数据结构初探:链表之单链表篇
本文图皆为作者手绘,所有代码基于vs2022运行测试
系列文章目录
数据结构初探:顺序表篇
文章目录
- 系列文章目录
- 前言
- 一、链表基础概念
- 二、链表的分类
- 简化边界条件处理
- 使代码更清晰简洁
- 提高程序稳定性
- 1.单链表(不带头不循环的单链表);
- 1.1存储结构;
- 1.2准备工作
- 1.3链表增删查改的实现
- 1.SList.h
- 2.SList.c
- 2.1链表的打印
- 2.2节点的创建
- 2.3链表的尾插
- 2.4链表的头插
- 2.5链表的尾删
- 2.6链表的头删
- 2.7链表的查找
- 2.8链表的中间插入
- 2.9链表的pos位置删除;
- 2.10 链表的在pos位置之后插入
- 2.11链表的在pos位置之后删除
- 2.12链表的销毁
- 2.13==完整代码==
- 3.test.c
- 1.4单链表的优缺点
- 2.双向带头循环链表
- 总结
前言
在编程的世界里,数据结构是构建高效算法的基石,而链表作为一种基础且重要的数据结构,有着独特的魅力和广泛的应用场景。本文将深入探讨链表的奥秘,从基础概念到复杂操作,再到实际应用,帮助你全面掌握链表这一数据结构。
一、链表基础概念
链表,从本质上来说,是一种线性的数据结构。它由一系列节点组成,这些节点就像是链条上的环,相互连接,形成了链表。每个节点都包含两个关键部分:数据域和指针域。数据域用于存储我们需要的数据,比如一个整数、一个字符串或者更为复杂的对象;而指针域则存储着下一个节点的内存地址,通过这个指针,各个节点得以串联起来,形成了链表的结构。
与我们熟悉的数组相比,链表在内存分配和操作方式上有着显著的不同。数组在内存中是连续存储的,这使得它可以通过索引快速地访问任意位置的元素,实现高效的随机访问。但这种连续存储的特性也带来了一些限制,比如在插入和删除元素时,往往需要移动大量的元素,操作的时间复杂度较高。而链表则不同,它的节点在内存中并不要求连续存储,插入和删除操作只需要修改相关节点的指针即可,时间复杂度较低。不过,链表由于没有索引,访问特定位置的元素需要从头节点开始依次遍历,这在一定程度上影响了它的访问效率。
以下是其基础结构:

二、链表的分类
接下来我会用一张图让你知道所有链表的类别:

这里共有八种链表形式,其中要说的一点是带头/不带头,也可以叫做带哨兵位/不带哨兵位.
哨兵位:
在链表等数据结构中,带有哨兵位的头结点有以下重要作用:
简化边界条件处理
- 插入操作:在普通链表插入节点到头部时,需要单独处理头指针的更新,以防丢失链表头部。而有了哨兵头结点,插入操作就可统一为在哨兵头结点后的节点插入,无需特殊处理头指针。
- 删除操作:删除链表第一个节点也需特殊处理头指针。有了哨兵头结点,删除操作可视为删除哨兵头结点后的节点,使删除操作逻辑统一。
使代码更清晰简洁
- 遍历操作:在遍历链表时,无需在循环中专门处理头指针的特殊情况,可直接从哨兵头结点的下一个节点开始遍历,让遍历代码更简洁。
- 其他操作:对于链表的合并、拆分等复杂操作,哨兵头结点能使操作的边界条件更清晰,让代码逻辑更易理解和维护,减少因边界条件处理不当导致的错误。
提高程序稳定性
- 避免空指针问题:在没有哨兵头结点的链表中,如果链表为空,进行某些操作可能会导致空指针引用错误。而有了哨兵头结点,即使链表暂时没有数据节点,也有一个固定的头结点存在,可有效避免空指针问题,提高程序的稳定性和健壮性。
但是在现实生活中用的最多的链表类型有两种,分别是:
不带头不循环的单链表;
双向带头循环链表;
接下来就让我们分开来讲讲吧!
1.单链表(不带头不循环的单链表);
1.1存储结构;
这张图就是它的结构:

看完了图结构,现在我们来了解一下它的逻辑代码结构:
typedef int SLTDataType;//方便修改变量类型;
//定义链表结构体
typedef struct SListNode
{SLTDataType data;//数据存储struct SListNode* next;//存储下一个节点的地址
}SLTNode;
这就是我们创建的节点结构:

这就是链表的节点结构,要想构成庞大的数据链,我们还需要增删查改函数的实现;
1.2准备工作
创建对应的三个文件夹:
1.SList.h:用于存储创建链表的节点结构体和增删查改函数的函数声明,以及对应的库函数,方便生成程序时的链接;
2.SList.c:用于函数的实现;
3.test.c:用于测试和修改;
ps:2和3,均要包含头文件1,即 #include"SList.h"
1.3链表增删查改的实现
1.SList.h
让我们先来看看链表的函数声明长什么样:
#pragma once#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<string.h>typedef int SLTDataType;
//定义链表结构体
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;
//打印
void SLTPrint(SLTNode* phead);
//节点的创建
SLTNode* CreatNode(SLTDataType d);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在pos位置之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在pos位置删除
void SLTErase(SLTNode** pphead, SLTNode* pos);
//在pos位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//在pos位置之后删除
void SLTEraseAfter(SLTNode* pos);
//销毁
void SLTDestroy(SLTNode* phead);
是不是感觉和顺序表大差不差? 但是接下来具体实现的时候你就会感觉到不同了!
2.SList.c
2.1链表的打印
//因为是对结构体内部指向的数据进行访问,我们只需要传一级指针,
//就可以做到改变实参的操作;
void SLTPrint(SLTNode* phead)
{//将传的头指针赋给curSLTNode* cur = phead;//只要不为空,就一直执行循环while (cur != NULL){//相当于遍历链表,进行打印;printf("%d-->", cur->data);cur = cur->next;//更新循环条件;}printf("NULL\n");//防止多次调用后,数据连在一起,所以添加换行符;
}
不太理解的话可以结合下图辅助理解:

2.2节点的创建
//因为需要它返回一个新节点给我,所以,我们的返回类型为SLTNode*
SLTNode* CreatNode(SLTDataType x)//因为我们是为了存储值而创建的节点,所以要传对应类型的值;
{//进行动态内存开辟,开一个结构体大小的空间作为新节点SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode));if (newNode == NULL)//判断是否开辟失败;{perror("malloc fail");//返回错误行return NULL;//直接结束}newNode->data = x;//赋值给data;newNode->next = NULL;//因为是新节点,还未链接,所以我们置空return newNode;//节点创建完成并返回;
}
基础的动态内存开辟的使用;
2.3链表的尾插
//思考:为什么传的是二级指针呢?
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);//进行断言,防止传为空,从而报错;SLTNode* newNode = CreatNode(x);//节点的创建的复用
//判断链表是否为空if (*pphead == NULL){//若为空,则直接链接,让头直接指向新节点;*pphead = newNode;}else{//若不为空,则找尾节点SLTNode* tail = *pphead;//从头开始找while (tail->next != NULL)//如果节点的next==NULL,则找到了尾,跳出循环{tail = tail->next;//进入循环则是还没找到尾,继续往下走;}tail->next = newNode;//找到尾后,直接将tail的next链接至新节点即可}
}
就是不断找尾,然后尾插,记得要先判断是否为空;

现在我们来看看为什么要传二级指针:我们在对链表进行插入、删除节点等操作时,可能需要修改头指针的值。若只传递头指针的副本(一级指针),函数内对指针的修改不会影响到函数外的头指针。而传递二级指针,即指针的指针,函数就可以通过修改二级指针所指向的内容来改变头指针的值,使函数外的头指针也能得到正确更新。比如在向空链表插入第一个节点时,需要让头指针指向新插入的节点,就需要通过二级指针来实现。
2.4链表的头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newNode = CreatNode(x);//复用newNode->next = *pphead;//本身头指针就是指向第一个节点的地址,现在我先让新节点的next指向头节点*pphead = newNode;//所以新节点就成为了链表的第一个节点,再对头指针进行更新;
}
这就是头插的完整逻辑,大家可以试试特殊情况下,这个还成不成立,比如说链表为空是的头插;
2.5链表的尾删
void SLTPopBack(SLTNode** pphead)
{assert(pphead);//暴力检查//assert(*pphead);//当为空链表时;if (*pphead == NULL)//判断是否为空{printf("链表为空,无法删除\n");return;//为空就直接结束;}//当只有一个节点时;if ((*pphead)->next == NULL){free(*pphead);//直接释放,这就已经删除了;*pphead = NULL;//然后置为空return;}//当有多个节点时;SLTNode* tail = *pphead;//从头开始找尾节点的前一个节点while (tail->next->next != NULL)//直接找尾的话,之后就无法找到新的尾的next进行置空了{tail = tail->next;}free(tail->next);//free掉真正的尾tail->next = NULL;//对新的尾的next进行置空;
}
结合下图进行理解:

完善逻辑链;
2.6链表的头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead);//当链表为空时;if (*pphead == NULL){printf("链表为空,无法删除\n");return;}else//不为空链表时,指针名称可以是del,head,first...{SLTNode* head = *pphead;//保存第一个节点的地址*pphead = head->next;//将头指针链接到第二个节点free(head);//释放并且置空head = NULL;}
}
逻辑如图:

2.7链表的查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{//从头开始找SLTNode* cur = phead;while (cur)只要不为空就继续{if (cur->data == x)//如果找到了{return cur;//就返回所在节点的地址}else{cur = cur->next;//否则继续往下找}}return NULL;//没找到就返回空指针
}
就是遍历查找啦;
2.8链表的中间插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pos);assert(pphead);//pos为头部时;if (pos == *pphead){SLTPushFront(pphead, x);//相当于头插;//也可以直接将头插写在这里,然后给pos为头,直接复用也可}else{SLTNode* prev = *pphead;//从头开始找while (prev->next != pos)//直到找到pos节点的前一个{prev = prev->next;}SLTNode* newNode = CreatNode(x);//复用prev->next = newNode;newNode->next = pos;//进行链接}
}
也可以找尾,然后给尾地址,这个也可以变成尾插
逻辑参考下图:

2.9链表的pos位置删除;
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pos);assert(pphead);//为头部时if (pos == *pphead){SLTPopFront(pphead);//相当于头删}else{SLTNode* prev = *pphead;while (prev->next != pos)//找到pos的前一个{prev = prev->next;}prev->next = pos->next;//前一个与后一个链接起来free(pos);//再将pos释放}为尾部时的逻辑代码,理解即可//SLTNode* tail = *pphead;//while (tail->next != NULL)//{// tail = tail->next;//}//if (pos == tail)//{// SLTPopBack(*pphead);//}}
参考上文的图例,可以自己尝试画画图来加深印象哦!
2.10 链表的在pos位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newNode = CreatNode(x);newNode->next = pos->next;pos->next = newNode;//直接进行链接;}
2.11链表的在pos位置之后删除
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}后面这两个是不是非常简单,就是因为我们已经知道pos,而且只要往后找就好啦;
2.12链表的销毁
void SLTDestroy(SLTNode* phead)
{SLTNode* cur = phead;while (cur)//逐个销毁{SLTNode* tmp = cur->next;free(cur);cur = tmp;}
}
2.13完整代码
#define _CRT_SECURE_NO_WARNINGS 1#include"SList.h"//链表的打印
void SLTPrint(SLTNode* phead)
{SLTNode* cur = phead;while (cur != NULL){printf("%d-->", cur->data);cur = cur->next;}printf("NULL\n");
}//链表元素的创建
SLTNode* CreatNode(SLTDataType x)
{SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode));if (newNode == NULL){perror("malloc fail");return NULL;}newNode->data = x;newNode->next = NULL;return newNode;
}//链表的尾部插入
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newNode = CreatNode(x);if (*pphead == NULL){*pphead = newNode;}else{SLTNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newNode;}
}//链表头部插入的逻辑代码;
void SLTPushFront1(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newNode = CreatNode(x);if (*pphead == NULL){*pphead = newNode;//完全可以忽略这一步,直接用下一步即可;}else{newNode->next = *pphead;*pphead = newNode;}
}//链表的头部插入(优化);
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newNode = CreatNode(x);newNode->next = *pphead;*pphead = newNode;
}//链表的尾部删除(详细);
void SLTPopBack(SLTNode** pphead)
{assert(pphead);//暴力检查//assert(*pphead);//当为空链表时;if (*pphead == NULL){printf("链表为空,无法删除\n");return;}//当只有一个节点时;if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}//当有多个节点时;SLTNode* tail = *pphead;while (tail->next->next != NULL){tail = tail->next;}free(tail->next);tail->next = NULL;
}//链表的头部删除;
void SLTPopFront(SLTNode** pphead)
{assert(pphead);//当链表为空时;if (*pphead == NULL){printf("链表为空,无法删除\n");return;}else//不为空链表时,指针名称可以是del,head,first...{SLTNode* head = *pphead;*pphead = head->next;free(head);head = NULL;}
}//链表的数据查找;
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{SLTNode* cur = phead;while (cur){if (cur->data == x){return cur;}else{cur = cur->next;}}return NULL;
}//链表的中间插入;
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pos);assert(pphead);//pos为头部时;if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newNode = CreatNode(x);prev->next = newNode;newNode->next = pos;}
}//删除pos位置的链表节点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pos);assert(pphead);//为头部时if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}为尾部时//SLTNode* tail = *pphead;//while (tail->next != NULL)//{// tail = tail->next;//}//if (pos == tail)//{// SLTPopBack(*pphead);//}}//在pos之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newNode = CreatNode(x);newNode->next = pos->next;pos->next = newNode;}//在pos位置后删除
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}//链表的销毁
void SLTDestroy(SLTNode* phead)
{SLTNode* cur = phead;while (cur){SLTNode* tmp = cur->next;free(cur);cur = tmp;}
}
接下来是测试代码;
3.test.c
直接上完整代码;
#define _CRT_SECURE_NO_WARNINGS 1#include"SList.h"void test1()
{SLTNode* phead = NULL;//βSLTPushBack(&phead, 1);SLTPushBack(&phead, 2);SLTPushBack(&phead, 3);SLTPushBack(&phead, 4);SLTPrint(phead);//ͷSLTPushFront(&phead, 20);SLTPushFront(&phead, 40);SLTPushFront(&phead, 60);SLTPushFront(&phead, 360);SLTPrint(phead);//βɾSLTPopBack(&phead);SLTPopBack(&phead);SLTPopBack(&phead);SLTPrint(phead);//ͷɾSLTPopFront(&phead);SLTPopFront(&phead);SLTPopFront(&phead);SLTPopFront(&phead);SLTPopFront(&phead);SLTPopFront(&phead);SLTPrint(phead);}void test2()
{SLTNode* phead = NULL;SLTPushBack(&phead, 1);SLTPushBack(&phead, 2);SLTPushBack(&phead, 3);SLTPushBack(&phead, 4);SLTPrint(phead);SLTNode* ret = SLTFind(phead, 2);printf("%d\n", ret->data);ret->data *= 2;SLTPrint(phead);SLTInsert(&phead, ret, 5);SLTPrint(phead);SLTInsertAfter(ret, 10000);SLTPrint(phead);SLTEraseAfter(ret);SLTPrint(phead);SLTErase(&phead, ret);SLTPrint(phead);SLTDestroy(phead);phead = NULL;SLTPrint(phead);}int main()
{test2();return 0;
}
1.4单链表的优缺点
其优缺点如下:
优点
- 动态性:单链表可以根据需要动态地分配和释放内存空间,无需预先知道数据的数量,在插入和删除节点时,只需修改指针,不需要移动大量数据,操作效率较高。例如在实时处理大量用户请求的系统中,使用单链表可以灵活地添加和删除请求节点。
- 插入和删除操作简便:在单链表中插入和删除节点通常只需要修改相关节点的指针,时间复杂度为O(1)。比如要在两个节点A和B之间插入节点C,只需让A的指针指向C,C的指针指向B即可。
- 节省内存:相较于一些需要连续内存空间的数据结构,单链表的节点可以分散存储在内存中,能更有效地利用内存碎片,只要内存中有可用空间,就可以创建新节点。
缺点
- 随机访问困难:单链表只能顺序访问,要访问第i个节点,必须从表头开始逐个节点遍历,时间复杂度为O(n)。比如要查找链表中间的某个节点,需要从头开始依次查找。
- 额外空间开销:每个节点除了存储数据本身外,还需要额外的空间存储指针,当数据量较小时,指针占用的空间比例可能较大,会造成一定的空间浪费。
- 节点指针易出错:在进行插入、删除操作或遍历链表时,如果指针操作不当,如指针丢失、指针指向错误等,可能会导致链表结构破坏,出现数据丢失或程序崩溃等问题。而且调试这类问题相对困难。
2.双向带头循环链表
篇幅至此,且容我下次再续
总结
- 单链表是一种优缺点都很鲜明的数据结构。在实际的编程应用中,我们需要根据具体的需求和场景来权衡是否选择使用单链表。如果应用场景对插入和删除操作的效率要求较高,而对随机访问的需求较少,同时内存空间比较零散,那么单链表无疑是一个很好的选择。但如果需要频繁地进行随机访问操作,或者对内存空间的利用率要求极高,我们可能就需要考虑其他更合适的数据结构了。通过深入了解单链表的特性,我们能够在编程过程中更加游刃有余地选择和运用合适的数据结构,从而编写出更高效、更优质的代码。
相关文章:
数据结构初探:链表之单链表篇
本文图皆为作者手绘,所有代码基于vs2022运行测试 系列文章目录 数据结构初探:顺序表篇 文章目录 系列文章目录前言一、链表基础概念二、链表的分类简化边界条件处理使代码更清晰简洁提高程序稳定性 1.单链表(不带头不循环的单链表);1.1存储结构;1.2准备工作1.3链表增删查改的实…...

介绍一下Mybatis的底层原理(包括一二级缓存)
表面上我们的就是Sql语句和我们的java对象进行映射,然后Mapper代理然后调用方法来操作数据库 底层的话我们就涉及到Sqlsession和Configuration 首先说一下SqlSession, 它可以被视为与数据库交互的一个会话,用于执行 SQL 语句(Ex…...

Linux基础 ——tmux vim 以及基本的shell语法
Linux 基础 ACWING y总的Linux基础课,看讲义作作笔记。 tmux tmux 可以干嘛? tmux可以分屏多开窗口,可以进行多个任务,断线,不会自动杀掉正在进行的进程。 tmux – session(会话,多个) – window(多个…...

64位的谷歌浏览器Chrome/Google Chrome
64位的谷歌浏览器Chrome/Google Chrome 在百度搜索关键字:chrome,即可下载官方的“谷歌浏览器Chrome/Google Chrome”,但它可能是32位的(切记注意网址:https://www.google.cn/...., 即:google.cnÿ…...

jetson编译torchvision出现 No such file or directory: ‘:/usr/local/cuda/bin/nvcc‘
文章目录 1. 完整报错2. 解决方法 1. 完整报错 jetson编译torchvision,执行python3 setup.py install --user遇到报错 running build_ext error: [Errno 2] No such file or directory: :/usr/local/cuda/bin/nvcc完整报错信息如下: (pytorch) nxnx-desktop:~/Do…...

多线程创建方式三:实现Callable接口
实现Callable第三种方式存在的原因 作用:可以返回线程执行完毕后的结果。 前两种线程创建方式都存在的一个问题:假如线程执行完毕后有一些数据需要返回,他们重写的run方法均不能直接返回结果。 如何实现 ● JDK 5.0提供了Callable接口和FutureTask类来…...

Linux下的编辑器 —— vim
目录 1.什么是vim 2.vim的模式 认识常用的三种模式 三种模式之间的切换 命令模式和插入模式的转化 命令模式和底行模式的转化 插入模式和底行模式的转化 3.命令模式下的命令集 光标移动相关的命令 复制粘贴相关命令 撤销删除相关命令 查找相关命令 批量化注释和去…...

Docker技术相关学习二
一、Docker简介 1.Docker之父Solomon Hykes形容docker就像传统的货运集装箱。 2.docker的特点和优势: 轻量级虚拟化:Docker容器相较于传统的虚拟机更加的轻量和高效,能够快速的启动和停止来节省系统资源。 一致性:确保应用程序在不…...

【人工智能】多模态学习在Python中的应用:结合图像与文本数据的深度探索
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 多模态学习是人工智能领域的一个重要研究方向,旨在通过结合多种类型的数据(如图像、文本、音频等)来提高模型的性能。本文将深入探讨多模…...

【MySQL】常用语句
目录 1. 数据库操作2. 表操作3. 数据操作(CRUD)4. 高级查询5. 索引管理6. 用户与权限7. 数据导入导出8. 事务控制9. 其他实用语句注意事项 如果这篇文章对你有所帮助,渴望获得你的一个点赞! 1. 数据库操作 创建数据库 CREATE DATA…...

Docker网络基础
一、Docker网络基础 1.docker安装后会自动创建3中网络,分别为bridge host none docker network ls 2.docker原生bridge网络: docker安装时会创建一个名为docker0的linux bridge,新建的容器会自动桥接到这个接口 bridge模式下没有公有ip,只有宿主机可以…...

重新刷题求职2-DAY2
977. 有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 示例 1: 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后…...

[STM32 标准库]EXTI应用场景 功能框图 寄存器
一、EXTI 外部中断在嵌入式系统中有广泛的应用场景,如按钮开关控制,传感器触发,通信接口中断等。其原理都差不多,STM32会对外部中断引脚的边沿进行检测,若检测到相应的边沿会触发中断,在中断中做出相应的处…...

Slint的学习
Slint是什么 Slint是一个跨平台的UI工具包,支持windows,linux,android,ios,web,可以用它来构建申明式UI,后端代码支持rust,c,python,nodejs等语言。 开源地址:https://github.com/slint-ui/slint 镜像地址:https://kkgithub.com/…...

STM32 DMA+AD多通道
接线图 代码配置 ADC单次扫描DMA单次转运模式 uint16_t AD_Value[4]; //DMAAD多通道 void DMA_Config(void) {//定义结构体变量 GPIO_InitTypeDef GPIO_InitStructure;//定义GPIO结构体变量 ADC_InitTypeDef ADC_InitStructure; //定义ADC结构体变量 DMA_InitTypeDef DMA_In…...

如何构建ObjC语言编译环境?构建无比简洁的clang编译ObjC环境?Windows搭建Swift语言编译环境?
如何构建ObjC语言编译环境? 除了在线ObjC编译器,本地环境Windows/Mac/Linux均可以搭建ObjC编译环境。 Mac自然不用多说,ObjC是亲儿子。(WSL Ubuntu 22.04) Ubuntu可以安装gobjc/gnustep和gnustep-devel构建编译环境。 sudo apt-get install gobjc gnus…...

【C语言】指针详解:概念、类型与解引用
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯指针的基本概念1. 什么是指针2. 指针的基本操作 💯指针的类型1. 指针的大小2. 指针类型与所指向的数据类型3. 指针类型与数据访问的关系4. 指针类型的实际意…...

VoIP中常见术语
在 VoIP(Voice over Internet Protocol,基于互联网协议的语音传输)技术中,涉及许多专业术语。以下是常见术语及其含义: 1. 核心协议相关 SIP(Session Initiation Protocol,会话发起协议…...

360嵌入式开发面试题及参考答案
解释一下 802.11ax 和 802.11ac/n 有什么区别 速度与带宽 802.11n 支持的最高理论速率为 600Mbps,802.11ac 进一步提升,单流最高可达 866.7Mbps,多流情况下能达到更高,如 1.3Gbps 等。而 802.11ax(Wi-Fi 6)引入了更多先进技术,理论最高速率可达 9.6Gbps,相比前两者有大…...

物理群晖SA6400核显直通win10虚拟机(VMM)
写在前面:请先确保你的核显驱动支持开启SR-IOV 确保你的BIOS开启了以下选项: VT-D VMX IOMMU Above 4G ResizeBAR 自行通过以下命令确认支持情况: dmesg | grep -i iommudmesg | grep DMAR分配1个虚拟vGPU:echo 1 | sudo tee /sy…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...
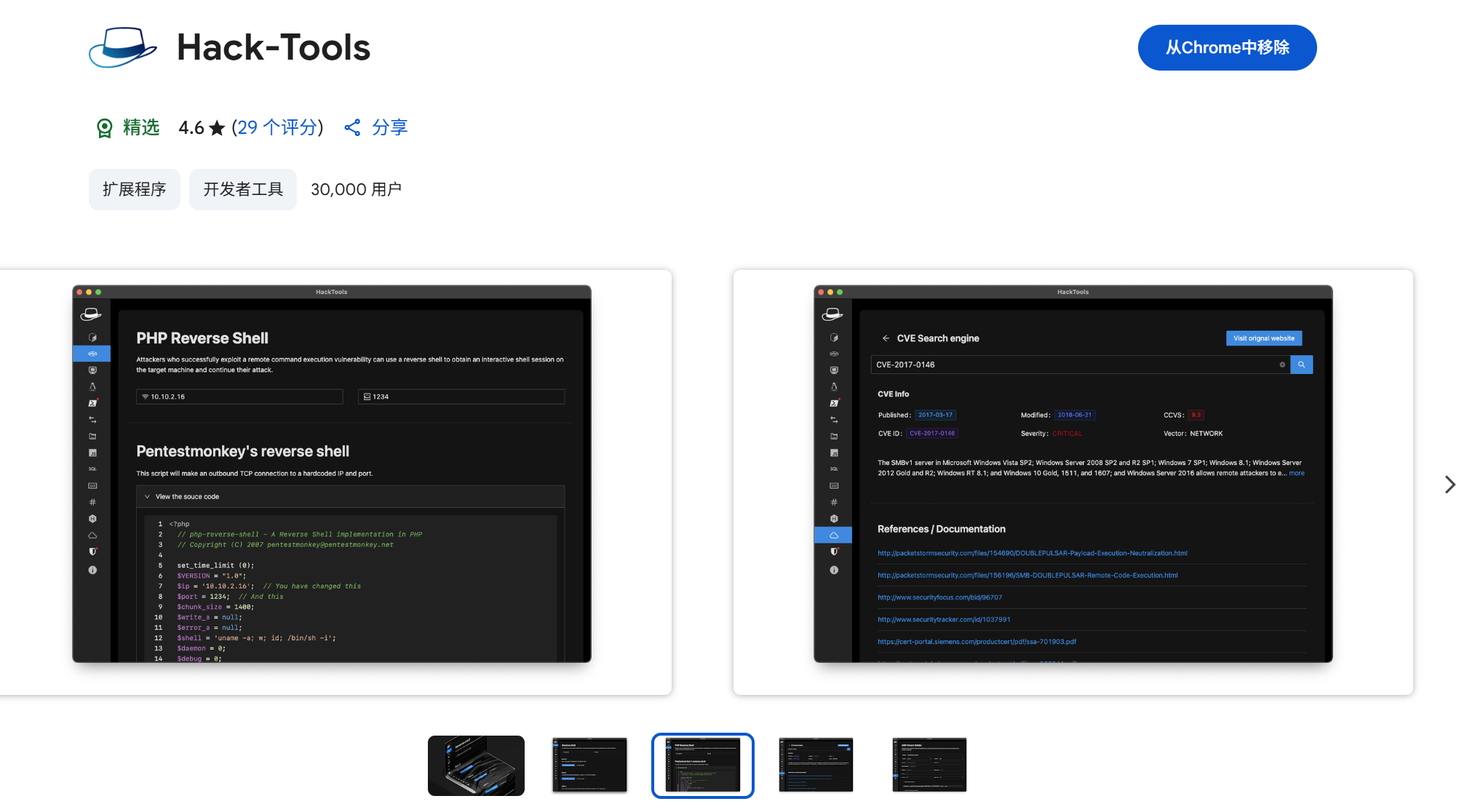
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...

跨平台商品数据接口的标准化与规范化发展路径:淘宝京东拼多多的最新实践
在电商行业蓬勃发展的当下,多平台运营已成为众多商家的必然选择。然而,不同电商平台在商品数据接口方面存在差异,导致商家在跨平台运营时面临诸多挑战,如数据对接困难、运营效率低下、用户体验不一致等。跨平台商品数据接口的标准…...