P5:使用pytorch实现运动鞋识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
语言环境:python 3.7.12
编译器:pycharm
深度学习环境:tensorflow 2.7.0
数据:本地数据集-运动鞋

一、代码
# 1 设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasetsimport os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)# 2 导入数据
import os,PIL,random,pathlibdata_dir = './data_sneakers/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[1] for path in data_paths]
print(classeNames)
# 构建数据集
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸# transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transform = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])train_dataset = datasets.ImageFolder("./data_sneakers/train/",transform=train_transforms)
test_dataset = datasets.ImageFolder("./data_sneakers/test/",transform=test_transform)train_dataset.class_to_idxbatch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break# 3 构建简单的CNN
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 12, kernel_size=5, padding=0), # 12*220*220nn.BatchNorm2d(12),nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(12, 12, kernel_size=5, padding=0), # 12*216*216nn.BatchNorm2d(12),nn.ReLU())self.pool3 = nn.Sequential(nn.MaxPool2d(2)) # 12*108*108self.conv4 = nn.Sequential(nn.Conv2d(12, 24, kernel_size=5, padding=0), # 24*104*104nn.BatchNorm2d(24),nn.ReLU())self.conv5 = nn.Sequential(nn.Conv2d(24, 24, kernel_size=5, padding=0), # 24*100*100nn.BatchNorm2d(24),nn.ReLU())self.pool6 = nn.Sequential(nn.MaxPool2d(2)) # 24*50*50self.dropout = nn.Sequential(nn.Dropout(0.2))self.fc = nn.Sequential(nn.Linear(24 * 50 * 50, len(classeNames)))def forward(self, x):batch_size = x.size(0)x = self.conv1(x) # 卷积-BN-激活x = self.conv2(x) # 卷积-BN-激活x = self.pool3(x) # 池化x = self.conv4(x) # 卷积-BN-激活x = self.conv5(x) # 卷积-BN-激活x = self.pool6(x) # 池化x = self.dropout(x)x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 24*50*50) ==> (batch, -1), -1 此处自动算出的是24*50*50x = self.fc(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Model().to(device)
print(model)# 4 训练模型
# 训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss# 测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
# 设置动态学习率
def adjust_learning_rate(optimizer, epoch, start_lr):# 每 2 个epoch衰减到原来的 0.92lr = start_lr * (0.92 ** (epoch // 2))for param_group in optimizer.param_groups:param_group['lr'] = lrlearn_rate = 1e-4 # 初始学习率
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)# # 调用官方动态学习率接口时使用
# lambda1 = lambda epoch: (0.92 ** (epoch // 2))
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
# scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) #选定调整方法# 5 训练
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 40train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):# 更新学习率(使用自定义学习率时使用)adjust_learning_rate(optimizer, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,epoch_test_acc * 100, epoch_test_loss, lr))
print('Done')# 6 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now() # 获取当前时间epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()# 预测指定图片
from PIL import Imageclasses = list(train_dataset.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')# plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 预测训练集中的某张照片
predict_one_image(image_path='./data_sneakers/test/adidas/1.jpg',model=model,transform=train_transforms,classes=classes)# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
二、结果



三、总结
3.1导入数据步骤
● 第一步:使用pathlib.Path()函数将字符串类型的文件夹路径转换为pathlib.Path对象。
● 第二步:使用glob()方法获取data_dir路径下的所有文件路径,并以列表形式存储在data_paths中。
● 第三步:通过split()函数对data_paths中的每个文件路径执行分割操作,获得各个文件所属的类别名称,并存储在classeNames中
● 第四步:打印classeNames列表,显示每个文件所属的类别名称。
3.2 模型结构

3.3训练函数与测试函数区别
由于测试不进行梯度下降对网络权重进行更新,所以不需要传入优化器
3.4动态学习率
1. torch.optim.lr_scheduler.StepLR
等间隔动态调整方法,每经过step_size个epoch,做一次学习率decay,以gamma值为缩小倍数。
函数原型:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
关键参数详解:
● optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名
● step_size(int):是学习率衰减的周期,每经过每个epoch,做一次学习率decay
● gamma(float):学习率衰减的乘法因子。Default:0.1
用法示例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
2. lr_scheduler.LambdaLR
根据自己定义的函数更新学习率。
函数原型:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
关键参数详解:
● optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名
● lr_lambda(function):更新学习率的函数
用法示例:
lambda1 = lambda epoch: (0.92 ** (epoch // 2) # 第二组参数的调整方法
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) #选定调整方法
3. lr_scheduler.MultiStepLR
在特定的 epoch 中调整学习率
函数原型:
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
关键参数详解:
● optimizer(Optimizer):是之前定义好的需要优化的优化器的实例名
● milestones(list):是一个关于epoch数值的list,表示在达到哪个epoch范围内开始变化,必须是升序排列
● gamma(float):学习率衰减的乘法因子。Default:0.1
用法示例:
optimizer = torch.optim.SGD(net.parameters(), lr=0.001 )
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[2,6,15], #调整学习率的epoch数gamma=0.1)
更多的官方动态学习率设置方式可参考:https://pytorch.org/docs/stable/optim.html
调用官方接口示例:
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)for epoch in range(20):for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()scheduler.step()
相关文章:
P5:使用pytorch实现运动鞋识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 我的环境 语言环境:python 3.7.12 编译器:pycharm 深度学习环境:tensorflow 2.7.0 数据:本地数据集-运动鞋 一…...

讲解下SpringBoot中MySql和MongoDB的配合使用
在Spring Boot中,MySQL和MongoDB可以配合使用,以充分发挥关系型数据库和非关系型数据库的优势。MySQL适合处理结构化数据,而MongoDB适合处理非结构化或半结构化数据。以下是如何在Spring Boot中同时使用MySQL和MongoDB的详细讲解。 1. 添加依…...

《手札·行业篇》开源Odoo MES系统与SKF Observer Phoenix API在化工行业的双向对接方案
一、项目背景 化工行业生产过程复杂,设备运行条件恶劣,对设备状态监测、生产数据采集和质量控制的要求极高。通过开源Odoo MES系统与SKF Observer Phoenix API的双向对接,可以实现设备状态的实时监测、生产数据的自动化采集以及质量数据的同步…...
)
数据结构与算法之数组: LeetCode 905. 按奇偶排序数组 (Ts版)
按奇偶排序数组 https://leetcode.cn/problems/sort-array-by-parity/description/ 描述 给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。 返回满足此条件的 任一数组 作为答案。 示例 1 输入:n…...

【STM32】HAL库Host MSC读写外部U盘及FatFS文件系统的USB Disk模式
【STM32】HAL库Host MSC读写外部U盘及FatFS文件系统的USB Disk模式 在先前 分别介绍了FatFS文件系统和USB虚拟U盘MSC配置 前者通过MCU读写Flash建立文件系统 后者通过MSC连接电脑使其能够被操作 这两者可以合起来 就能够实现同时在MCU、USB中操作Flash的文件系统 【STM32】通过…...

docker nginx 配置文件详解
在平常的开发工作中,我们经常需要访问静态资源(图片、HTML页面等)、访问文件目录、部署项目时进行负载均衡等。那么我们就会使用到Nginx,nginx.conf 的配置至关重要。那么今天主要结合访问静态资源、负载均衡等总结下 nginx.conf …...

如何实现华为云+deepseek?
在华为云上实现跨账号迁移数据或部署DeepSeek模型,可以通过以下步骤完成: 跨账号数据迁移 创建委托:在源账号中创建一个委托(Agency),授予目标账号访问数据的权限。 复制镜像:在源账号中&…...

【学习笔记】计算机网络(三)
第3章 数据链路层 文章目录 第3章 数据链路层3.1数据链路层的几个共同问题3.1.1 数据链路和帧3.1.2 三个基本功能3.1.3 其他功能 - 滑动窗口机制 3.2 点对点协议PPP(Point-to-Point Protocol)3.2.1 PPP 协议的特点3.2.2 PPP协议的帧格式3.2.3 PPP 协议的工作状态 3.3 使用广播信…...

稀土抑烟剂——为汽车火灾安全增添防线
一、稀土抑烟剂的基本概念 稀土抑烟剂是一类基于稀土元素(如稀土氧化物和稀土金属化合物)开发的高效阻燃材料。它可以显著提高汽车内饰材料的阻燃性能,减少火灾发生时有毒气体和烟雾的产生。稀土抑烟剂不仅能提升火灾时的安全性,…...

Qt Pro、Pri、Prf
一、概述 1、在Qt中,通常使用.pro(project)、pri(private include)、prf(project file)三种文件扩展名来组织项目。对于模块化编程,Qt提供了Pro和Pri,Pro管理项目,Pri管理模块。 2、pro文件是Qt项目的核心文件,包含了…...

基于AIOHTTP、Websocket和Vue3一步步实现web部署平台,无延迟控制台输出,接近原生SSH连接
背景:笔者是一名Javaer,但是最近因为某些原因迷上了Python和它的Asyncio,至于什么原因?请往下看。在着迷”犯浑“的过程中,也接触到了一些高并发高性能的组件,通过简单的学习和了解,aiohttp这个…...

如何在MacOS上查看edge/chrome的扩展源码
步骤 进入管理扩展页面点击详细信息复制对应id在命令行键入 open ~/Library/Application Support/Microsoft Edge/Default/Extensions/${你刚刚复制的id} 即可打开访达中对应的更目录 注意 由于原生命令行无法直接处理空格 ,所以需要加转义符\,即:open ~/Librar…...
)
【xdoj-离散线上练习H】T234(C++)
解题心得: 写递归函数的时候,首先写终止条件,这有助于对整个递归函数的把握。 题目:输入集合A和B,输出A到B上的所有函数。 问题描述 给定非空数字集合A和B,求出集合A到集合B上的所有函数。 输入格式 第一行…...

Docker Desktop Windows 安装
一、先下载Docker desktop WIndows 下载地址 二、安装 安装超简单 一路 下一步 三、安装之后,桌面会出现一个 小蓝鲸图标,打开它 》更新至最新版本,不然小蓝鲸打开,一会就退出了。 》wsl --update (这个有时比较慢…...

springCloud-2021.0.9 之 GateWay 示例
文章目录 前言springCloud-2021.0.9 之 GateWay 示例1. GateWay 官网2. GateWay 三个关键名称3. GateWay 工作原理的高级概述4. 示例4.1. POM4.2. 启动类4.3. 过滤器4.4. 配置 5. 启动/测试 前言 如果您觉得有用的话,记得给博主点个赞,评论,收…...

JDK8 stream API用法汇总
目录 1.集合处理数据的弊端 2. Steam流式思想概述 3. Stream流的获取方式 3.1 根据Collection获取 3.1 通过Stream的of方法 4.Stream常用方法介绍 4.1 forEach 4.2 count 4.3 filter 4.4 limit 4.5 skip 4.6 map 4.7 sorted 4.8 distinct 4.9 match 4.10 find …...

windows生成SSL的PFX格式证书
生成crt证书: 安装openssl winget install -e --id FireDaemon.OpenSSL 生成cert openssl req -x509 -newkey rsa:2048 -keyout private.key -out certificate.crt -days 365 -nodes -subj "/CN=localhost" 转换pfx openssl pkcs12 -export -out certificate.pfx…...

玩转大语言模型——使用Kiln AI可视化环境进行大语言模型微调数据合成
系列文章目录 玩转大语言模型——使用langchain和Ollama本地部署大语言模型 玩转大语言模型——三分钟教你用langchain提示词工程获得猫娘女友 玩转大语言模型——ollama导入huggingface下载的模型 玩转大语言模型——langchain调用ollama视觉多模态语言模型 玩转大语言模型—…...

2025 西湖论剑wp
web Rank-l 打开题目环境: 发现一个输入框,看一下他是用上面语言写的 发现是python,很容易想到ssti 密码随便输,发现没有回显 但是输入其他字符会报错 确定为ssti注入 开始构造payload, {{(lipsum|attr(‘global…...

FPGA 28 ,基于 Vivado Verilog 的呼吸灯效果设计与实现( 使用 Vivado Verilog 实现呼吸灯效果 )
目录 前言 一. 设计流程 1.1 需求分析 1.2 方案设计 1.3 PWM解析 二. 实现流程 2.1 确定时间单位和精度 2.2 定义参数和寄存器 2.3 实现计数器逻辑 2.4 控制 LED 状态 三. 整体流程 3.1 全部代码 3.2 代码逻辑 1. 参数定义 2. 分级计数 3. 状态切换 4. LED 输…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...
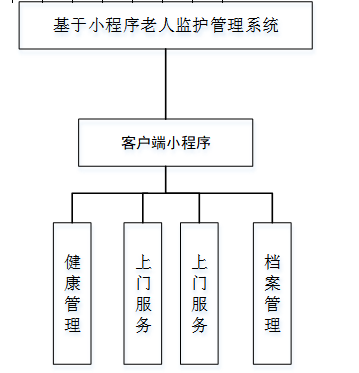
基于小程序老人监护管理系统源码数据库文档
摘 要 近年来,随着我国人口老龄化问题日益严重,独居和居住养老机构的的老年人数量越来越多。而随着老年人数量的逐步增长,随之而来的是日益突出的老年人问题,尤其是老年人的健康问题,尤其是老年人产生健康问题后&…...

OpenHarmony标准系统-HDF框架之I2C驱动开发
文章目录 引言I2C基础知识概念和特性协议,四种信号组合 I2C调试手段硬件软件 HDF框架下的I2C设备驱动案例描述驱动Dispatch驱动读写 总结 引言 I2C基础知识 概念和特性 集成电路总线,由串网12C(1C、12C、Inter-Integrated Circuit BUS)行数据线SDA和串…...