PhysioNet2017分类的代码实现
PhysioNet2017数据集介绍可参考文章:https://wendy.blog.csdn.net/article/details/128686196。本文主要介绍利用PhysioNet2017数据集对其进行分类的代码实现。
目录
- 一、数据集预处理
- 二、训练
- 2.1 导入数据集并进行数据裁剪
- 2.2 划分训练集、验证集和测试集
- 2.3 设置训练网络和结构
- 2.4 开始训练
- 2.5 查看训练结果
- 三、测试
一、数据集预处理
首先需要进行数据集预处理。
train2017文件夹中存放相应的训练集,其中REFERENCE.csv文件存放分类结果。分类结果有四种,分别是:N(Normal,正常),A(AF,心房颤动),O(Other,其他节律),~(Noisy,噪声记录)。
首先需要划分训练集、验证集和测试集:
# 加载数据集,默认80%训练集和20%测试集
def load_physionet(dir_path, test=0.2,vali=0, shuffle=True):"return train_X, train_y, test_X, test_y, valid_X, valid_y"if dir_path[-1]!='/': dir_path = dir_path+'/'ref = pd.read_csv(dir_path+'REFERENCE.csv',header=None) # 分类结果label_id = {'N':0, 'A':1, 'O':2, '~':3 }#Normal, AF, Other, NoisyX = []y = []test_X = Nonetest_y = Nonevalid_X = Nonevalid_y = Nonefor index, row in ref.iterrows():file_prefix = row[0]mat_file = dir_path+file_prefix+'.mat'hea_file = dir_path+file_prefix+'.hea'data = loadmat(mat_file)['val']data = data.squeeze()data = np.nan_to_num(data)data = data-np.mean(data)data = data/np.std(data)X.append( data )y.append( label_id[row[1]] )data_n = len(y)print(data_n)X = np.array(X)y = np.array(y)if shuffle:shuffle_idx = list(range(data_n))random.shuffle(shuffle_idx)X = X[shuffle_idx]y = y[shuffle_idx]valid_n = int(vali*data_n) test_n = int(test*data_n)assert (valid_n+test_n <= data_n) , "Dataset has no enough samples!"if vali>0:valid_X = X[0:valid_n]valid_y = y[0:valid_n]if test>0:test_X = X[valid_n: valid_n+test_n]test_y = y[valid_n: valid_n+test_n]if vali>0 or test>0:X = X[valid_n+test_n: ]y = y[valid_n+test_n: ]#print('Train: %d, Test: %d, Validation: %d (%s)'%((data_n-valid_n-test_n), test_n, valid_n, 'shuffled' if shuffle else 'unshuffled'))return np.squeeze(X), np.squeeze(y), np.squeeze(test_X), np.squeeze(test_y), np.squeeze(valid_X), np.squeeze(valid_y)
加载数据集并将其保存为mat文件:
def merge_data(dir_path, test=0.2, train_file='train',test_file='test',shuffle=True):train_X, train_y, test_X, test_y, _, _ = load_physionet(dir_path=dir_path, test=test, vali=0, shuffle=True) # 划分训练集、验证集和测试集# 数据集8528个记录 8528*0.8=6823,8528*0.2=1705train_data = {'data': train_X, 'label':train_y} # 6823test_data = {'data': test_X, 'label':test_y} # 1705# 保存训练集和测试集为mat文件savemat(train_file,train_data)savemat(test_file, test_data)print("[!] Train set saved as %s"%(train_file))print("[!] Test set saved as %s"%(test_file))def main():parser = argparse.ArgumentParser()parser.add_argument('--dir',type=str,default='training2017',help='the directory of dataset')parser.add_argument('--test_set',type=float,default=0.2,help='The percentage of test set')args = parser.parse_args()merge_data(args.dir, test=args.test_set)if __name__=='__main__':main()
运行之后将PhysioNet2017心电图数据集保存为train.mat和test.mat。

二、训练
2.1 导入数据集并进行数据裁剪
时序数据都需要进行相应的数据裁剪。裁剪函数如下:
def cut_and_pad(X, cut_size):n = len(X)X_cut = np.zeros(shape=(n, cut_size)) # (6823,300*30)for i in range(n):data_len = X[i].squeeze().shape[0] # 每个数据的长度# cut if too long / padd if too shortX_cut[i, :min(cut_size, data_len)] = X[i][0, :min(cut_size, data_len)] # 每个长度裁剪为cut_size=9000个return X_cut
首先需要将处理后的数据集导入并进行数据裁剪。
训练集的数据尺寸为:(1, 6823);训练集的标签尺寸为:(1, 6823);【总数据量为8528个数据,训练集数据占比80%,即8528*80%=6823】
加载训练集train.mat,进行数据裁剪,裁剪长度为300x30=9000,即前9000个数据。代码如下:
training_set = loadmat('train.mat') # 加载训练集
X = training_set['data'][0]
y = training_set['label'][0].astype('int32')#cut_size_start = 300 * 3
cut_size = 300 * 30X = cut_and_pad(X, cut_size)
裁剪后可以查看第一个数据的图像:
代码如下:
import matplotlib.pyplot as plt
plt.plot(range(cut_size),X[0])
plt.show()
效果图如下:
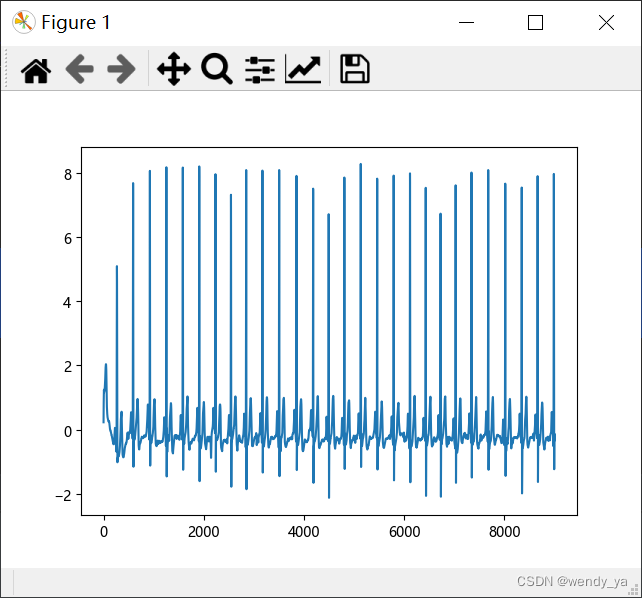
2.2 划分训练集、验证集和测试集
首先需要判断是否进行k折交叉验证,若进行k折交叉验证,下界为0上界为5(5折);若不进行k折交叉验证则下界为0上界为1(默认不进行交叉验证)。
# k-fold / train
if args.k_folder:low_border = 0high_border = 5F1_valid = np.zeros(5)
else:low_border = 0high_border = 1
然后利用get_sub_set函数根据是否进行交叉验证划分训练集和验证集,90%为训练集,10%为验证集。
# 划分训练集和验证集
def get_sub_set(X, y, k, K_folder_or_not):if not K_folder_or_not: # Falsek_dataset_len = int(len(X) * 0.9) # 6823*0.9=6140train_X = X[ : k_dataset_len] # 6140train_y = y[ : k_dataset_len]valid_X = X[ k_dataset_len:] # 683valid_y = y[ k_dataset_len:]else:k_dataset_len = int(len(X) / 5)if k == 0:valid_X = X[ : k_dataset_len ]valid_y = y[ : k_dataset_len ]train_X = X[ k_dataset_len :]train_y = y[ k_dataset_len :]else:print(k*k_dataset_len)valid_X = X[ k*k_dataset_len : (k+1)*k_dataset_len ]valid_y = y[ k*k_dataset_len : (k+1)*k_dataset_len ]train_X = np.concatenate((X[ : k*k_dataset_len] , X[(k+1)*k_dataset_len: ]), axis=0)train_y = np.concatenate((y[ : k*k_dataset_len] , y[(k+1)*k_dataset_len: ]), axis=0)return train_X, train_y, valid_X, valid_y
输出训练集长度和验证集长度查看信息。

2.3 设置训练网络和结构
网络架构利用ResNet实现,损失函数使用交叉熵损失函数softmax_cross_entropy,优化器利用Adam优化器实现。
加载模型时,如果有已经训练好的模型,则恢复模型:Model restored from checkpoints;否则,重新训练模型:Restore failed, training new model!
2.4 开始训练
开始训练代码如下:
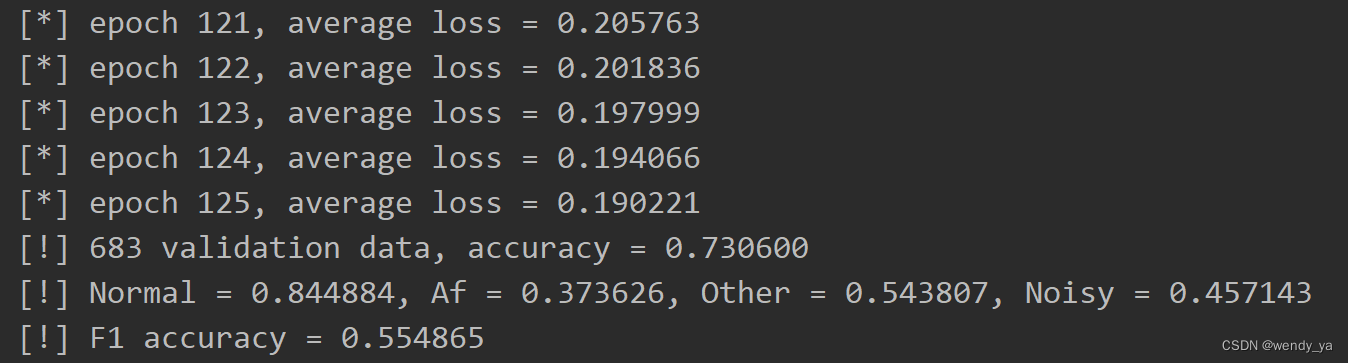
# 开始训练while True:total_loss = []ep = ep + 1for itr in range(0,len(train_X),batch_size):# prepare data batchif itr+batch_size>=len(train_X):cat_n = itr+batch_size-len(train_X)cat_idx = random.sample(range(len(train_X)),cat_n)batch_inputs = np.concatenate((train_X[itr:],train_X[cat_idx]),axis=0)batch_labels = np.concatenate((y_onehot[itr:],y_onehot[cat_idx]),axis=0)else:batch_inputs = train_X[itr:itr+batch_size] batch_labels = y_onehot[itr:itr+batch_size]_, summary, cur_loss = sess.run([opt, merge, loss], {data_input: batch_inputs, label_input: batch_labels})total_loss.append(cur_loss)#if itr % 10==0:# print(' iter %d, loss = %f'%(itr, cur_loss))# saver.save(sess, args.ckpt)# 将所有日志写入文件summary_writer.add_summary(summary, global_step=ep) # 将训练过程数据保存在summary中[train_loss]print('[*] epoch %d, average loss = %f'%(ep, np.mean(total_loss)))if not args.k_folder:saver.save(sess, 'checkpoints/model')# validationif ep % 5 ==0: #and ep!=0:err = 0n = np.zeros(class_num)N = np.zeros(class_num)correct = np.zeros(class_num)valid_n = len(valid_X)for i in range(valid_n):res = sess.run([logits], {data_input: valid_X[i].reshape(-1, cut_size,1)})# print(valid_y[i])# print(res)predicts = np.argmax(res[0],axis=1)n[predicts] = n[predicts] + 1 N[valid_y[i]] = N[valid_y[i]] + 1if predicts[0]!= valid_y[i]:err+=1else:correct[predicts] = correct[predicts] + 1print("[!] %d validation data, accuracy = %f"%(valid_n, 1.0 * (valid_n - err)/valid_n))res = 2.0 * correct / (N + n)print("[!] Normal = %f, Af = %f, Other = %f, Noisy = %f" % (res[0], res[1], res[2], res[3]))print("[!] F1 accuracy = %f" % np.mean(2.0 * correct / (N + n)))if args.k_folder:F1_valid[k] = np.mean(res)if np.mean(total_loss) < 0.2 and ep % 5 == 0:# 保存内容summary_writer.close()# 将total_loss保存为csvtl = pd.DataFrame(data=total_loss)tl.to_csv('loss.csv')break
2.5 查看训练结果
利用tensorboard可以查看训练的loss损失,损失图像如下:
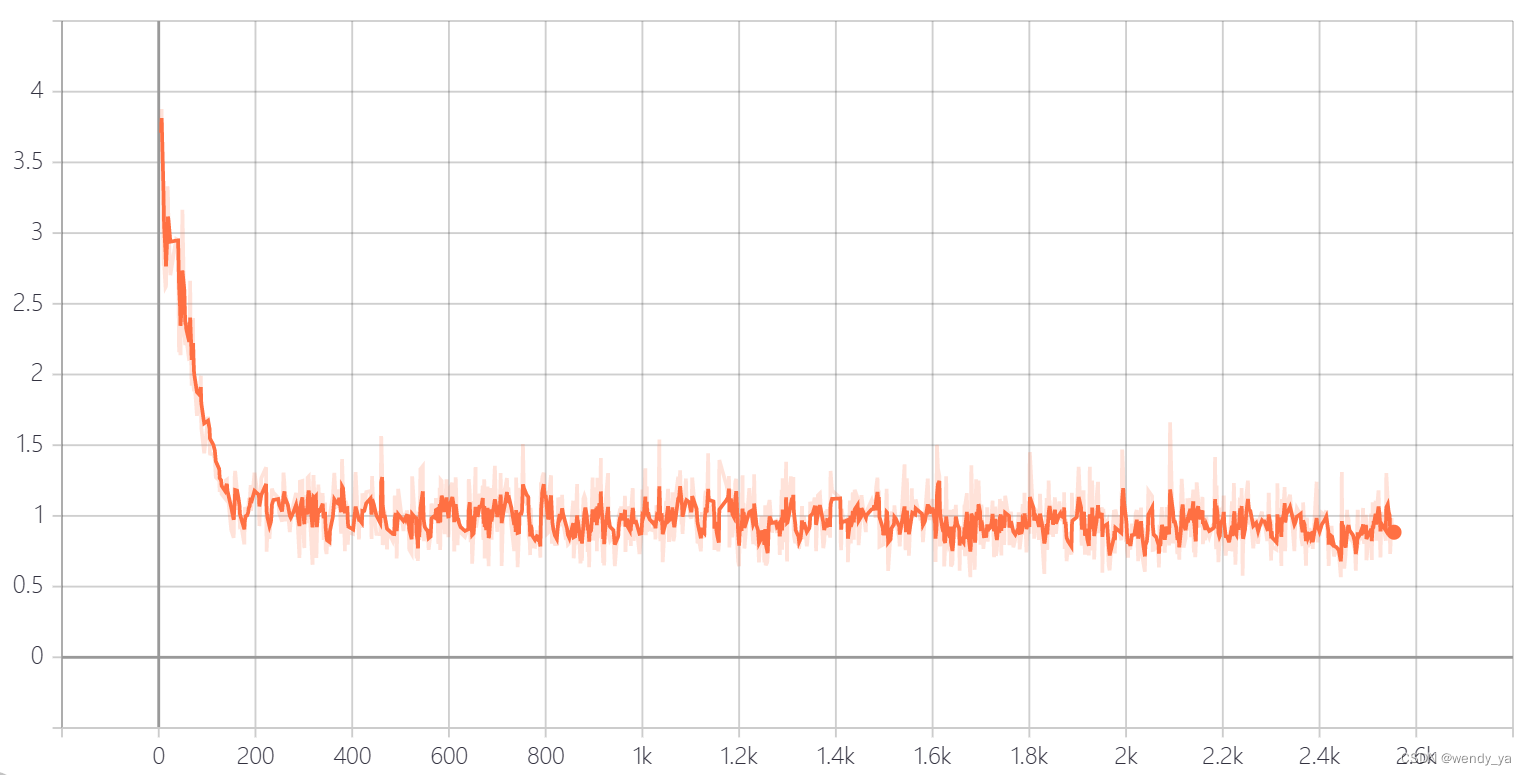
loss阈值设置为0.2,最后的准确率如下:
三、测试
训练完成后,开始测试。
首先需要将处理后的测试集导入并进行数据裁剪。
测试集的数据尺寸为:(1, 1705);测试集的标签尺寸为:(1, 1705);【总数据量为8528个数据,测试集数据占比20%,即8528*20%=1705】
加载测试集test.mat,进行数据裁剪,裁剪长度为300x30=9000,即前9000个数据。代码如下:
training_set = loadmat('test.mat')
X = training_set['data'][0] # (1705,)
y = training_set['label'][0].astype('int32') # (1705,)cut_size = 300 * 30
n = len(X)
X_cut = np.zeros(shape=(n, cut_size))
for i in range(n):data_len = X[i].squeeze().shape[0]X_cut[i, :min(cut_size, data_len)] = X[i][0, :min(cut_size, data_len)]
X = X_cut
然后将数据输入训练好的网络进行测试:
# reconstruct model
test_input = tf.placeholder(dtype='float32',shape=(None,cut_size,1))
res_net = ResNet(test_input, class_num=class_num)tf_config = tf.ConfigProto()
tf_config.gpu_options.allow_growth = True
sess = tf.Session(config=tf_config)sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables())# restore model
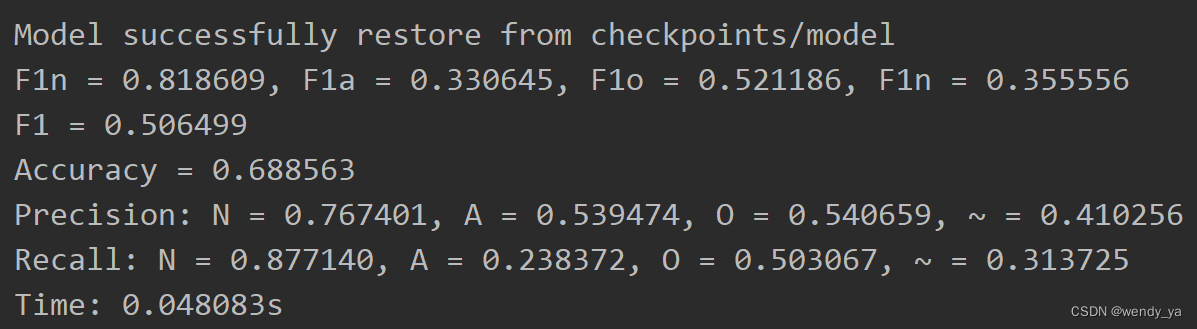
if os.path.exists(args.check_point_folder + '/'):saver.restore(sess, args.check_point_folder + '/model')print('Model successfully restore from ' + args.check_point_folder + '/model')
else: print('Restore failed. No model found!')
测试结束后,需要查看测试准确率,F1-score等诸多指标,这里首先需要定义三个变量:
PreCount = np.zeros(class_num) # 每种类型的预测数量
RealCount = np.zeros(class_num) # 每种类型的数量
CorrectCount = np.zeros(class_num) # 每种类型预测正确数量
PreCount用于存放每种类型的预测结果,RealCount用于存放每种类型的数量,CorrectCount用于存放每种类型预测正确的数量。
最后查看所有结果,F1-score、Accuracy,Precision,Recall,Time结果如下:(这是loss为0.2时的结果)
ok,以上便是本文的全部内容了,如果想要获取完整代码,可以参考资源:https://download.csdn.net/download/didi_ya/87444631
;
如果想重新训练,请删除checkpoints文件夹内所有文件和logs文件夹内所有文件(不要删除logs文件夹)并重新运行train.py程序,若不删除,则继续使用之前模型训练,logs文件夹主要用于存放tensorboard可视化图像,若不删除重新运行程序,可能会重新生成可视化图像,影响效果。188行可以指定最终的loss,如果想精确度高,请将loss尽量调小。tensorflow版本:1.x。(我使用的是tensorflow1.15)
遇到任何问题欢迎私信咨询~
相关文章:
PhysioNet2017分类的代码实现
PhysioNet2017数据集介绍可参考文章:https://wendy.blog.csdn.net/article/details/128686196。本文主要介绍利用PhysioNet2017数据集对其进行分类的代码实现。 目录一、数据集预处理二、训练2.1 导入数据集并进行数据裁剪2.2 划分训练集、验证集和测试集2.3 设置训…...

正大期货本周财经大事抢先看
美国1月CPI、Fed 等央行官员谈话 美国1月超强劲的非农就业人口,让投资人开始上修对这波升息循环利率顶点的预测,也使本周二 (14 日) 的美国 1月 CPI 格外受关注。 介绍正大国际期货主账户对比国内期货的优势 第一点:权限都在主账户 例如…...

html+css综合练习一
文章目录一、小米注册页面1、要求2、案例图3、实现效果3.1、index.html3.2、style.css二、下午茶页面1、要求2、案例图3、index.html4、style.css三、法国巴黎页面1、要求2、案例图3、index.html4、style.css一、小米注册页面 1、要求 阅读下列说明、效果图,进行静…...
安装jdk8
目录标题一、下载地址(一)Linux下载(二)Win下载二、安装(一)Linux(二)Win三、卸载(一)Linux(二)Win一、下载地址 jdk8最新版 jdk8其他…...

二分法心得
原教程见labuladong 首先,我们建议左右区间全部用闭区间。那么第一个搜索区间:left0; rightlen-1; 进入while循环,结束条件是right<left。 然后求mid,如果nums[mid]的值比target大,说明target在左边,…...

Linux安装Docker完整教程
背景最近接手了几个项目,发现项目的部署基本上都是基于Docker的,幸亏在几年前已经熟悉的Docker的基本使用,没有抓瞎。这两年随着云原生的发展,Docker在云原生中的作用使得它也蓬勃发展起来。今天这篇文章就带大家一起实现一下在Li…...

备份基础知识
备份策略可包括:– 整个数据库(整个)– 部分数据库(部分)• 备份类型可指示包含以下项:– 所选文件中的所有数据块(完全备份)– 只限自以前某次备份以来更改过的信息(增量…...

C++学习记录——팔 内存管理
文章目录1、动态内存管理2、内存管理方式operator new operator delete3、new和delete的实现原理1、动态内存管理 C兼容C语言关于内存分配的语法,而添加了C独有的东西。 //int* p1 (int*)malloc(sizeof(int));int* p1 new int;new是一个操作符,C不再需…...

Spring事务失效原因分析解决
文章目录1、方法内部调用2、修饰符3、非运行时异常4、try…catch捕获异常5、多线程调用6、同时使用Transactional和Async7、错误使用事务传播行为8、使用的数据库不支持事务9、是否开启事务支持在工作中,经常会碰到一些事务失效的坑,基于遇到的情况&…...
4个月的测试经验,来面试就开口要17K,面试完,我连5K都不想给他.....
2021年8月份我入职了深圳某家创业公司,刚入职还是很兴奋的,到公司一看我傻了,公司除了我一个测试,公司的开发人员就只有3个前端2个后端还有2个UI,在粗略了解公司的业务后才发现是一个从零开始的项目,目前啥…...
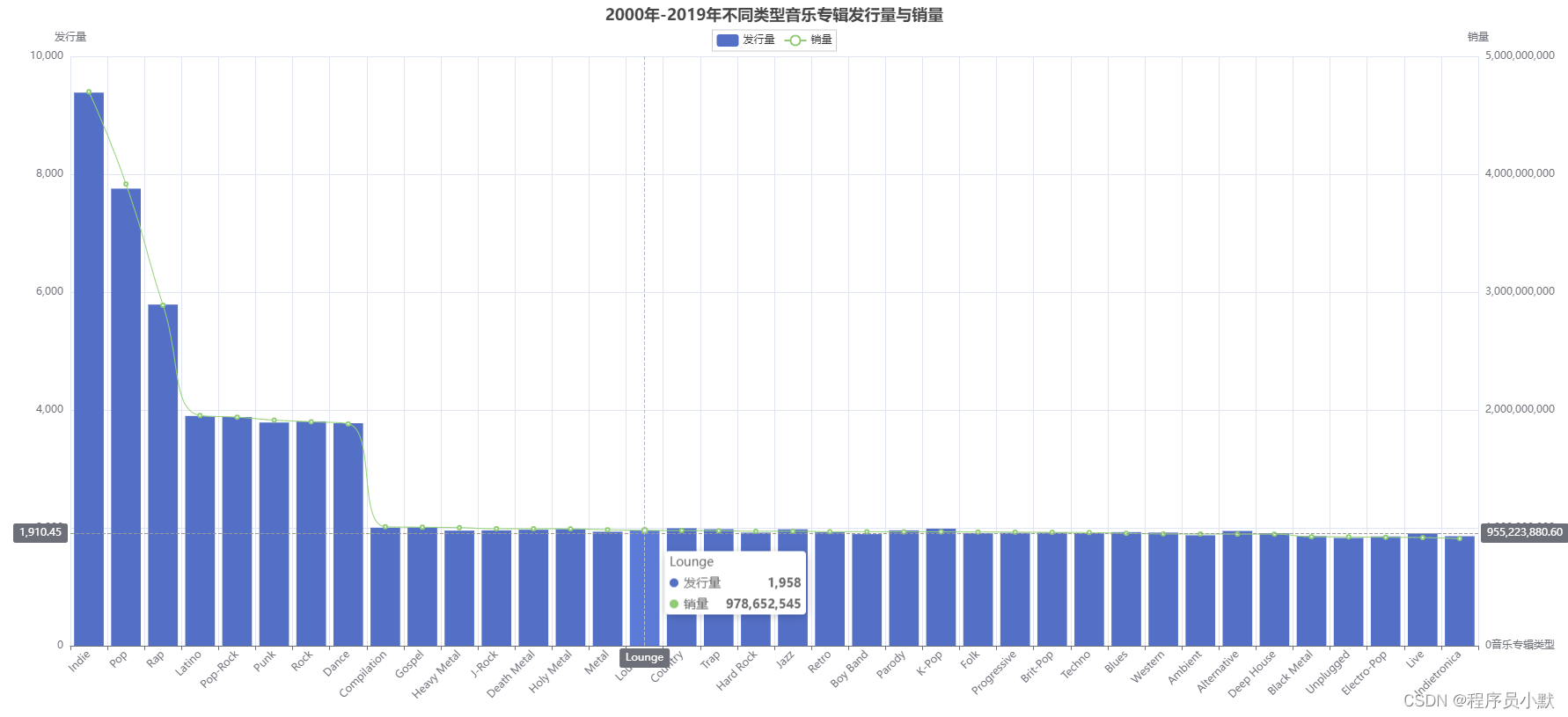
python学习之pyecharts库的使用总结
pyecharts官方文档:https://pyecharts.org//#/zh-cn/ 【1】Timeline 其是一个时间轴组件,如下图红框所示,当点击红色箭头指向的“播放”按钮时,会呈现动画形式展示每一年的数据变化。 data格式为DataFrame,数据如下图…...
【taichi】利用 taichi 编写深度学习算子 —— 以提取右上三角阵为例
本文以取 (bs, n, n) 张量的右上三角阵并展平为向量 (bs, n*(n1)//2)) 为例,展示如何用 taichi 编写深度学习算子。 如图,要把形状为 (bs,n,n)(bs,n,n)(bs,n,n) 的张量,转化为 (bs,n(n1)2)(bs,\frac{n(n1)}{2})(bs,2n(n1)) 的向量。我们先写…...

二进制 k8s 集群下线 worker 组件流程分析和实践
文章目录[toc]事出因果个人思路准备实践当前 worker 节点信息将节点标记为不可调度驱逐节点 pod将 worker 节点从 k8s 集群踢出下线 worker 节点相关组件事出因果 因为之前写了一篇 二进制 k8s 集群下线 master 组件流程分析和实践,所以索性再写一个 worker 节点的缩…...

Bean的六种作用域
限定程序中变量的可用范围叫做作用域,Bean对象的作用域是指Bean对象在Spring整个框架中的某种行为模式~~ Bean对象的六种作用域: singleton:单例作用域(默认) prototype:原型作用域(多例作用域…...

Http发展历史
1 缘起 有一次,听到有人在议论招聘面试的人员, 谈及应聘人员的知识深度,说:问了一些关于Http的问题,如Http相关结构、网络结构等, 然后又说,问没问相关原理、来源? 我也是有些困惑了…...

高级Java程序员必备的技术点,你会了吗?
很多程序员在入行之后的前一两年,快速学习到了做项目常用的各种技术之后,便进入了技术很难寸进的平台期。反正手里掌握的一些技术对于应付普通项目来说,足够用了。因此也会缺入停滞,最终随着年龄的增长,竞争力不断下降…...

【暴力量化】查找最优均线
搜索逻辑 代码主要以支撑概率和压力概率来判断均线的优劣 判断为压力: 当日线与测试均线发生金叉或即将发生金叉后继续下行 判断为支撑: 当日线与测试均线发生死叉或即将发生死叉后继续上行 判断结果的天数: 小于6日均线,用金叉或…...
Java读取mysql导入的文件时中文字段出现�??的乱码如何解决
今天在写程序时遇到了一个乱码问题,困扰了好久,事情是这样的, 在Mapper层编写了查询语句,然后服务处调用,结果控制器返回一堆乱码 然后查看数据源头处: 由重新更改解码的字符集,在数据库中是正…...
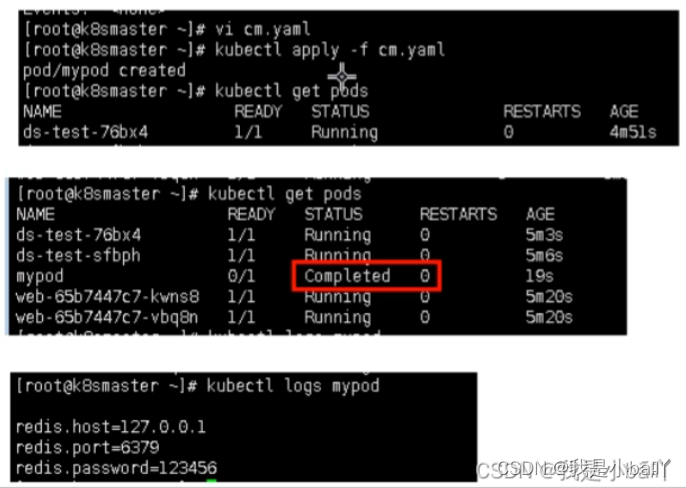
k8s核心概念—Pod Controller Service介绍——20230213
文章目录一、Pod1. pod概述2. pod存在意义3. Pod实现机制4. pod镜像拉取策略5. pod资源限制6. pod重启机制7. pod健康检查8. 创建pod流程9. pod调度二、Controller1. 什么是Controller2. Pod和Controller关系3. deployment应用场景4. 使用deployment部署应用(yaml&a…...

Tensorflow的数学基础
Tensorflow的数学基础 在构建一个基本的TensorFlow程序之前,关键是要掌握TensorFlow所需的数学思想。任何机器学习算法的核心都被认为是数学。某种机器学习算法的策略或解决方案是借助于关键的数学原理建立的。让我们深入了解一下TensorFlow的数学基础。 Scalar 标…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...
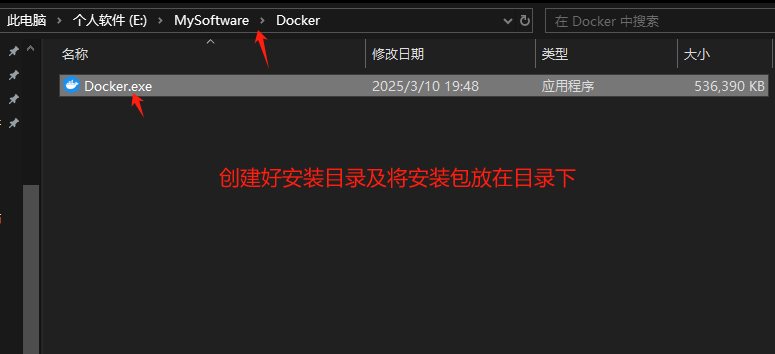
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...