【数据结构05】排序
系列文章目录
【数据结构05】排序
.
【算法思想04】二分查找
文章目录
- 系列文章目录
- @[toc]
- 1. 基本思想与实现
- 1.1 插入类排序
- 1.1.1 直接插入排序(*)
- 1.1.2 折半插入排序
- 1.1.3 希尔排序(*)
- 1.2 交换类排序
- 1.2.1 冒泡排序(*)
- 1.2.2 快速排序(**)
- 1.3 选择类排序
- 1.3.1 简单选择排序(*)
- 1.3.2 堆排序(*)
- 1.4 归并排序
- 1.4.1 2路归并排序(*)
- 1.4.2 k路归并排序
- 1.5 线性时间非比较类排序
- 1.5.1 基数排序(*)
- 1.5.2 计数排序
- 1.5.3 桶排序
- 2. 性能比较与应用
- 2.1 性能分析比较
- 2.2 应用
- 3. 例题
- 3.1 [归并排序 - 排序链表(148中等)](https://leetcode.cn/problems/sort-list/description/)
- 3.2 [快速排序 - 数组中的第K个最大元素(215中等)](https://leetcode.cn/problems/kth-largest-element-in-an-array/description/)
- 3.3 [各大排序算法练习题 - 排序数组(912中等)](https://leetcode.cn/problems/sort-an-array/description/)
- 3.3.1 快速排序
- 3.3.2 归并排序
- 总结
- 参考资料
文章目录
- 系列文章目录
- @[toc]
- 1. 基本思想与实现
- 1.1 插入类排序
- 1.1.1 直接插入排序(*)
- 1.1.2 折半插入排序
- 1.1.3 希尔排序(*)
- 1.2 交换类排序
- 1.2.1 冒泡排序(*)
- 1.2.2 快速排序(**)
- 1.3 选择类排序
- 1.3.1 简单选择排序(*)
- 1.3.2 堆排序(*)
- 1.4 归并排序
- 1.4.1 2路归并排序(*)
- 1.4.2 k路归并排序
- 1.5 线性时间非比较类排序
- 1.5.1 基数排序(*)
- 1.5.2 计数排序
- 1.5.3 桶排序
- 2. 性能比较与应用
- 2.1 性能分析比较
- 2.2 应用
- 3. 例题
- 3.1 [归并排序 - 排序链表(148中等)](https://leetcode.cn/problems/sort-list/description/)
- 3.2 [快速排序 - 数组中的第K个最大元素(215中等)](https://leetcode.cn/problems/kth-largest-element-in-an-array/description/)
- 3.3 [各大排序算法练习题 - 排序数组(912中等)](https://leetcode.cn/problems/sort-an-array/description/)
- 3.3.1 快速排序
- 3.3.2 归并排序
- 总结
- 参考资料
1. 基本思想与实现
排序,就是重新排列表中的元素,使表中的元素满足按关键字有序的过程。
在排序过程中,根据数据元素是否完全在内存中,可以将排序算法分为两类:
- 内部排序:在排序期间,元素全部放在内存中;
- 外部排序:在排序期间,元素无法全部同时存在内存中,必须在排序的过程中根据要求不断地在内、外存之间移动。
本文主要与内部排序有关。一般情况下,内部排序算法在执行过程都要进行两种操作:比较和移动。通过比较两个关键字的大小,确定对应元素的前后关系,然后通过移动元素以达到有序。当然,并非所有的内部排序算法都要基于比较操作,如基数排序就不基于比较。
内部排序算法的性能取决于算法的时间复杂度和空间复杂度,而时间复杂度一般是由比较和移动的次数决定的。
注意:大部分排序算法都仅适用于顺序存储的线性表。
1.1 插入类排序
每次将一个待排序的记录按其关键字大小插入前面已排好的子序列,直到全部记录插入完成。
1.1.1 直接插入排序(*)
| 有序序列 | 当前元素 | 无序序列 |
|---|---|---|
| L[1…i-1] | L(i) | L[i+1…n] |
- 查找出 L(i) 在 L[1…i-1] 中的插入位置 k;
- 将 L[k…i-1] 中的所有元素依次后移一个位置;
- 将 L(i) 复制到 L(k)。
| [ 初始关键字 ] | 哨兵 | (49) | 38* | 65 | 97 | 76 | 13 | 27 | 49’ |
|---|---|---|---|---|---|---|---|---|---|
| i = 2 | (49) | (38 | 49) | 65* | 97 | 76 | 13 | 27 | 49’ |
| i = 3 | (65) | (38 | 49 | 65) | 97* | 76 | 13 | 27 | 49’ |
| i = 4 | (97) | (38 | 49 | 65 | 97) | 76* | 13 | 27 | 49’ |
| i = 5 | (76) | (38 | 49 | 65 | 76 | 97) | 13* | 27 | 49’ |
| i = 6 | (13) | (13 | 38 | 49 | 65 | 76 | 97) | 27* | 49’ |
| i = 7 | (27) | (13 | 27 | 38 | 49 | 65 | 76 | 97) | 49’* |
| i = 8 | (27) | (13 | 27 | 38 | 49 | 49’ | 65 | 76 | 97) |

框架:(注意元素下标从1开始,下标0充当哨兵)
void InsertSort(ElemType[] A, int n) {for (int i = 2; i <= n; i++) { // 依次将A[2]~A[n]插入前面的已排序序列if (A[i] < A[i-1]) { // 若A[i]关键码小于前驱A[0] = A[i]; // 复制为哨兵,A[0]不存放元素,不需要另外定义temp变量for (int j = i-1; A[0] < A[j]; --j) // 从后往前查找待插入位置,判断条件不使用j>=0A[j+1] = A[j]; // 向后挪位A[j+1]=A[0]; // 复制到插入位置}}
}
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:向有序序列中逐个插入元素的擦做进行了 n-1 趟,每趟操作都分为比较关键字和移动元素,比较次数和移动次数取决于待排序序列的初始状态。
- 最好情况:表中元素已经有序,此时每插入一个元素都只需比较一次而不用移动元素,此时时间复杂度为 O(n);
- 最坏情况:表中元素顺序刚好与排序结果中的元素顺序相反(逆序),总的比较次数达到最大,总的移动次数也达到最大,此时时间复杂度为 O(n2)。
- 平均情况:总的比较次数与移动次数均为 n2/4,因此直接插入排序算法的时间复杂度为 O(n2)。
- 稳定性:由于每次插入元素时总是从后往前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,所以直接插入排序是一个稳定的排序算法。
- 适用性:直接插入排序算法适用于顺序存储和连式存储的线性表。为链式存储,可以从前往后查找指定元素的位置。
1.1.2 折半插入排序
直接排序算法总是边比较边移动元素,折半插入排序则将比较和移动操作分离。当排序表为顺序存储的线性表时,可以对直接插入排序算法做如下改进:先用折半查找出元素的待插入位置,再统一移动待插入位置之后的所有元素。
框架:(注意元素下标从1开始,下标0充当哨兵)
void InsertSort(ElemType[] A, int n) {for (int i = 2; i <= n; i++) { // 依次将A[2]~A[n]插入前面的已排序序列A[0] = A[i]; // A[i]暂存至A[0],不需要另外定义temp变量int low = 1, high = i-1;while (low <= high) { // 使用二分查找找到待插入位置int mid = (low + high) / 2;if (A[mid] > A[0]) high = mid - 1; // target in A[low, mid-1]else low = mid + 1; // target in A[mid+1, high]}for (int j = i-1; j >= high+1; --j) { // 向后挪位,空出插入位置A[j+1] = A[j];}A[high+1]=A[0]; // 复制到插入位置}
}
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:仅减少了比较元素的次数,约为 O(nlog2n),该比较次数与待排序表的初始状态无关,进取决于表中的元素个数 n;而元素的移动次数并未改变,依赖于待排序表的初始状态。因此折半插入排序的时间复杂度仍为 O(n2),但对于数据量不是很大的排序表来说,折半插入排序往往能表现出很好的性能。
- 稳定性:折半插入排序是一个稳定的排序算法。
Q:折半插入排序的前提是有序序列,但是都已经有序了为什么还要排序?
A:折半插入排序(Binary Insertion Sort)并非只能应用于完全有序的序列,而是在序列接近有序或者部分有序的情况下效率更高。即使序列已经是有序的,进行折半插入排序可以看作是再次验证并确保其有序性,同时在面对大规模或者部分有序数据时能够更高效地完成排序任务。
1.1.3 希尔排序(*)
由前面的分析可知,直接插入排序算法的时间复杂度为 O(n2),但若待排序列为“正序”时,其时间复杂度可提高至 O(n),由此可见它更适用于基本有序的排序表和数据量不大的排序表。希尔排序基于这两点分析对直接插入排序进行改进,又称缩小增量排序。
希尔排序将待排序列分割成若干形如 L[i, i+d, i+2d, … i+kd] 的子序列,即把相隔某个增量的记录组成一个子序列,对各个子序列分别进行直接插入排序。当增量因子为 1 时,整个表中的元素已呈“基本有序”,整个序列作为一个表来处理,再对全体记录进行一次直接插入排序。
- 先取一个小于 n 的步长 d1,把表中的全部记录分成 d1 组,所有距离为 d1 的倍数的记录放在同一组,在各组内进行直接插入排序;
- 然后取第二个步长 d2 < d1,重复上述过程,直到所取到的 dt = 1,即所有记录已放在同一组中,再进行直接插入排序,由于此时已经具有较好的局部有序性,故可以很快得到最终结果。
| [ 初始关键字 ] | 49 | 38 | 65 | 97 | 76 | 13 | 27 | 49’ | 55 | 04 |
|---|---|---|---|---|---|---|---|---|---|---|
| 交换 | 49 | 13 | ||||||||
| 交换 | 38 | 27 | ||||||||
| 交换 | 65 | 49’ | ||||||||
| 交换 | 97 | 55 | ||||||||
| 交换 | 76 | 04 | ||||||||
| 一趟排序结果 | 13 | 27 | 49’ | 55 | 04 | 49 | 38 | 65 | 97 | 76 |
| 55和38交换 | 13 | 55 | 38 | 76 | ||||||
| 27和04交换 | 27 | 04 | 65 | |||||||
| 49’ | 49 | 97 | ||||||||
| 二趟排序结果 | 13 | 04 | 49’ | 38 | 27 | 49 | 55 | 65 | 97 | 76 |
| 三趟排序结果 | 04 | 13 | 27 | 38 | 49’ | 49 | 55 | 65 | 76 | 95 |

框架:(注意元素下标从1开始)
void ShellSort(ElemType[] A, int n) {for (int dk = n/2; dk >= 1; dk = dk/2) { // 步长变化for (int i = dk+1; i <= n; ++i) { // 对子表进行直接插入排序if (A[i] < A[i-dk]) { // 需将A[i]插入有序增量子表A[0] = A[i]; // A[i]暂存至A[0],不需要另外定义temp变量for (int j = i-dk; j > 0 && A[0] <A[j]; j -= dk) { // 记录后移,查找插入位置A[j+dk] = A[j];}A[j+dk] = A[0]; // 复制到插入位置}}}
}
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:时间复杂度依赖于增量序列的函数,当表长 n 在某个特定范围时,希尔排序的时间复杂度约为 O(n1.3),在最坏情况下的时间复杂度为 O(n2)。
- 稳定性:当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序,因此希尔排序是一种不稳定的排序方法。如上49和49’的相对次序已经发生变化。
- 适用性:仅适用于线性表为顺序存储的情况。
1.2 交换类排序
交换是指,根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置。
1.2.1 冒泡排序(*)
冒泡排序:从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即A[i-1] > A[i]),则交换它们,直到序列比较完。
不同于直接插入排序,冒泡排序中所产生的有序子序列一定是全局有序的,也就是说,有序子序列中的所有元素的关键字一定小于或大于无序子序列中所有元素的关键字,这样每趟排序都会将一个元素放置到其最终的位置上。冒泡排序可用于链表。
从后往前两两比较:
- 第一趟结果:将最小的元素交换到待排序列的第一个位置(或将最大的元素交换到待排序列的最后一个位置)
- 下一趟:前一趟确定的最小元素不再参与比较,将待排序列中的最小元素(或最大元素)放到序列的最终位置;
- 重复以上步骤,最多 n-1 趟冒泡就能把所有元素排好序。
- 第一趟:27<49’,不交换;13<27,不交换;76>13,交换;97>13,交换;65>13,交换;38>13,交换;49>13,交换。
- 第二趟:27<49’,不交换;76>27,交换;97>27,交换;65>27,交换;38>27,交换;49>27,交换。
- …
| [ 初始关键字 ] | 49 | 38 | 65 | 97 | 76 | 13 | 27 | 49’ |
|---|---|---|---|---|---|---|---|---|
| 第1趟结束后 | 13 | 49 | 38 | 65 | 97 | 76 | 27 | 49’ |
| 第2趟结束后 | 13 | 27 | 49 | 38 | 65 | 97 | 76 | 49’ |
| 第3趟结束后 | 13 | 27 | 38 | 49 | 49’ | 65 | 97 | 76 |
| 第4趟结束后 | 13 | 27 | 38 | 49 | 49’ | 65 | 76 | 97 |
| 第5趟结束后 | 13 | 27 | 38 | 49 | 49’ | 65 | 76 | 97 |
| 第6趟结束后 | 13 | 27 | 38 | 49 | 49’ | 65 | 76 | 97 |
| 第7趟结束后(最终状态) | 13 | 27 | 38 | 49 | 49’ | 65 | 76 | 97 |
框架:(注意元素下标从0开始)
void BubbleSort(ElemType[] A, int n) {for (int i = 0; i < n; i++) {boolean flag = false; // 表示本趟冒泡是否发生交换的标志for (int j = n-1; j > i; j--) { // 一趟冒泡过程,从后往前if (A[j-1] > A[j]) { // 若为逆序swap(A[j-1], A[j]); // 交换flag = true;}}if (!flag) return; // 本趟遍历后没有发生交换,说明表已经有序}
}
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:
- 最好情况:当初始序列有序时,显然第一趟冒泡后 flag 仍然为 false(本趟冒泡没有元素交换),从而直接跳出循环,比较次数为 n-1,移动次数为0,此时时间复杂度为 O(n);
- 最坏情况:当初始序列逆序时,需要进行 n-1 趟排序,第 i 趟排序要进行 n-i 次关键字的比较,而且每次比较后都必须移动元素3次来交换元素位置(swap),此时时间复杂度为 O(n2)。
- 平均情况:时间复杂度为 O(n2)。
- 稳定性:由于 i > j 且 A[i] = A[j] 时不会发生交换,因此冒泡排序是一种稳定的排序方法。
1.2.2 快速排序(**)
快速排序的基本思想基于分治法。
- 在待排序表 L[1…n] 中任取一个元素 privot 作为枢轴(或基准,通常取首元素),通过一趟排序将待排序表划分为独立的两部分 L[1…k-1] 和 L[k+1…n],使得 L[1…k-1] 中的所有元素小于 privot,L[k+1…n] 中的所有元素大于 privot,则 privot 放在了其最终位置 L(k) 上,这个过程称为一趟快速排序(或一趟划分),一趟快速排序的过程是一个交替搜索和交换的过程。
- 分别递归地对 L[1…k-1] 和 L[k+1…n] 重复上述过程,直至每部分内只有一个元素或空为止,则所有元素放在了其最终位置上。
在快速排序中并不产生有序子序列,但每趟排序后会将枢轴(基准)元素放到其最终位置上。
快排过程:(low = 0…j,L[low] <= privot;high = n-1…i,L[high] >= privot)
| [ 关键字 ] | 49 | 38 | 65 | 97 | 76 | 13 | 27 | 49’ |
|---|---|---|---|---|---|---|---|---|
| [ 关键字 ] | 49 | 38 | 65 | 97 | 76 | 13 | 27 | 49’ |
| 交换 | privot / low | high | ||||||
| [ 关键字 ] | 27 | 38 | 65 | 97 | 76 | 13 | 49’ | |
| 交换 | low | high | ||||||
| [ 关键字 ] | 27 | 38 | 97 | 76 | 13 | 65 | 49’ | |
| 交换 | low | high | ||||||
| [ 关键字 ] | 27 | 38 | 13 | 97 | 76 | 65 | 49’ | |
| 交换 | low | high | ||||||
| [ 关键字 ] | 27 | 38 | 13 | 【49】 | 76 | 97 | 65 | 49’ |
| privot / low / high | ||||||||
| [ 关键字 ] | 27 | 38 | 13 | 【49】 | 76 | 97 | 65 | 49’ |
| 分别递归 | privot / low1 | high1 | privot / low2 | high2 | ||||
| [ 关键字 ] | 13 | 38 | 【49】 | 49’ | 97 | 65 | ||
| low1 | high1 | low2 | high2 | |||||
| [ 关键字 ] | 13 | 【27】 | 38 | 【49】 | 49’ | 65 | 97 | |
| privot / low1 / high1 | low2 | high2 | ||||||
| [ 关键字 ] | 13 | 【27】 | 38 | 【49】 | 49’ | 65 | 【76】 | 97 |
| privot / low2 / high2 |

框架:(注意元素下标从0开始)
void QuickSort(ElemType[] A, int low, int high) {if (low < high) { // 递归终止条件// 获取基准元素的最终位置用于划分满足条件的两个子表int privot_pos = Partition(A, low, high);// 对左右子表进行递归快排QuickSort(A, low, privot_pos-1);QuickSort(A, privot_pos+1, high);}
}int Partition(ElemType A[], int low, int high) { // 一趟划分ElemType privot = A[low]; // 取首元素作为基准while (low < high) {while (low < high && A[high] >= privot) --high; // 从后往前寻找小于privot的元素A[low] = A[high]; // 将比privot小的元素移动到左端while (low < high && A[low] <= privot) ++low; // 从前往后寻找大于privot的元素A[high] = A[low]; // 将比privot大的元素移动到右端}A[low] = privot; // 基准元素privot放到最终位置return low; // 返回基准元素的最终位置
}
- 空间效率:需要借助一个递归工作栈来保存每层递归调用的必要信息,其容量应与递归调用的最大深度一致。
- 最好情况:O(log2n);
- 最坏情况:要进行 n-1 次递归调用,所以栈的深度为 O(n);
- 平均情况:栈的深度为 O(log2n)。
- 时间效率:快速排序的运行时间与划分是否对称有关。
- 最好情况:Partition() 做到最平衡的划分,得到的两个子问题的大小都不可能大于 n/2,此时时间复杂度为 O(nlog2n)。
- 最坏情况:两个区域分别包含 n-1 个元素和 0 个元素时,这种最大限度的不对称性若发生在每层递归上,即对应出事排序表基本有序或基本逆序时,此时的时间复杂度为 O(n2)。
- 平均情况:运行时间与最好情况下的运行时间很接近。快速排序是所有内部排序算法中平均性能最优的排序算法。
- 稳定性:在划分算法中,若右端区间有两个关键字相同,且均小于基准值的记录,则在交换到左端区间后,它们的相对位置会发生变化,所以快速排序是一种不稳定的排序方法。如 L = {3, 2, 2} 在经过一趟排序后 L = {2, 2, 3},最终排序序列也是 L = {2, 2, 3},显然2与2的相对次序已经发生了变化。
1.3 选择类排序
每一趟(如第 i 趟)在后面 n-i+1(i=1,2,…,n-1)个待排序元素中选择关键字最小的元素,作为有序子序列的第 i 个元素,直到第 n-1 趟做完,待排序元素只剩下1个,就不用再选了。
1.3.1 简单选择排序(*)
假设排序表为 L[1…n],第 i 趟排序即从 L[i…n] 中选择关键字最小的元素与 L(i) 交换,每一堂排序可以确定一个元素的最终位置,这样经过 n-1 趟排序就可以使得整个排序表有序。简单选择排序可以用于链表。

框架:(注意元素下标从0开始)
void SelectSort(ElemType[] A, int n) {for (int i = 0; i < n-1; i++) { // 一共进行n-1趟int min = i; // 记录最小元素的下标for (int j = i+1; j < n; j++) { // 获取最小元素的位置if (A[j] < A[min]) min = j;}if (min != i) swap(A[i], A[min]); // 封装的swap()共移动元素3次}
}
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:元素移动的操作次数很少,不会超过 3(n-1) 次。
- 最好情况:元素移动0次,此时对应的表已经有序,但元素间比较的次数与序列的初始状态无关,始终是 n(n-1)/2 次,此时时间复杂度为 O(n2)。
- 稳定性:在第 i 趟找到最小元素后,和第 i 个元素交换,可能会导致第 i 个元素与其含有相同关键字元素的相对位置发生改变,因此简单选择排序是一种不稳定的排序方法。如 L = {2, 2, 1} 在经过一趟排序后 L = {1, 2, 2},最终排序序列也是 L = {1, 2, 2},显然2与2的相对次序已经发生了变化。
1.3.2 堆排序(*)
堆的定义如下,n 个关键字序列 L[1…n] 称为堆,当且仅当该序列满足
- L(i) >= L(2i) 且 L(i) >= L(2i+1) 或
- L(i) <= L(2i) 且 L(i) <= L(2i+1) (1 <= i <= ⌊ n / 2 ⌋ \lfloor n/2 \rfloor ⌊n/2⌋)
可以将该一维数组视为一颗完全二叉树。
- 满足条件1的堆称为大根堆(大顶堆),大根堆的最大元素存放在根结点,且其任一非根结点的值小于等于其双亲结点值。
- 满足条件2的堆称为小根堆(小顶堆),小根堆的最小元素存放在根结点,且其任一非根结点的值大于等于其双亲结点值。
二叉搜索树BST:左子结点值 <= 根结点值 <= 右子结点值
大根堆(完全二叉树):根结点值 >= 左、右子结点值
小根堆(完全二叉树):根结点值 <= 左、右子结点值
- 构建大顶堆:
首先,将待排序序列视为一个完全二叉树结构(通常以数组形式存储),从最后一个非叶子结点开始(即最后一个元素的父结点)向上调整堆结构。对于每个结点 i,检查其子结点 2i 和 2i+1(假设下标从0开始),如果当前结点的值小于其任一子结点的值,则交换两者的位置,然后继续对被交换到的子结点执行同样的操作,直到该子树满足大顶堆特性:每个结点的值都大于或等于其子结点的值。 - 交换堆顶元素与末尾元素并缩小堆大小:
将堆顶元素(即整个数组中的最大元素)与数组的最后一个元素交换位置,这样就确保了最大的元素已经被放到正确的位置上。然后,将堆的大小减1,忽略已排序的最大元素,并对剩余元素重新构建大顶堆。 - 重复调整堆与交换元素:
重复步骤1和步骤2,每次都将当前堆顶元素(当前未排序部分的最大元素)放到正确的位置上,然后对剩余元素重建堆。这个过程一直持续到堆的大小减小到1为止,此时整个数组已经按照从大到小的顺序排列完成。

堆排序框架(注意元素下标从1开始):
void HeapSort(ElemType[] A, int len) {BuildMaxHeap(A, len); // 初始建堆for (int i = len; i > 1; i--) { // n-1趟的交换和建堆过程Swap(A[i], A[1]); // 输出堆顶元素,并和堆底元素交换HeadAdjust(A, 1, i-1); // 调整,把剩余i-1个元素整理成堆}
}
建立大根堆的算法(注意元素下标从1开始):
void BuildMaxHeap(ElemType[] A, int len) { // 从最后一个非叶子节点开始逐个向上构建整个数组的大根堆结构for (int i = len/2; i > 0; i--) // 从后往前调整所有非终端结点A[len/2...1],即从序列末尾开始向前遍历HeadAdjust(A, i, len);
}
void HeadAdjust(ElemType[] A, int k, int len) { // 调整A[k]为根的子树A[0] = A[k]; // 暂存子树的根结点for (int i = 2*k; i <= len; i++) { // 沿key较大的子结点向下筛选if (i < len && A[i] < A[i+1]) i++; // 此处i<len保证了i+1<=len不会溢出,若左右子结点值相同,则优先和左子结点交换,if (A[0] >= A[i]) { // 根结点值大于等于左右子结点中的较大值,符合大根堆要求,调整结束break;} else { // 根节点值小于左右子结点中的较大值,不符合大根堆要求,继续调整A[k] = A[i]; // 将左右子结点值较大的结点A[i]调整到双亲结点(根结点)上k = i; // 修改k值,继续向下调整以左右子结点值较大的结点为根的子树}}A[k] = A[0]; // 将暂存的子树根结点值(即原A[k])放到正确的位置上,以保证经过调整后该子树满足大根堆特性
}
调整时间与树高有关,为O(h)。在建含 n 个元素的堆时,关键字的比较总次数不超过 4n,时间复杂度为 O(n)。
堆也支持插入操作:对堆进行插入操作时,先将新结点放在堆的末尾,再对这个新结点向上执行调整操作。
- 空间效率:仅使用常数个辅助单元,空间复杂度为 O(1)。
- 时间效率:建堆时间为 O(n),之后有 n-1 次向下调整操作,每次调整的时间复杂度为 O(h),故在最好、最坏和平均情况下,堆排序的时间复杂度为 O(nlog2n)。
- 稳定性:进行筛选时,有可能把后面相同关键字的元素调整到前面,所以堆排序是一种不稳定的排序方法。如 L = {1, 2, 2},构造初始堆时可能将2交换到栈顶,此时 L = {2, 1, 2},最终排序序列为 L = {1, 2, 2},显然2与2的相对次序已经发生了变化。
1.4 归并排序
归并排序与上述基于交换、选择等排序的思想不一样,“归并”的含义是将两个或两个以上的有序表组合成一个新的有序表。
1.4.1 2路归并排序(*)
假定待排序表含有 n 个记录,则可将其视为 n 个有序的子表,每个子表的长度为1,然后两两归并,得到 ⌈ n / 2 ⌉ \lceil n/2 \rceil ⌈n/2⌉ 个长度为2或1的有序表;继续两两归并……如此重复,直到合并成一个长度为 n 的有序表为止,这种排序方法称为2路归并排序。
| [ 初始关键字 ] | [49] | [38] | [65] | [97] | [76] | [13] | [27] |
|---|---|---|---|---|---|---|---|
| 划分 | 【49 | 38】 | 【65 | 97】 | 【76 | 13】 | 【27】 |
| 一趟归并后 | 【38 | 49】 | 【65 | 97】 | 【13 | 76】 | 【27】 |
| 划分 | 【38 | 49 | 65 | 97】 | 【76 | 13 | 27】 |
| 二趟归并后 | 【38 | 49 | 65 | 97】 | 【13 | 27 | 76】 |
| 划分 | 【38 | 49 | 65 | 97 | 76 | 13 | 27】 |
| 三趟归并后 | 【13 | 27 | 38 | 49 | 65 | 76 | 97】 |

递归形式的2路归并排序是基于分治,递归框架:(注意元素下标从0开始)
ElemType[] B = new ElemType[n]; // 辅助数组B
void merge(ElemType[] A, int low, int mid, int high) { // 负责合并两个已排序的子数组// 表A的两段A[low...mid]和A[mid+1...high]各自有序int i, j, k; // i和j分别指向左右子序列的起始位置,k指向结果数组的当前位置for (k = low; k <= high; k++) B[k] = A[k]; // 将A中所有元素复制到B中for (i = low, j = mid+1, k = i; i <= mid && j <= high; k++) {if (B[i] <= B[j]) A[k] = B[i++]; // 比较B的左右两段中的元素,将较小的值复制到A中else A[k] = B[j++];}while (i <= mid) A[k++] = B[i++]; // 若第一个表未检测完,复制while (j <= high) A[k++] = B[j++]; // 若第二个表未检测完,复制
}void MergeSort(ElemType[] A, int low, int high) {if (low < high) {int mid = (low+high) / 2; // 从中间划分两个子序列MergeSort(A, low, mid); // 对左侧子序列进行递归归并排序MergeSort(A, mid+1, high); // 对右侧子序列进行递归排序Merge(A, low, mid high); // 整体归并}
}
- 空间效率:Merge() 操作中需要 n 个单元作为辅助空间,空间复杂度为 O(n)。此外,递归调用也会占用一定的栈空间,但在最优的情况下(即输入数组已经有序时),递归深度为log2n,所以这部分的空间复杂度为O(logn)。但考虑到实际应用中主要受限于临时数组的使用,通常认为二路归并排序的空间复杂度为 O(n)。
- 时间效率:每趟归并的时间复杂度为 O(n),共需要进行 ⌈ l o g 2 n ⌉ \lceil log_2 n \rceil ⌈log2n⌉ 趟归并,所以算法的时间复杂度为 O(nlog2n)。
- 稳定性:不会改变相同关键字记录的相对次序,二路归并排序是一种稳定的排序方法。
1.4.2 k路归并排序
每选出一个元素需要对比关键字 k-1 次,如 Min{Min{Min{p1, p2}, p3}, p4}。
一般而言,对 n 个元素进行 k 路归并排序时,排序的趟数 m 满足 km = n,从而 m = logkn,又考虑到 m 为整数,所以 m = ⌈ l o g k n ⌉ \lceil log_k n \rceil ⌈logkn⌉。
1.5 线性时间非比较类排序
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;
1.5.1 基数排序(*)
基数排序不基于比较和移动进行排序,而基于关键字各位的大小进行排序。基数排序时一种借助多关键字排序思想对单逻辑关键字进行排序的方法。
为实现多关键字排序,通常有两种方法:
- 最高位优先(MSD)法:按关键字位权重递减一次逐层划分成若干更小的子序列,最后将所有子序列依次连接成一个有序序列。
- 最低位优先(LSD)法:按关键字权重递增依次进行排序,最后形成一个有序序列。
通常采用链式基数排序:(以最低位优先为例)
-> 278 -> 109 -> 063 -> 930 -> 589 -> 184 -> 505 -> 269 -> 008 -> 083
每个关键字是1000以下的正整数,基数 r = 10,在排序过程中需借助10个链队列,每个关键字由3位子关键字构成 K1K2K3,分别代表百位、十位、各位,一共需要进行三趟“分配”和“收集”操作。
第一趟分配后:
| 链队列 | q[0] | q[1] | q[2] | q[3] | q[4] | q[5] | q[6] | q[7] | q[8] | q[9] |
|---|---|---|---|---|---|---|---|---|---|---|
| 队头 | 930 | 063 | 184 | 505 | 278 | 109 | ||||
| 083 | 008 | 589 | ||||||||
| 269 |
第一趟收集后:(个位有序)
-> 930 -> 063 -> 083 -> 184 -> 505 -> 278 -> 008 -> 109 -> 589 -> 269
第二趟分配后:
| 链队列 | q[0] | q[1] | q[2] | q[3] | q[4] | q[5] | q[6] | q[7] | q[8] | q[9] |
|---|---|---|---|---|---|---|---|---|---|---|
| 队头 | 505 | 930 | 063 | 083 | ||||||
| 008 | 269 | 184 | ||||||||
| 109 | 589 |
第二趟收集后:(十位、个位有序)
-> 505 -> 008 -> 109 -> 930 -> 063-> 269 -> 278 -> 083 -> 184-> 589
第三趟分配后:
| 链队列 | q[0] | q[1] | q[2] | q[3] | q[4] | q[5] | q[6] | q[7] | q[8] | q[9] |
|---|---|---|---|---|---|---|---|---|---|---|
| 队头 | 008 | 109 | 269 | 505 | 930 | |||||
| 063 | 184 | 278 | 589 | |||||||
| 083 |
第三趟收集后:(百位、十位、个位有序)
-> 008 -> 063 -> 083 -> 109 -> 184 -> 269 -> 278 -> 505 -> 589 -> 930

- 空间效率:一趟排序需要的辅助存储空间为 r(r 个队列:r 个队头指针和r 个队尾指针),但以后的排序中会重复使用这些队列,所以基数排序的空间复杂度为 O®。
- 时间效率:基数排序需要进行 d 趟分配和收集,一趟分配需要 O(n),一趟收集需要 O®,所以基数排序的时间复杂度为 O(d(n+r)),与序列的初始状态无关。
- 稳定性:按位排序时必须是稳定的。
基数排序擅长解决的问题:
- 数据元素可以方便地拆分为 d 组且 d 较小;
- 每组关键字的取值范围不大,即 r 较小;
- 数据元素个数 n 较大。
1.5.2 计数排序
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为 i 的元素出现的次数,存入 C[i];
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素 i 放在新数组的第 C[i] 项,每放一个元素就将 C[i] 减去1。

1.5.3 桶排序
桶排序是计数排序的升级版(将离散数值升级为连续区间)。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量;
- 使用的映射函数能够将输入的 n 个数据均匀的分配到 k 个桶中。
- 同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。理想情况:当输入的数据可以均匀的分配到每一个桶中。最坏情况:所有数据分入一个桶中。

2. 性能比较与应用
2.1 性能分析比较

2.2 应用
通常情况下,对排序算法的比较和应用应考虑以下情况:
- 选取排序方法需要考虑的因素
- 待排序的元素数目 n
- 元素本身信息量的大小
- 关键字的结构及其分布情况
- 稳定性的要求
- 语言工具的条件,存储结构及辅助空间的大小等
- 排序算法小结
- 若 n 较小,可以采用直接插入排序或简单选择排序。
- 由于直接插入排序所需的记录移动次数比简单选择排序多,所以当记录本身信息量较大时,选用简单选择排序。
- 若文件的初始状态已按关键字基本有序,则选用直接插入排序或冒泡排序。
- 若 n 较大,则应采用时间复杂度为 O(nlog2n) 的排序方法:快速排序、堆排序或归并排序。
- 快速排序被认为是目前基于比较的内部排序方法中最好的方法,当待排序的关键字随机分布时,快速排序的平均时间最短。
- 堆排序所需的辅助空间少于快速排序,而且不会出现快速排序可能出现的最坏情况,两种排序都不稳定。
- 若要求排序稳定且时间复杂度为 O(nlog2n),则可以选用归并排序,通常可以将归并排序和直接插入排序结合在一起使用。
- 基于比较的排序方法中,每次比较两个关键字的大小之后,仅出现两种可能得转移,因此可以用一颗二叉树来描述比较判定过程,由此得:当文件的 n 个关键字随机分布时,任何借助于“比较”的排序算法,至少需要 O(nlog2n) 的时间。
- 若 n 很大,记录的关键字位数较少且可以分解时,采用基数排序。
- 当记录本身信息量较大时,为避免耗费大量时间移动记录,可用链表作为存储结构。
- 若 n 较小,可以采用直接插入排序或简单选择排序。
3. 例题
3.1 归并排序 - 排序链表(148中等)
好厉害的写法。希望下次能自己写出来。T^T

1. 快慢指针取链表的中间结点,断开获得两段链表
2. 对左半段、右半段链表再分别使用递归进行归并排序
3. 按序合并1.中已排序的两段链表并返回
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
// 对链表进行自顶向下的归并排序
class Solution {public ListNode sortList(ListNode head) {if (head == null || head.next == null) return head;// 快慢指针取链表的中间结点ListNode slow = head;ListNode fast = head;while(fast.next != null&& fast.next.next != null){slow = slow.next;fast = fast.next.next;}// 分割链表ListNode head2 = slow.next;slow.next = null; // 断开!!// 递归排序并合并结果return merge(sortList(head), sortList(head2));}public ListNode merge(ListNode head1, ListNode head2) {ListNode fakeHead = new ListNode(0);ListNode t = fakeHead, t1 = head1, t2 = head2;// 逐结点比较,拼接两段链表使其升序while (t1 != null && t2 != null) {if (t1.val <= t2.val) {t.next = t1;t1 = t1.next;} else {t.next = t2;t2 = t2.next;}t = t.next;}// 拼接剩余部分if (t1 != null) t.next = t1;else if (t2 != null) t.next = t2;return fakeHead.next;}
}
fszhang - 递归分割的链表归并排序
3.2 快速排序 - 数组中的第K个最大元素(215中等)

每一轮快速排序,都会确定本轮基准值的最终位置。
本题求解的是top-k第k大元素,不管元素是否重复,即排序后的nums[n-k]。
class Solution {int quickselect(int[] nums, int l, int r, int k) {// 基准值已到达最终位置if (l == r) return nums[k];// 默认取左端点元素为基准值int x = nums[l], i = l - 1, j = r + 1;// 开始双指针快排while (i < j) {// 找到数组左侧比基准元素大的元素do i++; while (nums[i] < x);// 找到数组右侧比基准元素小的元素do j--; while (nums[j] > x);// 交换两个元素if (i < j){int tmp = nums[i];nums[i] = nums[j];nums[j] = tmp;}}// 退出循环时j <= i,基准值的最终位置为nums[j]if (k <= j) return quickselect(nums, l, j, k); // nums[l...k...j]else return quickselect(nums, j+1, r, k); // nums[j+1...k...r]}public int findKthLargest(int[] _nums, int k) {int n = _nums.length;return quickselect(_nums, 0, n-1, n-k); // 对nums[0...n-1]进行快速排序后返回nums[n-k]}
}
3.3 各大排序算法练习题 - 排序数组(912中等)
3.3.1 快速排序
本题可以用来练习各大排序算法。
好不容易手写出快排,超时了。好吧。超时的常规快排:
class Solution {public int[] sortArray(int[] nums) {int n = nums.length;quickSort(nums, 0, n-1);return nums;}private void quickSort(int[] nums, int low, int high) {if (low < high) {int privot_pos = partition(nums, low, high);quickSort(nums, low, privot_pos-1);quickSort(nums, privot_pos+1, high);}}private int partition(int[] nums, int low, int high) {int privot = nums[low];while (low < high) {while (nums[high] > privot) --high;while(nums[low] < privot) ++low;if (low < high) {int temp = nums[low];nums[low] = nums[high];nums[high] = temp;}}// high <= lownums[high] = privot;return high;}
}
双指针优化后的快排:(也可以随机化快排)
class Solution {public int[] sortArray(int[] nums) {int n = nums.length;quickSort(nums, 0, n - 1);return nums;}private void quickSort(int[] nums, int low, int high) {if (low >= high) return;int privot = nums[low];int i = low, j = high;while (i <= j) {while (nums[j] > privot) --j;while (nums[i] < privot) ++i;if (i <= j) {int temp = nums[i];nums[i] = nums[j];nums[j] = temp;i++;j--;}}// 退出循环时nums[low...j...i...high]quickSort(nums, low, j);quickSort(nums, i, high);}
}
杰瑞不想刷题 - 快速排序O(nlogn)
3.3.2 归并排序
class Solution {int[] temp;public int[] sortArray(int[] nums) {int n = nums.length;temp = new int[n]; // 临时结果数组mergeSort(nums, 0, n-1); // 对nums[0...n-1]做归并排序return nums;}private void mergeSort(int[] nums, int low, int high) {if (low >= high) return;int mid = (low + high) / 2; // nums[low...high]二等分为nums[low...mid]和nums[mid+1...high]mergeSort(nums, low, mid); // 递归对nums[low...mid]做归并排序mergeSort(nums, mid+1, high); // 递归堆nums[mid+1...high]做归并排序int i = low, j = mid + 1; // nums[low...mid]和nums[mid+1...high]已经有序,按序合并,结果保存至temp中int cnt = 0;while (i <= mid && j <= high) {if (nums[i] <= nums[j]) temp[cnt++] = nums[i++];else temp[cnt++] = nums[j++];}while (i <= mid) temp[cnt++] = nums[i++]; // nums[low...mid]的剩余部分while (j <= high) temp[cnt++] = nums[j++]; // nums[mid+1...high]的剩余部分for (int k = 0; k < high - low + 1; ++k) // temp[0...high-low+1]已有序,但本次需要返回nums[low...high]的引用,故赋值nums[k+low] = temp[k];}
}
总结
- 快速排序:快速排序基于分治思想来对序列进行排序。
- 选择基准元素:从待排序的数组或序列中选取一个元素作为基准 privot;
- 分区操作:将数组中的所有元素与基准进行比较,并根据比较结果重新排列它们的位置,基准被放置在了最终排序后它应该在的位置上,且基准左右两侧的元素分别都小于或大于基准。
- 递归处理:对基准左侧和右侧的子数组,分别重复以上两个步骤,直到子数组只剩下一个元素或者为空,此时整个数组就被完全排序了。
- 归并排序:归并排序利用了分治的思想来对序列进行排序。
- 分解:将待排序的序列不断地分成两半,直到每个子序列只剩下一个元素。此时,每个单元素的子序列都可视为有序序列。
- 解决:线性合并每一对相邻的有序子序列。
- 合并:通过递归的方式重复上述步骤,每次合并两个有序的子序列,直至最终得到整个原始序列的一个有序版本。
- 堆排序:堆排序使用二叉堆数据结构来对序列进行排序。
- 建堆:首先构建一个最大堆(对于升序排列)或最小堆(对于降序排列)。这是一个完全二叉树,其中父节点总是大于(最大堆)或小于(最小堆)其子节点。
- 排序:移除堆顶(根节点),将其与堆中最后一个元素交换位置,然后将剩余的元素调整为新的堆,重复此过程直到所有元素都被排序。
- 重建堆:每次移除堆顶元素后,都需要调整堆以维持堆的性质。这一过程通常被称为“堆化”(heapify),它确保即使在移除根节点后,剩下的树仍然是一个有效的堆。
参考资料
- 《王道考研系列2023年数据结构考研复习指导》
- clint-chan - 算法导论总复习
- xin猿意码 - 力扣不会刷?先来看看这些排序类题目
- Leetcode 题解 - 排序
撰写于2024年1月13日14时
相关文章:
【数据结构05】排序
系列文章目录 【数据结构05】排序 . 【算法思想04】二分查找 文章目录 系列文章目录[toc] 1. 基本思想与实现1.1 插入类排序1.1.1 直接插入排序(*)1.1.2 折半插入排序1.1.3 希尔排序(*) 1.2 交换类排序1.2.1 冒泡排序(…...

推荐系统的三道菜
推荐系统的本质就是在有太多展示内容的情况下,对内容的呈现进行排序。 它的排序依据主要有三个方面: 1. 用户信息 排序的主要依据就是用户感兴趣的程度。 要获知用户的兴趣点,就要搜集“用户信息”,比如用户的历史行为、身份信息、…...

ModuleNotFoundError: No module named XXX
我们在安装了某个包之后,还是提示找不到包 方法一: python -m pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple 方法二: conda install 包名 如果还是找不到包: 请检查环境:...
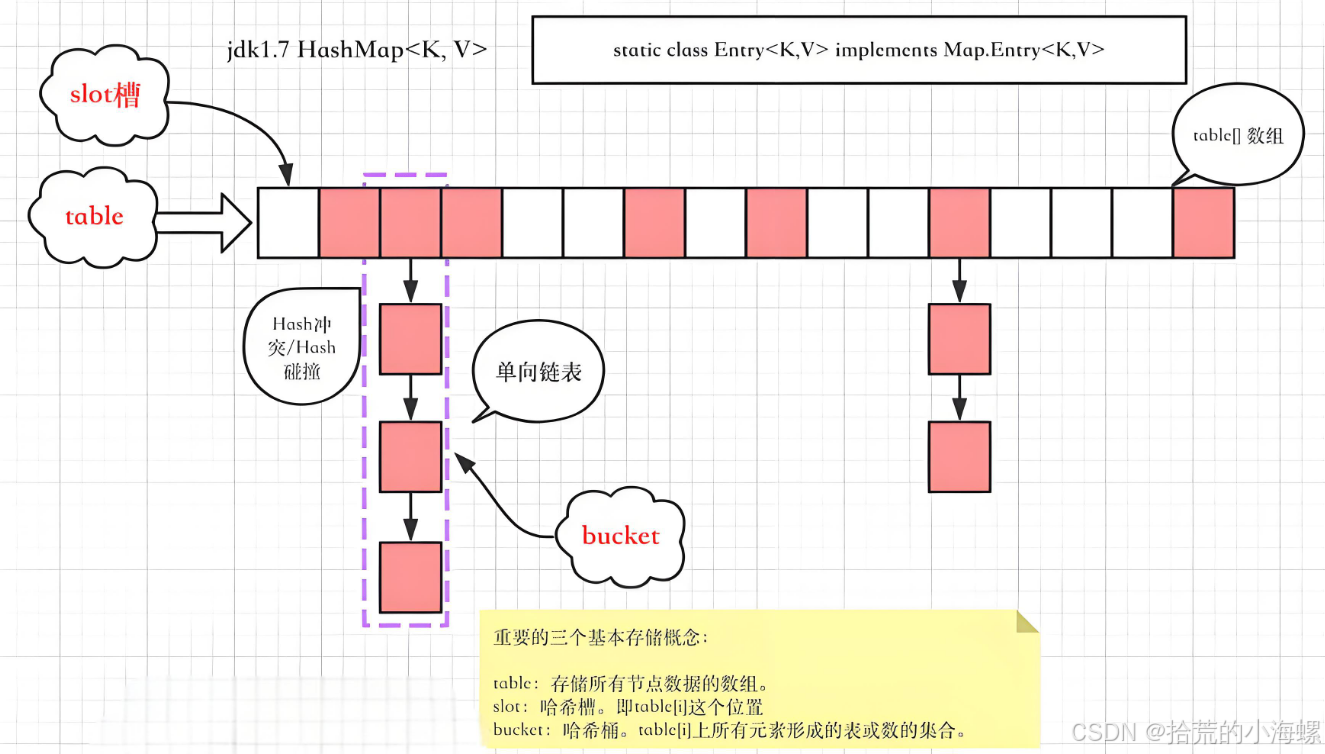
JAVA:HashMap在1.8做了哪些优化的详细解析
1、简述 HashMap 是 Java 中最常用的数据结构之一,它以键值对的形式存储数据,允许快速的插入、删除和查找操作。在 JDK 1.8 之前,HashMap 主要是基于数组加链表的结构实现的。然而,在面对大量哈希冲突时(即多个键的哈…...

jest使用__mocks__设置模拟函数不生效 解决方案
模拟文件 // __mocks__/axios.js const axios jest.fn(); axios.get jest.fn(); axios.get.mockResolvedValue({data: {undoList: [get data],}, }); export default axios; 测试文件 jest.mock(axios); import Axios from axios;test(mytest, () > {console.log("…...

javaEE-网络原理-1初识
目录 一.网络发展史 1.独立模式 2.网络互联 二.局域网LAN 1.基于网线直连: 2.基于集线器组件: 3.基于交换机组件: 4.基于交换机和路由器组件 编辑 三、广域网WAN 四、网络通信基础 1.ip地址 2.端口号: 3.协议 4.五…...

笔上云世界微服务版
目录 一、项目背景 二、项目功能 一功能介绍 三、环境准备 • 需要开发的端口 • Mysql 导入数据库 编辑 • Redis 编辑 • RabbitMQ 编辑 在创建blog虚拟主机(方法如下) • Nacos • Nginx 四、前端部署 五、后端部署 六、测试计划操作 一功能测试 二…...

linux安装redis及Python操作redis
目录 一、Redis安装 1、下载安装包 2、解压文件 3、迁移文件夹 4、编译 5、管理redis文件 6、修改配置文件 7、启动Redis 8、将redis服务交给systemd管理 二、Redis介绍 1、数据结构 ①字符串String ②列表List ③哈希Hash ④集合Set ⑤有序集合Sorted Set 2、…...

node.js内置模块之---stream 模块
stream 模块的作用 在 Node.js 中,stream 模块是一个用于处理流(stream)的核心模块。流是一种处理数据的抽象方式,允许程序处理大量数据时不会一次性将所有数据加载到内存中,从而提高性能和内存效率。通过流࿰…...

《learn_the_architecture_-_aarch64_exception_model》学习笔记
1.当发生异常时,异常级别可以增加或保持不变,永远无法通过异常来转移到较低的权限级别。从异常返回时,异常级别可能会降低或保持不变,永远无法通过从异常返回来移动到更高的权限级别。EL0级不进行异常处理,异常必须在比…...

【C++项目实战】贪吃蛇小游戏
一、引言 贪吃蛇,这款经典的电子游戏,自1976年诞生以来,一直受到全球玩家的喜爱。它的规则简单,玩法直观,但同时也充满了挑战性。在这篇文章中,我们将一起探索如何开发一个贪吃蛇游戏,无论是作为…...

Python基于matplotlib实现树形图的绘制
在Python中,你可以使用matplotlib库来绘制树形图(Tree Diagram)。虽然matplotlib本身没有专门的树形图绘制函数,但你可以通过组合不同的图形元素(如线条和文本)来实现这一点。 以下是一个简单的示例&#…...

【UE5 C++课程系列笔记】21——弱指针的简单使用
目录 概念 声明和初始化 转换为共享指针 打破循环引用 弱指针使用警告 概念 在UE C 中,弱指针(TWeakPtr )也是一种智能指针类型,主要用于解决循环引用问题以及在不需要强引用保证对象始终有效的场景下,提供一种可…...

【游戏设计原理】46 - 魔杖
幻想,人们可以通过多种形式来引发,比如文字,图片,绘画,语言等,但游戏与以上这些形式的区别,正如游戏与其他艺术形式的区别一样,游戏作为一种艺术和娱乐形式,其独特之处在…...
【路径跟踪】PIDMPC
路径跟踪(Path Tracking)是指在实际行驶过程中,根据预先规划好的路径进行控制,能够沿着设定的路径行驶。常见的路径跟踪算法包括基于模型的控制方法(如PID控制器)、模型预测控制(Model Predicti…...

Spring源码分析之事件机制——观察者模式(二)
目录 获取监听器的入口方法 实际检索监听器的核心方法 监听器类型检查方法 监听器的注册过程 监听器的存储结构 过程总结 Spring源码分析之事件机制——观察者模式(一)-CSDN博客 Spring源码分析之事件机制——观察者模式(二ÿ…...

热备份路由HSRP及配置案例
✍作者:柒烨带你飞 💪格言:生活的情况越艰难,我越感到自己更坚强;我这个人走得很慢,但我从不后退。 📜系列专栏:网路安全入门系列 目录 一,HSRP的相关概念二,…...
)
仿生的群体智能算法总结之三(十种)
群体智能算法是一类通过模拟自然界中的群体行为来解决复杂优化问题的方法。以下是30种常见的群体智能算法,本文汇总第21-30种。接上文 : 编号 算法名称(英文) 算法名称(中文) 年份 作者 1 Ant Colony Optimization (ACO) 蚁群优化算法 1991 Marco Dorigo 2 Particle Swar…...

CentOS 7系统 OpenSSH和OpenSSL版本升级指南
文章目录 CentOS 7系统 OpenSSH和OpenSSL版本升级指南环境说明当前系统版本当前组件版本 现存安全漏洞升级目标版本升级准备工作OpenSSL升级步骤1. 下载和解压2. 编译安装3. 配置环境 OpenSSH升级步骤1. 下载和解压2. 编译安装3. 创建systemd服务配置4. 更新SSH配置文件5. 设置…...

【专题】2024年出口跨境电商促销趋势白皮书报告汇总PDF洞察(附原数据表)
原文链接:https://tecdat.cn/?p38722 在当今全球化加速演进、数字经济蓬勃发展的大背景下,跨境电商行业正以前所未有的态势重塑国际贸易格局,成为各方瞩目的焦点领域。 根据亚马逊发布的《2024年出口跨境电商促销趋势白皮书》,…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

【安全篇】金刚不坏之身:整合 Spring Security + JWT 实现无状态认证与授权
摘要 本文是《Spring Boot 实战派》系列的第四篇。我们将直面所有 Web 应用都无法回避的核心问题:安全。文章将详细阐述认证(Authentication) 与授权(Authorization的核心概念,对比传统 Session-Cookie 与现代 JWT(JS…...
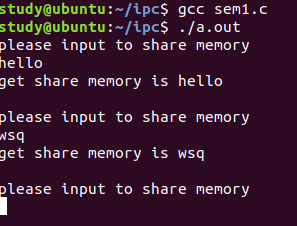
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...