Redis7——进阶篇(五)
前言:此篇文章系本人学习过程中记录下来的笔记,里面难免会有不少欠缺的地方,诚心期待大家多多给予指教。
基础篇:
- Redis(一)
- Redis(二)
- Redis(三)
- Redis(四)
- Redis(五)
- Redis(六)
- Redis(七)
- Redis(八)
进阶篇:
- Redis(九)
- Redis(十)
- Redis(十一)
- Redis(十二)
接上期内容:上期完成了相关案例的学习。下面学习缓存穿透、预热、雪崩、击穿,话不多说,直接发车。
一、缓存预热
(一)、定义
缓存预热是一种在系统启动阶段或者特定时间点,将一些经常访问或者关键的数据提前加载到缓存中的操作,以减少对数据源(如数据库)的访问次数,从而提高系统的响应速度和性能。避免在用户首次请求时才去加载数据而导致的性能延迟。
(二)、功能
- 减少首次请求延迟:当用户首次访问某些数据时,如果没有进行缓存预热,系统需要从数据库等数据源中查询数据,这个过程可能会比较耗时。
- 减轻数据库压力:在系统运行初期,如果大量用户同时发起请求,这些请求都直接访问数据库,会给数据库带来巨大的压力,甚至可能导致数据库性能下降或者崩溃。缓存预热可以将部分数据提前加载到缓存中,后续的请求优先从缓存中获取数据,从而减少了对数据库的访问频率,降低了数据库的负载
- 提高系统性能和稳定性:由于缓存的读写速度通常比数据库等数据源快很多,缓存预热可以让系统在处理请求时更快地获取数据,从而提高系统的整体性能。同时,减少了对数据库的依赖,降低了因数据库故障或性能问题导致系统不可用的风险,增强了系统的稳定性。
(三)、常用方案
- 硬编码(不大推荐):在代码中直接明确地指定需要加载到缓存的数据和逻辑,不通过外部配置或动态计算来改变。在系统启动时,按照预先编写好的代码逻辑将数据加载到缓存中。
- @PostConstruct注解: Java 中的一个注解,用于标记一个方法,该方法会在依赖注入完成之后、对象正式投入使用之前被自动调用。
- 定时器任务:通过定时任务框架(如 Spring 的@Scheduled注解、Quartz 等),按照预设的时间间隔(如每天凌晨、每小时等)自动执行缓存预热操作。
- 数据脚本:使用脚本语言(如 Python、Shell 等)编写脚本,通过脚本连接到缓存系统,将数据加载到缓存中。
二、缓存雪崩
(一)、名词解释
缓存雪崩是指在某一时刻,缓存中大量的键在同一时间点或者在极短的时间内集中过期失效,或者缓存服务器发生故障导致缓存服务不可用,此时大量原本可以从缓存中获取数据的请求,都直接涌向了数据库等后端数据源,给数据库带来巨大的压力,甚至可能导致数据库不堪重负而崩溃,进而使整个系统出现性能急剧下降、服务不可用等严重问题。
(二)、发生场景
1、硬件方面
缓存服务器的硬件设备(如硬盘、内存、网卡等)出现故障,可能会导致缓存服务无法正常运行,从而发生缓存雪崩现象。
2、业务方面
大量的业务key同时过期,比如在进行缓存预热时,为大量缓存数据设置了相同的过期时间,当这个过期时间到达时,这些缓存数据会同时失效,从而引起缓存雪崩现象。
(三)、预防与解决措施
硬件方面无法把控,主要从业务方面来解决。
业务方面:
-
避免大量缓存键同时过期:①、设置随机时间:在设置缓存键的过期时间时,为每个键的过期时间添加一个随机的偏移量,避免它们集中在同一时刻过期。②、设置key用不过期。
-
redis集群实现服务高可用:使用缓存服务器的集群模式,集群模式可以将数据分散存储在多个节点上,当某个节点出现故障时,其他节点仍然可以正常提供服务,保证缓存服务的可用性。
-
多缓存结合:采用多级缓存架构,例如同时使用本地缓存(ehcache)+redis缓存。
-
服务降级:在应用层对请求进行限流,当请求量超过一定阈值时,直接拒绝部分请求,避免过多的请求直接访问数据库。
三、缓存穿透
(一)、名词解释
缓存穿透是指客户端请求的数据在缓存中不存在,同时在数据库中也不存在,这样每次该请求都会穿透缓存,直接访问数据库。如果有大量这样的无效请求持续涌入,会对数据库造成极大的压力,甚至可能导致数据库不堪重负而崩溃。例如,黑客可能会故意发起大量不存在的键的请求,以消耗数据库资源。
(二)、发生场景
- 黑客恶意攻击:攻击者可能会利用系统的漏洞,构造大量不存在的请求,如不存在的用户 ID、商品 ID 等,向系统发起请求。由于这些请求对应的数据在缓存和数据库中都不存在,会导致大量请求直接穿透缓存访问数据库,从而影响系统的正常运行。
- 业务数据异常:在业务系统中,可能会出现数据不一致或者数据删除不及时的情况。
- 错误的用户输入:如果系统没有对用户输入进行严格的验证,用户可能会输入错误的查询条件,如输入一个不存在的订单号、手机号码等。这些无效请求会直接穿透缓存访问数据库。
(三)、预防与解决措施
1、方案一
缓存空值或默认值,当查询的数据在数据库中不存在时,在缓存中存储一个空值或者默认值,并设置一个较短的过期时间。这样下次相同的请求就可以直接从缓存中获取空值或默认值,而不会再穿透到数据库。

2、方案二
使用布隆过滤器,①、自研布隆过滤器。②、使用Google Guava 库实现布隆过滤器。

(四)、案例演示
自研简略版布隆过滤器在上一篇已经学习过了,下面将学习Google Guava实现方式。Guava源码地址:GitHub - google/guava: Google core libraries for Java
1、需求说明
模拟使用Guava布隆过滤器拦截掉非法数字,对于合法的数字放行。
2、导入依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.1.2-jre</version>
</dependency>
3、编码实现
public class GuavaBloomFilterDemo {public static void main(String[] args) {//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)//fpp the desired false positive probability 0.0 < fpp < 1.0,误判率越低,消耗的资源越多,哈希函数也用的越多,误判率也就越低// 默认值 0.03BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 1000000, 0.03);//1 先往布隆过滤器里面插入100万的样本数据for (int i = 1; i <= 1000000; i++) {bloomFilter.put(i);}List<Integer> list1 = Arrays.asList(120000000, 111111, 10, 222222222, 42575, 123457);list1.forEach(e -> {boolean result = bloomFilter.mightContain(e);if (result) {// TODO 查redis → 查数据库 → .....System.out.println("存在,放行" + e);} else {// 直接返回结果System.out.println("不存在,拦截" + e);}});//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里List<Integer> list = new ArrayList<>(1000000);for (int i = 1000000 + 1; i <= 1100000; i++) {if (bloomFilter.mightContain(i)) {list.add(i);}}System.out.println("误判的总数量::{}" + list.size());}
}
四、缓存击穿
(一)、名词解释
缓存击穿是指在高并发的场景下,一个非常热点的 key 在缓存中过期失效的瞬间,大量针对该 key 的请求同时涌入。由于此时缓存中没有该 key 对应的数据,这些请求就会全部转向数据库去查询。数据库在短时间内需要处理大量的查询请求,从而承受巨大的压力,可能会导致数据库性能急剧下降,甚至出现崩溃的情况,进而影响整个系统的正常运行。
(二)、发生场景
- 热点数据过期:在电商系统中,一款热门商品的信息会被大量用户频繁访问,为了减轻数据库压力,会将该商品信息缓存起来并设置过期时间。当这个过期时间到达,缓存中的数据失效,而此时恰好有大量用户同时发起对该商品信息的请求,就会出现缓存击穿的情况。
- 流量突发:一些突发的热点事件会导致瞬间产生大量的请求。比如,某明星突然发布一条微博,引发大量粉丝同时访问其个人主页,而该主页信息在缓存中过期,大量请求就会直接冲向数据库。
- 数据预热不正确:比如新闻网站在每天早上进行缓存预热,但遗漏了当天的一条重大热点新闻,当用户大量访问该新闻时,就会出现问题。
(三)、预防与解决措施
1、方案一
使用双检加锁策略。前面已经学习过了,不在阐述。
public String get(String key) {String value = redis.get(key);// 查询缓存if (value != null) {//缓存存在直接返回return value;} else {//缓存不存在则对方法加锁//假设请求量很大,缓存过期synchronized (this) {value = redis.get(key); // 在查一遍redisif (value == null) {// 从数据库获取数据value = dao.get(key);// 设置过期时间并回写到缓存redis.setex(key, time, value);}return value;}}}2、方案二
随机退避策略。当发现缓存中热点 key 失效时,让各个请求不要立即去访问数据库,而是各自随机等待一段不同的时间后再去尝试获取数据。这样可以避免大量请求在同一时刻集中访问数据库,将请求的时间分散开,减轻数据库在短时间内的压力。
public String randomBackoffMethod(String key) {try {Jedis jedis = RedisUtils.getJedis();String data = jedis.get(key);if (data == null) {try {// 生成随机退避时间 毫秒int backoffTime = new Random().nextInt(2000);Thread.sleep(backoffTime);// 再次尝试从缓存获取数据,// 但是在高并发场景下,可能线程随机退避时间会一样,// 为了避免造成缓存双写不一致问题,使用双检锁策略来防止String value = jedis.get(key);// 查询缓存if (value != null) {//缓存存在直接返回return value;} else {//缓存不存在则对方法加锁//假设请求量很大,缓存过期synchronized (this) {value = jedis.get(key); // 在查一遍redisif (value == null) {// 从数据库获取数据value = dao.get(key);// 设置过期时间并回写到缓存jedis.setex(key, time, value);}return value;}}} catch (InterruptedException e) {Thread.currentThread().interrupt();}}jedis.close();return data;} catch (Exception e) {e.printStackTrace();}return null;}3、方案三
差异失效策略。它的核心思想是避免多个热点 Key 在同一时刻同时失效,从而防止大量请求在瞬间全部涌向数据库,给数据库造成过大压力。
在缓存击穿场景中的实现方式为一个热点key拷贝两份,两份缓存过期时间不一样,将缓存失效的时间分散开来,以此保障系统的稳定性与性能。

/*** 差异失效策略查询*/public String differentialFailureSelectMethod(String key) {// 同一个热点key的前缀String prefixA = "keyA:";String prefixB = "keyB:";try {Jedis jedis = RedisUtils.getJedis();String data = jedis.get(prefixA + key);if (data == null) {System.out.println("=========A缓存已经失效");//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存Bdata = jedis.get(prefixB + key);if (data == null) {System.out.println("=========B缓存已经失效");//TODO 查数据库 → 回写redis}return data;}System.out.println("查询结果:{}" + data);} catch (Exception ex) {ex.printStackTrace();}return null;}/*** 差异失效策略更新*/public void differentialFailureUpdateMethod(String key) {try {// 以前的某个热点keyString oldHotKeyA = "oldHotKey:" + key;String oldHotKeyB = "oldHotKey:" + key;// 新热点key前缀String prefixA = "newKeyA:";String prefixB = "newKeyB:";//模拟从数据库查数据Jedis jedis = RedisUtils.getJedis();Object o = dao.get(key);//先更新B缓存jedis.del(oldHotKeyB);jedis.set(prefixB + o.getId());jedis.expire(prefixB + o.getId(), 2000);//再更新A缓存jedis.del(oldHotKeyA);jedis.set(prefixA + o.getId());jedis.expire(prefixA + o.getId(), 1000);} catch (Exception e) {e.printStackTrace();}}五、总结
一图总结,四个问题以及解决办法:
| 问题类型 | 核心问题 | 解决方案 | 典型场景 |
|---|---|---|---|
| 缓存预热 | 数据未提前加载 | 启动加载、定时任务、脚本 | 电商大促前的商品信息加载 |
| 缓存雪崩 | 大量缓存失效 | 随机过期、集群、高可用、限流 | 大量key过期、缓存服务器宕机时 |
| 缓存穿透 | 无效请求攻击 | 布隆过滤器、缓存空值 | 恶意攻击场景 |
| 缓存击穿 | 热点 Key 失效 | 双检锁、差异失效、随机退避 | 秒杀活动中的商品信息访问 |
ps:努力到底,让持续学习成为贯穿一生的坚守。学习笔记持续更新中。。。。
相关文章:
Redis7——进阶篇(五)
前言:此篇文章系本人学习过程中记录下来的笔记,里面难免会有不少欠缺的地方,诚心期待大家多多给予指教。 基础篇: Redis(一)Redis(二)Redis(三)Redis&#x…...

时序和延时
1、延迟模型的类型 verilog有三种类型的延迟模型:分布延迟 、 集总延迟 、 路径延迟(pin to pin) 1.1、 分布延迟 分布延迟是在每个独立元件的基础上进行定义的。 module M(output wire out ,input wire a …...

高效自动化测试:打造Python+Requests+Pytest+Allure+YAML的接口测试框架
一、背景 在快节奏的开发周期中,如何确保接口质量?自动化测试是关键。通过构建标准化、可复用的测试框架,能显著提升测试效率与准确性,为项目质量保驾护航[1][7]。 二、目标 ✅ 核心目标: ● 实现快速、高效的接口测试…...

[微服务设计]1_微服务
摘要:微服务设计应当是面向服务、适配团队、循序渐进的设计。 目录 开篇引言 微服务 什么样的服务是健康的服务 什么是微服务 面向服务的架构 微服务较传统单体架构多的行为 微服务行为带来的问题 微服务解决的问题 开篇引言 在之前的工作中,有…...

Webservice创建
Webservice创建 服务端创建 3层架构 service注解(commom模块) serviceimpl(server) 服务端拦截器的编写 客户端拦截器 客户端调用服务端(CXF代理) 客户端调用服务端(动态模式调用&a…...

Unity安卓Android从StreamingAssets加载AssetBundle
在安卓下无法获取StreamingAssets目录下所有目录和文件名,所以需要提前将文件名整理成一个文件filelist.txt。 1.用批处理命令将StreamingAssets下所有文件名输出到filelist.txt中 chcp 65001是使用UTF-8编码,否则中文是乱码。 echo off chcp 65001 d…...

【MySQL_06】表的相关操作
文章目录 一、表的基本操作1.1 创建表1.2 修改表结构1.2.1 添加列1.2.2 删除列1.2.3 修改列1.2.4 重命名列1.2.5 添加约束 1.3 删除表1.4 查询表结构1.5 重命名表1.6 复制表1.6.1 仅复制结构1.6.2 复制结构及数据 1.7 清空表数据 二、数据完整性约束2.1 主键约束2.2 唯一约束2.…...

如何选择开源向量数据库
文章目录 评估维度查询性能索引与存储扩展性数据管理能力生态支持 常见向量数据库对比 评估维度 选择开源向量数据库时,需要综合考虑查询性能、数据规模、索引构建速度、生态支持等多个因素,以下是关键的评估维度:选择开源向量数据库时&…...

c#面试题整理4
1.stirng str"",string strnull,俩者有何区别 空字符串占有存储控件,null不占用 2.class与struct的异同 异同class 可继承 引用类型 1.都可以定义方法字段 2.都可实例化,与类的使用几乎一样 struct 不可继承 值类型 只能声明带…...

智能焊机监测系统:打造工业安全的数字化盾牌
在现代工业生产中,焊机作为核心设备之一,其稳定性和安全性直接关系到生产效率和产品质量。德州迪格特科技有限公司推出的智能焊机监测系统,通过先进的技术手段,为工业生产构筑了一道坚固的安全防线。 智能监测,保障焊…...

Centos的ElasticSearch安装教程
由于我们是用于校园学习,所以最好是关闭防火墙 systemctl stop firewalld systemctl disable firewalld 个人喜欢安装在opt临时目录,大家可以随意 在opt目录下创建一个es-standonely-docker目录 mkdir es-standonely-docker 进入目录编辑yml文件 se…...

一二三应用开发平台——能力扩展:多数据源支持
背景 随着项目规模的扩大,单一数据源已无法满足复杂业务需求,多数据源应运而生。 技术选型 MyBatis-Plus 的官网提供了两种多数据源扩展插件:开源生态的 <font style"color:rgb(53, 56, 65);">dynamic-datasource</fon…...
)
pandas-基础(数据结构及文件访问)
1 Pandas的数据结构 1.1 Series 特点:一维的数据型对象,包含一个值序列和数据标签(即索引) 创建Series: pandas.Series(dataNone, indexNone, dtypeNone, nameNone, copyFalse, fastpathFalse) 参数说明: data&a…...

数据分析与AI丨AI Fabric:数据和人工智能架构的未来
AI Fabric 架构是模块化、可扩展且面向未来的,是现代商业环境中企业实现卓越的关键。 在当今商业环境中,数据分析和人工智能领域发展可谓日新月异。几乎每天都有新兴技术诞生,新的应用场景不断涌现,前沿探索持续拓展。可遗憾的是&…...

如何根据应用需求选择光谱相机
一、按核心参数匹配需求 光谱范围 农业监测:需覆盖可见光至近红外(400-1000nm),以捕捉作物叶绿素、水分等特征。 地质勘探:需宽光谱(350-2500nm)及高分辨率(3-10nm…...

内存泄漏出现的时机和原因,如何避免?
由于时间比较紧张我就不排版了,但是对于每一种可能的情况都会出对应的代码示例以及解决方案代码示例。 内存泄漏可能的原因之一在于用户在动态分配一个内存空间之中,忘记将这部分内容手动释放。例如:(c之中使用new分配内存没有使…...

Python第十六课:深度学习入门 | 神经网络解密
🎯 本节目标 理解生物神经元与人工神经网络的映射关系掌握激活函数与损失函数的核心作用使用Keras构建手写数字识别模型可视化神经网络的训练过程掌握防止过拟合的基础策略一、神经网络基础(大脑的数字化仿生) 1. 神经元对比 生物神经元人工神经元树突接收信号输入层接收特…...

从0到1,带你开启TypeScript的奇妙之旅
目录 一、TypeScript 是什么? 二、为什么要学习 TypeScript? 三、快速上手:环境搭建与 Hello World (一)安装 TypeScript (二)创建第一个 TypeScript 文件 (三)编译 TypeScript 文件 (四)运行编译后的 JavaScript 文件 四、深入 TypeScript 核心语法 (一)…...

如何修复“RPC 服务器不可用”错误
远程过程调用(Remote Procedure Call, RPC)是允许客户端在不同计算机上执行进程的众多可用网络进程之一。本文将深入探讨RPC如何在不同的软件系统之间实现无缝消息交换,同时重点介绍与RPC相关的常见错误的一些原因。 什么是远程过…...

【redis】五种数据类型和编码方式
文章目录 五种数据类型编码方式stringhashlistsetzset查询内部编码 五种数据类型 字符串:Java 中的 String哈希:Java 中的 HashMap列表:Java 中的 List集合:Java 中的 Set有序集合:除了存 member 之外,还有…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
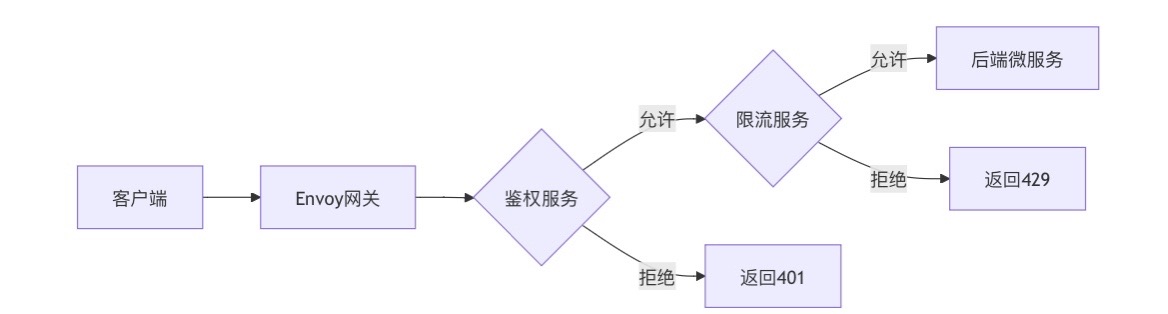
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...