通过k-means对相似度较高的语句进行分类
本文介绍了如何使用K-Means算法对相似度较高的语句进行分类,并附上java案例代码
import java.util.ArrayList;
import java.util.List;
import java.util.Random;public class KMeansTextClustering {public static void main(String[] args) {// 初始化语句数据集List<String> texts = new ArrayList<>();texts.add("如果他不是老师,他就是学生");texts.add("他可能是老师也可能是学生");texts.add("他经常在学校学习");texts.add("他在学校的学习成绩很好");texts.add("老师和学生在上课");texts.add("学校是学习的地方");texts.add("老师收到定金");texts.add("学校塑料袋管理科");texts.add("开心数量肯定两个都是");texts.add("开心的两个孩子");// 设置K值(簇的数量)int K = 3;// 执行K-Means算法List<List<String>> clusters = kMeans(texts, K);// 打印聚类结果for (int i = 0; i < clusters.size(); i++) {System.out.println("Cluster " + (i + 1) + ":");for (String text : clusters.get(i)) {System.out.println(text);}System.out.println();}}public static List<List<String>> kMeans(List<String> texts, int K) {// 随机选择K个语句作为初始簇中心Random random = new Random();List<String> centroids = new ArrayList<>();for (int i = 0; i < K; i++) {centroids.add(texts.get(random.nextInt(texts.size())));}boolean isChanged;List<List<String>> clusters = new ArrayList<>();do {// 创建K个空簇clusters.clear();for (int i = 0; i < K; i++) {clusters.add(new ArrayList<>());}// 分配数据点到最近的簇中心for (String text : texts) {int closestCentroidIndex = 0;double minDistance = Double.MAX_VALUE;for (int i = 0; i < K; i++) {double similarity = 1 - calcTextSim(text, centroids.get(i)); // 使用相似度的补数作为距离if (similarity < minDistance) {minDistance = similarity;closestCentroidIndex = i;}}clusters.get(closestCentroidIndex).add(text);}// 更新簇中心isChanged = false;for (int i = 0; i < K; i++) {String newCentroid = findCentroid(clusters.get(i), centroids.get(i));if (!newCentroid.equals(centroids.get(i))) {isChanged = true;centroids.set(i, newCentroid);}}} while (isChanged);return clusters;}// 计算两个语句的相似度public static double calcTextSim(String text, String targetText) {return ChineseTextRecommender.calcTextSim(text, targetText); // 返回相似度值}// 计算簇的中心点(这里简化为返回簇中第一个元素)public static String findCentroid(List<String> cluster, String currentCentroid) {if (cluster.isEmpty()) return currentCentroid;// 存储每个语句的平均相似度double[] averageSimilarities = new double[cluster.size()];// 计算每个语句与其他语句的平均相似度for (int i = 0; i < cluster.size(); i++) {double totalSimilarity = 0.0;for (int j = 0; j < cluster.size(); j++) {if (i != j) {totalSimilarity += calcTextSim(cluster.get(i), cluster.get(j));}}averageSimilarities[i] = totalSimilarity / (cluster.size() - 1);}// 找到平均相似度最高的语句作为簇中心点int centroidIndex = 0;double maxAverageSimilarity = averageSimilarities[0];for (int i = 1; i < averageSimilarities.length; i++) {if (averageSimilarities[i] > maxAverageSimilarity) {maxAverageSimilarity = averageSimilarities[i];centroidIndex = i;}}return cluster.get(centroidIndex);}
}
相似度工具:
import com.hankcs.hanlp.tokenizer.StandardTokenizer;import java.util.*;
import java.util.stream.Collectors;public class ChineseTextRecommender {public static double calcTextSim(String text, String targetText) {Map<String, Integer> targetVector = buildTermVector(targetText);Map<String, Integer> textVector = buildTermVector(text);double similarity = cosineSimilarity(targetVector, textVector);return similarity;}public static Map<String, Integer> buildTermVector(String text) {List<String> words = StandardTokenizer.segment(text).stream().map(term -> term.word).collect(Collectors.toList());Map<String, Integer> termVector = new HashMap<>();for (String word : words) {termVector.put(word, termVector.getOrDefault(word, 0) + 1);}return termVector;}// 计算余弦相似度public static double cosineSimilarity(Map<String, Integer> vectorA, Map<String, Integer> vectorB) {double dotProduct = 0.0;double normA = 0.0;double normB = 0.0;for (String key : vectorA.keySet()) {dotProduct += vectorA.get(key) * (vectorB.getOrDefault(key, 0));normA += Math.pow(vectorA.get(key), 2);}for (String key : vectorB.keySet()) {normB += Math.pow(vectorB.get(key), 2);}if (normA == 0 || normB == 0) {return 0.0;}return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));}
}
pom依赖
<!-- 分词工具 --><dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.8.4</version></dependency>
打印结果:
Cluster 1:
他经常在学校学习
他在学校的学习成绩很好
学校是学习的地方
学校塑料袋管理科Cluster 2:
开心数量肯定两个都是
开心的两个孩子Cluster 3:
如果他不是老师,他就是学生
他可能是老师也可能是学生
老师和学生在上课
老师收到定金
相关文章:

通过k-means对相似度较高的语句进行分类
本文介绍了如何使用K-Means算法对相似度较高的语句进行分类,并附上java案例代码 import java.util.ArrayList; import java.util.List; import java.util.Random;public class KMeansTextClustering {public static void main(String[] args) {// 初始化语句数据集…...

国信华源科技赋能长江蓄滞洪区水闸管护项目验收成果报道
“碧水悠悠绕古城,闸启长江万象新。”近日,由北京国信华源科技有限公司倾力打造的万里长江蓄滞洪区水闸管护项目,圆满通过验收,为这片鱼米之乡的防洪安全注入了新的科技活力。 长江之畔,水闸挺立,犹如干堤上…...

HTML:表格重点
用表格就用table caption为该表上部信息,用来说明表的作用 thead为表头主要信息,效果加粗 tbody为表格中的主体内容 tr是 table row 表格的行 td是table data th是table heading表格标题 ,一般表格第一行的数据都是table heading...

wine的使用方法
wine版本 所有分支,新的主要版本: wine-x.0 All branches, release candidates:各分支、候选版本: wine-x.0-rcn Stable branch updates: 稳定分支更新: wine-x.0.z Development branch updates: wine-x.y wine *.exe “更改目…...

Linux服务器离线安装unzip包
Linux服务器离线安装unzip包 1. 安装unzip包的目的 解压Docker部署包和服务部署包。 2. 查看当前环境是否已经安装unzip rpm -qa | grep --color unzip3. 下载对应的离线包 地址:http://www.rpmfind.net/linux/rpm2html/search.php?query&submitSearch 例…...

Excel拆分脚本
Excel拆分 工作表按行拆分为工作薄 工作表按行拆分为工作薄 打开要拆分的Excel文件,使用快捷键(AltF11)打开脚本界面,选择要拆分的sheet,打开Module,在Module中输入脚本代码,然后运行脚本 Su…...

Mybatis---事务
目录 引入 一、事务存在的意义 1.事务是什么? 2.Mybatis关于事务的管理 程序员自己控制处理的提交和回滚 引入 一、事务存在的意义 1.事务是什么? 多个操作同时进行,那么同时成功,那么同时失败。这就是事务。 事务有四个特性…...
)
企业直播间媒体分发新闻转播拉流推广名单(金融财经科技类)
【本篇由 言同数字媒体直播分发 原创】随着直播与短视频成为各大企业营销的重要手段,如何选择合适的视频平台进行内容分发与拉流成为了企业关注的焦点。对于财经和科技类企业而言,选择具有专业受众群体和广泛传播能力的平台尤为重要。下面是一些可以帮助…...

华为FreeBuds Pro 4丢了如何找回?(附查找功能使用方法)
华为FreeBuds Pro 4查找到底怎么用?华为FreeBuds Pro 4有星闪精确查找和离线查找,离线查找功能涵盖播放铃声、导航定位、星闪精确查找、上线通知、丢失模式、遗落提醒等。星闪精确查找是离线查找的子功能,当前仅华为FreeBuds Pro 4充电盒支持…...

若依微服务登录密码加密传输解决方案
文章目录 一、需求提出二、应用场景三、解决思路四、注意事项五、完整代码第一步:前端对密码进行加密第二步:后端工具类实现 RSA 加解密功能第三步:登录接口中添加解密逻辑 六、运行结果总结 一、需求提出 在默认情况下,RuoYi 微…...

NVR小程序接入平台/设备EasyNVR深度解析H.265与H.264编码视频接入的区别
随着科技的飞速发展和社会的不断进步,视频压缩编码技术已经成为视频传输和存储中不可或缺的一部分。在众多编码标准中,H.265和H.264是最为重要的两种。今天我们来将深入分析H.265与H.264编码的区别。 一、H.265与H.264编码的区别 1、比特率与分辨率 H.…...

Redisson常用方法
Redisson 参考: 原文链接 定义:Redisson 是一个用于与 Redis 进行交互的 Java 客户端库 优点:很多 1. 入门 1.1 安装 <!--redission--> <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifa…...

html自带的input年月日(date) /时间(datetime-local)/星期(week)/月份(month)/时间(time)控件
年月日期控件 type"date" <input type"date" id"StartDate" valueDateTime.Now.ToString("yyyy-MM-dd") /> //设置值 $("#StartDate").val("2024-12-12"); //获取值 var StartDate$("#StartDate&quo…...
-- 响应式设计详解)
CSS系列(12)-- 响应式设计详解
前端技术探索系列:CSS 响应式设计详解 📱 致读者:掌握响应式设计的艺术 👋 前端开发者们, 今天我们将深入探讨 CSS 响应式设计,学习如何创建适应各种设备的网页布局。 响应式基础 🚀 视口设…...

filecoin boost GraphQL API 查询
查询示例 查询失败交易 curl -X POST \ -H "Content-Type: application/json" \ -d {"query":"query { deals(limit: 10, query: \"failed to get size of imported\") { deals { ID CreatedAt Message } } }"} \ http://localhost:…...

SAS - Subtractive Port
在SAS(串行连接SCSI,Serial Attached SCSI)协议中,subtractive port 是一种特殊类型的端口,主要用于设备间的路由功能。它的作用是在路径选择过程中充当默认路径,以处理未明确指定路径的请求。以下是它的定…...

TCP客户端模拟链接websocket服务端
因一些特殊原因研究了下TCP模拟链接websocket。原理上可以连接但具体怎么连接怎么操作就不知道了,需要研究下,以下是个人研究的方案。 用线上和本地地址来做例子: 线上wss地址:wss://server.cs.com/cs/vido/1 本地地址ws://127…...

TypeScript 的崛起:全面解析与深度洞察
一、背景与起源 (一)JavaScript 的局限性 类型系统缺失 难以在编码阶段发现类型相关错误,导致运行时错误频发。例如,将字符串误当作数字进行数学运算,可能在运行时才暴露问题。函数参数类型不明确,容易传入…...

c#笔记2024
Ctrl r e自动添加get和set CompositeCurve3d 复合曲线 List<Entity> entS listline.Cast<Entity>().ToList();//list类型强转 前面拼上\u0003,就可以实现,不管有没有命令都能打断当前命令的效果 取消其他命令:Z.doc.SendStri…...

Hadoop一课一得
Hadoop作为大数据时代的奠基技术之一,自问世以来就深刻改变了海量数据存储与处理的方式。本文将带您深入了解Hadoop,从其起源、核心架构、关键组件,到典型应用场景,并结合代码示例和图示,帮助您更好地掌握Hadoop的实战…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...
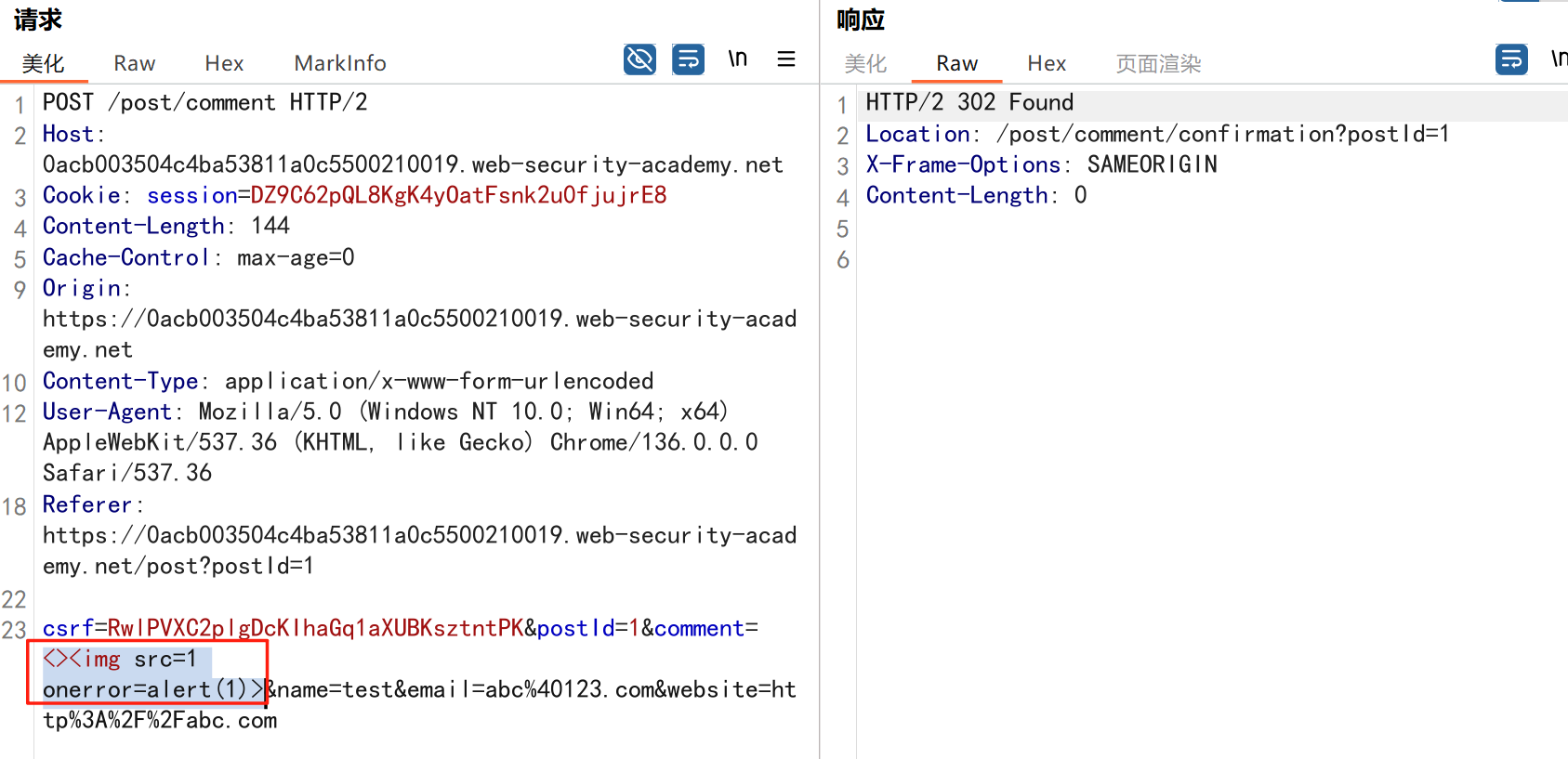
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...
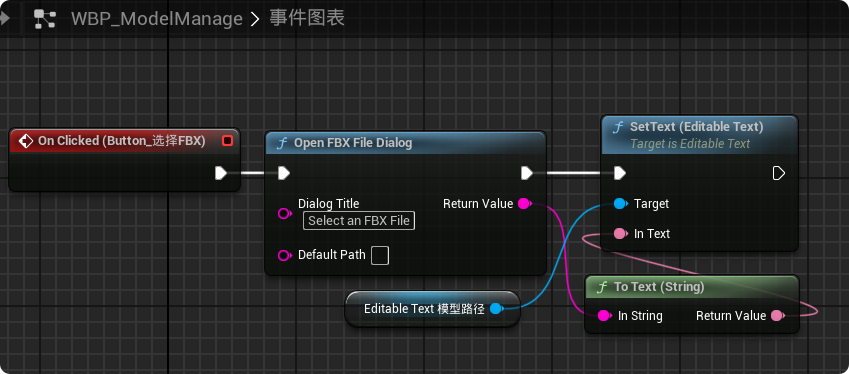
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...