Python深度学习GRU、LSTM 、BiLSTM-CNN神经网络空气质量指数AQI时间序列预测及机器学习分析|数据分享...
全文链接:https://tecdat.cn/?p=38742
分析师:Zhixiong Weng
人们每时每刻都离不开氧,并通过吸入空气而获得氧。一个成年人每天需要吸入空气达6500升以获得足够的氧气,因此,被污染了的空气对人体健康有直接的影响,空气品质对人的影响更是至关重要(点击文末“阅读原文”获取完整代码数据)。
每出现一次AQI指数数值过大,可以肯定它都会引起我们足够的重视,提醒我们要保护我们生存的环境,尽可能地减少对环境的破坏与污染。而从更高的层次来说,消除或减少空气污染对人类的危害,唯一可行的就是提高我们的环保理念,并切实在日常生活中对环境加以保护。从机器学习的角度来说,根据已有数据可预测未来AQI浓度,也可以将空气质量分类为优良差等,对提高环境保护有重要意义。
机器学习研究
任务/目标:
根据已有AQI数据对其进行简单的聚类、分类、降维、相关性分析、预测、可视化等,对其探索得出相关结论,如使用k-means将数据聚类,将其分成适合的组数探究AQI数据的分布情况;使用回归预测未来的AQI;使用主成分分析对其降维并探究AQI气体的相关性;使用K-NN算法将AQI数据分类,给未来没有分类的数据自动分好类等。
数据源准备:
网络爬取别称数据提取,就是从指定的网站上收集数据信息。网络爬虫是一种程序,他可以高效的获取我们想要的数据,主要用于搜索引擎,通过使用request、scrapy、selenium等库获取该案例所需数据。如下图为部分数据:
数据降维
AQI数据有多个变量,为了方便后续计算,使用主成分分析法将多个变量减少到两至三个:

选择两个主成分即可保留数据集的大部分信息。

建模
k均值算法
根据空气质量数据将其分成合适的组数,探索各空气污染气体的分布情况。过程是先收集数据并选择合适的中心点,计算其他数据点到中心点的距离,计算平均值,将数据点分配到给他最近的聚类中心。

点击标题查阅往期内容

R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)

左右滑动查看更多
01

02

03

04

线性回归
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。通常使用曲线/线来拟合数据点,目标是使曲线到数据点的距离差异最小。对大量的观测数据进行处理,从而得到比较符合事物内部规律的数学表达式。也就是说寻找到数据与数据之间的规律所在,从而就可以模拟出结果,也就是对结果进行预测。

k近邻算法
给定一个训练数据集,对新的输入实例,在训练集中找到与该实例最临近,就把这个实例分配到这个类中。

当所预测的空气污染物PM2.5,PM10,O3,No2,Co,So2的含量分别为29,20,50,13,0.88,10μg/m3(CO为mg/m3)时,空气质量为优。空气质量令人满意,基本无空气污染,对健康没有危害,各类人群可多参加户外活动,多呼吸一下清新的空气。


使用此模型,当测量出污染物指数时就可以预测空气的质量等级。每出现一次AQI指数数值过大,可以肯定它都会引起我们足够的重视,提醒我们要保护我们生存的环境,尽可能地减少对环境的破坏与污染。
Python 中深度学习模型(BiLSTM、GRU、LSTM 及 BiLSTM-CNN)的空气质量指数时间序列数据融合预测分析|附数据代码
接下来将探讨多种深度学习模型在空气质量指数时间序列预测与分析中的应用,通过对比不同模型的性能,以期找到更优的预测方法。
数据介绍
首先,我们获取了包含空气质量相关指标的数据集(查看文末了解数据免费获取方式),其以表格形式呈现,包含了诸如年份(year)、月份(month)、日(day)、小时(hour)以及多种污染物浓度指标(如 PM2.5、PM10、SO2、NO2、CO、O3 等)以及气象相关数据(如温度 TEMP、气压 PRES、露点 DEWP、降雨量 RAIN、风向 wd、风速 WSPM 等)信息。
通过pandas库的相关函数对数据进行读取,代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import preprocessing这段代码的作用是导入所需的库,并将存储空气质量数据的csv文件读取到程序中,形成一个可供后续操作的数据框(DataFrame)对象,方便进行数据处理和分析。
接着,我们可以使用describe函数来查看数据的基本统计信息,比如均值、标准差、最小值、最大值等,代码如下:
data.describe()这能帮助我们快速了解各指标数据的大致分布情况,为后续的数据预处理和模型构建提供参考依据。
数据预处理
原始数据可能存在一些缺失值等问题,为了保证模型训练的准确性,需要进行预处理。首先,我们使用如下代码去除含有缺失值的行:
data = data.dropna()然后,针对部分指标计算其特定时间窗口内的平均值等统计量,比如对于PM10、PM2.5等污染物指标,计算其 24 小时的平均浓度值,代码示例如下:
data\["PM10\_24hr\_avg"\] = data\["PM10"\].rolling(window = 24, min_periods = 16).mean().values这些新生成的指标数据可以更好地反映污染物浓度在一定时间范围内的综合情况,有助于提升模型对空气质量变化趋势的捕捉能力。
深度学习模型应用
在完成数据预处理后,我们将应用多种深度学习模型来进行空气质量指数的预测,以下是不同模型的构建与训练过程。
(一)双向长短期记忆网络(BiLSTM)模型
双向长短期记忆网络(BiLSTM)能够同时考虑时间序列数据的正向和反向信息,对于捕捉时间序列中的长期依赖关系有较好的效果。其模型构建代码如下:
import tensorflow as tf
model_BiLSTM = tf.keras.Sequential(\[tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(100, return\_sequences=True), input\_shape=(n\_steps, n\_features)),上述代码首先构建了一个包含两层双向 LSTM 层以及相应的Dropout层(用于防止过拟合)和输出层的序列模型,然后对模型进行编译,指定了优化器、损失函数以及评估指标等,最后通过summary函数查看模型的结构和参数信息。
使用tf.kel函数可以可视化模型结构,代码如下:
其生成的模型结构图片(如下所示)能让我们直观地看到各层的输入输出形状等关键信息。
随后对模型进行训练,代码如下:
hist = model_BiLSTM.fit训练完成后,可以使用训练好的模型进行预测,并计算相关的评估指标,如均方误差(MSE)等同时,还可以绘制预测值与真实值的对比图来直观地查看模型的预测效果
def plot\_predicted(predicted\_data, true_data):fig, ax = plt.subplots(figsize=(17,8))其生成的对比图(如下所示)有助于我们直观判断模型预测的准确性。
(二)门控循环单元(GRU)网络模型
门控循环单元(GRU)网络也是一种常用于处理时间序列数据的深度学习模型,相较于 LSTM 结构相对简单但同样能有效捕捉序列信息。其模型构建与训练过程如下:
from sklearn.metrics import mean\_squared\_error, mean\_absolute\_error, r2_score
regressorGRU = Sequential()
# 第一层 GRU 层并添加 Dropout 正则化
regressorGRU.add(GRU(units=50, return\_sequences=True, input\_shape=(X\_split\_train.shape\[1\],1), activation='tanh'))
regressorGRU.add(Dropout(0.2))
# 第二层 GRU 层
regressorGRU.add(GRU(units=50, return\_sequences=True, input\_shape=(X\_split\_train.shape\[1\],1), activation='tanh'))
......这段代码构建了一个多层的 GRU 网络模型,每一层都设置了相应的参数和激活函数,并添加了Dropout层来防止过拟合,最后进行编译,同样通过summary查看模型结构和参数信息。
训练结束后,进行预测并计算诸如均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)以及 R2 分数等评估指标。同时,也可以绘制预测值与真实值的对比图来直观展示模型效果,代码和前面类似,此处不再赘述。另外,还可以绘制模型训练过程中的损失函数变化曲线以及准确率变化曲线等,代码如下:
plt.plot(hist.history\['accuracy'\])
plt.plot(hist.history\['val_accuracy'\])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(\['train', 'test'\], loc='upper left')
plt.show()
plt.plot(hist.history\['loss'\])
plt.plot(hist.history\['val_loss'\])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(\['train', 'test'\], loc='upper left')
plt.show()生成的图片(如下所示)可以帮助我们分析模型是否存在过拟合等问题。

长短期记忆网络(LSTM)及其相关变体模型
除了上述的 BiLSTM 和 GRU 模型外,我们还应用了普通的 LSTM 以及 LSTM 与卷积神经网络(CNN)结合的模型(BiLSTM-CNN)来进行预测分析,其模型构建、训练和评估的过程与前面类似,只是在模型结构、参数设置等方面存在差异。
构建好模型后进行训练并在训练过程中记录相关指标,代码如下:
hist = model.fit(train_dataset,validation\_data = val\_dataset,epochs=50,callbacks=\[es,plateau\],verbose=1)训练完成后同样进行预测以及评估指标计算、绘制对比图等操作,代码与前面类似,不再赘述。而对于 BiLSTM-CNN 模型,其结合了双向 LSTM 对时间序列的处理能力和卷积神经网络对局部特征提取的优势。
后续同样进行训练、预测以及相关指标评估和结果可视化等操作,通过这些不同模型的对比分析,我们可以更全面地了解各模型在空气质量指数时间序列预测中的表现优劣。



结果对比与分析
通过对上述多种深度学习模型在相同数据集上进行训练、预测,并计算相应的评估指标(如均方误差、均方根误差、平均绝对误差、R2 分数等),我们可以对比不同模型的性能。从不同模型的预测值与真实值对比图以及各项指标数值来看,不同模型在捕捉空气质量指数变化趋势以及预测准确性上各有差异。例如,部分模型在某些时间段的预测值与真实值贴合度较高,而有些模型则可能存在一定偏差。通过分析这些结果,可以为后续进一步优化模型或者选择更合适的预测模型提供参考依据,以便更准确地对空气质量指数进行预测,从而更好地服务于环境保护等相关工作。
总之,深度学习模型在空气质量指数时间序列预测方面有着较大的应用潜力,但不同模型的适用性和性能表现还需要根据具体的数据特点和应用场景等因素综合考量,未来还可以进一步探索模型改进以及融合等方法来提升预测的准确性和可靠性。
关于分析师

在此对 Zhixiong Weng 对本文所作的贡献表示诚挚感谢,他在桂林电子科技大学完成了物流管理(信息化)专业的学习,专注数据采集、数据分析以及机器学习领域。擅长 R 语言、Python、SQL,在利用机器学习对空气质量指数的研究方面颇有建树。
数据获取
在公众号后台回复“空气质量数据”,可免费获取完整数据。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python深度学习GRU、LSTM 、BiLSTM-CNN神经网络空气质量指数AQI时间序列预测及机器学习分析》。
点击标题查阅往期内容
【视频讲解】共享单车使用量预测:RNN, LSTM,GRU循环神经网络和传统机器学习|数据分享
视频:Python深度学习量化交易策略、股价预测:LSTM、GRU深度门控循环神经网络|附代码数据
Python用GRU神经网络模型预测比特币价格时间序列数据2案例可视化|附代码数据
【视频】LSTM模型原理及其进行股票收盘价的时间序列预测讲解|附数据代码
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()

相关文章:
Python深度学习GRU、LSTM 、BiLSTM-CNN神经网络空气质量指数AQI时间序列预测及机器学习分析|数据分享...
全文链接:https://tecdat.cn/?p38742 分析师:Zhixiong Weng 人们每时每刻都离不开氧,并通过吸入空气而获得氧。一个成年人每天需要吸入空气达6500升以获得足够的氧气,因此,被污染了的空气对人体健康有直接的影响&…...

JSP基础
一、Tomcat 1.Tomcat简介: Tomcat是一个免费的开源JSP容器,是Apache的Jakarta项目中的一个核心项目因免费、稳定而成为目前比较流行的Web应用服务器网址:https://tomcat.apache.org/ 2.Tomcat的配置——环境变量 (1)…...

基于Springboot +Vue 在线考试管理系统
基于Springboot Vue 在线考试管理系统 前言 随着信息技术的飞速发展,教育领域正经历着深刻的变革。传统的考试模式因其诸多限制和不便,已难以满足现代教育的需求。基于SpringBoot和Vue框架开发的在线考试系统应运而生,它充分利用了现代互联…...

Node.js 函数
Node.js 函数 1. 概述 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它允许开发者使用 JavaScript 编写服务器端和网络应用程序。在 Node.js 中,函数是一等公民,意味着它们可以作为变量传递,可以作为参数传递给其他函数,也可以从其他函数返回。本文将详细…...
-JVM运行时数据区)
JVM学习指南(9)-JVM运行时数据区
JVM学习指南(9)-JVM运行时数据区 引言 Java虚拟机(JVM)是Java程序运行的核心,它为Java程序提供了一个与平台无关的执行环境。JVM的重要性不仅在于它实现了Java的跨平台特性,还在于它对程序执行过程中内存的管理。JVM运行时数据区是程序执行过程中存储数据的关键区域,理解…...

2025/1/4期末复习 密码学 按老师指点大纲复习
我们都要坚信,道路越是曲折,前途越是光明。 --------------------------------------------------------------------------------------------------------------------------------- 现代密码学 第五版 杨波 第一章 引言 1.1三大主动攻击 1.中断…...

关于嵌入式系统的知识课堂(二)
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于嵌入式系统的知识课堂(…...

基于ETAS工具的AutoConnect实现方案
文章目录 前言基于ISOLAR工具实现AutoConnect基于脚本实现AutoConnect总结前言 Autosar软件架构设计中,Connect通常来自于Composition之间(Assembly connectors),Component之间(Assembly connectors),Component与Composition之间(Delegation connectors),还有一种Pa…...

BGP基础配置实验
一、实验拓补 二、实验要求及分析 实验要求: 1,R1为AS 100区域;R2、R3、R4为AS 200区域且属于OSPF协议;R5为AS 300区域; 2,每个设备上都有环回,且通过环回可以使设备互通; 实验分…...

基于单片机的人体健康指标采集系统设计
1.系统的功能及方案设计 根据系统设计要求,人体健康指标采集系统的系统结构框图如图2.1所示。系统以单片机作为主控核心,协调控制各个模块进行工作。在传感器检测模块中包括MAX30102心率血氧检测模块、体温检测模块、液晶显示模块。系统以无创的形式实现…...

Go语言性能优化-字符串格式化优化
在 Go 语言中,格式化字符串(例如使用 fmt.Sprintf、fmt.Printf 等函数)确实可能对性能产生影响,尤其是当频繁执行格式化操作时。格式化字符串涉及对格式符的解析和数据类型的转换,这会增加额外的开销。为了减少格式化字符串带来的性能影响,可以采取以下一些优化策略: 1…...

UE5失真材质
渐变材质函数:RadialGradientExponential(指数径向渐变) 函数使用 UV 通道 0 来产生径向渐变,同时允许用户调整半径和中心点偏移。 用于控制渐变所在的位置及其涵盖 0-1 空间的程度。 基于 0-1 的渐变中心位置偏移。 源自中心的径…...

SAP 01-初识AMDP(ABAP-Managed Database Procedure)
1. 什么是AMDP(ABAP-Managed Database Procedure) 1.)AMDP - ABAP管理数据库程序,是一种程序,我们可以使用SQLSCRIPT在AMDP内部编写代码,SQLSCRIPT是一种与SQL脚本相同的数据库语言,这种语言易于理解和编码。 将AM…...

关于视频审核,内容风控在“控”什么?
随着互联网用户每周上网时长的增加,内容偏好逐渐向视频形式转移,视频内容成为了企业竞争的新战场。然而,视频内容审核和风险控制成为了企业面临的重大挑战。那么在视频审核中,内容风控到底在“控”什么呢? 视频内容风…...

5G NTN(七) 高层(1)
说明:本专题主要基于3GPP协议38.821 目录 1. Idle态移动性增强 1.1 TA问题 1.1.1 TA的大小 1.1.2 针对NTN LEO的移动TA,场景C2和D2 1.1.3 针对NTN LEO的固定TA,场景C2和D2 1.1.3.1 方法1:当UE位置信息无法获取的时候 1.1.…...
专家混合(MoE)大语言模型:免费的嵌入模型新宠
专家混合(MoE)大语言模型:免费的嵌入模型新宠 今天,我们深入探讨一种备受瞩目的架构——专家混合(Mixture-of-Experts,MoE)大语言模型,它在嵌入模型领域展现出了独特的魅力。 一、M…...

《柴油遗产-无耻时代》V98375官方版
靠近你所在赛道上的另一名玩家进行攻击或防守,跳到另一条赛道上进行恢复,或闪到对手背后打他个措手不及。与队友合作,充分利用每个角色的独特玩法来控制战斗走向! 《柴油遗产-无耻时代》官方版 https://pan.xunlei.com/s/VODW7xDX…...

科技云报到:洞见2025年科技潮流,技术大融合开启“智算时代”
科技云报到原创。 随着2024年逐渐接近尾声,人们不禁开始展望即将到来的2025年。这一年,被众多科技界人士视为开启新纪元的关键节点。站在新的起点上,我们将亲眼目睹未来科技如何改变我们的世界。从人工智能到量子计算,从基因编辑…...
【openwrt】OpenWrt 路由器的 802.1X 动态 VLAN
参考链接 [OpenWrt Wiki] Wi-Fi /etc/config/wirelesshttps://openwrt.org/docs/guide-user/network/wifi/basic#wpa_enterprise_access_point 介绍 基于802.1X 无线网络身份验证...

[coredump] 生成管理
在 Linux 系统中,core dump 文件的生成路径和文件名可以通过几个方面来控制: 系统默认路径: 默认情况下,core dump 文件通常生成在程序的工作目录,即程序运行时的当前目录。文件名通常为 core,或者在某些系…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...
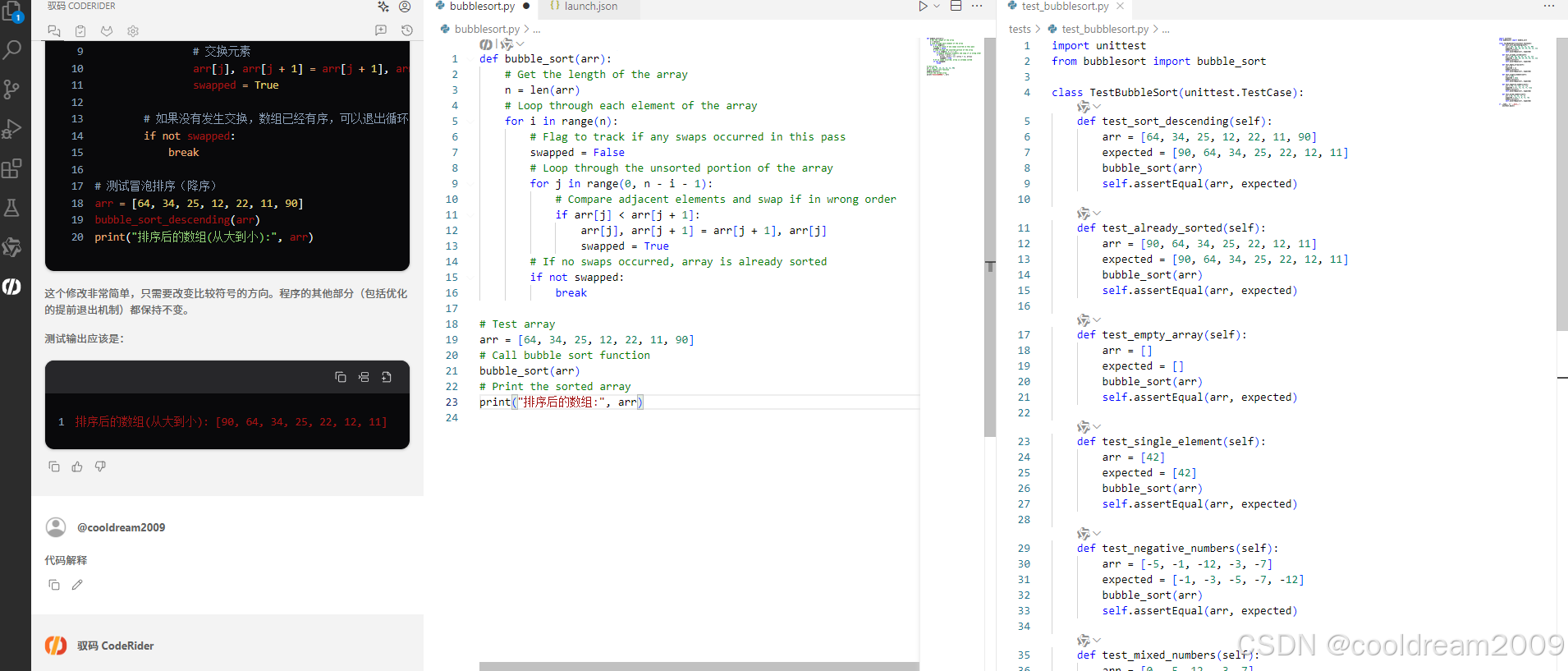
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...