【数据结构】顺序表和链表基本实现(含全代码)
文章目录
- 一、什么是线性表
- 1. 什么是顺序表
- 动态开辟空间和数组的问题解释
- LeetCode-exercise
- 2. 什么是链表
- 2.1链表的分类
- 2.2常用的链表结构及区别
- 2.3无头单向非循环链表的实现
- 2.4带头双向循环链表的实现
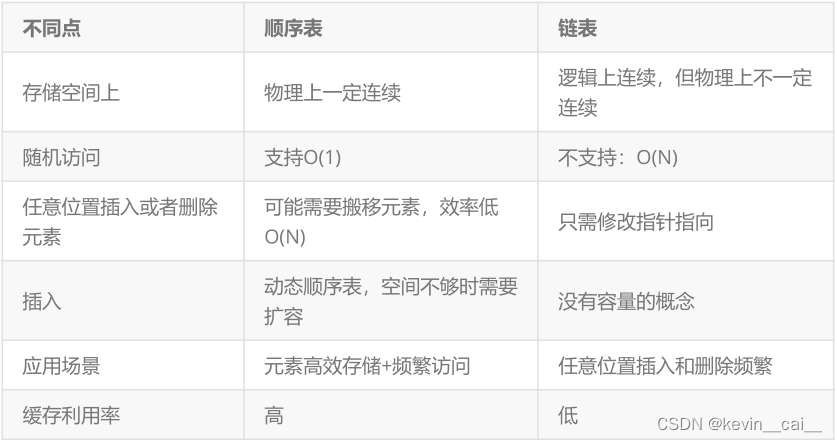
- 2.5循序表和链表的区别
- LeetCode-exercise
- 3. 快慢指针
- LeetCode-exercise
一、什么是线性表
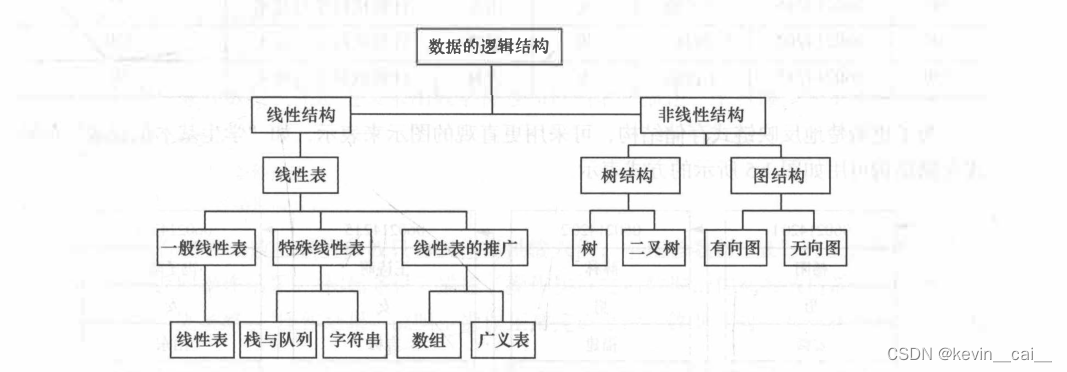
概念:线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…。线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
关于为什么物理结构上并不一定是连续的,可以看我的另外一篇文章【c语言】动态内存管理
1. 什么是顺序表
概念: 首先,顺序表是线性表其中之一;其次,顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表一般可以分为:
- 静态顺序表:使用定长数组存储元素。

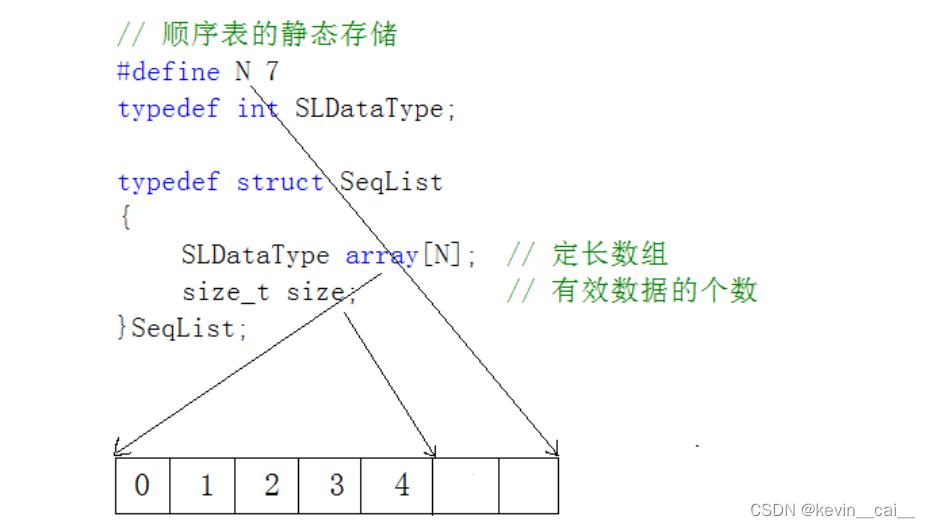
a.静态顺序表只适用于确定知道需要存多少数据的场景。静态顺序表的定长数组导致N定大了,空间开多了浪费,开少了不够用。所以现实中基本都是使用动态顺序表,根据需要动态的分配空间大小,所以下面我们实现动态顺序表。
b. 那我们在学习数据结构之前,肯定学习了C语言,C语言的题目大多是以IO的形式进行调试的,而我们学数据结构的题目大多是以接口的形式进行调试的。
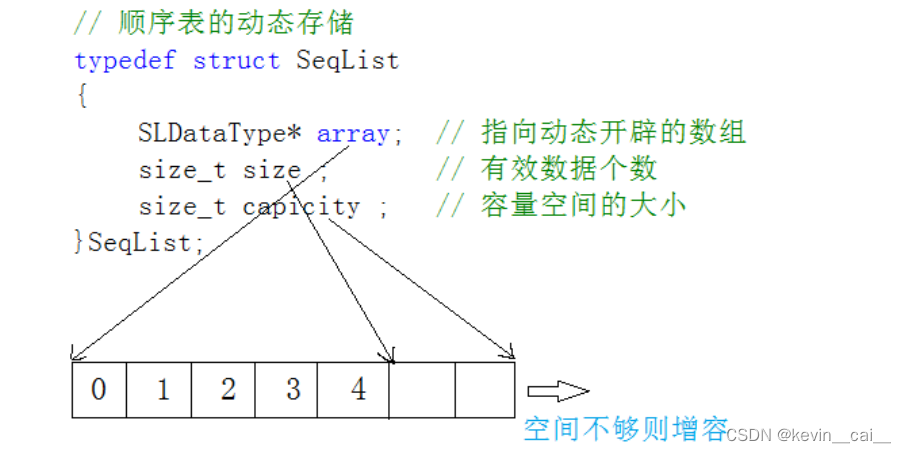
2. 动态顺序表:使用动态开辟的数组存储。
接口的实现:
#pragma once
// SeqList.h
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
// 顺序表的动态存储
typedef int SLDataType;
typedef struct SeqList
{SLDataType* a; // 指向动态开辟的数组[a是array的意思]-----关于这里动态开辟和数组的问题见下面解释int size ; // 有效数据个数int capicity ; // 容量空间的大小
}SeqList;
// 基本增删查改接口
// 顺序表初始化void SeqListInit(SeqList* ps);
// 检查空间,如果满了,进行增容
void SeqListCheckCapacity(SeqList* ps);
// 顺序表尾插
void SeqListPushBack(SeqList* ps, SLDateType x);
// 顺序表尾删
void SeqListPopBack(SeqList* ps);
// 顺序表头插
void SeqListPushFront(SeqList* ps, SLDateType x);
// 顺序表头删
void SeqListPopFront(SeqList* ps);
// 顺序表查找
int SeqListFind(SeqList* ps, SLDateType x, int begin);
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* ps, int pos, SLDateType x);
// 顺序表删除pos位置的值
void SeqListErase(SeqList* ps, int pos);
// 顺序表销毁
void SeqListDestroy(SeqList* ps);
// 顺序表打印
void SeqListPrint(SeqList* ps);
#define _CRT_SECURE_NO_WARNINGS 1
//SeqList.c
#include "SeqList.h"
//动态顺序表
void SeqListInit(SeqList* ps)
{assert(ps);ps->a = NULL;ps->size = 0;ps->capacity = 0;
}void SeqListCheckCapacity(SeqList* ps)
{assert(ps);if (ps->size == ps->capacity){int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;SLDateType* tmp = (SLDateType*)realloc(ps->a, newCapacity*sizeof(SLDateType));if (tmp == NULL){perror("realloc fail");exit(-1);}ps->a = tmp;ps->capacity = newCapacity;}
}void SeqListPushBack(SeqList* ps, SLDateType x)
{ //assert(ps);//SLCheckCapacity(ps);//ps->a[ps->size] = x;//因为顺序表的数据存放要连续//ps->size++;SeqListInsert(ps, ps->size ,x);}
void SeqListPopBack(SeqList* ps)
{//assert(ps);//assert(ps->size > 0);//ps->a[ps->size - 1] = 0;//ps->size--;SeqListErase(ps, ps->size - 1);
}
void SeqListPushFront(SeqList* ps, SLDateType x)
{//assert(ps);//SLCheckCapacity(ps);从前往后挪动数据 -- 再在前面插入数据//int end = ps->size - 1;//while (end >= 0)//{// ps->a[end + 1] = ps->a[end];// end--;//}//ps->a[0] = x;//ps->size++;SeqListInsert(ps, 0, x);}
void SeqListPopFront(SeqList* ps)
{//assert(ps);//assert(ps->size > 0);//int begin = 1;//while (begin < ps->size )//{// ps->a[begin - 1] = ps->a[begin];// begin++;//}//ps->size--;SeqListErase(ps, 0);}
int SeqListFind(SeqList* ps, SLDateType x ,int begin){assert(ps);for (int i = begin; i < ps->size; i++){if (ps->a[i] == x){return 1;}}return -1;
}
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* ps, int pos, SLDateType x)
{assert(ps);assert(pos >=0 && pos <= ps->size);SLCheckCapacity(ps);int end = ps->size - 1;while (end >= pos){ps->a[end + 1] = ps->a[end];end--;}ps->a[pos] = x;ps->size++;}
void SeqListErase(SeqList* ps, int pos)
{assert(ps);assert(pos >= 0 && pos < ps->size);int begin = pos + 1;while (begin < ps->size){ps->a[begin - 1] = ps->a[begin];begin++;}ps->size--;
}
void SeqListDestroy(SeqList* ps)
{assert(ps);if (ps->a != NULL){free(ps->a);ps->a = NULL;ps->size = 0;ps->capacity = 0;}
}
void SeqListPrint(SeqList* ps)
{assert(ps);for (int i = 0; i < ps->size; i++){printf("%d" , ps->a[i]);}printf("\n");}
动态开辟空间和数组的问题解释
- [ ]运算符是C语言几乎最高优先级的运算符。[ ]运算符需要两个操作数,一个指针类型,一个整数。
- 标准的写法是这样的:a[int]。这样编译器会返回 *(a+int) 的值。 a[int] 就等于 *(a + int)。
- 平时static开辟的空间是存在静态区;而在函数中定义使用的数组是存在栈区;而malloc动态开辟空间返回地址,解决了静态数组而需要实时更改数组大小以及一系列的问题。关于malloc动态内存管理可以看我之前写的文章
【c语言】动态内存管理
LeetCode-exercise
- 原地移除数组中所有的元素val,要求时间复杂度为O(N),空间复杂度为O(1)。
2. 什么是链表
概念:首先,链表是线性表之一;其次,链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
2.1链表的分类
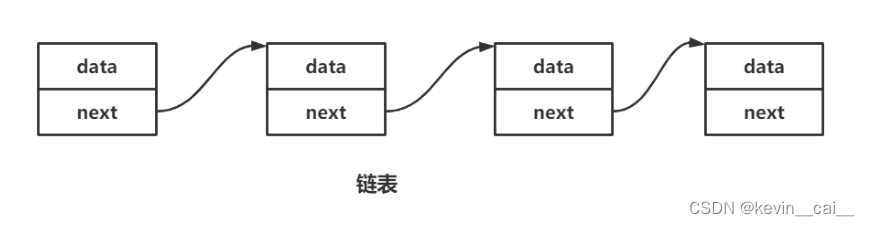
- 单向或者双向
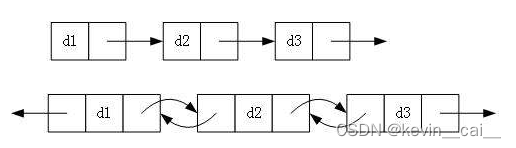
- 带头或者不带头
- 循环或者非循环
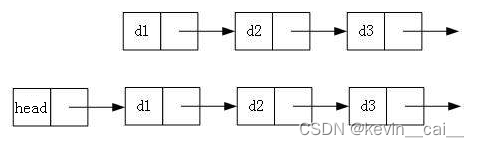
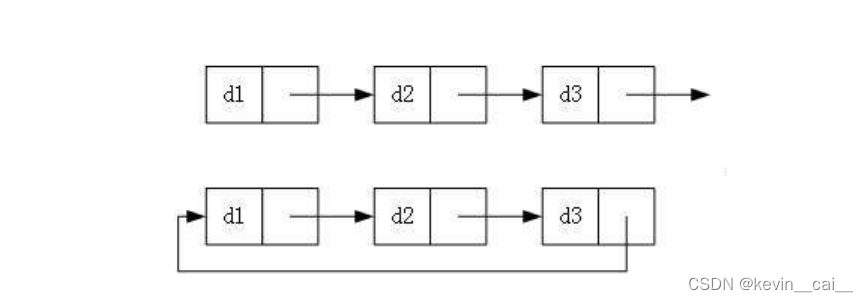
2.2常用的链表结构及区别
- 那么组合起来呢,2 ^ 3 = 8,所以总共有 8 种链表结构。但是常用的链表结构呢?主要有两种,无头单向非循环链表和带头双向循环链表
- 区别:
a.无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
b. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
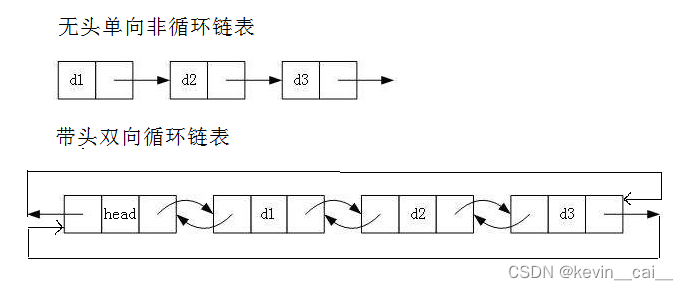
2.3无头单向非循环链表的实现
//#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// slist.h// 1、无头+单向+非循环链表增删查改实现
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType data;struct SListNode* next;
}SListNode;
// 动态申请一个结点
SListNode* BuySListNode(SLTDateType x);
//节点的连接
SListNode* CreateSList(int n);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 单链表删除pos位置之后的值
void SListEraseAfter(SListNode* pos);// 单链表的销毁
void SListDestroy(SListNode** plist);
SListNode* BuySListNode(SLTDateType x)
{SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));//if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->data = x;newnode->next = NULL;//申请节点先保证 这个指针不是野指针 初始化return newnode;
}
//SListNode* plist = CreateSList(5);
SListNode* CreateSList(int n)//最后phead地址传给CreateSList
{SListNode* phead = NULL,*ptail = NULL;for (int i = 0; i < n; i++){SListNode* newnode = BuySListNode(i);if (phead == NULL){ptail = phead = newnode;}else{ptail->next = newnode;ptail = newnode;}}return phead;
}// 单链表打印
//SListPrint(plist);
void SListPrint(SListNode* plist)//此时的plist是 上面传回来的 phead
{SListNode * cur = plist;while (cur != NULL){printf("%d->", cur->data);cur = cur->next;//下一个节点的地址}printf("NULL\n");//表示链表遍历结束,标识没有下一个节点
}
// 单链表尾插--------最后一个节点连接新节点
//SListPushBack(&plist , 100);
void SListPushBack(SListNode** pplist, SLTDateType x)//传递过来的是指针变量的地址
{//这里要改变的是实参,所以要用** plist;如果这里传的是plist,则无法通过改变形参来达到改变实参SListNode* newnode = BuySListNode(x);if (*pplist == NULL)//如果前面没有开辟 节点,链表为空{//这里就是解引用访问*plist 为访问指针pplist*pplist = newnode;}else{SListNode* tail = *pplist;while (tail->next)//直到最后tail->next节点结束位置,获取到tail的地址{tail = tail->next;}tail->next = newnode;//给tail后面 新开辟节点地址 实现尾插}
}// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{ //如果pplist为NULL 不用检查 不影响SListNode* newnode = BuySListNode(x);newnode->next = *pplist;*pplist = newnode;//生成新的 头地址指针
}
// 单链表的尾删
//SListPopBack(&pplist);
void SListPopBack(SListNode** pplist)
{ //暴力的检查 assert(*pplist);//排除 链表为空时 还继续一直删除if ((*pplist)->next == NULL){free(*pplist);*pplist = NULL;//此时又实参与由形参的问题}else{SListNode* tail = *pplist;while (tail->next->next){tail = tail->next;}free(tail->next);//tail == NULL; tail是个局部变量 tail->next = NULL;}
}// 单链表头删
void SListPopFront(SListNode** pplist)
{ //链表为空 不用删assert(*pplist);SListNode* next = (*pplist)->next;//*和->都是解引用 ,优先级确定不了所以要加括号free(*pplist);*pplist = next;
}
// 单链表查找
//SListNode* pos = SListFind(plist , 3);
//
SListNode* SListFind(SListNode* plist, SLTDateType x)
{SListNode* cur = plist;while (cur){if (cur->data = x){return cur;}cur = cur->next;}return NULL;
}
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
void SListInsertAfter(SListNode* pos, SLTDateType x)
{assert(pos);SListNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}
void SListEraseAfter(SListNode* pos)
{assert(pos);if (pos->next == NULL){return; }else{//free(pos->next);//pos->next = pos->next->next;//如果pos的next被释放则其值为随机值,但原本应该存放next的next的地址SListNode* nextNode = pos->next;pos->next = nextNode->next;free(nextNode);}
} // 单链表的销毁
void SListDestroy(SListNode** plist)
{SListNode* cur = *plist;while (cur){SListNode* next = cur->next;free(cur);cur = next;}*plist = NULL;
}
2.4带头双向循环链表的实现
//.h
// 2、带头+双向+循环链表增删查改实现
#pragma once#include <stdio.h>
#include <assert.h>
#include <stdlib.h>// 带头+双向+循环链表增删查改实现
typedef int LTDataType;
typedef struct ListNode
{LTDataType _data;struct ListNode* _next;struct ListNode* _prev;
}ListNode;//创建一个节点
ListNode* BuyListNode(LTDataType x);// 创建返回链表的头结点.
ListNode* ListCreate();
// 双向链表销毁
void ListDestory(ListNode* pHead);
// 双向链表打印
void ListPrint(ListNode* pHead);
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x);
// 双向链表尾删
void ListPopBack(ListNode* pHead);
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x);
// 双向链表头删
void ListPopFront(ListNode* pHead);
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x);
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x);
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);
#define _CRT_SECURE_NO_WARNINGS 1#include "DList.h"ListNode* BuyListNode(LTDataType x)
{ListNode* node = (ListNode*)malloc(sizeof(ListNode));if (node == NULL){perror("malloc fail");exit(-1);}node->_data = x;node->_next = NULL;node->_prev = NULL;return node;}
// 创建返回链表的头结点.
ListNode* ListCreate()
{ListNode* phead = BuyListNode(-1);phead->_next = phead;phead->_prev = phead;return phead;
}
// 双向链表销毁
void ListDestory(ListNode* pHead)
{assert(pHead);ListNode* cur = pHead->_next;while (cur != pHead){ListNode* ne_nextxt = cur->_next;free(cur);cur = ne_nextxt;}free(pHead);//phead = NULL;}
// 双向链表打印
void ListPrint(ListNode* pHead)
{assert(pHead);ListNode* cur = pHead->_next;printf("guard<=>\n");while (cur != pHead) {printf("%d<=>", cur->_data);cur = cur->_next;}printf("\n");}
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{assert(pHead);ListNode* newnode = BuyListNode(x);ListNode* tail = pHead->_prev;tail->_next = newnode;newnode->_prev = tail;newnode->_next = pHead;pHead->_prev = newnode;
}
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{assert(pHead);assert(pHead->_next != pHead); // 空ListNode* tail = pHead->_prev;ListNode* tailPrev = tail->_prev;tailPrev->_next = pHead;pHead->_prev = tailPrev;free(tail);
}
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{assert(pHead);/*LTNode* newnode = BuyListNode(x);newnode->next = phead->next;phead->next->prev = newnode;phead->next = newnode;newnode->prev = phead;*/ListNode* newnode = BuyListNode(x);ListNode* first = pHead->_next;// phead newnode first // 顺序无关pHead->_next = newnode;newnode->_prev = pHead;newnode->_next = first;first->_prev = newnode;
}
// 双向链表头删
void ListPopFront(ListNode* pHead)
{assert(pHead);assert(pHead->_next != pHead); // 空/*LTNode* first = phead->next;LTNode* second = first->next;free(first);phead->next = second;second->prev = phead;*/ListErase(pHead->_next);
}
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{assert(pHead);ListNode* cur = pHead->_next;while (cur != pHead){if (cur->_data == x){return cur;}cur = cur->_next;}return NULL;
}
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{assert(pos);ListNode* _prev = pos->_prev;ListNode* newnode = BuyListNode(x);// prev newnode pos_prev->_next = newnode;newnode->_prev = _prev;newnode->_next = pos;pos->_prev = newnode;
}
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{assert(pos);ListNode* _prev = pos->_prev;ListNode* _next = pos->_next;free(pos);_prev->_next = _next;_next->_prev = _prev;
}2.5循序表和链表的区别
LeetCode-exercise
1.删除链表中等于给定值 val 的所有结点
3. 快慢指针
LeetCode-exercise
- 给你一个链表的头节点 head ,判断链表中是否有环。
方法一:暴力解法:判断引用地址是否重复
- 这道题最简单的做法就是在遍历链表的同时记录下每一个节点,在遍历过程中不停的判断当前节点是不是之前已经记录过的节点。
- 如果遍历时发现有和记录下来的节点重复的,则证明是环形链表; 如果整个链表能够遍历完也没有重复节点,则证明不是环形链表。
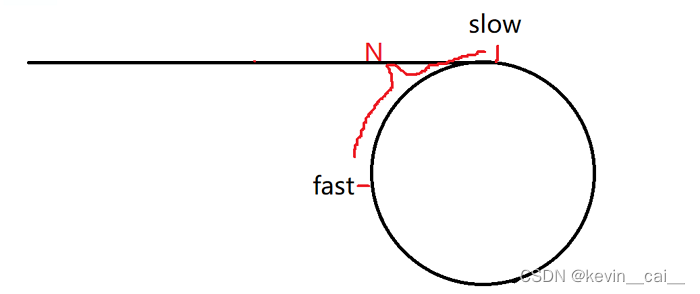
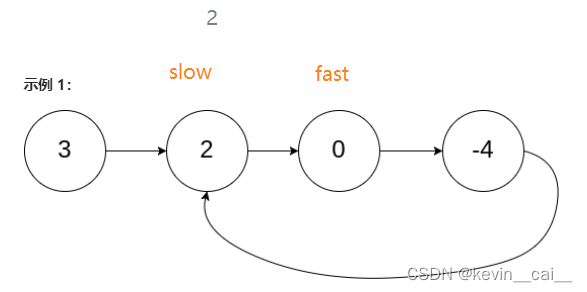
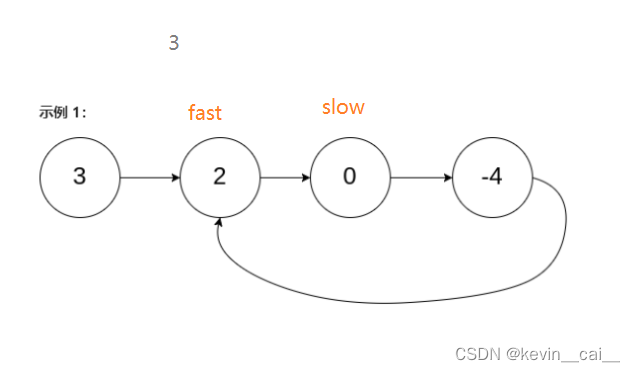
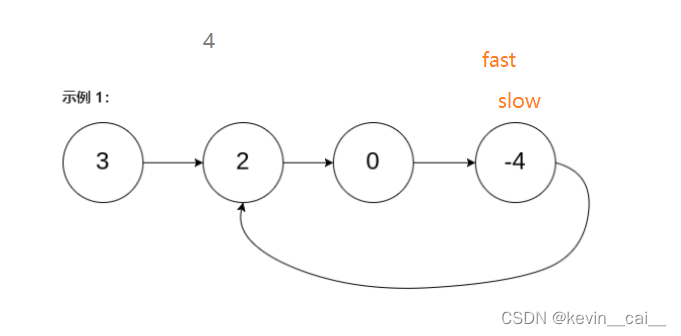
方法二:快慢指针解法:简单原理就是用两个指针,一个快,一个慢。 慢指针走一步,快指针走两步。
- 如果存在环,那么快指针始终可以追上慢指针,即两个指针一定会出现指向同一个节点的状态,就好像赛跑中被套圈。
- 因为是判断链表是否有环,所以我们考虑使用追及相遇来解决。我们使用快慢指针fast和slow,初始化它们都为头结点,然后让slow一次走一步,fast一次走两步。
- 为什么肯定能追击上呢?
如果存在环,当slow进环时,fast肯定在环里,此时两者相差N的距离,这个时候它们开始追及。因为fast的步长是slow的两倍,所以它们之间的距离每走一次是减小1的,它们之间的距离逐渐逼近,这样slow和fast一定可以相遇。当它们距离减小到0时,即它们相遇,这个时候就可以确定链表肯定有环。
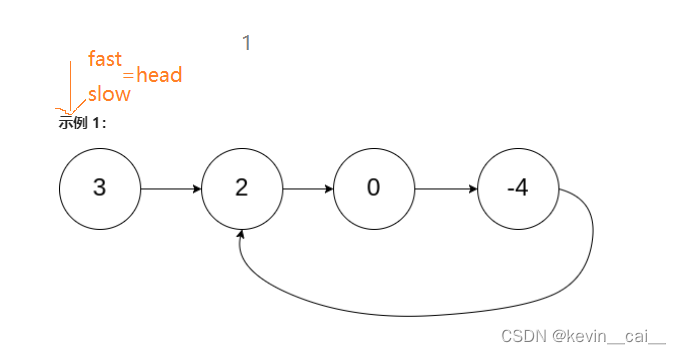
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
bool hasCycle(struct ListNode *head) {struct ListNode* slow = head, *fast = head;while(fast && fast->next)//如果不带环fast会为NULL;fast不为NULL,那么slow肯定不为NULL,fast->next不为NULL{slow = slow->next;fast = fast->next->next;if(slow == fast)return true;}return false;
}
相关文章:
【数据结构】顺序表和链表基本实现(含全代码)
文章目录 一、什么是线性表1. 什么是顺序表动态开辟空间和数组的问题解释LeetCode-exercise 2. 什么是链表2.1链表的分类2.2常用的链表结构及区别2.3无头单向非循环链表的实现2.4带头双向循环链表的实现2.5循序表和链表的区别LeetCode-exercise 3. 快慢指针LeetCode-exercise 一…...
CMake : Linux 搭建开发 - g++、gdb
目录 1、环境搭建 1.1 编译器 GCC,调试器 GDB 1.2 CMake 2、G 编译 2.1 编译过程 编译预处理 *.i 编译 *.s 汇编 *.o 链接 bin 2.2 G 参数 -g -O[n] -l、-L -I -Wall、-w -o -D -fpic 3、GDB 调试器 3.1 调试命令参数 4、CMake 4.1 含义 4.2…...
大数据实战 --- 美团外卖平台数据分析
目录 开发环境 数据描述 功能需求 数据准备 数据分析 RDD操作 Spark SQL操作 创建Hbase数据表 创建外部表 统计查询 开发环境 HadoopHiveSparkHBase 启动Hadoop:start-all.sh 启动zookeeper:zkServer.sh start 启动Hive: nohup …...

三大本土化战略支点,大陆集团扩大中国市场生态合作「朋友圈」
“在中国,大陆集团已经走过30余年的发展与耕耘历程,并在过去10年间投资了超过30亿欧元。中国市场也成为了我们重要的‘增长引擎’与‘定海神针’。未来,我们将继续深耕中国这个技术导向的市场。”4月19日上海车展上,大陆集团首席执…...

为什么停更ROS2机器人课程-2023-
机器人工匠阿杰肺腑之言: 我放弃了ROS2课程 真正的危机不是同行竞争,比如教育从业者相互竞争不会催生ChatGPT…… 技术变革的突破式发展通常是新势力带来的而非传统行业的升级改革。 2013年也就是10年前在当时主流视频网站开启分享: 比如 …...
【SpringCloud常见面试题】
SpringCloud常见面试题 1.微服务篇1.1.SpringCloud常见组件有哪些?1.2.Nacos的服务注册表结构是怎样的?1.3.Nacos如何支撑阿里内部数十万服务注册压力?1.4.Nacos如何避免并发读写冲突问题?1.5.Nacos与Eureka的区别有哪些ÿ…...

ChatGPT+智能家居在AWE引热议 OpenCPU成家电产业智能化降本提速引擎
作为家电行业的风向标和全球三大消费电子展之一,4月27日-30日,以“智科技、创未来”为主题的AWE 2023在上海新国际博览中心举行,本届展会展现了科技、场景等创新成果,为我们揭示家电与消费电子的发展方向。今年展馆规模扩大至14个…...

拷贝构造函数和运算符重载
文章目录 拷贝构造函数特点分析拷贝构造函数情景 赋值运算符重载运算符重载operator<运算符重载 赋值运算符前置和后置重载 拷贝构造函数 在创建对象的时候,是不是存在一种函数,使得能创建一个于已经存在的对象一模一样的新对象,那么接下…...

本周热门chatGPT之AutoGPT-AgentGPT,可以实现完全自主实现任务,附部署使用教程
AutoGPT 是一个实验性的开源应用程序,它由GPT-4驱动,但有别于ChatGPT的是, 这与ChatGPT的底层语言模型一致。 AutoGPT 的定位是将LLM的"思想"串联起来,自主地实现你设定的任何目标。 简单的说,你只用提出…...

Mysql 优化LEFT JOIN语句
1.首先说一下个人对LEFT JOIN 语句的看法,原先我是没注意到LEFT JOIN 会影响到性能的,因为我平时在项目开发中,是比较经常见到很多个关联表的语句的。 2.阿里巴巴手册说过,连接表的语句最好不超过3次,但是我碰到的项目…...

全栈成长-python学习笔记之数据类型
python数据类型 数字类型 类型类型转换整型 intint() 字符串类型转换 浮点型保留整数 int(3.14)3 int(3.94)3浮点型 floatfloat() #####字符串类型 类型类型转换字符串 strstr() 将其他数据类型转为字符串 布尔类型与空类型 布尔类型 类型类型转换布尔型 boolbool()将其他…...

面试|兴盛优选数据分析岗
1.离职原因、离职时间点 2.上一份工作所在的部门、小组、小组人员数、小组内的分工 3.个人负责的目标,具体是哪方面的成本 4.为了降低专员成本,做了哪些方面的工作 偏向于机制、分析方法、思维,当下主要是对于部分高收入专员收入不合理的情况…...
主从复制master-slave replication)
Redis(08)主从复制master-slave replication
文章目录 redis主从复制一. 配置文件的方式设置1. 主节点配置:2. 从节点1配置:3. 从节点2配置: 二. 命令的方式设置1. 创建服务2. 设置主从节点3. 测试 三. 从节点升级为主节点四. 查看主从关系 redis主从复制 Redis主从复制是将一个Redis实例的数据复制到多个Redis实例&#…...
被chatGPT割了一块钱韭菜
大家好,才是真的好。 chatGPT热度一直上升,让我萌生了一个胆大而创新的想法, 把chatGPT嵌入到Notes客户机中来玩。 考虑到我已经下载了一个chatGPT的Notes应用(请见《ChatGPT APIs for HCL DOMINO》),想着…...
vue3+ts+pinia+vite一次性全搞懂
vue3tspiniavite项目 一:新建一个vue3ts的项目二:安装一些依赖三:pinia介绍、安装、使用介绍pinia页面使用pinia修改pinia中的值 四:typescript的使用类型初识枚举 一:新建一个vue3ts的项目 前提是所处vue环境为vue3&…...

Apache安装与基本配置
1. 下载apache 地址:www.apache.org/download.cgi,选择“files for microsoft windows”→点击”ApacheHaus”→点击”Apache2.4 VC17”,选择x64/x86,点击右边download下面的图标。 2. 安装apache (1)把…...

哈夫曼树【北邮机试】
一、哈夫曼树 机试考察的最多的就是WPL,是围绕其变式展开考察。 哈夫曼树的构建是不断选取集合中最小的两个根节点进行合并,而且在合并过程中排序也会发生变化,因此最好使用优先队列来维护单调性,方便排序和合并。 核心代码如下…...
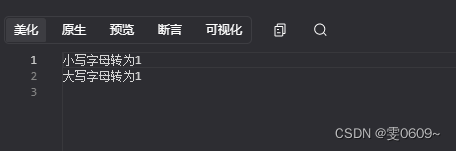
thinkphp:数值(保留小数点后N位,四舍五入,左侧补零,格式化货币,取整,生成随机数,数字与字母进行转换)
一、保留小数点后N位/类似四舍五入(以保留小数点后三位为准) number_format()函数:第一个参数为要格式化的数字,第二个参数为保留的小数位数 方法一: public function test() {$num 12.56789; // 待格式化的数字$r…...

用Flutter你得了解的七个问题
Flutter是Google推出的一款用于构建高性能、高保真度移动应用程序、Web和桌面应用程序的开源UI工具包。Flutter使用自己的渲染引擎绘制UI,为用户提供更快的性能和更好的体验。 Flutter使用Dart语言,具有强大的类型、效率和易学能力,基本上你…...

Nmap使用手册
Nmap语法 -A 全面扫描/综合扫描 nmap-A 127.0.0.1 扫描指定网段 nmap 127.0.0.1 nmap 127.0.0.1/24Nmap 主机发现 -sP ping扫描 nmap -sP 127.0.0.1-P0 无ping扫描备注:【协议1,协设2〕【目标】扫描 nmap -P0 127.0.0.1如果想知道是如何判断目标主机是否存在可…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...