【深度学习】深刻理解“变形金刚”——Transformer
Transformer 是一种用于处理序列数据的深度学习模型架构,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它彻底改变了自然语言处理(NLP)领域,成为许多高级任务(如机器翻译、文本生成、问答系统等)的基础架构。Transformer 的核心思想是自注意力机制(Self-Attention),而不依赖于传统的 RNN 或 CNN,在机器翻译上效果特别好,横扫NLP领域。
原文链接:Attention is all you need

1. Transformer整体结构
Transformer在数据角度上理解,和RNN是一致的,也和CNN是一致的。Transformer和RNN都保留了编码和解码的结构,这是什么原因呢?Transformer翻译过来叫做“变形金刚”,而编码-解码的过程,也如同变形金刚一样,先拆解为流体一般的变形元素,再变回机器人。Transformer 的结构复杂,分为编码和解码两个过程,每个encoder和decoder都是串联结构,其中编码器将输入序列编码成一个固定维度的表示,而解码器根据这个表示生成输出序列。注意力机制相当于是拆解对照表,计算各个零部件的权重,标明互相间的关系,而前馈网络就是根据权重变一次形状;在decoder还多了一层encoder-decoder attention,组装的时候不仅要考虑自己还要考虑拆解信息。数据如何在这些模块流动?首先,用算法把单词向量化,输入向量先嵌入位置信息,self attention是零件自查表,用softmax函数过滤掉不相关的单词,经过一系列矩阵操作,实现了单词计算,并消除Q,K,V初始值的影响,如下图所示:

将Encoder和Decoder拆开,可以看到完整的结构,如下图所示:

2. 词嵌入
2.1. 编解码
对于机器翻译来说,我们只能针对中文和英文这种纯文本来完成语义的对应,语言的可能性是无穷的,表达的语义也是无法穷尽,所以我们只能通过大量文本的上下文来确定词和词之间的关系。那编码和解码中的“码”到底是什么呢?其实就是把各种语言里面那些符号发音等等形式上的不同剥离掉之后,剩下来的单纯的语言关系。首先,因为需要用计算机来处理,这个语义关系应该是数字化的;其次,它需要表示语义之间的关系,所以这个语义关系码数字化后的数值要能体现出语义之间的关系来才行。假如,我们用高维空间里面的坐标来当作数字化码之后的结果,香蕉🍌对应的点和猴子🐒对应的点距离应该比较近,因为他们的语义比较近。那高维空间里面的码如何得到呢?
对文本里面的最基础的语义单元进行数字化有两种,tokenizer(分词器,标记器)和one hot(独热编码)。标记器和独热编码实际上就是采用不同的策略对TOKEN实施数字化:
- tokenizer:数字化的方式比较简单,就是给不同的token分配一个独立的id,就相当于是把所有的token都投射到了一根一维的数轴上。标记器是把所有token都投射到了一个一维空间。
- 独热编码:它做的事情就是把二进制的每一位对应一个token。独热编码则是为每一个token都分配了一个单独的维度,最后就变成了有多少token,就有多少维度的高维空间。
对于分词器来说,把所有的token都投射到了一根一维的数轴上,空间比较密集,就很难表达出一些复杂的语义;而独热编码空间太过稀疏了,很容易能表现出组合语义,但很难体现出token与token之间的联系(token之间互相正交,内积均为0,且均分布在距离原点为1的高维球面上)。
综合上述两种极端编码情况,我们就可以找到一个维度高但是没那么高的空间,也就是我们所说的潜空间。如何找到这样的潜空间呢?可以基于分词后的ID去升维,也可以基于独热编码去降维。降维相当于是将数据进行压缩,而升维相当于是将压缩后的数据进行还原,降维从直觉上去想相对简单一些。而降维其实是一种空间变换,也就是在线性代数里面就是矩阵与向量相乘。

2.2. Word2Vec
编码就是先把一个文本里的TOKEN都先编成独热码,然后再进行降维。这个过程就相当于是把输入的一句话,根据语义投射到潜空间中,把高维空间里的对象,投射到低维空间,这个过程叫做Embedding。因为是采用矩阵乘法这种方式实现嵌入的,所以把TOKEN投射到潜空间里的那个矩阵就被称作嵌入矩阵。比如,中文和英语完全可以用两套不一样的词汇表,然后分别嵌入到两个独立的潜空间中,然后采用某些算法,把这两个潜空间融合起来;也可以把中文和英文放到一个大的词汇表训练,得到一个大的潜空间。
一个句子经过编码后得到token,然后token经过解码后变成另一个句子,这两个句子应该是一样的。但是,训练应该是经过模型之后计算出来一个结果,这个结果和正确答案是有差异的,然后才能把这个差异去反向传播回去,去修正参数。而这种情况是没有办法进行训练的,因为不论输入的向量是什么,只要前面和后面的矩阵是伪逆关系,那输入输出结果一定是相等的。
如果有五个词向量,把中间一个扣掉,将剩下四个向量相加之后训练出来的是中间扣掉的向量。Word2Vec更像是编词典,不需要激活函数,训练之后体现的是单个TOKEN之间的联系,在生成的潜空间,用其他的词向量去合成目标词向量。

Word2Vec结构如下,不存在激活函数,仅有一层隐藏层。

2.3. Embedding layer
Transformer 的输入并非简单的one-hot vectore,原因包括这种表达方式的结果非常稀疏,非常大,且不能表达 word 与 word 之间的特征。所以这里对词进行 embedding,用较短的向量表达这个 word 的属性。一般在 Pytorch 中,我们都是用 nn.Embedding 来做,或者直接用 one-hot vector 与权重矩阵 W 相乘得到。
nn.Embedding 包含一个权重矩阵 W,对应的 shape 为 ( num_embeddings,embedding_dim )。num_embeddings 指的是词汇量,即想要翻译的 vocabulary 的长度,embedding_dim 指的是想用多长的 vector 来表达一个词,可以任意选择,比如64,128,256,512等。在 Transformer 论文中选择的是512(即 d_model =512)。其实可以形象地将 nn.Embedding 理解成一个 lookup table,里面对每一个 word 都存了向量 vector 。给任意一个 word,都可以从表中查出对应的结果。处理 nn.Embedding 权重矩阵有两种选择:
- 使用 pre-trained 的 embeddings 并固化,这种情况下实际就是一个 lookup table。
- 对其进行随机初始化(当然也可以选择 pre-trained 的结果),但设为 trainable。这样在 training 过程中不断地对 embeddings 进行改进。(嵌入矩阵需要在训练中调整参数)
在 Annotated Transformer 中,class “Embeddings“ 用来生成 word 的embeddings,其中用到 nn.Embedding。具体实现见下:
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)3. 注意力机制
3.1. 注意力
对词和词组合后的语义进行理解,靠的就是注意力机制。词嵌入已经解决了单个词单个TOKEN语义的问题,注意力机制要解决的是许多词组合之后整体的语义,这组词向量就组成了数据矩阵。经过注意力机制之后,输入的词向量矩阵都需要经过矩阵相乘之后得到Q, K, V。

注意力的思想,类似于寻址。给定Target(T)中的某个元素Query(Q),通过计算Query(Q)和各个Key(K)的相似性或相关性,得到每个Key(K)对应Value(V)的权重系数(即A,为注意力得分),然后对Value(V)进行加权求和,即得到最终的Attention数值。
需要注意的是,Q和K的转置作内积运算,本质上是求相关性,得到一个包含相关性信息的表——A。如果结果数值为0,则表明为正交关系;如果结果数值为1,则表明为正相关关系;如果结果数值为-1,则表明为负相关关系。
3.2. 交叉注意力
decoder与encoder相比,在注意力结束之后,还会进行一个交叉注意力机制,解码器里的每一层都会拿到编码器的结果进行参考。Transformer在训练过程中,解码部分和编码部分是可以并行进行训练的,最终可以得到编码器部分和解码器部分潜空间中的词向量,损失函数是两个词向量的差异,然后进行反向传播。
而在Transformer的推理过程中,考虑到在机器翻译的过程中,token的数量并非是一一对应的,相同的语义token的数量并不一样。输入一句中文进行翻译,得到的英文结果需要一个一个地去生成,这个过程就用到了RNN的思路。编码器部分需要将一句话全部输入,得到潜空间中的词向量,在解码器部分也是需要输入内容的,这时候我们输入“开始符号”——<BOS>,输入这个符号之后,经过交叉注意力进行计算之后,最后会得到一个结果,这个结果进行升维和softmax计算之后,会得到词汇表中的某个词,重复这个过程,直到收到结束符号之后,整个翻译过程结束。

3.3. 多头注意力
多头注意力机制对应整体结构图中的Multi——Head Attention,多头注意力机制扩展了模型专注于不同位置的能力,有多个查询/键/值权重矩阵集合,Transformer使用八个注意力头,并且每一个都是随机初始化的。和自注意力机制一样,用矩阵X乘以WQ、WK、WV来产生查询、键、值矩阵,但self-attention只是使用了一组WQ、WK、WV来进行变换得到查询、键、值矩阵,而Multi-Head Attention使用多组WQ,WK,WV得到多组查询、键、值矩阵,然后每组分别计算得到一个Z矩阵。

4. 位置编码(Positional Encoding)
由于 Transformer 模型并不具备像 RNN 或 CNN 那样的顺序性,没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序,通过将一组固定的编码添加到输入的嵌入向量中,表示输入的相对或绝对位置。
那 RNN 为什么在任何地方都可以对同一个 word 使用同样的向量呢?因为 RNN 是按顺序对句子进行处理的,一次一个 word。但是在 Transformer 中,输入句子的所有 word 是同时处理的,没有考虑词的排序和位置信息。Transformer 加入 “positional encoding” 来解决这个问题,使得 Transformer 可以衡量 word 位置有关的信息。positional encoding 与 word embedding 相加就得到 embedding with position。如果是乘法的话,位置对词向量的影响就太大。
那么具体 ”positional encoding“ 怎么做?为什么能表达位置信息呢?作者探索了两种创建 positional encoding 的方法:
- 通过训练学习 positional encoding 向量
- 使用公式来计算 positional encoding向量
试验后发现两种选择的结果是相似的,所以采用了第2种方法,优点是不需要训练参数,而且即使在训练集中没有出现过的句子长度上也能用。计算 positional encoding 的公式为:
其中,pos 指的是这个 word 在这个句子中的位置 ,i指的是 embedding 维度。比如选择 d_model=512,那么i就从1数到512
为什么选择 sin 和 cos ?positional encoding 的每一个维度都对应着一个正弦曲线,作者假设这样可以让模型相对轻松地通过对应位置来学习。
参考资料:
10分钟带你深入理解Transformer原理及实现 - 知乎https://zhuanlan.zhihu.com/p/80986272blog.csdn.net/leonardotu/article/details/136165819https://blog.csdn.net/leonardotu/article/details/136165819【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客https://blog.csdn.net/weixin_42475060/article/details/121101749从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1XH4y1T76e/?spm_id_from=333.1391.0.0&vd_source=0dc0c2075537732f2b9a894b24578eed一文了解Transformer全貌(图解Transformer)https://www.zhihu.com/tardis/zm/art/600773858
相关文章:
【深度学习】深刻理解“变形金刚”——Transformer
Transformer 是一种用于处理序列数据的深度学习模型架构,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它彻底改变了自然语言处理(NLP)领域,成为许多高级任务(如机器翻译、文本生成、问答…...

75_pandas.DataFrame 中查看和复制
75_pandas.DataFrame 中查看和复制 与pandas的DataFrame与NumPy数组ndarray类似,也有视图(view)和拷贝(copy)。 当使用loc[]或iloc[]等选择DataFrame的一部分以生成新的DataFrame时,与原对象共享内存的对…...

打电话玩手机识别-支持YOLO,COCO,VOC格式的标记,超高识别率可检测到手持打电话, 非接触式打电话,玩手机自拍等
打电话玩手机识别-支持YOLO,COCO,VOC格式的标记,超高识别率可检测到手持打电话, 非接触式打电话,玩手机自拍等1275个图片。 手持打电话: 非接触打电话 玩手机 数据集下载 yolov11:https://download.csdn…...

生产慎用之调试日志对空间矢量数据批量插入的性能影响-以MybatisPlus为例
目录 前言 一、一些缘由 1、性能分析 二、插入方式调整 1、批量插入的实现 2、MP的批量插入实现 3、日志的配置 三、默认处理方式 1、基础程序代码 2、执行情况 四、提升调试日志等级 1、在logback中进行设置 2、提升后的效果 五、总结 前言 在现代软件开发中,性能优…...
)
单片机:实现倒计时(附带源码)
使用单片机实现倒计时功能是一个常见的嵌入式应用,它能帮助你更好地理解如何进行时间控制和如何通过定时器实现精确的倒计时。通过该项目,你将学习如何使用单片机的定时器来进行时间计算,并通过LED或LCD显示倒计时的结果。 1. 项目概述 倒计…...

什么是多线程中的上下文切换
什么是多线程中的上下文切换 回答 上下文切换是指CPU从一个线程转到另一个线程时,需要保存当前线程的上下文状态,恢复另一个线程的上下文状态,以便于下一次恢复执行该线程时能够正确地运行。 在多线程编程中,上下文切换是一种常…...

如何在windwos批量拉取go mod
golang go-zero微服务开发,分的rpc项目太多了,变更了公共包,需要手动去拉取,直接一键拉取就好了,创建一个windwos脚本文件 文件名 tidy_all_go_mod.ps1 代码 # 辅助工具拉取go mod tidy # 根目录v99main执行 ./tidy_all_go_mod.ps1 # 定义项目的根目录 $RootDir Get-Locat…...

【Three.js基础学习】29.Hologram Shader
前言 three.js 通过着色器如何实现全息影像,以及一些动态的效果。 一些难点的思维,代码目录 下面图是摄像机视角观看影响上的时候,如何实现光影的渐变,透视以及叠加等。 一、代码 1.index.html <!DOCTYPE html> <html …...

文件包含进阶玩法以及绕过姿态
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 本文整理文件包含漏洞的进阶玩法与绕过姿态 不涉及基础原理了 特殊玩法汇总 本地包含 文件包含上传文件 原理: php的文件包含有着把其他文件类型当做php代码执行的功效,文件上传一般会限制后缀&am…...

Markdown编辑器工具--Typora
下载链接...

PyTorch 的 torch.unbind 函数详解与进阶应用:中英双语
中文版 PyTorch 的 torch.unbind 函数详解与进阶应用 在深度学习中,张量的维度操作是基础又重要的内容。PyTorch 提供了许多方便的工具来完成这些操作,其中之一便是 torch.unbind。与常见的堆叠函数(如 torch.stack)相辅相成&am…...

四十六:如何使用Wireshark解密TLS/SSL报文?
TLS/SSL是保护网络通信的重要协议,其加密机制可以有效地防止敏感信息被窃取。然而,在调试网络应用或分析安全问题时,解密TLS/SSL流量是不可避免的需求。本文将介绍如何使用Wireshark解密TLS/SSL报文。 前提条件 在解密TLS/SSL报文之前&…...
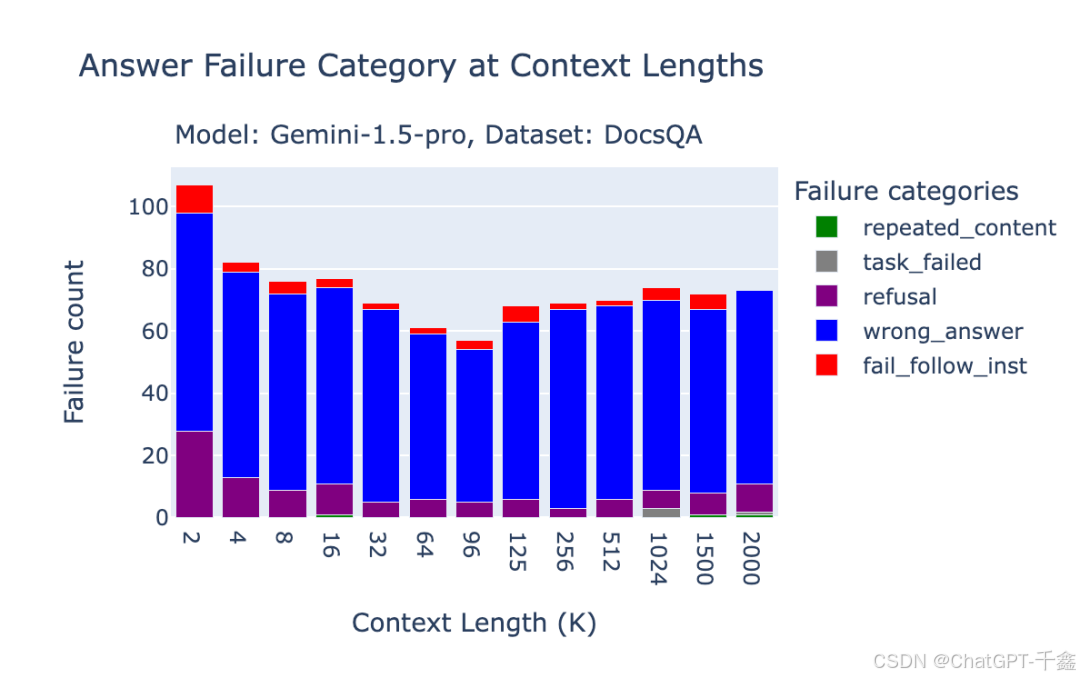
【人工智能】OpenAI O1模型:超越GPT-4的长上下文RAG性能详解与优化指南
在人工智能(AI)领域,长上下文生成与检索(RAG) 已成为提升自然语言处理(NLP)模型性能的关键技术之一。随着数据规模与应用场景的不断扩展,如何高效地处理海量上下文信息,成…...
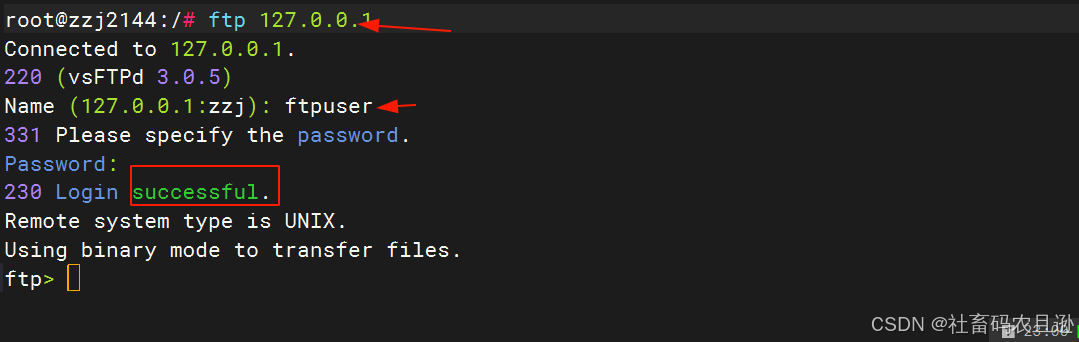
Ubuntu22.04搭建FTP服务器保姆级教程
在网络环境中,文件传输是一项至关重要的任务。FTP(文件传输协议)是一种基于客户端/服务器模式的协议,广泛用于在互联网上传输文件。Ubuntu作为一款流行的Linux发行版,因其稳定性和易用性而广受开发者和系统管理员的喜爱…...

操作系统(4)操作系统的结构
一、无序结构(整体结构或模块组合结构) 1.特点: 以大型表格和队列为中心,操作系统的各部分程序围绕着这些表格进行。操作系统由许多标准的、可兼容的基本单位(称为模块)构成,模块之间通过规定的…...
)
Python数据分析(OpenCV视频处理)
处理视频我们引入的还是numpy 和 OpenCV 的包 引入方式如下: import numpy as np import cv2 我们使用OpenCV来加载本地视频,参数就是你视频的路径就可以 #加载视频 cap cv2.VideoCapture(./1.mp4) 下面我们进行读取视频 #读取视频 flag,frame cap.re…...

跨域 Cookie 共享
跨域请求经常遇到需要携带 cookie 的场景,为了确保跨域请求能够携带用户的认证信息或其他状态,浏览器提供了 withCredentials 这个属性。 如何在 Axios 中使用 withCredentials 为了在跨域请求中携带 cookie,需要在 Axios 配置中设置 withCr…...
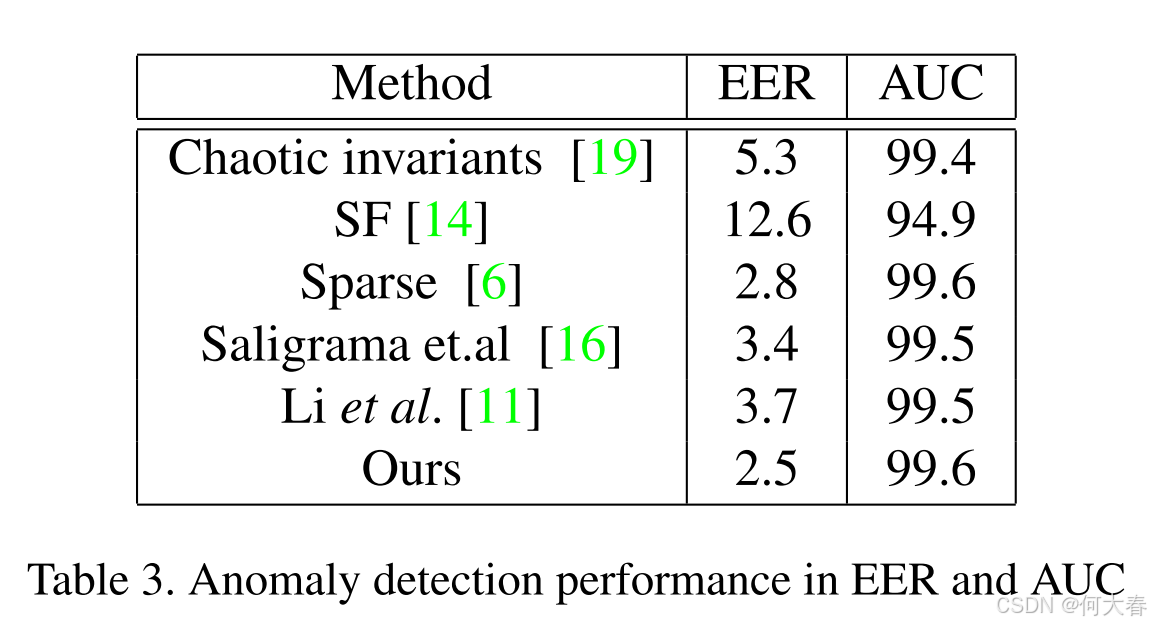
【视频异常检测】Real-Time Anomaly Detection and Localization in Crowded Scenes 论文阅读
文章信息: 发表于:CVPR2015(workshop) 原文链接:https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2015/W04/papers/Sabokrou_Real-Time_Anomaly_Detection_2015_CVPR_paper.pdf Real-Time Anomaly D…...

设计模式12:抽象工厂模式
系列总链接:《大话设计模式》学习记录_net 大话设计-CSDN博客 参考: C设计模式:抽象工厂模式(风格切换案例)_c 抽象工厂-CSDN博客 1.概念 抽象工厂模式(Abstract Factory Pattern)是软件设计…...
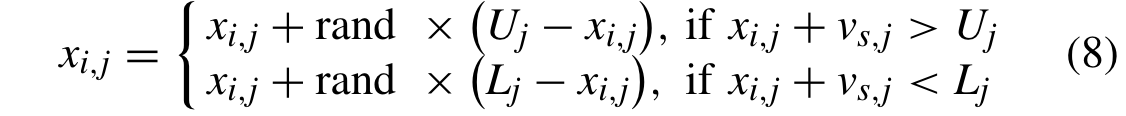
论文学习——多种变化环境下基于多种群进化的动态约束多目标优化
论文题目:Multipopulation Evolution-Based Dynamic Constrained Multiobjective Optimization Under Diverse Changing Environments 多种变化环境下基于多种群进化的动态约束多目标优化(Qingda Chen , Member, IEEE, Jinliang Ding , Senior Member, …...

为什么92%的DeepSeek部署项目在上线30天内遭遇Prompt注入?4个被忽视的配置陷阱全曝光
更多请点击: https://intelliparadigm.com 第一章:DeepSeek prompt注入防护的严峻现实与认知重构 近年来,DeepSeek系列大模型在开源社区广泛部署,但其默认推理接口(如/v1/chat/completions)对用户输入缺乏…...
】)
GaussDB 操作时间【玩转PB级数仓GaussDB(DWS)】
前言在使用 GaussDB DWS 进行数仓相关操作时,我们经常会涉及到对时间的操作,本文主要来讲解下有关时间操作的定义及函数格式化字符串模式描述HH一天的小时数(01-12)HH12一天的小时数(01-12)HH24一天的小时数(00-23)MI分钟(00-59)ss秒(00-59)MS毫秒(000-9…...

1.8.2 掌握Scala类与对象 - 单例对象与伴生对象
本次实战通过三个案例深入解析了 Scala 中 object 的核心机制,展示了其如何替代 Java 的 static 关键字。首先,通过 MathUtils 定义了存放常量与工具方法的独立单例对象;其次,利用 Person 类与其同名对象演示了“伴生对象”特性&a…...

Angular 17与Firebase全栈实战:从零构建现代化Web应用
1. 项目概述:一个基于 Angular 17 的现代化 Web 应用最近接手并重构了一个名为 Ditectrev 的 Web 项目,它本质上是一个功能性的前端应用,旨在解决特定领域的信息展示与交互需求。这个项目最初由 Angular CLI 17.3.17 生成,但原始的…...

QtScrcpy终极指南:高效实现Android投屏控制
QtScrcpy终极指南:高效实现Android投屏控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy QtScr…...

基于MCP协议的学术成果商业化AI管道:从论文到商业机会的自动化桥梁
1. 项目概述:从象牙塔到市场的自动化桥梁看到apifyforge/academic-commercialization-pipeline-mcp这个项目标题,我的第一反应是:终于有人把学术界和产业界之间那道无形的墙,用代码给砌出了一条自动化通道。这个项目本质上是一个“…...
Zotero PDF Translate终极配置指南:如何一键激活20+翻译服务
Zotero PDF Translate终极配置指南:如何一键激活20翻译服务 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh_mir…...

ITR9909反射光电管实测:10cm检测距离怎么来的?手把手教你做距离-电压曲线
ITR9909反射光电管深度测评:从原理到实战的距离-电压曲线构建指南 在工业自动化、机器人导航和智能家居领域,反射式光电检测管因其非接触式检测特性而广受欢迎。ITR9909作为一款性能优异的反射式红外光电管,其标称的10cm检测距离背后隐藏着怎…...

AI建站案例:一家外贸工厂如何用“AI+系统”拿下海外订单
AI建站案例:一家外贸工厂如何用“AI系统”拿下海外订单【引言:别让网站成为“电子名片”】我们看过太多外贸工厂的网站:花了几千块,做得金碧辉煌,但一年下来询盘屈指可数。问题不在产品,而在“数字化基建”…...

快速学C语言——第19章:C语言常用开发库
第19章:C语言常用开发库 C语言的标准库提供了丰富的函数来帮助开发者完成各种常见任务。掌握这些标准库的使用可以大大提高编程效率。 ⚠️本章只给出日常开发中常用的函数! 19.1 标准输入输出库(stdio.h) stdio.h 是最常用的库&a…...