某政务行业基于 SeaTunnel 探索数据集成平台的架构实践
分享嘉宾:某政务公司大数据技术经理 孟小鹏
编辑整理:白鲸开源 曾辉
导读:本篇文章将从数据集成的基础概念入手,解析数据割裂给企业带来的挑战,阐述数据集成的重要性,并对常见的集成场景与工具进行阐述,最后介绍了Apache SeaTunnel在应对技术挑战的架构演进。
包括以下几方面内容:
- 什么是数据集成
- 为什么要做数据集成?
- 常见的数据集成工具
- 离线场景的数据集成工具分析
- 离线 + 实时场景的数据集成需求与挑战
- Apache SeaTunnel 简介
什么是数据集成?
在当今的数字化时代,数据被称为“新石油”,其价值在于通过分析和应用为企业提供决策支持。然而,许多企业面临的一个共同挑战是数据割裂——数据分散在不同的业务线或系统中,导致信息孤岛、效率低下等问题的产生。

拿数据集成到底是什么呢?数据集成作为解决上述问题的重要手段,主要是通过将来自不同来源的数据标准化、清洗并统一整合成视图或存储形式,为企业的数据治理、分析和业务使用提供坚实的基础。
为什么要做数据集成?
在企业发展的早期,通常存在多个独立发展的业务线,比如 APP 1、APP 2 和 APP 3。

这些业务线在早期阶段缺乏统一的规划,导致各业务线分别维护自己的数据存储,形成了割裂的场景。独立的数据系统之间缺乏连接与协同,形成了数据“烟囱效应”和“信息孤岛”。这些问题的存在直接影响了企业的运营效率和决策能力,并引发了一系列具体挑战。
数据割裂带来的问题
决策数据的缺失
信息孤岛使得高层管理人员无法获取完整的数据视图,决策依据不完整,可能导致错误的决策。
资源浪费
多个业务线独立存储数据,增加了存储成本。同时,分散的数据管理也增加了复杂性和运维难度。
用户体验的割裂
在割裂的系统下,难以为用户提供一致性的服务。例如,不同APP中的数据无法同步,导致用户体验不佳。
数据安全隐患
数据重复存储(如多APP中都存储用户表)增加了数据丢失和泄露的风险。
数据流通效率低下
割裂的数据使企业难以实现高效的数据流通和跨业务的协同,最终导致整体业务效率的下降。
数据集成的必要性
为了应对以上挑战,需要通过数据集成工具将原本割裂的数据统一汇聚到一个中心化的存储位置,如数据中心或数据湖。

这种统一的存储方式可以带来以下优势:
支持多维度分析
例如,在电子商务场景下,构建用户忠诚度模型可能需要综合以下数据来源:
- 商品详情
- 用户满意度评分
- 用户活跃度数据
如果数据割裂,难以进行统一统计。而通过数据集成工具,能够将所有数据汇聚到一个仓库中,以实现多维度分析。
提升业务效率
通过统一的数据存储,可以减少数据重复,优化资源使用,并为业务提供高效的数据支持。
增强数据安全
数据的集中存储和统一管理能够降低数据泄露的风险,并简化安全管控。
优化用户体验
数据的统一可以实现跨业务的协同,为用户提供一致性更高的服务。
数据集成工具的场景
数据集成工具主要用于两种场景:

实时场景
需要在数据产生后快速同步到目标系统,适用于实时性要求高的业务场景。
离线场景
数据在特定时间点批量同步,适用于需要处理大规模历史数据的场景。
通过合理选择和配置数据集成工具,可以有效解决企业的数据割裂问题,为业务发展和决策支持提供坚实的基础。
常见的数据集成工具
在数据集成场景中,根据需求的不同,市面上或开源社区中存在多种数据集成工具。数据同步场景可以分为两类:基于查询的批处理场景和基于实时捕获的场景。
以下将对这两类场景及其对应工具的特点进行分析。
数据同步的两大场景
基于查询的批处理场景
特点:
- 通过定期调度的方式,将关系型数据库中的数据同步到目标系统。
- 以批处理方式进行,实时性要求较低。
- 适用于需要处理大规模历史数据或周期性分析的场景。
典型应用:
- 数据仓库的构建
- 历史数据分析
- 报表生成
基于实时捕获的流式处理场景
特点:
- 实时捕获和解析数据库中的变更数据(CDC, Change Data Capture)。
- 能够及时同步变更数据到目标系统,满足高实时性需求。
- 适用于需要实时响应和高时效场景的应用。
典型应用:
- 实时推荐系统
- 交易监控
- 实时日志分析
工具举例:
- Debezium:通过捕获关系型数据库(如MySQL的binlog或MongoDB的oplog)的变更日志,实现实时数据同步。
- Apache Kafka:配合Kafka Connect,可实现分布式数据流的实时采集与传输。
- Apache SeaTunnel:支持多种实时数据源和Sink,适合复杂的流式数据集成任务。
数据集成工具在数据仓库中的作用
无论是批处理还是实时场景,数据集成工具的最终目标都是将源数据统一采集到数据仓库或数据湖中,为后续的分析和应用提供支持。例如:
批处理场景:
将关系型数据库的数据定期采集到数据仓库,为离线数据分析和报表生成提供数据基础。
实时场景:
捕获数据库中的变更事件,通过实时同步到数据仓库,支持实时监控、推荐系统等应用。
Apache SeaTunnel 就是一个兼顾批处理和实时流式处理的集成工具,通过灵活的架构和丰富的连接器,能够满足多种数据集成需求。数据集成工具是现代数据生态中不可或缺的一环。根据场景需求选择合适的工具,可以大幅提升数据流通效率,为企业数据仓库建设和实时数据处理提供坚实保障。
离线场景的数据集成工具分析
在离线场景中,最常见的同步工具之一是 DataX。它作为一个新型架构的离线数据同步工具,被广泛应用于批量数据的迁移和同步。

然而,在使用过程中也暴露出了一些问题,尤其是在面对当前数据生态和未来发展的需求时,其局限性愈发明显。
DataX 的主要问题
生态不足
DataX 是一个专注于离线数据同步的框架,因此在实时数据同步方面存在明显的短板。这种生态不足表现为以下几点:
- 实时场景的缺失:在需要处理实时变更数据(如CDC)的场景中,DataX 无法满足需求。
- 信创化数据库支持的不足:随着国家对于信创国产化的政策要求,到 2026 年之前,政府部门和政务系统需要逐步替换为国产化数据库。然而,DataX 对国产化数据库的支持还不够完善,生态覆盖面较窄。
兼容性不足
DataX 在处理多种数据源类型时,采用了统一的架构设计,核心是 Reader 和 Writer 模块(如图所示),通过统一的接口和方法实现对不同数据库类型的支持。

这种设计虽然简化了架构复杂度,但也带来了兼容性问题:
- 字段类型处理粗糙:DataX 在字段映射和类型转换时,所有数据库类型的处理逻辑都集中在同一个函数内。这种实现方式对于一些特殊数据类型(如大字段、特殊格式的字段)的处理显得力不从心。
- 数据兼容性问题:对于某些复杂或非常规的数据源类型,DataX 需要额外定制化开发来满足需求,增加了使用和维护成本。

性能不足
DataX 的开源版本采用单节点架构,在处理超大规模数据时,性能瓶颈尤为明显:
- 单节点限制:单节点架构难以扩展,无法充分利用分布式系统的性能优势。
- 性能压力:在处理超大数据规模的场景下(如TB级别的数据迁移),性能往往难以满足企业需求,成为生产环境中的瓶颈。
需求驱动的工具演进
针对离线场景中暴露的问题,现代数据集成工具需要具备以下能力:
支持多种数据源的广泛兼容性:包括国产化数据库的适配和特殊字段类型的处理能力。
高性能架构:采用分布式架构以满足超大规模数据处理的需求。
实时与离线一体化:既能满足离线批量同步的需求,也能兼顾实时数据的同步能力。
DataX 的局限性为企业在选择数据集成工具时提供了警示:工具的适配性与扩展性决定了其在多样化需求下的生存能力。选择一个更灵活、更高效的工具(如 Apache SeaTunnel),能够帮助企业在离线数据同步中获得更高的性能和更广的生态支持。
离线 + 实时的需求与挑战
在现代数据平台中,数据集成通常涉及两大场景:离线场景与实时场景。企业在最初构建数据集成框架时,往往以离线场景为主,但随着业务需求的增加和数据分析实时性的要求提升,实时场景逐渐成为数据集成的重要组成部分。
当离线框架已成型而实时需求增加时,企业需要在原有架构基础上引入一条实时数据链路,这种扩展带来了新的挑战。
Lambda 架构下的痛点
Lambda 架构在数据集成领域的典型表现为同时运行离线和实时两条数据链路。这种架构虽然满足了多样化需求,但也引发了以下问题:

多条链路运维复杂
离线链路和实时链路需要分别设计和维护,增加了数据治理的复杂性。例如,离线链路可能基于 DataX,而实时链路则可能使用 Flink CDC,涉及不同的工具和框架。

重复开发工作
两套链路往往需要分别开发,重复性工作增加了开发成本。离线链路开发基于工具如 DataX,而实时链路需要构建 Flink 集群等,技术栈不同,导致开发和运维成本提高。
多技术栈的割裂
离线链路和实时链路使用不同技术栈,造成开发团队需要掌握多种工具,技术培训和维护难度增加。数据平台需要同时支持离线和实时的数据治理能力,进一步增加了平台的复杂性。
理想的数据集成工具的特点
为了解决上述问题,企业需要一个能够同时支持离线和实时场景的工具。

我认为以下是理想数据集成工具的关键特性:
丰富的生态支持
- 能够兼容多种数据源,包括主流数据库(如 MySQL、Oracle)以及国产化数据库。
- 适配多种Sink端(如数据仓库、数据湖、消息队列等),满足复杂的集成需求。
分布式架构
- 支持高并发和海量数据的处理,提供优越的扩展性。
- 在集群环境中高效运行,充分利用硬件资源。
批流一体
- 同时支持离线和实时数据同步需求,兼容批处理和流式处理架构。
- 减少多条链路运维的复杂性,实现一次开发、多场景复用。
性能优越
- 提供高吞吐和低延迟的数据处理能力,满足实时性要求。
- 在资源使用上做到高效,优化存储和计算的成本。
社区活跃度高
- 开源项目的活跃度能够保证工具的持续改进和问题响应速度。
- 丰富的文档和社区支持降低了上手难度。
批流一体架构的价值
通过批流一体的数据集成工具,可以有效解决 Lambda 架构带来的痛点:
简化运维:仅需维护一套架构,减少多链路治理的负担。
提升开发效率:通过一次开发,兼容离线和实时场景,避免重复劳动。
技术栈统一:减少技术培训和开发成本,增强团队协作效率。
像 Apache SeaTunnel 这样的批流一体架构工具,能够在离线与实时场景中都发挥优势,不仅具备丰富的生态支持,还具有优越的性能和分布式架构能力,是解决当前数据集成复杂性的优秀选择。
Apache SeaTunnel 简介
定义与背景

那给大家讲了这么久,SeaTunnel是什么呢?Apache SeaTunnel 是一款下一代高性能分布式超大规模数据同步工具,专为解决现代企业的批处理和实时流处理需求而设计。其名字来源于科幻小说《三体》中的“水滴”,早期被称为 WaterDrop,后在 2021 年更名为 Apache SeaTunnel。

上图展示了 SeaTunnel 的 LOGO,设计灵感源于水滴的简洁与强大,寓意其在数据处理领域的高效与灵活。
核心特性
Apache SeaTunnel 的核心特性围绕其在批处理与实时流处理中的统一能力展开:
批流一体架构
SeaTunnel 采用批流一体的架构,能够同时支持批数据处理和实时流数据处理:
- 无缝切换:在引擎层实现批处理和流处理的无缝切换,满足不同场景需求。
- 高灵活性:通过统一架构简化了开发与运维工作,提升了数据处理效率。
灵活的数据处理流程
从架构图中可以看出,SeaTunnel 的数据处理过程主要分为以下三部分:

- Source 层:定义数据源,支持多种主流数据源类型。
- Transform 层:执行轻量级的数据转换,如清洗、聚合等。
- Sink 层:将处理后的数据输出到目标位置,例如数据仓库、消息队列等。
这一架构允许开发者通过定义任务的输入、转换和输出,快速构建和部署数据管道。
架构演进
SeaTunnel 的核心架构在设计上强调抽象性和模块化,其核心组件如下:
-
任务初始化
每当用户定义了一个数据处理任务时,SeaTunnel 的引擎会将任务逻辑抽象为一个标准化的任务描述,完成初始化工作。 -
翻译层
翻译层的作用是将用户定义的 Source、Transform 和 Sink 转换为引擎可以识别的API调用。这一转换过程包括:- 将接口或代码片段抽象化。
- 转化为引擎能够识别的数据处理任务。
- 交由引擎执行完成整个数据流的处理。
-
模块化设计
SeaTunnel 的架构采用模块化设计,将数据输入、转换和输出分开,便于扩展和维护。
应用场景与案例
Apache SeaTunnel 的强大特性使其在以下场景中表现优异:
实时流处理
支持对交易监控、实时推荐等需要快速响应的场景进行高效处理。
批量数据处理
适合构建数据仓库、生成历史数据报表等大规模离线分析任务。
跨平台数据集成
无论是传统关系型数据库还是现代数据湖,SeaTunnel 都能通过其丰富的连接器生态,实现多种数据源与目标的无缝对接。
Apache SeaTunnel 特性
丰富的生态支持
Apache SeaTunnel 提供了丰富的生态支持,能够与170+种数据源和目标系统无缝对接,覆盖了常见的数据库、消息队列、大数据存储等组件。
目前支持的生态包括(展示部分):

- 关系型数据库:PostgreSQL、Oracle、MySQL
- 消息队列:Kafka、RabbitMQ、Pulsar
- 数据湖:Paimon、Hudi、Iceberg
- 大数据存储:HDFS、Hive、Kudu
- NoSQL 数据库:MongoDB、HBase、Redis
- 分析型数据库:ClickHouse、Doris
- 搜索引擎:Elasticsearch、Eazysearch
- 时序数据库:InfluxDB、TDengine
- 国产数据库:DM、openGauss
丰富的生态支持减少了开发者开发自定义插件的工作量,大幅降低了开发和维护成本。
多引擎支持
SeaTunnel 提供对以下三种引擎的支持:
Flink:主流流式计算引擎,适合需要实时数据处理的场景。
Spark:广泛应用于大数据离线处理的主流引擎。
Zeta 引擎:SeaTunnel 自主研发的轻量级引擎,专为不具备大数据平台或 Kubernetes 支持的企业设计。
Zeta 引擎的优势
- 适用场景:适合数据量较小、希望使用分布式能力但缺乏大数据平台支持的企业。
- 高性能:即使在资源较少的环境中,仍能提供优异的性能表现。
- 对比性能:在与 DataX 和 AWS DMS 的性能对比中,Zeta 引擎表现出资源占用低、处理速度快的特点。
数据处理能力
SeaTunnel 提供了强大的 Transform 模块,专注于轻量级的数据清洗与转换,包括以下功能:

轻量级处理:适合数据同步过程中需要的简单操作,例如:
- 增加虚拟字段
- 对行数据进行截取操作
- 引入加解密函数
复杂处理建议:对于复杂或重量级的处理,建议使用前置或后置的数据库(如通过SQL进行预处理),以更高效地利用现有数据库的计算能力。
性能对比
以下是 Apache SeaTunnel 在不同引擎下的性能表现(以 Zeta 引擎为例):

- 与 DataX 的对比:在资源较少的环境中,Zeta 引擎的性能明显优于 DataX,同步时间更短。

- 与 AWS DMS 的对比:Zeta 引擎在同步性能和资源效率方面表现优异,能够在更短的时间内完成数据同步。
Zeta 引擎(橙色部分)在资源和时间消耗上的表现均优于对比产品。
Apache SeaTunnel 架构演进

Apache SeaTunnel 的架构经历了从 V1 到 V2 的重要演进。这一演进的核心在于 解耦,显著提升了框架的灵活性、扩展性和维护性。
以下将对其架构演进过程及关键变化进行详细介绍。
V1 架构:多引擎高度耦合
在 V1 架构中,SeaTunnel 支持多个引擎(如 Flink 和 Spark),并针对每个引擎设计了独立的 API。

这种设计带来了以下问题:
多次实现成本高
- 每个新插件需要针对所有引擎分别实现一次。例如,将关系型数据库的数据同步到消息队列,需要分别开发适配 Flink 和 Spark 的逻辑。
引擎与插件的强耦合
- 插件(如 Source、Sink、Transform)与具体引擎深度绑定,导致版本升级和参数优化变得困难。
难以统一优化
- 各引擎独立运行,插件和任务的参数难以统一管理,增加了运维成本。
版本依赖复杂
- Source 到 Sink 端的逻辑高度依赖引擎的具体版本,导致版本升级风险高、成本大。
V2 架构:解耦与通用化
在 V2 架构中,SeaTunnel 通过解耦实现了高度模块化和灵活性。以下是架构的关键改进:

任务初始化的抽象化
SeaTunnel 将任务的输入(Source)、转换(Transform)、输出(Sink)进行高度抽象,形成统一的任务初始化流程:
- Source:定义数据来源。
- Transform:执行轻量级的数据转换。
- Sink:指定数据的目标存储位置。
这一层的抽象化解除了插件与引擎的绑定,使任务可以适配任何引擎(如 Flink、Spark、Zeta)。
引入翻译层(Translation)
翻译层负责将用户定义的任务通过通用 API 转换为具体引擎可执行的代码:
- 通用性:开发者只需实现一次 Source、Transform 和 Sink 的逻辑,翻译层会自动适配引擎。
- 降低开发成本:减少了插件开发中对多引擎的重复适配需求。
- 简化版本升级:由于插件与引擎解耦,版本升级仅需在翻译层中调整相关逻辑,无需修改核心插件。
参数与版本的统一
通过抽象化和翻译层的引入,SeaTunnel 实现了:
- 参数的统一管理:简化了多引擎场景下的任务配置。
- 版本升级的灵活性:任务的逻辑独立于引擎版本,升级引擎时无需担心任务兼容性问题。
解决业务痛点
实时与离线场景的统一
SeaTunnel 的 V2 架构解决了 Lambda 架构中的多条链路问题:
离线场景:支持任务调度和工作流的管理,满足复杂的批处理需求。
实时场景:支持实时数据处理与项目管理,适配动态业务需求。
降低开发成本与提升效率
- 商业化解决方案:例如,白鲸开源已基于Apache SeaTunnel 开发的并推出了商业版软件 WhaleTunnel,提供企业级功能增强、服务、运维、Debug、定期漏洞扫描和修复,无论是产品功能、稳定性、兼容性、速度还是安全性,都比开源版 Apache SeaTunnel 有巨大的进步!
- 工程化与规模化:通过工具的优化,企业可以快速构建高效的数据集成平台,减少自研成本。
总结
从 V1 到 V2 的架构演进,Apache SeaTunnel 实现了从多引擎耦合到解耦的飞跃。通过引入任务抽象化、翻译层和参数统一管理,SeaTunnel 不仅提高了开发效率,还显著降低了版本升级和运维的复杂度。在离线与实时场景的统一支持下,SeaTunnel 成为企业数据集成的强大工具,也为开发者提供了更多可能性。
祝愿 Apache SeaTunnel 社区和相关商业产品在未来的发展中越来越好!
本文由 白鲸开源科技 提供发布支持!
相关文章:
某政务行业基于 SeaTunnel 探索数据集成平台的架构实践
分享嘉宾:某政务公司大数据技术经理 孟小鹏 编辑整理:白鲸开源 曾辉 导读:本篇文章将从数据集成的基础概念入手,解析数据割裂给企业带来的挑战,阐述数据集成的重要性,并对常见的集成场景与工具进行阐述&…...

word-break控制的几种容器换行行为详解
word-break 属性在控制换行行为时需要根据语言判断,对于中文 一个字符就是一个单词,字符换行不影响阅读理解,而对于英文来说,多个连续的字符才会是一个单词,例如中文的 早 英文为 morning。 morning7个字符才算一个单词…...

【0x0084】HCI_Set_Min_Encryption_Key_Size命令详解
目录 一、命令概述 二、命令格式及参数 2.1 HCI_Set_Min_Encryption_Key_Size命令格式 2.2. Min_Encryption_Key_Size 三、生成事件及参数 3.1. HCI_Command_Complete 事件 3.2. Status 四、命令的执行流程 4.1. 主机端准备阶段 4.2. 命令发送阶段 4.3. 控制器接收和…...

关于2025年智能化招聘管理系统平台发展趋势
2025年,招聘管理领域正站在变革的十字路口,全新的技术浪潮与不断变化的职场生态相互碰撞,促使招聘管理系统成为重塑企业人才战略的关键力量。智能化招聘管理系统平台在这一背景下迅速崛起,其发展趋势不仅影响企业的招聘效率与质量…...
Docker部署Spring Boot + Vue项目
目录 前提条件 概述 下载代码 打开代码 Docker创建网络 MySQL容器准备 MySQL数据库配置 启动MySQL容器 测试连接MySQL 初始化MySQL数据 Redis容器准备 修改Redis配置 启动redis容器 部署后端 后端代码打包 上传jar包到Linux 创建Dockerfile 构建镜像 运行后…...

开发规范
开发规范 企业项目开发有2种开发模式:前后台混合开发和前后台分离开发。 前后台混合开发 顾名思义就是前台后台代码混在一起开发,如下图所示: 这种开发模式有如下缺点: 沟通成本高:后台人员发现前端有问题…...
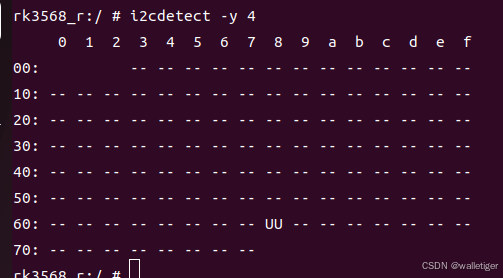
九 RK3568 android11 MPU6500
一 MPU6500 内核驱动 1.1 查询设备连接地址 查看原理图, MPU6500 I2C 连接在 I2C4 上, 且中断没有使用 i2c 探测设备地址为 0x68 1.2 驱动源码 drivers/input/sensors/gyro/mpu6500_gyro.c drivers/input/sensors/accel/mpu6500_acc.c 默认 .config 配置编译了 mpu6550 …...
openplant实时数据库(二次开发)
资源地址 我的网盘〉软件>数据库>openplant>openplant实时数据库(二次开发)...
C语言:-三子棋游戏代码:分支-循环-数组-函数集合
思路分析: 1、写菜单 2、菜单之后进入游戏的操作 3、写函数 实现游戏 3.1、初始化棋盘函数,使数组元素都为空格 3.2、打印棋盘 棋盘的大概样子 3.3、玩家出棋 3.3.1、限制玩家要下的坐标位置 3.3.2、判断玩家要下的位置是否由棋子 3.4、电脑出棋 3.4.1、…...

“AI智慧化服务系统:未来生活的智能管家
在当今快速发展的科技时代,人工智能(AI)正以前所未有的速度改变着我们的生活。AI智慧化服务系统作为这一变革的前沿技术,正在逐渐成为我们未来生活的智能管家。它们不仅提高了服务效率,还为我们带来了更加个性化和便捷…...

python管理工具:conda部署+使用
python管理工具:conda部署使用 一、安装部署 1、 下载 - 官网下载: https://repo.anaconda.com/archive/index.html - wget方式: wget -c https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh2、 安装 在conda文件的…...

minio https配置
minio启动时候指定数据目录,配置文件,密钥文件目录,环境文件 1.创建minio用户,专门用于服务启动的 groupadd -r minio-user useradd -M -r -g minio-user minio-user 2.在当前用户目录下创建minio目录,存储minio相关文件 mkdir minio 在mini…...
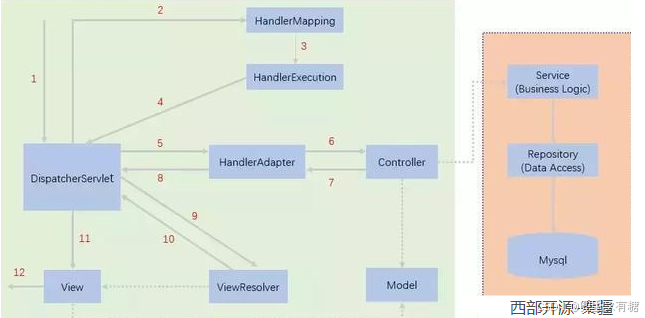
SpringMVC——原理简介
狂神SSM笔记 DispatcherServlet——SpringMVC 的核心 SpringMVC 围绕DispatcherServlet设计。 DispatcherServlet的作用是将请求分发到不同的处理器(即不同的Servlet)。根据请求的url,分配到对应的Servlet接口。 当发起请求时被前置的控制…...
Ubuntu18.04 解决 libc.so.6: version `GLIBC_2.28‘ not found
Glibc(GNU C Library)是 GNU 系统及其衍生系统如 Linux 操作系统中实现 C 语言标准库的核心组件。升级 Glibc 是一个非常谨慎的操作,因为它与系统的许多关键功能和服务密切相关。Ubuntu 18.04 默认安装的 Glibc 版本为 2.27,但某些…...
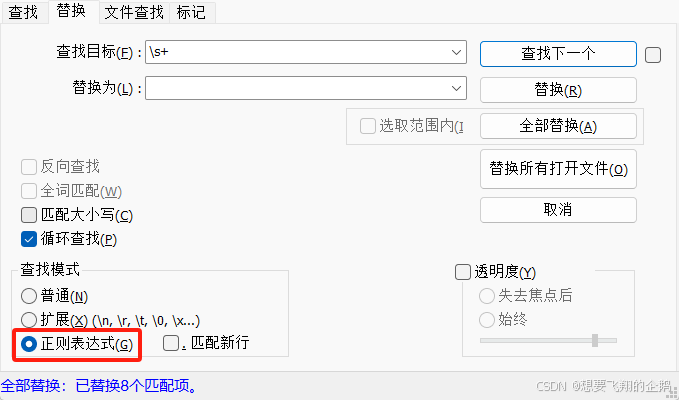
Notepad++移除所有空格
1.打开Notepad。 2.打开你想要编辑的文件。 3.按下 Ctrl H 打开查找和替换对话框,并选择 “正则表达式”。 4.在 “查找目标” 框中输入 \s。 5.在 “替换为” 框中留空,不填写任何内容。 6.点击 “全部替换” 按钮。...

Android BottomNavigationView不加icon使text垂直居中,完美解决。
这个问题网上千篇一律的设置iconsize为0,labale固定什么的,都没有效果。我的这个基本上所有人用都会有效果。 问题解决之前的效果:垂直方向,文本不居中,看着很难受 问题解决之后:舒服多了 其实很简单&…...

如何使用 `forEach` 遍历数组?
数组遍历相关问题:如何使用 forEach 遍历数组? 在 JavaScript 中,遍历数组是一个常见且必要的操作。数组提供了多种方法来进行遍历,其中 forEach 是一种非常方便且常用的方法。它可以轻松地对数组中的每个元素执行回调函数。理解…...

Go语言之路————条件控制:if、for、switch
Go语言之路————if、for、switch 前言ifforswitchgoto和label 前言 我是一名多年Java开发人员,因为工作需要现在要学习go语言,Go语言之路是一个系列,记录着我从0开始接触Go,到后面能正常完成工作上的业务开发的过程࿰…...
OpenAI推出首个AI Agent!日常事项自动化处理!
2025 年1月15日,OpenAI 正式宣布推出一项名为Tasks的测试版功能 。 该功能可以根据你的需求内容和时间实现自动化处理。比方说,你可以设置每天早晨 7 点获取天气预报,或定时提醒遛狗等日常事项。 看到这里,有没有一种熟悉的感觉&a…...

Go语言的编程范式
Go语言的编程范式 引言 Go语言,又称为Golang,由Google于2007年开发并于2009年开放源代码。Go语言被设计成一种简洁、高效且适用于多核计算和网络编程的语言。其独特的并发模型、静态类型系统以及高效的性能,使其在现代软件开发中逐渐获得了…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...
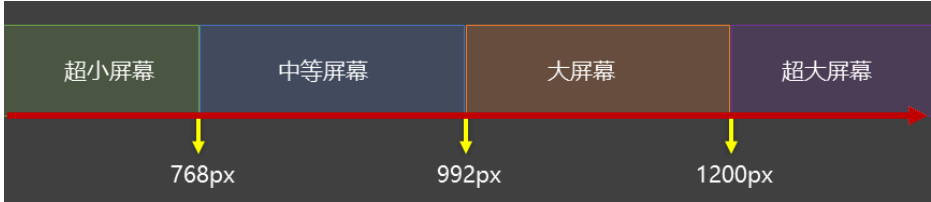
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...

第22节 Node.js JXcore 打包
Node.js是一个开放源代码、跨平台的、用于服务器端和网络应用的运行环境。 JXcore是一个支持多线程的 Node.js 发行版本,基本不需要对你现有的代码做任何改动就可以直接线程安全地以多线程运行。 本文主要介绍JXcore的打包功能。 JXcore 安装 下载JXcore安装包&a…...