关于大数据
在大数据背景下存在的问题:
非结构化、半结构化数据:NoSQL数据库只负责存储;程序处理时涉及到数据移动,速度慢
是否存在一套整体解决方案?
可以存储并处理海量结构化、半结构化、非结构化数据
处理海量数据的速度很快,且扩展性强
大数据:数据达到一定规模以后,对数据进行存储和计算的技术
大数据的特征包括:
- 数据规模巨大(Volume)
- 生成和处理速度极快(Velocity)
- 数据类型多样(Variety)
- 价值巨大但密度较低(Value)
场景
离线和实时区分:数据是否有界。
离线:数据产生以后存起来(如10G),以后不会增加或减少,以后的计算都是这么大。(断网也可以断网)。--------适合批处理
实时:数据产生后直接计算。------适合流处理

生态

传统单机架构:比如在OS上安装了MySQL,OS为mysql提供了文件系统、通用计算(比如sql转成os的指令来执行)、资源管理。
大数据:有没有操作系统底层就是管理多个机器的?没有。所以我们要在软件层面来实现把OS构建成分布式的,然后这些分布式分别装不同组件。Hadoop
大数据开发的工作内容:
如果做数仓,就用sqoop把数据抽到HDFS,用spark或者mapreduce进行数据清洗,计算的结果放在Hive里或者sparksql。中间这些任务调度用Oozie或Azkaban。
对于流处理来说,用flume或lagstach去监控非结构化或半结构化的数据,用OGG/CDC监控数据库日志(结构化),把这些数据实时抽取到kafak,然后由流引擎,比如sparkes生态圈的spark streaming,或flink进行处理,数据处理之后再把结果存到HBase里进行保存或者es。
Hadoop分布式文件系统,有三个核心子项目(HDFS、Yarn、Mapreduce),围绕着这三个子项目发展出来的生态就是Hadoop生态圈。
HDFS


相关文章:
关于大数据
在大数据背景下存在的问题: 非结构化、半结构化数据:NoSQL数据库只负责存储;程序处理时涉及到数据移动,速度慢 是否存在一套整体解决方案? 可以存储并处理海量结构化、半结构化、非结构化数据 处理海量数据的速…...

9-收纳的知识
[ComponentOf(typeof(xxx))]组件描述,表示是哪个实体的组件 [EntitySystemOf(typeof(xxx))] 系统描述 [Event(SceneType.Demo)] 定义事件,在指定场景的指定事件发生后触发 [ChildOf(typeof(ComputersComponent))] 标明是谁的子实体 [ResponseType(na…...

堆的实现——堆的应用(堆排序)
文章目录 1.堆的实现2.堆的应用--堆排序 大家在学堆的时候,需要有二叉树的基础知识,大家可以看我的二叉树文章:二叉树 1.堆的实现 如果有⼀个关键码的集合 K {k0 , k1 , k2 , …,kn−1 } ,把它的所有元素按完全⼆叉树…...

机器学习6-全连接神经网络2
机器学习6-全连接神经网络2-梯度算法改进 梯度下降算法存在的问题动量法与自适应梯度动量法一、动量法的核心思想二、动量法的数学表示三、动量法的作用四、动量法的应用五、示例 自适应梯度与RMSProp 权值初始化随机权值初始化Xavier初始化HE初始化(MSRA) 
基于 SpringBoot 的电影购票系统
基于SpringBoot的电影购票系统是一个集成了现代化Web开发技术的在线电影票务平台。以下是对该系统的详细介绍: 一、系统背景与意义 随着电影行业的快速发展和观众对观影体验的不断追求,电影票务管理面临着越来越多的挑战。传统的票务管理方式存在效率低…...
——list)
C++SLT(三)——list
目录 一、list的介绍二、list的使用list的定义方式 三、list的插入和删除push_back和pop_backpush_front和pop_frontinserterase 四、list的迭代器使用五、list的元素获取六、list的大小控制七、list的操作函数sort和reversemergeremoveremove_ifuniqueassignswap 一、list的介…...

C++ Primer 算术运算符
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

数据结构-堆和PriorityQueue
1.堆(Heap) 1.1堆的概念 堆是一种非常重要的数据结构,通常被实现为一种特殊的完全二叉树 如果有一个关键码的集合K{k0,k1,k2,...,kn-1},把它所有的元素按照完全二叉树的顺序存储在一个一维数组中,如果满足ki<k2i…...

【玩转 Postman 接口测试与开发2_017】第13章:在 Postman 中实现契约测试(Contract Testing)与 API 接口验证(下)
《API Testing and Development with Postman》最新第二版封面 文章目录 第十三章 契约测试与 API 接口验证8 导入官方契约测试集合9 契约测试集合的详细配置9.1 env-apiKey 的创建与设置9.2 env-workspaceId 的设置9.3 Mock 服务器及 env-server 的配置9.4 API 测试实例的配置…...

R语言 | 使用 ComplexHeatmap 绘制热图,分区并给对角线分区加黑边框
目的:画热图,分区,给对角线分区添加黑色边框 建议直接看0和4。 0. 准备数据 # 安装并加载必要的包 #install.packages("ComplexHeatmap") # 如果尚未安装 library(ComplexHeatmap)# 使用 iris 数据集 #data(iris)# 选择数值列&a…...

React图标库: 使用React Icons实现定制化图标效果
React图标库: 使用React Icons实现定制化图标效果 图标库介绍 是一个专门为React应用设计的图标库,它包含了丰富的图标集合,覆盖了常用的图标类型,如FontAwesome、Material Design等。React Icons可以让开发者在React应用中轻松地添加、定制各…...

Python sider-ai-api库 — 访问Claude、llama、ChatGPT、gemini、o1等大模型API
目前国内少有调用ChatGPT、Claude、Gemini等国外大模型API的库。 Python库sider_ai_api 提供了调用这些大模型的一个完整解决方案, 使得开发者能调用 sider.ai 的API,实现大模型的访问。 Sider是谷歌浏览器和Edge的插件,能调用ChatGPT、Clau…...

DeepSeek、哪吒和数据库:厚积薄发的力量
以下有部分来源于AI,毕竟我认为AI还不能替代,他只能是辅助 快速迭代是应用程序不是工程 在这个追求快速迭代、小步快跑的时代,我们似乎总是被 “快” 的节奏裹挟着前进。但当我们静下心来,审视 DeepSeek 的发展、饺子导演创作哪吒…...

DDD - 微服务架构模型_领域驱动设计(DDD)分层架构 vs 整洁架构(洋葱架构) vs 六边形架构(端口-适配器架构)
文章目录 引言1. 概述2. 领域驱动设计(DDD)分层架构模型2.1 DDD的核心概念2.2 DDD架构分层解析 3. 整洁架构:洋葱架构与依赖倒置3.1 整洁架构的核心思想3.2 整洁架构的层次结构 4. 六边形架构:解耦核心业务与外部系统4.1 六边形架…...

第 1 天:UE5 C++ 开发环境搭建,全流程指南
🎯 目标:搭建 Unreal Engine 5(UE5)C 开发环境,配置 Visual Studio 并成功运行 C 代码! 1️⃣ Unreal Engine 5 安装 🔹 下载与安装 Unreal Engine 5 步骤: 注册并安装 Epic Game…...
】)
【华为OD-E卷 - 109 磁盘容量排序 100分(python、java、c++、js、c)】
【华为OD-E卷 - 磁盘容量排序 100分(python、java、c、js、c)】 题目 磁盘的容量单位常用的有M,G,T这三个等级, 它们之间的换算关系为1T 1024G,1G 1024M, 现在给定n块磁盘的容量,…...
)
【大数据技术】编写Python代码实现词频统计(python+hadoop+mapreduce+yarn)
编写Python代码实现词频统计(python+hadoop+mapreduce+yarn) 搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell) 搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn) 本机PyCharm连接CentOS虚拟机 在阅读本文前,请确保已经阅读过以上三篇文章,成功搭建了…...

5-Scene层级关系
Fiber里有个scene是只读属性,能从fiber中获取它属于哪个场景,scene实体中又声明了fiber,fiber与scene是互相引用的关系。 scene层级关系 举例 在unity.core中的EntityHelper中,可以通过entity获取对应的scene root fiber等属性…...

JVM执行流程与架构(对应不同版本JDK)
直接上图(对应JDK8以及以后的HotSpot) 这里主要区分说明一下 方法区于 字符串常量池 的位置更迭: 方法区 JDK7 以及之前的版本将方法区存放在堆区域中的 永久代空间,堆的大小由虚拟机参数来控制。 JDK8 以及之后的版本将方法…...
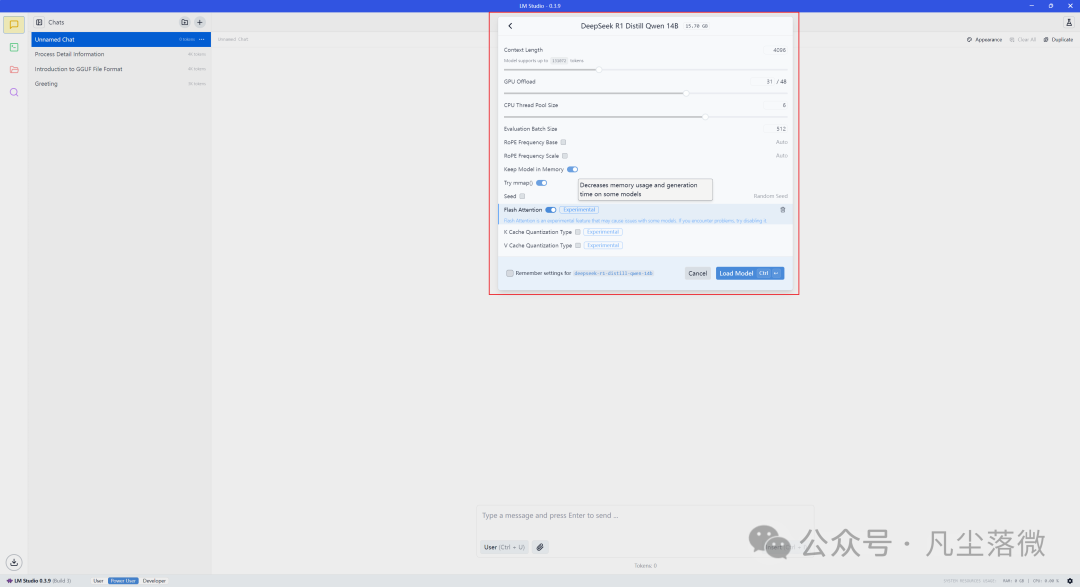
本地部署 DeepSeek-R1:简单易上手,AI 随时可用!
🎯 先看看本地部署的运行效果 为了测试本地部署的 DeepSeek-R1 是否真的够强,我们随便问了一道经典的“鸡兔同笼”问题,考察它的推理能力。 📌 问题示例: 笼子里有鸡和兔,总共有 35 只头,94 只…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...