spark汇总
目录
- 描述
- 运行模式
- 1. Windows模式
- 代码示例
- 2. Local模式
- 3. Standalone模式
- RDD
- 描述
- 特性
- RDD创建
- 代码示例(并行化创建)
- 代码示例(读取外部数据)
- 代码示例(读取目录下的所有文件)
- 算子
- DAG
- SparkSQL
- SparkStreaming
描述

Apache Spark 是用于大规模数据处理的统一分析引擎。它提供 Java、Scala、Python 和 R 中的高级 API,以及支持通用执行图的优化引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的Spark SQL 、用于机器学习的MLlib、用于图形处理的 GraphX 以及用于增量计算和流处理的结构化流。
1. Spark Core
Spark的核心,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
2. Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL对数据进行处理。
3. Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
4. Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
5. Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库。
运行模式
1. Windows模式
多用于本地测试,不需要虚拟机或服务器。
代码示例
WordCount.scala
package com.wunaiieq//1.导入SparkConf,SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {//2.构建SparkConf对象,并设置本地运行和程序的名称val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")//3.通过SparkConf对象构建SparkContext对象val sc = new SparkContext(conf)//4.读取文件,并生成RDD对象val fileRdd: RDD[String] = sc.textFile("data/words.txt")//5.将单词进行切割,得到一个存储全部单词的集合对象val wordsRdd: RDD[String] = fileRdd.flatMap(_.split(" "))//6.将单词转换为Tuple2对象("hello"->("hello",1))val wordAndOneRdd: RDD[(String, Int)] = wordsRdd.map((_, 1))//7.将元组的value按照key进行分组,并对该组所有的value进行聚合操作val resultRdd: RDD[(String, Int)] = wordAndOneRdd.reduceByKey(_ + _)//8.通过collect方法收集RDD数据val wordCount: Array[(String, Int)] = resultRdd.collect()//9.输出结果wordCount.foreach(println)}
}
log4j.properties
这个没什么说的直接复制用即可
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell/spark-sql log level to WARN. When running the
# spark-shell/spark-sql, the log level for these classes is used to overwrite
# the root logger's log level, so that the user can have different defaults
# for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
log4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN# Settings to quiet third party logs that are too verbose
log4j.logger.org.sparkproject.jetty=WARN
log4j.logger.org.sparkproject.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR# For deploying Spark ThriftServer
# SPARK-34128:Suppress undesirable TTransportException warnings involved in THRIFT-4805
log4j.appender.console.filter.1=org.apache.log4j.varia.StringMatchFilter
log4j.appender.console.filter.1.StringToMatch=Thrift error occurred during processing of message
log4j.appender.console.filter.1.AcceptOnMatch=false
2. Local模式
一台服务器或虚拟机搞定,所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。
# 进入spark根目录
cd /opt/module/spark/bin
# 运行视频spark-shell
./spark-shell
webUI
[atguigu@master bin]$ jps
2081 SparkSubmit
2206 Jps
[atguigu@master bin]$ netstat -anp|grep 2081
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
tcp6 0 0 192.168.16.100:42050 :::* LISTEN 2081/java
tcp6 0 0 :::4040 :::* LISTEN 2081/java
tcp6 0 0 192.168.16.100:35770 :::* LISTEN 2081/java
unix 2 [ ] STREAM CONNECTED 33071 2081/java
unix 2 [ ] STREAM CONNECTED 36801 2081/java
浏览器访问
http://192.168.16.100:4040/
spark-submit
以下为使用spark提交jar包示例
./spark-submit --master local[2] --class org.apache.spark.examples.SparkPi /opt/module/spark/examples/jars/spark-examples_2.12-3.1.1.jar 100| 参数 | 描述 |
|---|---|
--class | 要执行程序的主类,可以更换为自己写的应用程序的主类名称 |
--master local[2] | 部署模式,默认为本地模式;数字 2 表示分配的虚拟 CPU 核数量 |
spark-examples_2.12-3.2.1.jar | 运行的应用类所在的 jar 包,实际使用时可以设定为自己打的 jar 包 |
20 | 程序的入口参数,根据应用程序的需要,可以是任何有效的输入值 |
几种提交方式比较
| 工具 | 功能 | 特点 | 使用场景 |
|---|---|---|---|
bin/spark-submit | 提交 Java/Scala/Python/R 代码到 Spark 中运行 | 提交代码用 | 正式场合,正式提交 Spark 程序运行 |
bin/spark-shell | 提供一个 Scala 解释器环境,用来以 Scala 代码执行 Spark 程序 | 解释器环境,写一行执行一行 | 测试、学习、写一行执行一行、用来验证代码等 |
bin/pyspark | 提供一个 Python 解释器环境,用来以 Python 代码执行 Spark 程序 | 解释器环境,写一行执行一行 | 测试、学习、写一行执行一行、用来验证代码等 |
3. Standalone模式
Standalone是Spark自带的一个资源调度框架,它支持完全分布式,也支持HA

- Master角色:管理整个集群的资源,主要负责资源的调度和分配,并进行集群的监控等职责;并托管运行各个任务的Driver。如Yarn的ResourceManager。
- Worker角色:每个从节点分配资源信息给Worker管理,管理单个服务器的资源类,分配对应的资源来运行Executor(Task);资源信息包含内存Memory和CPU
Cores核数。如Yarn的NodeManager。- Driver角色,管理单个Spark任务在运行的时候的工作,如Yarn的ApplicationMaster “
- Executor角色,单个任务运行的时候的一堆工作者,干活的。它是集群中工作节点(Worker)中的一个JVM进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
1.负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
2.它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的
RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结
资源管理维度
集群资源管理者:Master
单机资源管理者:Worker任务计算维度
单任务管理者:Driver
单任务执行者:Executor
注:Executor运行于Worker进程内,由Worker提供资源供给它们运行
扩展:历史服务器HistoryServer(可选),Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
4. Yarn模式
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
5. 云服务模式(运行在云平台上)
Kubernetes(K8S)容器模式
Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境。容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是(K8S),而Spark也在新版本中支持了k8s部署模式。
6. Mesos
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter得到广泛使用,管理着Twitter超过30,0000台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用Mesos框架的并不多。
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |
RDD
描述
Spark RDD(Resilient Distributed Dataset,弹性分布式数据集)代表一个不可变、可分区、元素可并行计算的集合,是Spark进行数据处理的基本单元。
- 不可变性:RDD一旦创建,其数据就不可改变。对RDD的所有操作(如map、filter、reduce等)都会生成一个新的RDD,而不会修改原始RDD。这种不可变性使得RDD在分布式计算环境下非常稳定,避免了并发冲突。
- 可分区性:RDD可以分成多个分区(Partition),每个分区就是一个数据集片段。一个RDD的不同分区可以保存到集群中的不同节点上,从而可以在集群中的不同节点上进行并行计算。分区是Spark作业并行计算的基本单位,每个分区都会被一个计算任务处理,分区的数量决定了并行计算的粒度。
- 弹性:RDD具有弹性容错的特点。当运算中出现异常情况导致分区数据丢失或运算失败时,可以根据RDD的血统(Lineage)关系对数据进行重建。此外,RDD的数据可以保存在内存中,内存放不下时也可以保存在磁盘中,实现了存储的弹性。
特性
1. 分区(Partitions) 含义:RDD的数据被划分为多个分区,每个分区是一个数据块,分布在集群的不同节点上。 作用:每个分区会被一个计算任务处理,分区的数量决定了并行计算的粒度。用户可以在创建RDD时指定分区数,如果没有指定,Spark会根据集群的资源自动设置。
示例:从HDFS文件创建RDD时,默认分区数为文件的Block数。
2. 计算函数(Compute Function) 含义:RDD的计算方法会作用到每个分区上。 作用:当对RDD进行操作(如map、filter等)时,Spark会对每个分区应用这个函数。
示例:在map操作中,计算函数会对每个元素执行指定的转换逻辑。
3. 依赖关系(Dependencies) 含义:RDD之间存在依赖关系。 作用:在部分分区数据丢失时,Spark可以利用依赖关系重新计算丢失的数据,而不是重新计算整个RDD,提高了容错能力。
分类:依赖关系分为窄依赖(Narrow Dependency)和宽依赖(Wide
Dependency)。窄依赖指一个父RDD的分区最多被一个子RDD的分区使用;宽依赖指一个父RDD的分区被多个子RDD的分区使用。
4. 分区器(Partitioner,可选,只有kv型RDD才有) 含义:对于键值对(Key-Value)类型的RDD,可以指定一个分区器来决定数据的分区方式。
作用:分区器决定了数据在集群中的分布,影响并行计算的性能。
类型:Spark支持多种分区器,如HashPartitioner(基于哈希值分区)和RangePartitioner(基于范围分区)。
5. 优先位置(Preferred Locations,可选) 含义:RDD分区规划应当尽量靠近数据所在的服务器 作用:Spark在进行任务调度时,会优先将数据分配到其存储位置进行计算,减少数据传输开销,提高计算效率。
示例:对于HDFS文件,优先位置通常是文件块所在的节点。
RDD创建
1. 通过并行化集合创建,将本地集合对象转分布式RDD
val sc = new SparkContext(conf)
val rdd1:RDD[Int]=sc.parallelize(List(1, 2, 3, 4, 5, 6), 3)
rdd1.glom().collect()
makeRdd()创建,本质上也是使用sc.parallelize(…)
def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T] = withScope {parallelize(seq, numSlices)
}
2. 读取外部数据源 (比如:读取文件 )
//通过SparkConf对象构建SparkContext对象
val sc = new SparkContext(conf)
//读取文件
val fileRdd:RDD[String] = sc.textFile("data/words.txt")
程序执行入口:SparkContext对象
Spark RDD 编程的程序入口对象是SparkContext对象(Scala、Python、Java都是如此)
只有构建出SparkContext, 基于它才能执行后续的API调用和计算
本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来。
代码示例(并行化创建)
package com.wunaiieq//1.导入SparkConf类、SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CreateByParallelize {def main(args: Array[String]): Unit = {//2.构建SparkConf对象。并设置本地运行和程序的名称,*表示使用全部cpu内核,可以指定数量val sparkconf = new SparkConf().setMaster("local[*]").setAppName("CreateRdd1")//3.构建SparkContext对象val sparkContext = new SparkContext(sparkconf)//4.通过并行化创建RDD对象:将本地集合->分布式的RDD对象,如果不指定分区,则根据cpu内核数进行自动分配val rdd: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8),3)//5.输出默认的分区数println("默认分区数:"+rdd.getNumPartitions)//已经指定为3//6.collect方法:将rdd对象中每个分区的数据,都发送到Driver,形成一个Array对象val array1: Array[Int] = rdd.collect()println("rdd.collect()="+array1.mkString(","))//7.显示出rdd对象中元素被分布到不同分区的数据信息val array2: Array[Array[Int]] = rdd.glom().collect()println("rdd.glom().collect()的内容是:")for(eleArr<- array2){println(eleArr.mkString(","))}}
}
代码示例(读取外部数据)
package com.wunaiieq//1.导入SparkConf,SparkContext类
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object CreateByTextFile {def main(args: Array[String]): Unit = {//2.构建SparkConf对象,并设置本地运行和程序名val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("textFile")//3.通过sparkconf创建SparkContext对象val sparkContext = new SparkContext(sparkConf)//4.通过textFile读取文件//4.1.读取hdfs分布式文件系统上的文件
// val hdfsRdd: RDD[String] = sparkContext.textFile("hdfs://192.168.16.100:9820/input/data.txt")
// val hdfsResult: Array[String] = hdfsRdd.collect()
// println("hdfsRdd分区数"+hdfsRdd.getNumPartitions)
// println("hdfsRdd内容"+hdfsResult.mkString(","))//4.2读取本地文件val localRdd1: RDD[String] = sparkContext.textFile("data/words.txt")println("localRdd1分区数"+localRdd1.getNumPartitions)println("localRdd1内容"+localRdd1.collect().mkString(","))//5.设置最小分区数val localRdd2: RDD[String] = sparkContext.textFile("data/words.txt",3)println("localRdd2分区数"+localRdd2.getNumPartitions)println("localRdd2内容"+localRdd2.collect().mkString(","))//6.最小分区数设置是一个参考值,Spark会有自己的判断,值太大Spark不会理会val localRdd3: RDD[String] = sparkContext.textFile("data/words.txt", 100)println("localRdd3的分区数"+localRdd3.getNumPartitions)}
}代码示例(读取目录下的所有文件)
package com.wunaiieq//1.导入类
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object CreateByWholeTextFiles {def main(args: Array[String]): Unit = {//2.构建SparkConf对象,并设置本地运行和程序名称val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WholeTextFiles")//3.使用sparkconf对象构建SparkContet对象val sparkContext = new SparkContext(sparkConf)//5.读取指定目录下的小文件val rdd: RDD[(String, String)] = sparkContext.wholeTextFiles("data")val tuples: Array[(String, String)] = rdd.collect()tuples.foreach(ele=>println(ele._1,ele._2))//6.获取小文件中的内容val array: Array[String] = rdd.map(_._2).collect()println("---------------------------")println(array.mkString("|"))//4.关闭sparkContext对象sparkContext.stop()}
}算子
详见如下专题RDD算子集合
DAG
详见如下专题DAG专题
SparkSQL
详见如下专题SparkSQL专题
SparkStreaming
详见如下专题SparkStreaming专题
相关文章:
spark汇总
目录 描述运行模式1. Windows模式代码示例 2. Local模式3. Standalone模式 RDD描述特性RDD创建代码示例(并行化创建)代码示例(读取外部数据)代码示例(读取目录下的所有文件) 算子DAGSparkSQLSparkStreaming…...

【Rust自学】11.5. 在测试中使用Result<T, E>
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 11.5.1. 测试函数返回值为Result枚举 到目前为止,测试运行失败的原因都是因为触发了panic,但可以导致测试失败的…...

Sping Boot教程之五十四:Spring Boot Kafka 生产者示例
Spring Boot Kafka 生产者示例 Spring Boot 是 Java 编程语言中最流行和使用最多的框架之一。它是一个基于微服务的框架,使用 Spring Boot 制作生产就绪的应用程序只需很少的时间。Spring Boot 可以轻松创建独立的、生产级的基于 Spring 的应用程序,您可…...

设计模式-结构型-组合模式
1. 什么是组合模式? 组合模式(Composite Pattern) 是一种结构型设计模式,它允许将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得客户端对单个对象和组合对象的使用具有一致性。换句话说,组合模式允…...

基于Java的推箱子游戏设计与实现
基于Java的推箱子游戏设计与实现 摘 要 社会在进步,人们生活质量也在日益提高。高强度的压力也接踵而来。社会中急需出现新的有效方式来缓解人们的压力。此次设计符合了社会需求,Java推箱子游戏可以让人们在闲暇之余,体验游戏的乐趣。具有…...

Spark vs Flink分布式数据处理框架的全面对比与应用场景解析
1. 引言 1.1 什么是分布式数据处理框架 随着数据量的快速增长,传统的单机处理方式已经无法满足现代数据处理需求。分布式数据处理框架应运而生,它通过将数据分片分布到多台服务器上并行处理,提高了任务的处理速度和效率。 分布式数据处理框…...

python_excel列表单元格字符合并、填充、复制操作
读取指定sheet页,根据规则合并指定列,填充特定字符,删除多余的列,每行复制四次,最后写入新的文件中。 import pandas as pd""" 读取指定sheet页,根据规则合并指定列,填充特定字…...

nums[:]数组切片
问题:给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 使用代码如下没有办法通过测试示例,必须将最后一行代码改成 nums[:]nums[-k:]nums[:-k]切片形式: 原因:列表的切片操作 …...

【Arthas 】Can not find Arthas under local: /root/.arthas/lib 解决办法
报错 [INFO] JAVA_HOME: /opt/java/openjdk [INFO] arthas-boot version: 4.0.4 [INFO] Found existing java process, please choose one and input the serial number of the process, eg : 1. Then hit ENTER. [1]: 12 org.springframework.boot.loader.JarLauncher 1 [ER…...

录用率23%!CCF推荐-B类,Early Access即可被SCI数据库收录,中美作者占比过半
International Journal of Human-Computer Interaction(IJHCI)创刊于1989年,由泰勒-弗朗西斯(Taylor & Francis, Inc.)出版,主要发表关于交互式计算(认知和人体工程学)、数字无障…...

IP 地址与蜜罐技术
基于IP的地址的蜜罐技术是一种主动防御策略,它能够通过在网络上布置的一些看似正常没问题的IP地址来吸引恶意者的注意,将恶意者引导到预先布置好的伪装的目标之中。 如何实现蜜罐技术 当恶意攻击者在网络中四处扫描,寻找可入侵的目标时&…...

Vue_API文档
Vue API风格 Vue 的组件可以按两种不同的风格书写:选项式 API(Vue2) 和组合式 API(Vue3) 大部分的核心概念在这两种风格之间都是通用的。熟悉了一种风格以后,你也能够很快地理解另一种风格 选项式API(Opt…...

WebSocket 设计思路
WebSocket 设计思路 1. 核心结构体 1.1 Manager (管理器) // Manager 负责管理所有WebSocket连接 type Manager struct {clients sync.Map // 存储所有客户端连接broadcast chan []byte // 广播消息通道messages chan Message // 消息处理通道config *config.WebSo…...

Jenkins持续集成与交付安装配置
Jenkins 是一款开源的持续集成(CI)和持续交付(CD)工具,它主要用于自动化软件的构建、测试和部署流程。为项目持续集成与交付功能强大的应用。下面我们来介绍下它的安装与配置。 环境准备 更新系统组件(这…...

ESP32作为Wi-Fi AP模式的测试
一、AP模式的流程 初始化阶段 (Init Phase): 1.1: Main task(主任务)初始化LwIP(轻量级TCP/IP协议栈)。 ESP_ERROR_CHECK(esp_netif_init()); 1.2: 创建和初始化Event task(事件任务)。 ESP_ERROR_CHECK…...

【爬虫】单个网站链接爬取文献数据:标题、摘要、作者等信息
源码链接: https://github.com/Niceeggplant/Single—Site-Crawler.git 一、项目概述 从指定网页中提取文章关键信息的工具。通过输入文章的 URL,程序将自动抓取网页内容 二、技术选型与原理 requests 库:这是 Python 中用于发送 HTTP 请求…...
全面概述和知识要点(3万字长文))
Android RIL(Radio Interface Layer)全面概述和知识要点(3万字长文)
在Android面试时,懂得越多越深android framework的知识,越为自己加分。 目录 第一章:RIL 概述 1.1 RIL 的定义与作用 1.2 RIL 的发展历程 1.3 RIL 与 Android 系统的关系 第二章:RIL 的架构与工作原理 2.1 RIL 的架构组成 2.2 RIL 的工作原理 2.3 RIL 的接口与协议…...

leetcode_2816. 翻倍以链表形式表示的数字
2816. 翻倍以链表形式表示的数字 - 力扣(LeetCode) 搜先看到这个题目 链表的节点那么多 已经远超longlong能够表示的范围 那么暴力解题 肯定是不可以的了 我们可以想到 乘法运算中 就是从低位到高位进行计算 刚开始 我想先反转链表 然后在计算 然后在进…...

【论文阅读】MAMBA系列学习
Mamba code:state-spaces/mamba: Mamba SSM architecture paper:https://arxiv.org/abs/2312.00752 背景 研究问题:如何在保持线性时间复杂度的同时,提升序列建模的性能,特别是在处理长序列和密集数据(如…...

MySQL教程之:批量使用mysql
在前几节中,您以交互方式使用mysql输入语句并查看结果。您也可以运行mysql批量模式。为此,请将要运行的语句放在文件中,然后告诉mysql从文件中读取其输入: $> mysql < batch-file 如果您在Windows下运行mysql,…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...
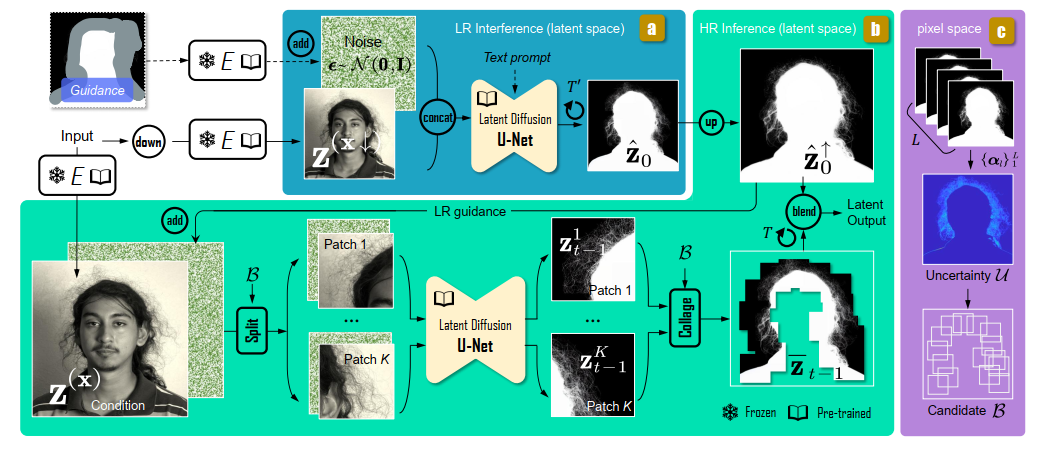
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...