大数据学习之Spark分布式计算框架RDD、内核进阶


一.RDD
28.RDD_为什么需要RDD

29.RDD_定义


30.RDD_五大特性总述


31.RDD_五大特性1


32.RDD_五大特性2


33.RDD_五大特性3

34.RDD_五大特性4

35.RDD_五大特性5

36.RDD_五大特性总结


37.RDD_创建概述


38.RDD_并行化创建


39.RDD_读取文件创建RDD


40.RDD_读取小文件创建RDD

41.RDD_算子概述

42.RDD_转换算子map


43.RDD_转换算子flatmap


44.RDD_转换算子reducebykey


45.RDD_转换算子filter


46.RDD_转换算子distinct


47.RDD_转换算子glom


48.RDD_转换算子groupby


49.RDD_转换算子groupbyKey



50.RDD_转换算子sortby

51.RDD_转换算子sortbyKey



52.RDD_转换算子union并集


53.RDD_转换算子交集和差集




54.RDD_转换算子关联算子


55.RDD_转换算子partitionBy



56.RDD_转换算子mapPatitions


57.RDD_转换算子sample



58.RDD_行动算子foreachPartition


59.RDD_行动算子foreach



60.RDD_行动算子saveAsTestFile




61.RDD_行动算子countByKey


62.RDD_行动算子reduce


63.RDD_行动算子fold



64.RDD_行动算子first_take_count



65.RDD_行动算子top_takeOrderd



66.RDD_行动算子takeSample



二.内核进阶
67.内核进阶_DAG概述


68.内核进阶_血缘关系



69.内核进阶_宽窄依赖关系

70.内核进阶_stage划分


71.内核进阶_任务调度概述


72.内核进阶_管道计算模式上


73.内核进阶_管道计算模式下




74.内核进阶_cache缓存



75.内核进阶_checkpoint检查点



76.内核进阶_cache和checkpoint区别


77.内核进阶_并行度


78.内核进阶_广播变量


79.内核进阶_累加器一


80.内核进阶_累加器二


81.内核进阶_累加器之重复计算



82.内核进阶_项目实战PVUV需求分析

83.内核进阶_项目实战PV分析



84.内核进阶_项目实战UV分析


85.内核进阶_二次排序实战



86.内核进阶_分组取topN实战



87.内核进阶_卡口统计项目需求分析



88.内核进阶_卡口统计项目统计正常的卡口



89.内核进阶_卡口统计项目TOP5



90.内核进阶_卡口统计项目统计不同区域同时出现的车辆


91.内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹一

92.内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹二


93.内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹三


94.内核进阶_卡口统计项目统计某卡口下通过的车辆轨迹四

相关文章:
大数据学习之Spark分布式计算框架RDD、内核进阶
一.RDD 28.RDD_为什么需要RDD 29.RDD_定义 30.RDD_五大特性总述 31.RDD_五大特性1 32.RDD_五大特性2 33.RDD_五大特性3 34.RDD_五大特性4 35.RDD_五大特性5 36.RDD_五大特性总结 37.RDD_创建概述 38.RDD_并行化创建 演示代码: // 获取当前 RDD 的分区数 Since ( …...

Unity 加载OSGB(webgl直接加载,无需转换格式!)
Unity webgl加载倾斜摄影数据 前言效果图后续不足 前言 Unity加载倾斜摄影数据,有很多的插件方便好用,但是发布到网页端均失败,因为webgl 的限制,IO读取失效。 前不久发现一个开源项目: UnityOSGB-main 通过两种方式在 Unity 中…...

tcp/ip网络协议,tcp/ip网络协议栈
TCP/IP网络协议和TCP/IP网络协议栈是互联网通信的基石,它们定义了电子设备如何连入因特网以及数据如何在它们之间传输的标准。以下是对TCP/IP网络协议和TCP/IP网络协议栈的详细解释: 一、TCP/IP网络协议 TCP/IP(Transmission Control Proto…...

【Debug】the remote host closed the connection错误信息分析
出现的情况说明:QT软件。刚开始都可以连接成功 之后连接 断开几次 就会出现连接失败 错误信息是the remote host closed the connection。the remote host closed the connection广泛原因分析 这个错误通常意味着远端 STM32 服务器主动关闭了连接。可能的原因包括&a…...

SpringBoot扩展篇:@Scope和@Lazy源码解析
SpringBoot扩展篇:Scope和Lazy源码解析 1. 研究主题及Demo2. 注册BeanDefinition3. 初始化属性3.1 解决依赖注入3.2 创建代理 ContextAnnotationAutowireCandidateResolver#getLazyResolutionProxyIfNecessary3.3 代理拦截处理3.4 单例bean与原型bean创建的区别 4. …...

“AI隐患识别系统,安全多了道“智能护盾”
家人们,在生活和工作里,咱们都知道安全那可是头等大事。不管是走在马路上,还是在工厂车间忙碌,又或是住在高楼大厦里,身边都可能藏着一些安全隐患。以前,发现这些隐患大多靠咱们的眼睛和经验,可…...

通向AGI之路:人工通用智能的技术演进与人类未来
文章目录 引言:当机器开始思考一、AGI的本质定义与技术演进1.1 从专用到通用:智能形态的范式转移1.2 AGI发展路线图二、突破AGI的五大技术路径2.1 神经符号整合(Neuro-Symbolic AI)2.2 世界模型架构(World Models)2.3 具身认知理论(Embodied Cognition)三、AGI安全:价…...

论文阅读:InstanceDiffusion: Instance-level Control for Image Generation
CVPR2024文章 摘要: 文本到图像扩散模型产生高质量的图像,但不提供对图像中单个实例的控制。我们引入了InstanceDiffusion,它将精确的实例级控制添加到文本到图像扩散模型中。InstanceDiffusion 支持每个实例的自由形式的语言条件ÿ…...

7.攻防世界 wzsc_文件上传
打开题目页面如下 上传了一张带有木马的图片 返回的页面是空白的,不过路径变了 猜测存在根目录/upload 也可以通过dirsearch扫描根目录 命令: dirsearch -u http://61.147.171.105:65024/ -e* 终于得到了上传的文件的信息 但是测试发现.php文件以及.…...

以为是响应式对象丢失导致数据没有回显
背景:之前ruoyi生成的vue2代码, <el-form ref“form”,后面我改成vue3的写法,没有实例化form, 在vue3中是需要定义const form ref(); 导致点击了修改后,页面弹框显示出来,数据没有回显。 一直…...

来 Gitcode 免费体验 DeepSeek 蒸馏模型,开启 AI 探索新旅程
在 AI 技术飞速发展的时代,你是否也怀揣着对前沿科技的无限好奇与探索欲望?然而,昂贵的模型体验费用和复杂的操作流程,是不是让你一次次望而却步?现在,这些都不再是问题!DeepSeek 蒸馏模型现已强…...

2.Mkdocs配置说明(mkdocs.yml)【最新版】
官方文件:Changing the colors - Material for MkDocs 建议详细学习一下上面的官方网站↑↑↑ 我把我目前的配置文件mkdocs.yml代码写在下面👇🏻 #[Info] site_name: Mkdocs教程 #your site name 显示在左上角 site_url: http://wcowin.wo…...

云轴科技ZStack+海光DCU:率先推出DeepSeek私有化部署方案
针对日益强劲的AI推理需求和企业级AI应用私有化部署场景(Private AI),云轴科技ZStack联合海光信息,共同推动ZStack智塔全面支持DeepSeek V3/R1/Janus Pro系列模型,基于海光DCU实现高性能适配,为企业提供安全…...

扩增子分析|零模型2——基于βNTI的微生物随机性和确定性装配过程(箱线图和柱状图R中实现)
一、引言 我们之前发布的周集中老师团队零模型R中实战案例:扩增子分析|基于零模型的群落确定性和随机性构建过程——R实战_bmntd-CSDN博客。在文末只输出了一个.csv 表格。并没有提供绘图的方法,有小伙伴问如何在R中一键成图呢?还真可以&…...

专题:剑指offer
链表 JZ6 从尾到头打印链表 思路:先顺序输出到栈里面 然后再以此从栈顶弹出即可 /** * struct ListNode { * int val; * struct ListNode *next; * ListNode(int x) : * val(x), next(NULL) { * } * }; */ #include …...

DeepSeek 部署过程中的问题
文章目录 DeepSeek 部署过程中的问题一、部署扩展:docker 部署 DS1.1 部署1.2 可视化 二、问题三、GPU 设置3.1 ollama GPU 的支持情况3.2 更新 GPU 驱动3.3 安装 cuda3.4 下载 cuDNN3.5 配置环境变量 四、测试 DeepSeek 部署过程中的问题 Windows 中 利用 ollama 来…...

DeepSeek R1本地化部署 Ollama + Chatbox 打造最强 AI 工具
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 Ollama 🦋 下载 Ollama🦋 选择模型🦋 运行模型🦋 使用 && 测试 二:🔥 Chat…...

应急场景中的数据融合与对齐
1. 概述 在应急管理中,快速、准确地掌握现场状况、实时监控灾情并进行决策至关重要。各类数据(如卫星影像、无人机图像、激光雷达点云、地理信息系统(GIS)数据、传感器数据、社交媒体信息、移动终端数据等)具有来源广泛、格式多样、时空特性不同等特点。如何将这些异构数…...

手机上运行AI大模型(Deepseek等)
最近deepseek的大火,让大家掀起新一波的本地部署运行大模型的热潮,特别是deepseek有蒸馏的小参数量版本,电脑上就相当方便了,直接ollamaopen-webui这种类似的组合就可以轻松地实现,只要硬件,如显存…...

Mellanox网卡信息查看
1、查看Mellanox网卡的SN(序列号)和PN mstvpd 04:00.0或者lspci -s 04:00.0 -vvv来自https://enterprise-support.nvidia.com/s/article/MLNX2-117-2532kn 2、查看Mellanox网卡驱动、固件版本 ethtool -i ens6np0...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...
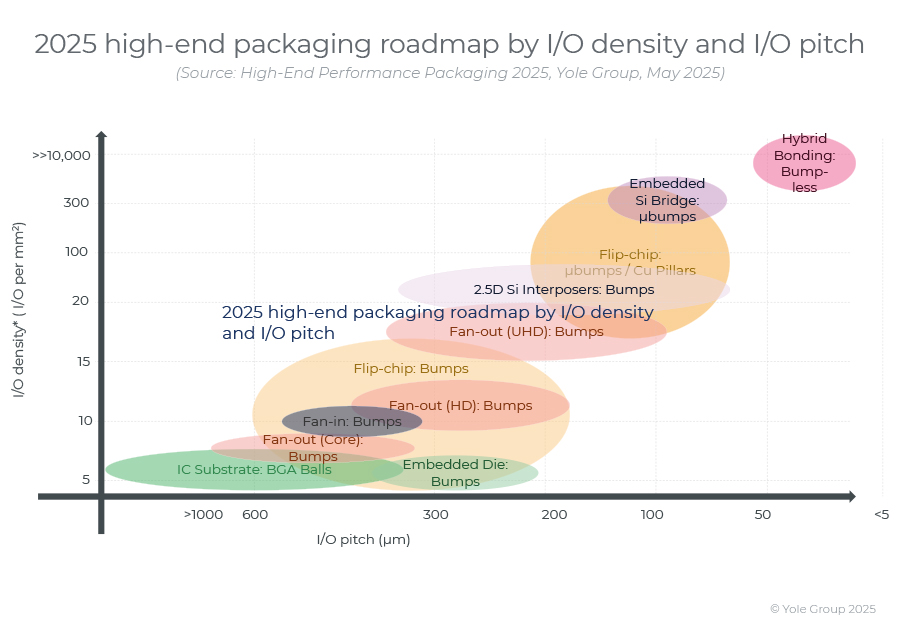
高端性能封装正在突破性能壁垒,其芯片集成技术助力人工智能革命。
2024 年,高端封装市场规模为 80 亿美元,预计到 2030 年将超过 280 亿美元,2024-2030 年复合年增长率为 23%。 细分到各个终端市场,最大的高端性能封装市场是“电信和基础设施”,2024 年该市场创造了超过 67% 的收入。…...

MeshGPT 笔记
[2311.15475] MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers https://library.scholarcy.com/try 真正意义上的AI生成三维模型MESHGPT来袭!_哔哩哔哩_bilibili GitHub - lucidrains/meshgpt-pytorch: Implementation of MeshGPT, SOTA Me…...

Python的__call__ 方法
在 Python 中,__call__ 是一个特殊的魔术方法(magic method),它允许一个类的实例像函数一样被调用。当你在一个对象后面加上 () 并执行时(例如 obj()),Python 会自动调用该对象的 __call__ 方法…...