怎么理解大模型推理时的Top_P参数?
本篇博客介绍一下大模型推理时的Top_P参数,Top_P与Top_K,Beamsearch,temperature 都是什么关系以及该如何选择Top_P参数。

文章目录
- 一、什么是Top_P参数?
- 二、工作原理
- 三、top_p和top_k是什么关系?
- 四、Top_P和BeamSearch是什么关系?
- 五、Top_P和temperature 是什么关系?
- 六、Top_P的选择
一、什么是Top_P参数?
在大语言模型推理过程中,Top_P参数(也叫 核采样)是一种控制生成文本的策略,用于调整生成的多样性和准确性。它的全称是 累积概率采样(Cumulative Probability Sampling)。
在文本生成任务中,模型会根据当前的上下文预测下一个单词或标记。在传统的 贪婪解码(greedy decoding)中,模型每次都会选择概率最大的单词。然而,这样的策略可能会导致生成的文本过于单一、缺乏多样性。
为了增加多样性,top_p 提供了一种替代方法。它基于模型预测的单词概率来控制生成的单词选择范围。
二、工作原理
Top_P策略: 在每次生成下一个单词时,模型首先计算出所有可能单词的概率分布。然后,将这些单词按照概率从高到低排序,直到累计的概率和超过 Top_P的阈值。例如,如果 Top_P= 0.9,模型会选择概率最高的单词,直到这些单词的累计概率大于或等于 90%。
这样,模型只会从这部分可能的单词中随机选择一个生成。通过调整 Top_P的值,我们可以控制生成文本的多样性。
举个例子
假设模型预测下一个词的概率分布如下(按概率降序排列):

如果 Top_P= 0.9,我们会从前两个单词(“apple” 和 “banana”)中随机选择一个,因为它们的累计概率(0.5 + 0.3 = 0.8)还没有达到 0.9。模型会继续加入下一个单词(“cherry”),直到累计概率大于或等于 0.9(0.5 + 0.3 + 0.1 = 0.9)。因此,模型会从 “apple”、“banana” 和 “cherry” 中随机选择一个词作为下一个生成的单词。
三、top_p和top_k是什么关系?
Top_K策略:Top_K只考虑概率最高的 k 个单词,不管它们的累计概率是多少。例如,Top_K= 3 会选择概率最高的 3 个单词,然后从这 3 个单词中随机选择,k是固定的。
Top_P策略:Top_P根据累计概率来选择单词的候选集,其候选单词数目是不固定的,可以动态变化。这种方法更灵活,通常会使得生成的文本更加自然。
四、Top_P和BeamSearch是什么关系?
Top_P和 Beam Search 都是自然语言生成任务中常用的解码策略,用于生成模型输出的文本。虽然它们都旨在改善生成过程,但它们的工作原理和效果有很大的不同。
- Beam Search 和 Top_P的主要区别:Beam Search 是一种确定性的策略,它尝试找到最优的序列路径,通过维持多个候选路径来减少错误并提高输出质量。而 Top_P则是一种随机采样策略,它通过限制候选词的累积概率范围来控制多样性,因此生成的文本可能更加多样化,但也可能不如 Beam Search 那样稳定和精确。
- Beam Search 和 Top_P可以结合使用:在一些高级的生成模型中,可以将 Top_P和 Beam Search 结合起来。具体来说,可以在 Beam Search 中的每一步进行采样(即在每个候选路径上使用 Top_P进行选择),这可以增加生成的多样性,同时仍然保持 Beam Search 对最优路径的探索。
五、Top_P和temperature 是什么关系?
- Top_P和 temperature 都是用于控制大语言模型生成文本时随机性和多样性的参数,它们在调整生成的文本质量和多样性方面有不同的作用。虽然它们的功能有重叠,但它们的工作原理不同,可以相互配合使用,以获得更好的生成效果。
- Top_P控制候选词的范围:它限制了候选词的数量或概率范围。通过设置 Top_P,你决定了模型在每一步生成时,能够从哪些单词中选择。Top_P是一个 动态 的过滤器,它的候选集大小是变化的,取决于单词的概率分布。
- temperature 控制概率分布的平滑性:它改变所有单词的概率分布的形状,影响生成时的“选择犹豫度”。较低的 temperature 会使概率分布更加尖锐,模型倾向于选择概率最高的单词。较高的 temperature 会使概率分布更加平滑,生成的文本更加多样化。
六、Top_P的选择
Top_P控制的是从可能的单词中采样的范围。较低的 Top_P会导致生成更加确定和保守的结果,而较高的 top_p 会生成更具多样性和创新性的文本。
- 低 Top_P值(如 0.7 或更低)
适用场景:当你希望生成的文本具有更高的确定性和一致性时,适合选择较低的 Top_P值。较低的 Top_P会让模型更倾向于选择概率较高的单词,从而生成的文本通常更加保守、连贯和符合预期。优点:更高的连贯性:生成的文本更加符合语法和逻辑,减少了出现不相关或不合适单词的概率。更稳定的输出:生成的结果会更接近训练数据中的模式,适合一些需要较为保守、标准的输出场合(如新闻报道、技术文档等)。缺点:多样性较差:文本会较为单一,缺乏创意和多样性,适合重复性较高的任务,但不适合需要创意的场合。
例如:在文本摘要、对话系统、问答系统中,如果想要结果更加简洁、清晰和一致,可以选择较低的 Top_P 值(如 0.7 或 0.8)。
- 中等 Top_P值(如 0.8 到 0.95)
适用场景:中等的 top_p 值提供了一定的随机性和多样性,同时又保持了文本的合理性。它适用于大多数日常生成任务,能够生成既连贯又富有创意的文本。优点:平衡多样性和连贯性:生成的文本既有创意又能保持较高的连贯性,适合多种场合(如写作助手、内容生成、聊天机器人等)。
较为自然的输出:文本有时会包含一些创新的表达或意外的单词选择,但通常不会变得过于离题。
*缺点:可能出现偶尔的不连贯:虽然生成的文本较为自然,但在某些情况下,可能会偶尔出现一些不太符合上下文的单词,尤其是在处理复杂话题时。
例如:对于创意写作、内容生成(如文章或小说生成)、对话系统等任务,可以使用 0.8 到 0.9 的 Top_P值。
- 高 Top_P值(如 0.95 或更高)
适用场景:当你希望生成的文本有更多的创意、多样性和不可预测性时,选择较高的 Top_P值。较高的 Top_P值允许模型从更大的词汇空间中进行采样,能够生成更多新颖、意外的文本。优点:更高的创意性:文本更具创造性,生成的内容可能包含更独特、有趣的词汇和表达方式。
更丰富的多样性:生成的文本不容易变得重复,可以适应一些需要探索性或新颖性的应用场景。缺点:可能会缺乏连贯性:由于允许更多的随机性和不可预测性,生成的文本可能会出现一些不合适或不连贯的部分,尤其是在较复杂的任务中。生成结果不稳定:每次生成的文本可能会大不相同,因此可能不适用于那些要求高一致性和精确性的任务。例如:对于需要较高创意的任务(如诗歌生成、故事创作等)或对话系统中富有多样性的对话,可以选择更高的 Top_P值(如 0.95 或更高)。
相关文章:
怎么理解大模型推理时的Top_P参数?
本篇博客介绍一下大模型推理时的Top_P参数,Top_P与Top_K,Beamsearch,temperature 都是什么关系以及该如何选择Top_P参数。 文章目录 一、什么是Top_P参数?二、工作原理三、top_p和top_k是什么关系?四、Top_P和BeamSea…...

hive+hadoop架构数仓使用问题记录
使用问题记录 问题1:5条数据的表执行count(*)函数,很慢,43s才出结果? 该数仓的分析计算是基于hadoop的mapreduce分布式计算框架运行的,适用于大量/海量数据,少量数据,还是使用单体数据库快。也…...
:数据类型对比 - 彻底的一切皆对象实现和包装对象异同)
前端的 Python 入门指南(三):数据类型对比 - 彻底的一切皆对象实现和包装对象异同
《前端的 Python 入门指南》系列文章: (一):常用语法和关键字对比(二):函数的定义、参数、作用域对比(三):数据类型对比 - 彻底的一切皆对象实现和包装对象异…...

Axios结合Typescript 二次封装完整详细场景使用案例
Axios 是一个基于 promise 的 HTTP 客户端,用于浏览器和 node.js。二次封装 Axios 主要是为了统一管理 HTTP 请求,例如设置统一的请求前缀、头部、超时时间,统一处理请求和响应的格式,以及错误处理等。 以下是一个使用 TypeScrip…...

基于Kubesphere实现微服务的CI/CD——部署微服务项目(三)
目录 一、kubesphere安装 1、安装本地持久存储 1.1、default-storage-class.yaml 1.2、 openebs-operator.yaml 1.3、安装 Default StorageClass 2、安装kubesphere 2.1、安装Helm 2.2、安装kubesphere 二、配置kubesphere 1、安装插件 2、创建devops项目 3、配置…...

【使用webrtc-streamer解析rtsp视频流】
webrtc-streamer WebRTC (Web Real-Time Communications) 是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或&a…...

element左侧导航栏
由element组件搭建的左侧导航栏 预览: html代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>首页</title><style> /*<!-- 调整页面背景颜色-->*/body{background-colo…...

【金融贷后】贷后运营精细化管理
文章目录 一、贷后专业术语讲解① 什么是贷后,贷后部是干什么的?② 贷后部门常见组织架构?③ 贷后专业术语有哪些? 二、贷后常用作业手段介绍① 贷后产品形态介绍?② 催收常用的方法? 三、贷后策略岗位介绍…...

学习CSS第七天
学习文章目录 一.交集选择器 一.交集选择器 使用多个条件符合的元素,可提高区分的精准度 元素配合类名是使用场景最多的 (元素必须是第一位,ID一般不写) <!DOCTYPE html> <html lang"zh-CN"> <head>…...

Image Stitching using OpenCV
文章目录 简介图像拼接管道特征检测和提取特征检测特征提取 特征匹配强力匹配FLANN(近似最近邻快速库)匹配 单应性估计扭曲和混合结论 使用opencv进行图像拼接 原为url: https://medium.com/paulsonpremsingh7/image-stitching-using-opencv-a-step-by-s…...
)
CentOS7 安装Selenium(使用webdriver_manager自动安装ChromeDriver)
在 CentOS 7 上安装 Selenium 通常涉及几个步骤,包括安装 Python、安装 Selenium 库、安装 WebDriver 以及配置环境。以下是详细的步骤: 1. 安装 Python 和 pip 如果你的系统中还没有安装 Python 和 pip,可以使用以下命令进行安装ÿ…...

鸿蒙手机文件目录
最近在开发鸿蒙,想把文件从电脑上发送到鸿蒙上我的手机APP的根目录,但是试了几次目录都不对,最后终于找到了,在这里记录一下 鸿蒙手机路径: /storage/media/100/local/files/Docs 将文件从电脑发送到手机:hdc file s…...

泷羽Sec学习笔记-Bp中ip伪造、爬虫审计
ip伪造与爬虫审计 ip伪造 下载插件:burpFakeIP 地址:GitHub - TheKingOfDuck/burpFakeIP: 服务端配置错误情况下用于伪造ip地址进行测试的Burp Suite插件 python版需要配置jython:下载地址:Maven Central: org.python:jython-…...

电子电工一课一得
首语 在现代社会中,电子电工技术已经渗透到我们生活的方方面面,从家用电器到工业自动化,从通信设备到智能系统,无一不依赖于电子电工技术。因此,掌握电子电工的基础知识,不仅对理工科学生至关重要…...

Cesium 限制相机倾斜角(pitch)滑动范围
1.效果 2.思路 在项目开发的时候,有一个需求是限制相机倾斜角,也就是鼠标中键调整视图俯角时,不能过大,一般 pitch 角度范围在 0 至 -90之间,-90刚好为正俯视。 在网上查阅了很多资料,发现并没有一个合适的…...

配置ssh-key连接github
GitHub 通过在 2022 年 3 月 15 日删除旧的、不安全的密钥类型来提高安全性。 具体内容参考如下链接 https://docs.github.com/zh/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent mac配置 ssh-keygen -t ed25519 -C …...

Linux——进程控制模拟shell
1.进程创建 我们在之前的文章中介绍过进程创建的方法,可以通过系统调用接口fork来创建新的进程。 fork在创建完新的子进程之后,返回值是一个pid,对于父进程返回子进程的pid,对于子进程返回0。fork函数后父子进程共享代码ÿ…...

【HarmonyOS】鸿蒙应用实现手机摇一摇功能
【HarmonyOS】鸿蒙应用实现手机摇一摇功能 一、前言 手机摇一摇功能,是通过获取手机设备,加速度传感器接口,获取其中的数值,进行逻辑判断实现的功能。 在鸿蒙中手机设备传感器ohos.sensor (传感器)的系统API监听有以下…...

Kael‘thas Sunstrider Ashes of Al‘ar
Kaelthas Sunstrider 凯尔萨斯逐日者 <血精灵之王> Kaelthas Sunstrider - NPC - 魔兽世界怀旧服TBC数据库_WOW2.43数据库_70级《燃烧的远征》数据库 Ashes of Alar 奥的灰烬 (凤凰 310%速度) Ashes of Alar - Item - 魔兽世界怀旧服TBC数据…...

CNCF云原生生态版图
CNCF云原生生态版图 概述什么是云原生生态版图如何使用生态版图 项目和产品(Projects and products)会员(Members)认证合作伙伴与提供商(Certified partners and providers)无服务(Serverless&a…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...
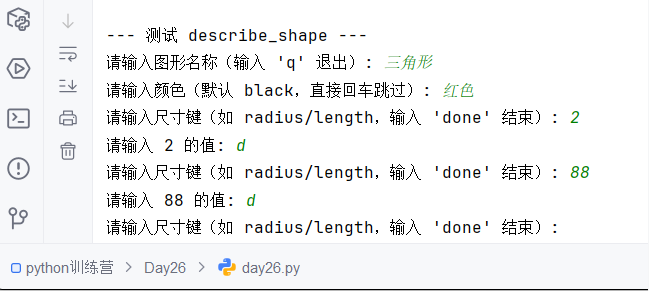
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...