八股——Java基础(四)
目录
一、泛型
1. Java中的泛型是什么 ?
2. 使用泛型的好处是什么?
3. Java泛型的原理是什么 ? 什么是类型擦除 ?
4.什么是泛型中的限定通配符和非限定通配符 ?
5. List和List 之间有什么区别 ?
6. 可以把List传递给一个接受List
7. Array中可以用泛型吗?
8. 判断ArrayList与ArrayList是否相等?
二、序列化
1. Java序列化与反序列化是什么?
2. 为什么需要序列化与反序列化?
3. 序列化实现的方式有哪些?
3.1 Serializable接口
3.2 Externalizable接口
3.3 两种序列化的对比
4. 什么是serialVersionUID?
5. 为什么还要显示指定serialVersionUID的值?
6. Java 序列化中如果有些字段不想进行序列化,怎么办?
7. 静态变量会被序列化吗?
一、泛型
1. Java中的泛型是什么 ?
泛型是 JDK1.5 的一个新特性,泛型就是将类型参数化,其在编译时才确定具体的参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
2. 使用泛型的好处是什么?
远在 JDK 1.4 版本的时候,那时候是没有泛型的概念的,如果使用 Object 来实现通用、不同类型的处理,有这么两个缺点:
(1)每次使用时都需要强制转换成想要的类型
(2)在编译时编译器并不知道类型转换是否正常,运行时才知道,不安全。
如这个例子:
List list = new ArrayList();
list.add("www.cnblogs.com");
list.add(23);
String name = (String)list.get(0);
String number = (String)list.get(1); //ClassCastException上面的代码在运行时会发生强制类型转换异常。这是因为我们在存入的时候,第二个是一个 Integer 类型,但是取出来的时候却将其强制转换为 String 类型了。Sun 公司为了使 Java 语言更加安全,减少运行时异常的发生。于是在 JDK 1.5 之后推出了泛型的概念。
根据《Java 编程思想》中的描述,泛型出现的动机在于:有许多原因促成了泛型的出现,而最引人注意的一个原因,就是为了创建容器类。
使用泛型的好处有以下几点:
(1)类型安全
-
泛型的主要目标是提高 Java 程序的类型安全
-
编译时期就可以检查出因 Java 类型不正确导致的 ClassCastException 异常
-
符合越早出错代价越小原则
(2)消除强制类型转换
-
泛型的一个附带好处是,使用时直接得到目标类型,消除许多强制类型转换
-
所得即所需,这使得代码更加可读,并且减少了出错机会
(3)潜在的性能收益
-
由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改
-
所有工作都在编译器中完成
-
编译器生成的代码跟不使用泛型(和强制类型转换)时所写的代码几乎一致,只是更能确保类型安全而已
3. Java泛型的原理是什么 ? 什么是类型擦除 ?
泛型是一种语法糖,泛型这种语法糖的基本原理是类型擦除。Java中的泛型基本上都是在编译器这个层次来实现的,也就是说:泛型只存在于编译阶段,而不存在于运行阶段。在编译后的 class 文件中,是没有泛型这个概念的。
类型擦除:使用泛型的时候加上的类型参数,编译器在编译的时候去掉类型参数。
例如:
public class Caculate<T> {private T num;
}我们定义了一个泛型类,定义了一个属性成员,该成员的类型是一个泛型类型,这个 T 具体是什么类型,我们也不知道,它只是用于限定类型的。反编译一下这个 Caculate 类:
public class Caculate{public Caculate(){}private Object num;
}发现编译器擦除 Caculate 类后面的两个尖括号,并且将 num 的类型定义为 Object 类型。
那么是不是所有的泛型类型都以 Object 进行擦除呢?大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。那就是使用到了extends和super语法的有界类型,如:
public class Caculate<T extends String> {private T num;
}这种情况的泛型类型,num 会被替换为 String 而不再是 Object。这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类,也就是你构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类,所以无论你限定 T 为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
实际上编译器会正常的将使用泛型的地方编译并进行类型擦除,然后返回实例。但是除此之外的是,如果构建泛型实例时使用了泛型语法,那么编译器将标记该实例并关注该实例后续所有方法的调用,每次调用前都进行安全检查,非指定类型的方法都不能调用成功。
实际上编译器不仅关注一个泛型方法的调用,它还会为某些返回值为限定的泛型类型的方法进行强制类型转换,由于类型擦除,返回值为泛型类型的方法都会擦除成 Object 类型,当这些方法被调用后,编译器会额外插入一行 checkcast 指令用于强制类型转换。这一个过程就叫做『泛型翻译』。
4.什么是泛型中的限定通配符和非限定通配符 ?
限定通配符对类型进行了限制。有两种限定通配符,一种是<? extends T>它通过确保类型必须是T的子类来设定类型的上界,另一种是<? super T>它通过确保类型必须是T的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。
非限定通配符 ?,可以用任意类型来替代。如List<?> 的意思是这个集合是一个可以持有任意类型的集合,它可以是List<A>,也可以是List<B>,或者List<C>等等。
5. List<? extends T>和List <? super T>之间有什么区别 ?
这两个List的声明都是限定通配符的例子,List<? extends T>可以接受任何继承自T的类型的List,而List<? super T>可以接受任何T的父类构成的List。例如List<? extends Number>可以接受List<Integer>或List<Float>。
6. 可以把List<String>传递给一个接受List<Object>参数的方法吗?
不可以。真这样做的话会导致编译错误。因为List<Object>可以存储任何类型的对象包括String, Integer等等,而List<String>却只能用来存储String。
List<Object> objectList;
List<String> stringList;
objectList = stringList; //compilation error incompatible types7. Array中可以用泛型吗?
不可以。这也是为什么 Joshua Bloch 在 《Effective Java》一书中建议使用 List 来代替 Array,因为 List 可以提供编译期的类型安全保证,而 Array 却不能。
8. 判断ArrayList<String>与ArrayList<Integer>是否相等?
ArrayList<String> a = new ArrayList<String>();
ArrayList<Integer> b = new ArrayList<Integer>();
Class c1 = a.getClass();
Class c2 = b.getClass();
System.out.println(c1 == c2); 输出的结果是 true。因为无论对于 ArrayList 还是 ArrayList,它们的 Class 类型都是一直的,都是 ArrayList.class。那它们声明时指定的 String 和 Integer 到底体现在哪里呢?
答案是体现在类编译的时候。当 JVM 进行类编译时,会进行泛型检查,如果一个集合被声明为 String 类型,那么它往该集合存取数据的时候就会对数据进行判断,从而避免存入或取出错误的数据。
二、序列化
1. Java序列化与反序列化是什么?
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程:
-
序列化:序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。核心作用是对象状态的保存与重建。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。把Java对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
-
反序列化:客户端从文件中或网络上获得序列化后的对象字节流,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
2. 为什么需要序列化与反序列化?
简要描述:对内存中的对象进行持久化或网络传输, 这个时候都需要序列化和反序列化
深入描述:
(1)对象序列化可以实现分布式对象。
主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
(2)java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。
可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
(3)序列化可以将内存中的类写入文件或数据库中。
比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。
总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
(4)对象、文件、数据,有许多不同的格式,很难统一传输和保存。
序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件。
3. 序列化实现的方式有哪些?
实现Serializable接口或者Externalizable接口。
3.1 Serializable接口
类通过实现 java.io.Serializable 接口以启用其序列化功能。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
如以下例子:
import java.io.Serializable;public class User implements Serializable {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "User{" +"name='" + name +'}';}
}通过下面的代码进行序列化及反序列化:
public class SerializableDemo {public static void main(String[] args) {//Initializes The ObjectUser user = new User();user.setName("cosen");System.out.println(user);//Write Obj to Filetry (FileOutputStream fos = new FileOutputStream("tempFile"); ObjectOutputStream oos = new ObjectOutputStream(fos)) {oos.writeObject(user);} catch (IOException e) {e.printStackTrace();}//Read Obj from FileFile file = new File("tempFile");try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))) {User newUser = (User)ois.readObject();System.out.println(newUser);} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}}
}//OutPut:
//User{name='cosen'}
//User{name='cosen'}3.2 Externalizable接口
Externalizable继承自Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。
当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法。否则所有变量的值都会变成默认值。
public class User implements Externalizable {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public void writeExternal(ObjectOutput out) throws IOException {out.writeObject(name);}public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {name = (String) in.readObject();}@Overridepublic String toString() {return "User{" +"name='" + name +'}';}
}通过下面的代码进行序列化及反序列化:
public class ExternalizableDemo1 {public static void main(String[] args) {//Write Obj to fileUser user = new User();user.setName("cosen");try(ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"))){oos.writeObject(user);} catch (IOException e) {e.printStackTrace();}//Read Obj from fileFile file = new File("tempFile");try(ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))){User newInstance = (User) ois.readObject();//outputSystem.out.println(newInstance);} catch (IOException | ClassNotFoundException e ) {e.printStackTrace();}}
}//OutPut:
//User{name='cosen'}3.3 两种序列化的对比

4. 什么是serialVersionUID?
serialVersionUID 用来表明类的不同版本间的兼容性
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
5. 为什么还要显示指定serialVersionUID的值?
如果不显示指定serialVersionUID, JVM在序列化时会根据属性自动生成一个serialVersionUID, 然后与属性一起序列化, 再进行持久化或网络传输. 在反序列化时, JVM会再根据属性自动生成一个新版serialVersionUID, 然后将这个新版serialVersionUID与序列化时生成的旧版serialVersionUID进行比较, 如果相同则反序列化成功, 否则报错.
如果显示指定了, JVM在序列化和反序列化时仍然都会生成一个serialVersionUID, 但值为我们显示指定的值, 这样在反序列化时新旧版本的serialVersionUID就一致了.
在实际开发中, 不显示指定serialVersionUID的情况会导致什么问题? 如果我们的类写完后不再修改, 那当然不会有问题, 但这在实际开发中是不可能的, 我们的类会不断迭代, 一旦类被修改了, 那旧对象反序列化就会报错. 所以在实际开发中, 我们都会显示指定一个serialVersionUID, 值是多少无所谓, 只要不变就行。
6. Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。transient 只能修饰变量,不能修饰类和方法。
7. 静态变量会被序列化吗?
不会。因为序列化是针对对象而言的, 而静态变量优先于对象存在, 随着类的加载而加载, 所以不会被序列化.
看到这个结论, 是不是有人会问, serialVersionUID也被static修饰, 为什么serialVersionUID会被序列化? 其实serialVersionUID属性并没有被序列化, JVM在序列化对象时会自动生成一个serialVersionUID, 然后将我们显示指定的serialVersionUID属性值赋给自动生成的serialVersionUID。

相关文章:
八股——Java基础(四)
目录 一、泛型 1. Java中的泛型是什么 ? 2. 使用泛型的好处是什么? 3. Java泛型的原理是什么 ? 什么是类型擦除 ? 4.什么是泛型中的限定通配符和非限定通配符 ? 5. List和List 之间有什么区别 ? 6. 可以把List传递给一个接受List参数的方法吗? 7. Arra…...

CVE-2023-38831 漏洞复现:win10 压缩包挂马攻击剖析
目录 前言 漏洞介绍 漏洞原理 产生条件 影响范围 防御措施 复现步骤 环境准备 具体操作 前言 在网络安全这片没有硝烟的战场上,新型漏洞如同隐匿的暗箭,时刻威胁着我们的数字生活。其中,CVE - 2023 - 38831 这个关联 Win10 压缩包挂…...

【自然语言处理(NLP)】深度循环神经网络(Deep Recurrent Neural Network,DRNN)原理和实现
文章目录 介绍深度循环神经网络(DRNN)原理和实现结构特点工作原理符号含义公式含义 应用领域优势与挑战DRNN 代码实现 个人主页:道友老李 欢迎加入社区:道友老李的学习社区 介绍 **自然语言处理(Natural Language Pr…...
)
Linux 命令之技巧(Tips for Linux Commands)
Linux 命令之技巧 简介 Linux 是一种免费使用和自由传播的类Unix操作系统,其内核由林纳斯本纳第克特托瓦兹(Linus Benedict Torvalds)于1991年10月5日首次发布。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户…...

【文星索引】搜索引擎项目测试报告
目录 一、项目背景二、 项目功能2.1 数据收集与索引2.2 API搜索功能2.3 用户体验与界面设计2.4 性能优化与维护 三、测试报告3.1 功能测试3.2 界面测试3.3 性能测试3.4 兼容性测试3.5 自动化测试 四、测试总结4.1 功能测试方面4.2 性能测试方面4.3 用户界面测试方面 一、项目背…...

低代码系统-产品架构案例介绍、轻流(九)
轻流低代码产品定位为零代码产品,试图通过搭建来降低企业成本,提升业务上线效率。 依旧是从下至上,从左至右的顺序 名词概述运维层底层系统运维层,例如上线、部署等基础服务体系内置的系统能力,发消息、组织和权限是必…...

二叉树(补充)
二叉树 1.二叉树的基本特性2.堆2.1.堆的基本概念2.2.堆的实现2.2.1.基本结构2.2.2.堆的初始化 2.2.3.堆的销毁2.2.4.堆的插入2.2.5.取出堆顶的数据2.2.6.堆的删除2.2.7.堆的判空2.2.8.堆的数据个数2.2.9.交换2.2.10.打印堆数据2.2.11.堆的创建2.2.12.堆排序 1.二叉树的基本特性…...
达梦数据库基本操作(持续更新))
(DM)达梦数据库基本操作(持续更新)
1、连接达梦数据库 ./disql 用户明/"密码"IP端口或者域名 2、进入某个模式(数据库,因达梦数据库没有库的概念,只有模式,可以将模式等同于库) set schema 库名; 3、查表结构; SELECT COLUMN_NAM…...

CRM 微服务
文章目录 项目地址一、项目地址 教程作者:教程地址:代码仓库地址:所用到的框架和插件:dbt airflow一、 用户与认证服务 主要功能: 用户注册、登录、注销。 认证(OAuth、JWT 等)。 权限和角色管理(RBAC/ABAC)。 单点登录(SSO)。 技术亮点: 集成第三方身份认证(如 …...

AI软件外包需要注意什么 外包开发AI软件的关键因素是什么 如何选择AI外包开发语言
1. 定义目标与需求 首先,要明确你希望AI智能体做什么。是自动化任务、数据分析、自然语言处理,还是其他功能?明确目标可以帮助你选择合适的技术和方法。 2. 选择开发平台与工具 开发AI智能体的软件时,你需要选择适合的编程语言、…...

DBSyncer开源数据同步中间件
一、简介 DBSyncer(英[dbsɪŋkɜː(r)],美[dbsɪŋkɜː(r) 简称dbs)是一款开源的数据同步中间件,提供MySQL、Oracle、SqlServer、PostgreSQL、Elasticsearch(ES)、Kafka、File、SQL等同步场景。支持上传插件自定义同步转换业务,提供监控全量…...

< OS 有关 > 阿里云 几个小时前 使用密钥替换 SSH 密码认证后, 发现主机正在被“攻击” 分析与应对
信息来源: 文件:/var/log/auth.log 因为在 sshd_config 配置文件中,已经定义 LogLevel INFO 部分内容: 2025-01-27T18:18:55.68272708:00 jpn sshd[15891]: Received disconnect from 45.194.37.171 port 58954:11: Bye Bye […...

react-bn-面试
1.主要内容 工作台待办 实现思路: 1,待办list由后端返回,固定需要的字段有id(查详细)、type(本条待办的类型),还可能需要时间,状态等 2,一个集中处理待办中转路由页,所有待办都跳转到这个页面…...

1. Java-MarkDown文件创建-工具类
Java-MarkDown文件创建-工具类 1. 思路 根据markdown语法,拼装markdown文本内容 2. 工具类 import java.util.Arrays; import java.util.List;/*** Markdown生成工具类* Author: 20004855* Date: 2021/1/15 16:00*/ public class MarkdownGenerator {private Str…...

全连接神经网络(前馈神经网络)
一、全连接神经网络介绍 在多层神经网络中, 第 N 层的每个神经元都分别与第 N-1 层的神经元相互连接。 1、神经元 这个神经元接收的输入信号为向量 , 向量为输入向量的组合权重, 为偏置项, 是一个标量。 神经元的作用是对输入向…...

【llm对话系统】什么是 LLM?大语言模型新手入门指南
什么是 LLM?大语言模型新手入门指南 大家好!欢迎来到 LLM 的奇妙世界!如果你对人工智能 (AI) 的最新进展,特别是那些能像人类一样阅读、写作甚至进行对话的 AI 感兴趣,那么你来对地方了。这篇文章将带你认识 LLM 的基…...

【Linux】互斥锁、基于阻塞队列、环形队列的生产消费模型、单例线程池
⭐️个人主页:小羊 ⭐️所属专栏:Linux 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 1、互斥锁2、生产消费模型2.1 阻塞队列2.2 环形队列 3、单例线程池4、线程安全和重入问题 1、互斥锁 临界资源:多线程…...

【学术会议征稿】第五届能源、电力与先进热力系统学术会议(EPATS 2025)
能源、电力与先进热力系统设计是指结合物理理论、工程技术和计算机模拟,对能源转换、利用和传输过程进行设计的学科领域。它涵盖了从能源的生产到最终的利用整个流程,旨在提高能源利用效率,减少能源消耗和环境污染。 重要信息 官网…...

ES6 类语法:JavaScript 的现代化面向对象编程
Hi,我是布兰妮甜 !ECMAScript 2015,通常被称为 ES6 或 ES2015,是 JavaScript 语言的一次重大更新。它引入了许多新特性,其中最引人注目的就是类(class)语法。尽管 JavaScript 一直以来都支持基于…...

Sprintboot原理
配置优先级 Springboot中支持的三种配置文件: application.propertiesapplication.ymlapplication.yaml java系统属性:-Dxxxxxx 命令行参数:-xxxxxx 优先级:命令行参数>java系统属性>application.properties>applicat…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...
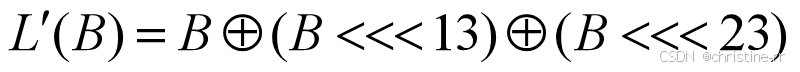
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

负载均衡器》》LVS、Nginx、HAproxy 区别
虚拟主机 先4,后7...