【C++】C++11常用特性总结
哥们哥们,把书读烂,困在爱里是笨蛋!

文章目录
- 一、统一的列表初始化
- 1.统一的{}初始化
- 2.std::initializer_list类型的初始化
- 二、简化声明的关键字
- 1.decltype
- 2.auto && nullptr
- 三、STL中的一些变化
- 1.新增容器:array && forward_list && unordered系列容器
- 2.新增接口:移动构造/赋值 && emplace系列接口
- 四、右值引用和移动语义(重要)
- 1.什么是左值和右值?
- 2.左值引用和右值引用 的引用规则
- 3.右值引用价值之一:右值拷贝或赋值给其他对象(移动构造和移动赋值)
- 4.右值引用价值之二:push_back插入数据(补充知识:const右值引用)
- 5.改造自己写的list,实现右值引用版本的push_back
- 6.万能引用和完美转发( 函数模板std::forward< T >() )
- 五、类的新功能
- 1.新增成员函数
- 2.类成员的初始化(缺省值,default,delete)
- 六、lambda表达式(叫表达式,其实是可调用对象)
- 1.lambda表达式的用法和本质
- 2.配合多线程使用lambda表达式
- 七、可变参数模板
- 1.展开参数包的两种方式(递归展开,借助数组推开参数包)
- 2.对比emplace和insert(使用语法 和 插入的效率)
- 八、function包装器
- 1.对学过的所有可调用对象进行包装
- 2.逆波兰表达式求解--包装器的使用
- 3.bind绑定的用法
一、统一的列表初始化
1.统一的{}初始化
1.
以前在C语言的时候,{}一般用于初始化数组或结构体,例如下面代码的初始化方式,数组array1和array2可以在创建的同时进行初始化,同样结构体p1和p2也可以在定义的时候初始化,p2的_y成员变量默认初始化为0.
struct Point
{int _x;int _y;
};
int main()
{int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p1 = { 1, 2 };Point p2 = { 1 };// _y默认初始化成0了return 0;
}
2.
然而在C++11中,扩大了{}列表初始化的范围,使其能够初始化所有的自定义类型和内置类型,实现统一的列表初始化{},并且在初始化的时候,如果不想写=赋值符号,也可以将其省略,只保留{}花括号列表。
例如下面的x1 x2变量在初始化时,也可以用{}来初始化,并且也可以省略=,同样的结构体p1和数组array1 array2都可以省略=,但并不推荐省略花括号,因为省略之后确实有些奇怪,但如果你非要省略,那编译器也拦不住你,语法规定既可以省略也可以不省略。
列表初始化当然也可以用在new开空间的时候,例如p2指针指向空间在开辟的时候,内部元素被初始化为0,p3结构体指针指向的结构体数组也可以用统一的列表进行初始化。
以上都是列表作用于C语言的对象上面,例如数组 结构体等对象。
struct Point
{int _x;int _y;
};
int main()
{//用初始化列表初始化时,可以省略 赋值符号=//以前的{}只能初始化结构体和数组,现在的{}对于自定义类型和内置类型的对象都可以初始化,一切皆可用列表初始化。int x1 = 1;int x2{ 2 };//不要这么玩,我们自己能看懂就行int array1[]{ 1, 2, 3, 4, 5 };int array2[5]{ 0 };Point p1{ 1, 2 };//对结构对象进行初始化,c++11可以省略=// C++11中列表初始化也可以适用于new表达式中int* p2 = new int[4]{ 0 };Point* p3 = new Point[2]{ {1,2}, {3,4} };return 0;
}
3.
列表在C++中作用于对象时,同样也可以初始化对象。当然,{}列表在初始化对象的时候会调用对象所属类的构造函数。如果你调试下面代码,其实就可以发现光标在初始化对象时,会跳到类的构造函数处进行对象的初始化。
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
};
int main()
{Date d1(2022, 1, 1); // old style// C++11支持的列表初始化,下面会调用构造函数初始化Date d2{ 2022, 1, 2 };Date d3 = { 2022, 1, 3 };//构造一个临时对象,然后拷贝构造给d3-->编译器优化为直接构造return 0;
}
2.std::initializer_list类型的初始化
1.
下面对于STL容器初始化的方式,实际是使用了C++11中新增的一个类,叫做initializer_list,这个类的对象的形式其实就是下面代码赋值符号右边的部分,右边就是initializer_list对象,所以下面初始化的方式就是将initializer_list对象拷贝给v和vv对象。
int main()
{vector<int> v = { 1, 2, 3 };vector<int> vv = { 1, 2, 3, 4, 5, 6 };
}

2.
那vector容器实现了initializer_list对象的拷贝构造吗?当然实现了,在C++11中所有的STL容器(适配器不算)都实现了initializer_list对象的拷贝构造,包括map,set,list,vector,unordered系列等容器在C++11版本中都增加了initializer_list对象的初始化。

3.
那initializer_list大概是一个什么类呢?其实我们可以将其认为成是一个常量数组,这个类的成员函数也很简单,只有构造和两个获取迭代器的接口,当然他的底层实现也一定不复杂,因为他本质就是一个数组,维护的成本很低。

4.
我们自己模拟实现一个用initializer_list对象拷贝构造vector对象的函数,也很简单,只需要遍历initializer_list对象,将每一个元素尾插到vector当中即可。例如下面代码实现的拷贝构造,因为initializer_list实现了迭代器,所以遍历initializer_list可以用范围for来实现,注意取initializer_list内部的迭代器类型时,要加typename关键字告诉编译器你取的是类内部的内嵌类型。遍历initializer_lis对象中的每一个元素将其拷贝到vector中,这样就实现了vector的initializer_list版本的拷贝构造了,实现拷贝赋值,我们可以让拷贝构造给我们打工,然后交换资源即可,即为交换指针,这样就实现了拷贝赋值,是不是很简单呢?
namespace wyn
{template<class T>class vector {public:typedef T* iterator;//vector的迭代器就是原生指针嘛vector(const initializer_list<T>& l){_start = new T[l.size()];_finish = _start + l.size();_endofstorage = _start + l.size();iterator vit = _start;typename initializer_list<T>::iterator lit = l.begin();//取类模板的内嵌类型记得加typename关键字,因为编译器不知道你取的是类型还是静态变量或函数while (lit != l.end()){*vit++ = *lit++;}//for (auto e : l)// *vit++ = e;}vector<T>& operator=(initializer_list<T> l) {vector<T> tmp(l);std::swap(_start, tmp._start);std::swap(_finish, tmp._finish);std::swap(_endofstorage, tmp._endofstorage);return *this;}private:iterator _start;iterator _finish;iterator _endofstorage;};
}
int main()
{wyn::vector<int> v = { 1, 2, 3, 4, 5, 6 };//用initializer_list对象进行vector的拷贝构造v = { 11, 22, 33, 44, 55, 66 };//用initializer_list对象进行vector的拷贝赋值
}
5.
除上面那样较为简单的initializer_list的使用方法外,向下面这样初始化vector< Date >和map<string, string>对象,同样也可以使用initializer_list对象。
下面两行代码赋值符号的右边都是混和用了C++11的列表初始化和initializer_list初始化。先用列表{}初始化对象,然后再把对象当作常量数组的元素,构造出initializer_list对象,最后将这个对象拷贝构造给v3和dict对象。
int main()
{vector<Date> v3 = { {1,1,1}, {2,2,2}, {3,3,3} };//用Date对象的一个常量对象数组来初始化构造一个vector// 这里{"sort", "排序"}会先初始化构造一个pair对象,然后用pair对象搞一个常量对象数组来初始化构造一个map//里层是pair类的列表初始化{},会调用pair的构造函数,外层是initializer_list类,会生成匿名initializer_list对象map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };// 使用大括号initializer_list对象进行vector的赋值,stl容器也支持这样的赋值方式return 0;
}
6.
C++11新增的{}列表统一初始化,和用initializer_list对象初始化容器的这两种方式,在初始化形式上都是利用了{}进行初始化。所以从语法角度上讲,无论是在C++还是在C语言中,所有的变量和自定义对象都可以用{}花括号进行初始化了,包括STL的容器,实现统一的列表{ }初始化。
这里的统一实际上是指使用形式的统一,列表初始化是C++11新增的语法,initializer_list是C++新增的类,这一点我们要分清楚。
二、简化声明的关键字
1.decltype
1.
C++11新增了关键字decltype,此关键字可以帮助我们简化变量的声明,typeid仅仅能获取某一类型的信息,但decltype可以获取变量的类型后,定义出其他的变量,例如在F函数中,我们想用t1 * t2的结果类型定义出一个变量ret,但我们不清楚t1和t2是什么类型,我们不能单独用t1或t2类型定义出变量ret。此时就可以用decltype获取t1 * t2的结果类型,并用这个结果类型定义出变量ret。
2.
但实际上,我们可以用auto推导出t1*t2的结果类型,然后用结果类型定义出ret变量,所以decltype看起来花里胡哨的,但非常的鸡肋好吧,真不如auto好用。
template<class T1, class T2>
void F(T1 t1, T2 t2)
{//decltype()拿到括号里的类型,可以用类型定义出变量 --> 看起来挺牛逼,实际也没啥用decltype(t1 * t2) ret = t1 * t2;//用t1*t2的类型 定义变量ret,做到了typeid做不到的事情//typeid().name拿到的是类型的字符串,无法定义变量,只能用来打印cout << typeid(ret).name() << endl;cout << ret << endl;
}
int main()
{const int x = 1; double y = 2.2;decltype(x * y) ret; // 用x * y的类型double,定义出ret变量decltype(&x) p; // 用&x的类型int const*,定义出p变量cout << typeid(ret).name() << endl;cout << typeid(p).name() << endl;F(1, 'a');//字符其实就是ascii码F(x, y);return 0;
}
2.auto && nullptr
1.
auto是非常常见的一种简化变量或对象声明的一个关键字,例如在写范围for迭代遍历容器时,我们经常不想写容器元素的类型,此时一般都会选择用auto来声明容器元素的类型。
auto也可以进行引用推导,即定义一个变量,此变量的类型用auto推导,并且此变量为引用实体的别名,但需注意的是,auto在进行引用推导的时候,必须加&,也就是auto & r=x;这样的形式,r就是x的别名,x的类型auto会自动推导出来。
所以auto还是一个非常不错的关键字,在写代码的时候能帮使代码变得更加简洁一些。
2.
下面是C++98中NULL这个宏的定义,由于NULL既可表示字面值0,也可以表示空指针(void*)0,为了便于区分字面值和空指针,在C++11中引入了关键字nullptr,此关键字专门用来表示空指针,正好能和字面值0区分开来。
// NULL既能表示为整型常量,又能表示为指针常量
//所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
三、STL中的一些变化
1.新增容器:array && forward_list && unordered系列容器
1.
C++11中新增了容器array,array是一个固定大小的序列式容器,其模板定义中含有非类型模板参数N,N代表数组的大小。
这个容器对标的其实就是C语言的静态数组,也就是平常我们定义的定长数组。array容器比我们定义的数组要说强,那其实就是强在越界访问检查机制上面了,array会进行越界访问的assert断言检查,而静态数组对于较远的空间位置的越界访问是有可能不报错的,因为较远的空间一般不会被OS分配出去,所以此时不会报错。
2.
但其实array也没个p用,我们都已经有vector了,为什么还要用array呢?vector也有断言检查越界啊,并且vector还是动态开辟的,静态我们就用自己定义的静态数组,为什么要用你的array啊?所以这个容器和关键字decltype一样都是鸡肋。
template < class T, size_t N > class array;
int main()
{// array<int, 10> a1; vs int a2[10];//array相比静态数组有什么优势?array<int, 10> a1;//堆空间int a2[10];//栈空间//越界读不会报错a2[10];a2[20];// 越界写的位置较近会报错,较远时不会报错 --> 系统对于普通数组的越界是一种抽查行为//如果越界的空间位置没有被分配出去,那一般访问时不会报错,如果被分配出去,则进行数据覆盖时会发生越权,那就会报错a2[10] = 10;//报错a2[20] = 20;//不报错a1[20];//a1无论读写都可以检查出来,a1是array的对象,这里调用operator[]函数,内部会进行assert检查。//但其实array也没啥用,虽然比C语言的普通数组多了越界的检查,但既然我已经有了vector,那为什么还要用你的array呢?//我的vector的operator[]也可以检查越界啊!vector<int> v(10);//默认给我们初始化成int(),也就是初始化为0,不比array用的舒服?你array还不给我初始化。return 0;
}
3.
C++11新增的forward_list是单链表,这个也没啥用,库里只实现了forward_list的头插和头删,尾插尾删并没有实现,因为得找尾,找尾的效率很低,所以forward_list和list相比更是被虐的渣渣不剩了,list是带头双向循环链表啊,结构比你单链表牛逼多了,我有list为啥用你单链表呢?
可能单链表唯一的优势就是占用的内存空间少一点,每一个结点能省下一个指针,也是比较鸡肋的。
4.
比较有用的就是unordered系列容器了,这个容器也是C++11新增的,其实就是我之前文章讲的哈希表,底层是用挂哈希桶的方式实现的,哈希桶就是用单链表的方式来实现的,单链表在这个地方作为某些数据结构的子结构还是有点用的。
2.新增接口:移动构造/赋值 && emplace系列接口
1.
移动构造和移动赋值放到第四部分展开讲解。
emplace涉及到可变参数模板和右值引用的知识,所以emplace放到第七部分讲解。
2.
C++11其实还新增了C系列的获取迭代器的接口,其实也没必要,因为原来的迭代器接口已经实现了const和非const两个版本了,但C++委员会可能怕有的人看不懂这样的函数重载,或者const关键字的用法,又专门搞出来C系列的获取迭代器的接口,专门给const对象获取const迭代器时进行调用。
四、右值引用和移动语义(重要)
1.什么是左值和右值?
1.
左值就是能够取地址,能被赋值的数据表达式,比如变量或解引用的指针等,解引用后的指针实际也是变量。左值既可以出现在赋值符号的左面,也可以出现在赋值符号的右面。
2.
右值不能被取地址,不能被赋值,右值有字面值,表达式的返回值,传值返回的函数调用的返回值,匿名对象等等,都是常见的右值。右值在引用时用&&来表示右值引用。

2.左值引用和右值引用 的引用规则
1.
左值引用只能引用左值,但const左值引用可以引用右值。右值引用只能引用右值,但右值引用可以引用move以后的左值,因为左值move以后,其实就变成右值了。
std命名空间中的move函数可以将左值转为右值,move其实就是移动语义,move后的左值变成将亡值。(右值可以分为纯右值和将亡值,纯右值例如字面值,表达式返回值,将亡值例如匿名对象,传值返回的返回值也就是临时对象)
什么是将亡值呢?例如匿名对象,传值返回的函数调用的返回值等,因为匿名对象在其所在代码行执行完毕后就会被销毁,并且传值返回的函数调用实际利用了中间生成的一个临时变量将返回值从被调用的函数栈帧即将销毁时带出,这个临时变量的值一旦被接收,也就是拷贝或者引用后,此临时变量就会被销毁。所以我们把匿名对象,传值返回的函数调用的返回值称为将亡值,将亡值也是右值。
int main()
{// 左值引用只能引用左值,不能引用右值。int a = 10;int& ra = a; // ra为a的别名//int& ra2 = 10; // 编译失败,因为10是右值// const左值引用既可引用左值,也可引用右值。const int& ra3 = 10;//权限平移const int& ra4 = a;//权限缩小return 0;
}int main()
{// 右值引用只能右值,不能引用左值。int&& r1 = 10;// error C2440: “初始化”: 无法从“int”转换为“int &&”// message : 无法将左值绑定到右值引用int a = 10;int&& r2 = a;// 右值引用可以引用move以后的左值,move会返回右值引用int&& r3 = std::move(a);return 0;
}
3.右值引用价值之一:右值拷贝或赋值给其他对象(移动构造和移动赋值)
1.
左值引用的意义就是减少拷贝,提高效率。例如函数参数是左值引用,那就可以减少拷贝提高效率,事实上函数的返回值也可以是左值引用,但必须要求返回值出了函数作用域未被销毁,这样才能用左值引用返回,减少拷贝提高效率。
那当某个函数的返回值就是一个临时对象呢?我们就用不了传引用返回,只能用传值返回。如果返回的是内置类型,代价还好,如果返回的是一个vector< vector< int >>的二维数组呢?比如力扣杨辉三角那个题返回的就是二维数组,那就需要深拷贝一个二维数组,然后随着栈帧销毁,原来的二维数组也会被销毁,这样的代价就会非常的大了。如果返回的是一棵红黑树呢?我们在深拷贝一棵红黑树吗?效率未免也太低了吧!
2.
所以此时出现了右值引用,其价值之一就是为了补齐左值引用的最后一块儿短板,即当返回值为传值传递时,有可能带来深拷贝导致程序效率降低的问题。
实际上在以前没有右值引用的时候,是通过输出型参数来解决传值返回代价太大的问题,即在调用函数之前创建好要返回的对象,然后将这个返回的对象通过传引用的方式来传参,在函数内部通过改变这个输出型参数的方式来改变函数外面提前创建好的对象或变量。
输出型参数确实解决了问题,但由于使用起来有些别扭,C++11又搞出来了右值引用,当然右值引用解决传值返回代价大的问题只是右值引用的价值之一而已,右值引用在插入数据时也能提高效率,减少深拷贝的次数。
3.
下面是自己实现的一个string类,在拷贝构造,拷贝赋值等函数内部进行了语句的打印,方便我们在测试时看到对应的输出结果。并且还实现了一个专门用于测试传值返回的函数to_string()。
wyn命名空间中的移动构造和移动赋值也实现了,实际移动构造和移动赋值的原理很简单,就是因为右值是将亡值嘛,那既然你都是将亡值了,何不直接把资源转移给被拷贝或是被赋值的对象呢?这样就不需要进行资源的重新拷贝了啊。用移动拷贝和移动赋值对比拷贝构造和拷贝赋值就可以看出来,拷贝构造和拷贝赋值即使参数是左值引用,在传参时能够减少拷贝提高效率,但只要涉及到资源申请的时候,拷贝构造和拷贝赋值内部一定是将资源重新拷贝了一份,把重新拷贝的资源给到被拷贝对象或被赋值对象,这当然一点问题都没有。
但如果是右值的拷贝或赋值呢?因为拷贝构造和拷贝赋值的参数是const左值引用,自然可以接收右值的传参,在函数内部必然还是要进行资源的重新拷贝,那是不是有点太浪费了啊?此时就需要移动拷贝和移动赋值来提高这样场景下的效率,怎么提高呢?很简单,我们不再拷贝资源,而是直接将右值的资源移动给被拷贝对象或被赋值对象,省去一次深拷贝。
而像函数传值返回带来的深拷贝这样的问题此时也就迎刃而解了,如果我们要将传值返回的返回值接收,也就是用返回值初始化接收值时,由于返回值是一个右值,此时不再匹配拷贝构造或拷贝赋值,而是直接匹配移动构造或移动赋值,将右值的空间资源通过交换指针这样的浅拷贝的方式来实现转移,这样就不会进行深拷贝,提高了传值返回接收时带来的深拷贝的问题。
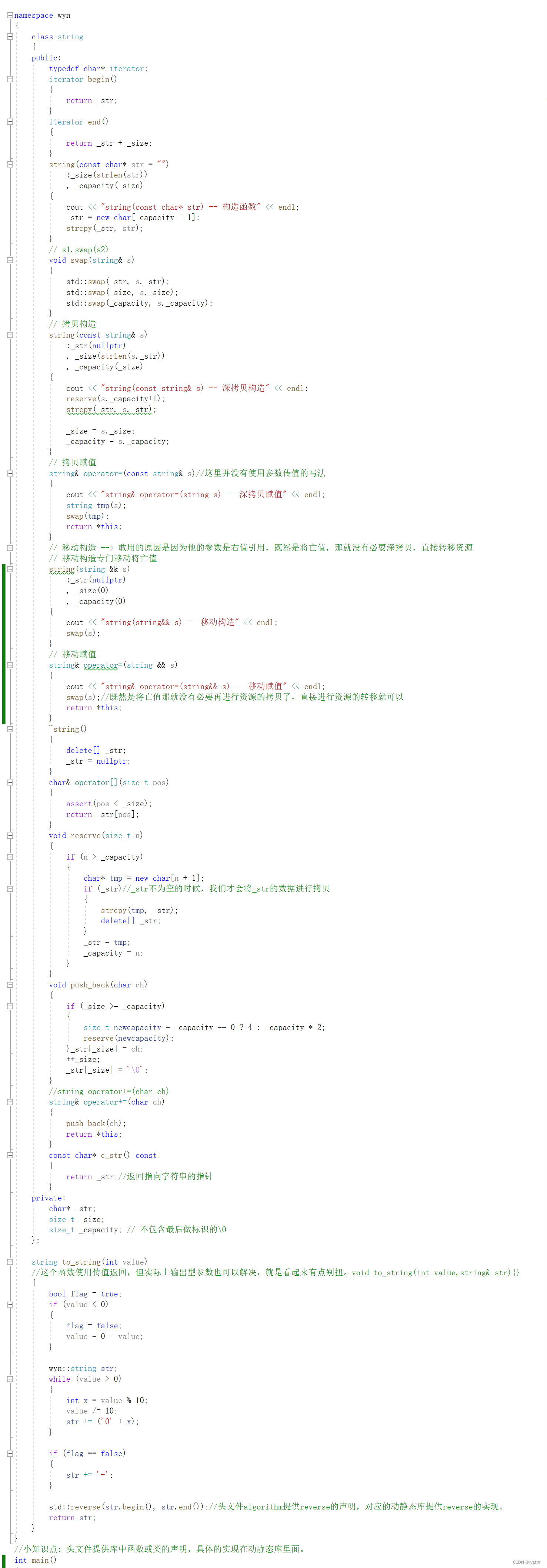
4.
从打印结果就可以看出,当拷贝对象是右值的时候,不会再调用深拷贝构造或是深拷贝赋值了,而是调用移动构造和移动赋值。
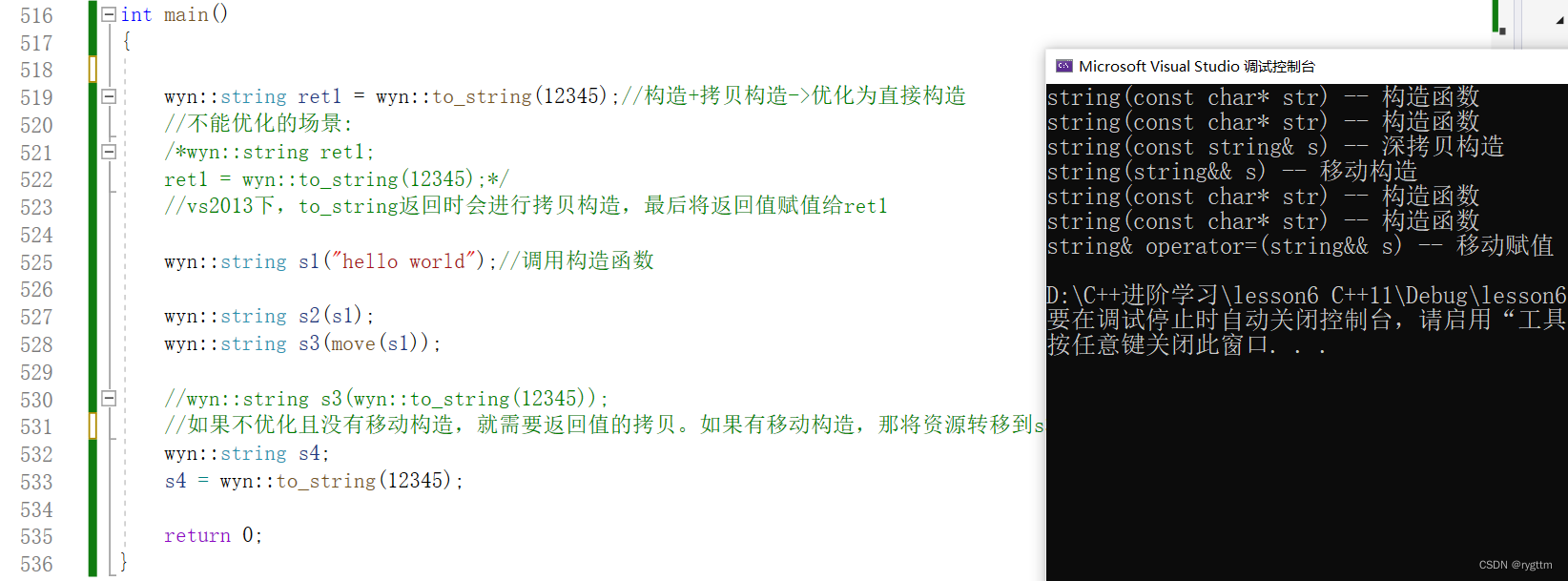
5.
对于string这样涉及资源申请的类,实现移动构造和移动赋值是非常有必要的,因为某些右值拷贝或赋值的场景下,直接进行空间资源的转移,而不是进行空间资源的再申请,也就是空间资源的拷贝,效率会很高。
但对于Date这样不涉及资源申请的日期类,就没有必要实现移动构造和移动赋值了,因为你没有资源啊,压根不会出现深拷贝的场景,你所有资源的拷贝都是浅拷贝,移动语义的接口和拷贝构造、拷贝赋值这些接口没有区别,都是进行数据的浅拷贝。只有当某个类涉及到空间资源申请的时候,为了防止不必要的深拷贝,我们才会在这样的类里面实现移动构造和移动赋值,所以大家要区分好右值引用使用的场景。
6.
我们自己实现的string有移动构造和移动拷贝的接口,那库里面有嘛?库里面当然有,我们可以通过调试窗口看一下,移动构造之后s1和s3资源的转移。未执行第三行移动构造代码之前,s1内部包含字符串hello world,但在执行过后就可以发现,s1内部的资源被转移到s3去了,s1变成了一个空字符串。
所以,在C++11中,容器也都实现了右值版本的移动构造和移动赋值,以便于在某些场景下能够提高效率,如果拷贝的是一个右值,那么就会对应的调用移动构造和移动赋值,将资源进行转移,而不是进行拷贝一份,此时效率就会提高很多。



7.
最后再说一下关于编译器优化的问题,一般来说越新的编译器优化的就越优,我们看到的现象也就越不明显,所以在测试优化时最好采用较久版本的编译器,比如说vs2013这样的编译器,我用的是vs2022,这款编译器优化的很厉害,对于左边的场景,一般的编译器就算开了优化之后,也需要进行一次拷贝构造,但vs2022连这一次的拷贝构造都优化没了,我都不知道他是怎么做到的,只能说优化太强了,但大部分编译器比如说2019之前的版本的编译器,他们还是比较正常的,对于左边场景下,也就是先构造临时变量,再拷贝构造ret,构造+拷贝构造会直接优化为构造ret,一般编译器都会调用一次拷贝构造,但我的编译器没有调,没调就没调吧,也不影响我学知识嘛。
对于右边的场景来说,编译器是不能优化的,因为被赋值对象是已经存在的,编译器不能直接构造ret,必须以赋值重载的方式来拷贝ret,那就必须需要一个临时变量将str的资源保存下来,然后将临时变量赋值给ret,所以这样的情况下,编译器无法做出优化,那么在平常写代码的时候,尽量写出左边的代码,左边的效率要比右边高一些,因为左边的场景编译器可以进行优化。

4.右值引用价值之二:push_back插入数据(补充知识:const右值引用)
1.
上面所说的右值引用在右值进行拷贝或赋值时,能够减少深拷贝,而是直接将资源进行转移,这其实是右值引用的价值之一,实际右值引用在容器插入数据的时候,也能提高很多的效率。
在C++98里面,下面三行代码的效率是一样的,都需要先进行对象的构造,然后将构造出来的对象作为左值传到链表对象的push_back接口,push_back内部一定会new一个结点出来,将左值参数里的资源重新拷贝一份放到new出来的结点里面。
但在C++11里面,后两行的代码效率要高于第一行,归根结底就是因为参数不再是左值,而是右值,第二行和第三行代码插入时,传参传的都是匿名对象,也就是右值,实际STL容器除实现移动构造和移动赋值外,还实现了右值引用版本的插入数据接口,意思是当插入数据为右值的时候,不会再调用C++98里面const左值引用版本的插入数据接口了,因为C++11现在实现了右值引用的版本接口,在调用时,如果是右值插入则一定优先调用右值引用版本的接口。在push_back内部new结点的时候,不会重新拷贝一份资源出来,而是直接将右值参数的资源转移到new出来的结点内部,减少一次深拷贝,提高效率。
int main()
{list<wyn::string> lt;wyn::string s1("111111");lt.push_back(s1);//lt.push_back(move(s1));lt.push_back(wyn::string("111111"));lt.push_back("111111");//单参数的隐式类型转换return 0;
}
2.
通过运行结果也可以看出,当wyn::string内部实现了移动构造后,list插入数据时,如果插入数据是右值,在new结点调用struct node结点的构造函数时,会调用string类的移动构造,我们自己实现的string类恰好实现了移动构造,所以对于list的插入接口来说,当插入数据为右值时,相比原来C++98只有const左值引用版本的插入接口,对于插入数据涉及到资源申请的时候,效率能提升很多。
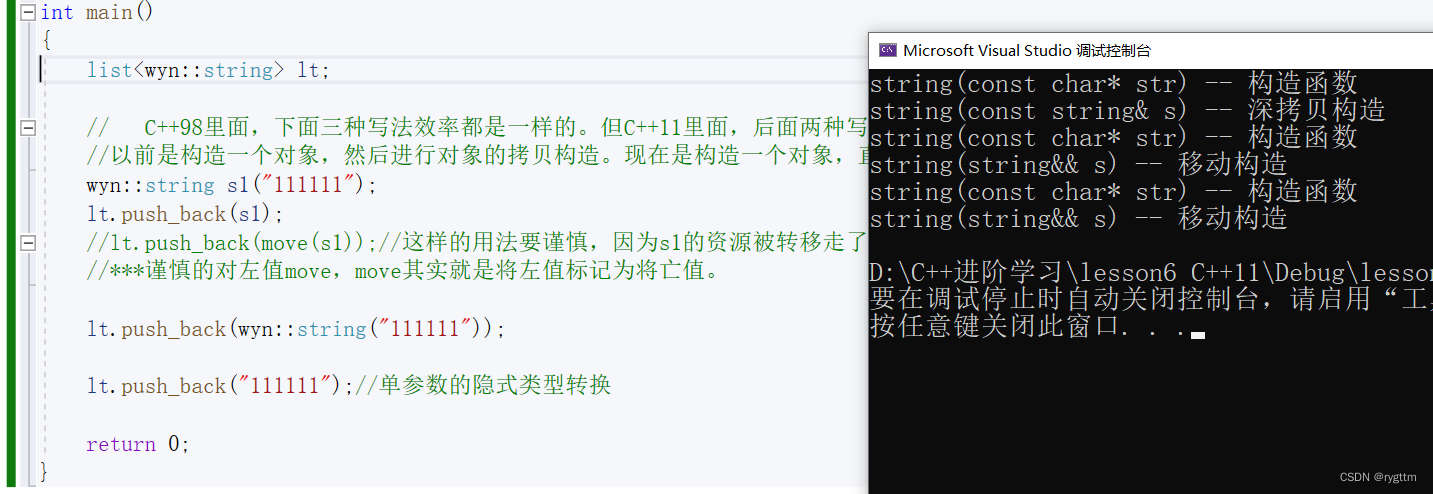
3.
下面再补充一个知识点。除const左值引用外,实际上还有const右值引用,有人可能会问,右值不是不能被修改嘛?你搞一个const右值引用有什么意义啊?你说的没错哈,右值确实不能被修改,但右值引用后的引用对象就变成左值了,像下面的rr1和rr2都是右值引用,但rr1却可以修改,rr2不能被修改。这是为什么呢?实际上当右值被右值引用之后,引用对象就丢失了右值的属性,你可以理解为右值被右值引用之后,右值会被存储到名为引用对象的一个空间当中,此时rr1和rr2实际就变成了左值,丢失了右值的属性,rr1和rr2都能够取地址,因为他们其实各自有一块空间用来存储右值,但rr2是不能被修改的,因为rr2在引用时带有const属性。

4.
知道上面的知识后,也就能解释为什么移动构造或移动赋值或右值引用版本的插入等等接口的参数都是普通右值引用了,因为这些接口都要对右值进行资源的移动,也就是改变右值引用的引用对象,所以右值引用的时候必须是普通的引用,如果用const那就无法实现资源移动了,也就无法实现效率的提升,那右值引用就失去了他的价值。
5.
所以const右值引用用的肯定不多,因为我们用右值引用的目的还是为了转移右值内部资源,你都无法修改右值引用的引用实体,那还转移啥资源啊。
网上有一种说法是右值引用延长了对象的生命周期,其实这句话是错误的,对象该什么时候销毁还是什么时候销毁,右值对象销毁前进行了资源的转移,所以实际上是延长了右值资源的生命周期。
5.改造自己写的list,实现右值引用版本的push_back
1.
实现右值引用版本的push_back并不困难,我们只要重载一个参数为右值引用的push_back就可以了,同样的结点的构造函数以及insert接口也都需要相应的实现右值引用版本,这些都不困难。
但非常容易忽略的一个点就是上面我们提到的那个知识点,右值被右值引用之后,引用实体会丢失右值属性转而变为左值,所以在传递引用实体时,我们必须加move,将其属性再变为右值,这样才能调用到下一个右值引用版本的接口,所以可以看到push_back,insert,list_node等函数在传递右值引用实体时,都需要加move保持其属性依旧为右值,这样才能在层层调用的过程中让引用实体一直保持为右值。
list_node(T&& x):_next(nullptr), _prev(nullptr), _data(move(x))
{}
iterator insert(iterator pos, T&& x)
{node* newnode = new node(move(x));node* cur = pos._pnode;node* prev = cur->_prev;//prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);
}
void push_back(T&& x)
{insert(end(), move(x));//如果仅仅只传x,则会调到insert的普通版本,因为右值引用之后x变成左值,所以还需要move//insert(end(), std::forward<T>(x));//move是强制转成右值了,完美转发是保持属性不变。
}
2.
在改造lisi过后,从打印结果就可以看到,当push_back的元素是右值时,我们自己实现的list也能够很好的完成右值引用版本的插入,不再进行像const左值引用版本的资源拷贝,而是直接移动右值资源,下面的四行代码,相比C++98的插入元素接口,减少了四次深拷贝,效率很不错。所以C++11新增的右值引用还是非常有货的,不像decltype那样鸡肋,而是实实在在的有用。

6.万能引用和完美转发( 函数模板std::forward< T >() )
1.
上面在解决右值在右值引用过后属性丢失,但是需要连续给多个接口传参的问题时,采用了不断move的方式来解决,以此来保持传递参数过程中右值的属性能够保持不变。
但这样的解决方式并不被青睐,C++11又推出了一种新的解决方式,叫做完美转发。在了解完美转发之前,还需要了解万能引用。
2.
&&这样的引用方式我们都知道他是右值引用,但&&在模板中并不代表右值引用,他有新的名词,叫做万能引用,所谓万能引用就是什么类型的参数都可以接收,包括普通左值,普通右值,const左值,const右值,万能引用都可以接收。
推演实例化的时候,也会由于参数的不同相应实例化出不同的函数实体,如果传过来的是左值,&&在接收的时候,会发生引用折叠,也就是由两个&变为一个&,从形式上的右值引用折叠为左值引用。
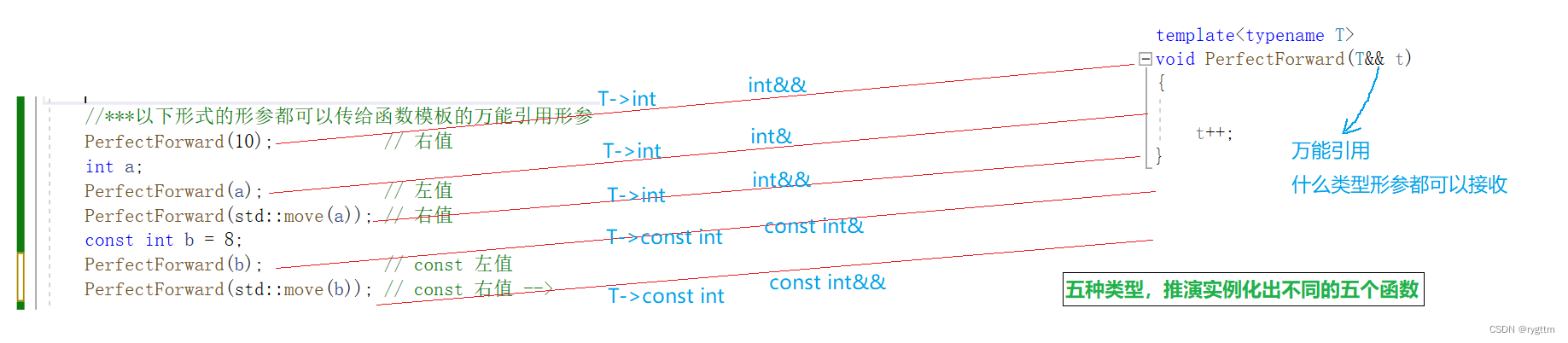
3.
那如果在函数模板内部,要调用Fun函数呢?我们想保证在调用的时候,依旧可以调用到对应参数类型的函数,也就是保持参数的属性不变。
如果此时直接调用Fun,并将t参数传过去,就会发生我们之前所说的问题,右值被右值引用过后属性丢失,引用对象重新变为左值,那t就会作为左值传递给Fun函数,所以就只能调用到const左值引用和左值引用版本的Fun函数,无法调到右值版本的函数了。
如果想要调用右值版本的函数,就需要借助move左值,将左值搞成右值,这样就可以调用到右值版本的Fun函数了,但这样的话又无法调到左值版本的Fun函数了,哎呦,真是难搞啊,属性老是丢失,该怎么办啊?
C++11此时就提出了完美转发:函数模板std::forward< T >(),此函数可以帮助我们在调用某些函数进行传参时,保证参数的原有属性不变。有了完美转发后,在上面改造list的时候,我们也可以不用不断move左值的方式向下传参,可以直接使用完美转发这个函数模板,保持参数原有属性不变。

void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
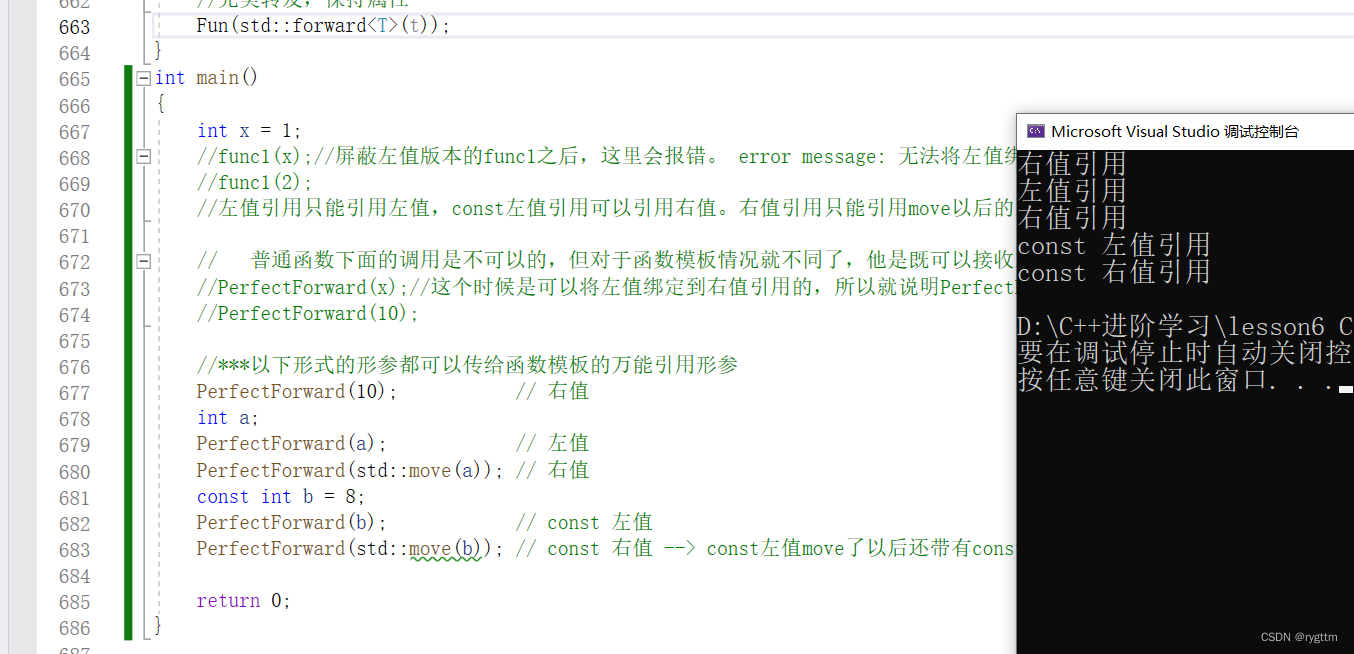
void Fun(const int&& x) { cout << "const 右值引用" << endl; }template<typename T>
void PerfectForward(T&& t)
{//*** t可能是左值,也可能是右值,所以如果Fun在函数模板里面作为中转层,无法很好保留参数的属性。Fun(t);//t作为参数往下一传,其实就是作为左值传下去了。Fun(move(t));//move一下也不行,那就又全变成右值引用了。Fun(std::forward<T>(t));//完美转发,保持属性
}
int main()
{//***以下形式的形参都可以传给函数模板的万能引用形参PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值 --> const左值move了以后还带有const的属性return 0;
}
五、类的新功能
1.新增成员函数
1.
在C++98中,类的默认成员函数有六个,在C++11中新增了两个默认成员函数,分别为移动构造和移动赋值。
如果你自己没有实现移动构造函数,并且没有实现析构函数,拷贝构造,拷贝赋值这三个函数,那么编译器会自动默认生成一个移动构造,该移动构造对内置类型完成逐字节拷贝,对自定义类型需要看该自定义类型是否实现移动构造,如果实现移动构造就调用移动构造,如果没有实现就调用拷贝构造。
如果你自己没有实现移动赋值函数,并且没有实现析构函数,拷贝构造,拷贝赋值这三个函数,那么编译器会自动默认生成一个移动赋值,该移动赋值对内置类型完成逐字节拷贝,对自定义类型需要看该自定义类型是否实现移动赋值,如果实现移动赋值就调用移动赋值,如果没有实现就调用拷贝赋值。
当内置类型涉及资源申请的时候,编译器默认生成的移动构造或移动赋值是无法完成任务的,所以这种时候需要我们自己写移动构造或移动赋值。
2.
编译器默认生成的移动构造和赋值的要求太严苛了,那如果我们不小心破坏了生成的条件,但是还想使用编译器默认生成的该怎么办呢?也很简单,可以用一个关键字default强制编译器生成默认的成员函数。
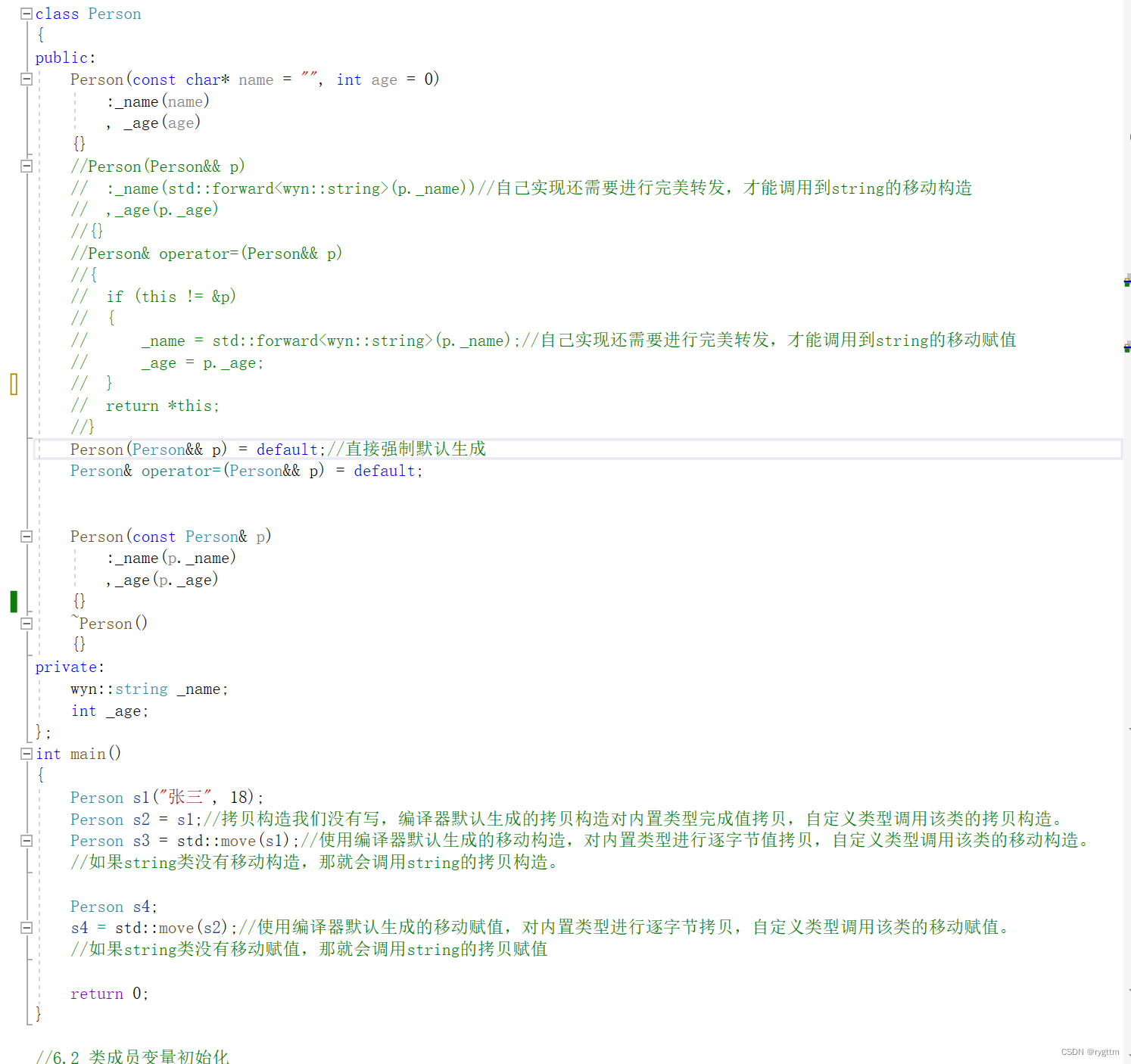
2.类成员的初始化(缺省值,default,delete)
1.
由于构造函数对内置类型不处理,所以C++11在成员变量打了补丁,即允许在类定义的时候,给成员变量缺省值,这个缺省值会在构造函数的初始化列表使用,进行成员变量的初始化。别忘记拷贝构造也是构造函数,他们两个构成重载关系,拷贝构造也有初始化列表。
2.
default关键字在上面的部分已经见到过了,他的作用其实就是强制编译器生成默认的成员函数。
假设我们现在要实现一个不能被拷贝的类,也就是这个类的对象不允许被拷贝,这种场景叫做防拷贝,某些类的成员并不想被拷贝。我们该怎么解决这个问题呢?
C++98中,可以采用的方式就是拷贝构造函数设置为私有,这样在类外面如果有人想要进行对象的拷贝,他肯定是调不到拷贝构造函数的,这样的解决方式可以防止类外面进行对象的拷贝。
那如果类内的某个公有函数进行了对象的拷贝呢?设置为私有的方式就无法解决了,因为访问限定符只能限制类外,无法限制类内,这样的场景又该怎么办呢?其实还有一种方法,就是只声明不实现,这样就会报链接错误,因为编译阶段生成的符号表存的拷贝构造函数的地址是无效的,所以链接阶段通过地址找拷贝构造函数的定义时,就会发生链接错误,所以这样的方式也可以防拷贝。
上面都是C++98的解决方式,C++11中没有这么麻烦,只需要delete关键字就可以解决,在拷贝构造的声明处加上delete修饰即可,如果有人进行对象的拷贝,则编译期间就会报语法错误。

六、lambda表达式(叫表达式,其实是可调用对象)
1.lambda表达式的用法和本质
1.
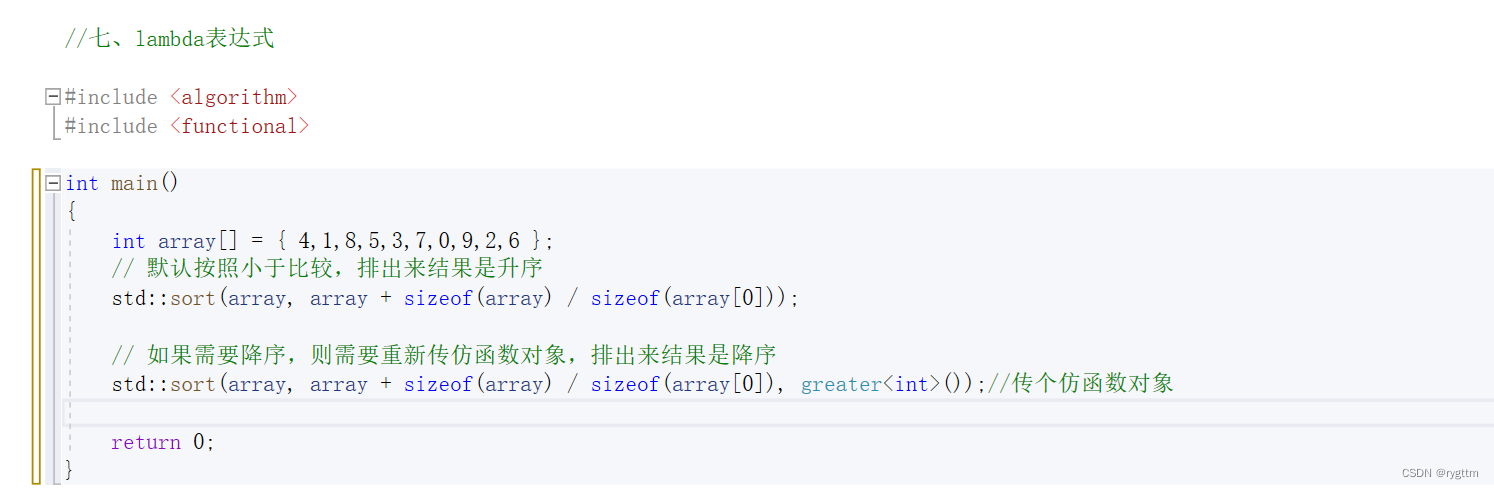
C++觉得C语言的函数指针太恶心了,C++进而就搞出来仿函数对象,仿函数实际是一个重载了operator()的一个类,比如下面进行排序的场景,调用库的sort时,sort函数模板的第三个参数的缺省值就是less< T >()仿函数对象,默认排升序,如果想要排降序,只需要传一个greater< T >()仿函数对象即可。
2.
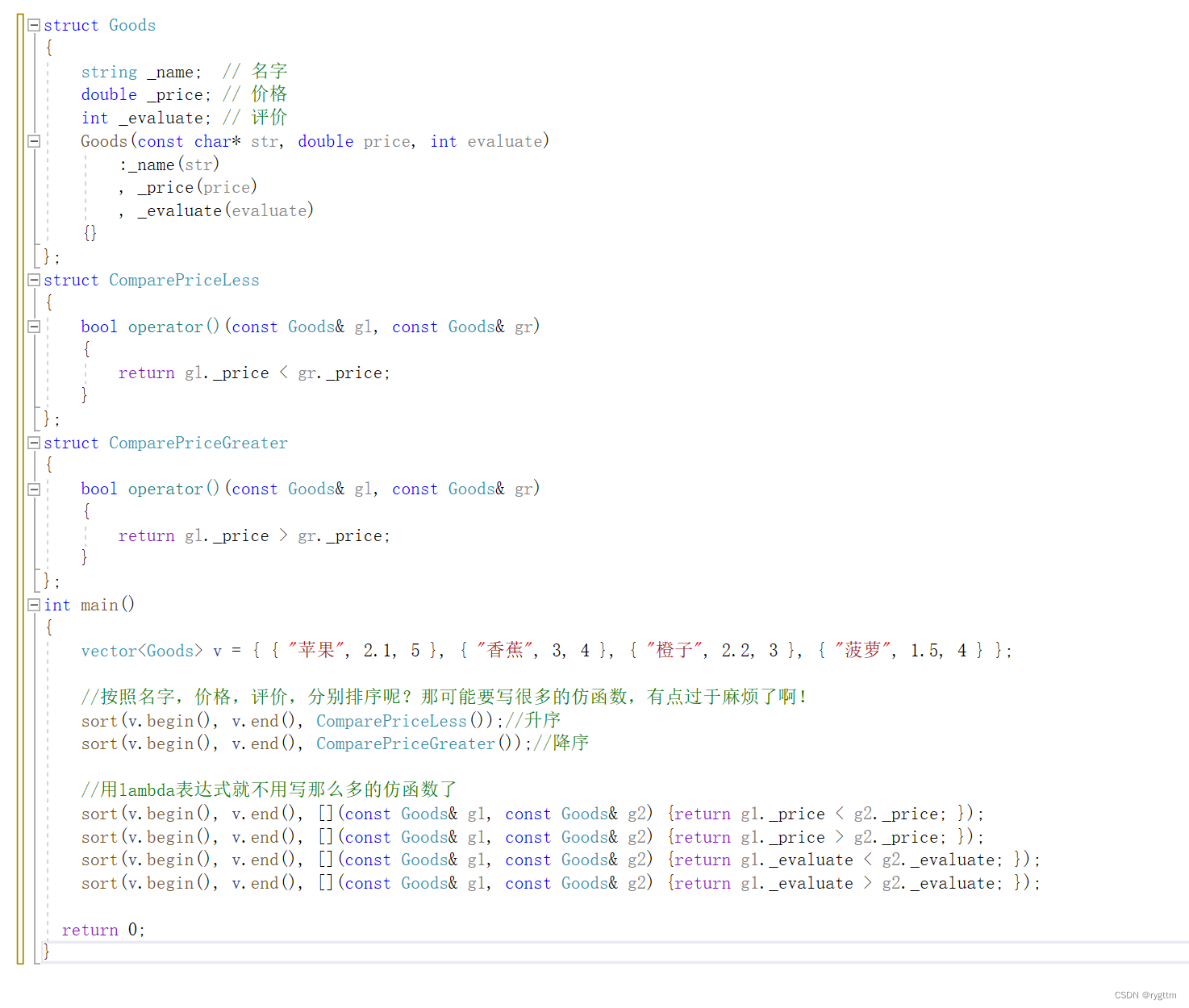
那如果需要比较的性质特别多呢?比如要比较商品的名字,价格,评价等等,并且要实现从小到大和从大到小的仿函数,那我们就需要实现6个仿函数,这样岂不是太繁琐了,写6个struct类,如果类的命名不太好,比如按照1-6来命名类,那看代码的人每看到一个仿函数都需要向上去找对应的仿函数看看具体是什么功能,这样也太麻烦了吧!
C++此时觉得光有一个仿函数可调用对象有点不太够啊,能不能再搞出一个比仿函数用起来还舒服的对象呢?此时lambda表达式就登场了,lambda表达式的本质也是一个可调用对象,此时就无需再实现仿函数类什么的了,我们直接写一个lambda表达式给sort传过去,这样就可以一行代码搞定传可调用对象的问题了。
3.
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters): 参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable: 默认情况下,lambda传值捕捉变量时,默认是const传值捕捉,mutable可以取消其常量
性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype: 返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}: 函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量
4.
sort内部进行排序的时候,会依次向后两两比较vector的元素,在比较时就会用我们传的可调用对象进行比较,然后给可调用对象传两个vector元素过去,根据比较结果开始进行排序,所以lambda表达式和仿函数对象一样都是可调用对象,lambda表达式的参数也和仿函数类一样,都是Goods类对象的常引用。
5.
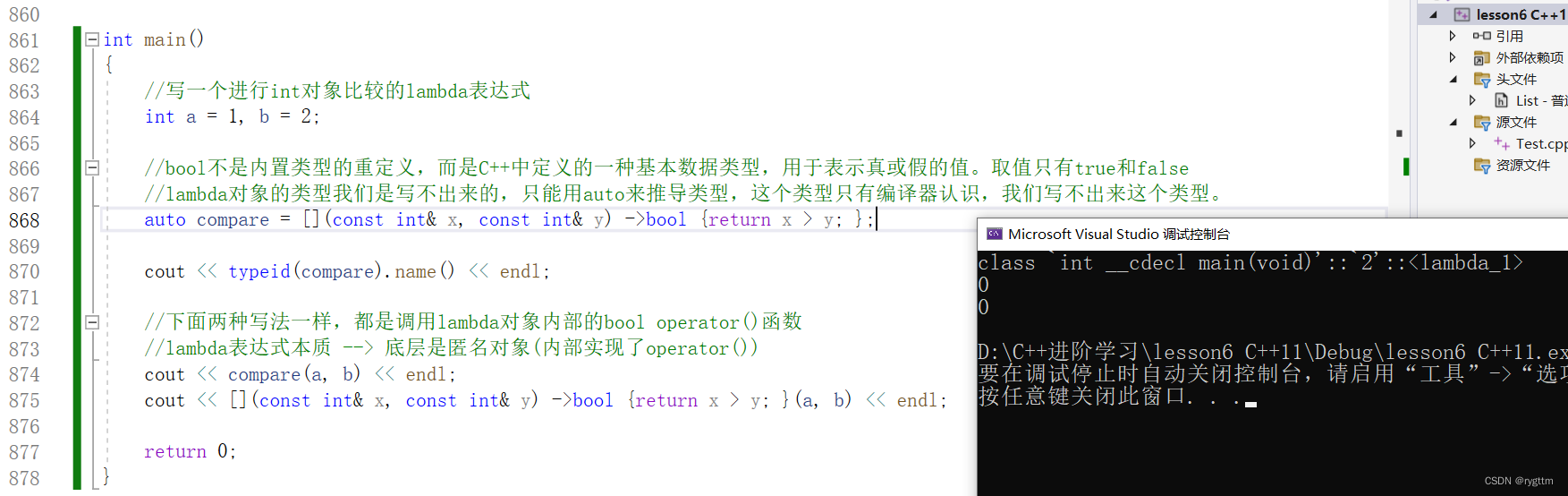
值得注意的是,lambda表达式的类型我们是写不出来的,这个类型是编译器自己生成的,所以这也就注定限制了我们使用lambda表达式的语法,像下面代码一样,我们只能用auto关键字自动推导lambda类型定义出compare对象,或者直接拿lambda这个匿名对象进行调用,只有这两种使用方式。
补充知识点: 使用宏的时候,换行时需要加续行符,因为宏必须是完整的一行,连空格都不能有。其他场景不需要加续行符。
6.
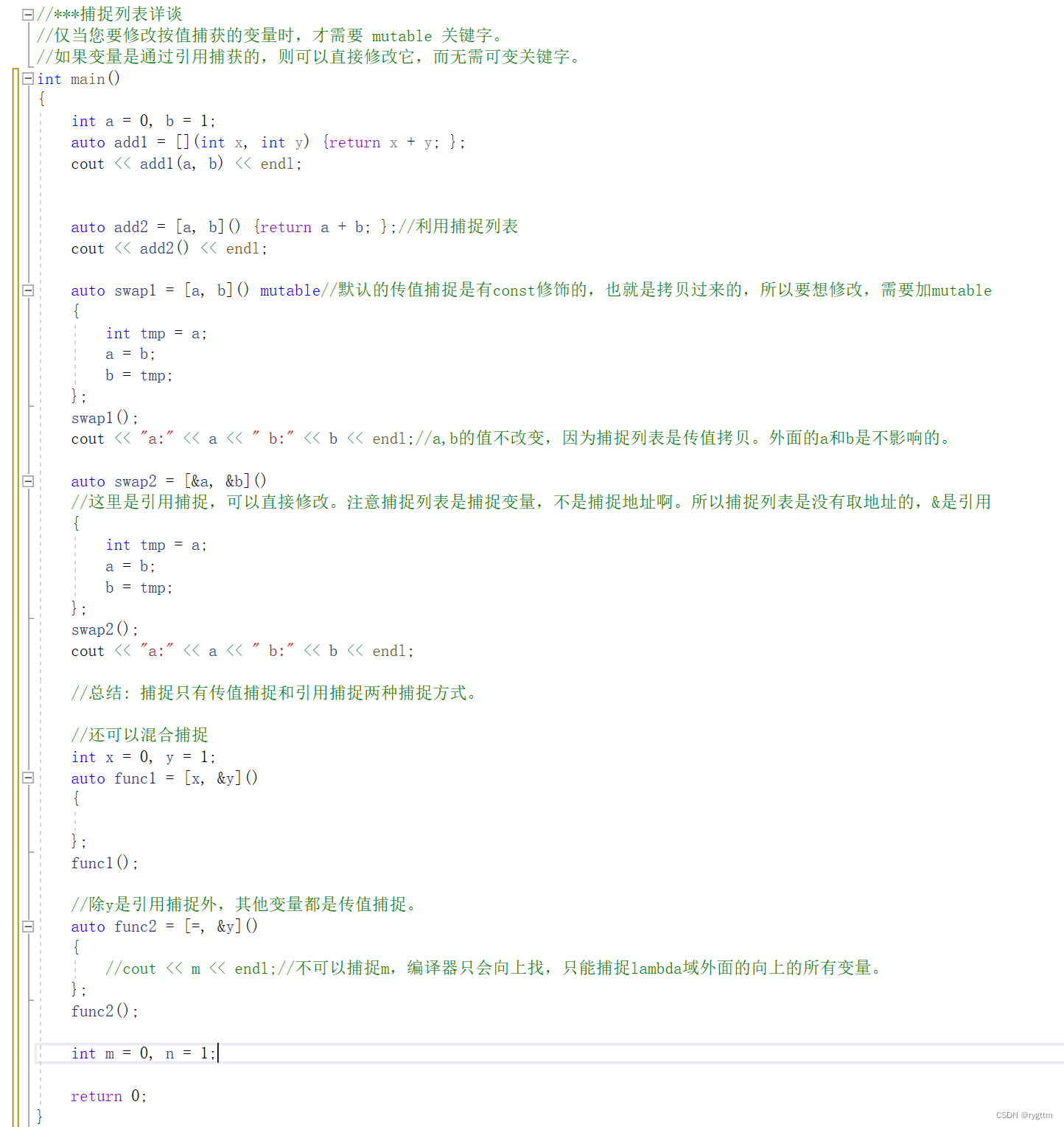
捕捉列表可以捕捉lambda外面的所有变量,但前提是这些变量都得在lambda表达式的上面。lambda的函数体除能够使用参数列表被别人传过来的值外,还可以使用捕捉列表里面所捕捉到的变量。
捕捉变量的方式有两种,分为传值捕捉和传引用捕捉,传值捕捉是const修饰的,所以如果想要修改传值捕捉的变量,则可以利用mutable来修饰,即取消传值捕捉变量的const属性。传引用捕捉并没有const修饰,可以直接修改,无需可变关键字。
捕捉列表中只有=时,代表传值捕捉lambda父作用域中lambda表达式向上的所有变量,如果有this指针则也可以捕捉this指针。
捕捉列表中只有&时,代表传引用捕捉lambda父作用域中lambda表达式向上的所有变量,如果有this指针则也可以捕捉this指针。
捕捉列表不允许变量重复传递,否则就会导致编译错误。 比如:[=, a]:=已经以值传递方式捕捉了所有变量,再次捕捉a变量重复。
7.
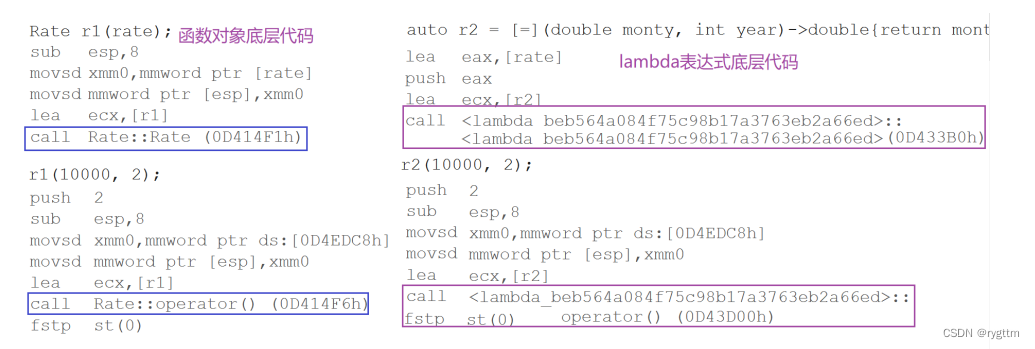
我们还需要了解一下lambda底层到底是什么,其实lambda底层就是仿函数对象,编译器自动生成了一个lambda的类,并在这个类里面实现了operator(),这个类是编译器自己生成的,每一个lambda的类都是不一样的,执行lambda函数体实际还是执行lambda类里面的operator(),所以本质上lambda和仿函数一样,只不过仿函数的类是我们自己写的,lambda的类是编译器自己随机生成的。

8.
C++允许使用一个lambda表达式拷贝构造一个新的副本,但不允许lambda表达式之间相互赋值。在了解lambda的底层之后,我们就可以理解了,因为各个lambda表达式的类都不一样,所以各个lambda表达式对象都没有关系,不能调用拷贝赋值函数。
但拷贝构造还是可以的,因为lambda还没初始化出来嘛,赋值是已经存在一个lambda对象了,拷贝构造就相当于搞出来一个lambda的副本,和原来的lambda共用编译器随机生成的同一个类。
void (*PF)();
int main()
{auto f1 = []{cout << "hello world" << endl; };auto f2 = []{cout << "hello world" << endl; };//f1 = f2; // 编译失败--->提示找不到operator=()// 允许使用一个lambda表达式拷贝构造一个新的副本auto f3(f2);f3();// 可以将lambda表达式赋值给相同类型的函数指针,本质都是可调用对象嘛!PF = f2;PF();return 0;
}
2.配合多线程使用lambda表达式
1.
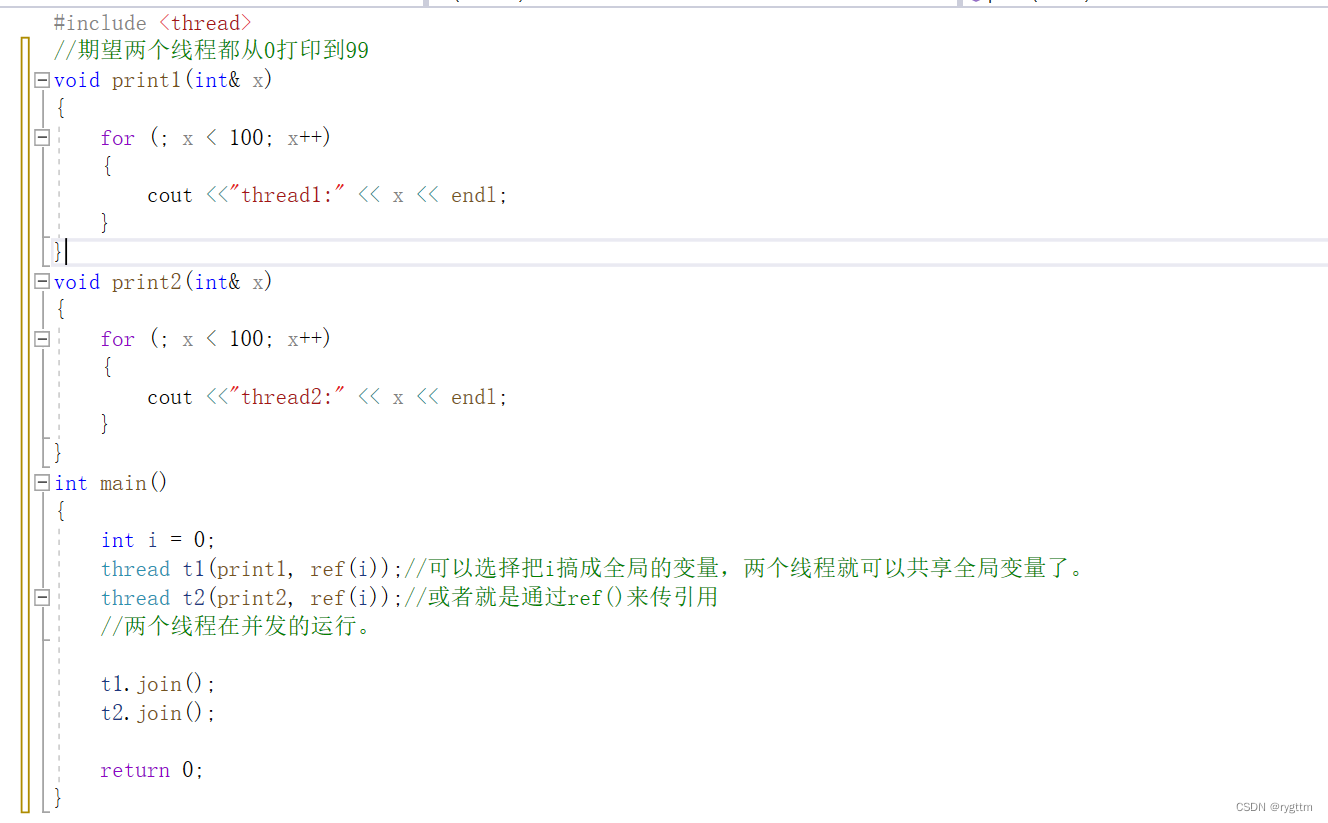
假设我们期望两个线程并发式的从0打印到99,我们可以选择实现两个函数,然后分别让线程并发的去运行,这样的方式其实就是给线程传函数指针,函数指针就是可调用对象嘛,线程刚好可以执行。
2.
除上面那种方式外,我们其实还可以利用lambda表达式,在创建线程的同时传可调用对象lambda过去,lambda引用捕捉一下i就可以,要注意区分参数列表和捕捉列表,虽然捕捉列表看上去像是在传参,但实际并不是传参,仅仅是捕捉变量而已。
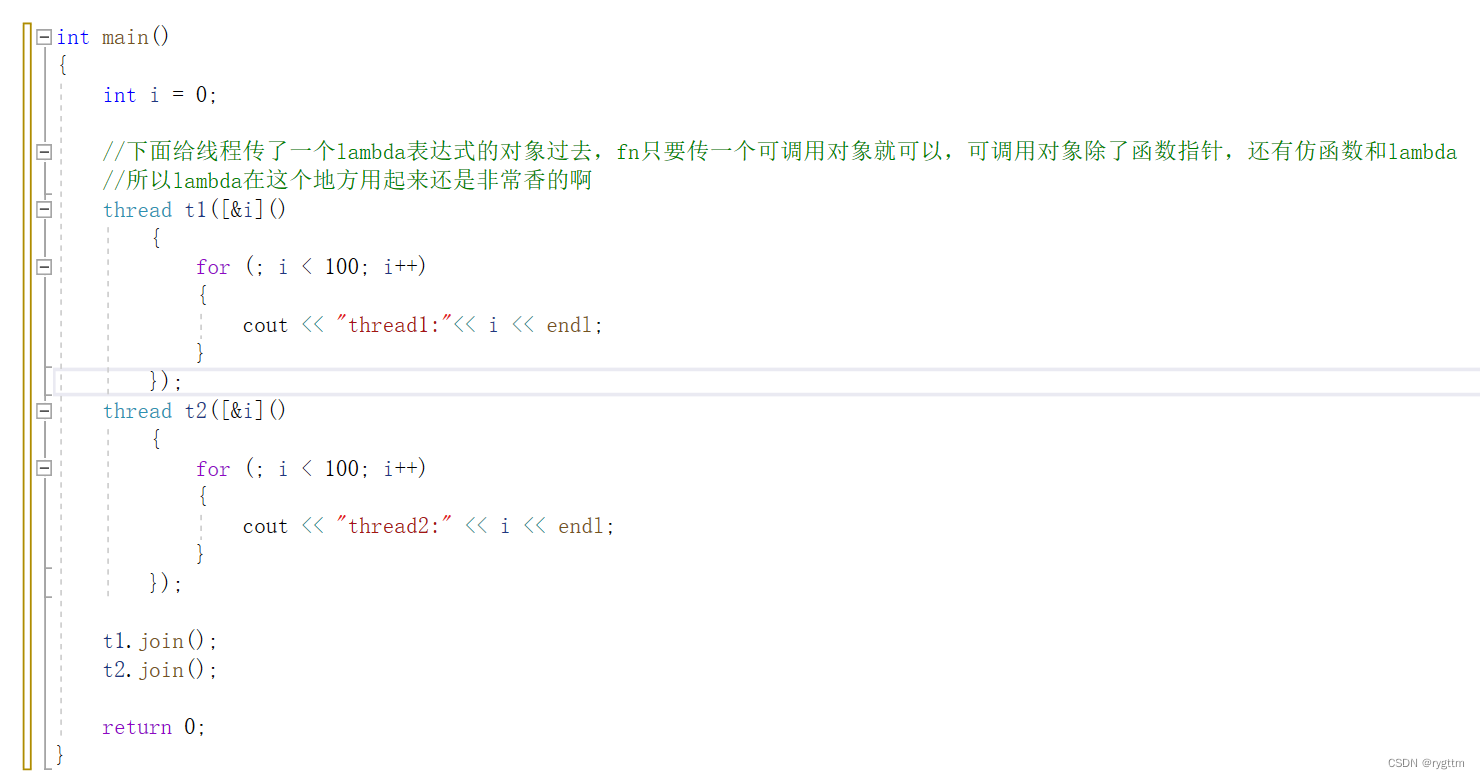
3.
下面的使用方式灵活的体现了C++面向对象的特性,我们将线程当作对象存储到容器vector里面,创建线程的同时将lambda可调用对象传给线程,这样所有的线程就会同时并发的打印0-99数字。

七、可变参数模板
1.展开参数包的两种方式(递归展开,借助数组推开参数包)
1.
C++新引入了可变参数模板的语法,即函数的参数可为一个参数包,这个参数包中可以包含任意个数的函数形参,想打印出参数包中参数的个数,可以通过sizeof…()函数取到参数包中参数的个数。

2.
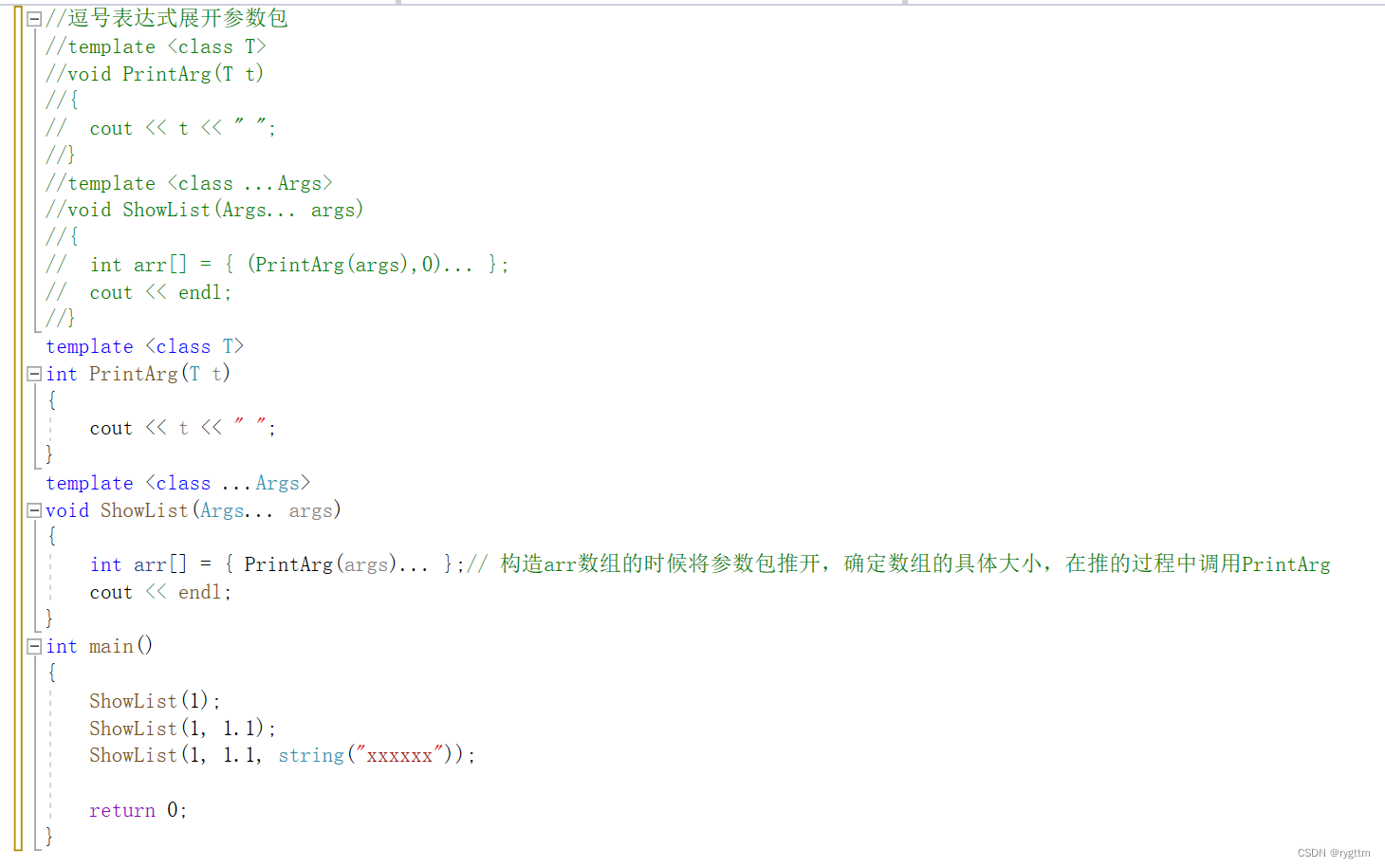
下面是第一种展开参数包的方式,即递归方式调用ShowList,递归结束条件就是参数个数为0的ShowList()函数,在不断递归调用ShowList的过程中,参数个数会逐渐减少,直到args…的个数为0时,此时递归结束,调用无参的ShowList即可。

3.
下面是第二种展开参数包的方式,上面那种方式需要多增加一个模板参数T,用T定义出的val来表示单个的参数。
下面是通过辅助数组arr来实现推开参数包,在推的过程中调用PrintArg来打印出每个参数是什么,每推出来一个参数,就会调用对应的PrintArg函数进行参数的打印。
第一种屏蔽的方式就是逗号表达式,他会在推参数包的过程中顺便将arr数组初始化为0,但其实不初始化也没有关系,直接推参数包也行。
2.对比emplace和insert(使用语法 和 插入的效率)
1.
C++11新引入的emplace接口既有可变参数模板,又有万能引用,看起来很牛嘛,那他真的比insert接口效率高很多嘛?实际上并没有高很多,可能也就强那么一点点。

2.
在使用形式上,emplace支持直接传参数,不用自己构造键值对,调用像push_back和insert这样的接口时,需要先构造出键值对,然后调用移动构造版本的push_back函数进行键值对的插入,而emplace直接传pair键值对的俩参数就可以,emplace会直接用这个参数包构造出pair对象,并将对象插入到mylist里面。
所以在使用形式上emplace比push_back更加简洁一些,因为只需要传参数就可以。当然你如果也想构造键值对进行插入,emplace也是可以做到的。

3.
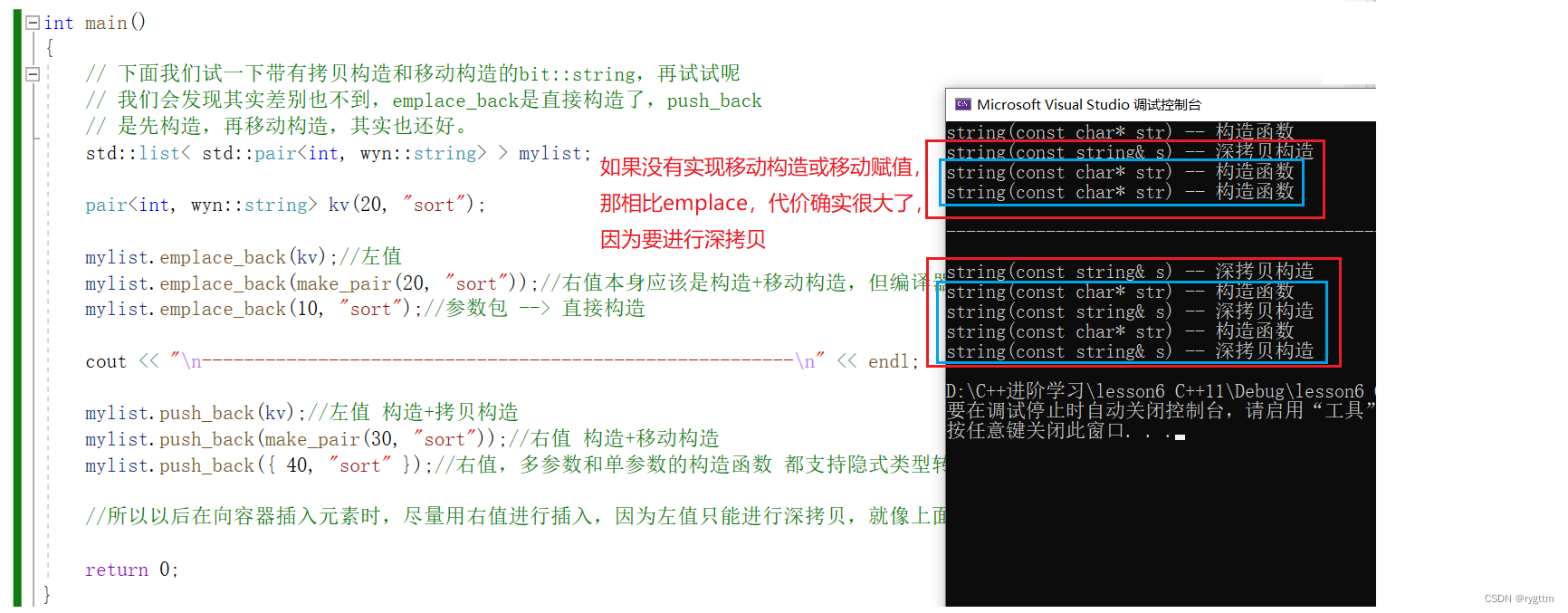
在效率上面两者的差距也不大,一个是直接构造,一个是先直接构造然后再移动构造。所以emplace也没有那么的牛,因为移动构造的代价也很低,只能说emplace比insert稍微强一点吧!(emplace对标insert,emplace_back对标push_back)
但如果string没有实现移动构造的话,那两者差距还是挺大的,一个是直接构造,一个是先直接构造然后再深拷贝。但我们不用担心这一点,下面代码是拿我们自己实现的string测试的,STL里面的容器哪个没有实现移动构造啊!所以这两个接口的效率差距也不大,甚至可以忽略不计。

下面是string实现了移动构造的场景

下面是string没有实现移动构造的场景
八、function包装器
1.对学过的所有可调用对象进行包装
1.
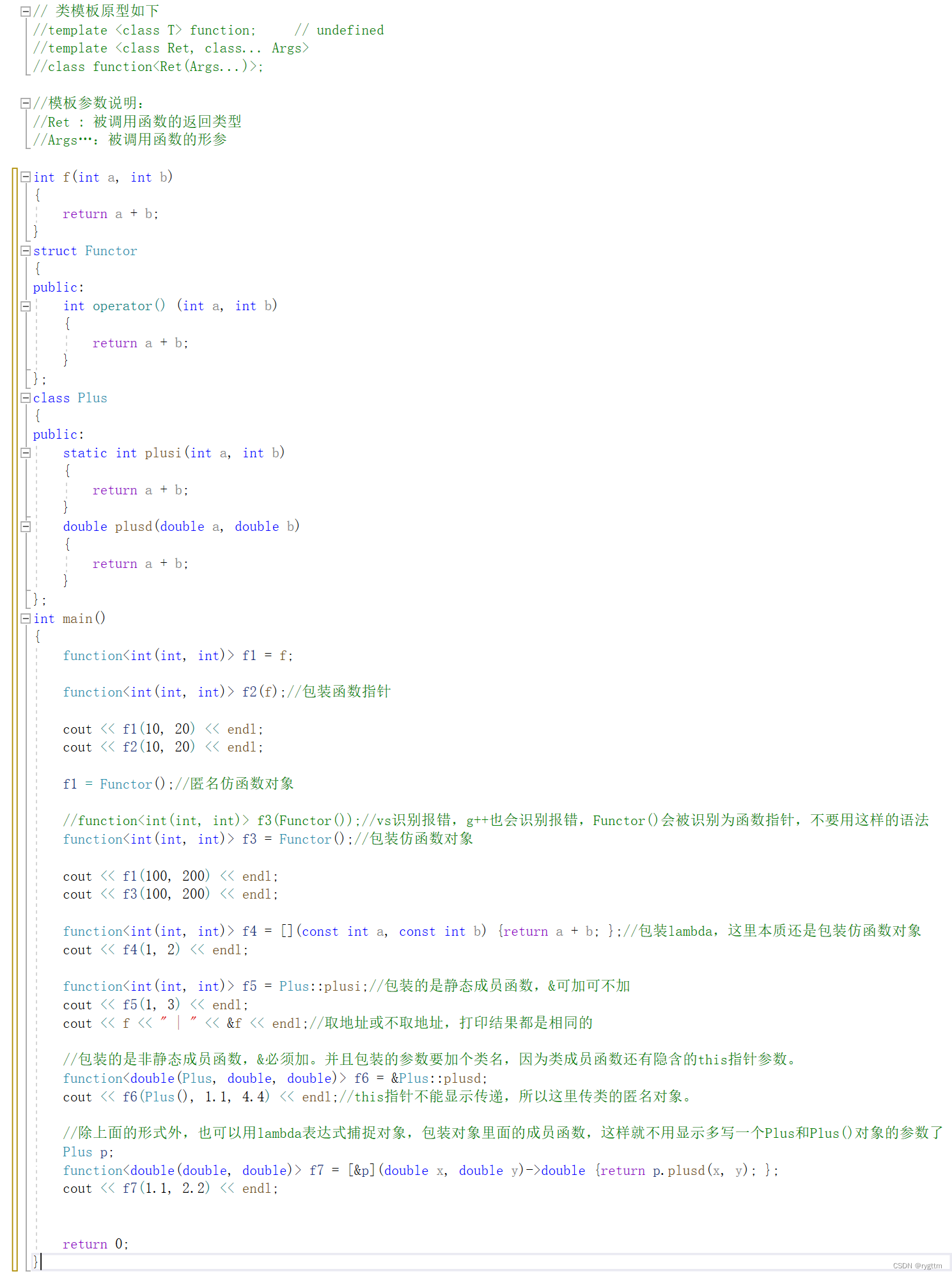
function就像范围for一样都是语法糖,看起来很牛逼,底层的实现并不复杂,function用起来还是非常香的,语法很简单,并且很好用,C++委员会总算干点儿正事了。
function学起来并不困难,他其实就是将我们原来所学的可调用对象,例如函数指针,仿函数对象,lambda进行包装,使其变成一个新的可调用对象,这个可调用对象就是包装器,有人说为什么要包装啊?以前的可调用对象用起来不是挺好的吗?你说的没错,但是包装过后,无论你是什么类型的可调用对象,在使用形式上统一都是包装器定义出来的对象的使用形式,在语法上更加的便捷。
2.
对于下面函数模板useF来说,如果传函数指针,仿函数对象,lambda就会导致模板实例化出三份不同的函数实体来,导致模板的效率有些低。但如果我们将上面三个可调用对象进行包装,那就只会实例化出一份函数实体,但是却依靠这一份函数实体,实现了三种可调用对象的调用,不用像原来一样实例化出三份函数实体分别去调用函数指针,仿函数对象,lambda,这就是包装器带来的价值。
3.
事实上,你可以这么理解包装器,包装器也是一个仿函数对象,他的内部也实现了operator(),但他的operator()内部又调用了包装器包装的可调用对象的operator(),所以包装器这个类可以理解为他内部封装了三个可调用对象的operator(),在调用时根据不同的可调用对象,去调用包装器内部对应的operator()。
这里有点像多态,可调用对象是函数指针,那就调对应封装函数指针的包装器。可调用对象是函数对象,那就调对应封装函数对象的包装器。可调用对象是lambda,那就调对应封装lambda的包装器。
2.逆波兰表达式求解–包装器的使用
1.
像下面这样命令和动作对应的场景,其实就可以用包装器,让包装器包装lambda,然后把string和包装器对象构成的键值对存储到map里面,建立命令和动作的映射关系。
在调用对应的lambda时,我们就不用写一长串lambda然后加上(x,y)这样的调用方式了,而是直接用function包装器加上(x,y)这样的调用方式。
所以function用起来还是很香的。

3.bind绑定的用法
1.
bind绑定其实和function是一种适配器模式,就像vector适配出stack,list适配出queue一样。
bind的用法也是花里胡哨的,下面列出了两种bind的用法。
一种是调整参数的顺序,通过调整占位对象来实现。
另一种是固定绑定参数,在绑定类成员函数时,function要在模板参数第一个位置加类名,在调用的时候也需要先传一个该成员函数所属类的对象(平常我们直接传匿名对象了就),这样用起来有点烦,所以可以在绑定类成员函数的同时,固定第一个参数为类的匿名对象,这样在使用包装器调用类成员函数的时候,就不需要再显示传一个匿名对象了。

2.
下面是绑定在控制参数时的用法,我们可以在绑定的同时给可调用对象显示传参数,也可以用占位对象_1 _2 _3…等等来替代参数位置,等待包装器调用的时候再传参数。
相关文章:
【C++】C++11常用特性总结
哥们哥们,把书读烂,困在爱里是笨蛋! 文章目录 一、统一的列表初始化1.统一的{}初始化2.std::initializer_list类型的初始化 二、简化声明的关键字1.decltype2.auto && nullptr 三、STL中的一些变化1.新增容器:array &…...

泛型——List 优于数组
数组与泛型有很大的不同: 1. 数组是协变的(covariant) 意思是:如果Sub是Super的子类型,则数组类型Sub[] 是数组类型Super[] 的子类型。 2. 泛型是不变的(invariant) 对于任何两种不同的类型Ty…...

JavaScript中对象的定义、引用和复制
JavaScript是一种广泛使用的脚本语言,其设计理念是面向对象的范式。在JavaScript中,对象就是一系列属性的集合,每个属性包含一个名称和一个值。属性的值可以是基本数据类型、对象类型或函数类型,这些类型的值相互之间有着不同的特…...

JavaScript通过函数异常处理来输入圆的半径,输出圆的面积的代码
以下为实现通过函数异常处理来输入圆的半径,输出圆的面积的代码和运行截图 目录 前言 一、通过函数异常处理来输入圆的半径,输出圆的面积 1.1 运行流程及思想 1.2 代码段 1.3 JavaScript语句代码 1.4 运行截图 前言 1.若有选择,您可以…...

Ubuntu 安装 Mysql
主要内容 本文主要是实现在虚拟机 Ubuntu 18.04 成功安装 MySQL 5.7,并实现远程访问功能,以 windows 下客户端访问虚拟机上的 mysql 数据库。 1. 切换至 root 用户 ,shell 终端指令均执行在 root 用户下 sudo su 2. 安装并设置 mysql 安…...

【五一创作】【Midjourney】Midjourney 连续性人物创作 ② ( 获取大图和 Seed 随机种子 | 通过 seed 随机种子生成类似图像 )
文章目录 一、获取大图和 Seed 随机种子二、通过 seed 种子生成类似图像 一、获取大图和 Seed 随机种子 注意 : 一定是使用 U 按钮 , 在生成的大图的基础上 , 添加 信封 表情 , 才能获取该大图的 Seed 种子编码 ; 在上一篇博客生成图像的基础上 , 点击 U3 获取第三张图的大图 ;…...
分布式事务 --- Seata事务模式、高可用
一、事务模式 1.1、XA模式 XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。…...

SQL(基础)
DDL: 数据定义语言 Definition,用来定义数据库对象(数据库、表、字段)CREATE、DROP、ALTER DML: 数据操作语言 Manipulation,用来对数据库表中的数据进行增删改 INSERT、UPDATE、DELETE 注意: DDL是改变表的结构 DML…...

「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验
「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验 一、前言1.1 本次实践介绍1.2 本次实践目的 二、准备环境资源2.1 部署前需准备工作2.2 本地环境规划 三、部署Docker环境3.1 安装Docker3.2 配置Docker镜像加速3.3 开启路由转发3.4 重启Docker服务 四、检查本地Doc…...
计算机操作系统实验:银行家算法模拟
目录 前言实验目的实验内容实验原理实验过程代码如下代码详解算法过程运行结果 总结 前言 本文是计算机操作系统实验的一部分,主要介绍了银行家算法的原理和实现。银行家算法是一种用于解决多个进程对多种资源的竞争和分配的算法,它可以避免死锁和资源浪…...
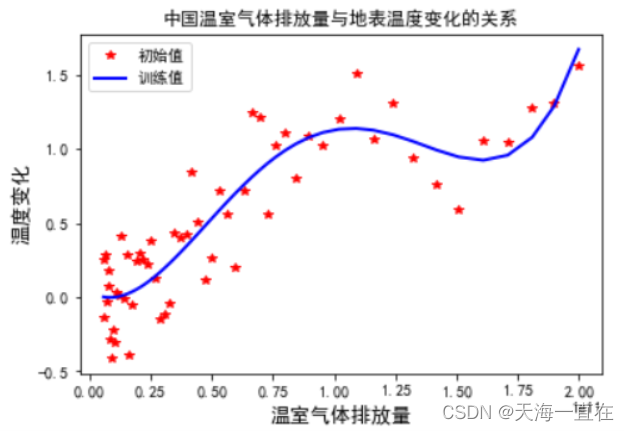
机器学习:多项式拟合分析中国温度变化与温室气体排放量的时序数据
文章目录 1、前言2、定义及公式3、案例代码1、数据解析2、绘制散点图3、多项式回归、拟合4、注意事项 1、前言 当分析数据时,如果我们找的不是直线或者超平面,而是一条曲线,那么就可以用多项式回归来分析和预测。 2、定义及公式 多项…...

一个 24 通道 100Msps 逻辑分析仪
这是一个创建非常便宜的逻辑分析仪的项目,但其功能可与昂贵的商业分析仪相媲美。该分析仪可以以每秒 1 亿个样本的最高速度对多达 24 个通道进行采样,并且可以通过单个通道中的极性变化或多达 16 个通道形成的模式来触发。 该项目不仅包含硬件࿰…...

使用Process Explorer和Dependency Walker排查C++程序中dll库动态加载失败问题
目录 1、exe主程序启动时的库加载流程说明 2、加载dll库两种方式 2.1、dll库的隐式引用...
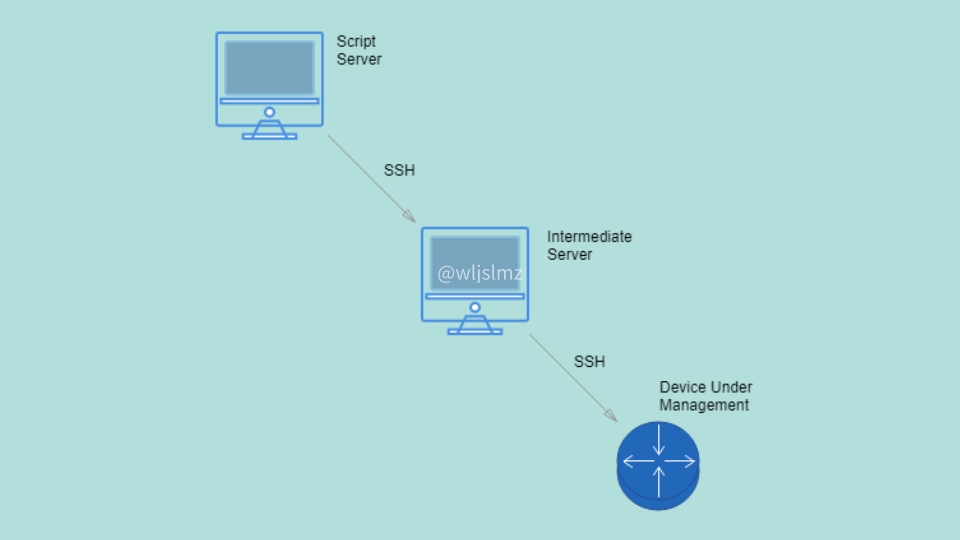
网工Python:如何使用Netmiko的SCP函数进行文件传输?
在网络设备管理中,传输配置文件、镜像文件等是经常需要进行的操作。Netmiko是一个Python库,可用于与各种网络设备进行交互,提供了一些用于传输文件的函数,其中包括SCP(Secure Copy Protocol)函数。本文将介…...
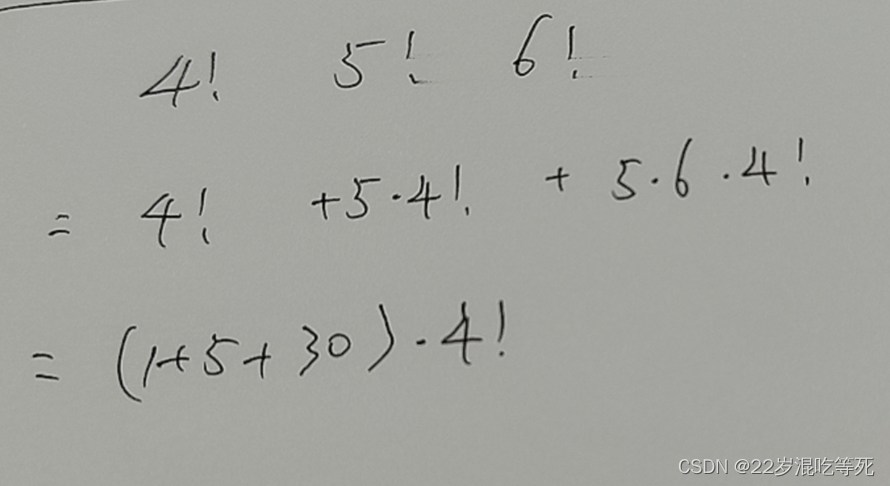
题目 3166: 蓝桥杯2023年第十四届省赛真题-阶乘的和--不能完全通过,最好情况通过67.
原题链接: 题目 3166: 蓝桥杯2023年第十四届省赛真题-阶乘的和 https://www.dotcpp.com/oj/problem3166.html 致歉 害,首先深感抱歉,这道题还是没有找到很好的解决办法。目前最好情况就是67分。 这道题先这样跳过吧,当然以后还…...
 介绍)
ChatGPT- OpenAI 的 模型(Model) 介绍
ChatGPT的火爆程度大家都知道了,该章节我们来了解一下 ChatGPT 一个关键概念 - 模型(Model)。主要是为大家介绍一下在 OpenAI 中,究竟有哪些模型可以使用。 在后续的章节,我们会分单独的小章节逐一的为大家介绍各个不同模型的调用以及接口参…...

X 态及基于 VCS 的 X-Propagation 检测
🔥点击查看精选 IC 技能树系列文章🔥 🔥点击进入【芯片设计验证】社区,查看更多精彩内容🔥 📢 声明: 🥭 作者主页:【MangoPapa的CSDN主页】。⚠️ 本文首发于CSDN&#…...
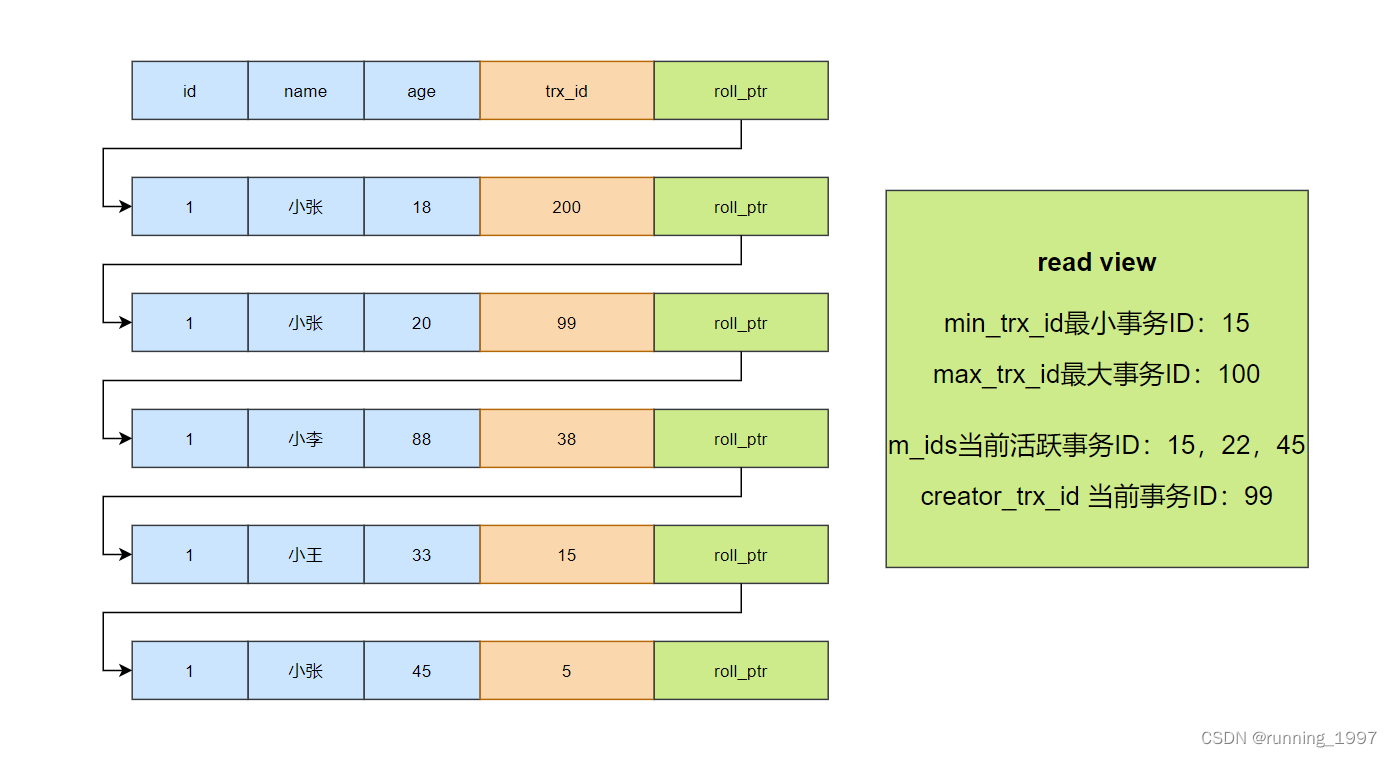
数据库之事务隔离级别详解
事务隔离级别详解 一、事务的四大特性(ACID)1. 原子性(atomicity):2. 一致性(consistency):3. 隔离性(isolation):4. 持久性(durability): 二、事务的四种隔离级别1. 读未提交(Read uncommitted)࿱…...

守护进程、僵尸进程、孤儿进程
守护进程、僵尸进程、孤儿进程 守护进程(Daemon Process) 定义 守护进程又称Daemon进程(精灵进程),是Linux中的后台服务进程。 它的生命周期较长,通常独立于控制终端并且周期性地执行某种任务或者等待处…...
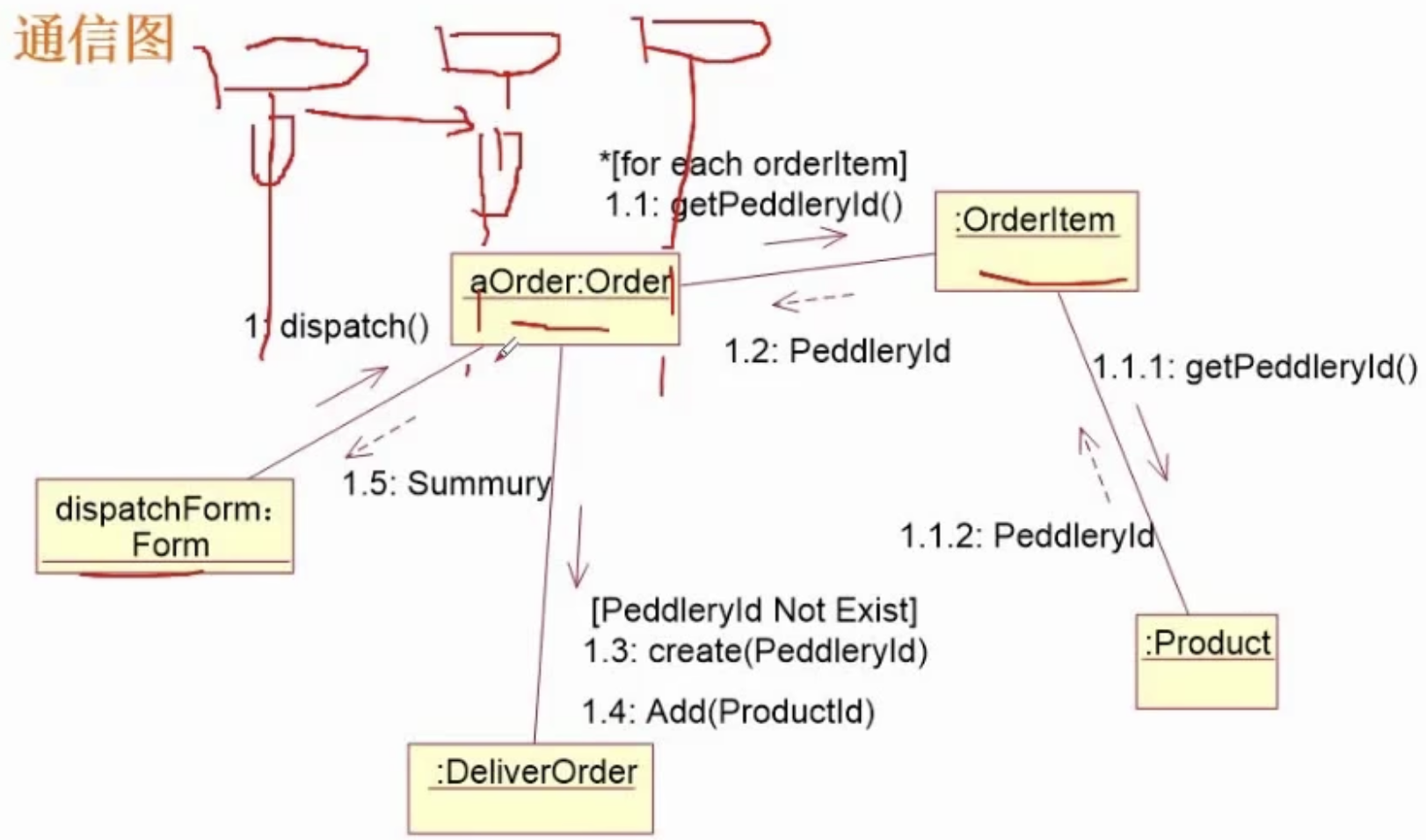
软件设计师笔记
软件设计师笔记 计算机组成与体系结构 数据的表示、计算机结构、Flynn分类法、CISC与RISC、流水线技术、存储系统、总线系统、可靠性、校验码 1. 数据的表示 (一)进制转换 R进制转十进制使用按权展开法: 十进制转R进制使用短除法 二进制…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...