STL中list的模拟实现
文章目录
- 1. 前言and框架
- 2. 相对完整的框架
- 3. 模拟实现接口
- 1. 迭代器的引入
- 2. 迭代器的区分
- list迭代器
- 迭代器的构造
- list迭代器的实现
- 模拟指针
- 解引用
- 前置++和前置--
- 后置++和--
- 迭代器!=
- 迭代器->
- list的const迭代器
- 迭代器模板
- 迭代器是否需要析构,拷贝构造,赋值重载
- 3. 迭代器begin(),end()
- 2. push_back
- 3. insert和erase
- 4.push_back,push_front,pop_back,pop_front
- 构造
- 1. 默认构造
- 2. 迭代器区间构造
- 3. 拷贝构造(深拷贝)
- 4. 析构
- 赋值重载
- 4. list和vector对比
1. 前言and框架
首先,我们要明白list的本质是什么,list的本质是带头双向循环链表
- 注意事项
- 类模板的声明:在类前面加一个模板
template<class T>即可 - 需要创建一个类list,但list的底层是带头双向循环链表。链表则需要结点,那我们就还需要创建要给结点的类。【总结:就是在列表list中有一个头结点的指针。一个结点里面又会有数据,前一个,后一个结点指针】
- 这是自己模拟实现的,则需要有命名空间,否则编译器会调用库里的list
- 如果类里面的内容都是公有的,那么则可以使用struct。有公有和私有,那么使用class(这是惯例,但不是规定)。在struct中,如果没有对某个内容用限定符修饰,那么它就是私有。
- 一共两个类。
list_node(结点)和list(列表)
namespace hou
{template<class T>struct list_node{//在list_node中,存放这个结点的数据,前一个和后一个结点指针,T _data;list_node<T>* _next;list_node<T>* _prev;};template<class T>class list{typedef list_node<T> Node;private:Node* _head;};
}
-
typedef list_node<T> Node;这一步是为了防止大家忘记写模板参数< T>。
在class中,class没有用限定符修饰,是私有的。因此,只有在这个类里面才可以用Node,在这个类里面Node才代表list_node<T>. -
为什么
list_node的所有成员全部对外开放?
因为链表list在增删查改的时候需要高频地控制list_node的成员变量。如果list_node的成员都私有的话,则需要友元函数,比较麻烦。
但是全部对外开放,不害怕别人修改你的数据吗?
其实是很难修改的。我们在使用list的时候,是感知不到底层的结点,哨兵位之类的东西的。我们只是看到了它的各种接口,可以感知到它是双向的。想修改内容,需要知道变量的名称,命名空间的名字。所以,虽然开放,但是也安全。 -
list中大部分用迭代器。在此之前,有迭代器失效这个概念,这里也会出现。但string中也有迭代器失效,但比较少,因为大部分用下标访问,较少使用迭代器。vector也有迭代器失效。
2. 相对完整的框架
- 牢记牢记牢记:为了方便,我们已经将
list_node<T>在list这个类里面typedef为Node。 - 给list构造(无参):
void empty_init(){_head = new Node(); //_head的类型是Node*(也就是list_node<T>)结点的指针_head->_prev = _head;_head->_next = _head;}list(){empty_init();}
- list_node的构造
list_node(const T& x = T()):_data(x),_next(nullptr),_prev(nullptr){}
- 迭代器
面向对象的三大特征:封装,继承,多态。
封装可以用类和迭代器来实现。(它可以用来“屏蔽底层的实现细节,屏蔽个容器的结构差异,本质是封装底层细节和差异,提供同一的访问方式)
只需要提供一个结点即可

namespace hou
{template<class T>struct list_node{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T& x = T()):_data(x),_next(nullptr),_prev(nullptr){}};template<class T>struct list_iterator{typedef list_node<T> Node;Node* _node;}; template<class T>class list{typedef list_node<T> Node;public:typedef list_iterator<T> iterator; void empty_init(){_head = new Node(); //_head的类型是Node*(也就是list_node<T>)结点的指针_head->_prev = _head;_head->_next = _head;}list(){empty_init();}private:Node* _head;};
}
3. 模拟实现接口
1. 迭代器的引入
把原生指针直接命名为迭代器?迭代器的价值在于封装底层,不具体暴露底层的实现细节,提供统一的访问方式。(比如:在使用list的时候,我们并不能知道底层的结点,哨兵位之类的,这就是对底层的封装,不暴露底层的细节)
迭代器有两个特征:解引用,++/–
vector和string类,它的物理空间是连续的(那原生指针就可能是迭代器),那解引用得到的就是数据了。但对于空间不连续的list,那解引用是得不到数据的(node*解引用是node,并不是数据)。
既然空间已经是不连续了,更不用说++指向下一个结点了
所以,对于list的迭代器,原生指针已经不符合我们的需求了,我们需要去进行特殊处理:进行类的封装。我们可以通过类的封装以及运算符重载支持,这样就可以实现像内置类型一样的运算符。
2. 迭代器的区分
迭代器也分为普通迭代器和const迭代器。
何时用const的迭代器呢?当const的容器想用迭代器的时候,必须用const的迭代器。【注:const修饰之后,只有在定义的时候才有初始化的机会,可以在定义的时候进行push_back();】
但首先我们要先明白const是在 *左边,还是 *右边呢?
const int* p1; //左定值
int* const p2; //右定址
const在int*前面,则是修饰p1所指向的内容(int*这个类型)。const在int*的后边,在p2的前面,则const是在修饰p2这个迭代器(可能是指针)【左定值,右定址】
那么在list的const迭代器中,const修饰谁呢?
在while中,有一个步骤是将迭代器++,这个步骤就决定了const不是用来修饰迭代器/地址/指针,因为迭代器还要++呢,所以const迭代器类似于模拟p1的行为,保护指向的对象不被修改,迭代器本身可以修改。
迭代器的实现我们需要去考虑普通迭代器和const迭代器。这两种迭代器不同,也会带来不同的接口,我们先去分开实现(提供一个结点即可)
list迭代器
迭代器的构造
这里list的迭代器并不是原生指针,而是用一个类封装的。
一个类型的构造函数是用来构造自己类型的对象的,迭代器类型要构造迭代器对象就需要构造函数。
template<class T>struct list_iterator //struct代表着:全开放{typedef list_node<T> Node;Node* _node; //迭代器中的一个成员变量(公有)list_iterator(Node* pnode):_node(pnode){}};
list迭代器的实现
template<class T>
struct list_iterator
{typedef list_node<T> Node;Node* _node;list_iterator(Node* pnode):_node(pnode){}
};
模拟指针
解引用
T& operator*(){return _node->_data; //返回此结点的值}
前置++和前置–
即想要下一个结点的数据(但之前的地址++是不可取的,list的物理空间不连续),那我们可以让结点变成结点的_next
Self& operator++(){_node = _node->_next;return *this;}Self& operator--(){_node = _node->_prev;return *this;}后置++和–
就是要给这个变量++和–,但是此刻用的还是没有经过++和–的值
Self operator++(int a){Self tmp(*this);//Self是list_iterator<T>_node = _node->_next;return tmp;}Self operator--(int a){Self tmp(*this);//Self是list_iterator<T>_node = _node->_prev;return tmp;}
迭代器!=
判断迭代器是否相等,就需要看这两个迭代器所指向的结点是否相等。
谁是begin(),第一个结点。谁是end(),哨兵位是。
bool operator!=(const Self& s){return _node != s._node;}
迭代器->
.是直接访问对象的成员(类访问成员就用. 【调用类中的成员函数和成员变量:用. 】)
->是通过对象的指针访问成员。
T* operator->(){return &_node->_data;}
list的const迭代器
我们需要再实现一个单独的类,叫做list_const_iterator吧。这个与普通迭代器不同的是类名不同,operator*和operator->的返回值类型不同
template<class T>struct list_const_iterator{typedef list_node<T> Node;typedef list_const_iterator<T> Self;Node* _node; //迭代器中的一个成员变量(公有)list_const_iterator(Node* pnode):_node(pnode){}const T& operator*(){return _node->_data; //返回此结点的值}const T* operator->(){return &_node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self& operator--(){_node = _node->_prev;return *this;}Self operator++(int a){Self tmp(*this);//Self是list_iterator<T>_node = _node->_next;return tmp;}Self operator--(int a){Self tmp(*this);//Self是list_iterator<T>_node = _node->_prev;return tmp;}bool operator!=(const Self& s){return _node != s._node;}};迭代器模板
普通迭代器返回T&,可读可写,const迭代器返回const T&,可读不可写,上面的代码存在很大的问题:代码冗余,所以我们应该去解决这个问题:我们可以参考源码的实现:类模板参数解决这个问题,这也是迭代器的强大之处。
只有几个地方不一样,代表着普通和const迭代器高度相似。那我们可以用同一个类模板实现它们俩个(同一个类模板,只要我们传递不同的参数实例化成不同的迭代器
记得将list中的也修改

//typedef list_iterator<T,T&,T*> iterator;//typedef list_iterator<T,const T&,const T*> iterator; template<class T,class Ref,class Ptr>struct list_iterator{typedef list_node<T> Node;typedef list_iterator<T, Ref, Ptr> Self;Node* _node;Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self& operator--(){_node = _node->_prev;return *this;}Self operator++(int){Self tmp(*this);_node = _node->_next;return tmp;}Self operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};
迭代器是否需要析构,拷贝构造,赋值重载
- it访问完该结点,不可能将该结点释放掉,所以list迭代器不需要析构函数(迭代器只是通过这个系欸但访问,修改这个容器,释放结点是链表的事情
- 不析构------>那么也不需要拷贝构造和赋值重载(迭代器的拷贝构造和赋值重载我们并不需要自己去手动实现,编译器默认生成的就是浅拷贝(迭代器只是一个用来访问元素的工具,拷贝迭代器,也只是复制出了一个一模一样的工具,所以是浅拷贝),而我们需要的就是浅拷贝,这也说明了,并不是说如果有指针就需要我们去实现深拷贝。另外,迭代器通过结构体指针访问修改链表,所以,对于迭代器我们并不需要构造函数,结点的释放由链表管理。
3. 迭代器begin(),end()
谁是begin(),第一个结点。谁是end(),哨兵位是。

iterator begin(){return iterator(_head->_next);//调用迭代器构造list_iterator(Node* pnode)}iterator end(){return iterator(_head);//调用迭代器构造list_iterator(Node* pnode)}

2. push_back
第一种实现方式:
在链表中新插一个结点。
原来的最后一个tail(_head->prev)指向新结点。
新结点的_prev指向之前的最后一个(即tail)
新结点的_next指向第一个(即_head)
哨兵位的前一个指向新结点
void push_back(const T& x){Node* newnode = new Node(x);Node* tail = _head->_prev;tail->_next= newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;}
第二种实现方式:
可以先不实现头插/头删,先实现insert/erase,可以用这个实现头插/头删。
3. insert和erase
这两个都是写在list中的,因为插入或删除链表中的结点。

- insert可以在任意位置插入数据,无论是最后一个结点的前面还是哨兵位的前面都可以插入。(在哨兵位插入数据,哨兵位前一个不就是最后一个数据)
- Return value:An iterator that points to the first of the newly inserted elements.(返回值:指向第一个新插入元素的迭代器)
- erase不可以删除哨兵位的数据
- Return value:An iterator pointing to the element that followed the last element erased by the function call. This is the container end if the operation erased the last element in the sequence.(返回值:一个迭代器(这个迭代器指向,通过函数调用函数所删除的元素的下一个元素(fallowed紧跟着,也就是下一个)如果删除了序列的最后一个元素,这就是容器的结尾)

重点:erase记得最后删除那个结点

4.push_back,push_front,pop_back,pop_front
返回值:none
push_back是尾插


插入insert是将position这个位置换成插入的结点,那不就是position在插入结点之后吗,那end()的前面就是最后一个结点。
void push_back(const T& x)
{insert(end(), x);
}
头插push_front是在哨兵位之后,第一个结点之前。(第一个结点也就是lt.begin();)
void push_front(const T& x)
{insert(begin(), x);
}
尾删(返回值:none)
void pop_back()
{erase(iterator(end()--);
}
void pop_front()
{erase(begin());
}
构造
1. 默认构造

2. 迭代器区间构造
//迭代器区间构造template <class InputIterator>list(InputIterator first, InputIterator last){empty_init();while (first != last){push_back(*first);++first;}}
3. 拷贝构造(深拷贝)
在使用时的样子:lt2(lt1);
list(const list<T>& lt){empty_init();for (const auto& e : lt){push_back(e);}}
用范围for进行尾插,但是要注意要加上&,范围for是*it赋值给给e,又是一个拷贝,e是T类型对象,依次取得容器中的数据,T如果是string类型,不断拷贝,push_back之后又销毁。
现代写法:
先使用迭代区间构造(值也一样),再将两个结点的头结点交换(头结点不同,那指向的下一个结点也就不一样了)
void swap(list<T>& lt)
{std::swap(_head, lt._head);
}
list(const list<T>& lt)
{empty_init();list<T> tmp(lt.begin(), lt.end());swap(tmp);
}
4. 析构
对于list,有单独的clear()接口,list的析构可以直接复用clear(),同时还需要我们去释放掉头结点:
同时,我们也要知道clear()和~list()有什么区别
clear()只是将来自list容器的所有元素移除,再将size修改为0【clear()所有结点删除,哨兵位不动】
~list会将所有结点+哨兵位都删除
~list(){clear();//哨兵位也释放掉delete _head;_head = nullptr;}void clear(){iterator it = begin();while (it != end()){it = erase(it);//erase()函数会返回(所删除元素)的下一个元素的迭代器,就相当于++了}}
赋值重载
传统:
list<T>& operator=(list<T>& lt){if (this != <){clear();for (const auto& e : lt){push_back(e);}}return *this;}
现代:
若是想lt2=lt3;,需要先释放lt2,可以将参数改为list<T> lt;
先将lt3拷贝给给lt(lt和lt3有一样大的空间,一样大的值),这个时候可以将lt和lt2交换(这样子lt2时lt的内容,即和lt3一模一样。但同时lt3也没有被修改)
list<T>& operator=(list<T> lt){swap(lt);return *this;}
4. list和vector对比
vector:vector的优点在于下标的随机访问,尾插尾删效率高,CPU高速缓存命中高。而缺点在于前面部分插入删除数据效率低O(N),扩容有消耗,还存一定空间浪费。
list:list的优点在于无需扩容,按需申请释放,在任意位置插入删除O(1)。缺点在于不支持下标的随机访问,CPU高速缓存命中低。
vector和list的关系就像是在互补配合!

而对于string的insert和erase迭代器也会失效跟vector类似。但是我们并不太关注。因为string的接口参数大部分是下标支持,迭代器反而用得少。
相关文章:
STL中list的模拟实现
文章目录 1. 前言and框架2. 相对完整的框架3. 模拟实现接口1. 迭代器的引入2. 迭代器的区分list迭代器迭代器的构造list迭代器的实现模拟指针解引用前置和前置--后置和--迭代器!迭代器-> list的const迭代器迭代器模板迭代器是否需要析构,拷贝构造&…...

计算机网络知识速记:HTTP1.0和HTTP1.1
计算机网络知识速记:HTTP1.0和HTTP1.1 1. 基本概念 1.1 HTTP1.0 HTTP1.0是1996年发布的第一个正式版本,主要用于客户端与服务器之间的简单请求和响应交互。它的设计理念相对简单,适合处理一些基本的网页服务。 1.2 HTTP1.1 HTTP1.1是HTT…...

Apache Kafka 中的认证、鉴权原理与应用
编辑导读:本篇内容将进一步介绍 Kafka 中的认证、鉴权等概念。AutoMQ 是与 Apache Kafka 100% 完全兼容的新一代 Kafka,可以帮助用户降低 90%以上的 Kafka 成本并且进行极速地自动弹性。作为 Kafka 生态的忠实拥护者,我们也会持续致力于传播 …...
基础与实践)
DeepSeek自然语言处理(NLP)基础与实践
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,专注于让计算机理解、生成和处理人类语言。NLP技术广泛应用于机器翻译、情感分析、文本分类、问答系统等场景。DeepSeek提供了强大的工具和API,帮助我们高效地构建和训练NLP模型。本文将详细介…...

激光工控机在精密制造中的应用与优势
在精密制造中,激光工控机可以用于许多场景例如 激光切割与雕刻:用于金属、塑料、陶瓷等材料的精密切割和雕刻,适用于汽车、航空航天、电子等行业;可实现复杂图案和高精度加工,满足微米级精度要求。 激光焊接…...

Docker换源加速(更换镜像源)详细教程(2025.2最新可用镜像,全网最详细)
文章目录 前言可用镜像源汇总换源方法1-临时换源换源方法2-永久换源(推荐)常见问题及对应解决方案1.换源后,可以成功pull,但是search会出错 补充1.如何测试镜像源是否可用2.Docker内的Linux换源教程 换源速通版(可以直…...

12.14 算法练习
1. 每日温度 算法思路 1. 单调栈的作用:记录我们遍历过的元素,与当前的元素方便对比,本质是以空间换时间; 2. 比较当前元素与栈顶元素的大小,当当前元素大于栈顶元素时,持续弹出栈顶元素下标,…...

ASP.NET Core SignalR的分布式部署
假设聊天室程序被部署在两台服务器上,客户端1、2连接到了服务器A上的ChatRoomHub,客户端3、4连接到服务器B上的ChatRoomHub,那么客户端1发送群聊消息时,只有客户端1、2能够收到,客户端3、4收不到;在客户端3…...

Express 中间件
在构建 Web 应用程序时,中间件(Middleware)扮演着至关重要的角色。它允许你定义一系列的函数来处理 HTTP 请求和响应过程中的各种任务。Express.js 是 Node.js 上最流行的框架之一,以其简洁且强大的中间件机制著称。本文将深入探讨…...

ABB能源自动化选用宏集Cogent DataHub避免DCOM问题,实现高效、安全的数据传输
案例概况 ABB能源自动化公司通过宏集Cogent DataHub软件将电厂设施的数据实时传输到公司办公室,实现了OPC隧道/镜像解决方案,在电厂和公司网络之间建立了一个安全、可靠的连接,确保数据传输的高度安全,减少入侵风险。 ࿰…...

springboot239-springboot在线医疗问答平台(源码+论文+PPT+部署讲解等)
💕💕作者: 爱笑学姐 💕💕个人简介:十年Java,Python美女程序员一枚,精通计算机专业前后端各类框架。 💕💕各类成品Java毕设 。javaweb,ssm…...

【Elasticsearch】分析器的构成
在Elasticsearch中,分析器(Analyzer)是一个处理文本数据的管道,它将输入的文本转换为一系列词元(tokens),并可以对这些词元进行进一步的处理和规范化。分析器由以下三个主要组件构成:…...

Python 调用 Azure OpenAI API
在人工智能和机器学习快速发展的今天,Azure OpenAI 服务为开发者提供了强大的工具来集成先进的 AI 能力到他们的应用中。本文将指导您如何使用 Python 调用 Azure OpenAI API,特别是使用 GPT-4 模型进行对话生成。 准备工作 在开始之前,请确保您已经: 拥有一个 Azure 账户…...

数据结构 算法时间复杂度和空间复杂度
一、算法好坏的度量 【事前分析法】 算法设计好后,根据算法的设计原理,只要问题规模确定,算法中基本语句执⾏次数和需求资源个数 基本也就确定了。 ⽐如求1 2 3 ... n − 1 n ,可以设计三种算法: 算法Aÿ…...

CNN-BiGRU卷积神经网络双向门控循环单元多变量多步预测,光伏功率预测
CNN-BiGRU卷积神经网络双向门控循环单元多变量多步预测,光伏功率预测 代码下载:CNN-BiGRU卷积神经网络双向门控循环单元多变量多步预测,光伏功率预测 一、引言 1.1、研究背景及意义 随着全球能源危机和环境问题的日益严重,可再…...

钉钉位置偏移解决,钉钉虚拟定位打卡
虚拟定位打卡工具 一,介绍免费获取工具 一,介绍 提到上班打卡,职场人的内心戏估计能拍成一部连续剧。打卡,这俩字仿佛自带“紧箍咒”,让无数打工人又爱又恨。想象一下,你气喘吁吁地冲进办公室,…...

【面试集锦】如何设计SSO方案?和OAuth有什么区别?
如何设计SSO方案?和OAuth有什么区别?--楼兰 带你聊最纯粹的Java 如果面试问你,你会做一个权限系统吗?那你肯定会说做过。不就是各种登录、验证吗。我做的第一个CRUD应用就是注册、登录。简单!但是,如果问你在工作中真的做过权限系统吗?其实很多人都只能默默摇摇头。因…...

Python 基于 OpenCV 的人脸识别上课考勤系统(附源码,部署教程)
博主介绍:✌2013crazy、10年大厂程序员经历。全网粉丝12W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&a…...

vcredist_x64.exe 是 Microsoft Visual C++ Redistributable 的 64 位版本
vcredist_x64.exe 是 Microsoft Visual C++ Redistributable 的 64 位版本,它提供了运行基于 Visual C++ 编写的应用程序所需的库文件。许多 Windows 应用程序都依赖这些库来正常运行,特别是使用 Visual Studio 编译的程序。 用途和重要性: 运行时库:vcredist_x64.exe 安装…...

Tailwind CSS 的核心理念
实用优先(Utility-First) Tailwind CSS 的最核心理念是"实用优先"。这种方法颠覆了传统的 CSS 开发方式,不再编写自定义的类名和样式规则,而是通过组合预定义的工具类来构建界面。这种方式带来了以下优势: …...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...
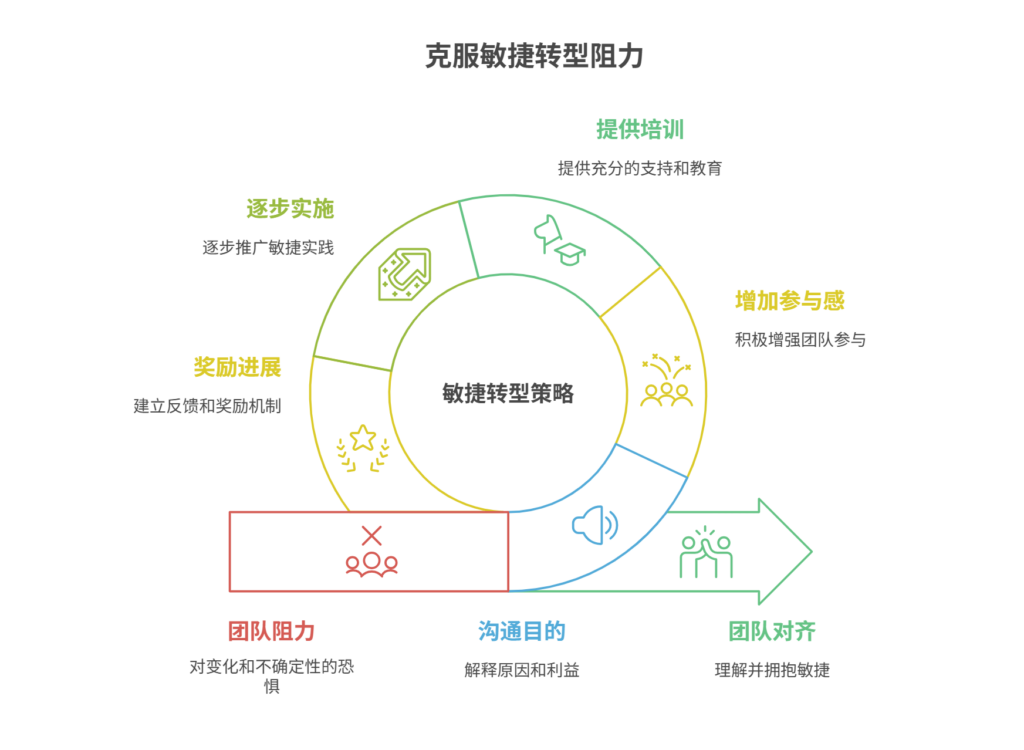
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...