【数据挖掘实战】——电力窃漏电用户自动识别

【数据挖掘实战】——电力窃漏电用户自动识别
- 一、背景和挖掘目标
- 二、分析方法与过程
- 1、初步分析
- 2、数据抽取
- 3、探索分析
- 4、数据预处理
- 5、构建专家样本
- 三、构建模型
- 1、构建窃漏电用户识别模型
- 2、模型评价
- 3、进行窃漏电诊断
- 拓展思考
项目代码地址:https://gitee.com/lingxw123/datamining_project.git
项目来源于《数据分析与挖掘实战》
一、背景和挖掘目标
传统的防窃漏电方法主要通过定期巡检、定期校验电表、用户举报窃电等方法来发现窃电或计量装置故障。但这种方法对人的依赖性太强,抓窃查漏的目标不明确。目前,很多供电局主要通过营销稽查人员、用电检查人员和计量工作人员利用计量异常报警功能和电能量数据查询功能开展用户用电情况的在线监控工作,通过采集电量异常、负荷异常、终端报警、主站报警、线损异常等信息,建立数据分析模型,来实时监测窃漏电情况和发现计量装置的故障。根据报警事件发生前后客户计量点有关的电流、电压、负荷数据情况等,构建基于指标加权的用电异常分析模型,实现检查客户是否存在窃电、违章用电及计量装置故障等。
以上防窃漏电的诊断方法,虽然能获得用电异常的某些信息,但由于终端误报或漏报过多,无法达到真正快速精确定位窃漏电嫌疑用户的目的,往往令稽查工作人员无所适从。而且在采用这种方法建模时,模型各输入指标权重的确定需要用专家的知识和经验来判断,具有很大的主观性,存在明显的缺陷,所以实施效果往往不尽如人意。
现有的电力计量自动化系统能够采集到各相电流、电压、功率因数等用电负荷数据以及用电异常等终端报警信息。异常告警信息和用电负荷数据能够反映用户的用电情况,同时稽查工作人员也会通过在线稽查系统和现场稽查来找出窃漏电用户,并录入系统。若能通过这些数据信息提取出窃漏电用户的关键特征,构建窃漏电用户的识别模型,就能自动检查、判断用户是否存在窃漏电行为。

表6-1给出了某企业大用户的用电负荷数据,采集时间间隔为15分钟,即0.25小时,可进一步计算该大用户的用电量。表6-2给出了该企业大用户的终端报警数据,其中与窃漏电相关的报警能较好的识别用户的窃漏电行为。表6-3给出了某企业大用户违约、窃电处理通知书,表中记录了用户的用电类别和窃电时间。

本次数据挖掘建模目标如下。
1)归纳出窃漏电用户的关键特征,构建窃漏电用户的识别模型。
2)利用实时监测数据,调用窃漏电用户识别模型实现实时诊断。

二、分析方法与过程
1、初步分析
- 窃漏电用户在电力计量自动化系统的监控大用户中只占一小部分,同时某些大用户也不可能存在窃漏电行为,如银行、税务、学校和工商等非居民类别,故在数据预处理时有必要将这些类别用户剔除。
- 系统中的用电负荷不能直接体现出用户的窃漏电行为,终端报警存在很多误报和漏报的情况,故需要进行数据探索和预处理,总结窃漏电用户的行为规律,再从数据中提炼出描述窃漏电用户的特征指标。
- 最后结合历史窃漏电用户信息,整理出识别模型的专家样本数据集,再进一步构建分类模型,实现窃漏电用户的自动识别。

1)从电力计量自动化系统、营销系统有选择性地抽取部分大用户用电负荷、终端报警及违约窃电处罚信息等原始数据。
2)对样本数据探索分析,剔除不可能存在窃漏电行为行业的用户,即白名单用户,初步审视正常用户和窃漏电用户的用电特征。
3)对样本数据进行预处理,包括数据清洗、缺失值处理和数据变换。
4)构建专家样本集。
5)构建窃漏电用户识别模型。
6)在线监测用户用电负荷及终端报警,调用模型实现实时诊断。
2、数据抽取
- 与窃漏电相关的原始数据主要有用电负荷数据、终端报警数据、违约窃电处罚信息以及用户档案资料等。
- 为了尽可能全面覆盖各种窃漏电方式,建模样本要包含不同用电类别的所有窃漏电用户及部分正常用户。窃漏电用户的窃漏电开始时间和结束时间是表征其窃漏电的关键时间节点,在这些时间节点上,用电负荷和终端报警等数据也会有一定的特征变化,故样本数据抽取时务必要包含关键时间节点前后一定范围的数据。
- 抽取近5年来所有的窃漏电用户有关数据和部分不同用电类别正常用电用户的有关数据。
3、探索分析
- 窃漏电用户分布分析

- 用电量周期性分析


4、数据预处理
数据清洗:从业务以及建模的相关需要方面考虑,筛选出需要的数据
- 通过数据的探索分析,发现在用电类别中,非居民用电类别不可能存在漏电窃电的现象,需要将非居民用电类别的用电数据过滤掉。
- 结合本案例的业务,节假日用电量与工作日相比,会明显偏低。为了尽可能达到较好数据效果,过滤节假日的用电数据。
 缺失值处理:在原始计量数据,特别是用户电量抽取过程中,发现存在缺失的现象。若将这些值抛弃掉,会严重影响后续分析结果。
缺失值处理:在原始计量数据,特别是用户电量抽取过程中,发现存在缺失的现象。若将这些值抛弃掉,会严重影响后续分析结果。

拉格朗日插值的代码:
# -*- coding: utf-8 -*-
# 拉格朗日插值代码
import pandas as pd # 导入数据分析库Pandas
from scipy.interpolate import lagrange # 导入拉格朗日插值函数inputfile = '../data/missing_data.xls' # 输入数据路径,需要使用Excel格式;
outputfile = '../tmp/missing_data_processed.xls' # 输出数据路径,需要使用Excel格式data = pd.read_excel(inputfile, header=None) # 读入数据# 自定义列向量插值函数
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):y = s[list(range(n - k, n)) + list(range(n + 1, n + 1 + k))] # 取数y = y[y.notnull()] # 剔除空值return lagrange(y.index, list(y))(n) # 插值并返回插值结果# 逐个元素判断是否需要插值
for i in data.columns:for j in range(len(data)):if (data[i].isnull())[j]: # 如果为空即插值。data[i][j] = ployinterp_column(data[i], j)data.to_excel(outputfile, header=None, index=False) # 输出结果**数据变换:**电量趋势下降指标、线损指标、告警类指标。

从正常用电到窃漏电特征分析:
对统计当天设定前后5天为统计窗口期,计算这11天内的电量趋势下降情况,首先计算这11天的每天的电量趋势,计算第i天的用电量趋势是考虑前后5天期间的用电量斜率,即:

若电量趋势为不断下降的,则认为具有一定的窃电嫌疑,故计算这11天内,当天比前一天用电量趋势为递减的天数,即设有

线路的线损率可作为用户线损率的参考值,若用户发生窃漏电,则当天的线损率会下降,但由于用户每天的用电量存在波动,单纯以当天线损率下降了作为窃漏电特征则误差过大,所以考虑前后几天的线损率平均值,判断其增长率是否大于1%,若线损率的增长率大于1%则具有窃漏电的可能性。
对统计当天设定前后5天为统计窗口期,首先分别计算统计当天与前5天之间的线损率平均值 和统计当天与后5天之间的线损率平均值 ,若 比 的增长率大于1%,则认为具有一定的窃电嫌疑,故定义线损指标:

告警类指标:
与窃漏电相关的终端报警主要有电压缺相、电压断相、电流反极性等告警,计算发生与窃漏电相关的终端报警的次数总和,作为告警类指标。
5、构建专家样本
对2009年1月1日至2014年12月31日所有窃漏电用户及部分正常用户的电量、告警及线损数据和该用户在当天是否窃漏电的标识,按窃漏电评价指标进行处理,得到专家样本库。

三、构建模型
1、构建窃漏电用户识别模型
对专家样本随机选取20%的作为测试样本,剩下80%的作为训练样本。
- LM神经网络建模
由混淆矩阵(训练样本),可以算得分类准确率为(161+58)/(161+58+6+7)=94.4%,正常用户被误判为窃漏电用户占正常用户的7/(161+7)=4.2%,窃漏电用户被误判为正常用户占正常窃漏电用户的6/(6+58)=9.4%。
# -*- coding: utf-8 -*-
# 构建并测试CART决策树模型import pandas as pd # 导入数据分析库
from random import shuffle # 导入随机函数shuffle,用来打算数据from matplotlib import pyplot as pltdatafile = '../data/model.xls' # 数据名
data = pd.read_excel(datafile) # 读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix() # 将表格转换为矩阵
shuffle(data) # 随机打乱数据p = 0.8 # 设置训练数据比例
train = data[:int(len(data) * p), :] # 前80%为训练集
test = data[int(len(data) * p):, :] # 后20%为测试集# 构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier # 导入决策树模型treefile = '../tmp/tree.pkl' # 模型输出名字
tree = DecisionTreeClassifier() # 建立决策树模型
tree.fit(train[:, :3], train[:, 3]) # 训练# 保存模型
from sklearn.externals import joblibjoblib.dump(tree, treefile)from cm_plot import * # 导入自行编写的混淆矩阵可视化函数cm_plot(train[:, 3], tree.predict(train[:, :3])).show() # 显示混淆矩阵可视化结果
# 注意到Scikit-Learn使用predict方法直接给出预测结果。from sklearn.metrics import roc_curve # 导入ROC曲线函数fpr, tpr, thresholds = roc_curve(test[:, 3], tree.predict_proba(test[:, :3])[:, 1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC of CART', color='green') # 作出ROC曲线
plt.xlabel('False Positive Rate') # 坐标轴标签
plt.ylabel('True Positive Rate') # 坐标轴标签
plt.ylim(0, 1.05) # 边界范围
plt.xlim(0, 1.05) # 边界范围
plt.legend(loc=4) # 图例
plt.show() # 显示作图结果

- CART决策树建模
由混淆矩阵(训练样本),分类准确率为(160+56)/(160+56+3+13)=93.1%,正常用户被误判为窃漏电用户占正常用户的13/(13+160)=7.5%,窃漏电用户被误判为正常用户占正常窃漏电用户的3/(3+56)=5.1%。
# -*- coding: utf-8 -*-import pandas as pd
from random import shuffledatafile = '../data/model.xls'
data = pd.read_excel(datafile)
data = data.as_matrix()
shuffle(data)p = 0.8 # 设置训练数据比例
train = data[:int(len(data) * p), :]
test = data[int(len(data) * p):, :]# 构建LM神经网络模型
from keras.models import Sequential # 导入神经网络初始化函数
from keras.layers.core import Dense, Activation # 导入神经网络层函数、激活函数netfile = '../tmp/net.model' # 构建的神经网络模型存储路径net = Sequential() # 建立神经网络
net.add(Dense(input_dim=3, output_dim=10)) # 添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) # 隐藏层使用relu激活函数
net.add(Dense(input_dim=10, output_dim=1)) # 添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) # 输出层使用sigmoid激活函数
net.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary") # 编译模型,使用adam方法求解net.fit(train[:, :3], train[:, 3], nb_epoch=1000, batch_size=1) # 训练模型,循环1000次
net.save_weights(netfile) # 保存模型predict_result = net.predict_classes(train[:, :3]).reshape(len(train)) # 预测结果变形
'''这里要提醒的是,keras用predict给出预测概率,predict_classes才是给出预测类别,而且两者的预测结果都是n x 1维数组,而不是通常的 1 x n'''from cm_plot import * # 导入自行编写的混淆矩阵可视化函数cm_plot(train[:, 3], predict_result).show() # 显示混淆矩阵可视化结果from sklearn.metrics import roc_curve # 导入ROC曲线函数predict_result = net.predict(test[:, :3]).reshape(len(test))
fpr, tpr, thresholds = roc_curve(test[:, 3], predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC of LM') # 作出ROC曲线
plt.xlabel('False Positive Rate') # 坐标轴标签
plt.ylabel('True Positive Rate') # 坐标轴标签
plt.ylim(0, 1.05) # 边界范围
plt.xlim(0, 1.05) # 边界范围
plt.legend(loc=4) # 图例
plt.show() # 显示作图结果

混淆矩阵的函数代码:
def cm_plot(y, yp):from sklearn.metrics import confusion_matrix #导入混淆矩阵函数cm = confusion_matrix(y, yp) #混淆矩阵import matplotlib.pyplot as plt #导入作图库plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。plt.colorbar() #颜色标签for x in range(len(cm)): #数据标签for y in range(len(cm)):plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')plt.ylabel('True label') #坐标轴标签plt.xlabel('Predicted label') #坐标轴标签return plt
2、模型评价
用测试样本对两个模型进行评价,评价方法采用ROC曲线进行评估。
经过对比发现LM神经网络的ROC曲线比CART决策树的ROC曲线更加靠近单位方形的左上角,LM神经网络ROC曲线下的面积更大,说明LM神经网络模型的分类性能较好,能应用于窃漏电用户识别。
- LM神经网络在测试样本下的ROC曲线

- CART决策树在测试样本下的ROC曲线

3、进行窃漏电诊断

拓展思考
- 目前企业偷漏税现象泛滥,应该加大对企业偷漏税行为的防范工作。如何用数据挖掘的思想,智能的识别企业偷漏税行为,有力的打击企业偷漏税的违法行为。
- 汽车销售行业,通常是指销售汽车整车的行业。汽车销售行业在税收上存在少开发票金额、少计收入,上牌、按揭 、保险等一条龙服务未入帐反映,不及时确认保修索赔款等多种情况,导致政府损失大量税收。汽车销售企业的部分经营指标能一定程度上评估企业的偷漏税倾向。
相关文章:
【数据挖掘实战】——电力窃漏电用户自动识别
【数据挖掘实战】——电力窃漏电用户自动识别一、背景和挖掘目标二、分析方法与过程1、初步分析2、数据抽取3、探索分析4、数据预处理5、构建专家样本三、构建模型1、构建窃漏电用户识别模型2、模型评价3、进行窃漏电诊断拓展思考项目代码地址:https://gitee.com/li…...
树莓派 安装 宝塔linux面板5.9. 2023-2-13
一.环境 1.硬件环境: 树莓派3b , 8GB tf卡 ,micro usb电源 2.网络环境: 网线直连路由器 , 可访问互联网 3.软件环境: 树莓派操作系统 CentOS-Userland-7-armv7hl-RaspberryPI-Minimal-2009-sda(linux) 系统刻录工具 Win32DiskImager (win) ip扫描工具 Adv…...

如何提高短视频的播放量-4个技巧
做短视频自媒体,点击率是第一位,点击量越多,粉丝也就越多。可是,怎么才能增加短视频的点击率和提高播放量呢?今天就来教大家4个技巧: 1、蹭热点 热门话题自带流量,它的热度和价值,是…...
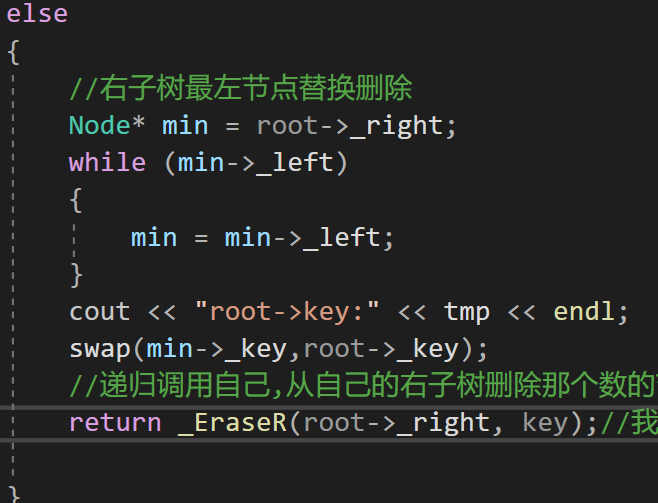
搜索二叉树
文章目录二叉搜索树模拟实现InsertInsertR()EraseEraseR搜索树的价值实现代码二叉搜索树 在二叉树的基础之上, 左子树的值都比根节点小,右子树都更大。那么他的左右子树也分别叫做二叉搜索树。 查找一个节点,最多查找高度次(建立在这个树是比较均衡的).10亿里面找…...

CentOS8基础篇5:用户账号与用户组的创建
一、用户与用户组概念 Linux是一个多用户、多任务的服务器操作系统,多用户多任务指可以在系统上建立多个用户,而多个用户可以在同一时间内登录同一个系统执行各自不同的任务,而互不影响。 Linux用户是根据角色定义的,具体分为三…...

阿里云服务器使用
服务器配置CPU&内存:2核(vCPU)2 GiB操作系统:Ubuntu 22.04 64位运行环境部署因为部署用到了nodejs首先,打开终端,并输入以下命令以安装必要的软件包:sudo apt-get install curl接着,使用 curl 命令安装…...

全国空气质量排行,云贵川和西藏新疆等地空气质量更好
哈喽,大家好,春节刚刚过去,不知道大家是不是都开始进入工作状态了呢?春节期间,允许燃放烟花爆竹的地区的朋友们不知道都去欣赏烟花表演没有?其他地区的朋友们相比烟花表演可能更关心燃放烟花爆竹造成的环境…...

Learning C++ No.8【内存管理】
引言: 北京时间:2023/2/12/18:04,昨天下午到达学校,摆烂到现在,该睡睡,该吃吃,该玩玩,在一顿操作之下,目前作息调整好了一些,在此记录,2月11&…...

『 MySQL篇 』:MySQL表的相关约束
基础篇 MySQL系列专栏(持续更新中 …)1『 MySQL篇 』:库操作、数据类型2『 MySQL篇 』:MySQL表的CURD操作3『 MySQL篇 』:MySQL表的相关约束文章目录 1 . 非空约束 (not null)2 . 唯一性约束(unique)3 . check约束4 . 默认约束(default)5 . 主…...

家政服务小程序实战教程10-分类展示
小程序一般底部菜单栏会有一个分类的功能,点击分类,以侧边栏导航的形式列出所有类目,点击某个类目可以做数据筛选,我们本篇就实现一下该功能 01 优化数据源 在我们家政服务小程序里,我们已经建立了类型和服务的数据源…...

一篇文章带你学会Ansible的安装及部署
目录 前言 一、什么是Ansible 二、Ansible的工作方式 三、Ansible的安装 四、构建Anisble清单 1、清单书写方式 2、清单查看 3、清单书写规则 4、主机规格的范围化操作 五、ansible命令指定清单的正则表达式 六、 Ansible配置文件参数详解 1、配置文件的分类与优先…...

opencv常用函数
1)读视频 img cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) if vc.isOpened():ret, frame vc.read() else:ret False while ret:#此处省略具体的操作ret, frame vc.read() # 读下一帧 vc.release() 2)保存视频 def mk_video_writer(vc, path,frame_…...
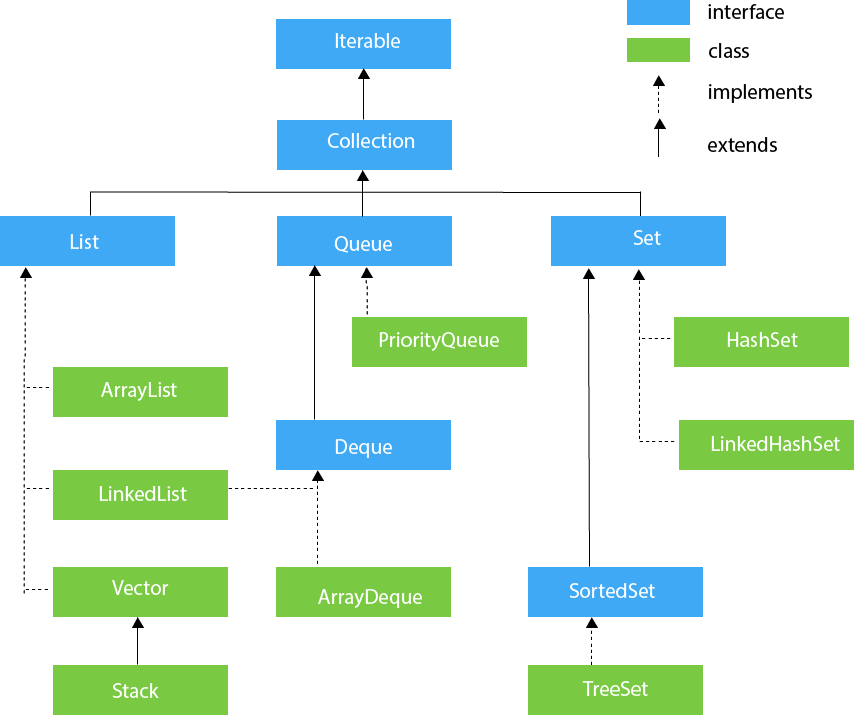
Java集合框架常见面试题
1. 剖析面试最常见问题之 Java 集合框架 1.1. 集合概述 1.1.1. Java 集合概览1.1.2. 说说 List,Set,Map 三者的区别?1.1.3. 集合框架底层数据结构总结 1.1.3.1. List1.1.3.2. Set1.1.3.3. Map 1.1.4. 如何选用集合?1.1.5. 为什么要使用集合? 1.2. Colle…...

医用雾化器单片机方案设计
产品概述 雾化器是一款基于电路板的振荡信号被大功率三极管进行能量放大,传递给压电陶瓷片,当压电陶瓷片受电信号的激励,产生高频谐振,并使吸附在微孔膜上的液体结产生超声振荡,将液体的结构打散而产生自然飘逸的雾。不…...
)
python魔术方法(一)
所谓的魔术方法就是让用户客制化类的方法,常常是python中开头有两个下划线的方法。 __new__() new是创建一个类的过程 class A:def __new__(cls,x):print("__new__")return super().__new__(cls)由于new函数是建立了一个对象,所以必须返回一…...
IDEA配置部署tomcat详细步骤(maven web 和Javaweb)
目录 读者手册 一、概念与准备工作 (一)概念 (二)准备工作 (三)IDEA配置tomcat服务器(maven web项目演示) ( 四)Javaweb项目创建tomcat演示 读者手册 读…...
没有设置密码,每次打开RAR文件却都要输密码?
有小伙伴说遇到这种情况:用WinRAR软件压缩RAR文件后,再次打开时显示需要输入密码,但自己压缩文件时并没有设置密码,后续不管几次压缩文件都需要密码,这是怎么回事呢? 其实,这很可能是之前设置压…...

想要知道有哪些免费API接口,看它就够了
免费API它来啦! 微信开放平台 https://open.weixin.qq.com/ 让你的应用支持微信登录、微信分享、微信支付等功能。 百度地图开放平台 https://lbsyun.baidu.com/index.php?titlewebapi 百度地图Web服务API为开发者提供http/https接口,即开发者通过…...

【Java】二叉树
一、树形结构 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点: 有一个特殊…...

C++学习记录——구 模板初阶
文章目录1、泛型编程和函数模板1、函数模板的实例化2、模板参数的匹配原则2、类模板1、泛型编程和函数模板 泛型编程顾名思义,泛用性很高。之前C可以用重载来对付同名函数,但还是麻烦,有一个类型的变量就得写一个类型的函数。C对此创建了库这…...

无人机视角热成像行人车辆检测数据集VOC+YOLO格式2755张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):2755标注数量(xml文件个数):2755标注数量(txt文件个数):2755标注类别…...

MobaXterm远程连接:管理Baichuan-M2-32B-GPTQ-Int4服务器
MobaXterm远程连接:管理Baichuan-M2-32B-GPTQ-Int4服务器 1. 为什么选择MobaXterm来管理大模型服务器 部署Baichuan-M2-32B-GPTQ-Int4这样的医疗增强推理模型,通常需要在Linux服务器上运行vLLM或SGLang等推理引擎。这类服务对系统资源要求高࿰…...

3步突破AI工具限制:开源解决方案全解析
3步突破AI工具限制:开源解决方案全解析 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to pro. We have this limi…...
)
J-Flash烧录KEA128芯片全流程指南(附常见错误排查)
J-Flash烧录KEA128芯片全流程指南(附常见错误排查) 对于嵌入式开发工程师来说,掌握可靠的烧录工具是基本功。J-Flash作为SEGGER公司推出的专业烧录软件,以其稳定性和广泛的芯片支持著称。本文将带你从零开始,手把手完成…...

用快马平台十分钟搭建你的第一个zotero式文献管理web原型
今天想和大家分享一个超实用的开发经验:如何用InsCode(快马)平台快速搭建文献管理系统的web原型。作为一个经常需要整理论文的研究狗,zotero这类工具简直是刚需,但有时候我们想验证一些定制化功能的想法,从零开发又太耗时。下面我…...

终极魔兽争霸III优化工具:WarcraftHelper完整配置指南
终极魔兽争霸III优化工具:WarcraftHelper完整配置指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战略游戏&a…...

老旧设备重生计划:Windows 11绕过系统限制的安全安装指南
老旧设备重生计划:Windows 11绕过系统限制的安全安装指南 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 想让你的老旧电脑也能流畅运行Windows 11吗?本文将为你提供一套完…...

3个关键步骤让老款Mac重获新生:OpenCore Legacy Patcher终极指南
3个关键步骤让老款Mac重获新生:OpenCore Legacy Patcher终极指南 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当苹果宣布你的Mac不再支持最新的macOS系统时…...

新手零失败指南:基于快马平台生成win10安装openclaw的交互式学习应用
最近在Windows 10上折腾OpenClaw的安装,作为新手真的踩了不少坑。环境配置报错、依赖冲突、权限问题...每次遇到错误都要花大量时间搜索解决方案。后来发现用InsCode(快马)平台可以快速生成带交互指导的安装程序,终于找到了适合新手的打开方式。这里把完…...

OFA模型与AI编程助手结合:自动生成代码注释中的图像描述
OFA模型与AI编程助手结合:自动生成代码注释中的图像描述 1. 引言 你有没有遇到过这种情况?接手一个老项目,代码里引用了好几张图表或者UI设计图,但注释里只有一句“详见图片”,图片文件本身命名又很随意,…...