一篇文章带你读懂HashMap
HashMap是面试中经常问到的一个知识点,也是判断一个候选人基础是否扎实的标准之一。可见HashMap的掌握是多重要。
一、HashMap源码分析
1、构造函数
让我们先从构造函数说起,HashMap有四个构造方法,别慌
1.1 HashMap()
// 1.无参构造方法、// 构造一个空的HashMap,初始容量为16,负载因子为0.75public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}无参构造方法就没什么好说的了。
1.2 HashMap(int initialCapacity)
// 2.构造一个初始容量为initialCapacity,负载因子为0.75的空的HashMap,public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR);}HashMap(int initialCapacity) 这个构造方法调用了1.3中的构造方法。
1.3 HashMap(int initialCapacity, float loadFactor)
// 3.构造一个空的初始容量为initialCapacity,负载因子为loadFactor的HashMappublic HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " +loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity);} //最大容量//static final int MAXIMUM_CAPACITY = 1 << 30;当指定的初始容量< 0时抛出IllegalArgumentException异常,当指定的初始容量> MAXIMUM_CAPACITY时,就让初始容量 = MAXIMUM_CAPACITY。当负载因子小于0或者不是数字时,抛出IllegalArgumentException异常。
设定threshold。 这个threshold = capacity * load factor 。当HashMap的size到了threshold时,就要进行resize,也就是扩容。
tableSizeFor()的主要功能是返回一个比给定整数大且最接近的2的幂次方整数,如给定10,返回2的4次方16.
我们进入tableSizeFor(int cap)的源码中看看:
//Returns a power of two size for the given target capacity.static final int tableSizeFor(int cap) { int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}note: HashMap要求容量必须是2的幂。
首先,int n = cap -1是为了防止cap已经是2的幂时,执行完后面的几条无符号右移操作之后,返回的capacity是这个cap的2倍,因为cap已经是2的幂了,就已经满足条件了。 如果不懂可以往下看完几个无符号移位后再回来看。(建议自己在纸上画一下)
-
如果n这时为0了(经过了cap-1之后),则经过后面的几次无符号右移依然是0,最后返回的capacity是1(最后有个n+1的操作)。这里只讨论n不等于0的情况。
以16位为例,假设开始时 n 为 0000 1xxx xxxx xxxx (x代表不关心0还是1)
-
第一次右移
n |= n >>> 1;由于n不等于0,则n的二进制表示中总会有一bit为1,这时考虑最高位的1。通过无符号右移1位,则将最高位的1右移了1位,再做或操作,使得n的二进制表示中与最高位的1紧邻的右边一位也为1,如0000 11xx xxxx xxxx 。
-
第二次右移
n |= n >>> 2;注意,这个n已经经过了
n |= n >>> 1;操作。此时n为0000 11xx xxxx xxxx ,则n无符号右移两位,会将最高位两个连续的1右移两位,然后再与原来的n做或操作,这样n的二进制表示的高位中会有4个连续的1。如0000 1111 xxxx xxxx 。 -
第三次右移
n |= n >>> 4;这次把已经有的高位中的连续的4个1,右移4位,再做或操作,这样n的二进制表示的高位中会有8个连续的1。如0000 1111 1111 xxxx 。
第。。。,你还忍心让我继续推么?相信聪明的你已经想出来了,容量最大也就是32位的正数,所以最后一次 n |= n >>> 16; 可以保证最高位后面的全部置为1。当然如果是32个1的话,此时超出了MAXIMUM_CAPACITY ,所以取值到 MAXIMUM_CAPACITY 。
这里我从别人的文章当一个别人的图片,懒得画了
![]()

注意,得到的这个capacity却被赋值给了threshold。 这里我和这篇博客的博主开始的想法一样,认为应该这么写:this.threshold = tableSizeFor(initialCapacity) * this.loadFactor; 因为这样子才符合threshold的定义:threshold = capacity * load factor 。但是,请注意,在构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算 。
我说一下我在理解这个tableSizeFor函数中间遇到的坑吧,我在想如果n=-1时的情况,因为初始容量可以传进来0。我将n= -1 和下面几条运算一起新写了个测试程序,发现输出都是 -1。 这是因为计算机中数字是由补码存储的,-1的补码是 0xffffffff。所以无符号右移之后再进行或运算之后还是 -1。 那我想如果就无符号右移呢? 比如-1>>>10。听我娓娓道来,32个1无符号右移10位后,高10位为0,低22位为1,此时这个数变成了正数,由于正数的补码和原码相同,所以就变成了0x3FFFFF即10进制的4194303。真刺激。
好开森,这个构造方法我们算是拿下了。怎么样,我猜你现在一定很激动,Hey,old Fe,这才刚开始。接下来看最后一个构造方法。
1.4 HashMap(Map<? extends K, ? extends V> m)
// 4. 构造一个和指定Map有相同mappings的HashMap,初始容量能充足的容下指定的Map,负载因子为0.75public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}套路,直接看 putMapEntries(m,false) 。源码如下:
/*** 将m的所有元素存入本HashMap实例中*/final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) { //得到 m 中元素的个数int s = m.size(); //当 m 中有元素时,则需将map中元素放入本HashMap实例。if (s > 0) { // 判断table是否已经初始化,如果未初始化,则先初始化一些变量。(table初始化是在put时)if (table == null) { // pre-size// 根据待插入的map 的 size 计算要创建的 HashMap 的容量。float ft = ((float)s / loadFactor) + 1.0F; int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY); // 把要创建的 HashMap 的容量存在 threshold 中if (t > threshold)threshold = tableSizeFor(t);} // 如果table初始化过,因为别的函数也会调用它,所以有可能HashMap已经被初始化过了。// 判断待插入的 map 的 size,若 size 大于 threshold,则先进行 resize(),进行扩容else if (s > threshold)resize(); //然后就开始遍历 带插入的 map ,将每一个 <Key ,Value> 插入到本HashMap实例。for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue(); // put(K,V)也是调用 putVal 函数进行元素的插入putVal(hash(key), key, value, false, evict);}}}介绍putVal方法前,说一下HashMap的几个重要的成员变量:
/*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*///实际存储key,value的数组,只不过key,value被封装成Node了transient Node<K,V>[] table; /*** The number of key-value mappings contained in this map.*/transient int size; /*** The number of times this HashMap has been structurally modified* Structural modifications are those that change the number of mappings in* the HashMap or otherwise modify its internal structure (e.g.,* rehash). This field is used to make iterators on Collection-views of* the HashMap fail-fast. (See ConcurrentModificationException).*/transient int modCount; /*** The next size value at which to resize (capacity * load factor).** @serial*/// (The javadoc description is true upon serialization.// Additionally, if the table array has not been allocated, this// field holds the initial array capacity, or zero signifying// DEFAULT_INITIAL_CAPACITY.)//因为 tableSizeFor(int) 返回值给了thresholdint threshold; /*** The load factor for the hash table.** @serial*/final float loadFactor;其实就是哈希表。HashMap使用链表法避免哈希冲突(相同hash值),当链表长度大于TREEIFY_THRESHOLD(默认为8)时,将链表转换为红黑树,当然小于UNTREEIFY_THRESHOLD(默认为6)时,又会转回链表以达到性能均衡。 我们看一张HashMap的数据结构(数组+链表+红黑树 )就更能理解table了:
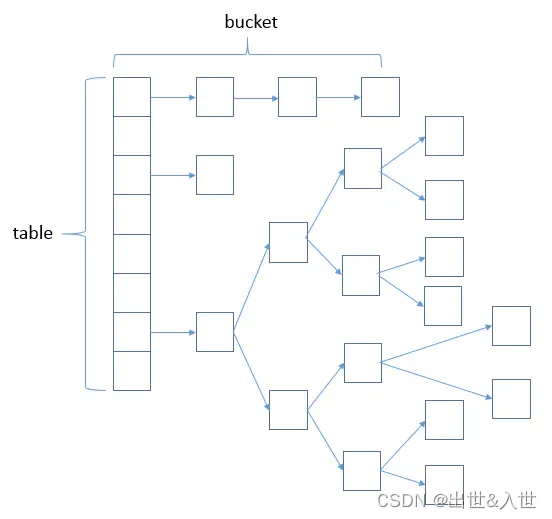
再回到putMapEntries函数中,如果table为null,那么这时就设置合适的threshold,如果不为空并且指定的map的size>threshold,那么就resize()。然后把指定的map的所有Key,Value,通过putVal添加到我们创建的新的map中。
putVal中传入了个hash(key),那我们就先来看看hash(key):
/*** key 的 hash值的计算是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16)* 主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候* 也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销*/static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}异或运算:(h = key.hashCode()) ^ (h >>> 16)
原 来 的 hashCode : 1111 1111 1111 1111 0100 1100 0000 1010
移位后的hashCode: 0000 0000 0000 0000 1111 1111 1111 1111
进行异或运算 结果:1111 1111 1111 1111 1011 0011 1111 0101
这样做的好处是,可以将hashcode高位和低位的值进行混合做异或运算,而且混合后,低位的信息中加入了高位的信息,这样高位的信息被变相的保留了下来。掺杂的元素多了,那么生成的hash值的随机性会增大。
刚才我们漏掉了resize()和putVal() 两个函数,现在我们按顺序分析一波:
首先resize() ,先看一下哪些函数调用了resize(),从而在整体上有个概念:
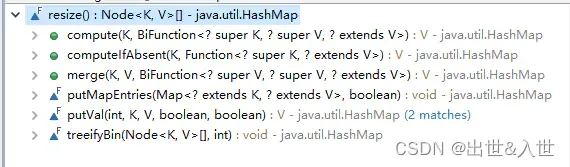
接下来上源码:
final Node<K,V>[] resize() { // 保存当前tableNode<K,V>[] oldTab = table; // 保存当前table的容量int oldCap = (oldTab == null) ? 0 : oldTab.length; // 保存当前阈值int oldThr = threshold; // 初始化新的table容量和阈值 int newCap, newThr = 0; /*1. resize()函数在size > threshold时被调用。oldCap大于 0 代表原来的 table 表非空,oldCap 为原表的大小,oldThr(threshold) 为 oldCap × load_factor*/if (oldCap > 0) { // 若旧table容量已超过最大容量,更新阈值为Integer.MAX_VALUE(最大整形值),这样以后就不会自动扩容了。if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE; return oldTab;} // 容量翻倍,使用左移,效率更高else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY) // 阈值翻倍newThr = oldThr << 1; // double threshold} /*2. resize()函数在table为空被调用。oldCap 小于等于 0 且 oldThr 大于0,代表用户创建了一个 HashMap,但是使用的构造函数为 HashMap(int initialCapacity, float loadFactor) 或 HashMap(int initialCapacity)或 HashMap(Map<? extends K, ? extends V> m),导致 oldTab 为 null,oldCap 为0, oldThr 为用户指定的 HashMap的初始容量。*/else if (oldThr > 0) // initial capacity was placed in threshold//当table没初始化时,threshold持有初始容量。还记得threshold = tableSizeFor(t)么;newCap = oldThr; /*3. resize()函数在table为空被调用。oldCap 小于等于 0 且 oldThr 等于0,用户调用 HashMap()构造函数创建的 HashMap,所有值均采用默认值,oldTab(Table)表为空,oldCap为0,oldThr等于0,*/else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);} // 新阈值为0if (newThr == 0) { float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) // 初始化tableNode<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab; if (oldTab != null) { // 把 oldTab 中的节点 reHash 到 newTab 中去for (int j = 0; j < oldCap; ++j) {Node<K,V> e; if ((e = oldTab[j]) != null) {oldTab[j] = null; // 若节点是单个节点,直接在 newTab 中进行重定位if (e.next == null)newTab[e.hash & (newCap - 1)] = e; // 若节点是 TreeNode 节点,要进行 红黑树的 rehash 操作else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 若是链表,进行链表的 rehash 操作else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next; // 将同一桶中的元素根据(e.hash & oldCap)是否为0进行分割(代码后有图解,可以回过头再来看),分成两个不同的链表,完成rehashdo {next = e.next; // 根据算法 e.hash & oldCap 判断节点位置rehash 后是否发生改变//最高位==0,这是索引不变的链表。if ((e.hash & oldCap) == 0) { if (loTail == null)loHead = e; elseloTail.next = e;loTail = e;} //最高位==1 (这是索引发生改变的链表)else { if (hiTail == null)hiHead = e; elsehiTail.next = e;hiTail = e;}} while ((e = next) != null); if (loTail != null) { // 原bucket位置的尾指针不为空(即还有node) loTail.next = null; // 链表最后得有个nullnewTab[j] = loHead; // 链表头指针放在新桶的相同下标(j)处} if (hiTail != null) {hiTail.next = null; // rehash 后节点新的位置一定为原来基础上加上 oldCap,具体解释看下图newTab[j + oldCap] = hiHead;}}}}} return newTab;}
}引自美团点评技术博客。我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
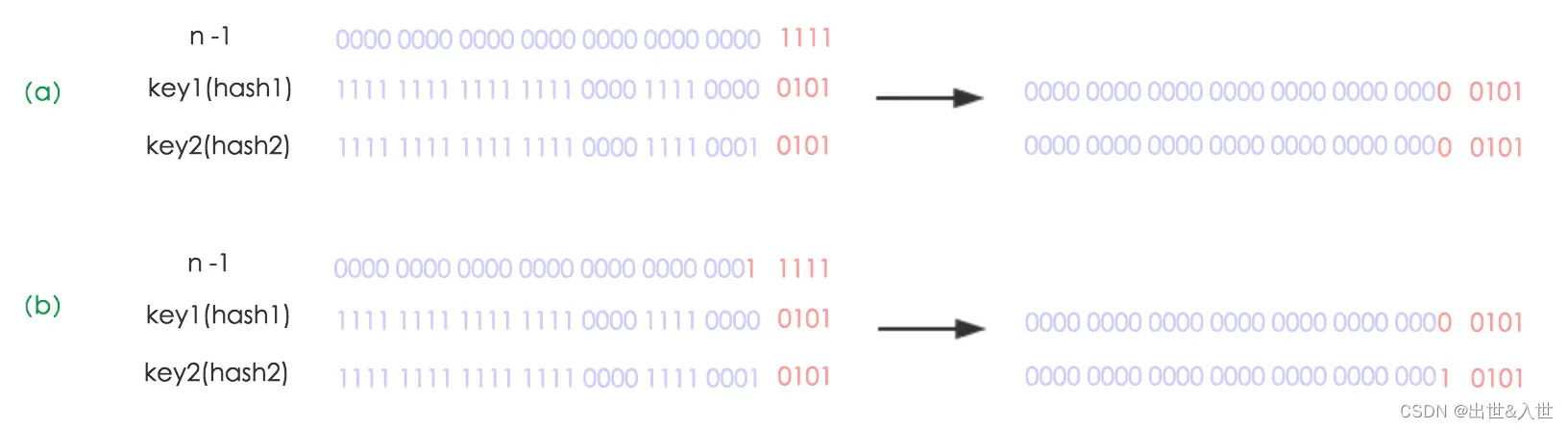
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
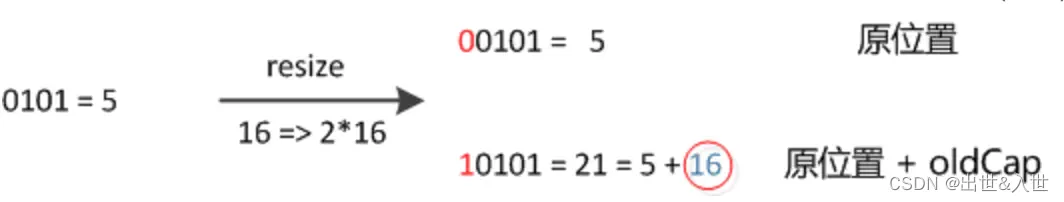
因此,我们在扩充HashMap的时候,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图 :
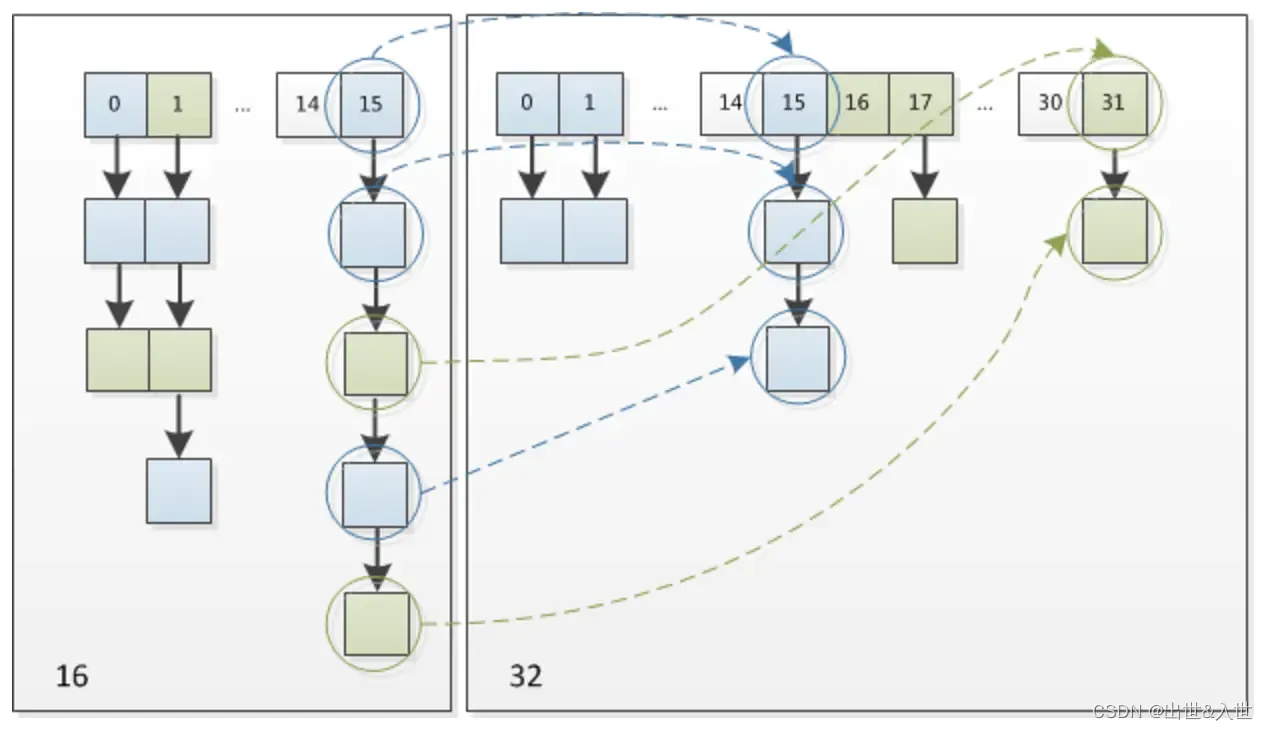
什么时候扩容:通过HashMap源码可以看到是在put操作时,即向容器中添加元素时,判断当前容器中元素的个数是否达到阈值(当前数组长度乘以加载因子的值)的时候,就要自动扩容了。
扩容(resize):其实就是重新计算容量;而这个扩容是计算出所需容器的大小之后重新定义一个新的容器,将原来容器中的元素放入其中。
resize()告一段落,接下来看 putVal() 。
上源码:
//实现put和相关方法。final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i; //如果table为空或者长度为0,则resize()if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length; //确定插入table的位置,算法是(n - 1) & hash,在n为2的幂时,相当于取摸操作。找到key值对应的槽并且是第一个,直接加入if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null); //在table的i位置发生碰撞,有两种情况,1、key值是一样的,替换value值,//2、key值不一样的有两种处理方式:2.1、存储在i位置的链表;2.2、存储在红黑树中else {Node<K,V> e; K k; //第一个node的hash值即为要加入元素的hashif (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p; //2.2else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //2.1else { //不是TreeNode,即为链表,遍历链表for (int binCount = 0; ; ++binCount) { ///链表的尾端也没有找到key值相同的节点,则生成一个新的Node,//并且判断链表的节点个数是不是到达转换成红黑树的上界达到,则转换成红黑树。if ((e = p.next) == null) { // 创建链表节点并插入尾部p.next = newNode(hash, key, value, null); 超过了链表的设置长度8就转换成红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash); break;} if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) break;p = e;}} //如果e不为空就替换旧的oldValue值if (e != null) { // existing mapping for keyV oldValue = e.value; if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e); return oldValue;}}++modCount; if (++size > threshold)resize();afterNodeInsertion(evict); return null;}注:hash 冲突发生的几种情况:
1.两节点key 值相同(hash值一定相同),导致冲突;
2.两节点key 值不同,由于 hash 函数的局限性导致hash 值相同,冲突;
3.两节点key 值不同,hash 值不同,但 hash 值对数组长度取模后相同,冲突;
相比put方法,get方法就比较简单,这里就不说了。
1.7和1.8的HashMap的不同点
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法就是能够提高插入的效率,但是也会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(2)扩容后数据存储位置的计算方式也不一样:
-
在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1) 。
-
而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
(3)JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(N)变成O(logN)提高了效率)。
HashMap为什么是线程不安全的?
HashMap 在并发时可能出现的问题主要是两方面:
-
put的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。 -
resize而引起死循环
这种情况发生在HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。
HashMap和HashTable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
-
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
-
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
-
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
-
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
-
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
需要注意的重要术语:
-
sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
-
Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
-
结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
相关文章:
一篇文章带你读懂HashMap
HashMap是面试中经常问到的一个知识点,也是判断一个候选人基础是否扎实的标准之一。可见HashMap的掌握是多重要。 一、HashMap源码分析 1、构造函数 让我们先从构造函数说起,HashMap有四个构造方法,别慌 1.1 HashMap() // 1.无参构造方法、// 构造一…...

Java如何进行优雅的判空——Optional类的灵活应用
0 引言 在Java Web项目开发中,经常令人头疼的NPE问题(NullPointerException)——空指针,例如我们在调用equal()方法时,就经常会出现NPE问题: String str null; str.equals("fsfs");…...

Fluent Python 笔记 第 12 章 继承的优缺点
重点是说明对 Python 而言尤为重要的两个细节: 子类化内置类型的缺点多重继承和方法解析顺序 12.1 子类化内置类型很麻烦 内置类型(使用 C 语言编写)不会调用用户定义的类覆盖的特殊方法。 不要子类化内置类型,用户自己定义的类应 该继承 collections 模块(http…...

Go语言读取解析yml文件,快速转换yml到go struct
YAML (YAML Aint a Markup Language)是一种标记语言,通常以.yml为后缀的文件,是一种直观的能够被计算机程序识别的数据序列化格式,并且容易被人类阅读,容易和脚本语言交互的,可以被支持YAML库的不同的编程语言程序导入…...
)
第二十六章 java并发常见知识内容(ThreadLocal 详解)
JAVA重要知识点带着疑问看ThreadLocalGC 之后 key 是否为 null?ThreadLocalMap Hash 算法ThreadLocalMap Hash 冲突ThreadLocalMap.set()方法ThreadLocalMap过期 key 的探测式清理流程ThreadLocalMap扩容机制ThreadLocalMap.get()详解ThreadLocalMap过期 key 的启发…...

人类的第一语言是什么
其实机器智能始终存在一个争议 没有人类的肢体和感受器无法理解和感同身受 这不用想是自然,但是可以通过虚拟数据进行模拟,深度学习便是 深度学习是模拟简单输入输出的最好选择,但不是开放性的学习 没有智能交互的智能永远不是智能 就像狼孩一…...

jsp(全部知识点)
👌 棒棒有言:也许我一直照着别人的方向飞,可是这次,我想要用我的方式飞翔一次!人生,既要淡,又要有味。凡事不必太在意,一切随缘,缘深多聚聚,缘浅随它去。凡事…...

测试开发面试基础题
1.对测试开发的理解 测试开发首先离不开测试,而软件测试是指,在规定的条件下对程序进行操作,以发现程序错误,衡量软件质量,并对其是否能满足设计要求进行评估的过程。 而且,现在不仅仅是通过手工测试来发…...
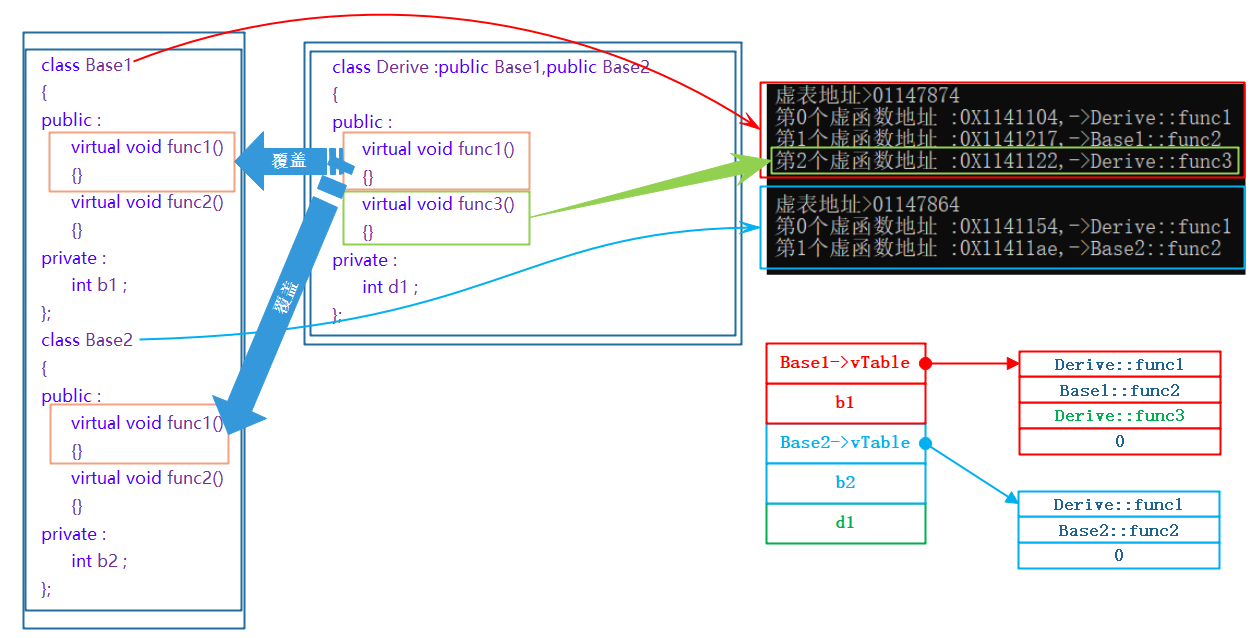
C++——多态|虚函数|重写|虚表
文章目录1. 多态的概念1.1 概念2. 多态的定义及实现2.1多态的构成条件2.2 虚函数2.3虚函数的重写虚函数重写的三个例外:2.4 普通调用和多态调用:2.5 C11 override 和 final2.6 重载、虚函数的覆盖(重写)、隐藏(重定义)的对比3. 抽象类(有关纯虚函数)3.1 …...

IPV4地址详解
文章目录IPV4地址分类编址划分子网无分类编制CIDR路由聚合应用规划(子网划分的细节)定长的子网掩码FLSM变长的子网掩码VLSMIPV4地址 IPV4地址就是给因特网(Internet)上的每一台主机(或路由器)的每一个接口…...
(一)初识Streamlit(附安装)
本入门指南介绍Streamlit的工作原理、如何在您首选的操作系统上安装Streamlit,以及如何创建第一个Streamlit应用程序! 1 安装 1.1 先决条件 Python 3.7 – Python 3.11 **注:我这里使用的是anaconda的虚拟环境,用pycharm编写代…...
| 刷完获取OD招聘渠道)
【新】华为OD机试 - 斗地主 2(Python)| 刷完获取OD招聘渠道
斗地主 2 题目描述 在斗地主扑克牌游戏中,扑克牌由小到大的顺序为3 4 5 6 7 8 9 10 J Q K A 2 玩家可以出的扑克牌阵型有,单张,对子,顺子,飞机,炸弹等 其中顺子的出牌规则为,由至少 5 张由小到大连续递增的扑克牌组成 且不能包含2 例如:{3,4,5,6,7}、{3,4,5,6,7,8,9,1…...
秒杀项目之消息推送
目录一、创建消费者二、创建订单链路配置2.1 定义RabbitMQ配置类2.2 创建RabbitmqOrderConfig配置类三、如何实现RabbitMQ重复投递机制3.1 开启发送者消息确认模式3.2 消费发送确认3.2.1 创建ConfirmCallBack确认模式3.2.2 创建ReturnCallBack退回模式3.3 创建生产者3.4 创建消…...
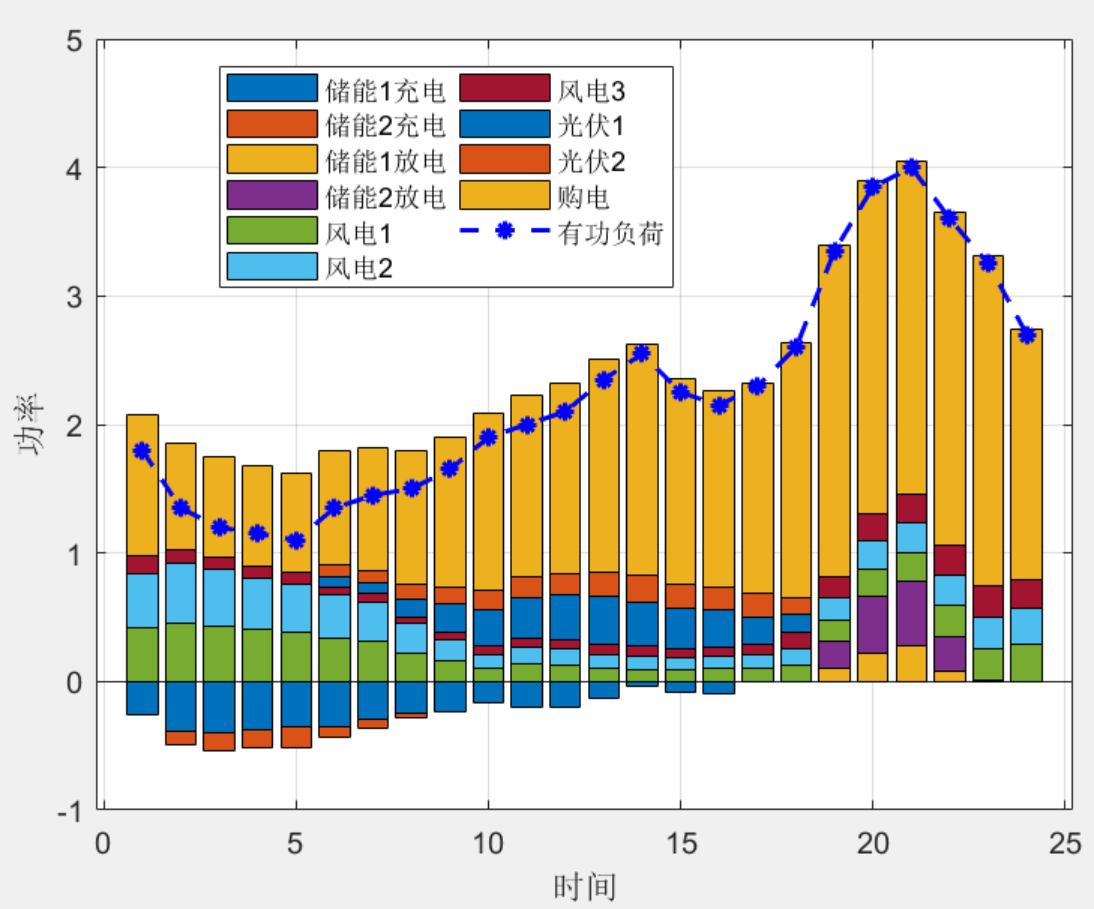
【重磅】IEEE33配电网两阶段鲁棒优化调度CCG
目录 1 前言 2基本内容 2.1 配网两阶段鲁棒模型 2.2 求解步骤 3部分程序 4程序结果 5程序链接 1 前言 鲁棒优化是电力系统研究的热点,而两阶段鲁棒和分布鲁棒研究就成为各类期刊(sci/ei/核心)的宠儿,最简单的思路是通过改…...

GPT2代码拆解+生成实例
本文代码来自博客,GPT2模型解析参考 import torch import copy import torch.nn as nn import torch.nn.functional as F from torch.nn.modules import ModuleList from torch.nn.modules.normalization import LayerNorm import numpy as np import os from tqd…...

基于android的即时通讯APP 聊天APP
基于android的即时通讯APP 或者 聊天APP 一 项目概述 该项目是基于Android 的聊天APP系统,该APP包含前台,后台管理系统,前台包含用户通讯录,用户详情,用户聊天服务,用户二维码,发现功能,发现详情 , 个人中心, 个人信…...

【C++】二叉树之力扣经典题目1——详解二叉树的递归遍历,二叉树的层次遍历
如有错误,欢迎指正。 如有不理解的地方,可以私信问我。 文章目录题目1:根据二叉树创建字符串题目实例思路与解析代码实现题目2:二叉树的层序遍历题目思路与解析代码实现题目1:根据二叉树创建字符串 点击进入题目链接—…...
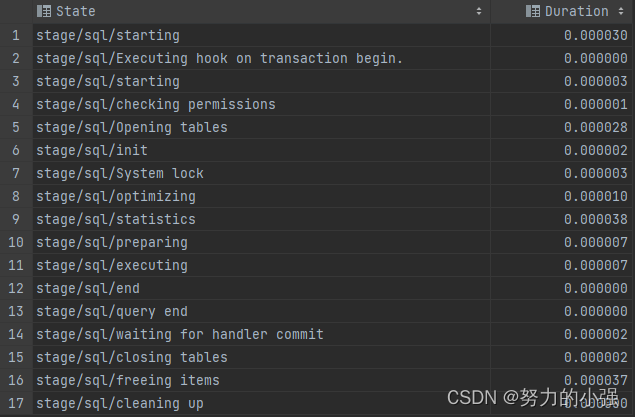
MySQL数据库调优————SQL性能分析
TIPS 本文基于MySQL 8.0 本文探讨如何深入SQL内部,去分析其性能,包括了三种方式: SHOW PROFILEINFORMATION_SCHEMA.PROFILINGPERFORMANCE_SCHEMA SHOW PROFILE SHOW PROFILE是MySQL的一个性能分析命令,可以跟踪SQL各种资源消耗。…...
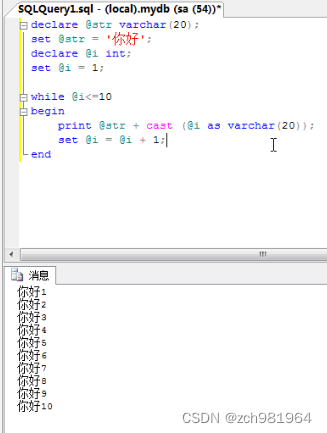
sql数据库高级编程总结(一)
1、数学函数:操作一个数据,返回一个结果 (1)取上限 ceiling 如果有一个小数就取大于它的一个最小整数 列如9.5 就会取到 10 select code,name,ceiling(price) from car (2)取下限 floor 如果有一个小数就…...

软件工程(5)--喷泉模型
前言 这是基于我所学习的软件工程课程总结的第五篇文章。 迭代是软件开发过程中普遍存在的一种内在属性。经验表明,软件过程各个阶段之间的迭代或一个阶段内各个工作步骤之间的迭代,在面向对象范型中比在结构化范型中更常见。 一般说来,使用…...

AIGC内容创作:结合Qwen3-ASR-0.6B实现视频音频自动生成字幕
AIGC内容创作:结合Qwen3-ASR-0.6B实现视频音频自动生成字幕 做视频最头疼的是什么?对我来说,不是拍摄,不是剪辑,而是加字幕。一小时的访谈视频,手动听打、校对、对齐时间轴,三四个小时就没了。…...

OpenClaw语音交互方案:Qwen3.5-9B对接Whisper实现语音指令控制
OpenClaw语音交互方案:Qwen3.5-9B对接Whisper实现语音指令控制 1. 为什么需要语音交互能力? 上周我在整理电脑文件时突然想到:既然OpenClaw能模拟人类操作电脑,为什么不给它加上耳朵呢?这个想法源于我经常双手沾满咖…...

Qwen3.5-9B-AWQ-4bit开源可部署:支持Docker Compose扩展的多模型共存方案
Qwen3.5-9B-AWQ-4bit开源可部署:支持Docker Compose扩展的多模型共存方案 1. 平台介绍 Qwen3.5-9B-AWQ-4bit是一个支持图像理解的多模态模型,能够结合上传图片与文字提示词,输出中文分析结果。这个开源模型特别适合处理以下任务:…...

PyTorch 2.6 镜像使用教程:开箱即用,快速开启你的AI之旅
PyTorch 2.6 镜像使用教程:开箱即用,快速开启你的AI之旅 1. 为什么选择PyTorch 2.6镜像 PyTorch作为当前最流行的深度学习框架之一,其2.6版本带来了多项性能优化和新特性。但对于初学者来说,环境配置往往是最头疼的问题——CUDA…...

Claude Code智能体与CasRel模型协作:自动化数据标注流水线
Claude Code智能体与CasRel模型协作:自动化数据标注流水线 1. 引言 做关系抽取项目,最头疼的是什么?十有八九的工程师会告诉你:是数据标注。传统的人工标注,不仅耗时费力,成本高昂,而且面对复…...

FoundationPress Webpack模块打包:深入理解现代WordPress主题JavaScript架构
FoundationPress Webpack模块打包:深入理解现代WordPress主题JavaScript架构 【免费下载链接】FoundationPress olefredrik/FoundationPress: 一个基于 WordPress 的主题框架,基于 Foundation 框架构建。适合用于开发 WordPress 主题,可以使用…...

Qwen3-Reranker-0.6B效果实测:轻量级模型重排序能力展示
Qwen3-Reranker-0.6B效果实测:轻量级模型重排序能力展示 1. 引言:为什么需要重排序模型? 在信息检索和问答系统中,我们经常会遇到这样的场景:用户输入一个问题,系统返回多个相关文档。但如何判断哪些文档…...

gte-base-zh开发者实操手册:launch_model_server.py脚本深度解析
gte-base-zh开发者实操手册:launch_model_server.py脚本深度解析 如果你正在寻找一个强大的中文文本嵌入模型,并且希望快速部署一个可用的服务,那么gte-base-zh结合Xinference的方案,绝对值得你花时间研究。今天,我们…...

OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性
OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性 1. 为什么需要AI辅助代码测试? 作为长期与Python打交道的开发者,我经常面临一个经典困境:在快速迭代功能时,测试用例的编写往往成为瓶颈。传统方案要…...

10点滑动平均滤波器:嵌入式零依赖高效实现
1. 项目概述MovingAverageFilter 是一个轻量级、零依赖的嵌入式数字滤波器实现,专为资源受限的微控制器环境设计。其核心功能是执行固定长度(10点)的滑动平均(Moving Average)运算,并在每次新采样输入后立即…...