爬取豆瓣书籍数据
# 1. 导入库包
import requests
from lxml import etree
from time import sleep
import os
import pandas as pd
import reBOOKS = []
IMGURLS = []# 2. 获取网页源代码
def get_html(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 异常处理try:html = requests.get(url, headers=headers)# 声明编码方式html.encoding = html.apparent_encoding# 判断if html.status_code == 200:print('成功获取源代码')# print(html.text)except Exception as e:print('获取源代码失败:%s' % e)# 返回htmlreturn html.text# 3. 解析网页源代码
def parse_html(html):html = etree.HTML(html)# 每个图书信息分别保存在 class="indent" 的div下的 table标签内tables = html.xpath("//div[@class='indent']//table")# print(len(tables)) # 打印之后如果是25的话就是对的books = []imgUrls = []# 遍历通过xpath得到的li标签列表# 因为要获取标题文本,所以xpath表达式要追加 /text(), t.xpath返回的是一个列表,且列表中只有一个元素所以追加一个[0]for t in tables:# title = t.xpath(".//div[@class='p12']/a/@title") # 匹配得到的是空的# 书名title = t.xpath(".//td[@valign='top']//a/@title")[0]# 链接link = t.xpath(".//td[@valign='top']//a/@href")[0]# 获取pl标签的字符串pl = t.xpath(".//td[@valign='top']//p[1]/text()")[0]# 截取国家if '[' in pl:country = pl.split('[')[1].split(']')[0]else:country = '中' # 没有国家的默认为“中国”# 截取作者if '[' in pl:author = pl.split(']')[1].split('/')[0].replace(" ", "")elif len(pl.split('/')) == 3:author = '无'elif len(pl.split('/')) == 2:author = pl.split('/')[0]elif '[' not in pl:if len(pl.split('/')) == 4:author = pl.split('/')[-4]elif len(pl.split('/')) == 5:author = pl.split('/')[-5]elif len(pl.split('/')) == 6:author = pl.split('/')[-6]else:author = '无'# 截取翻译者if len(pl.split('/')) == 3:translator = ' 'elif '[' in pl:if len(pl.split('/')) == 4:translator = pl.split('/')[-3]elif len(pl.split('/')) == 5:translator = pl.split('/')[-4]elif len(pl.split('/')) == 6:translator = pl.split('/')[-5]else:translator = ' '# 截取出版社if len(pl.split('/')) == 2:publisher = pl.split('/')[0]elif len(pl.split('/')) == 3:publisher = pl.split('/')[0]elif '[' in pl:if len(pl.split('/')) == 4:publisher = pl.split('/')[1]elif len(pl.split('/')) == 5:publisher = pl.split('/')[2]elif len(pl.split('/')) == 6:publisher = pl.split('/')[-3]elif len(pl.split('/')) == 7:publisher = pl.split('/')[-4]elif '[' not in pl:# if len(pl.split('/'))== 3:publisher = pl.split('/')[-3]# if len(pl.split('/')) == 6:# publisher = pl.split('/')[-3]# elif len(pl.split('/')) == 7:# publisher = pl.split('/')[-4]# 截取出版时间if len(pl.split('/')) == 2:time = '不详'elif len(pl.split('/')) == 4:time = pl.split('/')[-2]elif len(pl.split('/')) == 5:time = pl.split('/')[-2]elif len(pl.split('/')) == 6:time = pl.split('/')[-2]# 截取单价if '元' in pl:price = pl.split('/')[-1].split('元')[0]else:price = pl.split('/')[-1]# 获取星级数str1 = t.xpath(".//td[@valign='top']//div[@class='star clearfix']/span[1]/@class")[0].replace("allstar", "")# 此时获取到的数字其实是字符串类型,不能直接%10,需要把str转化为intnum = int(str1)star = num / 10# 获取评分score = t.xpath(".//td[@valign='top']//div[@class='star clearfix']/span[2]/text()")[0]# 获取评价人数pnum = t.xpath(".//td[@valign='top']//div[@class='star clearfix']/span[3]/text()")[0]people = re.sub("\D", "", pnum)# 获取简介comments = t.xpath(".//p[@class='quote']/span/text()")comment = comments[0] if len(comments) != 0 else "无"book = {'书名': title,'链接': link,'国家': country,'作者': author,'翻译者': translator,'出版社': publisher,'出版时间': time,'价格': price,'星级': star,'评分': score,'评价人数': people,'简介': comment}# 图片imgUrl = t.xpath(".//a/img/@src")[0]# print(imgUrl)books.append(book)imgUrls.append(imgUrl)return books, imgUrls# 4. 下载图片保存文件
def downloadimg(url, book):# 判断文件夹是否在指定路径下面,建立文件夹并把指定路径移到文件夹下面if 'img' in os.listdir(r'D:\pachong'):passelse:os.mkdir(r'D:\pachong\img')os.chdir(r'D:\pachong\img')# 返回img的二进制流img = requests.request('GET', url).contentwith open(book['书名'] + '.jpg', 'wb') as f:# print('正在下载: %s' % url)f.write(img)# 5. 数据预处理
# def processData():if __name__ == '__main__':# url = 'https://book.douban.com/top250?start=0'# 10页循环遍历for i in range(10):# 2. 定义url并获取网页源代码url = 'https://book.douban.com/top250?start={}'.format(i * 25)# print(url)html = get_html(url)# 3. 解析网页源代码sleep(1)books = parse_html(html)[0]imgUrls = parse_html(html)[1]BOOKS.extend(books)IMGURLS.extend(imgUrls)# 4. 下载图片保存文件# for i in range(250):# # sleep(1)# downloadimg(IMGURLS[i], BOOKS[i])os.chdir(r'D:/pachong/img')# 以csv格式写入本地bookdata = pd.DataFrame(BOOKS)bookdata.to_csv('D:/pachong/book.csv', index=False)print("图书信息写入本地成功")# 以txt格式写入本地错误# 得到的是字典格式,要想写成txt格式需要先转化成字符串格式# for i in range(25):# with open('book.txt', 'a') as f:# f.write(books[i] + '\n')


相关文章:
爬取豆瓣书籍数据
# 1. 导入库包 import requests from lxml import etree from time import sleep import os import pandas as pd import reBOOKS [] IMGURLS []# 2. 获取网页源代码 def get_html(url):headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…...

基于微信小程序的电子商城购物系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

6-图像金字塔与轮廓检测
文章目录 6.图像金字塔与轮廓检测(1)图像金字塔定义(2)金字塔制作方法(3)轮廓检测方法(4)轮廓特征与近似(5)模板匹配方法6.图像金字塔与轮廓检测 (1)图像金字塔定义 高斯金字塔拉普拉斯金字塔 高斯金字塔:向下采样方法(缩小) 高斯金字塔:向上采样方法(放大)…...

【Ai】DeepSeek本地部署+Page Assist图形界面
准备工作 1、ollama,用于部署各种开源模型,并开放接口的程序 https://ollama.com/download 2、deepseek-r1:32b 模型 https://ollama.com/library/deepseek-r1:32b 不同的模型版本对计算机性能的要求不一样,版本越高对显卡和内存的要求越高…...

【最长不下降子序列——树状数组、线段树、LIS】
题目 代码 #include <bits/stdc.h> using namespace std; const int N 1e510; int a[N], b[N], tr[N];//a保存权值,b保存索引,tr保存f,g前缀属性最大值 int f[N], g[N]; int n, m; bool cmp(int x, int y) {if(a[x] ! a[y]) return a[x] < a[…...

【实战篇章】深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据
文章目录 深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据一、服务器如何响应前端请求HTTP 请求生命周期全解析1.前端发起 HTTP 请求(关键细节强化版)2. 服务器接收请求(深度优化版) 二、后端如何查看前…...

Games104——引擎工具链基础
总览 工具链 用户到引擎架构图 工具链是衔接不同岗位、软件之间的桥梁,比如美术与技术,策划与美术,美术软件与引擎本身等,有Animation、UI、Mesh、Shader、Logical 、Level Editor等等。一般商业级引擎里的工具链代码量是超过…...

分层多维度应急管理系统的设计
一、系统总体架构设计 1. 六层体系架构 #mermaid-svg-QOXtM1MnbrwUopPb {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QOXtM1MnbrwUopPb .error-icon{fill:#552222;}#mermaid-svg-QOXtM1MnbrwUopPb .error-text{f…...

【漏斗图】——1
🌟 解锁数据可视化的魔法钥匙 —— pyecharts实战指南 🌟 在这个数据为王的时代,每一次点击、每一次交易、每一份报告背后都隐藏着无尽的故事与洞察。但你是否曾苦恼于如何将这些冰冷的数据转化为直观、吸引人的视觉盛宴? 🔥 欢迎来到《pyecharts图形绘制大师班》 �…...

(二)QT——按钮小程序
目录 前言 按钮小程序 1、步骤 2、代码示例 3、多个按钮 ①信号与槽的一对一 ②多对一(多个信号连接到同一个槽) ③一对多(一个信号连接到多个槽) 结论 前言 按钮小程序 Qt 按钮程序通常包含 三个核心文件: m…...

【Linux】从硬件到软件了解进程
个人主页~ 从硬件到软件了解进程 一、冯诺依曼体系结构二、操作系统三、操作系统进程管理1、概念2、PCB和task_struct3、查看进程4、通过系统调用fork创建进程(1)简述(2)系统调用生成子进程的过程〇提出问题①fork函数②父子进程关…...

HTB:Alert[WriteUP]
目录 连接至HTB服务器并启动靶机 信息收集 使用rustscan对靶机TCP端口进行开放扫描 使用nmap对靶机TCP开放端口进行脚本、服务扫描 使用nmap对靶机TCP开放端口进行漏洞、系统扫描 使用nmap对靶机常用UDP端口进行开放扫描 使用ffuf对alert.htb域名进行子域名FUZZ 使用go…...

ARM嵌入式学习--第十天(UART)
--UART介绍 UART(Universal Asynchonous Receiver and Transmitter)通用异步接收器,是一种通用串行数据总线,用于异步通信。该总线双向通信,可以实现全双工传输和接收。在嵌入式设计中,UART用来与PC进行通信,包括与监控…...

玉米苗和杂草识别分割数据集labelme格式1997张3类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):1997 标注数量(json文件个数):1997 标注类别数:3 标注类别名称:["corn","weed","Bean…...

哈夫曼树
哈夫曼树(Huffman Tree)是一种最优的二叉树,常用于数据压缩,如在 Huffman 编码中使用。它是根据字符出现的频率来构造的,频率越高的字符越靠近树的根,频率低的字符则在较深的节点上。其核心思想是通过构建一…...

wax到底是什么意思
在很久很久以前,人类还没有诞生文字之前,人类就产生了语言;在诞生文字之前,人类就已经使用了语言很久很久。 没有文字之前,人们的语言其实是相对比较简单的,因为人类的生产和生活水平非常低下,…...

笔记:使用ST-LINK烧录STM32程序怎么样最方便?
一般板子在插件上, 8脚 3.3V;9脚 CLK;10脚 DIO;4脚GND ST_Link 19脚 3.3V;9脚 CLK;7脚 DIO;20脚 GND 烧录软件:ST-LINK Utility,Keil_5; ST_Link 接口针脚定义: 按定义连接ST_Link与电路板; 打开STM32 ST-LINK Uti…...

数据分析系列--[11] RapidMiner,K-Means聚类分析(含数据集)
一、数据集 二、导入数据 三、K-Means聚类 数据说明:提供一组数据,含体重、胆固醇、性别。 分析目标:找到这组数据中需要治疗的群体供后续使用。 一、数据集 点击下载数据集 二、导入数据 三、K-Means聚类 Ending, congratulations, youre done....

Python在数据科学领域的深度应用:从数据处理到机器学习模型构建
Python在数据科学领域的深度应用:从数据处理到机器学习模型构建 在当今大数据与人工智能蓬勃发展的时代,Python凭借其简洁的语法、强大的库支持和活跃的社区,已成为数据科学家和工程师的首选编程语言。本文将深入探讨Python在数据科学领域的应用,从数据预处理、探索性分析…...

海外问卷调查渠道查,具体运营的秘密
相信只要持之以恒并逐渐掌握技巧,每一位调查人在踏上征徐之时都会非常顺利的。并在日后的职业生涯中拥有捉刀厮杀的基本技能!本文会告诉你如何做好一个优秀的海外问卷调查人。 在市场经济高速发展的今天,众多的企业为了自身的生存和发展而在…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...
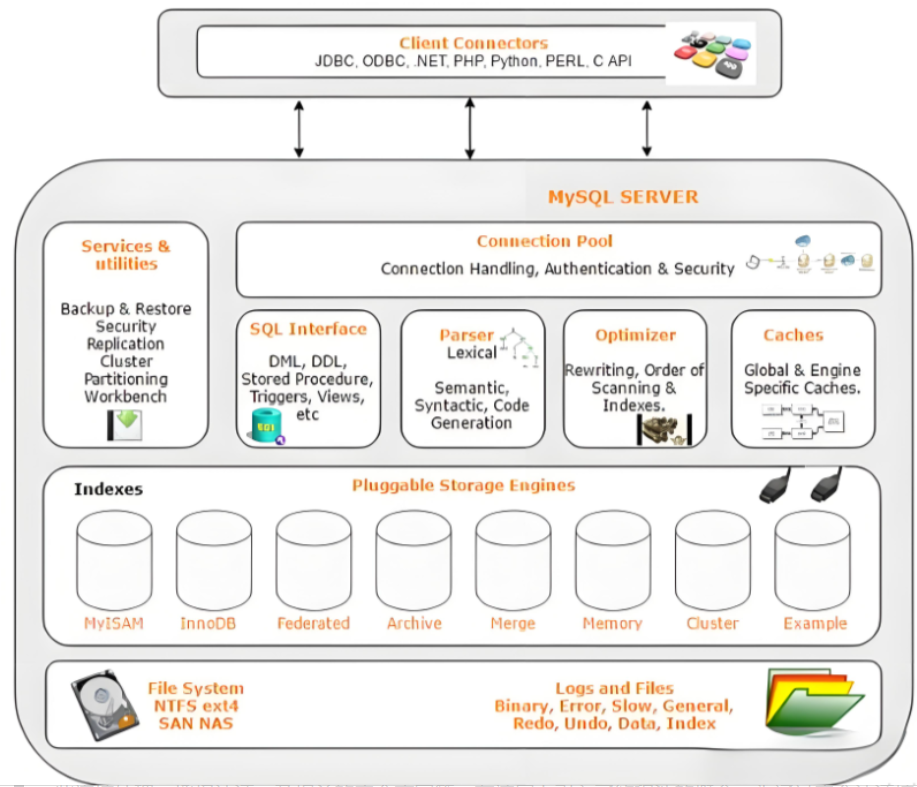
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...
echarts使用graphic强行给图增加一个边框(边框根据自己的图形大小设置)- 适用于无法使用dom的样式
pdf-lib https://blog.csdn.net/Shi_haoliu/article/details/148157624?spm1001.2014.3001.5501 为了完成在pdf中导出echarts图,如果边框加在dom上面,pdf-lib导出svg的时候并不会导出边框,所以只能在echarts图上面加边框 grid的边框是在图里…...
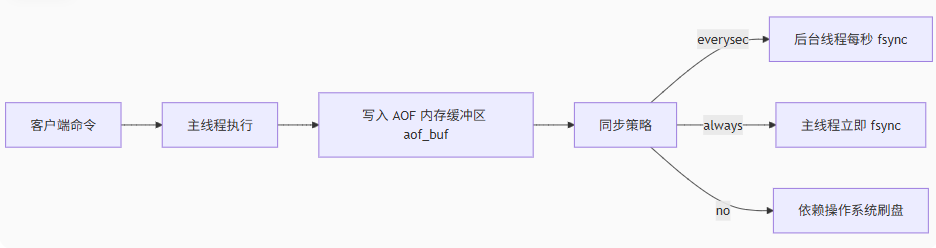
Redis上篇--知识点总结
Redis上篇–解析 本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。 1. 基本介绍 Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 val…...