网络通信---MCU移植LWIP
使用的MCU型号为STM32F429IGT6,PHY为LAN7820A
目标是通过MCU的ETH给LWIP提供输入输出从而实现基本的Ping应答

OK废话不多说我们直接开始
下载源码
- LWIP包源码:lwip源码
-在这里下载

- ST官方支持的ETH包:ST-ETH支持包
这里下载

创建工程
这里我使用我的STM32外扩RAM工程,若是手里无有外扩内存的板卡也可以直接使用点灯工程

加入ETH支持包
将刚刚下载的ETH支持包里
STM32F4x7_ETH_LwIP_V1.1.1\Libraries\STM32F4x7_ETH_Driver
目录下有/inc /src 两个文件夹,分别存放着ETH驱动的源文件和头文件
把他们对应的加入源码工程中
\Libraries\STM32F4xx_StdPeriph_Driver
的 /inc 和 /src中
然后将stm32f4x7_eth_conf_temp.h重命名为stm32f4x7_eth_conf.h
在keil工程中加入他们!
修改stm32f4x7_eth_conf.h
直接编译会报错,因为没ETH使用的delay函数,这里直接不使用ETH的delay,直接注释掉USE_Delay

修改stm32f4x7_eth.c
在这个文件的一开始会发现
搜索这里的宏定义是发现这些描述符和Buffer占用了大量的空间,描述符占用了320byte,因为后面用DMA搬运所以使用片内RAM,而这里的Buffer一共占用了大约38Kbyte,这非常大,所以一般放在外部RAM,这里我使用的片外SRAM是IS42S16400J 拥有8M内存,所以可以放在片外SRAM,所以这里先注释掉,稍后使用malloc分配内存给它们,如果移植的板卡无片外扩展SRAM则不用管这里,直接放在内部RAM

然后注释的后面添加指针
ETH_DMADESCTypeDef *DMARxDscrTab;
ETH_DMADESCTypeDef *DMATxDscrTab;
uint8_t *Tx_Buff;
uint8_t *Rx_Buff;
这里需要使用malloc.c和malloc.h
malloc.c
#include "malloc.h"
#include "stdio.h"// //内存池(4字节对齐)
#pragma pack(4)u8 mem1base[MEM1_MAX_SIZE];u8 mem2base[MEM2_MAX_SIZE] __attribute__((at(0xD0000000))); //外部SRAM内存池
#pragma pack()//内存管理表
u16 mem1mapbase[MEM1_ALLOC_TABLE_SIZE]; //内部SRAM内存池MAP
u16 mem2mapbase[MEM2_ALLOC_TABLE_SIZE] __attribute__((at(0xD0000000+MEM2_MAX_SIZE))); //外部SRAM内存池MAP
//内存管理参数
const u32 memtblsize[SRAMBANK]={MEM1_ALLOC_TABLE_SIZE,MEM2_ALLOC_TABLE_SIZE}; //内存表大小
const u32 memblksize[SRAMBANK]={MEM1_BLOCK_SIZE,MEM2_BLOCK_SIZE}; //内存分块大小
const u32 memsize[SRAMBANK]={MEM1_MAX_SIZE,MEM2_MAX_SIZE}; //内存总大小//内存管理控制器
struct _m_mallco_dev mallco_dev=
{mymem_init, //内存初始化mem_perused, //内存使用率mem1base,mem2base, //内存池mem1mapbase,mem2mapbase,//内存管理状态表0,0, //内存管理未就绪
};//复制内存
//*des:目的地址
//*src:源地址
//n:需要复制的内存长度(字节为单位)
void mymemcpy(void *des,void *src,u32 n)
{u8 *xdes = des;u8 *xsrc = src;while(n--) *xdes++ = *xsrc++;
}//设置内存
//*s:内存首地址
//c :要设置的值
//count:需要设置的内存大小(字节为单位)
void mymemset(void*s,u8 c,u32 count)
{u8 *xs = s;while(count--) *xs++=c;
}//内存管理初始化
//memx:所属内存块
void mymem_init(u8 memx)
{mymemset(mallco_dev.memmap[memx],0,memtblsize[memx]*2); //内存状态表清零mymemset(mallco_dev.membase[memx], 0,memsize[memx]); //内存池所有数据清零 mallco_dev.memrdy[memx]=1; //内存管理初始化OK
}//获取内存使用率
//memx:所属内存块
//返回值:使用率(0~100)
u8 mem_perused(u8 memx)
{ u32 used=0; u32 i; for(i=0;i<memtblsize[memx];i++) { if(mallco_dev.memmap[memx][i])used++; } return (used*100)/(memtblsize[memx]);
} //内存分配(内部调用)
//memx:所属内存块
//size:要分配的内存大小(字节)
//返回值:0XFFFFFFFF,代表错误;其他,内存偏移地址
u32 mymem_malloc(u8 memx,u32 size)
{ signed long offset=0; u16 nmemb; //需要的内存块数 u16 cmemb=0;//连续空内存块数u32 i; if(!mallco_dev.memrdy[memx])mallco_dev.init(memx);//未初始化,先执行初始化 if(size==0)return 0XFFFFFFFF;//不需要分配nmemb=size/memblksize[memx]; //获取需要分配的连续内存块数if(size%memblksize[memx])nmemb++; for(offset=memtblsize[memx]-1;offset>=0;offset--)//搜索整个内存控制区 { if(!mallco_dev.memmap[memx][offset])cmemb++;//连续空内存块数增加else cmemb=0; //连续内存块清零if(cmemb==nmemb) //找到了连续nmemb个空内存块{for(i=0;i<nmemb;i++) //标注内存块非空 { mallco_dev.memmap[memx][offset+i]=nmemb; } return (offset*memblksize[memx]);//返回偏移地址 }} return 0XFFFFFFFF;//未找到符合分配条件的内存块
} //释放内存(内部调用)
//memx:所属内存块
//offset:内存地址偏移
//返回值:0,释放成功;1,释放失败;
u8 mymem_free(u8 memx,u32 offset)
{ int i; if(!mallco_dev.memrdy[memx])//未初始化,先执行初始化{mallco_dev.init(memx); return 1;//未初始化 } if(offset<memsize[memx])//偏移在内存池内. { int index=offset/memblksize[memx]; //偏移所在内存块号码 int nmemb=mallco_dev.memmap[memx][index]; //内存块数量for(i=0;i<nmemb;i++) //内存块清零{ mallco_dev.memmap[memx][index+i]=0; } return 0; }else return 2;//偏移超区了.
} //释放内存(外部调用)
//memx:所属内存块
//ptr:内存首地址
void myfree(u8 memx,void *ptr)
{ u32 offset; printf("myfree\r\n"); if(ptr==NULL)return;//地址为0. offset=(u32)ptr-(u32)mallco_dev.membase[memx]; mymem_free(memx,offset);//释放内存
} //分配内存(外部调用)
//memx:所属内存块
//size:内存大小(字节)
//返回值:分配到的内存首地址.
void *mymalloc(u8 memx,u32 size)
{ u32 offset; offset=mymem_malloc(memx,size); if(offset==0XFFFFFFFF)return NULL; else return (void*)((u32)mallco_dev.membase[memx]+offset);
} //重新分配内存(外部调用)
//memx:所属内存块
//*ptr:旧内存首地址
//size:要分配的内存大小(字节)
//返回值:新分配到的内存首地址.
void *myrealloc(u8 memx,void *ptr,u32 size)
{ u32 offset; offset=mymem_malloc(memx,size); if(offset==0XFFFFFFFF)return NULL; else { mymemcpy((void*)((u32)mallco_dev.membase[memx]+offset),ptr,size); //拷贝旧内存内容到新内存 myfree(memx,ptr); //释放旧内存return (void*)((u32)mallco_dev.membase[memx]+offset); //返回新内存首地址}
}
malloc.h
#ifndef _MALLOC_H
#define _MALLOC_H
#include "stm32f4xx.h"#ifndef NULL
#define NULL 0
#endif//定义三个内存池
#define SRAMIN 0 //内部内存池
#define SRAMEX 1 //外部内存池#define SRAMBANK 2 //定义支持的SRAM块数//mem1内存参数设定,mem1完全处于内部SRAM里面
#define MEM1_BLOCK_SIZE 32 //内存块大小为32字节
#define MEM1_MAX_SIZE 30*1024 //最大管理内存 10k
#define MEM1_ALLOC_TABLE_SIZE MEM1_MAX_SIZE/MEM1_BLOCK_SIZE //内存表大小//mem2内存参数设定,mem2处于外部SRAM里面
#define MEM2_BLOCK_SIZE 32 //内存块大小为32字节
#define MEM2_MAX_SIZE 500*1024 //最大管理内存 500k
#define MEM2_ALLOC_TABLE_SIZE MEM2_MAX_SIZE/MEM2_BLOCK_SIZE //内存表大小//内存管理控制器
struct _m_mallco_dev
{void (*init)(u8); //初始化u8 (*perused)(u8); //内存使用率u8 *membase[SRAMBANK]; //内存池,管理SRAMBANK个区域的内存u16 *memmap[SRAMBANK]; //内存状态表u8 memrdy[SRAMBANK]; //内存管理是否就绪
};
extern struct _m_mallco_dev mallco_dev; //在malloc.c里面定义void mymemset(void *s,u8 c,u32 count); //设置内存
void mymemcpy(void *des,void *src,u32 n);//复制内存
void mymem_init(u8 memx); //内存管理初始化函数(外/内部调用)
u32 mymem_malloc(u8 memx,u32 size); //内存分配(内部调用)
u8 mymem_free(u8 memx,u32 offset); //内存释放(内部调用)
u8 mem_perused(u8 memx); //获得内存使用率(外/内部调用)
//用户调用函数
void myfree(u8 memx,void *ptr); //内存释放(外部调用)
void *mymalloc(u8 memx,u32 size); //内存分配(外部调用)
void *myrealloc(u8 memx,void *ptr,u32 size);//重新分配内存(外部调用)
#endif
然后在main函数中使用

修改stm32f4x7_eth.h
在 #include “stm32f4x7_eth.h” 的最后添加 extern 使得外部文件可以使用

至此 ETH的DMA描述符,缓存,接收帧内存 都可以使用了
加入LWIP包
在工程源目录中加入LWIP文件夹, 并且把lwip包的文件全部复制到源码目录的LWIP文件夹里
添加lwip源码

在keil中创建相对应的Group并且在keil中加入这些路径
- lwip/core
需要单独加入ipv4的内容,不加ipv6的内容

lwip/netif 加入这些中的ethernet.c文件,注意只加ethernet.c

- lwip.api
加入这些
 - lwip/arch
- lwip/arch
这个文件夹是单独创建在User中的arch文件夹,这里存放着lwip与用户的接口
在我的文件夹中的User/arch 文件夹中,直接复制过去

添加lwip头文件路径
在keil工程中加入头文件路径

添加lwip时钟更新
在这里我使用的是我10ms的定时器驱动的一个任务调度器,没软件定时器的可以直接放入10ms定时器中.

把上图的函数放入10ms任务中,其中lwip_localtime+=10表示的是10ms更新的时基。
添加以太网底层驱动
以太网初始化
初始化GPIO
初始化GPIO并且选择RMII接口的SYSCFG
RCC->AHB1ENR |= RCC_AHB1Periph_GPIOA|RCC_AHB1Periph_GPIOB|RCC_AHB1Periph_GPIOC|RCC_AHB1Periph_GPIOG;RCC->APB2ENR |=RCC_APB2Periph_SYSCFG;//使能SYSCFG时钟SYSCFG->PMC=(uint32_t)(0x800000);//MAC和PHY之间使用RMII接口GPIOA->MODER|=(uint32_t)(0x8028); //PA1 PA2 PA7GPIOB->MODER|=(uint32_t)(0x800000); //PB11GPIOC->MODER|=(uint32_t)(0xA08); //PC1 PC4 PC5GPIOG->MODER|=(uint32_t)(0x28000000); //PG13 PG14GPIOA->AFR[0]|=(uint32_t)(0xB0000BB0);//PA1 PA2 PA7GPIOB->AFR[1]|=(uint32_t)(0xB000); //PB11GPIOC->AFR[0]|=(uint32_t)(0xBB00B0); //PC1 PC4 PC5GPIOG->AFR[1]|=(uint32_t)(0xBB00000); //PG13 PG14GPIOA->OSPEEDR|=(uint32_t)(0xC03C); //PA1 PA2 PA7GPIOB->OSPEEDR|=(uint32_t)(0xC00000); //PB11GPIOC->OSPEEDR|=(uint32_t)(0xF0C); //PC1 PC4 PC5GPIOG->OSPEEDR|=(uint32_t)(0x3C000000); //PG13 PG14
初始化以太网MAC_DMA
//初始化ETH MAC层及DMA配置
//返回值:ETH_ERROR,发送失败(0)
// ETH_SUCCESS,发送成功(1)
u8 ETH_MAC_DMA_Config(void)
{u8 rval;ETH_InitTypeDef ETH_InitStructure; //使能以太网时钟RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_ETH_MAC | RCC_AHB1Periph_ETH_MAC_Tx |RCC_AHB1Periph_ETH_MAC_Rx, ENABLE);ETH_DeInit(); //AHB总线重启以太网ETH_SoftwareReset(); //软件重启网络while (ETH_GetSoftwareResetStatus() == SET);//等待软件重启网络完成 ETH_StructInit(Ð_InitStructure); //初始化网络为默认值 ///网络MAC参数设置 ETH_InitStructure.ETH_AutoNegotiation = ETH_AutoNegotiation_Enable; //开启网络自适应功能ETH_InitStructure.ETH_LoopbackMode = ETH_LoopbackMode_Disable; //关闭反馈ETH_InitStructure.ETH_RetryTransmission = ETH_RetryTransmission_Disable; //关闭重传功能ETH_InitStructure.ETH_AutomaticPadCRCStrip = ETH_AutomaticPadCRCStrip_Disable; //关闭自动去除PDA/CRC功能 ETH_InitStructure.ETH_ReceiveAll = ETH_ReceiveAll_Disable; //关闭接收所有的帧ETH_InitStructure.ETH_BroadcastFramesReception = ETH_BroadcastFramesReception_Enable;//允许接收所有广播帧ETH_InitStructure.ETH_PromiscuousMode = ETH_PromiscuousMode_Disable; //关闭混合模式的地址过滤 ETH_InitStructure.ETH_MulticastFramesFilter = ETH_MulticastFramesFilter_Perfect;//对于组播地址使用完美地址过滤 ETH_InitStructure.ETH_UnicastFramesFilter = ETH_UnicastFramesFilter_Perfect; //对单播地址使用完美地址过滤 ETH_InitStructure.ETH_ChecksumOffload = ETH_ChecksumOffload_Enable; //开启ipv4和TCP/UDP/ICMP的帧校验和卸载 //当我们使用帧校验和卸载功能的时候,一定要使能存储转发模式,存储转发模式中要保证整个帧存储在FIFO中,//这样MAC能插入/识别出帧校验值,当真校验正确的时候DMA就可以处理帧,否则就丢弃掉该帧ETH_InitStructure.ETH_DropTCPIPChecksumErrorFrame = ETH_DropTCPIPChecksumErrorFrame_Enable; //开启丢弃TCP/IP错误帧ETH_InitStructure.ETH_ReceiveStoreForward = ETH_ReceiveStoreForward_Enable; //开启接收数据的存储转发模式 ETH_InitStructure.ETH_TransmitStoreForward = ETH_TransmitStoreForward_Enable; //开启发送数据的存储转发模式 ETH_InitStructure.ETH_ForwardErrorFrames = ETH_ForwardErrorFrames_Disable; //禁止转发错误帧 ETH_InitStructure.ETH_ForwardUndersizedGoodFrames = ETH_ForwardUndersizedGoodFrames_Disable; //不转发过小的好帧 ETH_InitStructure.ETH_SecondFrameOperate = ETH_SecondFrameOperate_Enable; //打开处理第二帧功能ETH_InitStructure.ETH_AddressAlignedBeats = ETH_AddressAlignedBeats_Enable; //开启DMA传输的地址对齐功能ETH_InitStructure.ETH_FixedBurst = ETH_FixedBurst_Enable; //开启固定突发功能 ETH_InitStructure.ETH_RxDMABurstLength = ETH_RxDMABurstLength_32Beat; //DMA发送的最大突发长度为32个节拍 ETH_InitStructure.ETH_TxDMABurstLength = ETH_TxDMABurstLength_32Beat; //DMA接收的最大突发长度为32个节拍ETH_InitStructure.ETH_DMAArbitration = ETH_DMAArbitration_RoundRobin_RxTx_1_1;rval=ETH_Init(Ð_InitStructure,LAN8720_PHY_ADDRESS); //配置ETHif(rval==ETH_SUCCESS)//配置成功{ETH_DMAITConfig(ETH_DMA_IT_NIS|ETH_DMA_IT_R,ENABLE); //使能以太网接收中断 NVIC_InitTypeDef NVIC_InitStructure;NVIC_InitStructure.NVIC_IRQChannel = ETH_IRQn; //以太网中断NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 0; //中断寄存器组2最高优先级NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0;NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;NVIC_Init(&NVIC_InitStructure);ETH_MACAddressConfig(ETH_MAC_Address0,lwipdev.mac);printf("ETH Init Sucess\r\n");}return rval;
}- 这里 设置MAC地址 很重要,否则以太网无法接收自己的IP地址所对应的包!
ETH_MACAddressConfig(ETH_MAC_Address0,lwipdev.mac);
的是lwipdev.mac
这里的lwipdev.mac在lwip_comm.h中,在main函数中调用lwip_comm_init() 用来初始化lwip的底层设备和lwip内核,MAC地址在这个函数的lwip_comm_default_ip_set(&lwipdev); 中修改。
2. 这里一定要 开启ETH的DMA中断并且使能ETH_IRQn !
设置以太网DMA描述符 & DMA缓存的对应关系
rval=ETH_MAC_DMA_Config();if(rval==ETH_SUCCESS){printf("ETH init OK ");}else{printf("ETH init Failed ");}ETH_DMATxDescChainInit(DMATxDscrTab,Tx_Buff,ETH_TXBUFNB);//将接收描述符和接收缓存区关联起来 串成链式结构 初始化了发送追踪描述符ETH_DMARxDescChainInit(DMARxDscrTab,Rx_Buff,ETH_RXBUFNB);//将发送描述符和发送缓存区关联起来 串成链表 初始化了接收追踪描述符for(uint8_t i=0; i<ETH_TXBUFNB; i++){ETH_DMATxDescChecksumInsertionConfig(&DMATxDscrTab[i], ETH_DMATxDesc_ChecksumTCPUDPICMPFull);ETH_DMATxDescCRCCmd(&DMATxDscrTab[i],ENABLE);} ETH_Start();
后面
for(uint8_t i=0; i<ETH_TXBUFNB; i++)
{
ETH_DMATxDescChecksumInsertionConfig(&DMATxDscrTab[i],ETH_DMATxDesc_ChecksumTCPUDPICMPFull);
ETH_DMATxDescCRCCmd(&DMATxDscrTab[i],ENABLE);
}
设置了以太网TX发送描述缓存帧的和校验,这步是我在前面测试的时候发现的问题若没这段程序,以太网只可以发送ARP请求,TCP/UDP/ICMP等都发送出去的帧都是0和校验,形成错误帧,所以一定要开启TX缓存的和校验!
另一个需要注意的是一定要开启ETH!
ETH_Start();
在这里我贴出的这段程序,可以获得PHY芯片和外部协商的结果,可以验证设置的以太网是是否和外部PHY芯片通讯上。
//得到8720的速度模式
//返回值:
//001:10M半双工
//101:10M全双工
//010:100M半双工
//110:100M全双工
//其他:错误.
void LAN8720_Get_Speed(void)
{u8 speed;speed=((ETH_ReadPHYRegister(PHY_BCR,PHY_SR)&0x1C)>>2); //从LAN8720的31号寄存器中读取网络速度和双工模式switch(speed){case 1: printf("10M半双工\r\n"); break;case 5: printf("10M全双工\r\n"); break;case 2: printf("100M半双工\r\n"); break;case 6: printf("100M全双工\r\n"); break;default: printf("ETH 初始化失败 %d\r\n",speed); break;}
}
以太网接收中断函数
在前初始化了以太网中断,这里编写以太网中断函数
//以太网中断服务函数
void ETH_IRQHandler(void){if(ETH_CheckFrameReceived()){ETH_flag=1;}ETH_DMAClearITPendingBit(ETH_DMA_IT_R); //清除DMA中断标志位ETH_DMAClearITPendingBit(ETH_DMA_IT_NIS); //清除DMA接收中断标志位
} LWIP初始化
在LWIP底层硬件初始化
在这个函数中加入ETH初始化
static void low_level_init(struct netif *netif)

设置LWIP底层输入/ 输出函数
底层输入函数:
static struct pbuf * low_level_input(struct netif *netif)
底层输出函数:
static err_t low_level_output(struct netif *netif, struct pbuf *p)
修改这两个函数即可使用LWIP适配以太网(从这里看LWIP其实可以通过任何通讯方式运行,不只局限于ETH,只要是输入的是以太网帧格式的数据就可以,但是需要修改的部分较多,需要重新定义DMA描述符、追踪描述符、缓存的数据方向)。
LWIP输入处理
在while(1)中检测ETH中断函数的flg并且做出反应
if(ETH_flag){ETH_flag = 0;ethernetif_input(&lwip_netif);//调用网卡接收函数}
有两种ETH输入数据分解的方法, ETH中断是其中一种,但是实测发现了一个问题,当我把我的以太网线插入开发板<—>电脑 之间后,因为电脑一边从WIFI中获取数据一边会从以太网中尝试获取数据,于是会发生ETH超级频繁的进入ETH中断导致ETH这次的任务还没有处理完,下一次的任务标志位又被置为了导致出现了原子操作,也就是会出现数据量大的时候可能漏掉网络请求的情况,如图:

于是发现可以不使用ETH中断,禁用掉ETH中断,改用频率更高的while(1)大循环中循环检测,如图

在这里每一次大循环都会检测ETH输入帧是否收到,大大提高了实时响应性,ping命令不会出现遗漏的现象。
测试程序
ETH是否正常接收可以查看debug,这里贴出两个测试程序用来测试ETH是否可以正常发送
void ethernet_sendtest1(void){uint8_t frame_data[] ={/* 以太网帧格式 */0x50,0xFA,0x84,0x15,0x3C,0x3C, /* 远端MAC */0x0,0x80,0xE1,0x0,0x0,0x0, /* 本地MAC */0x8,0x0, /* ip类型 */0x45,0x0,0x0,0x26/*l*/,0x0,0x0,0x0,0x0,0xFF,0x11,0x0,0x0, /* UDP报头 */0xC0,0xA8,0x2,0x8, /* 本地IP */0xC0,0xA8,0x2,0xC2, /* 远端IP */0x22,0xB0, /* 本地端口 */0x22,0xB1, /* 远端端口 */0x0,0x12, /* UDP长度 */0x0,0x0, /* UDP校验和 */0x68,0x65,0x6C,0x6C,0x6F,0x20,0x7A,0x6F,0x72,0x62 /* 数据 */};struct pbuf *p;/* 分配缓冲区空间 */p = pbuf_alloc(PBUF_TRANSPORT, 0x26 + 14, PBUF_POOL);if (p != NULL){/* 填充缓冲区数据 */pbuf_take(p, frame_data, 0x26 + 14);/* 把数据直接通过底层发送 */lwip_netif.linkoutput(&lwip_netif, p);/* 释放缓冲区空间 */pbuf_free(p);}}void ethernet_sendtest2(void){uint8_t dstAddr[6] = {0x50,0xFA,0x84,0x15,0x3C,0x3C}; /* 远端MAC */uint8_t frame_data[] ={/* UDP帧格式 */0x45,0x0,0x0,0x26/*l*/,0x0,0x0,0x0,0x0,0xFF,0x11,0x0,0x0, /* UDP报头 */192,168,1,68, /* 本地IP */192,168,1,11, /* 远端IP */0x22,0xB0, /* 本地端口 */0x22,0xB1, /* 远端端口 */0x0,0x12, /* UDP长度 */0x0,0x0, /* UDP校验和 */1,2,3,4,5,6,6,6,6,6 /* 数据 */};struct pbuf *p;/* 分配缓冲区空间 */p = pbuf_alloc(PBUF_TRANSPORT, 0x26, PBUF_POOL);if (p != NULL){/* 填充缓冲区数据 */pbuf_take(p, frame_data, 0x26);/* 把数据进行以太网封装,再通过底层发送 */ethernet_output(&lwip_netif, p, (const struct eth_addr*)lwip_netif.hwaddr,(const struct eth_addr*)dstAddr, ETHTYPE_IP);/* 释放缓冲区空间 */pbuf_free(p);}}至此,ETH已经具备了运行LWIP并且可以PING了。
这里我修改IP地址和MAC,防止电脑内部MAC / ARP表影响测试结果

ping了好多次发现都可以,实验成功

总结一下,这里有很重要但是也很有可能会疏漏的几点:
- 设置为MCU设置MAC地址,有专门的一个函数用来为MCU设置自己ETH的MAC地址,否则无法接收到自己IP地址包。
- 配置DMA的描述符和缓存的关系,这也是有专门的函数用来初始化对应的关系,否则描述符无法和缓存对应起来,接收到的是乱码或者直接进入硬件错误中断
- 如果是外部SRAM的板子,ETH的TX/RX的30K缓存可以放到外部SRAM中,而占用300字节的设备描述符不可以放入外部SRAM,因为这些描述符是直接与内部ETH的DMA交互的,将这些描述符的内存指向外部RAM会导致读取不到描述符出现直接无法读取的现象。
- 开启每个TX缓存的和校验,有专门的函数,如果不设置TX缓存和校验会导致TX发送的所有数据的和校验都是0x00 在抓包软件中出现的是错误。
- 如果使用片内RAM存储缓存,可以调节ETH_TXBUFNB 或者 ETH_RXBUFNB 调节有多少个缓存区从而调节缓存区大小
- 经过我的实测,将RX/TX缓存BUFFER存放在外部SRAM中会有几率ping失败或者超时几个,存放在内部RAM会一直可以使用,怀疑是SRAM的速度影响了DMA搜索地址传输的速度,缓存存放在内部RAM效率高,失误率低,(是否有可能是cache的作用?)
处理以太网数据帧的三种方式对比
续:在写完这篇博客之后我再次重新理解了以太网响应数据的方式,在以太网使用中断检测可用的帧数据&大循环处理 / 直接在大循环中检测可用的帧&处理 / 以太网中断接收到置为标志位&大循环中处理这三种方法我都尝试了一下,
中断检测可使用的帧 & 大循环处理:
这里使用的是在中断中
//以太网中断服务函数
void ETH_IRQHandler(void){
if(ETH_CheckFrameReceived()){
ETH_flag=1;
}
ETH_DMAClearITPendingBit(ETH_DMA_IT_R); //清除DMA中断标志位
ETH_DMAClearITPendingBit(ETH_DMA_IT_NIS); //清除DMA接收中断标志位
}
大循环中
if(ETH_flag==1){
ETH_flag=0;
if(ETH_CheckFrameReceived()){
ethernetif_input(&lwip_netif);//调用网卡接收函数
}
}
这样实际测试发现因为在ETH_CheckFrameReceived( ) 这个函数中有这样一段
/* check if last segment */
if(((DMARxDescToGet->Status & ETH_DMARxDesc_OWN) == (uint32_t)RESET) &&
((DMARxDescToGet->Status & ETH_DMARxDesc_LS) != (uint32_t)RESET))
{
DMA_RX_FRAME_infos->Seg_Count++;
if (DMA_RX_FRAME_infos->Seg_Count == 1)
{
DMA_RX_FRAME_infos->FS_Rx_Desc = DMARxDescToGet;
}
DMA_RX_FRAME_infos->LS_Rx_Desc = DMARxDescToGet;
return 1;
}
这里可以看到它会不断更新是否是最新的缓存区域,如果不是,则++缓存到另一个,但是这样当中断正在检测frame的时候又发生了中断,会直接导致frame检测混乱,count++了之后又++,正在处理上一个事件的时候又被后半部分指到了下一个事件的数据,所以 ETH_CheckFrameReceived( ) 这个函数不可重入!!,实际测发现这样有概率成功ping通几个包,大部分因为网络频繁进中断导致了无法ping通,那么在中断检测帧在大循环处理这个方法PASS
直接在大循环里检测 & 处理
例如:
if(ETH_CheckFrameReceived()){
ethernetif_input(&lwip_netif);//调用网卡接收函数
}
直接在while(1)中不断检测,这样的好处是可以一直检测,有任何帧被发现都会处理,缺点是这样会占用大量MCU资源,当任务多了之后会发现检测不是很及时,并且会拖累其他任务的响应,直接导致系统响应慢。
中断置位标志位累加 & 大循环处理
这里我使用的是在中断中给需要处理的事件++
//以太网中断服务函数
void ETH_IRQHandler(void){
if(ETH_CheckFrameReceived()){
ETH_flag++;
}
ETH_DMAClearITPendingBit(ETH_DMA_IT_R); //清除DMA中断标志位
ETH_DMAClearITPendingBit(ETH_DMA_IT_NIS); //清除DMA接收中断标志位
}
这样相当于记录了有多少个事件应该被处理
在大循环中处理
if(ETH_flag){
ETH_flag–;
ethernetif_input(&lwip_netif);//调用网卡接收函数
printf(“ETH_flag=%d\r\n”,ETH_flag);
}
这样既不会发生frame检测重入,又可以即使处理所有缓存中的事件!!
实测效果如下:
在debug界面,最多发生一次剩余缓存未处理,并且可以看到后面已经即使处理了

在ping响应中,往返小于1ms

之前方法2全部在while中处理的时候的时间是2-3ms:

所以方法3无论是响应速度或者是处理数据的数量来说都是比较合理的,如果又更好的方法欢迎私信我!
源码获取
文件链接:
通过网盘分享的文件:CSDN_ETH.rar
链接: https://pan.baidu.com/s/15UMS1rLIsaaPfxGsWYXK9Q?pwd=kg2m 提取码: kg2m
相关文章:
网络通信---MCU移植LWIP
使用的MCU型号为STM32F429IGT6,PHY为LAN7820A 目标是通过MCU的ETH给LWIP提供输入输出从而实现基本的Ping应答 OK废话不多说我们直接开始 下载源码 LWIP包源码:lwip源码 -在这里下载 ST官方支持的ETH包:ST-ETH支持包 这里下载 创建工程 …...

Go-并行编程新手指南
Go 并行编程新手指南 在Go语言中,并行编程是充分利用多核CPU资源、提升程序性能的重要手段。它的核心概念包括goroutine和channel,这些特性使得Go在处理并发任务时表现出色。 goroutine:轻量级的并发执行单元 goroutine是Go并行编程的基础…...

基于Django的个人博客系统的设计与实现
【Django】基于Django的个人博客系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 系统采用Python作为主要开发语言,结合Django框架构建后端逻辑,并运用J…...

Python爬虫获取custom-1688自定义API操作接口
一、引言 在电子商务领域,1688作为国内领先的B2B平台,提供了丰富的API接口,允许开发者获取商品信息、店铺信息等。其中,custom接口允许开发者进行自定义操作,获取特定的数据。本文将详细介绍如何使用Python调用1688的…...

kaggle-ISIC 2024 - 使用 3D-TBP 检测皮肤癌-学习笔记
问题描述: 通过从 3D 全身照片 (TBP) 中裁剪出单个病变来识别经组织学确诊的皮肤癌病例 数据集描述: 图像临床文本信息 评价指标: pAUC,用于保证敏感性高于指定阈值下的AUC 主流方法分析(文本) 基于CatBoo…...

滤波电路汇总
0、前言 1. 引言 滤波电路是电子系统中不可或缺的组成部分,其主要功能是选择性地通过或衰减特定频率范围内的信号。在现代电子技术中,滤波电路广泛应用于信号处理、通信系统、音频设备、电源设计等多个领域。通过滤波,可以去除信号中的噪声和干扰,提高信号的质量和稳定性…...

1.Template Method 模式
模式定义 定义一个操作中的算法的骨架(稳定),而将一些步骤延迟(变化)到子类中。Template Method 使得子类可以不改变(复用)一个算法的结构即可重定义(override 重写)该算法的某些特…...

MySQL分表自动化创建的实现方案(存储过程、事件调度器)
《MySQL 新年度自动分表创建项目方案》 一、项目目的 在数据库应用场景中,随着数据量的不断增长,单表存储数据可能会面临性能瓶颈,例如查询、插入、更新等操作的效率会逐渐降低。分表是一种有效的优化策略,它将数据分散存储在多…...

基于回归分析法的光伏发电系统最大功率计算simulink建模与仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于回归分析法的光伏发电系统最大功率计算simulink建模与仿真。选择回归法进行最大功率点的追踪,使用光强和温度作为影响因素,电压作为输出进行建模。…...

计算机毕业设计【任务书】怎么写?
1. 什么是毕业设计任务书 毕业设计任务书是学生在毕业设计初期向指导教师提交的文档,主要用于说明毕业设计的选题、研究内容、目标、方法、进度安排等。 2. 撰写任务书的步骤 2.1 确定选题 选题是撰写任务书的第一步。选题应结合自身兴趣、专业方向和实际应用需…...

GRAPHARG——学习
20250106 项目git地址:https://github.com/microsoft/graphrag.git 版本:1.2.0 ### This config file contains required core defaults that must be set, along with a handful of common optional settings. ### For a full list of available setti…...

【Rust自学】15.6. RefCell与内部可变性:“摆脱”安全性限制
题外话,这篇文章一共4050字,是截止到目前为止最长的文章,如果你能坚持读完并理解,那真的很强! 喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以…...

14.模型,纹理,着色器
模型、纹理和着色器是计算机图形学中的三个核心概念,用通俗易懂的方式来解释: 1. 模型:3D物体的骨架 通俗解释: 模型就像3D物体的骨架,定义了物体的形状和结构。 比如,一个房子的模型包括墙、屋顶、窗户等…...

【C语言分支与循环结构详解】
目录 ---------------------------------------begin--------------------------------------- 一、分支结构 1. if语句 2. switch语句 二、循环结构 1. for循环 2. while循环 3. do-while循环 三、嵌套结构 结语 -----------------------------------------end----…...

新项目上传gitlab
Git global setup git config --global user.name “FUFANGYU” git config --global user.email “fyfucnic.cn” Create a new repository git clone gitgit.dev.arp.cn:casDs/sawrd.git cd sawrd touch README.md git add README.md git commit -m “add README” git push…...

qt-QtQuick笔记之常见项目类简要介绍
qt-QtQuick笔记之常见项目类简要介绍 code review! 文章目录 qt-QtQuick笔记之常见项目类简要介绍1.QQuickItem2.QQuickRectangle3.QQuickImage4.QQuickText5.QQuickBorderImage6.QQuickTextInput7.QQuickButton8.QQuickSwitch9.QQuickListView10.QQuickGridView11.QQuickPopu…...

Continuous Batching 连续批处理
原始论文题目: Continuous Batching — ORCA: a distributed serving system for Transformer-based generative models 关键词: Continuous Batching, iteration-level scheduling, selective batching 1.迭代级调度(iteration-level scheduling) Orca系统又由几个关键…...

海外问卷调查渠道查如何设置:最佳实践+示例
随着经济全球化和一体化进程的加速,企业间的竞争日益加剧,为了获得更大的市场份额,对企业和品牌而言,了解受众群体的的需求、偏好和痛点才是走向成功的关键。而海外问卷调查才是获得受众群体痛点的关键,制作海外问卷调…...

把本地搭建的hexo博客部署到自己的服务器上
配置远程服务器的git 安装git 安装依赖工具包 yum install -y curl-devel expat-devel gettext-devel openssl-devel zlib-devel安装编译工具 yum install -y gcc perl-ExtUtils-MakeMaker package下载git,也可以去官网下载了传到服务器上 wget https://www.ke…...

初阶数据结构:链表(二)
目录 一、前言 二、带头双向循环链表 1.带头双向循环链表的结构 (1)什么是带头? (2)什么是双向呢? (3)那什么是循环呢? 2.带头双向循环链表的实现 (1)节点结构 (2…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

【安全篇】金刚不坏之身:整合 Spring Security + JWT 实现无状态认证与授权
摘要 本文是《Spring Boot 实战派》系列的第四篇。我们将直面所有 Web 应用都无法回避的核心问题:安全。文章将详细阐述认证(Authentication) 与授权(Authorization的核心概念,对比传统 Session-Cookie 与现代 JWT(JS…...
GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比Grap…...
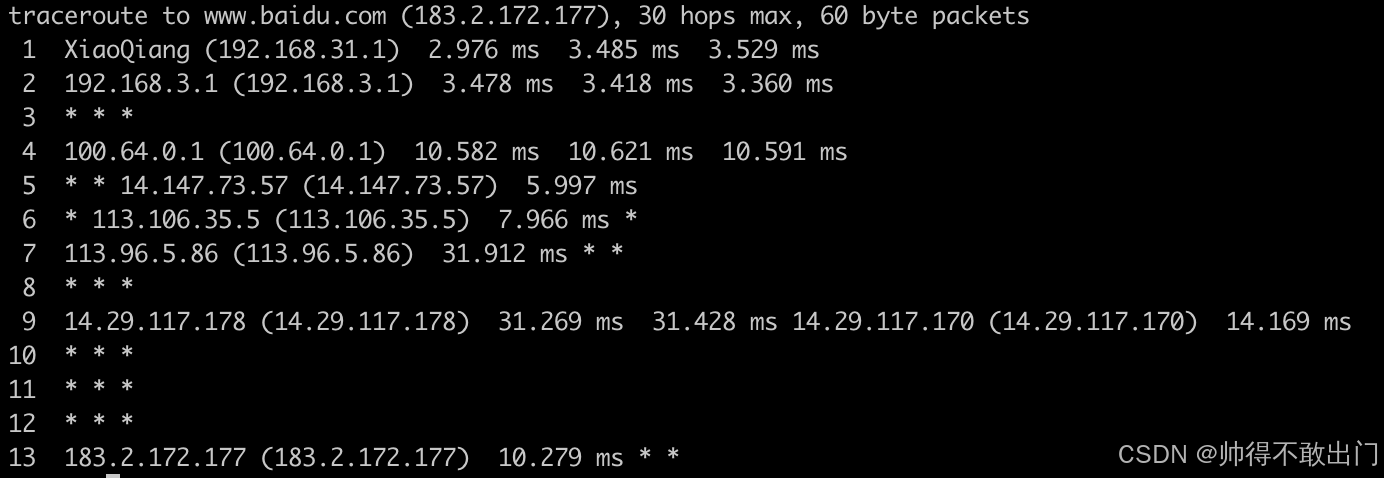
Android Framework预装traceroute执行文件到system/bin下
文章目录 Android SDK中寻找traceroute代码内置traceroute到SDK中traceroute参数说明-I 参数(使用 ICMP Echo 请求)-T 参数(使用 TCP SYN 包) 相关文章 Android SDK中寻找traceroute代码 设备使用的是Android 11,在/s…...