华为阿里版ChatGPT横空出世,谁的成效更好呢?
“你训练的大模型涌现了吗?”“还没有。好难受。”一时间成为了最近AI赛道玩家的一个爆热梗。
不管承不承认,相信每个玩家都不愿意输掉这场激烈的竞争。自百度成为国内“第一个吃螃蟹的人”后,又有两大中国科技巨头做好了准备——华为和阿里巴巴各自新研发的“大模型”、“ChatGPT”,也都即将于近日问世。
首先是华为的盘古大模型新版本即将亮相的消息!据称,4月8日,华为云人工智能首席科学家田奇,将在杭州人工智能大模型技术高峰论坛上,通过一场技术分享介绍“盘古大模型的进展及其应用”。
与此同时,一封来自阿里的会议邀请函也给业内带来了很有分量的消息:在4月11日的阿里云峰会上,将正式推出阿里最新自研的大模型,模型内测目前已在进行中,且接下来还会有各类行业应用类模型问世。就在今天中午,通义大模型已经官宣开始企业邀测!

如果说之前巨头们从“大炼模型”到“炼大模型”是在秀肌肉、打地基,那么这次发布模型的意义,则更多的在于入局类ChatGPT产品赛道!
一、华为:深耕B端,开辟多业务场景
事实上,华为自2020年便启动了AI大模型布局。据相关资料显示,盘古NLP大模型采用深度学习和自然语言处理技术,采用了大量中文语料库进行训练,基于“预训练+下游微调”的工业化AI开发模式,拥有超千亿参数,并支持多种自然语言处理任务,包括文本生成、文本分类、系统问答等。
1.华为版ChatGPT:接近GPT3.5水平,注重中文优化
根据华为云官方显示,华为即将上线的“盘古系列AI大模型”分别为NLP大模型(对标ChatGPT)、CV大模型、多模态大模型与科学计算大模型。据介绍,其中NLP大模型在预训练阶段学习了超40TB中文文本数据;CV大模型首次实现兼顾图像判别与生成能力;而科学计算大模型则可应用于气象、生物医药等领域。

与ChatGPT相比,盘古NLP大模型在数据方面更接近GPT3.5的水平,但其更加注重中文语言优化,在中文语法语义理解上有着更大优势,并且其拥有泛化能力强、小样本学习和模型高精度三大特性,可适用大量复杂的行业场景,即使少量样本也能达到高精度。
根据华为官方介绍,盘古NLP大模型在总排行榜及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录,总排行榜得分83.046,多项子任务得分业界领先,是目前最接近人类理解水平 (85.61)的预训练模型之一。
2.华为的三个独特优势
在大模型研发方面,华为相比于其他国内企业有着一项较为独特的优势——拥有完整的产业链和较强的算力匹配能力。据介绍,盘古系列大模型都是基于华为Model Arts所构建的,并由在2022年蝉联全球人工智能算力第一的鹏城云脑二期提供算力底座。在训练盘古大模型时,华为团队调用了超过2000块昇腾910芯片,进行了超过2个月的训练。
产业生态层面,华为则延续了自己重B端的企业基因,大模型产业化的初衷正是在于开辟更多B端业务场景,正如华为云人工智能首席科学家田奇所言,“将工业化的一面放置在更高的优先级上”。此外,盘古大模型还融入了华为在5G、云计算、物联网等领域的技术优势,可应用于智能客服、机器翻译、语音识别等多个领域,为企业提供智能化服务。
据中信建投研究报告显示,目前盘古预训练大模型能力已在包括能源、零售、金融、工业等领域得到验证。同时盘古NLP大模型通过迁移学习实现少样本学习目标,并采用了分布式计算技术,可以实现模型的在线训练和增量学习,随着数据量的增加不断优化模型,提高模型的准确度和质量,使其更加适合复杂的商用场景,在部分应用中的表现已超过GPT-3.5。
二、阿里:C端发力,测评结果喜人
再来看阿里这边,无独有偶,阿里的中文大模型研发之路也始于2020年左右。2021年,阿里先后发布国内首个超百亿参数的多模态大模型“通义-M6”以及号称“中文版GPT-3”的语言模型PLUG。虽然参数量仅为270亿,但PLUG与GPT-3一样拥有强大的文本生成能力。
1.通义大模型融合升级
据报道显示,即将发布的阿里达摩院版ChatGPT,正是基于通义大模型体系融合升级而成。通义大模型底座基于统一学习范式OFA等底层技术打造,在不引入新增结构的情况下即可同时处理文生文、文生图、图片描述、内容摘要等多项单模态和多模态任务。经历升级后,更是可以处理超过包括语音和动作在内的多种跨模态任务。
其中“通义-M6”主要解决文本图像生成构建的相关任务,包括图文理解、图文生成、语音理解、语音生成,且阿里2021年发布的模型版本已达千亿参数;而通义-AliceMind则为NLP预训练模型,应用场景包括文生文、文本理解、问答对话等;通义-视觉应用场景则涵盖视频表征、图像检测、视频编辑等。
2.阿里内部爆料
在此前一份有关阿里大模型的采访中,阿里内部人员表示:阿里在大模型方面可以提供的方案主要有两种,一是阿里内部推出的模型效果相对较好,可以与集团内部广泛的C端产品进行结合,例如天猫、淘宝和高德地图的搜索业务,这将为搜索引擎带来全新的商业模式,也将为阿里本就蓬勃的C端业务注入更多活力,而C端的数据积累,也将很好地反哺阿里大模型及相关应用的研发。此外,阿里还可以输出自己的API,并向合作伙伴或渠道商收费。对于API,可能会在特定领域上对合作伙伴有所帮助,例如电商、搜索推荐等。
而在算力方面,阿里云在云上至少有上万片A100,整体至少能够达到10万片,集团的话应该会是阿里云5倍的量级。达摩院、天猫、淘宝的算力资源都是集团内资源使用。由于大模型及衍生应用研发等需求,阿里云今年增速会达到30-50%,个别客户会有复现GPT的需求,提出大规模AI算力需求,阿里将以云的方式进行支持。
除此之外,还有爆料显示,阿里即将推出的类ChatGPT对话机器人产品还可能将与钉钉生产力工具进行结合,后续也得到阿里巴巴方面确认。
3.B站博主测评:结果喜人
更值得注意的是,就在近几天,有B站博主测试了阿里的天猫精灵,发现其已经上线了阿里版ChatGPT的语音助手。对此阿里也进行了回应,表示目前天猫精灵所整合的是大模型技术Demo,“天猫精灵和达摩院一直在紧密合作,其中包括推进大语言模型、声学模型、语音AI等综合应用”。

在B站博主所发布的测评视频中,博主与集成Demo版大模型的天猫精灵进行了超过3分钟的15轮问答对话,其中10问题的回复都明显优于国内已公布的同类型产品。且在了解到用户订餐需求后,天猫精灵同意了用户请求并表示已帮助用户完成了订餐。虽然由于并为集成相应接口,Demo版天猫精灵并没有如它所言完成任务,但相信在正式版发布后,诸如订餐、打车、购票等功能均可能得到实现。
三、专家热评华为生态布局扎实阿里数据和算力更优
那么,业内专家对于阿里和华为即将发布的大模型又有哪些评价和看法呢?为此,51CTO采访到了人工智能技术专家、前智源研究院政务创新中心技术负责人刘占亮老师。
据刘占亮分析,华为在该方面的最主要优势是:华为在toB领域的长期积累使其拥有着非常扎实的产业生态,而华为在人工智能方面的全栈布局将有助于企业在各领域、各不同业务中的长期发展。但从短期角度来看,华为大模型的商业化进展将有可能会受到底层基础设施成熟度的影响。
对于阿里而言,其拥有着覆盖多个行业的生态体系,大量C端以及B端的数据积累将为阿里大模型研发提供非常重要的动力,而在算力方面,阿里相比于大部分科技企业而言也有着巨大的优势。在数据和算力优势的加持之下,阿里在大模型研发及生产应用方面的效率应该能够达到较高水平。
虽然从应用领域与目标用户的角度来看,华为和阿里两家企业可能会有所不同。但归根结底,两家公司都有潜力推动中国人工智能领域发展。
但在此之前,刘占亮还指出,摆在这两位巨头眼前的还有三大主要挑战,其一是需要应对国内外激烈的市场竞争;其二是需要对潜在的政治风险做到0失误的精准控制;其三则是老生常谈的技术挑战,无论华为还是阿里,在自身业务层面都有着非常丰富的经验积累,那么其所研发的大模型及一系列衍生产品能否在实际生产中发挥更高的效率,这考验的便是企业对于特定领域技术的应用与理解。
四、国产化ChatGPT才是出路
近期以来,ChatGPT陷入了一些列纷争之中,由于非法收集用户数据的原因,意大利已进行了对ChatGPT的全面禁封,德国也出于对数据保护的考虑,正在计划在全国范围内禁止ChatGPT的使用。而在不久前,ChatGPT也针对亚洲地区进行了一次悄无声息的大规模封号。就以上事件看来,依靠ChatGPT,微软与OpenAI已经成为事实上的头号玩家,而这对于国内企业类似产品的发展而言,不管是封禁还是封号,都并不是一个良好的势头。
诚然,由于中文天然的复杂性,实现中文版ChatGPT的难度将会变得更大,但国内科技企业能够在这一时期,利用自身优势研发针对不同业务场景的同类型模型及应用,无论是出于对自身利益的考量还是出于对更高理想的追求,这本身都是一件值得鼓励的事情。人工智能的发展在带来科技革命的同时,也注定会带来同一赛道上的百家争鸣,不管是企业层面,还是全球层面,都避无可避。
五、写在最后
如今,ChatGPT成为下一代操作系统的“叙事”刚刚开始,其所带来的强大的生产力提升必将赋能千行百业,并带来巨大的商业机会。在这样的情况下,自主可控与合理监管才是每个国家、每家科技企业甚至每位技术从业者应该关注与思考的问题。
虽然就目前而言,无论百度、华为、阿里还是其他正在深耕该领域的科技企业,都暂时无法推出能与GPT-4一较高下的AI大模型。但有时后发未必一定是坏事,让我们给予它们一些信心与时间,相信在这些企业与技术从业者的不断努力下,国内AIGC生态建设自主化的步伐将能够越走越快。
相关文章:
华为阿里版ChatGPT横空出世,谁的成效更好呢?
“你训练的大模型涌现了吗?”“还没有。好难受。”一时间成为了最近AI赛道玩家的一个爆热梗。 不管承不承认,相信每个玩家都不愿意输掉这场激烈的竞争。自百度成为国内“第一个吃螃蟹的人”后,又有两大中国科技巨头做好了准备——华为和阿里…...

【云原生之Docker实战】使用docker部署kooteam在线团队协作工具
【云原生之Docker实战】使用docker部署kooteam在线团队协作工具 一、kooteam介绍1.kooteam介绍2.kooteam的技术选型二、检查本地docker环境1.检查Docker版本2.检查Docker状态三、下载kooteam镜像四、部署kooteam文档管理系统1.创建安装目录2.创建mysql数据库3.新建kooteam数据库…...

ITSS认证是什么认证,itss资质认证
一、ITSS是什么 ITSS根据英文翻译信息技术服务标准(InformationTechnologyServiceStandards,简称ITSS),它既是一套成体系和综合配套的标准库,又是一套选择和提供IT服务的方法学,对企业IT服务而言࿰…...
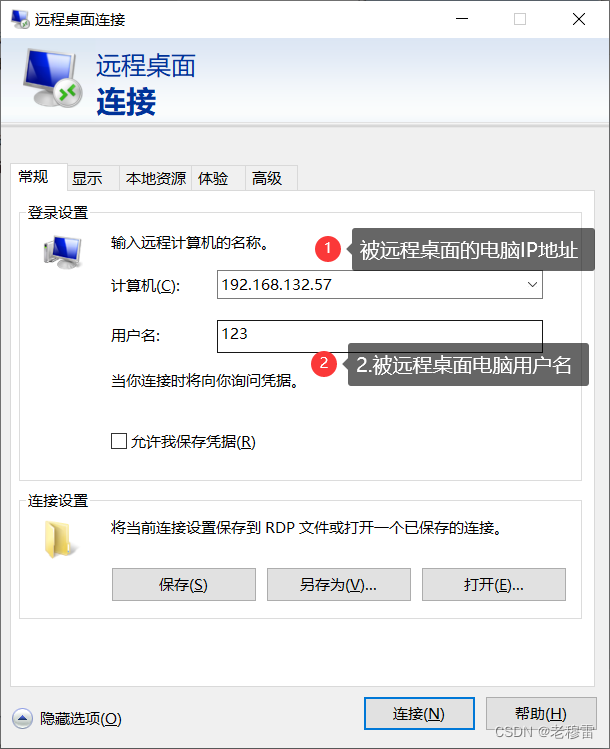
FTP-----局域网内部远程桌面
此文包含详细的图文教程。有疑问评论区留言。博主第一时间解决。 目录 一、被远程桌面的电脑 1.开启远程权限 2.添加账户,有本地账户跳过这步 3.帐号隶属于 远程桌面 4.帐号隶属于 本地用户组 二、本地电脑连接远程桌面 前提条件: 1.两台电脑在…...

Learning C++ No.18【STL No.8】
引言: 北京时间:2023/3/18/21:47,周末,不摆烂,但是欠钱终于还是遭报应了,导致坐牢7小时(上午3.5,下午3.5),难受,充分意识到行哥是那么的和蔼可亲…...

pytorch搭建ResNet50实现鸟类识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客 🍦 参考文章地址: 365天深度学习训练营-第J1周:ResNet-50算法实战与解析 🍖 作者:K同学啊 理论知识储备 深度残差网络ResNet(dee…...

Node.js -- npm与包
1.包 Node.js中的第三方模块又叫做包 就像电脑和计算机指的是相同的东西,第三方模块和包指的是同一概念,只不过叫法不同。 包的来源: 包是由第三方或者个人团队开发出来的,免费供个人使用。 国外有一家IT 公司,叫做n…...

二 、Locust自定义用户(场景)
二 、自定义用户(场景) 一个用户类代表了你系统中的一种用户/场景。当你做一个测试运行时,你指定你想模拟的并发用户的数量,Locust将为每个用户创建一个实例。你可以给这些类/实例添加任何你喜欢的属性,但有一些属性对…...

1~3年的测试工程师薪资陷入了瓶颈期,如何突破自己实现涨薪?
对于技术人员而言,职业规划一般分为两个方向:做技术、做管理。进入软件测试行业的新人都会从最基础的执行开始,然后是基本的功能测试。 随后大家会根据个人职业发展来进一步细化,有的走管理路线,成为主管、经理、项目…...

springboot项目前端ajax 07进阶优化,使用jQuery的ajax
使用官网https://jquery.com/ 在下载那里,选择Download the compressed, production jQuery 3.6.4(版本不一样),而后在打开的网页中,选择另存为,就下载好了js文件。 > function doAjax(){ …...

东数西存场景的探索与实践
“东数西算”是通过构建数据中心、云计算、大数据一体化的新型算力网络体系,将东部算力需求有序引导到西部,对优化数据中心建设布局,提升国家整体算力水平,促进绿色发展,扩大有效投资,具有重要意义。 在实…...

[图神经网络]PyTorch简单实现一个GCN
Pytorch自带一个PyG的图神经网络库,和构建卷积神经网络类似。不同于卷积神经网络仅需重构__init__( )和forward( )两个函数,PyTorch必须额外重构propagate( )和message( )函数。 一、环境构建 ①安装torch_geometric包。 pip install torch_geometric …...
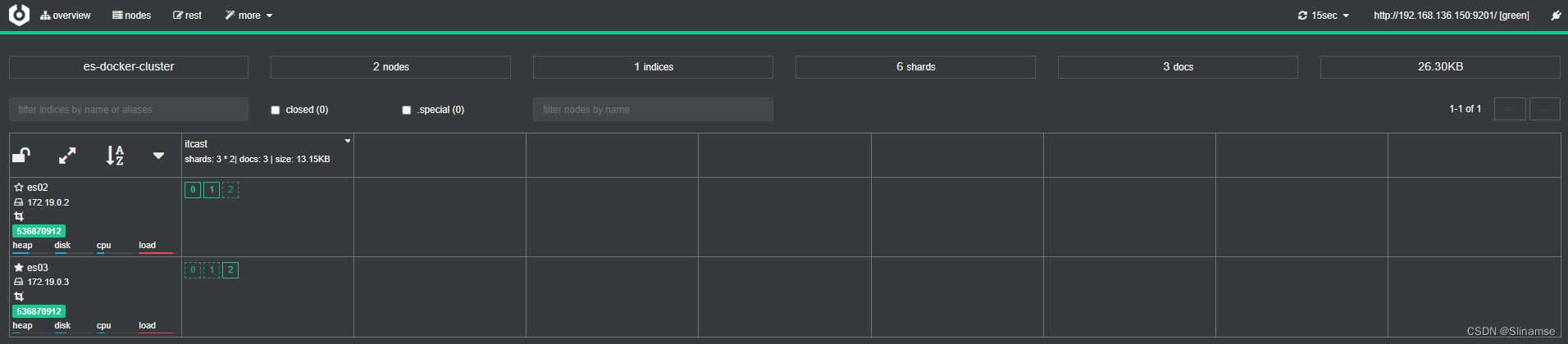
Elasticsearch(黑马)
初识elasticsearch . 安装elasticsearch 1.部署单点es 1.1.创建网络 因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络: docker network create es-net 1.2.加载镜像 这里我们采用elasticsearch的7.12.1版本的…...

oracle数据库调整字段类型
oracle数据库更改字段类型比较墨迹,因为如果该字段有值,是不允许直接更改字段类型的。另外oralce不支持在指定的某个字段后面新增一个字段,但是mysql数据可以向指定的字段后面新增一个字段。 mysql向指定字段后面新增一个字段: al…...
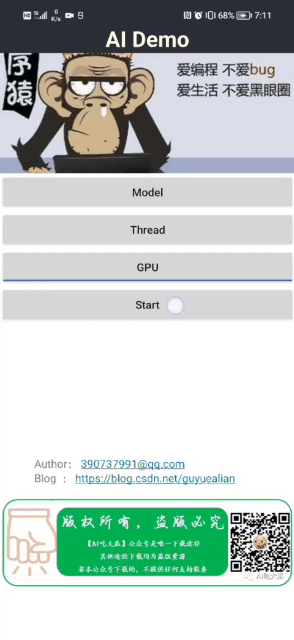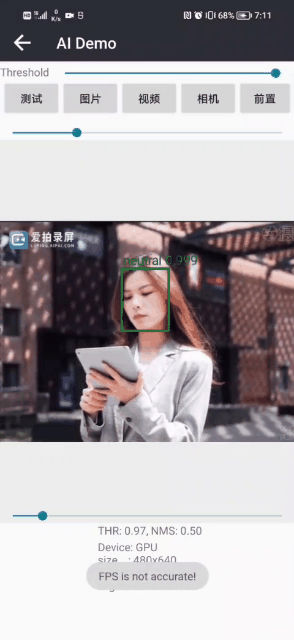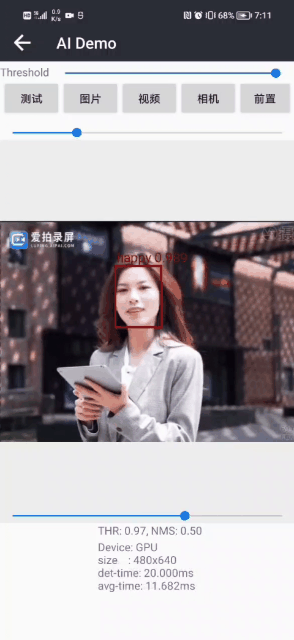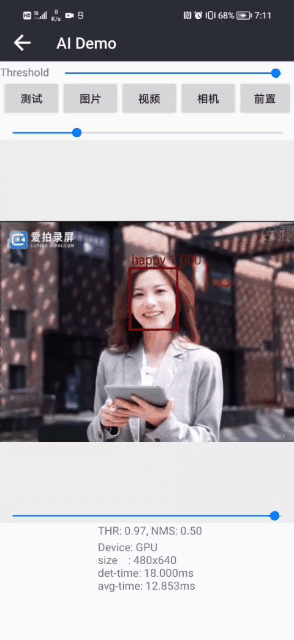
面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)
面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码) 目录 面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码) 1.面部表情识别方法 2.面部表情识别数据集 (1)表情识别数据集说明 (2&…...
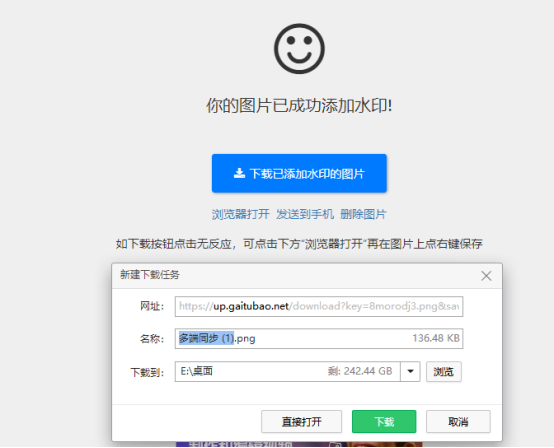
赛效:如何在线给图片加水印
学会给图片加水印是一个非常实用的技能,可以让你的图片更具保护性和个性化。说到加水印,很多人不知道怎么操作。其实,给图片加水印非常简单,不用下载任何程序,在线就能完成。今天,我将介绍如何使用改图宝在…...
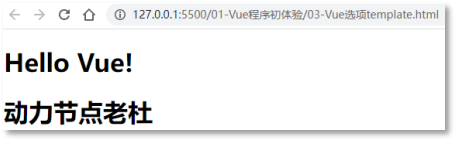
动力节点杜老师Vue笔记——Vue程序初体验
一、Vue程序初体验 我们可以先不去了解Vue框架的发展历史、Vue框架有什么特点、Vue是谁开发的,这些对我们编写Vue程序起不到太大的作用,更何况现在说了一些特点之后,我们也没有办法彻底理解它,因此我们可以先学会用,使…...
ajax上传图片存入到指定的文件夹并回显
html代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><script src"js/jquery-2.1.0.js"></script> </head> <body> <form…...

cesium加载cesiumlab切的影像切片和标准TMS瓦片的区别
1.加载cesiumlab切的影像 var labImg viewer.scene.imageryLayers.addImageryProvider( new Cesium.UrlTemplateImageryProvider({url:http://192.168.1.25:8080/DOMtms/{z}/{x}/{y}.png,fileExtension : "png"})); 2.标准TMS瓦片 var labImg viewer.scene.im…...
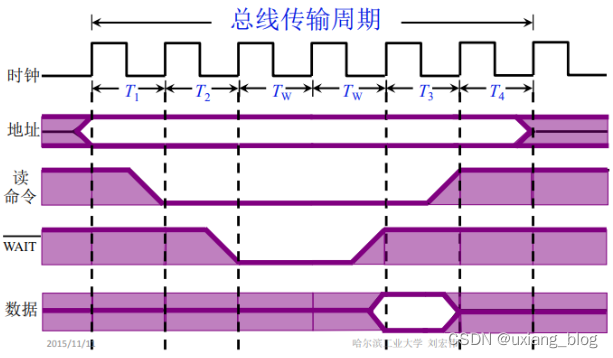
第二周P9-P22
文章目录第三章 系统总线3.1、总线的基本概念一、为什么要用总线二、什么是总线三、总线上信息的传送四、总线结构的计算机举例1、单总线结构框图2、面向CPU的双总线结构框图3、以存储器为中心的双总线结构图3.2、总线的分类1、片内总线2、系统总线3、通信走线3.3、总线特性及性…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...
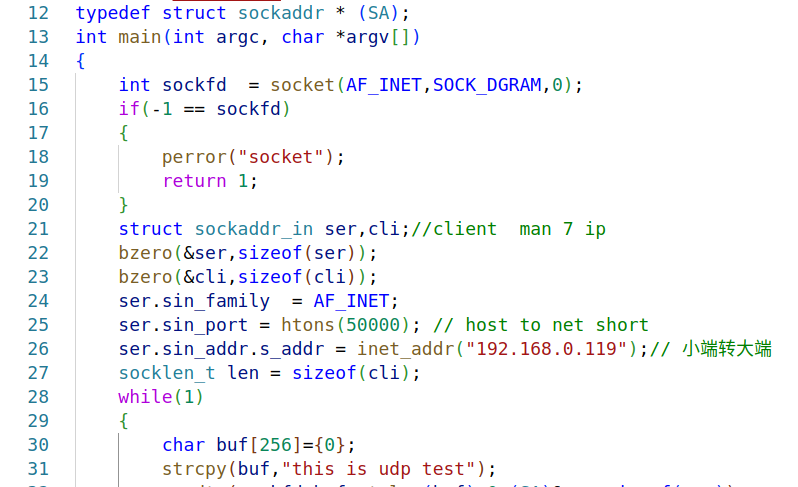
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...
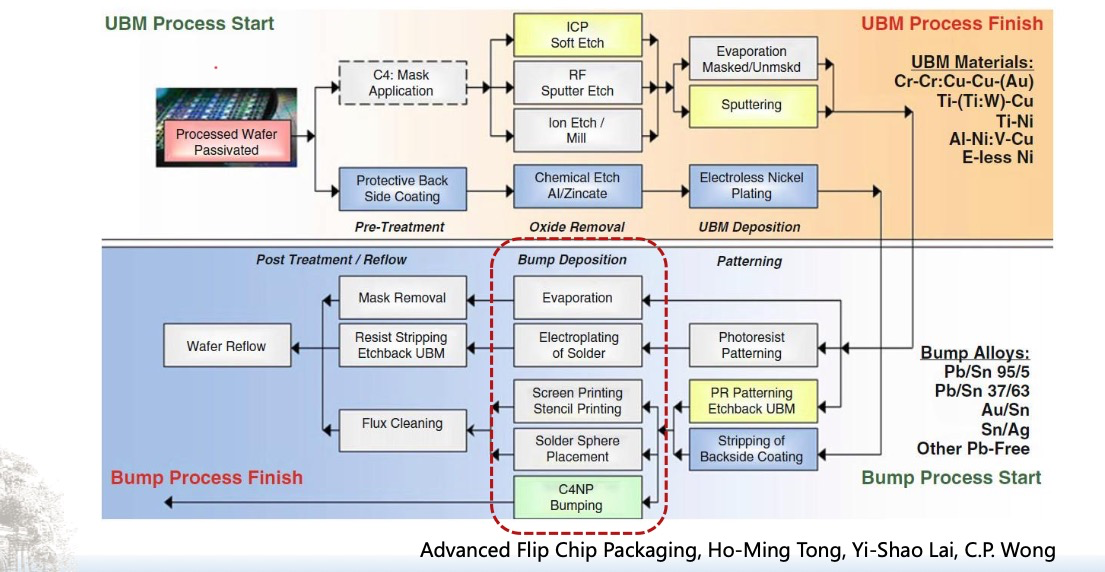
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...