RocketMQ源码(21)—ConsumeMessageConcurrentlyService并发消费消息源码
基于RocketMQ release-4.9.3,深入的介绍了ConsumeMessageConcurrentlyService并发消费消息源码。
此前我们学习了consumer消息的拉取流程源码:
- RocketMQ源码(18)—DefaultMQPushConsumer消费者发起拉取消息请求源码
- RocketMQ源码(19)—Broker处理DefaultMQPushConsumer发起的拉取消息请求源码【一万字】
- RocketMQ源码(20)—DefaultMQPushConsumer处理Broker的拉取消息响应源码
当前DefaultMQPushConsumer拉取到消息之后,会将消息提交到对应的processQueue处理队列内部的msgTreeMap中。然后通过consumeMessageService#submitConsumeRequest方法将拉取到的消息构建为ConsumeRequest,然后通过内部的consumeExecutor线程池消费消息。
consumeMessageService有ConsumeMessageConcurrentlyService并发消费和ConsumeMessageOrderlyService顺序消费两种实现,下面我们来看看这两种实现如何消费消息,本次我们先学习ConsumeMessageConcurrentlyService并发消费的源码。
文章目录
- 1 start启动服务定时清理过期消息
- 1.1 cleanExpireMsg清理过期消息
- 1.2cleanExpiredMsg清理过期消息
- 2 submitConsumeRequest提交消费请求
- 2.2 submitConsumeRequestLater延迟提交
- 2.2 consumeMessageBatchMaxSize和pullBatchSize
- 3 ConsumeRequest执行消费任务
- 3.1 resetRetryAndNamespace重设重试topic
- 4 processConsumeResult处理消费结果
- 4.1 removeMessage移除消息
- 4.2 updateOffset更新offset
- 4.2.1 compareAndIncreaseOnly仅增加offset
1 start启动服务定时清理过期消息
consumeMessageService服务在DefaultMQPushConsumerImpl#start方法中被初始化并启动,即调用start方法。
ConsumeMessageConcurrentlyService#start方法将会通过cleanExpireMsgExecutors定时任务清理过期的消息,启动后15min开始执行,后每15min执行一次,这里的15min是RocketMQ大的默认超时时间,可通过defaultMQPushConsumer#consumeTimeout属性设置。
/*** ConsumeMessageConcurrentlyService的方法* 启动服务*/
public void start() {//通过cleanExpireMsgExecutors定时任务清理过期的消息//启动后15min开始执行,后每15min执行一次,这里的15min时RocketMQ大的默认超时时间,可通过defaultMQPushConsumer#consumeTimeout属性设置this.cleanExpireMsgExecutors.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {try {//清理过期消息cleanExpireMsg();} catch (Throwable e) {log.error("scheduleAtFixedRate cleanExpireMsg exception", e);}}}, this.defaultMQPushConsumer.getConsumeTimeout(), this.defaultMQPushConsumer.getConsumeTimeout(), TimeUnit.MINUTES);
}
1.1 cleanExpireMsg清理过期消息
该方法获取所有的消息队列和处理队列的键值对,循环遍历并且调用ProcessQueue#cleanExpiredMsg方法清理过期消息。
/*** ConsumeMessageConcurrentlyService的方法* <p>* 清理过期消息*/
private void cleanExpireMsg() {//获取所有的消息队列和处理队列的键值对Iterator<Map.Entry<MessageQueue, ProcessQueue>> it =this.defaultMQPushConsumerImpl.getRebalanceImpl().getProcessQueueTable().entrySet().iterator();//循环遍历while (it.hasNext()) {Map.Entry<MessageQueue, ProcessQueue> next = it.next();ProcessQueue pq = next.getValue();//调用ProcessQueue#cleanExpiredMsg方法清理过期消息pq.cleanExpiredMsg(this.defaultMQPushConsumer);}
}
1.2cleanExpiredMsg清理过期消息
循环清理msgTreeMap中的过期消息,每次最多循环清理16条消息。
- 每次循环首先获取msgTreeMap中的第一次元素的起始消费时间,msgTreeMap是一个红黑树,第一个节点就是offset最小的节点。
- 如果消费时间距离现在时间超过默认15min,那么获取这个msg,如果没有被消费,或者消费时间距离现在时间不超过默认15min,则结束循环。
- 将获取到的消息通过sendMessageBack发回broker延迟topic,将在给定延迟时间(默认从level 3,即10s开始)之后发回进行重试消费。
- 加锁判断如果这个消息还没有被消费完,并且还是在第一位,那么调用removeMessage方法从msgTreeMap中移除消息,进行下一轮判断。
/*** ProcessQueue的方法* 清理过期消息** @param pushConsumer 消费者*/
public void cleanExpiredMsg(DefaultMQPushConsumer pushConsumer) {//如果是顺序消费,直接返回,只有并发消费才会清理if (pushConsumer.getDefaultMQPushConsumerImpl().isConsumeOrderly()) {return;}//一次循环最多处理16个消息int loop = msgTreeMap.size() < 16 ? msgTreeMap.size() : 16;//遍历消息,最多处理前16个消息for (int i = 0; i < loop; i++) {MessageExt msg = null;try {//加锁this.treeMapLock.readLock().lockInterruptibly();try {if (!msgTreeMap.isEmpty()) {//获取msgTreeMap中的第一次元素的起始消费时间,msgTreeMap是一个红黑树,第一个节点就是offset最小的节点String consumeStartTimeStamp = MessageAccessor.getConsumeStartTimeStamp(msgTreeMap.firstEntry().getValue());//如果消费时间距离现在时间超过默认15min,那么获取这个msgif (StringUtils.isNotEmpty(consumeStartTimeStamp) && System.currentTimeMillis() - Long.parseLong(consumeStartTimeStamp) > pushConsumer.getConsumeTimeout() * 60 * 1000) {msg = msgTreeMap.firstEntry().getValue();} else {//如果没有被消费,或者消费时间距离现在时间不超过默认15min,则结束循环break;}} else {//msgTreeMap为空,结束循环break;}} finally {this.treeMapLock.readLock().unlock();}} catch (InterruptedException e) {log.error("getExpiredMsg exception", e);}try {//将消息发回broker延迟topic,将在给定延迟时间(默认从level3,即10s开始)之后进行重试消费pushConsumer.sendMessageBack(msg, 3);log.info("send expire msg back. topic={}, msgId={}, storeHost={}, queueId={}, queueOffset={}", msg.getTopic(), msg.getMsgId(), msg.getStoreHost(), msg.getQueueId(), msg.getQueueOffset());try {this.treeMapLock.writeLock().lockInterruptibly();try {//如果这个消息还没有被消费完if (!msgTreeMap.isEmpty() && msg.getQueueOffset() == msgTreeMap.firstKey()) {try {//移除消息removeMessage(Collections.singletonList(msg));} catch (Exception e) {log.error("send expired msg exception", e);}}} finally {this.treeMapLock.writeLock().unlock();}} catch (InterruptedException e) {log.error("getExpiredMsg exception", e);}} catch (Exception e) {log.error("send expired msg exception", e);}}
}
2 submitConsumeRequest提交消费请求
该方法将消息批量的封装为ConsumeRequest提交到ConsumeMessageConcurrentlyService内部的consumeExecutor线程池中进行异步消费,如果提交失败,则调用submitConsumeRequestLater方法延迟5s进行提交,而不是丢弃。
- 首先获取单次批量消费的数量,默认1,通过DefaultMQPushConsumer的consumeMessageBatchMaxSize属性配置。
- 如果消息数量 <= 单次批量消费的数量,那么直接全量消费,构建一个ConsumeRequest并提交到consumeExecutor线程池。
- 如果消息数量 > 单次批量消费的数量,那么需要分割消息进行分批提交。
从该方法可以得知,对于并发消费模式,拉取到的一批消息被分批次提交到线程池之后,就由线程池里面的线程异步的消费,我们知道线程池里面的线程执行先后顺序时不可控制的,因此这些不同批次的消息会被并发、的无序的消费。
/*** ConsumeMessageOrderlyService的方法* 提交并发消费请求** @param msgs 拉取到的消息* @param processQueue 处理队列* @param messageQueue 消息队列* @param dispatchToConsume 是否分发消费,对于并发消费无影响*/
@Override
public void submitConsumeRequest(final List<MessageExt> msgs,final ProcessQueue processQueue,final MessageQueue messageQueue,final boolean dispatchToConsume) {//单次批量消费的数量,默认1final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();/** 如果消息数量 <= 单次批量消费的数量,那么直接全量消费*/if (msgs.size() <= consumeBatchSize) {//构建消费请求,将消息全部放进去ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);try {//将请求提交到consumeExecutor线程池中进行消费this.consumeExecutor.submit(consumeRequest);} catch (RejectedExecutionException e) {//提交的任务被线程池拒绝,那么延迟5s进行提交,而不是丢弃this.submitConsumeRequestLater(consumeRequest);}}/** 如果消息数量 > 单次批量消费的数量,那么需要分割消息进行分批提交*/else {//遍历for (int total = 0; total < msgs.size(); ) {//一批消息集合,每批消息最多consumeBatchSize条,默认1List<MessageExt> msgThis = new ArrayList<MessageExt>(consumeBatchSize);//将消息按顺序加入集合for (int i = 0; i < consumeBatchSize; i++, total++) {if (total < msgs.size()) {msgThis.add(msgs.get(total));} else {break;}}//将本批次消息构建为ConsumeRequestConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);try {//将请求提交到consumeExecutor线程池中进行消费this.consumeExecutor.submit(consumeRequest);} catch (RejectedExecutionException e) {for (; total < msgs.size(); total++) {msgThis.add(msgs.get(total));}//提交的任务被线程池拒绝,那么延迟5s进行提交,而不是丢弃this.submitConsumeRequestLater(consumeRequest);}}}
}
consumeExecutor线程池用于消费消息,其定义如下:最小、最大线程数默认20,阻塞队列为无界阻塞队列LinkedBlockingQueue。
/** 并发消费线程池* 最小、最大线程数默认20,阻塞队列为无界阻塞队列LinkedBlockingQueue*/
this.consumeExecutor = new ThreadPoolExecutor(this.defaultMQPushConsumer.getConsumeThreadMin(),this.defaultMQPushConsumer.getConsumeThreadMax(),1000 * 60,TimeUnit.MILLISECONDS,this.consumeRequestQueue,new ThreadFactoryImpl(consumeThreadPrefix));
//单线程的延迟任务线程池,用于延迟提交消费请求
this.scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("ConsumeMessageScheduledThread_"));
//单线程的延迟任务线程池,用于处理过期的消息
this.cleanExpireMsgExecutors = Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("CleanExpireMsgScheduledThread_"));
2.2 submitConsumeRequestLater延迟提交
提交的任务被线程池拒绝,那么延迟5s进行提交,而不是丢弃。
/*** ConsumeMessageConcurrentlyService的方法* * 提交的任务被线程池拒绝,那么延迟5s进行提交,而不是丢弃* @param consumeRequest 提交请求*/
private void submitConsumeRequestLater(final ConsumeRequest consumeRequest
) {this.scheduledExecutorService.schedule(new Runnable() {@Overridepublic void run() {//将提交的行为封装为一个线程任务,提交到scheduledExecutorService延迟线程池,5s之后执行ConsumeMessageConcurrentlyService.this.consumeExecutor.submit(consumeRequest);}}, 5000, TimeUnit.MILLISECONDS);
}
2.2 consumeMessageBatchMaxSize和pullBatchSize
consumeMessageBatchMaxSize是什么意思呢?他的字面意思就是单次批量消费的数量,实际上它代表着每次发送给消息监听器MessageListenerOrderly或者MessageListenerConcurrently的consumeMessage方法中的参数List msgs中的最多的消息数量。
consumeMessageBatchMaxSize默认值为1,所以说,无论是并发消费还是顺序消费,每次的consumeMessage方法的执行,msgs集合默认都只有一条消息。同理,如果把它设置为其他值n,无论是并发消费还是顺序消费,每次的consumeMessage的执行,msgs集合默认都最多只有n条消息。
另外,在此前拉取消息的源码中,我们还学习了另一个参数pullBatchSize,默认值为32,其代表的是每一次拉取请求最多批量拉取的消费数量。也就是说无论是并发消费还是顺序消费,每次最多拉取32条消息。
3 ConsumeRequest执行消费任务
ConsumeRequest本身是一个线程任务,当拉取到消息之后,会将一批消息构建为一个ConsumeRequest对象,提交给consumeExecutor,由线程池异步的执行,它的run方法就是并发消费的核心方法。大概逻辑为:
- 如果处理队列被丢弃,即dropped=true,那么直接返回,不再消费,例如负载均衡时该队列被分配给了其他新上线的消费者,尽量避免重复消费。
- 调用resetRetryAndNamespace方法,当消息是重试消息的时候,将msg的topic属性从重试topic还原为真实的topic。
- 如果有消费钩子,那么执行钩子函数的前置方法consumeMessageBefore。我们可以通过DefaultMQPushConsumerImpl#registerConsumeMessageHook方法注册消费钩子ConsumeMessageHook,在消费消息的前后调用。
- 调用listener#consumeMessage方法,进行消息消费,调用实际的业务逻辑,返回执行状态结果如status为null。
- 正常情况下可返回两种状态:ConsumeConcurrentlyStatus.CONSUME_SUCCESS表示消费成功 , ConsumeConcurrentlyStatus.RECONSUME_LATER表示消费失败,如果中途抛出异常,则status为null。
- 对返回的执行状态结果进行判断处理。从这里可得知消费超时时间为15min,另外如果返回的status为null,那么status将会被设置为RECONSUME_LATER,即消费失败。
- 计算消费时间consumeRT。如果status为null,如果业务的执行抛出了异常,设置returnType为EXCEPTION,否则设置returnType为RETURNNULL。
- 如消费时间consumeRT大于等于consumeTimeout,默认15min。设置returnType为TIME_OUT。消费超时时间可通过DefaultMQPushConsumer. consumeTimeout属性配置,默认15,单位分钟。
- 如status为RECONSUME_LATER,即消费失败,设置returnType为FAILED。
- 如status为CONSUME_SUCCESS,即消费成功,设置returnType为SUCCESS。
- 如果有消费钩子,那么执行钩子函数的后置方法consumeMessageAfter。
- 如果处理队列没有被丢弃,即dropped=false,那么调用ConsumeMessageConcurrentlyService#processConsumeResult方法处理消费结果,包含消费重试、提交offset等操作。
需要注意的是,如果在执行了listener#consumeMessage方法,即执行了业务逻辑之后,处理消费结果之前,该消息队列被丢弃了,例如负载均衡时该队列被分配给了其他新上线的消费者,那么由于dropped=false,导致不会进行最后的消费结果处理,将会导致消息的重复消费,因此必须做好业务层面的幂等性!
class ConsumeRequest implements Runnable {//一次消费的消息集合,默认1条消息private final List<MessageExt> msgs;//处理队列private final ProcessQueue processQueue;//消息队列private final MessageQueue messageQueue;public ConsumeRequest(List<MessageExt> msgs, ProcessQueue processQueue, MessageQueue messageQueue) {this.msgs = msgs;this.processQueue = processQueue;this.messageQueue = messageQueue;}public List<MessageExt> getMsgs() {return msgs;}public ProcessQueue getProcessQueue() {return processQueue;}/*** ConsumeMessageConcurrentlyService的内部类ConsumeRequest的方法* <p>* 执行并发消费*/@Overridepublic void run() {//如果处理队列被丢弃,那么直接返回,不再消费,例如负载均衡时该队列被分配给了其他新上线的消费者,尽量避免重复消费if (this.processQueue.isDropped()) {log.info("the message queue not be able to consume, because it's dropped. group={} {}", ConsumeMessageConcurrentlyService.this.consumerGroup, this.messageQueue);return;}/** 1 获取并发消费的消息监听器,push模式模式下是我们需要开发的,通过registerMessageListener方法注册,内部包含了要执行的业务逻辑*/MessageListenerConcurrently listener = ConsumeMessageConcurrentlyService.this.messageListener;ConsumeConcurrentlyContext context = new ConsumeConcurrentlyContext(messageQueue);ConsumeConcurrentlyStatus status = null;//重置重试topicdefaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());/** 2 如果有消费钩子,那么执行钩子函数的前置方法consumeMessageBefore* 我们可以注册钩子ConsumeMessageHook,再消费消息的前后调用*/ConsumeMessageContext consumeMessageContext = null;if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {consumeMessageContext = new ConsumeMessageContext();consumeMessageContext.setNamespace(defaultMQPushConsumer.getNamespace());consumeMessageContext.setConsumerGroup(defaultMQPushConsumer.getConsumerGroup());consumeMessageContext.setProps(new HashMap<String, String>());consumeMessageContext.setMq(messageQueue);consumeMessageContext.setMsgList(msgs);consumeMessageContext.setSuccess(false);ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookBefore(consumeMessageContext);}//起始时间戳long beginTimestamp = System.currentTimeMillis();boolean hasException = false;//消费返回类型,初始化为SUCCESSConsumeReturnType returnType = ConsumeReturnType.SUCCESS;try {if (msgs != null && !msgs.isEmpty()) {//循环设置每个消息的起始消费时间for (MessageExt msg : msgs) {MessageAccessor.setConsumeStartTimeStamp(msg, String.valueOf(System.currentTimeMillis()));}}/** 3 调用listener#consumeMessage方法,进行消息消费,调用实际的业务逻辑,返回执行状态结果* 有两种状态ConsumeConcurrentlyStatus.CONSUME_SUCCESS 和 ConsumeConcurrentlyStatus.RECONSUME_LATER*/status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);} catch (Throwable e) {log.warn(String.format("consumeMessage exception: %s Group: %s Msgs: %s MQ: %s",RemotingHelper.exceptionSimpleDesc(e),ConsumeMessageConcurrentlyService.this.consumerGroup,msgs,messageQueue), e);//抛出异常之后,设置异常标志位hasException = true;}/** 4 对返回的执行状态结果进行判断处理*///计算消费时间long consumeRT = System.currentTimeMillis() - beginTimestamp;//如status为nullif (null == status) {//如果业务的执行抛出了异常if (hasException) {//设置returnType为EXCEPTIONreturnType = ConsumeReturnType.EXCEPTION;} else {//设置returnType为RETURNNULLreturnType = ConsumeReturnType.RETURNNULL;}}//如消费时间consumeRT大于等于consumeTimeout,默认15minelse if (consumeRT >= defaultMQPushConsumer.getConsumeTimeout() * 60 * 1000) {//设置returnType为TIME_OUTreturnType = ConsumeReturnType.TIME_OUT;}//如status为RECONSUME_LATER,即消费失败else if (ConsumeConcurrentlyStatus.RECONSUME_LATER == status) {//设置returnType为FAILEDreturnType = ConsumeReturnType.FAILED;}//如status为CONSUME_SUCCESS,即消费成功else if (ConsumeConcurrentlyStatus.CONSUME_SUCCESS == status) {//设置returnType为SUCCESS,即消费成功returnType = ConsumeReturnType.SUCCESS;}//如果有钩子,则将returnType设置进去if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {consumeMessageContext.getProps().put(MixAll.CONSUME_CONTEXT_TYPE, returnType.name());}//如果status为nullif (null == status) {log.warn("consumeMessage return null, Group: {} Msgs: {} MQ: {}",ConsumeMessageConcurrentlyService.this.consumerGroup,msgs,messageQueue);//将status设置为RECONSUME_LATER,即消费失败status = ConsumeConcurrentlyStatus.RECONSUME_LATER;}/** 5 如果有消费钩子,那么执行钩子函数的后置方法consumeMessageAfter* 我们可以注册钩子ConsumeMessageHook,在消费消息的前后调用*/if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {consumeMessageContext.setStatus(status.toString());consumeMessageContext.setSuccess(ConsumeConcurrentlyStatus.CONSUME_SUCCESS == status);ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookAfter(consumeMessageContext);}//增加消费时间ConsumeMessageConcurrentlyService.this.getConsumerStatsManager().incConsumeRT(ConsumeMessageConcurrentlyService.this.consumerGroup, messageQueue.getTopic(), consumeRT);/** 6 如果处理队列没有被丢弃,那么调用ConsumeMessageConcurrentlyService#processConsumeResult方法处理消费结果,包含重试等逻辑*/if (!processQueue.isDropped()) {ConsumeMessageConcurrentlyService.this.processConsumeResult(status, context, this);} else {log.warn("processQueue is dropped without process consume result. messageQueue={}, msgs={}", messageQueue, msgs);}}public MessageQueue getMessageQueue() {return messageQueue;}}
3.1 resetRetryAndNamespace重设重试topic
当消息是重试消息的时候,将msg的topic属性从重试topic还原为真实的topic。
public void resetRetryAndNamespace(final List<MessageExt> msgs, String consumerGroup) {//获取重试topicfinal String groupTopic = MixAll.getRetryTopic(consumerGroup);for (MessageExt msg : msgs) {//尝试通过PROPERTY_RETRY_TOPIC属性获取每个消息的真实topicString retryTopic = msg.getProperty(MessageConst.PROPERTY_RETRY_TOPIC);//如果该属性不为null,并且重试topic和消息的topic相等,则表示当前消息是重试消息if (retryTopic != null && groupTopic.equals(msg.getTopic())) {//那么设置消息的topic为真实topic,即还原回来msg.setTopic(retryTopic);}if (StringUtils.isNotEmpty(this.defaultMQPushConsumer.getNamespace())) {msg.setTopic(NamespaceUtil.withoutNamespace(msg.getTopic(), this.defaultMQPushConsumer.getNamespace()));}}
}
4 processConsumeResult处理消费结果
对于并发消费的消费结果通过ConsumeMessageConcurrentlyService#processConsumeResult方法处理。
需要注意的是,如果在执行了listener#consumeMessage方法,即执行了业务逻辑之后,处理消费结果之前,该消息队列被丢弃了,例如负载均衡时该队列被分配给了其他新上线的消费者,那么由于dropped=false,导致不会进行最后的消费结果处理,将会导致消息的重复消费,因此必须做好业务层面的幂等性!
processConsumeResult方法的大概步骤为:
- 获取ackIndex,默认初始值为Integer.MAX_VALUE,该值表示消费成功的消息在消息集合中的索引,用于辅助进行消息重试。
- 判断消费状态,设置ackIndex的值:
- CONSUME_SUCCESS消费成功: ackIndex = 消息数量 – 1。
- RECONSUME_LATER消费失败: ackIndex = -1。
- 判断消息模式,处理消费失败的情况:
- BROADCASTING广播模式:对于没有消费成功的消息仅仅打印日志。
- CLUSTERING集群模式:
- 对于消费失败的消息,调用sendMessageBack方法向broker发送发回当前消息作为延迟消息到重试队列,等待重试消费。对于sendMessageBack发送失败的消息加入msgBackFailed失败集合,设置消息的重试次数属性reconsumeTimes+1
- 对于sendMessageBack发送失败的消息,调用submitConsumeRequestLater方法,延迟5s将sendMessageBack执行失败的消息再次提交到consumeExecutor进行消费。
- 调用ProcessQueue#removeMessage方法从处理队列的msgTreeMap中将消费成功的消息,以及消费失败但是发回broker成功的这批消息移除,然后返回msgTreeMap中的最小的偏移量。
- 如果偏移量大于等于0并且处理队列没有被丢弃,调用OffsetStore# updateOffset方法,尝试更新内存中的offsetTable中的最新偏移量信息,第三个参数是否仅单调增加offset为true,表示只会尝试更新offset为更大的值。这里仅仅是更新内存中的数据,而offset除了在拉取消息时上报broker进行持久化之外,还会定时每5s调用persistAllConsumerOffset定时持久化。我们在后面Consumer消费进度管理部分会学习相关源码。
/*** ConsumeMessageConcurrentlyService的方法* <p>* 处理消费结果** @param status 消费状态* @param context 上下文* @param consumeRequest 消费请求*/
public void processConsumeResult(final ConsumeConcurrentlyStatus status,final ConsumeConcurrentlyContext context,final ConsumeRequest consumeRequest
) {//ackIndex,默认初始值为Integer.MAX_VALUE,表示消费成功的消息在消息集合中的索引int ackIndex = context.getAckIndex();//如果消息为空则直接返回if (consumeRequest.getMsgs().isEmpty())return;/** 1 判断消费状态,设置ackIndex的值* 消费成功: ackIndex = 消息数量 - 1* 消费失败: ackIndex = -1*/switch (status) {//如果消费成功case CONSUME_SUCCESS://如果大于等于消息数量,则设置为消息数量减1//初始值为Integer.MAX_VALUE,因此一般都会设置为消息数量减1if (ackIndex >= consumeRequest.getMsgs().size()) {ackIndex = consumeRequest.getMsgs().size() - 1;}//消费成功的个数,即消息数量int ok = ackIndex + 1;//消费失败的个数,即0int failed = consumeRequest.getMsgs().size() - ok;//统计this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok);this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed);break;//如果消费失败case RECONSUME_LATER://ackIndex初始化为-1ackIndex = -1;//统计this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(),consumeRequest.getMsgs().size());break;default:break;}/** 2 判断消息模式,处理消费失败的情况* 广播模式:打印日志* 集群模式:向broker发送当前消息作为延迟消息,等待重试消费*/switch (this.defaultMQPushConsumer.getMessageModel()) {//广播模式下case BROADCASTING://从消费成功的消息在消息集合中的索引+1开始,仅仅是对于消费失败的消息打印日志,并不会重试for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {MessageExt msg = consumeRequest.getMsgs().get(i);log.warn("BROADCASTING, the message consume failed, drop it, {}", msg.toString());}break;//集群模式下case CLUSTERING:List<MessageExt> msgBackFailed = new ArrayList<MessageExt>(consumeRequest.getMsgs().size());//消费成功的消息在消息集合中的索引+1开始,遍历消息for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {//获取该索引对应的消息MessageExt msg = consumeRequest.getMsgs().get(i);/** 2.1 消费失败后,将该消息重新发送至重试队列,延迟消费*/boolean result = this.sendMessageBack(msg, context);//如果执行发送失败if (!result) {//设置重试次数+!msg.setReconsumeTimes(msg.getReconsumeTimes() + 1);//加入失败的集合msgBackFailed.add(msg);}}if (!msgBackFailed.isEmpty()) {//从consumeRequest中移除消费失败并且发回broker失败的消息consumeRequest.getMsgs().removeAll(msgBackFailed);/** 2.2 调用submitConsumeRequestLater方法,延迟5s将sendMessageBack执行失败的消息再次提交到consumeExecutor进行消费*/this.submitConsumeRequestLater(msgBackFailed, consumeRequest.getProcessQueue(), consumeRequest.getMessageQueue());}break;default:break;}/** 3 从处理队列的msgTreeMap中将消费成功以及消费失败但是发回broker成功的这批消息移除,然后返回msgTreeMap中的最小的偏移量*/long offset = consumeRequest.getProcessQueue().removeMessage(consumeRequest.getMsgs());//如果偏移量大于等于0并且处理队列没有被丢弃if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {//尝试更新内存中的offsetTable中的最新偏移量信息,第三个参数是否仅单调增加offset为truethis.defaultMQPushConsumerImpl.getOffsetStore().updateOffset(consumeRequest.getMessageQueue(), offset, true);}
}
4.1 removeMessage移除消息
从处理队列的msgTreeMap中将消费成功,以及消费失败但是发回broker成功的这批消息移除,然后返回msgTreeMap中的最小的消息偏移量。如果移除后msgTreeMap为空了,那么直接返回该处理队列记录的最大的消息偏移量+1。
这个返回的offset将会尝试用于更新在内存中的offsetTable中的最新偏移量信息,而offset除了在拉取消息时持久化之外,还会定时每5s调用persistAllConsumerOffset定时持久化。我们在后面Consumer消费进度管理部分会学习源码。
/*** ProcessQueue的方法* <p>* 移除执行集合中的所有消息,然后返回msgTreeMap中的最小的消息偏移量** @param msgs 需要被移除的消息集合* @return msgTreeMap中的最小的消息偏移量*/
public long removeMessage(final List<MessageExt> msgs) {long result = -1;final long now = System.currentTimeMillis();try {//获取锁this.treeMapLock.writeLock().lockInterruptibly();//更新时间戳this.lastConsumeTimestamp = now;try {//如果msgTreeMap存在数据if (!msgTreeMap.isEmpty()) {//首先将result设置为该队列最大的消息偏移量+1result = this.queueOffsetMax + 1;int removedCnt = 0;//遍历每一条消息尝试异常for (MessageExt msg : msgs) {MessageExt prev = msgTreeMap.remove(msg.getQueueOffset());if (prev != null) {removedCnt--;msgSize.addAndGet(0 - msg.getBody().length);}}msgCount.addAndGet(removedCnt);//如果移除消息之后msgTreeMap不为空集合,那么result设置为msgTreeMap当前最小的消息偏移量if (!msgTreeMap.isEmpty()) {result = msgTreeMap.firstKey();}}} finally {this.treeMapLock.writeLock().unlock();}} catch (Throwable t) {log.error("removeMessage exception", t);}return result;
}
4.2 updateOffset更新offset
尝试更新内存中的offsetTable中的最新偏移量信息,第三个参数是否仅单调增加offset,顺序消费为false,并发消费为true。
/*** RemoteBrokerOffsetStore的方法* 更新内存中的offset** @param mq 消息队列* @param offset 偏移量* @param increaseOnly 是否仅单调增加offset,顺序消费为false,并发消费为true*/
@Override
public void updateOffset(MessageQueue mq, long offset, boolean increaseOnly) {if (mq != null) {//获取已存在的offsetAtomicLong offsetOld = this.offsetTable.get(mq);//如果没有老的offset,那么将新的offset存进去if (null == offsetOld) {offsetOld = this.offsetTable.putIfAbsent(mq, new AtomicLong(offset));}//如果有老的offset,那么尝试更新offsetif (null != offsetOld) {//如果仅单调增加offset,顺序消费为false,并发消费为trueif (increaseOnly) {//如果新的offset大于已存在offset,则尝试在循环中CAS的更新为新offsetMixAll.compareAndIncreaseOnly(offsetOld, offset);} else {//直接设置为新offset,可能导致offset变小offsetOld.set(offset);}}}
}
4.2.1 compareAndIncreaseOnly仅增加offset
如果目标对象目前的值已经大于目标值,则返回false,否则在一个循环中尝试CAS的更新目标对象的值为目标值。
/*** MixAll的方法* 仅增加offset** @param target 目标值* @param value 目标对象* @return 是否增加成功*/
public static boolean compareAndIncreaseOnly(final AtomicLong target, final long value) {//获取目标对象目前的值long prev = target.get();//如果目标值大于当前值,则在循环中CAS的设置值while (value > prev) {//那么尝试CAS的设置当前值为目标值boolean updated = target.compareAndSet(prev, value);//如果CAS成功则返回trueif (updated)return true;//如果AS失败,则重新获取目标对象目前的值prev = target.get();}//获取目标对象目前的值已经大于目标值,则返回falsereturn false;
}
相关文章:
—ConsumeMessageConcurrentlyService并发消费消息源码)
RocketMQ源码(21)—ConsumeMessageConcurrentlyService并发消费消息源码
基于RocketMQ release-4.9.3,深入的介绍了ConsumeMessageConcurrentlyService并发消费消息源码。 此前我们学习了consumer消息的拉取流程源码: RocketMQ源码(18)—DefaultMQPushConsumer消费者发起拉取消息请求源码RocketMQ源码(19)—Broker处理Default…...

基于 STM32+FPGA 的多轴运动控制器的设计
运动控制器是数控机床、高端机器人等自动化设备控制系统的核心。为保证控制器的实用性、实时性和稳定 性,提出一种以 STM32 为主控制器、FPGA 为辅助控制器的多轴运动控制器设计方案。给出了运动控制器的硬件电路设计, 将 S 形加减速算法融入运动控制器&…...

《爆肝整理》保姆级系列教程python接口自动化(十三)--cookie绕过验证码登录(详解
python接口自动化(十三)--cookie绕过验证码登录(详解 简介 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。获取…...
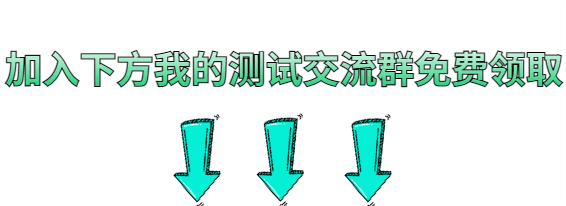
soapui + groovy 接口自动化测试
1.操作excel的groovy脚本 package pubimport jxl.* import jxl.write.Label import jxl.write.WritableWorkbookclass ExcelOperation {def xlsFiledef workbookdef writableWorkbookdef ExcelOperation(){}//设置xlsFile文件路径def ExcelOperation(xlsFile){this.xlsFile x…...
:内存规整简介)
Linux内存管理(三十五):内存规整简介
源码基于:Linux5.4 0. 前言 伙伴系统以页面为单位来管理内存,内存碎片也是基于页面的,即由大量离散且不连续的页面组成的。从内核角度来看,出现内存碎片不是好事情,有些情况下物理设备需要大段的连续的物理内存,如果内核无法满足,则会发生内核错误。内存规整就是为了解…...
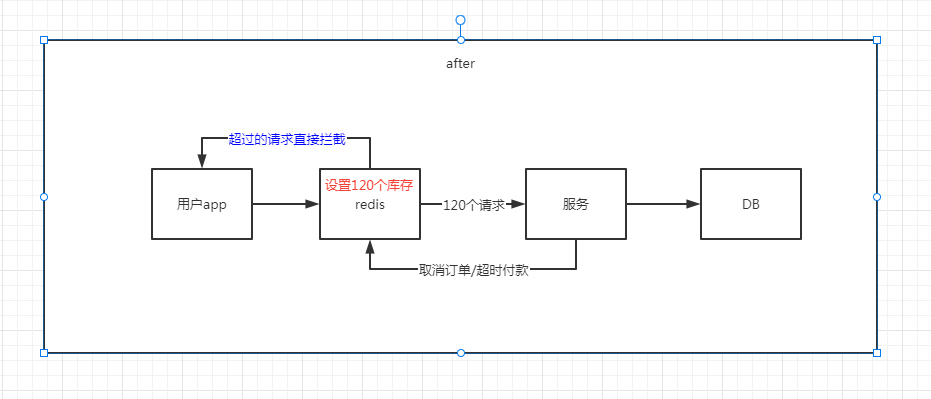
Java连接Redis
Jedis是Redis官方推荐的Java连接开发工具。api:https://tool.oschina.net/apidocs/apidoc?apijedis-2.1.0一、 导入包<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency><groupId>redis.clients</groupId><…...
)
Python语言零基础入门教程(十六)
Python 模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。 模块让你能够有逻辑地组织你的 Python 代码段。 把相关的代码分配到一个模块里能让你的代码更好用,更易懂。 模块能定…...
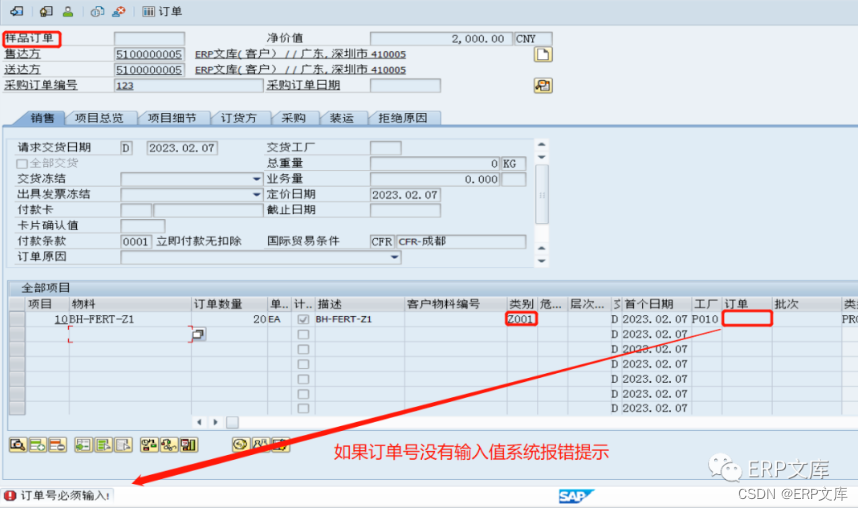
SAP ERP系统SD模块常用增强之一:VA01/VA02创建或修改SO的输入检查
在SAP/ERP项目的实施中销售管理模块(SD)的创建和修改销售订单必定会有输入字段校验检查的需求,来防止业务人员录入错误或少录入数据,SAP公司也考虑到这一点,所以这方面的配置功能也非常强大,通常情况下不需…...

深度学习知识补充
候选位置(proposal) RCNN 什么时ROI? 在图像处理领域,感兴趣区域(region of interest , ROI) 是从图像中选择的一个图像区域,这个区域是你的图像分析所关注的重点。圈定该区域以便进行进一步处理。使用ROI圈定你想读的目标&…...
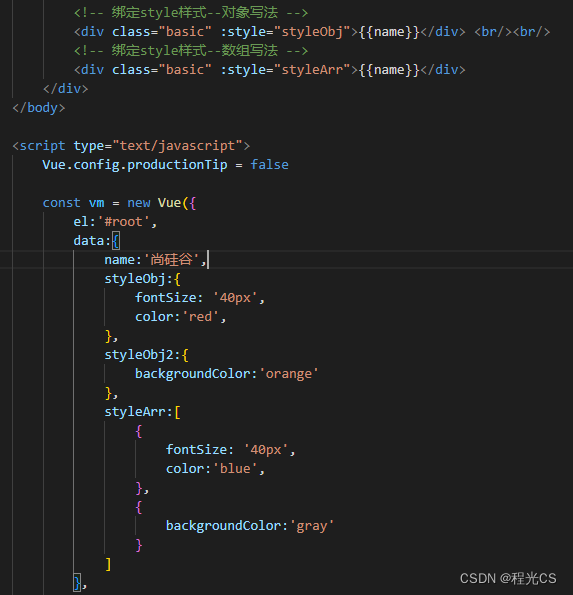
Vue笔记(1)——数据代理与绑定
一、初始Vue 1.想让Vue工作,就必须创建一个Vue实例,且要传入一个配置对象; 2.root容器里的代码依然符合html规范,只不过混入了一些特殊的Vue语法; 3.root容器里的代码被称为【Vue模板】; 4.Vue实例和容器是…...

LeetCode题目笔记——2563. 统计公平数对的数目
文章目录题目描述题目链接题目难度——中等方法一:排序双指针代码/Python代码/C方法二代码/Python总结题目描述 这是前天周赛的第二题。 统计公平数对的数目 - 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,和两个整数 lower 和 upper ,…...

【MySQL Shell】8.9.5 将集群重新加入到 InnoDB ClusterSet
如果 InnoDB 集群是 InnoDB ClusterSet 部署的一部分,MySQL Shell 会在重新启动后立即自动将其恢复到拓扑中的角色,前提是其运行正常且未被标记为无效。但是,如果集群被标记为无效或其 ClusterSet 复制通道已停止,则必须使用 clus…...

元素水平垂直居中的方法有哪些?如果元素不定宽高呢?
实现元素水平垂直居中的方式: 利用定位margin:auto利用定位margin:负值利用定位transformtable布局flex布局grid布局 1-利用定位margin:auto <style>.father{width:500px;height:300px;border:1px solid #0a3b98;position: relative;}.son{width:100px;heig…...

访问学者在新加坡访学生活日常花销大吗?
新加坡地理位置优越,社会发达,教学质量好,吸引不少国内学生前往新加坡留学、访学。那么,去新加坡访学,访问学者花销需要多少钱呢?下面和51访学网小编一起来了解一下吧。 一、饮食 新加坡的饮食从很亲民的…...
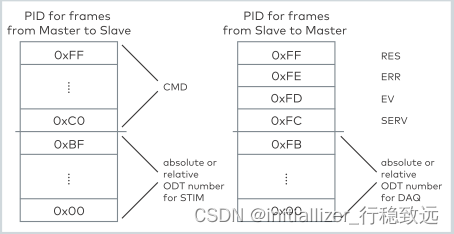
XCP实战系列介绍11-几个常用的XCP命令解析
本文框架 1.概述2. 常用命令解析2.1 CONNECT连接(0xFF)2.2 SHORT_UPLOAD 命令(0xF4)2.2 SET_MTA (0xF6)2.3 MOVE命令(0x19)2.4 GET_CAL_PAGE(0xEA)2.5 SET_CAL_PAGE(0xEB)2.6 DOWNLOAD(0xF0)1.概述 在文章《看了就会的XCP协议介绍》中详细介绍了XCP的协议,在《XCP实战系列介绍…...

全志V853芯片 如何在Tina V85x平台切换sensor?
目的 V85x某方案目前默认Sensor是GC2053。实际使用时若需要用到GC4663(比如wdr功能)和SC530AI(支持500W),可按如下步骤完成切换。 步骤 下面以GC4663为例,SC530AI按相应方式适配。 Step1 检查Sensor驱动…...
2023全网最火的接口自动化测试,一看就会
目录 接口自动化测试用例设计Excel接口测试用例访问MySQL接口测试用例访问PyTest测试框架接口自动化测试必备技能-HTTP协议request库实现接口请求 引言 与UI相比,接口一旦研发完成,通常变更或重构的频率和幅度相对较小。因此做接口自动化的性价比更高&…...
)
华为OD机试真题JAVA实现【最小传递延迟】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出示例一输入输出说明解题思路核心知识点Code运行结果版权说...

Transformer
Transformer由4部分组成,分别是:输入模块、编码模块、解码模块、输出模块整体架构图:一、输入模块结构 (1)源文本嵌入层及其位置编码器(2)目标文本嵌入层及其位置编码器二、编码器模块结构由N个…...

并发包工具之 批量处理任务 CompletionService(异步)、CompletableFuture(回调)
文章目录一、处理异步任务并获取返回值——CompletionService二、线程池三、Callable 与 Future四、通过回调方式处理可组合编排任务——CompletableFuture一、处理异步任务并获取返回值——CompletionService 特点描述: 对于比较复杂的计算,把…...

Qwen3-4B Instruct-2507效果展示:PPT大纲生成+逐页内容填充实例
Qwen3-4B Instruct-2507效果展示:PPT大纲生成逐页内容填充实例 1. 项目简介与核心能力 Qwen3-4B Instruct-2507是阿里通义千问团队推出的纯文本大语言模型,专注于文本生成和处理任务。这个版本移除了视觉相关模块,专注于提升文本处理的效率…...

实战StyleGAN2:从环境配置到高质量人脸生成的完整指南
1. 环境准备:选对系统,事半功倍 如果你正准备一头扎进StyleGAN2的世界,想自己动手生成那些以假乱真的人脸,那我得先给你泼点冷水,也给你指条明路:环境配置是第一个,也是最大的拦路虎。我见过太多…...

从STM32到AI:嵌入式设备远程调用雪女-斗罗大陆-造相Z-Turbo生成开机画面
从STM32到AI:嵌入式设备远程调用雪女-斗罗大陆-造相Z-Turbo生成开机画面 你有没有想过,手里那块小小的、资源有限的STM32开发板,也能玩转前沿的AI图像生成?今天,我们就来做一个有趣的软硬件结合项目:让一块…...
)
告别“封号”与“宕机”:2026企业级Python分布式爬虫架构实战(微服务+K8s全链路解析)
前言 在2026年的今天,数据采集早已不是写个requests循环就能搞定的小事。 面对反爬机制的智能化(指纹识别、行为分析、AI验证码)、目标网站的高并发压力以及企业内部对数据时效性、合规性的严苛要求,传统的单体爬虫架构显得捉襟见…...

gte-base-zh在智能客服中的应用:如何用语义理解提升问答匹配度
gte-base-zh在智能客服中的应用:如何用语义理解提升问答匹配度 1. 引言:智能客服的痛点与破局点 想象一下,你是一家电商平台的客服主管。每天,你的团队要处理成千上万的用户咨询。其中,大量问题其实大同小异…...

3步实现QQ机器人零门槛搭建:LuckyLilliaBot开源机器人服务配置指南
3步实现QQ机器人零门槛搭建:LuckyLilliaBot开源机器人服务配置指南 【免费下载链接】LuckyLilliaBot 使你的NTQQ支持OneBot11协议进行QQ机器人开发 项目地址: https://gitcode.com/gh_mirrors/ll/LuckyLilliaBot 在数字化时代,拥有一个属于自己的…...

一文讲透|9个降AI率网站测评:自考降AI率全攻略
在当前学术写作中,AI生成内容(AIGC)的广泛应用让论文查重和降AI率成为自考学生必须面对的难题。随着各大高校对AI痕迹检测的重视程度不断提升,传统的改写方式已难以满足需求。这时候,专业的AI降重工具便成为提升论文质…...

Day 3 面试算法练习:二叉树层序遍历
核心思路:利用队列,根左右的顺序循环出队入队时间复杂度:o(n)from collections import dequeclass TreeNode:def __init__(self, val0, leftNone, rightNone):self.val valself.left leftself.right rightdef level_order(root):if root i…...

如何快速集成APlayer到你的网站?5分钟入门指南
如何快速集成APlayer到你的网站?5分钟入门指南 【免费下载链接】APlayer 项目地址: https://gitcode.com/gh_mirrors/apl/APlayer APlayer是一款轻量级的HTML5音乐播放器,能够帮助开发者在网站中快速实现专业的音频播放功能。本指南将带你在5分钟…...

LPCNet架构详解:Linear Prediction与WaveRNN如何完美结合?
LPCNet架构详解:Linear Prediction与WaveRNN如何完美结合? 【免费下载链接】LPCNet 项目地址: https://gitcode.com/gh_mirrors/lp/LPCNet LPCNet是一种创新的神经语音合成技术,它巧妙结合了Linear Prediction(线性预测&a…...