Pulsar
一、简介
Apache Pulsar是Apache软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案。
二、架构介绍
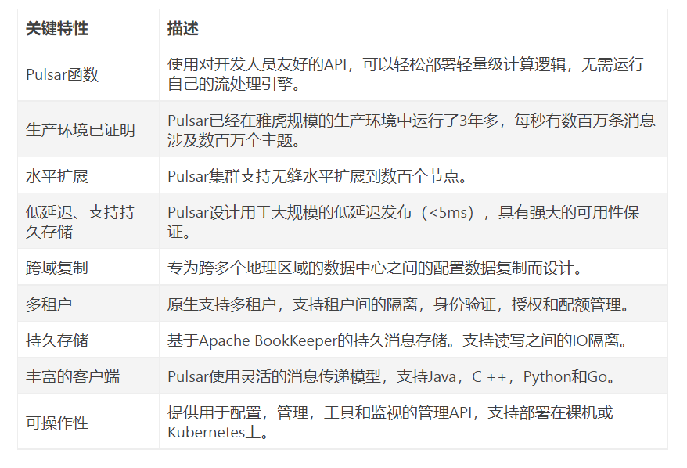
Pulsar由Producer、Consumer、多个Broker、一个BookKeeper集群、一个Zookeeper集群构成

Producer:数据生成者,即发送消息的一方。生产者负责创建消息,将其投递到Pulsar中。
Consumer:数据消费者,即接收消息的一方。消费者连接到 Pulsar 并接收消息,进行相应的业务处理。
Broker:无状态的服务层,负责接收消息、传递消息、集群负载均衡等操作,Broker不会持久化保存元数据。
BookKeeper:有状态的持久层,包含多个Bookie,负责持久化地存储消息。
ZooKeeper:存储Pulsar、BookKeeper的元数据,集群配置等信息,负责集群间的协调(例如:Topic与Broker的关系)、服务发现等。
Broker扩展
在Pulsar中Broker是无状态的,当需要支持更多的消费者或生产者时,可以简单地添加更多的Broker节点来满足业务需求。Pulsar支持自动的分区负载均衡,在Broker节点的资源使用率达到阈值时,会将负载迁移到负载较低的Broker节点,这个过程中分区也将在多个Broker节点中做平衡迁移,一些分区的所有权会转移到新的Broker节点。
Bookie扩展
存储层的扩容,通过增加Bookie节点来实现。在BooKie扩容的阶段,由于分片机制,整个过程不会涉及到不必要的数据搬迁,即不需要将旧数据从现有存储节点重新复制到新存储节点。
Topic
分区Topic(Topic-Partition)
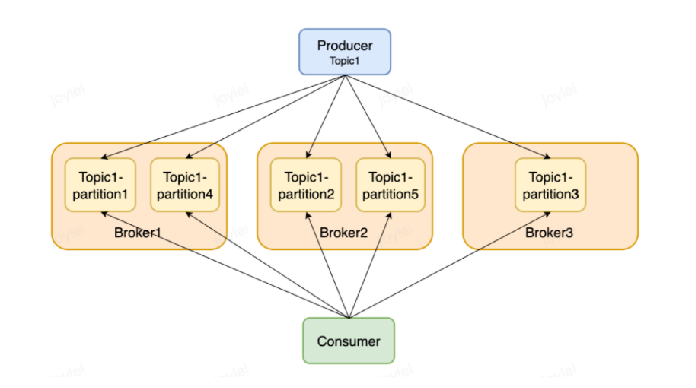
Pulsar的Topic可以分为非分区Topic和分区Topic。普通的Topic仅仅被保存在单个Broker中,这限制了Topic的最大吞吐量。分区Topic是一种特殊类型的主题,支持被多个Broker处理,从而实现更高的吞吐量。
持久Topic、非持久Topic
默认情况下,Pulsar会保存所有没确认的消息到BookKeeper中。持久Topic的消息在Broker重启或者Consumer出现问题时保存下来。
除了持久Topic,Pulsar也支持非持久Topic。这些Topic的消息只存在于内存中,不会存储到磁盘。
因为Broker不会对消息进行持久化存储,当Producer将消息发送到Broker时,Broker可以立即将ack返回给Producer,所以非持久Topic的消息传递会比持久Topic的消息传递更快一些。相对的,当Broker因为一些原因宕机、重启后,非持久Topic的消息都会消失,订阅者将无法收到这些消息
重试Topic
由于业务逻辑处理出现异常,消息一般需要被重新消费。Pulsar支持生产者同时将消息发送到普通的Topic和重试Topic,并指定允许延时和最大重试次数。当配置了允许消费者自动重试时,如果消息没有被消费成功,会被保存到重试Topic中,并在指定延时时间后,重新被消费。
死信Topic
当Consumer消费消息出错时,可以通过配置重试Topic对消息进行重试,但是,如果当消息超过了最大的重试次数仍处理失败时,该怎么办呢?Pulsar提供了死信Topic,通过配置deadLetterTopic,当消息达到最大重试次数的时候,Pulsar会将消息推送到死信Topic中进行保存。
订阅(subscription)
订阅类型(Subscription type)
Pulsar支持独占(Exclusive)、灾备(Failover)、共享(Shared)、Key_Shared这四种订阅类型。
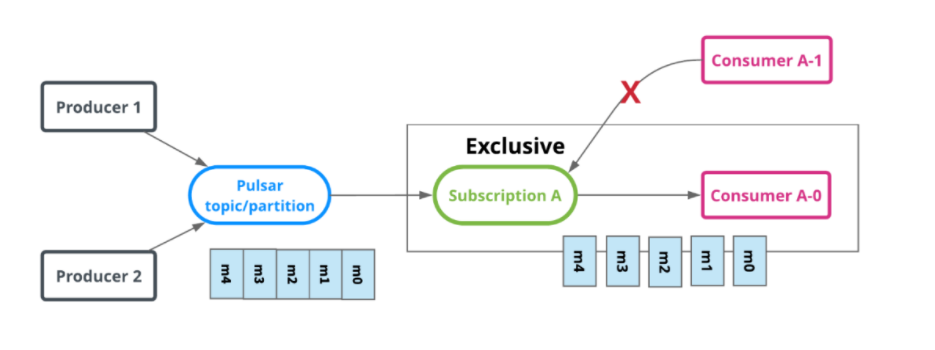
独占(Exclusive)SinglePartition
Exclusive下,只允许Subscription存在一个消费者,如果多个消费者使用同一个订阅名称去订阅同一个Topic,则会报错。如下图,只有Consumer A-0可以消费数据。
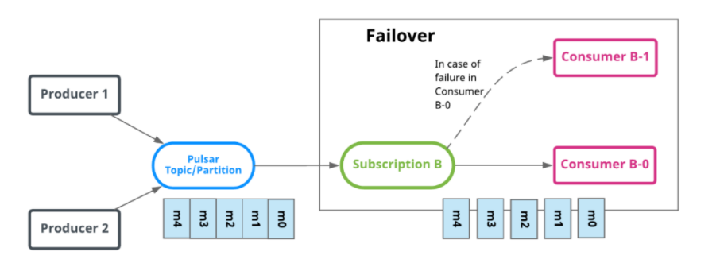
灾备(Failover)
Failover下,一个Subscription中可以有多个消费者,但只有Master Consumer可以消费数据。当Master Consumer断开连接时,消息会由下一个被选中的Consumer进行消费。
分区Topic:Broker会按照消费者的优先级和消费名的顺序对消费者进行排序,将Topic均匀地分配给优先级最高的消费者。
非分区Topic:Broker会根据消费者订阅的非分区Topic的时间顺序选择消费者。
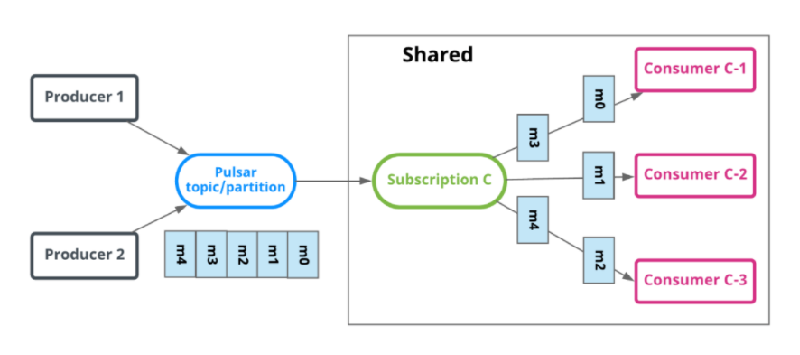
共享(Shared)
shared中,多个消费者可以绑定到同一个Subscription上。消息通过 round robin即轮询机制分发给不同的消费者,并且每个消息仅会被分发给一个消费者。当消费者断开连接,所有被发送给消费者但没有被确认的消息将被重新处理,分发给其它存活的消费者。
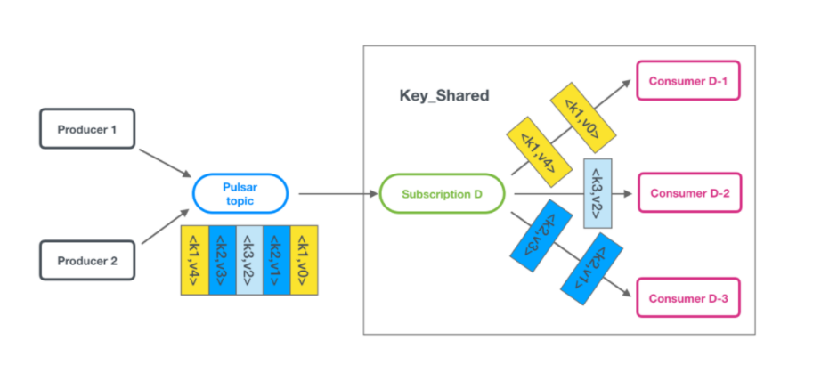
Key_Shared
Key_Shared中,多个Consumer可以绑定到同一个Subscription。消息在传递给Consumer时,具有相同键的消息只会传递给同一个Consumer。
订阅模式(Subscription modes)
订阅模式有持久化和非持久化两种。订阅模式取决于游标(cursor)的类型。
创建订阅时,将创建一个相关的游标来记录最后使用的位置。当订阅的consumer重新启动时,它可以从它所消费的最后一条消息继续消费。
Durable(持久订阅):游标是持久性的,会保留消息并保持游标记录的位置。当Broker重新启动时,可以从BookKeeper中恢复游标,消息可以从游标上次记录的位置继续消费。默认情况下,都是持久化订阅。
NonDurable(非持久订阅):游标不是持久性的,当Broker宕机时,游标会丢失并无法恢复,所以消息无法继续从上次消费的位置开始继续消费。
多主题订阅
当Consumer订阅Topic时,默认指定订阅一个主题。从Pulsar的1.23.0-incubating的版本开始,Pulsar消费者可以同时订阅多个Topic。可以通过两种方式进行订阅:
正则表达式,例如:
persistent://public/default/finance-.*
明确指定Topic列表。
Pulsar生产者(Producer)
访问模式
消息生成者有多种模式访问Topic ,可以使用以下几种方式将消息发送到Topic。
Shared:默认情况下,多个生成者可以将消息发送到同一个Topic。
Exclusive:在这种模式下,只有一个生产者可以将消息发送到Topic ,当其他生产者尝试发送消息到这个Topic时,会发生错误。只有独占Topic的生产者发生宕机时(Network Partition)该生产者会被驱逐,新的生产者才能产生并向Topic发送消息。
WaitForExclusive:在这种模式下,只有一个生产者可以将消息发送到Topic。当已有生成者和Topic建立连接时,其他生产者的创建会被挂起而不会产生错误。如果想要采用领导者选举机制来选择消费者的话,可以采用这种模式。
2.路由模式
当将消息发送到分区Topic时,需要指定消息的路由模式,这决定了消息将会被发送到哪个分区Topic。Pulsar有以下三种消息路由模式,RoundRobinPartition为默认路由模式。
RoundRobinPartition:如果消息没有指定key,为了达到最大吞吐量,生产者会以round-robin (轮询)方式将消息发布到所有分区。请注意round-robin并不是作用于每条单独的消息,而是作用于延迟处理的批次边界,以确保批处理有效。如果消息指定了key,分区生产者会根据key的hash值将该消息分配到对应的分区。这是默认的模式。
SinglePartition:如果消息没有指定key,生产者将会随机选择一个分区,并发布所有消息到这个分区。如果消息指定了key,分区生产者会根据key的hash值将该消息分配到对应的分区。
CustomPartition:自定义模式,用户可以创建自定义路由模式,通过实现MessageRouter接口实现自定义路由规则。
批量处理
Pulsar支持对消息进行批量处理。批量处理启用后,Producer会在一次请求中累积并发送一批消息。批量处理时的消息数量取决于最大消息数(单次批量处理请求可以发送的最大消息数)和最大发布延迟(单个请求的最大发布延迟时间)决定。
索引确认机制
启用批量索引确认机制,Consumer将筛选出已被确认的批量索引,并将批量索引确认请求发送给Broker。Broker维护批量索引的确认状态并跟踪每批索引的确认状态,以避免向Consumer发送已确认的消息。当该批信息的所有索引都被确认后,该批信息将被删除。
key-based batching
key_shared模式下,Broker会根据消息的key来分发消息,但默认的批量处理模式,无法保证将所有的相同的key都打包到同一批中,而且Consumer在接收到批数据时,会默认把第一个消息的key当作这批消息的key,这会导致消息的错乱。因此key_shared模式下,不支持默认的批量处理。
key-based batching能够确保Producer在打包消息时,将相同key的消息打包到同一批中,从而consumer在消费的时候,也能够消费到指定key的批数据。
没有指定key的消息在打包成批后,这一批数据也是没有key的,Broker在分发这批消息时,会使用NON_KEY作为这批消息的key。
Pulsar消费者(Consumer)
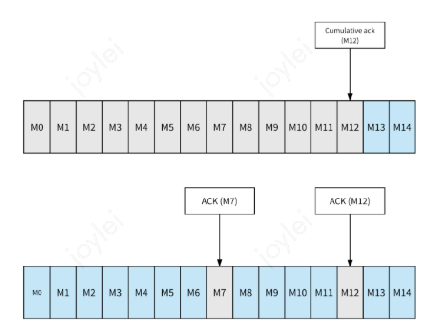
Pulsar提供两种确认模式:
累积确认:消费者只需要确认最后一条收到的消息,在此之前的消息,都不会被再次发送给消费者。
单条确认:消费者需要确认每条消息并发送ack给Broker。
AcknowledgmentsGroupingTracker
消息的单条确认和累积确认并不是直接发送确认请求给Broker,而是把请求转交给AcknowledgmentsGroupingTracker处理。
为了保证消息确认的性能,并避免Broker接收到非常高并发的ack请求,Tracker默认支持批量确认,即使是单条消息的确认,也会先进入队列,然后再一批发往Broker。在创建consumer的时候,可以设置acknowledgementGroupTimeMicros,默认情况下,每100ms或者堆积超过1000时,AcknowledgmentsGroupingTracker会发送一批确认请求。如果设置为0,则每次确认消息后,Consumer都会立即发送确认请求。
Pulsar服务端
Broker是Pulsar的一个无状态组件,主要负责运行以下两个组件:
http服务:提供为生产者和消费者管理任务和Topic查找的REST API。Producer通过连接到Broker来发送消息,Consumer通过连接到Broker来接收消息。
调度器:提供异步http服务,用于二进制数据的传输。
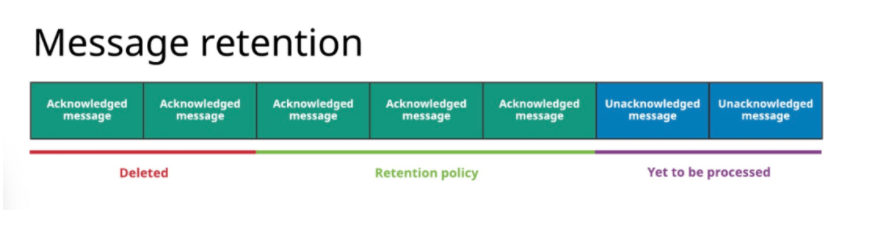
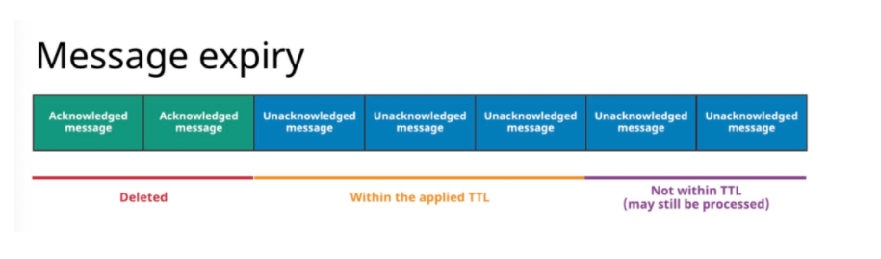
Pulsar Broker会默认删除已经被所有Consumer确认的消息,并以backlog的方式持久化存储所有未被确认的内消息。Pulsar的message retention(消息留存) 和message expiry (消息过期)这两个特性可以调整Broker的默认设置。
Message retention: 保留Consumer已确认的消息。
通过留存规则的设定,可以保证已经被确认且符合留存规则的消息持久地保存在Pulsar中,而没有被留存规则覆盖、已经被确认的消息会被删除。
Message expire(消息过期):设置未确认消息的存活时长(TTL)。
通过设置消息的TTL,有些即使还没有被确认,但已经超过TTL的消息,也会被删除
消息去重
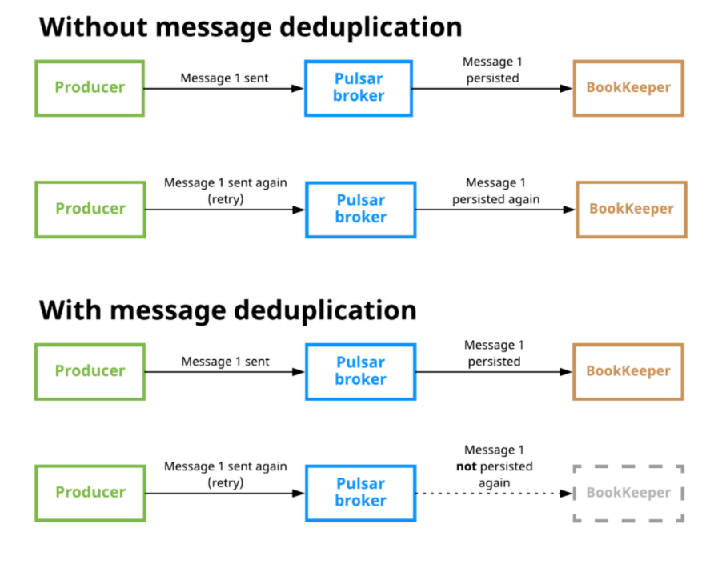
实现消息去重的一种方式是确保消息仅生成一次,即生产者幂等。这种方式的缺点是把消息去重的工作交由应用去做。
在Pulsar中,Broker支持配置开启消息去重,用户不需要为了消息去重去调整Producer的代码。启用消息去重后,即使一条消息被多次发送到Topic上,这条消息也只会被持久化到磁盘一次。
去重原理
Producer对每一个发送的消息,都会采用递增的方式生成一个唯一的sequenceID,这个消息会放在message的元数据中传递给Broker。同时,Broker也会维护一个PendingMessage队列,当Broker返回发送成功ack后,Producer会将PendingMessage队列中的对于的sequence id删除,表示Producer任务这个消息生产成功。Broker会记录针对每个Producer接收到的最大Sequence ID和已经处理完的最大Sequence ID。
当Broker开启消息去重后,Broker会对每个消息请求进行是否去重的判断。收到的最新的Sequence ID是否大于Broker端记录的两个维度的最大Sequence ID,如果大于则不重复,如果小于或等于则消息重复。消息重复时,Broker端会直接返回ack,不会继续走后续的存储处理流程。
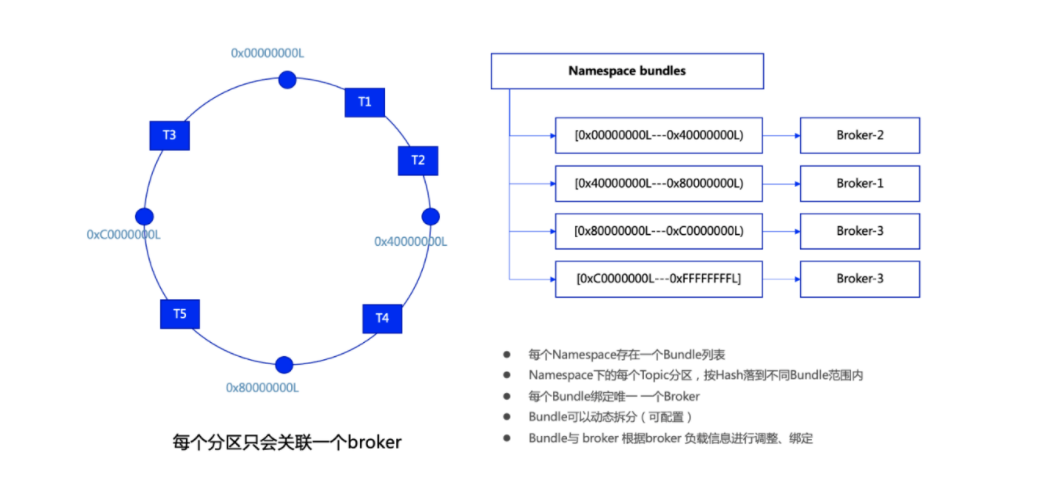
Bundle
Topic分区与Broker的关联是通过Bundle机制进行管理的。
每个namespace存在一个Bundle列表,在namesapce创建时可以指定Bundle的数量。Bundle其实是一个分片机制,每个Bundle拥有 namespace 整个hash范围的一部分。每个Topic (分区) 通过hash运算落到相应的Bundle区间,进而找到当前区间关联的Broker。每个Bundle绑定唯一的一个Broker,但一个Broker可以有多个Bundle。
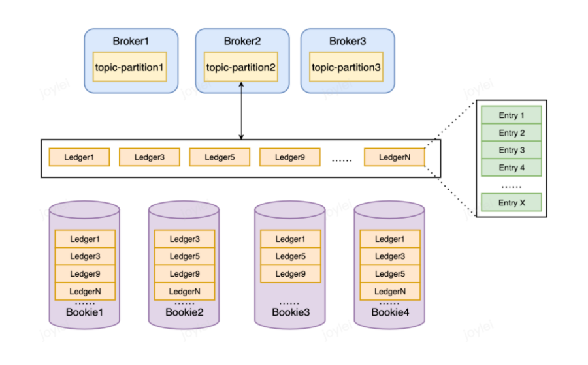
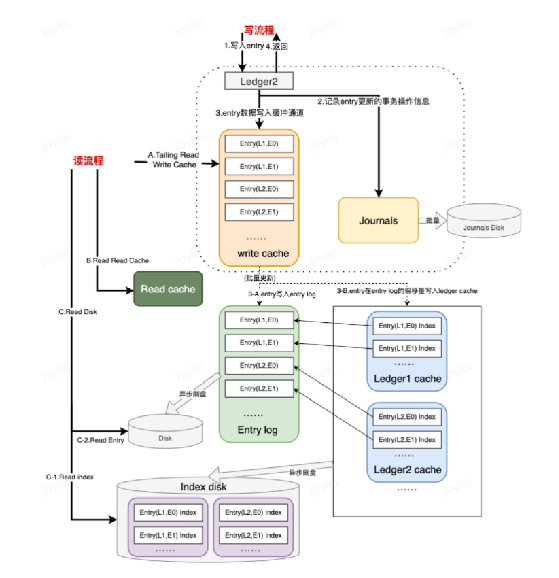
Pulsar存储层(Bookkeeper)
分片存储
概念:
Bookie:BookKeeper的一部分,处理需要持久化的数据。
Ledger:BookKeeper的存储逻辑单元,可用于追加写数据。
Entry:写入BookKeeper的数据实体。当批量生产时,Entry为多条消息,当非批量生产时,Entry为单条数据
相关文章:
Pulsar
一、简介Apache Pulsar是Apache软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、…...

项目介绍 + 定长内存池设计及实现
你好,我是安然无虞。 文章目录项目介绍当前项目做的是什么?技术栈内存池是什么?池化技术内存池内存池主要解决的问题malloc定长内存池学习目的定长内存池设计项目介绍 当前项目做的是什么? 这个项目是实现一个高并发的内存池, 它的原型是 Google 的一个开源项…...

Linux--线程安全的单例模式--自旋锁--0211
1. 线程安全的单例模式 1.1 什么是单例模式 某些类, 只应该具有一个对象(实例), 就称之为单例. 1.1.1 懒汉方式实现单例模式 以上篇博文的线程池为例 Liunx--线程池的实现--0208 09_Gosolo!的博客-CSDN博客 实现懒汉模式首先要先将构造函数私有化,…...
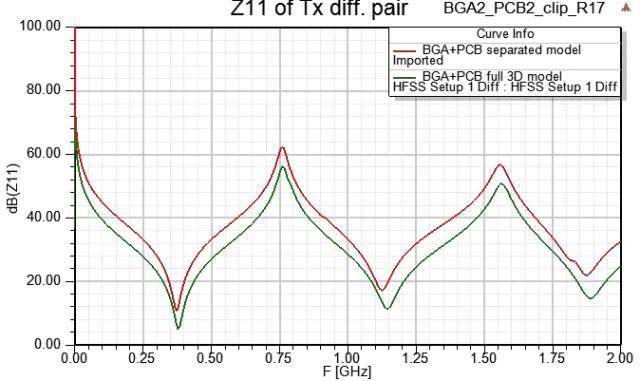
图文解说S参数(进阶篇)
S参数是RF工程师/SI工程师必须掌握的内容,业界已有多位大师写过关于S参数的文章,即便如此,在相关领域打滚多年的人, 可能还是会被一些问题困扰着。你懂S参数吗? 图文解说S参数(基础篇) 请继续往下看...台湾…...
Sentinel源码阅读
基础介绍 Sentinel 的使用可以分为两个部分: 核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持(见 主流框架适配&…...
2023年浙江食品安全管理员考试真题题库及答案
百分百题库提供食品安全管理员考试试题、食品安全管理员考试预测题、食品安全管理员考试真题、食品安全管理员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、判断题 7.(重点)《餐饮服务食品安全…...
Webstorm 代码没有提示,uniapp 标签报错
问题 项目是用脚手架创建的: vue create -p dcloudio/uni-preset-vue my-project 打开之后,添加view标签警告报错的。代码也没有提示,按官方说法:CLI 工程默认带了 uni-app 语法提示和 5App 语法提示。 但是我这里就是有问题。…...

MySQL-Innodb引擎事务原理
文章目录1.事务介绍2 事务特性3. 事务的实现原理4 redo log 保证持久性5 undo log 保证原子性6 MVCC 概念6.1 隐藏字段6.2 版本链6.3 ReadView6.3.1readview 版本控制规则7 隔离性 实现7.2 隔离性- REPEATABLE READ 可重复读下8 一致性1.事务介绍 事务是一组操作的集合…...

Linux操作系统学习(了解环境变量)
文章目录环境变量初识除了上述介绍的PATH,还有一些常见的环境变量如:查看环境变量方法 :环境变量的基本概念:本地变量:环境变量初识 环境变量解释起来比较抽象,先看示例: #include <stdio.…...
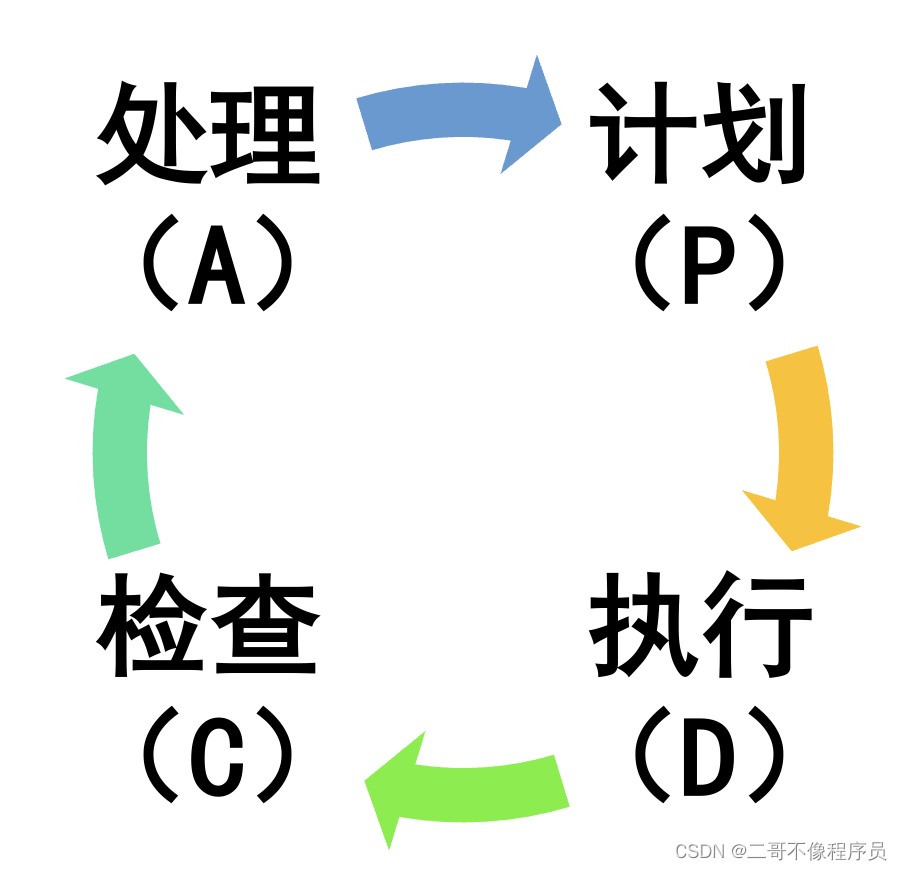
数据分析思维(六)|循环/闭环思维
循环/闭环思维 1、概念 在很多的分析场景下,我们需要按照一套流程反复分析,而不是进行一次性的分析,也就是说这套流程的结果会成为该流程的新一次输入,从而形成一个闭环,此时的分析思维我们称之为循环/闭环思维。 常…...

C++:类和对象(下)
文章目录1 再谈构造函数1.1 构造函数体赋值1.2 初始化列表1.3 explicit关键字2 static成员2.1 概念2.2 特性3 友元3.1 友元函数(流插入(<<)及流提取(>>)运算符重载)3.2 友元类4 内部类5 匿名对…...

ASP.NET Core MVC 项目 AOP之IResultFilter和IAsyncResultFilter
目录 一:说明 二:IActionFilter同步 三:IAsyncActionFilter异步 一:说明 IResultFilter同步过滤器与IAsyncResultFilter异步过滤器常常被用作于渲染视图或处理结果。 IResultFilter同步过滤器执行顺序: 1:执行控制器中的构造函数,实例化控制器 2:执行具体的Acti…...
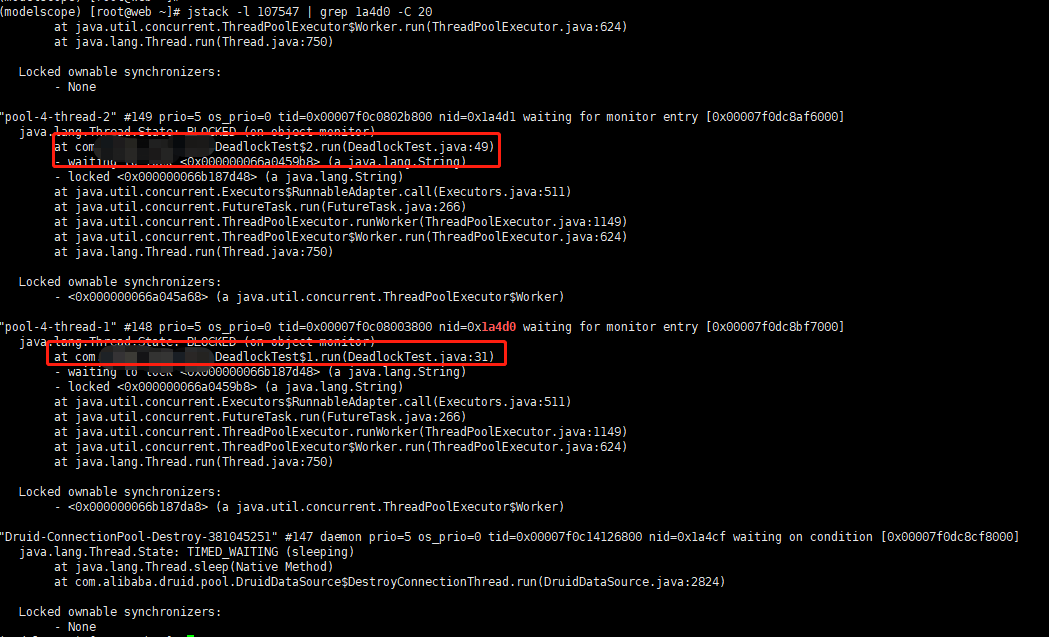
jstack排查cpu占用高[复习]
这样就可以看到占用CPU高的代码位置。 总结:就是先查到占用高的应用和具体的线程,然后根据线程到堆积信息查找即可。 不过堆栈信息非十进制,需提前把线程号转为十六进制。 这样就可以看到占用CPU高的代码位置。 总结:就是先查到…...
网络安全-Pyhton环境搭建
网络安全-Pyhton环境搭建 https://www.kali.org/get-kali/#kali-installer-images—kali官网下载地址 python这个东东呢 是目前来说最简单,方便的开源的脚本语言 广泛用于Web开发,AI,网站开发等领域 python要装2和3 为什么要安装两个版本…...

SpringBoot Mybatis 分页实战
pageInfo的属性 pageNum:当前页 pageSize:页面数据量 startRow:当前页首条数据为总数据的第几条 endRow:当前页最后一条数据为总数据的第几条 total:总数据量 pages:总页面数 listPage{}结果集 reasonable …...

计算机断层扫描结肠镜和全自动骨密度仪在一次检查中的可行性
计算机断层扫描结肠镜和全自动骨密度仪在一次检查中的可行性 Feasibility of Simultaneous Computed Tomographic Colonography and Fully Automated Bone Mineral Densitometry in a Single Examination 简单总结: 数据:患者的结肠镜检查和腹部CT检查…...
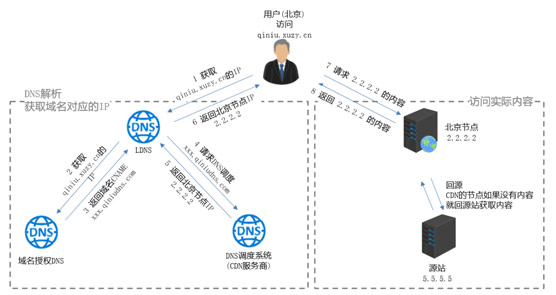
Java多级缓存是为了解决什么的?
前言 提到缓存,想必每一位软件工程师都不陌生,它是目前架构设计中提高性能最直接的方式。 缓存技术存在于应用场景的方方面面。从网站提高性能的角度分析,缓存可以放在浏览器,可以放在反向代理服务器,还可以放…...

MongoDB--》索引的了解及具体操作
目录 索引—index 索引的类型 索引的管理操作 索引的使用 索引—index 使用索引的原因:索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这…...
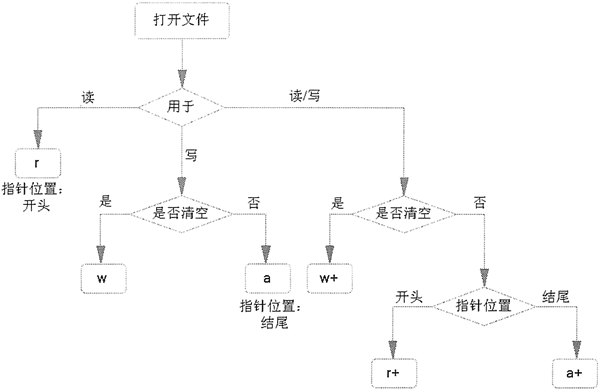
Python open()函数详解:打开指定文件
在 Python 中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:file ope…...

CentOS Stream 9尝鲜安装教程
作者:IT圈黎俊杰 一、下载CentOS Stream 9安装介质 在CentOS官网可以下载到CentOS Stream 9的安装介质,正面列出ISO介质的下载链接地址: https://download.cf.centos.org/9-stream/BaseOS/x86_64/iso/CentOS-Stream-9-20221019.0-x86_64-dv…...

空洞骑士模组管理终极指南:Scarab让你的游戏体验翻倍提升
空洞骑士模组管理终极指南:Scarab让你的游戏体验翻倍提升 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为《空洞骑士》模组安装的繁琐步骤而烦恼吗ÿ…...

Linux网络配置:为什么你的lo网卡IP总是127.0.0.1?深入解析环回接口工作原理
Linux网络配置:为什么你的lo网卡IP总是127.0.0.1?深入解析环回接口工作原理 作为Linux系统管理员或开发者,你一定无数次在终端输入ifconfig或ip addr命令,看到那个熟悉的lo接口和它的固定IP地址127.0.0.1。这个看似简单的配置背后…...

OpenVAS漏洞扫描实战:从安装到首次扫描的全流程指南
OpenVAS漏洞扫描实战:从零构建企业级安全检测环境 在数字化威胁日益复杂的今天,主动发现系统漏洞已成为安全防御的第一道防线。作为开源漏洞评估领域的标杆工具,OpenVAS以其全面的漏洞数据库和灵活的扫描策略,帮助安全从业者建立…...
Transformer推理加速实战:KV Cache与GQA在自回归生成中的优化技巧
Transformer推理加速实战:KV Cache与GQA在自回归生成中的优化技巧 当我们需要处理长文本生成任务时,Transformer模型的推理效率往往成为瓶颈。每次生成新token时重复计算所有历史token的注意力权重,这种计算方式在长序列场景下会带来显著的性…...
权重提示)
AI头像生成器提示词工程:Qwen3-32B生成含艺术家风格(e.g. Artgerm)权重提示
AI头像生成器提示词工程:Qwen3-32B生成含艺术家风格(e.g. Artgerm)权重提示 1. 引言:为什么你需要一个专业的头像生成器? 你有没有过这样的经历?想给自己换个头像,脑子里有模糊的想法…...

WarcraftHelper终极指南:5个技巧让魔兽争霸3在现代电脑上流畅运行
WarcraftHelper终极指南:5个技巧让魔兽争霸3在现代电脑上流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 如果你还在为魔兽争霸3在…...

STM32型号太多看花眼?手把手教你用官方选型手册5分钟锁定最适合你的芯片
STM32选型实战指南:5步精准匹配项目需求的芯片筛选法 面对ST官网提供的上百款STM32系列微控制器,许多工程师在选型时容易陷入"参数海洋"——GPIO数量、通信接口、主频、存储容量等数十项指标如何权衡?本文将分享一套经过实战验证的…...
:从手动测试到数学证明的范式跃迁)
C裸机代码可信性革命(NASA/ISO 26262 ASIL-D级验证实录):从手动测试到数学证明的范式跃迁
第一章:C裸机代码可信性革命的范式跃迁传统嵌入式系统开发长期依赖“调试即验证”的经验主义路径:寄存器直写、中断裸调、无内存保护的无限信任模型。当安全关键场景(如航天飞控、医疗设备固件)要求代码行为在任意输入、任意时序下…...
)
保姆级教程:在Ubuntu 22.04上为ARM板卡交叉编译hostapd 2.10(附openssl/libnl依赖处理)
深度实战:在Ubuntu 22.04上为ARM设备构建hostapd 2.10的完整指南 在嵌入式开发领域,为ARM架构设备交叉编译软件是开发者必须掌握的技能之一。当我们需要在树莓派、RK系列开发板等ARM设备上部署WiFi热点功能时,hostapd无疑是最可靠的选择。本…...

Puter云原生架构:从单体应用到微服务的转型之路
Puter云原生架构:从单体应用到微服务的转型之路 【免费下载链接】puter Puter 是一个先进、开源的互联网操作系统,旨在功能丰富、异常快速且高度可扩展,它可以用于构建远程桌面环境或作为云存储服务、远程服务器、Web托管平台等的接口。 项…...