理解训练数据至关重要:
!head-n5 {dataset.location}/dataset/_annotations.train.jsonl
JSONL格式的注释文件具有以下结构:
image: 图像文件的引用路径prefix: 描述性标签和指令suffix: 包含边界框坐标和标签的详细注释
数据可视化系统实现
实现一个数据可视化系统,用于验证注释质量和检查数据分布:
importcv2importjsonimportsupervisionassvfromtypingimportListdefread_n_lines(file_path: str, n: int) ->List[str]:"""读取指定数量的注释行Args:file_path: 注释文件路径n: 需要读取的行数Returns:包含注释数据的字符串列表"""withopen(file_path, 'r') asfile:lines= [next(file).strip() for_inrange(n)]returnlinesimages= []lines=read_n_lines(f"{dataset.location}/dataset/_annotations.train.jsonl", 25)first=json.loads(lines[0])# 解析数据集类别信息CLASSES=first.get('prefix').replace("detect ", "").split(" ; ")# 处理每个样本并生成可视化结果forlineinlines:data=json.loads(line)image=cv2.imread(f"{dataset.location}/dataset/{data.get('image')}")(h, w, _) =image.shape# 将注释转换为检测对象detections=sv.Detections.from_lmm(lmm='paligemma',result=data.get('suffix'),resolution_wh=(w, h),classes=CLASSES)# 添加可视化标注image=sv.BoxAnnotator(thickness=4).annotate(image, detections)image=sv.LabelAnnotator(text_scale=2, text_thickness=4).annotate(image, detections)images.append(image)# 生成可视化网格sv.plot_images_grid(images, (5, 5))

以上步骤建立了一个完整的数据集预处理和验证系统,为后续的模型训练提供高质量的数据支持。这个系统的实现确保了数据的质量和可靠性,是模型成功训练的重要基础。
PaliGemma2模型初始化与配置
完成数据预处理后,下一个关键步骤是正确初始化和配置PaliGemma2模型。
核心组件导入
首先导入模型所需的基础组件:
importtorchfromtransformersimportPaliGemmaProcessor, PaliGemmaForConditionalGeneration
这些组件的作用如下:
- torch库提供了深度学习的基础框架支持,包括张量运算和GPU加速功能
- transformers库中的PaliGemma相关组件提供了预训练模型的访问和处理能力
模型系统初始化
以下代码实现了模型系统的完整初始化过程:
# 模型标识符配置MODEL_ID="google/paligemma2-3b-pt-448"# 设备环境检测与配置DEVICE=torch.device("cuda"iftorch.cuda.is_available() else"cpu")# 初始化模型处理器processor=PaliGemmaProcessor.from_pretrained(MODEL_ID)# 设定计算精度TORCH_DTYPE=torch.bfloat16# 加载预训练模型并部署到指定设备model=PaliGemmaForConditionalGeneration.from_pretrained(MODEL_ID, torch_dtype=TORCH_DTYPE).to(DEVICE)
各配置参数的技术说明:
- MODEL_ID定义了要使用的具体模型版本,这里选择了3B参数量、448分辨率的预训练版本
- DEVICE配置实现了自动设备选择,优先使用GPU以提升计算效率
- TORCH_DTYPE设置为bfloat16,这种混合精度格式在保持计算精度的同时可以显著减少显存占用
模型组件优化
为了提高微调效率,需要对模型的特定组件进行优化配置:
# 冻结视觉编码器参数forparaminmodel.vision_tower.parameters():param.requires_grad=False# 冻结多模态投影器参数forparaminmodel.multi_modal_projector.parameters():param.requires_grad=False
这段代码实现了以下优化策略:
- 通过设置requires_grad=False冻结视觉编码器的参数,防止在微调过程中对预训练好的视觉特征提取能力造成破坏
- 同样冻结多模态投影器,保持其在预训练阶段获得的模态融合能力
高效微调配置
对于需要在有限计算资源下进行微调的场景,可以实现以下参数高效微调方案:
# LoRA和QLoRA配置示例fromtransformersimportBitsAndBytesConfigfrompeftimportget_peft_model, LoraConfig# 量化配置bnb_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.bfloat16)# LoRA适配配置lora_config=LoraConfig(r=8, # LoRA的秩,影响参数量和模型容量target_modules=["q_proj", "o_proj", "k_proj", "v_proj","gate_proj", "up_proj", "down_proj"],task_type="CAUSAL_LM")# 模型转换与参数统计model=PaliGemmaForConditionalGeneration.from_pretrained(MODEL_ID, device_map="auto")model=get_peft_model(model, lora_config)model.print_trainable_parameters()# 更新计算精度TORCH_DTYPE=model.dtype
我们通过BitsAndBytesConfig实现模型的4比特量化,显著减少显存占用。LoRA配置定义了低秩适应的具体参数,包括秩的大小和目标模块的选择。通过get_peft_model转换原始模型为支持参数高效微调的版本。print_trainable_parameters函数提供了可训练参数的统计信息,帮助评估微调的计算需求
配置验证
在开始训练前,建议执行以下验证步骤:
- 确认模型已正确加载到指定设备(CPU/GPU)
- 验证模型的计算精度设置
- 检查可训练参数的比例和分布
- 测试模型的基础推理能力
数据加载系统实现
数据加载系统的效率和正确性对训练过程有着决定性影响。本节详细说明如何构建一个高效的数据加载系统,以确保模型能够以最优的方式接收训练数据。
基础组件导入
首先导入数据处理所需的核心组件:
importosimportrandomfromPILimportImagefromtypingimportList, Dict, Any, Tuplefromtorch.utils.dataimportDataset, DataLoader
这些组件各自承担不同的数据处理职责:
- os模块提供文件系统操作能力
- random模块用于实现数据增强中的随机化处理
- PIL库负责图像文件的读取和预处理
- typing模块提供类型注解支持,增强代码的可维护性
- torch.utils.data模块提供数据集管理的基础框架
自定义数据集类实现
以下是针对JSONL格式数据的自定义数据集类实现:
classJSONLDataset(Dataset):"""JSONL格式数据集的封装类该类提供了对JSONL格式注释文件和对应图像数据的统一访问接口。属性:jsonl_file_path: 注释文件的路径image_directory_path: 图像文件所在目录entries: 加载的所有数据条目"""def__init__(self, jsonl_file_path: str, image_directory_path: str):self.jsonl_file_path=jsonl_file_pathself.image_directory_path=image_directory_pathself.entries=self._load_entries()def_load_entries(self) ->List[Dict[str, Any]]:"""加载并解析所有JSONL条目Returns:包含所有数据条目的列表,每个条目是一个字典"""entries= []withopen(self.jsonl_file_path, 'r') asfile:forlineinfile:data=json.loads(line)entries.append(data)returnentriesdef__len__(self) ->int:"""返回数据集中的样本总数"""returnlen(self.entries)def__getitem__(self, idx: int) ->Tuple[Image.Image, Dict[str, Any]]:"""获取指定索引的数据样本Args:idx: 样本索引Returns:包含图像对象和注释信息的元组Raises:IndexError: 当索引超出范围时FileNotFoundError: 当图像文件不存在时"""ifidx<0oridx>=len(self.entries):raiseIndexError("数据索引超出有效范围")entry=self.entries[idx]image_path=os.path.join(self.image_directory_path, entry['image'])try:image=Image.open(image_path).convert("RGB")return (image, entry)exceptFileNotFoundError:raiseFileNotFoundError(f"无法找到图像文件:{image_path}")
数据增强与批处理实现
数据增强和批处理是提高模型泛化能力的关键技术:
defaugment_suffix(suffix: str) ->str:"""对注释后缀进行随机重排增强通过随机打乱注释顺序来增加数据的多样性,防止模型过度依赖特定的注释顺序。Args:suffix: 原始注释后缀字符串Returns:重排后的注释后缀字符串"""parts=suffix.split(' ; ')random.shuffle(parts)return' ; '.join(parts)defcollate_fn(batch: List[Tuple[Image.Image, Dict[str, Any]]]) ->Dict[str, torch.Tensor]:"""批处理数据整理函数将多个样本组合成一个批次,并进行必要的预处理。Args:batch: 包含图像和注释的样本列表Returns:处理后的批次数据,包含所有必要的模型输入"""images, labels=zip(*batch)# 提取必要的路径和文本信息paths= [label["image"] forlabelinlabels]prefixes= ["<image>"+label["prefix"] forlabelinlabels]suffixes= [augment_suffix(label["suffix"]) forlabelinlabels]# 使用处理器进行模型输入预处理inputs=processor(text=prefixes,images=images,return_tensors="pt",suffix=suffixes,padding="longest" # 对批次中的序列进行填充对齐).to(TORCH_DTYPE).to(DEVICE)returninputs
数据加载器初始化
为训练和验证分别创建数据加载器实例:
# 初始化训练数据集train_dataset=JSONLDataset(jsonl_file_path=f"{dataset.location}/dataset/_annotations.train.jsonl",image_directory_path=f"{dataset.location}/dataset",)# 初始化验证数据集valid_dataset=JSONLDataset(jsonl_file_path=f"{dataset.location}/dataset/_annotations.valid.jsonl",image_directory_path=f"{dataset.location}/dataset",)
这种分离的数据集设计实现了以下目标:
- 确保训练和验证使用不同的数据样本,避免评估偏差
- 允许独立监控模型在验证集上的性能表现
- 为模型调优提供可靠的性能度量标准
通过以上实现,我们建立了一个完整的数据加载系统。这个数据加载系统为模型训练提供了可靠的数据流支持,是确保训练过程顺利进行的重要基础设施。
模型微调系统实现
模型微调是整个系统中最为关键的环节,它直接决定了最终模型的性能表现。本节将详细阐述微调过程的技术实现,包括训练参数配置、优化器选择以及训练流程控制。
训练管理器初始化
首先导入必要的训练组件:
fromtransformersimportTrainingArguments, Trainer
这两个组件在训练过程中承担不同职责:
- TrainingArguments类负责管理所有训练相关的超参数配置
- Trainer类提供了完整的训练循环实现,包括梯度更新、模型保存等功能
训练参数系统配置
以下代码实现了详细的训练参数配置:
args=TrainingArguments(num_train_epochs=2, # 训练轮数remove_unused_columns=False, # 保留所有数据列per_device_train_batch_size=1, # 每个设备的批次大小gradient_accumulation_steps=16, # 梯度累积步数warmup_steps=2, # 学习率预热步数learning_rate=2e-5, # 基础学习率weight_decay=1e-6, # 权重衰减率adam_beta2=0.999, # Adam优化器β2参数logging_steps=50, # 日志记录间隔optim="adamw_hf", # 优化器选择save_strategy="steps", # 模型保存策略save_steps=1000, # 模型保存间隔save_total_limit=1, # 保存检查点数量限制output_dir="paligemma_vqav2", # 输出目录bf16=True, # 使用bfloat16精度report_to=["tensorboard"], # 训练监控工具dataloader_pin_memory=False # 内存钉固设置)
每个训练参数的技术原理和选择依据:
训练周期控制参数
- num_train_epochs=2:选择两个完整训练周期,在获得足够模型适应性的同时避免过拟合
- warmup_steps=2:通过预热步骤使学习率逐渐增加,提高训练初期的稳定性
批次处理参数
- per_device_train_batch_size=1:考虑到模型规模和显存限制,采用较小的批次大小
- gradient_accumulation_steps=16:通过梯度累积模拟更大的批次,在保持内存效率的同时提升训练效果
优化器参数配置
- learning_rate=2e-5:选择相对保守的学习率,确保微调过程的稳定性
- weight_decay=1e-6:轻微的权重衰减有助于防止过拟合
- adam_beta2=0.999:动量参数的选择有助于处理梯度的稀疏性
训练监控与保存策略
- logging_steps=50:频繁的日志记录有助于及时监控训练进展
- save_strategy=“steps”:按步数保存模型,提供细粒度的检查点控制
- save_total_limit=1:限制保存的检查点数量,避免过度占用存储空间
训练器实例化
trainer=Trainer(model=model, # 预配置的PaliGemma2模型train_dataset=train_dataset, # 训练数据集data_collator=collate_fn, # 数据批处理函数args=args # 训练参数配置)
训练流程启动
# 启动训练流程trainer.train()
训练过程中的关键操作:
- 系统自动执行数据加载和批处理
- 根据配置的参数进行前向传播和反向传播
- 执行梯度更新和优化器步进
- 定期记录训练指标和保存模型检查点
预期的训练输出信息:
***** Running training *****Num examples = 1000Num Epochs = 2Instantaneous batch size per device = 1Gradient Accumulation steps = 16Total optimization steps = 125...
通过监控训练输出,可以获取以下关键信息:
- 数据样本总量和训练轮数
- 实际的批次大小和梯度累积配置
- 需要执行的总优化步数
- 训练过程中的损失变化和学习进度
为确保训练过程的稳定性,建议采取以下措施:
- 定期检查训练日志,监控损失值的变化趋势
- 观察验证集上的性能指标,及时发现过拟合现象
- 确保计算设备的稳定运行,避免训练中断
- 适时调整学习率等超参数,优化训练效果
模型推理与评估系统
模型微调完成后,需要建立完整的推理和评估体系,以验证模型性能并进行实际应用。本节详细说明推理系统的实现方法和性能评估的技术细节。
测试数据集初始化
首先构建专用的测试数据加载器:
test_dataset=JSONLDataset(jsonl_file_path=f"{dataset.location}/dataset/_annotations.test.jsonl",image_directory_path=f"{dataset.location}/dataset",)
测试数据集的设计原则:
- 使用完全独立于训练集的数据样本,确保评估的客观性
- 保持与训练集相同的数据格式和预处理流程,保证评估的一致性
- 数据分布应当反映实际应用场景,提供真实的性能参考
推理系统实现
以下代码实现了完整的推理流程:
importtorchdefperform_inference(image, label, model, processor, device):"""执行单个样本的推理过程Args:image: 输入图像label: 图像标签信息model: 微调后的PaliGemma2模型processor: 数据预处理器device: 计算设备Returns:decoded_text: 生成的检测结果文本"""# 构建输入数据prefix="<image>"+label["prefix"]inputs=processor(text=prefix,images=image,return_tensors="pt").to(device)# 记录前缀长度用于后处理prefix_length=inputs["input_ids"].shape[-1]# 执行推理计算withtorch.inference_mode():generation=model.generate(**inputs,max_new_tokens=256,do_sample=False)# 提取生成的文本序列generation=generation[0][prefix_length:]decoded_text=processor.decode(generation,skip_special_tokens=True)returndecoded_text# 执行示例推理image, label=test_dataset[1]decoded_result=perform_inference(image,label,model,processor,DEVICE)print("检测结果:", decoded_result)
推理系统的核心功能如下:
- 输入数据处理:将图像和文本提示转换为模型可接受的格式
- 推理模式控制:使用torch.inference_mode()确保高效的推理计算
- 文本生成参数:通过max_new_tokens控制输出长度,do_sample=False确保结果的确定性
- 后处理逻辑:去除前缀信息,提取实际的检测结果
检测结果可视化
实现检测结果的可视化系统:
importsupervisionassvdefvisualize_detection(image, decoded_text, classes):"""可视化检测结果Args:image: 原始图像decoded_text: 模型生成的检测文本classes: 类别列表Returns:annotated_image: 标注后的图像"""# 获取图像尺寸w, h=image.size# 解析检测结果detections=sv.Detections.from_lmm(lmm='paligemma',result=decoded_text,resolution_wh=(w, h),classes=classes)# 创建可视化标注annotated_image=image.copy()annotated_image=sv.BoxAnnotator().annotate(annotated_image,detections)annotated_image=sv.LabelAnnotator(smart_position=True).annotate(annotated_image, detections)returnannotated_image# 执行检测可视化visualized_result=visualize_detection(image,decoded_result,CLASSES)

可视化系统实现了以下功能:
- 检测结果解析:将文本格式的检测结果转换为结构化的检测对象
- 边界框绘制:在图像上标注检测到的目标区域
- 标签放置:采用智能位置算法放置类别标签
- 图像合成:生成包含完整检测信息的可视化结果
性能评估系统
建立完整的模型评估体系:
importnumpyasnpfromsupervision.metricsimportMeanAveragePrecision, MetricTargetdefevaluate_model_performance(model, test_dataset, classes):"""评估模型性能Args:model: 待评估的模型test_dataset: 测试数据集classes: 类别列表Returns:evaluation_metrics: 包含各项评估指标的字典"""map_metric=MeanAveragePrecision(metric_target=MetricTarget.BOXES)predictions= []targets= []# 收集预测结果和真实标签withtorch.inference_mode():foriinrange(len(test_dataset)):# 获取样本数据image, label=test_dataset[i]# 执行推理decoded_text=perform_inference(image, label, model, processor, DEVICE)# 解析预测结果和真实标签w, h=image.sizeprediction=sv.Detections.from_lmm(lmm='paligemma',result=decoded_text,resolution_wh=(w, h),classes=classes)target=sv.Detections.from_lmm(lmm='paligemma',result=label['suffix'],resolution_wh=(w, h),classes=classes)# 设置评估所需的额外信息prediction.class_id=np.array([classes.index(cls) forclsinprediction['class_name']])prediction.confidence=np.ones(len(prediction))target.class_id=np.array([classes.index(cls) forclsintarget['class_name']])predictions.append(prediction)targets.append(target)# 计算评估指标metrics=map_metric.update(predictions,targets).compute()returnmetrics# 执行性能评估evaluation_results=evaluate_model_performance(model,test_dataset,CLASSES)print("模型性能评估结果:", evaluation_results)

评估系统的核心功能:
- 指标计算:实现了平均精确度(mAP)等关键指标的计算
- 批量评估:支持对整个测试集进行自动化评估
- 结果分析:提供详细的性能指标分析和统计信息
性能分析与优化策略
在完成基础的模型评估后,我们需要深入分析模型性能并实施相应的优化策略。本节将详细探讨如何通过系统化的方法提升模型性能。
混淆矩阵分析系统
混淆矩阵是理解模型分类性能的重要工具。以下代码实现了详细的混淆矩阵分析:
# 构建混淆矩阵分析系统confusion_matrix=sv.ConfusionMatrix.from_detections(predictions=predictions,targets=targets,classes=CLASSES)defanalyze_confusion_matrix(confusion_matrix, classes):"""深入分析混淆矩阵数据Args:confusion_matrix: 计算得到的混淆矩阵classes: 类别列表Returns:analysis_report: 包含详细分析结果的字典"""total_samples=confusion_matrix.matrix.sum()per_class_metrics= {}fori, class_nameinenumerate(classes):# 计算每个类别的关键指标true_positives=confusion_matrix.matrix[i, i]false_positives=confusion_matrix.matrix[:, i].sum() -true_positivesfalse_negatives=confusion_matrix.matrix[i, :].sum() -true_positives# 计算精确率和召回率precision=true_positives/ (true_positives+false_positives+1e-6)recall=true_positives/ (true_positives+false_negatives+1e-6)f1_score=2* (precision*recall) / (precision+recall+1e-6)per_class_metrics[class_name] = {'precision': precision,'recall': recall,'f1_score': f1_score,'sample_count': confusion_matrix.matrix[i, :].sum()}return {'per_class_metrics': per_class_metrics,'total_samples': total_samples}# 执行混淆矩阵分析analysis_results=analyze_confusion_matrix(confusion_matrix, CLASSES)

这个分析系统帮助我们理解:
- 每个类别的识别准确度
- 类别之间的混淆情况
- 样本分布的均衡性
- 模型的系统性错误模式
性能优化策略实施
基于性能分析结果,我们可以实施以下优化策略:
defcalculate_optimal_thresholds(predictions, targets, initial_threshold=0.5):"""计算每个类别的最优检测阈值通过遍历不同阈值,找到每个类别的最佳性能平衡点。Args:predictions: 模型预测结果列表targets: 真实标注列表initial_threshold: 初始阈值Returns:optimal_thresholds: 每个类别的最优阈值"""threshold_range=np.arange(0.3, 0.9, 0.05)optimal_thresholds= {}forclsinCLASSES:best_f1=0best_threshold=initial_thresholdforthresholdinthreshold_range:# 应用不同阈值进行评估filtered_predictions=filter_predictions(predictions, cls, threshold)metrics=calculate_metrics(filtered_predictions, targets, cls)ifmetrics['f1_score'] >best_f1:best_f1=metrics['f1_score']best_threshold=thresholdoptimal_thresholds[cls] =best_thresholdreturnoptimal_thresholds
针对不同性能问题,我们建议采取以下优化措施:
数据质量优化
defenhance_training_data(dataset, analysis_results):"""基于性能分析结果优化训练数据识别并处理数据集中的问题样本,提升数据质量。"""problematic_classes=identify_problematic_classes(analysis_results)augmentation_strategies= {'rare_class': lambdax: apply_augmentation(x, factor=2),'confusing_class': lambdax: enhance_contrast(x),'boundary_case': lambdax: add_context(x)}enhanced_dataset= []forsampleindataset:class_name=sample['label']ifclass_nameinproblematic_classes:strategy=determine_enhancement_strategy(class_name,analysis_results)enhanced_sample=augmentation_strategies[strategy](sample)enhanced_dataset.append(enhanced_sample)else:enhanced_dataset.append(sample)returnenhanced_dataset
模型架构优化
defoptimize_model_architecture(model, performance_analysis):"""基于性能分析优化模型架构调整模型结构以解决特定的性能问题。"""# 分析模型在不同尺度上的表现scale_performance=analyze_scale_performance(performance_analysis)# 根据分析结果调整特征金字塔网络ifscale_performance['small_objects'] <threshold:enhance_fpn_features(model)# 优化注意力机制ifperformance_analysis['spatial_accuracy'] <threshold:adjust_attention_mechanism(model)returnmodel
训练策略优化
defoptimize_training_strategy(training_args, performance_analysis):"""优化训练策略配置根据性能分析结果调整训练参数。"""# 基于类别平衡性调整损失权重class_weights=calculate_class_weights(performance_analysis)# 调整学习率策略ifperformance_analysis['convergence_speed'] <threshold:training_args.learning_rate=adjust_learning_rate(training_args.learning_rate,performance_analysis)# 优化批次大小ifperformance_analysis['gradient_stability'] <threshold:training_args.batch_size=optimize_batch_size(training_args.batch_size,performance_analysis)returntraining_args
这些优化策略的实施应遵循以下原则:
数据质量优先
- 首先解决数据集中的质量问题
- 确保类别分布的合理性
- 增强难例样本的表示
渐进式优化
- 每次只调整一个参数
- 详细记录每次改动的效果
- 建立可靠的性能基准
系统化验证
- 使用交叉验证评估改进效果
- 关注模型的泛化能力
- 验证优化措施的稳定性
通过这个系统化的优化流程,我们可以:
- 准确识别模型的性能瓶颈
- 实施有针对性的优化措施
- 量化评估优化效果
- 确保优化措施的可持续性
系统优化最佳实践与技术总结
计算资源优化策略
在处理大规模模型训练时,合理利用计算资源至关重要。以下代码展示了一个完整的资源监控和优化系统:
classResourceOptimizer:"""计算资源优化管理器用于监控和优化GPU内存使用,平衡计算效率与资源消耗。"""def__init__(self, model, device):self.model=modelself.device=deviceself.memory_threshold=0.9 # GPU内存使用警戒线defmonitor_gpu_memory(self):"""监控GPU内存使用状况"""iftorch.cuda.is_available():memory_allocated=torch.cuda.memory_allocated(self.device)memory_reserved=torch.cuda.memory_reserved(self.device)return {'allocated': memory_allocated,'reserved': memory_reserved,'utilization': memory_allocated/memory_reserved}returnNonedefoptimize_batch_processing(self, batch_size, sequence_length):"""优化批处理参数根据当前资源使用情况动态调整批处理参数。Args:batch_size: 当前批次大小sequence_length: 序列长度Returns:optimal_batch_size: 优化后的批次大小gradient_accumulation_steps: 建议的梯度累积步数"""memory_stats=self.monitor_gpu_memory()ifmemory_statsandmemory_stats['utilization'] >self.memory_threshold:# 计算最优批次大小和梯度累积步数optimal_batch_size=batch_size//2gradient_accumulation_steps=max(1, batch_size//optimal_batch_size)returnoptimal_batch_size, gradient_accumulation_stepsreturnbatch_size, 1defapply_memory_optimization(self):"""应用内存优化技术"""ifhasattr(self.model, 'vision_tower'):# 对视觉特征进行缓存优化self.model.vision_tower=torch.jit.script(self.model.vision_tower)# 启用梯度检查点self.model.gradient_checkpointing_enable()
这个资源优化系统能够:
- 实时监控GPU内存使用情况
- 动态调整批处理参数
- 实现智能的内存管理策略
- 优化模型计算效率
训练过程监控系统
为了确保训练过程的可控性和可观测性,我们需要实现一个完善的监控系统:
classTrainingMonitor:"""训练过程监控系统提供全面的训练状态监控和分析功能。"""def__init__(self, model_name, log_dir):self.model_name=model_nameself.writer=SummaryWriter(log_dir)self.metrics_history=defaultdict(list)deflog_training_metrics(self, metrics, step):"""记录训练指标Args:metrics: 包含各项指标的字典step: 当前训练步数"""formetric_name, valueinmetrics.items():self.metrics_history[metric_name].append(value)self.writer.add_scalar(f'train/{metric_name}', value, step)defanalyze_training_progress(self):"""分析训练进展返回关键的训练状态指标和建议。"""analysis= {}# 分析损失趋势loss_trend=self.analyze_metric_trend('loss')analysis['loss_trend'] = {'is_decreasing': loss_trend['is_decreasing'],'convergence_rate': loss_trend['rate'],'stability': loss_trend['stability']}# 分析学习率影响lr_impact=self.analyze_lr_impact()analysis['learning_rate'] = {'is_effective': lr_impact['is_effective'],'suggested_adjustment': lr_impact['suggestion']}returnanalysisdefgenerate_training_report(self):"""生成训练报告返回详细的训练状态报告。"""report= {'model_name': self.model_name,'training_duration': self.get_training_duration(),'best_metrics': self.get_best_metrics(),'convergence_analysis': self.analyze_convergence(),'recommendations': self.generate_recommendations()}returnreport
这个监控系统提供了:
- 实时的训练状态跟踪
- 详细的性能指标分析
- 智能的训练建议生成
- 完整的训练报告输出
自动化优化流程
为了简化优化过程,我们可以实现一个自动化的优化流程系统:
classAutoOptimizer:"""自动优化系统提供自动化的模型优化流程。"""def__init__(self, model, training_args, dataset):self.model=modelself.training_args=training_argsself.dataset=datasetself.optimization_history= []defauto_optimize(self, optimization_budget=10):"""执行自动优化过程Args:optimization_budget: 允许的优化尝试次数Returns:optimized_model: 优化后的模型optimization_report: 优化过程报告"""best_performance=float('-inf')best_config=Noneforiinrange(optimization_budget):# 生成新的优化配置current_config=self.generate_optimization_config()# 应用优化配置optimized_model=self.apply_optimization(current_config)# 评估性能performance=self.evaluate_performance(optimized_model)# 更新最佳配置ifperformance>best_performance:best_performance=performancebest_config=current_config# 记录优化历史self.optimization_history.append({'iteration': i,'config': current_config,'performance': performance})# 应用最佳配置final_model=self.apply_optimization(best_config)returnfinal_model, self.generate_optimization_report()
总结
本文详细阐述了如何利用PaliGemma2构建高性能的多模态目标检测系统。通过整合SigLIP-So400m视觉编码器与Gemma 2语言模型的先进特性,我们实现了一个完整的技术方案,涵盖从环境配置、数据预处理、模型微调到性能优化的全流程实现。在实践中,需要需要特别关注了计算资源优化、训练过程监控和自动化优化流程等关键技术环节,通过合理的架构设计和优化策略,PaliGemma2能够在目标检测任务中展现出优异的性能。展望未来,随着多模态技术的不断发展,我们期待在模型压缩、推理加速和应用场景拓展等方面取得更多突破,进一步提升系统的实用价值。本指南的经验和方法,可为相关技术实践提供有益的参考。
本文源代码:
https://avoid.overfit.cn/post/d272453b39104f2cad8a4a8f75fb11c0
作者:Isuru Lakshan Ekanayaka
相关文章:
使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
目标检测技术作为计算机视觉领域的核心组件,在自动驾驶系统、智能监控、零售分析以及增强现实等应用中发挥着关键作用。本文将详细介绍PaliGemma2模型的微调流程,该模型通过整合SigLIP-So400m视觉编码器与Gemma 2系列的高级语言模型,专门针对…...

MinerU:PDF文档提取工具
目录 docker一键启动本地配置下载模型权重文件demo.pyGPU使用情况 wget https://github.com/opendatalab/MinerU/raw/master/Dockerfile docker build -t mineru:latest .docker一键启动 有点问题,晚点更新 本地配置 就是在Python环境中配置依赖和安装包 根据需求…...

spark的共享变量
因为RDD在spark中是分布式存储 1、python中定义的变量仅仅在driver中运行,在excutor中是获取不到值的——广播变量 2、若定义了一个变量进行累加,先分别在driver和excutor中进行累加,但是结果是不会主动返回给driver的——累加器 Broadcas…...

Scrapy与MongoDB
Scrapy可以在非常短的时间里获取大量的数据。这些数据无论是直接保存为纯文本文件还是CSV文件,都是不可取的。爬取一个小时就可以让这些文件大到无法打开。这个时候,就需要使用数据库来保存数据了。 MongoDB由于其出色的性能,已经成为爬虫的首…...

爬虫基础与实践
爬虫技术基础与实践 在当今数字化的时代,数据成为了宝贵的资源。爬虫技术作为获取数据的重要手段,受到了广泛的关注和应用。本文将介绍爬虫的基本概念、工作原理以及一些常用的技术和工具。 一、爬虫的基本概念 爬虫,也称为网络蜘蛛或网络机器…...

快速上手Serverless架构与FastAPI结合实现自动化移动应用后端
快速上手Serverless架构与FastAPI结合实现自动化移动应用后端 引言 随着云计算技术的发展,Serverless架构已经成为构建现代应用的一种流行选择。它允许开发者将更多精力集中在核心业务逻辑上,而无需管理底层基础设施。本文将以AWS Lambda和API Gateway…...

ansible自动化运维(二)playbook模式详解
一.Ansible中的playbook模式 Playbook不同于使用单个模块操作远程服务器,Playbook的功能更加强大。如果说单个模块执行类似于Linux系统中的命令,那么Playbook就类似于shell脚本,将多个模块组合起来实现一组的操作。 Playbook还是会用到ad-h…...

基于Springboot社团管理系统【附源码】
基于Springboot社团管理系统 效果如下: 系统登录页面 用户管理页面 社团信息管理页面 社团活动管理页面 经费信息管理页面 新闻信息管理页面 系统主页面 社团信息页面 研究背景 在当今高校与社区环境中,学生社团蓬勃发展,成为学生课余生活…...

CSS:html中,.png的动态图,怎么只让它显示部分,比如只显示右上部分的,或右边中间部分
目录 背景 方法 1: 使用 background-image 和 background-position 示例代码 解释 方法 2: 使用 clip-path 裁剪图像 示例代码 解释 方法 3: 使用 object-fit 和 overflow 示例代码 解释 示例 总结 背景 在HTML中,如果你有一个 .png 的动态图(例如一个 GIF 动画或…...

解读CVPR2024-论文分享|RepViT: Revisiting Mobile CNN From ViT Perspective
论文标题 RepViT: Revisiting Mobile CNN From ViT Perspective 论文链接: https://arxiv.org/abs/2307.09283 论文作者 Ao Wang, Hui Chen, Zijia Lin, Jungong Han, Guiguang Ding 内容简介 这篇论文探讨了在资源受限的移动设备上,轻量级视觉变…...
linux部署安装wordpress
一、环境准备 首先我们先介绍下环境和实验中所需要的包 环境: 我使用的是centos7.6的系统 建议关掉selinux和影响到80端口的防火墙策略 selinux永久有效 修改 /etc/selinux/config 文件中的 SELINUX"" 为 disabled ,然后重启。 selinux即…...

[Java] 配置Powershell 的 Maven 环境变量
目录 前言单独为 Powershell 设置 Maven 环境变量 前言 安装使用 maven 的时候发现,明明已经配置好了环境变量。但是在 powershell 中还是无法识别 mvn 命令。原来这货需要另外配置。 单独为 Powershell 设置 Maven 环境变量 要在 PowerShell 中永久配置 Maven 环…...

Android -- [SelfView] 自定义弹窗式颜色选择器
Android – [SelfView] 自定义弹窗式颜色选择器 PS: 1. 弹框式显示; 2. 支持透明度设置; 3. 支持拖动控件选择颜色; 4. 支持 ARGB | HEX 数值填写预览颜色并返回; 5. 输出支持Hex 和 Int 两种格式;效果 使用方法&…...

vue-echarts高度缩小时autoresize失效
背景 项目中采用动态给x-vue-echarts style赋值width,height的方式实现echarts图表尺寸的改变 <v-chart...autoresize></v-chart>给v-chart添加autoresize后,在图表宽度变化,高度增加时无异常,高度减小时图表并未缩…...

rabbitMq的rabbitmqctl status报错
Error: unable to perform an operation on node rabbitASUS-PC. Please see diagnostics information and suggestions below. 遇到上图这个错大部分问题可能是由于 RabbitMQ CLI 工具的 Erlang Cookie 与服务器上的不匹配而导致连接问题。Erlang Cookie 在 RabbitMQ 节点之间…...

linux c++ uuid编译时的问题
linux c uuid编译时的问题 写在前面可能编译过和不能编译过的可以编译和link过的不能编译过的 写在前面 几次翻车与uuid相关,超出我认知。 所以,把一些遇到的相关问题写在这里。 可能编译过和不能编译过的 可以编译和link过的 cmake_minimum_require…...

【STM32】RTT-Studio中HAL库开发教程九:FLASH中的OPT
文章目录 一、概要二、内部FLASH排布三、内部FLASH主要特色四、OTP函数介绍五、测试验证 一、概要 STM32系列是一款强大而灵活的微控制器,它的片内Flash存储器可以用来存储有关代码和数据,在实际应用中,我们也需要对这个存储器进行读写操作。…...

[SWPUCTF 2021 新生赛]crypto9
[MoeCTF 2021]Web安全入门指北—GET 意思是GET传参,moeflag 就可以得到falg 输入?moeflag flag为: NSSCTF{ff26110b-8793-403c-990e-15c7f1820596} [SWPUCTF 2021 新生赛]crypto9 #gpt写的代码 from itertools import product letter_list ABCDEFG…...

vue中常用的指令
v - if 指令 功能详细解释 它是一种真正的条件渲染指令。在 Vue 实例初始化以及数据更新过程中,Vue.js 会对v - if指令中的表达式进行求值。这个表达式可以是简单的布尔变量,也可以是一个复杂的计算表达式,只要最终结果是布尔值就行。当表达式…...

Docker Compose实战三:轻松部署PHP
通过前面的文章(Docker Compose基础语法与MySQL部署),你已经掌握了Docker Compose的基本语法和常用指令,并成功部署了一个MySQL数据库服务器。今天,我们将继续深入探索Docker Compose的强大功能,介绍如何使…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...
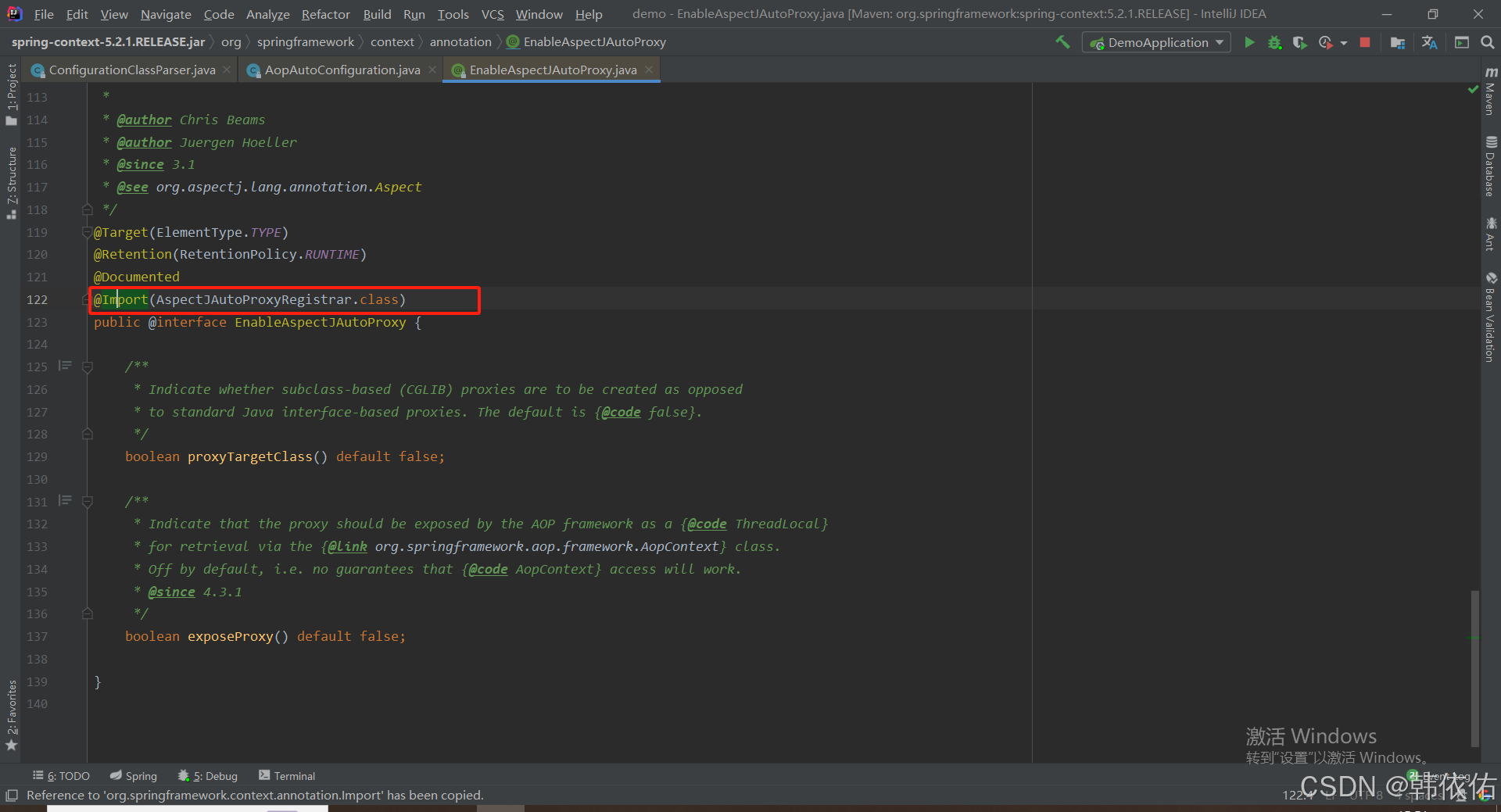
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...
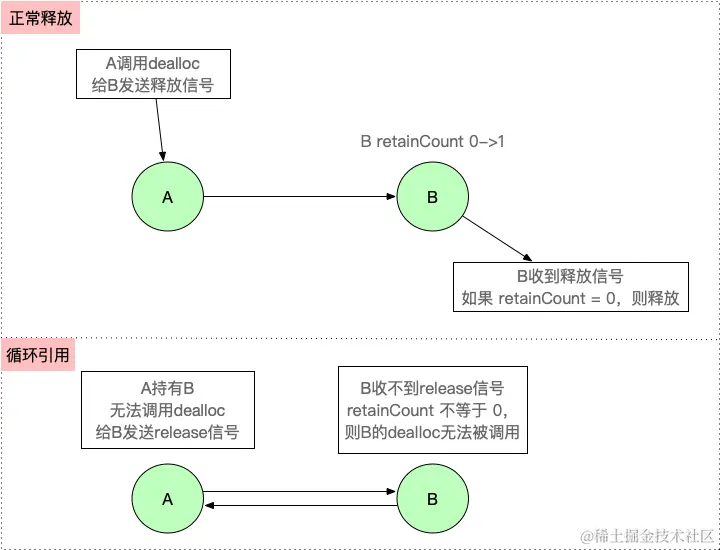
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...