wow-agent---task2使用llama-index创建Agent
一:创造俩个函数,multiply和add作为fuction calling被LLM当做工具来使用,实现计算一个简单的计算题:
from llama_index.llms.ollama import Ollama
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionToolllm = Ollama(model="qwen2.5:latest", request_timeout=120.0)def multiply(a: float, b: float) -> float:"""Multiply two numbers and returns the product"""return a * bdef add(a: float, b: float) -> float:"""Add two numbers and returns the sum"""return a + bdef main():multiply_tool = FunctionTool.from_defaults(fn=multiply)add_tool = FunctionTool.from_defaults(fn=add)# 创建ReActAgent实例agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)response = agent.chat("20+(2*4)等于多少?使用工具计算每一步,最好输出计算结果")print(response)if __name__ == "__main__":main()计算后的输出:

二:统计数据库中俩个部门的人数总和,数据库如下:

首先要创建数据库,这个以sqlite为例进行创建
import sqlite3
# 创建数据库
sqllite_path = 'llmdb.db'
con = sqlite3.connect(sqllite_path)# 创建表
sql = """
CREATE TABLE `section_stats` (`部门` varchar(100) DEFAULT NULL,`人数` int(11) DEFAULT NULL
);
"""
c = con.cursor()
cursor = c.execute(sql)
c.close()
con.close()写入数据
import sqlite3
# 创建数据库
sqllite_path = 'llmdb.db'con = sqlite3.connect(sqllite_path)
c = con.cursor()
data = [["专利部",22],["商标部",25],
]
for item in data:sql = """INSERT INTO section_stats (部门,人数) values('%s','%d')"""%(item[0],item[1])c.execute(sql)con.commit()
c.close()
con.close()最后让LLM调用add工具进行俩个部门的人数统计
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SQLDatabase
from llama_index.core.query_engine import NLSQLTableQueryEngine
from sqlalchemy import create_engine, select
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbeddingllm = Ollama(model="qwen2.5:latest", request_timeout=120.0)
embedding = OllamaEmbedding(model_name="bge-m3:latest")
Settings.llm = llm
Settings.embed_model = embedding
## 创建数据库查询引擎
engine = create_engine("sqlite:///llmdb.db")
# prepare data
sql_database = SQLDatabase(engine, include_tables=["section_stats"])
query_engine = NLSQLTableQueryEngine(sql_database=sql_database,tables=["section_stats"],llm=Settings.llm,embed_model=Settings.embed_model
)def multiply(a: float, b: float) -> float:"""将两个数字相乘并返回乘积。"""return a * bmultiply_tool = FunctionTool.from_defaults(fn=multiply)def add(a: float, b: float) -> float:"""将两个数字相加并返回它们的和。"""return a + badd_tool = FunctionTool.from_defaults(fn=add)# 把数据库查询引擎封装到工具函数对象中
staff_tool = QueryEngineTool.from_defaults(query_engine,name="section_staff",description="查询部门的人数。"
)agent = ReActAgent.from_tools([multiply_tool, add_tool, staff_tool], verbose=True)
response = agent.chat("请从数据库表中获取`专利部`和`商标部`的人数,并将这两个部门的人数相加!最后输出想加的结果")
print(response)
三:RAG实现,这里使用faiss向量数据库---pip install faiss-cpu,有条件的也可以用faiss-gpu。
文本内容huahua.txt

from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.core import SimpleDirectoryReader,Document
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion.pipeline import run_transformations
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.response_synthesizers import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
from llama_index.core.agent import ReActAgentembedding = OllamaEmbedding(model_name="bge-m3:latest")
llm = Ollama(model="qwen2.5:latest", request_timeout=120.0)#加载文档
documents = SimpleDirectoryReader(input_files=['huahua.txt']).load_data()
# 构建节点
transformations = [SentenceSplitter(chunk_size = 512)]
nodes = run_transformations(documents, transformations=transformations)# 构建索引
emb = embedding.get_text_embedding("你好呀呀")
vector_store = FaissVectorStore(faiss_index=faiss.IndexFlatL2(len(emb)))
storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex(nodes = nodes,storage_context=storage_context,embed_model = embedding,
)# 构建检索器,想要自定义参数,可以构造参数字典
kwargs = {'similarity_top_k': 5, 'index': index, 'dimensions': len(emb)}
# 必要参数
retriever = VectorIndexRetriever(**kwargs)
# 构建合成器
response_synthesizer = get_response_synthesizer(llm=llm, streaming=True)
# 构建问答引擎
engine = RetrieverQueryEngine(retriever=retriever,response_synthesizer=response_synthesizer,)query_engine_tools = [QueryEngineTool(query_engine=engine,metadata=ToolMetadata(name="RAG工具",description=("用于在原文中检索相关信息"),),),
]agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
response = agent.chat("花花是谁?")
print(response)
四:这里实现的是调用web_search_tool来进行网页摘要的问答,我这里直接写了个mock输出用于调用,你可以使用curl或者restful借口来实现获取信息,agent的实现原理都是一样。
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.core.tools import FunctionToolapi_key='ollama'
base_url = 'http://localhost:11434/v1'
chat_model = Ollama(model="qwen2.5:latest", request_timeout=120.0)
emb_model = OllamaEmbedding(model_name="bge-m3:latest")def web_search_tool(query):res="1月17日,商务部等8部门办公厅发布关于做好2025年汽车以旧换新工作的通知。通知称,2025年,对个人消费者报废2012年6月30日前注册登记的汽油乘用车、2014年6月30日前注册登记的柴油及其他燃料乘用车,或2018年12月31日前注册登记的新能源乘用车,并购买纳入工业和信息化部《减免车辆购置税的新能源汽车车型目录》的新能源乘用车或2.0升及以下排量燃油乘用车,给予一次性定额补贴。对报废上述符合条件旧车并购买新能源乘用车的,补贴2万元;对报废上述符合条件燃油乘用车并购买2.0升及以下排量燃油乘用车的,补贴1.5万元。在一个自然年度内,每位个人消费者最多享受一次汽车报废更新补贴。2025年,对个人消费者转让登记在本人名下的乘用车,并购买乘用车新车的,给予一次性补贴支持,购买新能源乘用车补贴最高不超过1.5万元,购买燃油乘用车补贴最高不超过1.3万元。个人消费者申请汽车置换更新补贴,转让的既有乘用车登记在本人名下的时间最迟不得晚于2025年1月8日。每位个人消费者在一个自然年度内最多可享受一次汽车置换更新补贴,就同一辆新车只能选择申领汽车报废更新补贴或者置换更新补贴。汽车以旧换新补贴资金按照总体9:1的原则实行央地共担,并分地区确定具体分担比例。其中,对东部省份按8.5:1.5比例分担,对中部省份按9:1比例分担,对西部省份按9.5:0.5比例分担。各省级财政根据中央资金分配情况按比例安排配套资金,省以下经费分担办法由省级财政确定。"return res#https://baijiahao.baidu.com/s?id=1821492416829025049llm = Ollama(model="qwen2.5:latest", request_timeout=120.0)
search_tool = FunctionTool.from_defaults(fn=web_search_tool)
from llama_index.core.agent import ReActAgent
agent = ReActAgent.from_tools([search_tool], llm=llm, verbose=True)query = "汽车以旧换新补贴资金的比例是怎么分配的?"
response = agent.chat(f"请帮我搜索以下内容:{query}")
print(response)
后记:要充分了解agent的相关概念如LLM模型,嵌入模型,工具调用实现,向量数据库,RAG实现等,再熟悉llama-index的基本使用,以上代码还是可以很轻松的学会,况且你还有各种在线的LLM帮你来解答,个人认为未来agent开发模型会向低代码或无代码化继续演进,接合 RAG可以实现让LLM快速理解领域知识,从而可以更好的深入服务于各个垂直行业的业务。
相关文章:
wow-agent---task2使用llama-index创建Agent
一:创造俩个函数,multiply和add作为fuction calling被LLM当做工具来使用,实现计算一个简单的计算题: from llama_index.llms.ollama import Ollama from llama_index.core.agent import ReActAgent from llama_index.core.tools …...

RabbitMQ实现延迟消息发送——实战篇
在项目中,我们经常需要使用消息队列来实现延迟任务,本篇文章就向各位介绍使用RabbitMQ如何实现延迟消息发送,由于是实战篇,所以不会讲太多理论的知识,还不太理解的可以先看看MQ的延迟消息的一个实现原理再来看这篇文章…...

Oracle 拉链式merge sort join 原理
Oracle 拉链式Merge Sort Join 的原理,我用一个生活中的比喻来解释。 --- 比喻场景:匹配快递包裹和收件人 1. 快递包裹清单 想象我们有一个快递公司送货的包裹清单,清单按照收件人的邮编(ZIP Code)排序: …...

QModbusTCPClient占用内存持续增长
最近使用QModbusTCPClient通信,需要频繁发送读写请求,发现软件占用内存一直在增减,经过不断咨询和尝试,终于解决了。 1.方案一(失败) 最开始以为是访问太频繁,导致创建reply的对象比delete re…...

代码中使用 Iterable<T> 作为方法参数的解释
/*** 根据课程 id 集合查询课程简单信息* param ids id 集合* return 课程简单信息的列表*/ GetMapping("/courses/simpleInfo/list") List<CourseSimpleInfoDTO> getSimpleInfoList(RequestParam("ids") Iterable<Long> ids); 一、代码解释&…...

Oracle数据库传统审计怎么用
Oracle数据库传统审计怎么用 审计功能开启与关闭By Session还是By AccessWhenever Successful数据库语句审计数据库对象审计查看审计策略和记录Oracle数据库审计功能分为传统审计(Traditional Auditing)和统一审计(Unified Auditing)。统一审计是从Oracle 12c版本开始引入的…...

leetcode-买卖股票问题
309. 买卖股票的最佳时机含冷冻期 - 力扣(LeetCode) 动态规划解题思路: 1、暴力递归(难点如何定义递归函数) 2、记忆化搜索-傻缓存法(根据暴力递归可变参数确定缓存数组维度) 3、严格表结构依…...

MYSQL学习笔记(三):分组、排序、分页查询
前言: 学习和使用数据库可以说是程序员必须具备能力,这里将更新关于MYSQL的使用讲解,大概应该会更新30篇,涵盖入门、进阶、高级(一些原理分析);这一篇是讲解分组、排序、分页查询,并且结合案例进行讲解;虽…...

上位机工作感想-2024年工作总结和来年计划
随着工作年限的增增长,发现自己越来越不喜欢在博客里面写一些掺杂自己感想的东西了,或许是逐渐被工作逼得“成熟”了吧。2024年,学到了很多东西,做了很多项目,也帮别人解决了很多问题,唯独没有涨工资。来这…...

【视觉惯性SLAM:十六、 ORB-SLAM3 中的多地图系统】
16.1 多地图的基本概念 多地图系统是机器人和计算机视觉领域中的一种关键技术,尤其在 SLAM 系统中具有重要意义。单一地图通常用于表示机器人或相机在环境中的位置和构建的空间结构,但单一地图在以下情况下可能无法满足需求: 大规模场景建图…...

【C++笔记】红黑树封装map和set深度剖析
【C笔记】红黑树封装map和set深度剖析 🔥个人主页:大白的编程日记 🔥专栏:C笔记 文章目录 【C笔记】红黑树封装map和set深度剖析前言一. 源码及框架分析1.1 源码框架分析 二. 模拟实现map和set2.1封装map和set 三.迭代器3.1思路…...

4.若依 BaseController
若依的BaseController是其他所有Controller的基类,一起来看下BaseController定义了什么 1. 定义请求返回内容的格式 code/msg/data 返回数据格式不是必须是AjaxResult,开发者可以自定义返回格式,注意与前端取值方式一致即可。 2. 获取调用…...

vue项目配置多语言
本文详细介绍如何在 Vue 项目中集成 vue-i18n 和 Element-UI ,实现多语言切换;首先通过 npm 安装 vue-i18n 和相关语言包,接着在配置文件中设置中文和英文的语言信息;最后在 main.js 中导入并挂载多语言实例,实现切换地…...

数据可视化大屏设计与实现
本文将带你一步步了解如何使用 ECharts 实现一个数据可视化大屏,并且如何动态加载天气数据展示。通过整合 HTML、CSS、JavaScript 以及后端接口请求,我们可以构建一个响应式的数据可视化页面。 1. 页面结构介绍 在此例中,整个页面分为几个主…...

PDF文件提取开源工具调研总结
概述 PDF是一种日常工作中广泛使用的跨平台文档格式,常常包含丰富的内容:包括文本、图表、表格、公式、图像。在现代信息处理工作流中发挥了重要的作用,尤其是RAG项目中,通过将非结构化数据转化为结构化和可访问的信息࿰…...

多监控m3u8视频流,怎么获取每个监控的封面图(纯前端)
文章目录 1.背景2.问题分析3.解决方案3.1解决思路3.2解决过程3.2.1 封装播放组件3.2.2 隐形的视频div3.2.3 截取封面图 3.3 结束 1.背景 有这样一个需求: 给你一个监控列表,每页展示多个监控(至少12个,m3u8格式)&…...

【机器学习实战入门项目】使用深度学习创建您自己的表情符号
深度学习项目入门——让你更接近数据科学的梦想 表情符号或头像是表示非语言暗示的方式。这些暗示已成为在线聊天、产品评论、品牌情感等的重要组成部分。这也促使数据科学领域越来越多的研究致力于表情驱动的故事讲述。 随着计算机视觉和深度学习的进步,现在可以…...

技术洞察:C++在后端开发中的前沿趋势与社会影响
文章目录 引言C在后端开发中的前沿趋势1. 高性能计算的需求2. 微服务架构的兴起3. 跨平台开发的便利性 跨领域技术融合与创新实践1. C与人工智能的结合2. C与区块链技术的融合 C对社会与人文的影响1. 提升生产力与创新能力2. 促进技术教育与人才培养3. 技术与人文的深度融合 结…...

【人工智能 | 大数据】基于人工智能的大数据分析方法
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈智能大数据分析 ⌋ ⌋ ⌋ 智能大数据分析是指利用先进的技术和算法对大规模数据进行深入分析和挖掘,以提取有价值的信息和洞察。它结合了大数据技术、人工智能(AI)、机器学习(ML&a…...

数字经济时代下的创新探索与实践:以“开源AI智能名片2+1链动模式S2B2C商城小程序源码”为核心
摘要:在数字经济蓬勃发展的今天,中国作为全球数字经济的领航者,正以前所未有的速度推进“数字中国”建设。本文旨在探讨“开源AI智能名片21链动模式S2B2C商城小程序源码”在数字经济背景下的应用潜力与实践价值,从多个维度分析其对…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...
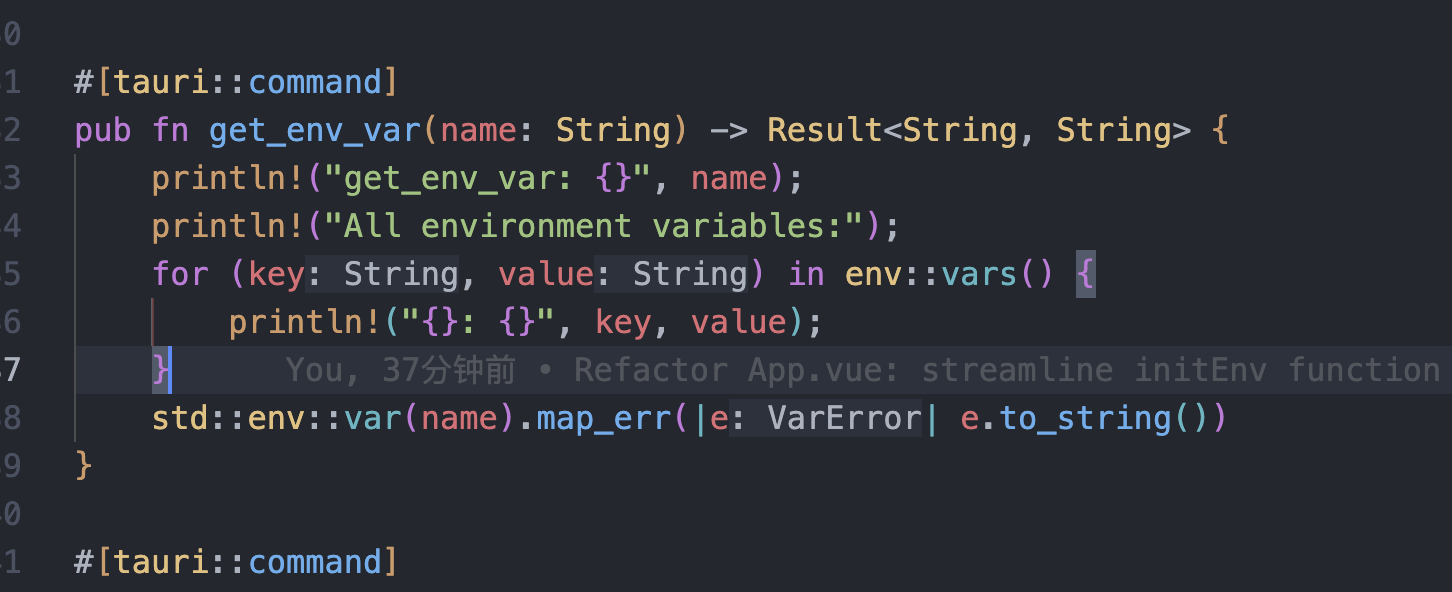
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...
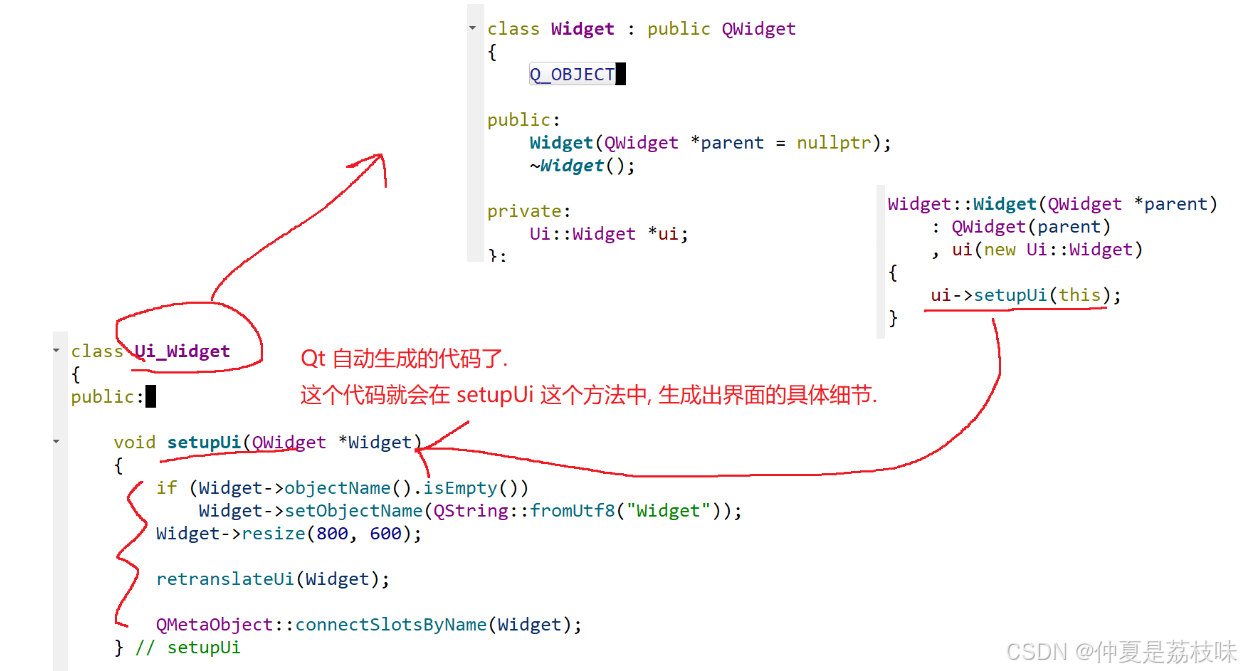
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...