从TinyZero的数据与源码来理解DeepSeek-R1-Zero的强化学习训练过程
1. 引入
TinyZero(参考1)是伯克利的博士生复现DeepSeek-R1-Zero的代码参仓库,他使用veRL来运行RL强化学习方法,对qwen2.5的0.5B、1.5B、3B等模型进行训练,在一个数字游戏数据集上,达到了较好的推理效果。
下面解读源码中的关键训练逻辑细节。
2. 训练过程
- 原始数据
原始数据来自参考2,一共490k条数据,数据中只有两个字段,格式如下:
{"nums": [ 95, 11, 56 ],"target":28
}
这是一个数字游戏,要求对nums中的数据,进行基础数学运算(+, -, *, /),每个数字只能用一次,最终结果等于target的值。比如上例子,95-11-56=28。
- 数据处理
具体源码见参考3,下文仅仅解析关键步骤:
(1)训练集和测试集大小
默认值如下:
parser.add_argument('--train_size', type=int, default=327680)
parser.add_argument('--test_size', type=int, default=1024)
(2)对原始数据添加提示词
下面的dp就是一条原始数据(参考2.1例子):
def make_prefix(dp, template_type):target = dp['target']# 取出目标numbers = dp['nums']# 取出数字# 对于默认模型加的提示词如下if template_type == 'base':"""This works for any base model"""prefix = f"""A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
User: Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
Assistant: Let me solve this step by step.
<think>"""# 对于qwen-instruct模型加的提示词如下elif template_type == 'qwen-instruct':"""This works for Qwen Instruct Models"""prefix = f"""<|im_start|>system\nYou are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.<|im_end|>\n<|im_start|>user\n Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.<|im_end|>\n<|im_start|>assistant\nLet me solve this step by step.\n<think>"""return prefix
(3)对数据进行完整的处理,增加提示词与reward等数据
如下函数中的example就是一条原始数据(参考2.1例子)。
def process_fn(example, idx):question = make_prefix(example, template_type=args.template_type) # 增加提示词,见2.2.2solution = {"target": example['target'],"numbers": example['nums']}data = {"data_source": data_source, # 任务名称,默认为'countdown'"prompt": [{"role": "user","content": question, # 带有提示词的问题}],"ability": "math","reward_model": {"style": "rule","ground_truth": solution # 含有nums和target},"extra_info": {'split': split,'index': idx,}}return data
最终数据为含有prompt和reward_model等字段的json结构。
- 训练
从参考4的训练代码中,摘取部分配置如下:
python3 -m verl.trainer.main_ppo \
data.train_files=$DATA_DIR/train.parquet \
data.val_files=$DATA_DIR/test.parquet \
data.train_batch_size=256 \
data.val_batch_size=1312 \
data.max_prompt_length=256 \
data.max_response_length=1024 \
actor_rollout_ref.model.path=$BASE_MODEL \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=128 \
actor_rollout_ref.actor.ppo_micro_batch_size=8 \
actor_rollout_ref.rollout.log_prob_micro_batch_size=8 \
actor_rollout_ref.rollout.tensor_model_parallel_size=$ROLLOUT_TP_SIZE \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
actor_rollout_ref.ref.log_prob_micro_batch_size=4 \
critic.optim.lr=1e-5 \
critic.model.path=$BASE_MODEL \
critic.ppo_micro_batch_size=8 \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.logger=['wandb'] \
+trainer.val_before_train=False \
trainer.default_hdfs_dir=null \
trainer.n_gpus_per_node=$N_GPUS \
trainer.nnodes=1 \
trainer.save_freq=100 \
trainer.test_freq=100 \
trainer.project_name=TinyZero \
trainer.experiment_name=$EXPERIMENT_NAME \
trainer.total_epochs=15 2>&1 | tee verl_demo.log
这条命令是一个典型的 Python 脚本调用,用于训练一个基于 PPO(Proximal Policy Optimization) 算法的模型。
用veRL进行训练(参考5),需要指定 数据、模型、超参数:
(1)数据相关配置
data.train_files=$DATA_DIR/train.parquet:指定训练数据文件路径(Parquet 格式)。data.val_files=$DATA_DIR/test.parquet:指定验证数据文件路径。data.train_batch_size=256:训练时的批量大小(batch size)。data.val_batch_size=1312:验证时的批量大小。data.max_prompt_length=256:输入提示(prompt)的最大长度。data.max_response_length=1024:生成响应(response)的最大长度。
(2)Actor 模型配置
actor_rollout_ref.model.path=$BASE_MODEL:指定 Actor 模型的预训练权重路径。actor_rollout_ref.actor.optim.lr=1e-6:Actor 模型的学习率。actor_rollout_ref.actor.ppo_mini_batch_size=128:PPO 算法中 Actor 的 mini-batch 大小。actor_rollout_ref.actor.ppo_micro_batch_size=8:PPO 算法中 Actor 的 micro-batch 大小。actor_rollout_ref.rollout.log_prob_micro_batch_size=8:Rollout 阶段计算 log probability 的 micro-batch 大小。actor_rollout_ref.rollout.tensor_model_parallel_size=$ROLLOUT_TP_SIZE:Rollout 阶段的张量并行大小(用于分布式训练)。actor_rollout_ref.rollout.gpu_memory_utilization=0.4:Rollout 阶段的 GPU 内存利用率。actor_rollout_ref.ref.log_prob_micro_batch_size=4:参考模型(ref model)计算 log probability 的 micro-batch 大小。
(3)Critic 模型配置
critic.optim.lr=1e-5:Critic 模型的学习率。critic.model.path=$BASE_MODEL:指定 Critic 模型的预训练权重路径。critic.ppo_micro_batch_size=8:PPO 算法中 Critic 的 micro-batch 大小。
(4)算法配置
algorithm.kl_ctrl.kl_coef=0.001:KL 散度(Kullback-Leibler divergence)的系数,用于控制策略更新的稳定性。
(5)训练器配置
trainer.logger=['wandb']:使用 Weights & Biases(WandB)作为日志记录工具。+trainer.val_before_train=False:在训练开始前不进行验证。trainer.default_hdfs_dir=null:HDFS 目录未设置(HDFS 是分布式文件系统)。trainer.n_gpus_per_node=$N_GPUS:每个节点使用的 GPU 数量。trainer.nnodes=1:使用的节点数量(单节点训练)。trainer.save_freq=100:每 100 步保存一次模型。trainer.test_freq=100:每 100 步进行一次测试。trainer.project_name=TinyZero:WandB 项目名称。trainer.experiment_name=$EXPERIMENT_NAME:实验名称。trainer.total_epochs=15:总训练轮数(epochs)。
- 训练效果
用强化学习的方法训练后,能如下所示,输出字段(推理过程),并给出最终结果字段。

3. 总结
通过具体的数据与处理训练过程,来更好的理解DeepSeek-R1-Zero的强化学习训练方法。
4. 参考
- 项目:https://github.com/Jiayi-Pan/TinyZero
- 数据:https://huggingface.co/datasets/Jiayi-Pan/Countdown-Tasks-3to4
- 数据处理源码:https://github.com/Jiayi-Pan/TinyZero/blob/main/examples/data_preprocess/countdown.py
- 训练源码:https://github.com/Jiayi-Pan/TinyZero/blob/main/scripts/train_tiny_zero.sh
- veRL:https://verl.readthedocs.io/en/latest/start/quickstart.html
相关文章:
从TinyZero的数据与源码来理解DeepSeek-R1-Zero的强化学习训练过程
1. 引入 TinyZero(参考1)是伯克利的博士生复现DeepSeek-R1-Zero的代码参仓库,他使用veRL来运行RL强化学习方法,对qwen2.5的0.5B、1.5B、3B等模型进行训练,在一个数字游戏数据集上,达到了较好的推理效果。 …...

爬虫基础(四)线程 和 进程 及相关知识点
目录 一、线程和进程 (1)进程 (2)线程 (3)区别 二、串行、并发、并行 (1)串行 (2)并行 (3)并发 三、爬虫中的线程和进程 &am…...

【自开发工具介绍】SQLSERVER的ImpDp和ExpDp工具01
1、开发背景 大家都很熟悉,Oracle提供了Impdp和ExpDp工具,功能很强大,可以进行db的导入导出的处理。但是对于Sqlserver数据库只是提供了简单的图形化的导出导入工具,在实际的开发和生产环境不太可能让用户在图形化的界面选择移行…...

队列—学习
1. 手写队列的实现 使用数组实现队列是一种常见的方法。队列的基本操作包括入队(enqueue)和出队(dequeue)。队列的头部和尾部分别用 head 和 tail 指针表示。 代码实现 const int N 10000; // 定义队列容量,确保够…...

SpringBoot的配置(配置文件、加载顺序、配置原理)
文章目录 SpringBoot的配置(配置文件、加载顺序、配置原理)一、引言二、配置文件1、配置文件的类型1.1、配置文件的使用 2、多环境配置 三、加载顺序四、配置原理五、使用示例1、配置文件2、配置类3、控制器 六、总结 SpringBoot的配置(配置文件、加载顺序、配置原理) 一、引言…...

如何本地部署DeepSeek?DeepThink R1 本地部署全攻略:零基础小白指南。
🚀 离线运行 AI,免费使用 OpenAI 级别推理模型 本教程将手把手教你如何在本地部署 DeepThink R1 AI 模型,让你无需联网就能运行强大的 AI 推理任务。无论你是AI 新手还是资深开发者,都可以轻松上手! 📌 目录…...
mastery lies beyond poetry)
陆游的《诗人苦学说》:从藻绘到“功夫在诗外”(中英双语)mastery lies beyond poetry
陆游的《诗人苦学说》:从藻绘到“功夫在诗外” 今天看万维钢的《万万没想到》一书,看到陆游的功夫在诗外的句子,特意去查找这首诗的原文。故而有此文。 我国学人还往往过分强调“功夫在诗外”这句陆游的名言,认为提升综合素质是一…...

Golang —协程池(panjf2000/ants/v2)
Golang —协程池(panjf2000/ants/v2) 1 ants1.1 基本信息1.2 ants 是如何运行的(流程图) 1 ants 1.1 基本信息 代码地址:github.com/panjf2000/ants/v2 介绍:ants是一个高性能的 goroutine 池,…...

在 crag 中用 LangGraph 进行评分知识精炼-下
在上一次给大家展示了基本的 Rag 检索过程,着重描述了增强检索中的知识精炼和补充检索,这些都是 crag 的一部分,这篇内容结合 langgraph 给大家展示通过检索增强生成(Retrieval-Augmented Generation, RAG)的工作流&am…...

基于springboot+vue的哈利波特书影音互动科普网站
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...
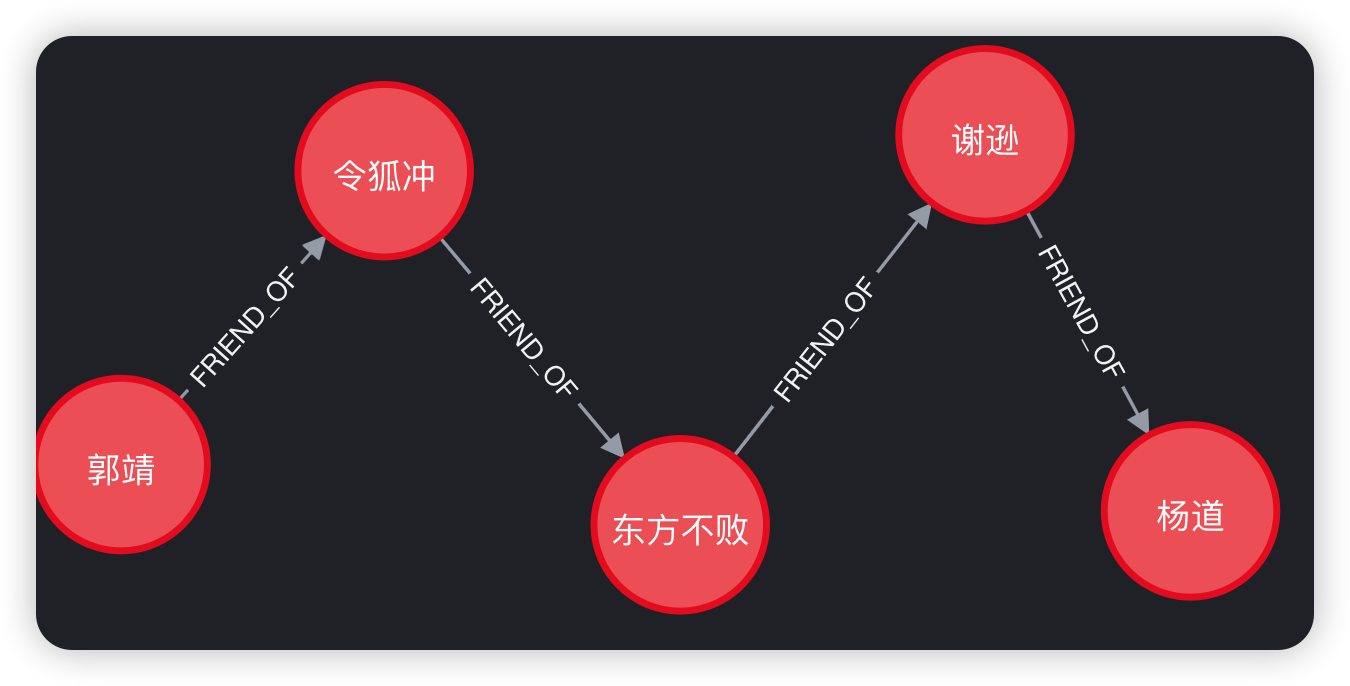
Cypher入门
文章目录 Cypher入门创建数据查询数据matchoptional matchwhere分页with 更新数据删除数据实例:好友推荐 Cypher入门 Cypher是Neo4j的查询语言。 创建数据 在Neo4j中使用create命令创建节点、关系、属性数据。 create (n {name:$value}) return n //创建节点&am…...

使用Z-score进行数据特征标准化
数据标准化是数据处理过程中非常重要的一步,尤其在构建机器学习模型时尤为关键。标准化的目的是将不同量纲的变量转换到相同的尺度,以避免由于量纲差异导致的模型偏差。Z-score标准化是一种常见且简单的标准化方法,它通过计算数据点与平均值的差异,并将其按标准差进行缩放,…...

初级数据结构:栈和队列
一、栈 (一)、栈的定义 栈是一种遵循后进先出(LIFO,Last In First Out)原则的数据结构。栈的主要操作包括入栈(Push)和出栈(Pop)。入栈操作是将元素添加到栈顶,这一过程中…...

【思维导图】java
学习计划:将目前已经学的知识点串成一个思维导图。在往后的学习过程中,不断往思维导图里补充,形成自己整个知识体系。对于思维导图里的每个技术知识,自己用简洁的话概括出来, 训练自己的表达能力。 面向对象三大特性 …...

Redis脑裂问题详解及解决方案
Redis是一种高性能的内存数据库,广泛应用于缓存、消息队列等场景。然而,在分布式Redis集群中,脑裂问题(Split-Brain)是一个需要特别关注的复杂问题。本文将详细介绍Redis脑裂问题的成因、影响及解决方案。 一、什么是…...

玩转大语言模型——配置图数据库Neo4j(含apoc插件)并导入GraphRAG生成的知识图谱
系列文章目录 玩转大语言模型——使用langchain和Ollama本地部署大语言模型 玩转大语言模型——ollama导入huggingface下载的模型 玩转大语言模型——langchain调用ollama视觉多模态语言模型 玩转大语言模型——使用GraphRAGOllama构建知识图谱 玩转大语言模型——完美解决Gra…...

【Windows Server实战】生产环境云和NPS快速搭建
前置条件 本文假定你已达成以下前提条件: 有域控DC。有证书服务器(AD CS)。已使用Microsoft Intune或者GPO为客户机申请证书。服务器上至少有两张网卡(如果用虚拟机做的测试环境,可以用一张HostOnly网卡做测试&#…...

[ESP32:Vscode+PlatformIO]新建工程 常用配置与设置
2025-1-29 一、新建工程 选择一个要创建工程文件夹的地方,在空白处鼠标右键选择通过Code打开 打开Vscode,点击platformIO图标,选择PIO Home下的open,最后点击new project 按照下图进行设置 第一个是工程文件夹的名称 第二个是…...

【NLP251】Transformer精讲 残差链接与层归一化
精讲部分,主要是对Transformer的深度理解方便日后从底层逻辑进行创新,对于仅应用需求的小伙伴可以跳过这一部分,不影响正常学习。 1. 残差模块 何凯明在2015年提出的残差网络(ResNet),Transformer在2016年…...

康德哲学与自组织思想的渊源:从《判断力批判》到系统论的桥梁
康德哲学与自组织思想的渊源:从《判断力批判》到系统论的桥梁 第一节:康德哲学中的自然目的论与自组织思想 核心内容: 康德哲学中的自然目的论和反思判断力概念,为现代系统论中的自组织思想提供了哲学基础,预见了复…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...