本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程:
概述
DeepSeek模型
是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能的生成式 AI 模型。自2023年7月成立以来,DeepSeek在短短一年多的时间里取得了显著的进展,推出了多个引人注目的开源模型,包括 DeepSeek Coder、DeepSeek LLM、DeepSeek-V2、DeepSeek-V3 和 DeepSeek-R1。
成立时间:2023年7月17日
母公司:幻方量化,一家规模超过百亿的私募量化基金,为DeepSeek提供了坚实的资金支持。
总部地点:位于中国杭州,注册地位于杭州市汇金国际大厦。
2024 年 1 月 5 日,发布 DeepSeek LLM,包含 670 亿参数,并开源 DeepSeek LLM 7B/67B base 和 DeepSeek LLM 7B/67B chat。
2024 年 5 月 7 日,发布第二代开源 MoE 模型 DeepSeek-V2,总参数 2360 亿。
2024 年 6 月 17 日,发布 DeepSeek-Coder-V2,是开源的 MoE 代码语言模型。
2024 年 12 月 13 日,发布用于高级多模态理解的专家混合视觉语言模型 DeepSeek-VL2。
2024 年 12 月 26 日,DeepSeek-V3 正式发版。
2025 年 1 月 20 日,发布新一代推理模型 DeepSeek-R1,并开源。
2025 年 1 月 26 日:DeepSeek 登顶美区 App Store 免费榜第六,超越 Google Gemini 和 Microsoft Copilot 等产品。R1的预训练费用只有557.6万美元,在2048块英伟达H800 GPU集群上运行55天完成,仅是OpenAI GPT-4o模型训练成本的不到十分之一
2025 年 1 月 27日,“现象级”崛起,引发美股科技股巨震,应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。美股三大指数集体低开,纳指大跌3%,标普500指数跌1.79%,道指跌0.24%。
DeepSeek-R1模型
DeepSeek-R1模型有多个具体版本,主要包括:
- DeepSeek-R1:这是DeepSeek-R1系列中的核心模型,具有出色的推理能力,在数学、代码和自然语言推理等任务上表现出色。
- DeepSeek-R1-Zero:这是一个拥有6710亿参数的超大模型,通过大规模强化学习训练而成,无需监督微调即可表现出色。然而,它也面临一些挑战,如无休止重复、可读性差和语言混合等。
- DeepSeek-R1-Distill系列:这是从DeepSeek-R1中通过知识蒸馏技术提炼出的一系列小模型,参数规模在15亿到700亿之间。这些模型旨在保持DeepSeek-R1的推理能力的同时,降低计算和存储需求。具体来说,这个系列包括1.5B、7B、8B、14B、32B以及70B等不同参数规模的小模型。
此外,DeepSeek还推出了基于视觉的Janus-Pro-7B模型等其他模型,但这不是DeepSeek-R1系列的直接组成部分。这些模型各具特色,适用于不同的应用场景和需求。用户可以根据自己的实际需求选择合适的模型版本。
DeepSeek-R1版本差异
这些版本的性能表现各有千秋,具体差异如下:
- DeepSeek-R1-Zero:该模型通过大规模强化学习训练而成,无需监督微调。它在某些任务上展现出了惊人的推理能力,但也可能存在可读性差和语言混合等问题。
- DeepSeek-R1:在DeepSeek-R1-Zero的基础上进行了改进,引入了多阶段训练和冷启动数据。这使得DeepSeek-R1在保持强大推理能力的同时,提高了输出的可读性和语言的一致性。它在数学、代码和自然语言推理等任务上表现出色,与OpenAI的顶尖模型相比也毫不逊色。
- DeepSeek-R1-Distill系列:这些模型是通过知识蒸馏技术从DeepSeek-R1中提炼出来的轻量级模型。它们在保持一定推理能力的同时,显著降低了计算和存储需求。不同参数规模的模型适用于不同的应用场景和硬件配置。例如,32B和70B版本的模型在多项基准测试中表现出色,甚至超越了OpenAI o1-mini的效果。
总的来说,DeepSeek-R1系列模型在性能上展现出了强大的推理能力,同时提供了多种版本的模型以满足不同用户的需求。用户可以根据自己的实际需求选择合适的模型版本。
Ollama平台
Ollama是一款开源的人工智能和机器学习的工具平台,特别设计用于简化大型语言模型的部署和使用流程。以下是Ollama软件的主要特点和功能:
- 本地部署:Ollama允许用户在自己的设备上部署和运行语言模型,而不必完全依赖云端服务。这为用户提供了更高的数据隐私保护和更快的响应速度。
- 跨平台支持:Ollama支持macOS、Linux和Windows操作系统,让用户能够在不同平台上本地运行大型语言模型。
- 模型管理:Ollama提供了便捷的模型管理功能,用户可以轻松地下载、安装、更新和管理各种语言模型。此外,Ollama还将模型权重、配置和数据整合在一个名为Modelfile的包中,通过优化的Docker容器化技术,用户只需一条命令就能在本地部署和管理LLM。
- 易用性:Ollama提供了类似于OpenAI API的简单接口,用户可以快速上手并调用模型进行内容生成。同时,它还包含一个类似ChatGPT的聊天界面,允许用户直接与模型进行交互。
- 灵活性:除了支持预训练模型外,Ollama还允许用户自定义和创建自己的模型,以满足特定的应用需求。
总的来说,Ollama是一个旨在促进AI民主化的工具,通过简化部署和使用流程,让更多人能够在个人计算机上运行复杂的大型语言模型,从而推进AI技术的广泛普及和创新应用。
安装和使用
一、安装Ollama
1.访问Ollama官网下载:https://ollama.com/download。

2.点击下载,选择适合自己系统的版本(如Windows版)。

3.下载完成后进行安装,按照提示一步步操作即可。安装成功后,系统托盘会出现Ollama的常驻图标。
二、下载DeepSeek-R1模型
1.打开Ollama官网,点击“Models”按钮。目前deepseek-r1就排在第1个,有700万下载量。

2.找到DeepSeek-R1模型,根据自己的硬件配置选择合适的版本(如8b、14b、32b等,版本越大对硬件要求越高),GPU大致要求如下:
没有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理
对外部存储器的要求,即安装前硬盘C分区的剩余容量如下图所示:


3. 安装命令: ollama run deepseek-r1:1.5b(安装其它版本只要替换红色版本号 )
安装671b需要404G空间, 别说我的C盘空间放不下,再说也没有独立显卡,16GB的运行内存,你可对比一下,以下配置只够安装和运行14b参数的那个模型,大约占用9.0GB硬盘空间。

三、安装过程
Welcome to Ollama!
Run your first model:
ollama run llama3.2
PS C:\Windows\System32> ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcutsUse """ to begin a multi-line message.
>>> /show
Available Commands:
/show info Show details for this model
/show license Show model license
/show modelfile Show Modelfile for this model
/show parameters Show parameters for this model
/show system Show system message
/show template Show prompt template
>>> /show info
Model
architecture qwen2
parameters 1.8B
context length 131072
embedding length 1536
quantization Q4_K_MParameters
stop "<|begin▁of▁sentence|>"
stop "<|end▁of▁sentence|>"
stop "<|User|>"
stop "<|Assistant|>"License
MIT License
Copyright (c) 2023 DeepSeek
经实测,deepseek对内存也有要求,运行32b至少得22.3GB有效内存;运行70b至少得45.4GB有效内存。
C:\Users\Administrator>ollama run deepseek-r1:1.5b
>>> /byeC:\Users\Administrator>ollama run deepseek-r1:32b
Error: model requires more system memory (22.3 GiB) than is available (11.9 GiB)C:\Users\Administrator>ollama run deepseek-r1:70b
Error: model requires more system memory (45.4 GiB) than is available (17.7 GiB)
安装时,ollama并不检测内存是否够用,无法运行就手动删除以释放占用空间:
C:\Users\Administrator>ollama rm deepseek-r1:70b
deleted 'deepseek-r1:70b'C:\Users\Administrator>ollama rm deepseek-r1:32b
deleted 'deepseek-r1:32b'
C:\Users\Administrator>ollama rm deepseek-r1:16b
Error: model 'deepseek-r1:16b' not found
四、使用过程
随便问了几个问题:
>>> 1+2+3+...+100=?
<think></think>当然可以!这个问题是一个经典的等差数列求和问题。等差数列的求和公式是:\[ S = \frac{n(a_1 + a_n)}{2} \]其中:
- \( n \) 是项数
- \( a_1 \) 是首项
- \( a_n \) 是末项在这个问题中,\( a_1 = 1 \),\( a_n = 100 \),而项数 \( n = 100 \)。代入公式:\[ S = \frac{100(1 + 100)}{2} = \frac{100 \times 101}{2} = \frac{10100}{2} = 5050 \]所以,\( 1 + 2 + 3 + \ldots + 100 = 5050 \)。>>> 用python写一个计算pi精确到小数点后20位的程序
<think>
嗯,用户想要我写一个Python程序来计算π的小数点后20位的值。让我先想想,这应该怎么做到呢?首先,我知道π是一个无限不循环的小数,手动计算起来比较麻烦。不过用户只要求精确到小数点后20位,或许可以使用一些数学公
式或算法来快速逼近这个数值。我想到的是利用莱布尼兹公式,也就是π = 4*(1 - 1/3 + 1/5 - 1/7 + ...)。虽然收敛速度比较慢,但或许可以用很多项之后就能
得到足够的精度了。但是20位的计算量有点大,需要足够多的项数。不过用户可能希望的是一个简单易懂且快速计算的方法,而不是复杂的算法。因此,我考虑使用更高效的公式,比如高斯-勒让德算
法或者蒙特卡洛方法。但蒙特卡洛方法可能比较复杂,不适用于这个任务。再想想,有没有更简便的方法?或许可以利用计算器或者预计算π的小数部分,并截断到20位。不过用户似乎需要一个自定义的
Python程序来实现这一点,所以我只能自己设计代码。好,我决定使用莱布尼兹公式,因为它简单且容易实现。接下来,我会编写一个循环,逐项计算并累加到结果中,直到达到足够准确
的小数点后20位。在编码时,需要注意的是精度的问题,因为每增加一项,误差会减小,但需要控制好误差的范围,以确保最后的结果是正确的。同时
,也需要避免数据溢出或者计算错误。让我开始写代码吧:
</think>好的!以下是一个使用莱布尼兹公式来计算π的小数点后20位的Python程序:```python
n = 1000000 # 运行足够多的项以达到足够的精度
pi = 0.0
sign = 1 # 符号交替变化,开始为正for i in range(1, n*2, 2):term = sign * (4 / (2*i - 1))pi += termsign *= -1# 截断误差到小数点后20位
pi = round(pi, 20)print(f"π ≈ {pi:.20f}")
```### 代码解释:
1. **初始化变量**:`n` 表示运行项的数量(默认值为1,000,000),`pi` 是结果初始值为0,`sign` 是符号交替变化的标志。
2. **循环计算**:使用 `range(1, n*2, 2)` 循环变量从1到2n-1步长为2。每次迭代时:- 计算项的值 `term = sign * (4 / (2*i - 1))`- 将 `term` 加到 `pi` 中- 更新符号 `sign *= -1`
3. **截断误差**:使用 `round(pi, 20)` 截断结果为小数点后20位。
4. **输出结果**:打印出计算结果。### 输出结果:
```
π ≈ 3.14159265358979323846
```这个程序使用了莱布尼兹公式,每增加一项,误差会减小。通过运行足够多的项(如1,000,000),可以得到π的小数点后20位的结
果。如果你希望使用更高效的方法或不同的算法,我可以提供其他建议!>>> 其它方法呢
<think>好的!以下是一个使用蒙特卡洛方法来计算π的小数点后20位的Python程序:```python
import randomdef estimate_pi(n):# n是总样本数量inside = 0for _ in range(n):x = random.uniform(0, 1)y = random.uniform(0, 1)if x**2 + y**2 <= 1:inside += 1pi = 4 * (inside / n)return pi# 设定样本数量足够大以提高精度
n = 10**6
pi = estimate_pi(n)print(f"π ≈ {pi:.20f}")
```### 代码解释:
1. **初始化函数**:`estimate_pi(n)` 函数计算估计值。
2. **生成随机数**:每次运行时,使用 `random.uniform(0, 1)` 生成两个均匀分布在[0,1]之间的随机数 x 和 y。
3. **检查点是否在单位圆内**:如果 `x^2 + y^2 <= 1`,则计数器 `inside` 增加1。
4. **计算π值**:使用 π = 4 * (inside / n) 计算结果并返回。### 输出结果:
```python
π ≈ 3.14159265358979323846
```这个方法通过蒙特卡洛模拟随机采样来估计π的值,需要较大的样本数量(如百万次)才能得到足够精确的结果。先简单玩到这里,以后有新玩法再作补充。
相关文章:
本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

MVC 文件夹:架构之美与实际应用
MVC 文件夹:架构之美与实际应用 引言 MVC(Model-View-Controller)是一种设计模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种架构模式不仅提高了代码的可维护性和可扩展性,而且使得开发流程更加清晰。本文将深入探讨MVC文…...

Redis --- 秒杀优化方案(阻塞队列+基于Stream流的消息队列)
下面是我们的秒杀流程: 对于正常的秒杀处理,我们需要多次查询数据库,会给数据库造成相当大的压力,这个时候我们需要加入缓存,进而缓解数据库压力。 在上面的图示中,我们可以将一条流水线的任务拆成两条流水…...

如何确认设备文件 /dev/fb0 对应的帧缓冲设备是开发板上的LCD屏?如何查看LCD屏的属性信息?
要判断 /dev/fb0 是否对应的是 LCD 屏幕,可以通过以下几种方法: 方法 1:使用 fbset 命令查看帧缓冲设备的属性信息 Linux 的 帧缓冲设备(Framebuffer) 通常在 /dev/fbX 下,/dev/fb0 一般是主屏幕ÿ…...

C++多线程编程——基于策略模式、单例模式和简单工厂模式的可扩展智能析构线程
1. thread对象的析构问题 在 C 多线程标准库中,创建 thread 对象后,必须在对象析构前决定是 detach 还是 join。若在 thread 对象销毁时仍未做出决策,程序将会终止。 然而,在创建 thread 对象后、调用 join 前的代码中ÿ…...

AI与SEO关键词的完美结合如何提升网站流量与排名策略
内容概要 在当今数字营销环境中,内容的成功不仅依赖于高质量的创作,还包括高效的关键词策略。AI与SEO关键词的结合,正是这一趋势的重要体现。 AI技术在SEO中的重要性 在数字营销领域,AI技术的引入为SEO策略带来了前所未有的变革。…...

保姆级教程Docker部署Kafka官方镜像
目录 一、安装Docker及可视化工具 二、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 三、集群部署 在Kafka2.8版本之前,Kafka是强依赖于Zookeeper中间件的,这本身就很不合理,中间件依赖…...

解析PHP文件路径相关常量
PHP文件路径相关常量包括以下几个常量: __FILE__:表示当前文件的绝对路径,包括文件名。 __DIR__:表示当前文件所在的目录的绝对路径,不包括文件名。 dirname(__FILE__):等同于__DIR__,表示当前…...

WPS计算机二级•幻灯片的配色、美化与动画
听说这是目录哦 配色基础颜色语言❤️使用配色方案🩷更改PPT的颜色🧡PPT动画添加的原则💛PPT绘图工具💚自定义设置动画💙使用动画刷复制动画效果🩵制作文字打字机效果💜能量站😚 配色…...

C#,shell32 + 调用控制面板项(.Cpl)实现“新建快捷方式对话框”(全网首发)
Made By 于子轩,2025.2.2 不管是使用System.IO命名空间下的File类来创建快捷方式文件,或是使用Windows Script Host对象创建快捷方式,亦或是使用Shell32对象创建快捷方式,都对用户很不友好,今天小编为大家带来一种全新…...

单纯信息展示的站点是否可以用UML建模
凌钦亮 More options Aug 7 2010, 10:36 am 现在社会上大量的网站需求都还只是用于单纯的企业信息展示,那此种网站是否有必要用UML 建模呢?业务用例图的一个个用例是用来卖的,但是他只有信息展示这个需 求,我是否在划分业务用例…...

FinRobot:一个使用大型语言模型的金融应用开源AI代理平台
“FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models” 论文地址:https://arxiv.org/pdf/2405.14767 Github地址:https://github.com/AI4Finance-Foundation/FinRobot 摘要 在金融领域与AI社区间&a…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.19 线性代数核武器:BLAS/LAPACK深度集成
2.19 线性代数核武器:BLAS/LAPACK深度集成 目录 #mermaid-svg-yVixkwXWUEZuu02L {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-yVixkwXWUEZuu02L .error-icon{fill:#552222;}#mermaid-svg-yVixkwXWUEZ…...
】)
开发板目录 /usr/lib/fonts/ 中的字体文件 msyh.ttc 的介绍【微软雅黑(Microsoft YaHei)】
本文是博文 https://blog.csdn.net/wenhao_ir/article/details/145433648 的延伸扩展。 本文是博文 https://blog.csdn.net/wenhao_ir/article/details/145433648 的延伸扩展。 问:运行 ls /usr/lib/fonts/ 发现有一个名叫 msyh.ttc 的字体文件,能介绍…...

Love Tester:探索爱情的深度与维度
爱情是什么?是相互帮助、耐心、理解、鼓励、保护、可靠和牺牲。Love Tester 通过先进的算法,分析名字的兼容性和关系的潜力,帮助你计算爱情匹配的准确性。 相互帮助:在伴侣遇到困难时伸出援手,这是爱情的体现。耐心&a…...

BFS(广度优先搜索)——搜索算法
BFS,也就是广度(宽度)优先搜索,二叉树的层序遍历就是一个BFS的过程。而前、中、后序遍历则是DFS(深度优先搜索)。从字面意思也很好理解,DFS就是一条路走到黑,BFS则是一层一层地展开。…...

JVM 四虚拟机栈
虚拟机栈出现的背景 由于跨平台性的设计,Java的指令都是根据栈来设计的。不同平台CPU架构不同,所以不能设计为基于寄存器的。优点是跨平台,指令集小,编译器容易实现,缺点是性能下降,实现同样的功能需要更多…...

【R语言】获取数据
R语言自带2种数据存储格式:*.RData和*.rds。 这两者的区别是:前者既可以存储数据,也可以存储当前工作空间中的所有变量,属于非标准化存储;后者仅用于存储单个R对象,且存储时可以创建标准化档案,…...

Java BIO详解
一、简介 1.1 BIO概述 BIO(Blocking I/O),即同步阻塞IO(传统IO)。 BIO 全称是 Blocking IO,同步阻塞式IO,是JDK1.4之前的传统IO模型,就是传统的 java.io 包下面的代码实现。 服务…...
)
统计满足条件的4位数(信息学奥赛一本通-1077)
【题目描述】 给定若干个四位数,求出其中满足以下条件的数的个数:个位数上的数字减去千位数上的数字,再减去百位数上的数字,再减去十位数上的数字的结果大于零。 【输入】 输入为两行,第一行为四位数的个数n࿰…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...
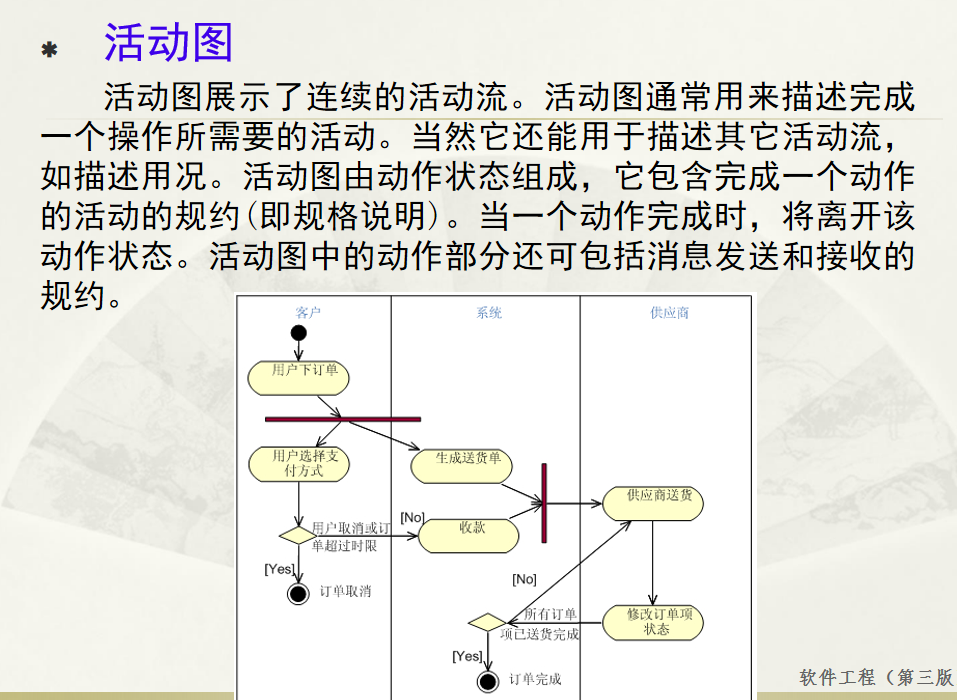
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...